In 1998, I was working on a billing system for a telecom company when we discovered that roughly $40,000 in charges had simply vanished from the database. Not stolen, not hacked, just gone. The root cause turned out to be a custom transaction handler written by a contractor who did not understand isolation levels. Two concurrent billing processes were reading and writing the same account records, and the lack of proper isolation meant updates were silently overwriting each other.
That was the week I stopped taking ACID properties for granted and started treating them as the most important thing to understand about any database system. Twenty-seven years later, I still believe that. ACID is not academic theory. It is the difference between a system that works and a system that loses your data under load.
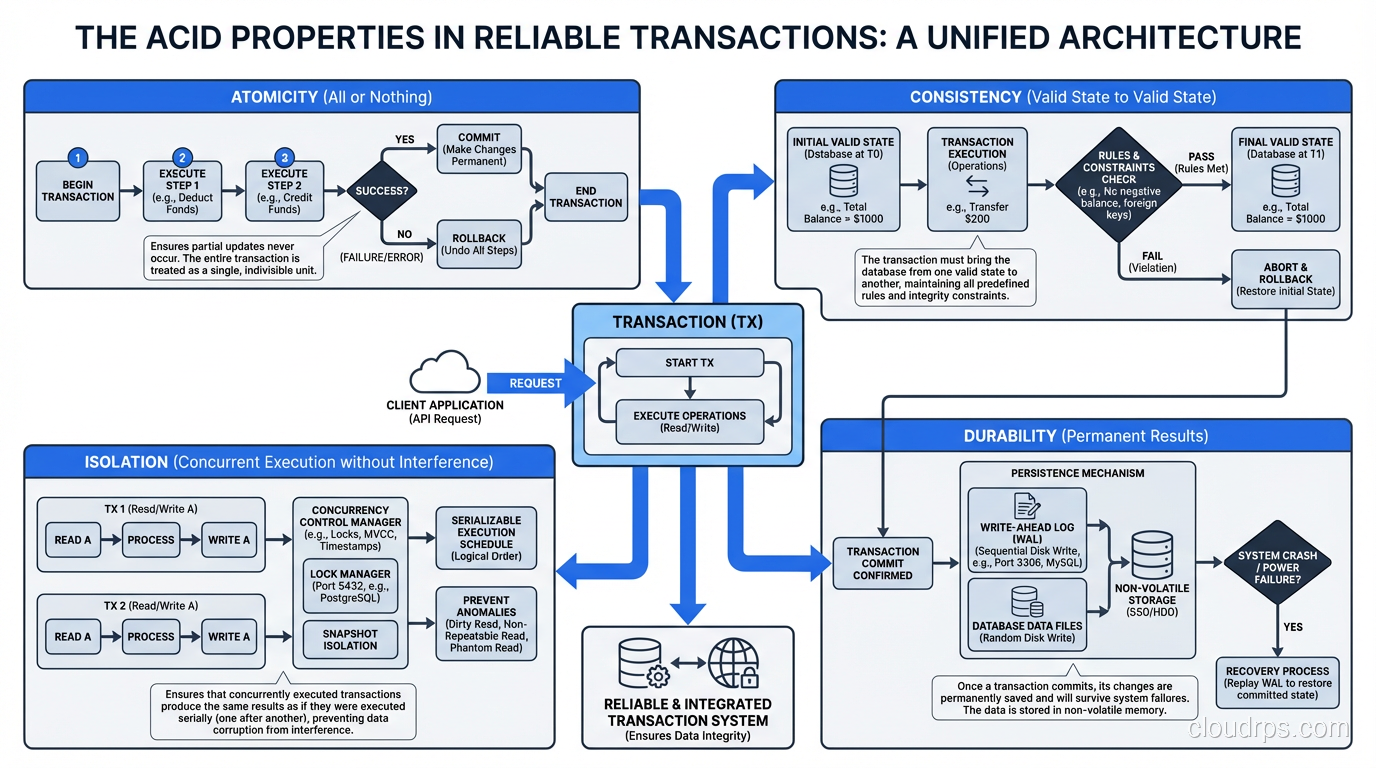
What ACID Actually Means
ACID is an acronym coined by Andreas Reuter and Theo Harder in 1983 to describe the properties that guarantee reliable transaction processing in a database. Every relational database (PostgreSQL, MySQL, Oracle, SQL Server) implements these properties, though the implementation details vary significantly.
Let me walk through each property with the concreteness that textbook definitions usually lack.
Atomicity: All or Nothing
Atomicity means that a transaction is indivisible. Every operation within a transaction either completes entirely or has no effect at all. There is no such thing as a partial transaction.
The classic example is a bank transfer. When you move $500 from checking to savings, two things must happen: $500 is subtracted from checking, and $500 is added to savings. Atomicity guarantees that both operations succeed or neither does. You will never end up in a state where the money was subtracted from checking but not added to savings.
How Atomicity Works in Practice
Under the hood, databases implement atomicity using a write-ahead log (WAL). Before any change is applied to the actual data files, the intended change is written to the WAL. If the transaction commits, the WAL entries are marked as committed and the changes are applied to the data files. If the transaction aborts (or the server crashes mid-transaction), the WAL entries for that transaction are rolled back, and the data files remain unchanged.
I once had to manually inspect a PostgreSQL WAL to diagnose a corruption issue. The experience gave me deep appreciation for how much work the database does behind the scenes to ensure that every transaction is atomic. The WAL is the unsung hero of database reliability.
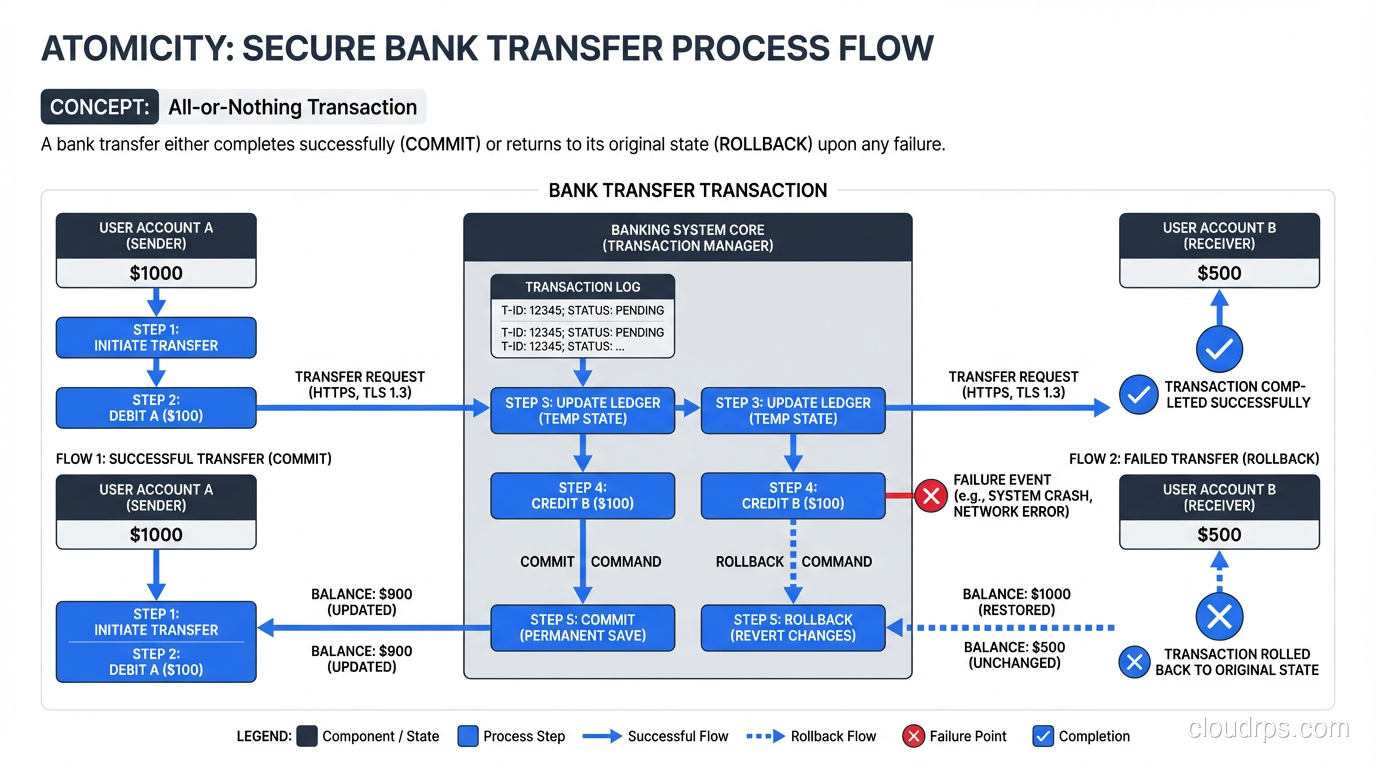
When Atomicity Saves You
Atomicity matters most in multi-step operations. Inserting an order and its line items. Updating an inventory count and recording the transaction. Creating a user account and assigning default permissions. Any operation that touches multiple rows or tables needs atomicity to prevent inconsistent partial states.
I have seen applications that perform multi-step operations without transactions (individual INSERT and UPDATE statements without a BEGIN/COMMIT wrapper), and the data inconsistencies accumulate silently until someone notices that the numbers do not add up. By then, untangling the mess is a multi-week project.
Consistency: Respecting the Rules
Consistency in the ACID sense means that a transaction can only bring the database from one valid state to another. “Valid” is defined by the constraints you have configured: primary keys, foreign keys, unique constraints, check constraints, and triggers.
If you have a foreign key constraint saying that every order must reference a valid customer, and a transaction tries to insert an order for a non-existent customer, the database will reject the entire transaction. The database never enters a state that violates its own rules.
Consistency Is Only As Good As Your Constraints
This is where I see people get tripped up. Consistency enforcement is powerful, but it only covers the rules you have actually defined. If you do not create foreign key constraints, the database will happily let you insert orphaned records. If you do not add check constraints, it will accept negative prices and impossible dates.
I am a strong advocate for pushing data integrity rules into the database layer rather than relying on application code. Application code can be bypassed by a bug, a migration script, or a direct database connection from a panicked developer at 2 AM. Database constraints cannot be bypassed. They are enforced at the storage layer, period.
One of the first things I do when I inherit a database is check the constraint coverage. It is disturbingly common to find databases with no foreign keys, no check constraints, and primary keys that are the only enforced rules. These databases invariably contain inconsistent data.
Consistency Across the Stack
Do not confuse ACID consistency with the consistency in the CAP theorem. They describe different concepts. ACID consistency is about enforcing constraints within a single database. CAP consistency is about whether all nodes in a distributed system see the same data at the same time. The overloaded terminology is unfortunate, but the distinction matters.
Isolation: Concurrent Transactions Without Chaos
Isolation is the property I find most engineers understand the least, and it is the one that causes the most subtle, hard-to-reproduce bugs. Isolation means that concurrent transactions execute as if they were running sequentially, even though they are actually running in parallel.
The Isolation Levels
The SQL standard defines four isolation levels, each offering a different trade-off between correctness and performance.
Read Uncommitted: The lowest level. A transaction can see changes made by other transactions that have not yet committed. This allows “dirty reads,” meaning you can see data that might be rolled back. I have never intentionally used this level in production. I honestly cannot think of a good reason to.
Read Committed: A transaction only sees data that has been committed by other transactions. No dirty reads, but you might get “non-repeatable reads.” If you read the same row twice within a transaction, the value might change between reads because another transaction committed a change in between. This is the default in PostgreSQL and Oracle.
Repeatable Read: Once a transaction reads a row, it will see the same value for that row for the duration of the transaction, even if other transactions modify and commit changes to it. This prevents non-repeatable reads but can still allow “phantom reads,” where new rows inserted by other transactions can appear in repeated queries.
Serializable: The strictest level. Transactions behave as if they executed one after another with no overlap. No dirty reads, no non-repeatable reads, no phantoms. The database detects conflicts and aborts transactions that would violate serializability.

The Real-World Cost of Weak Isolation
That $40,000 billing discrepancy I mentioned at the beginning? It happened because the application was using Read Committed isolation (the default) for a process that needed Repeatable Read or Serializable. Two billing processes would read a customer’s balance, calculate charges independently, and write back updated balances. Because each process saw the committed state at its read time, the second write simply overwrote the first, effectively erasing one set of charges.
This is a textbook “lost update” problem, and it is astonishingly common. I have found some version of this bug in at least a dozen systems over my career. The fix is usually straightforward: use a higher isolation level, or use SELECT FOR UPDATE to explicitly lock the row. But finding the bug in the first place requires understanding isolation well enough to know what to look for.
My Default Approach
I use Read Committed as my default and move to Serializable for specific transactions that involve read-modify-write patterns on shared data. The performance cost of Serializable is real; the database has to track dependencies and abort conflicting transactions. But for critical financial or inventory operations, the correctness guarantee is worth it.
PostgreSQL’s implementation of Serializable Snapshot Isolation (SSI) is particularly good. It detects serialization conflicts and aborts one of the conflicting transactions rather than using locks, which means you get serializable correctness without the throughput collapse that traditional locking-based serializable isolation can cause.
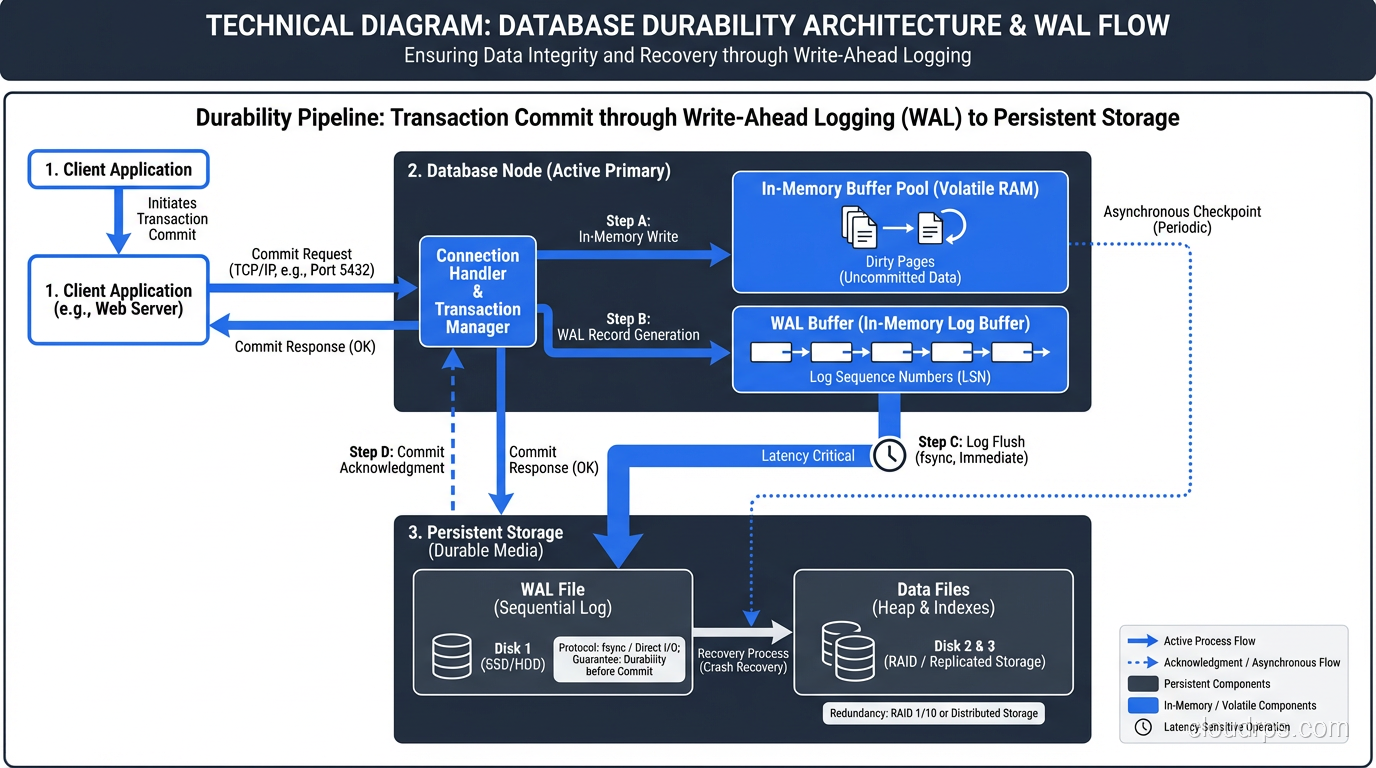
Durability: Surviving the Crash
Durability means that once a transaction is committed, it stays committed, even if the server loses power, the operating system crashes, or the hardware fails. The committed data is written to stable storage and will survive any non-catastrophic failure.
How Durability Works
Durability is implemented through the write-ahead log and a process called “fsyncing,” which forces the operating system to flush data from its write cache to physical storage. When a transaction commits, the database writes the WAL entry to disk and calls fsync to ensure it is truly on persistent storage before acknowledging the commit to the client.
This is why disabling fsync in PostgreSQL makes it faster but unsafe. Without fsync, the operating system might acknowledge a write that is still sitting in a volatile write cache. If the power goes out, that data is gone, and your “committed” transaction was a lie.
I had a heated argument with a developer in 2012 who wanted to disable fsync on a production PostgreSQL instance because “it made the benchmarks look better.” I explained that benchmarks that cheat on durability are meaningless. He was unconvinced until I pulled the power cord on a test server mid-benchmark and showed him the data loss. He never asked again.
Durability and Hardware
Durability depends on the entire stack, not just the database. Battery-backed write caches on RAID controllers ensure that data in the controller’s cache survives a power loss. UPS systems keep the server running long enough to flush writes. Enterprise SSDs have power-loss protection capacitors that allow them to flush their internal caches.
If any link in this chain is missing, your durability guarantee is weakened. I have seen data loss from every one of these failures: consumer SSDs without power-loss protection, RAID controllers with dead batteries, servers without UPS. Durability is a system-level property, not a database-level property.
ACID in Distributed Systems
The ACID properties become much harder to guarantee in distributed databases where data is spread across multiple nodes. Network partitions, node failures, and clock skew all introduce failure modes that single-node databases do not have to worry about.
This is the fundamental tension that the CAP theorem describes. Distributed databases that prioritize availability (like Cassandra) often provide weaker consistency and isolation guarantees. Databases that prioritize consistency (like CockroachDB or Spanner) use consensus protocols that add latency.
Understanding where your database falls on this spectrum is critical. If you are using DynamoDB with eventual consistency reads, you do not have ACID isolation. If you are using Cassandra with QUORUM reads and writes, you have a form of consistency but not ACID consistency. Know what guarantees your database actually provides, not what you assume it provides.
ACID Is Not Optional
Every few years, someone writes a blog post arguing that ACID is “too expensive” or “unnecessary for modern applications.” And every few years, those same applications end up with data corruption, lost transactions, or financial discrepancies that take months to untangle.
ACID properties exist because decades of real-world experience proved they are necessary for reliable data storage. The specific implementation details matter (which isolation level you choose, how you configure durability, what constraints you define), but the principles themselves are non-negotiable for any system that stores data you care about.
If you are building something where data integrity matters (and if it does not, why are you using a database at all?), start with a database that provides real ACID guarantees and be very deliberate about any decision to weaken those guarantees. You might decide that eventual consistency is acceptable for certain workloads. You might choose Read Committed over Serializable for performance reasons. But make those decisions explicitly, understanding what you are giving up, rather than stumbling into them by default.
The $40,000 that vanished from that billing system in 1998 taught me this lesson permanently. I hope reading about it saves you from learning it the same way I did.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.