Last year, I helped a fintech company deploy their first agentic AI system into production. The agent’s job was straightforward: process incoming support tickets, classify them, pull relevant account data, draft a response, and route complex cases to human agents. We tested it thoroughly in staging. The demo went great. Leadership was thrilled. We flipped it on for 10% of production traffic on a Tuesday morning.
By Thursday, the monthly LLM bill had already exceeded what we budgeted for the entire quarter.
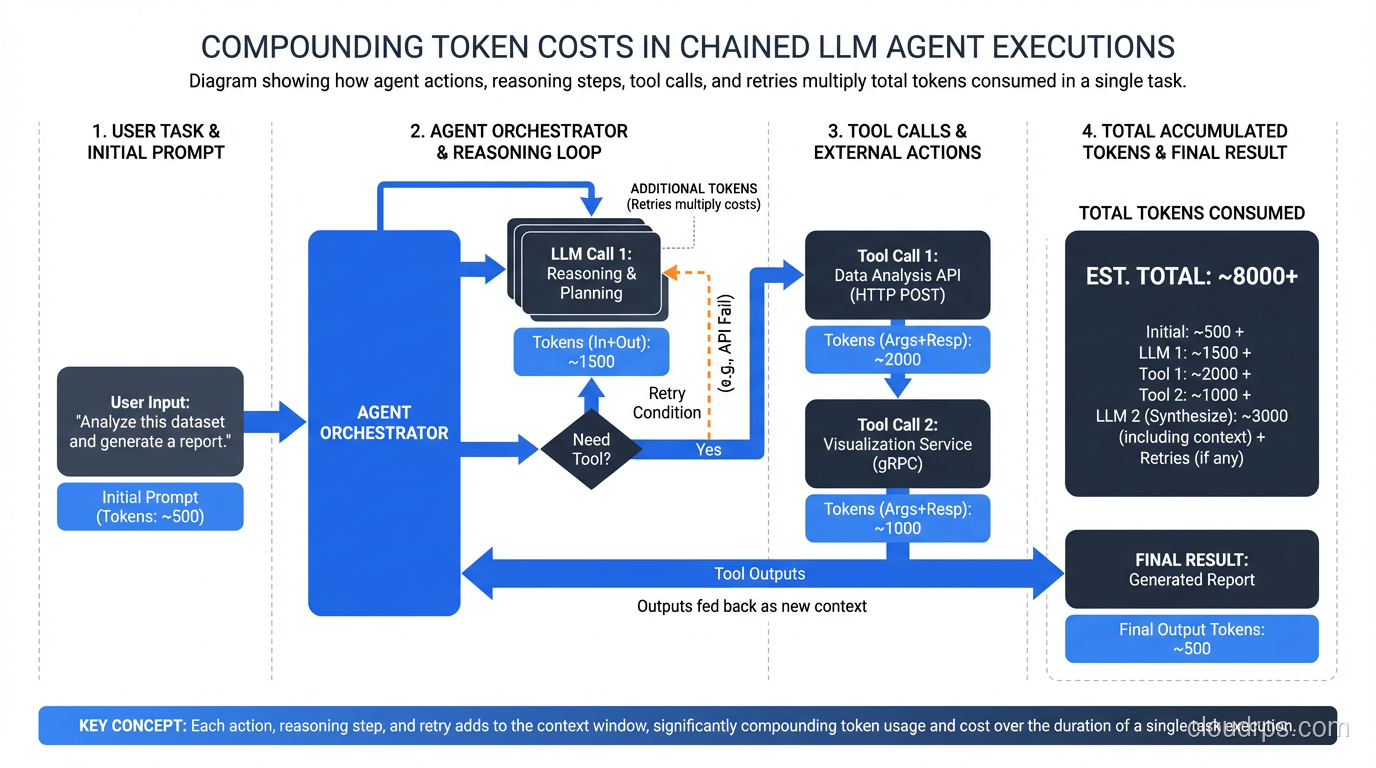
The agent was working. That was the maddening part. It was classifying tickets correctly, pulling the right data, writing decent responses. But it was also doing something we hadn’t anticipated: on roughly 15% of tickets, the agent would enter what I now call a “reasoning spiral.” It would pull account data, decide it needed more context, pull transaction history, realize it needed to cross-reference with another system, make three more API calls, reconsider its classification, start the draft over, and sometimes loop through this cycle four or five times before producing output. Each loop burned thousands of tokens. Multiply that by hundreds of tickets per hour, and you get the kind of invoice that makes a CFO’s eye twitch.
That experience taught me something that every team building with agentic AI eventually learns the hard way: the gap between “works in demo” and “works in production” is wider for agentic systems than for almost anything else in software engineering.
This article is the guide I wish I’d had before that deployment. If you’re building or planning to build agentic AI systems, everything here comes from real production experience, not theory.
What Makes Agentic AI Different
Before we get into the problems, let’s be precise about what we mean by “agentic AI.” A standard LLM API call is a function: input goes in, output comes out. You can reason about it the same way you reason about any API call. It’s expensive compared to traditional compute, sure, but it’s predictable.
Agentic AI is fundamentally different. An agent is an LLM that can:
- Plan: Break a goal into steps
- Use tools: Call APIs, query databases, execute code, search the web
- Observe: Process the results of its actions
- Reason: Decide what to do next based on what it learned
- Loop: Repeat this cycle until the task is complete
That loop is where everything changes. A simple LLM call has a bounded cost and bounded execution time. An agentic system has neither. The agent decides how many steps to take, which tools to call, and when it’s “done.” You’ve handed control flow to a probabilistic system, and if that sentence doesn’t make you slightly nervous, you haven’t run one in production yet.
This is also what makes agents so powerful. They can handle ambiguous, multi-step tasks that would require complex, brittle state machines if you tried to code them traditionally. But that power comes with a set of production challenges that most teams are completely unprepared for.
The Non-Determinism Problem
Here’s something that trips up every team coming from traditional software engineering: the same input to an agentic system can produce wildly different execution paths.
I don’t just mean the output text varies slightly. I mean the agent might take 3 steps to handle one request and 12 steps to handle an identical request five minutes later. It might call tools in a completely different order. It might decide a task requires human escalation on one run and handle it autonomously on the next.
This breaks almost every assumption in traditional software testing and monitoring. When your CI/CD pipeline runs your test suite, what does “passing” even mean for a system that behaves differently each time?
In practice, I’ve found the non-determinism falls into a few categories:
Benign variation. The agent takes a slightly different path but arrives at the same correct result. This is fine, and honestly, it’s similar to how humans work. Two experienced support agents might handle the same ticket differently but both resolve it correctly.
Cost variation. The agent arrives at the correct result but some paths cost 10x more than others. This is the most common production problem. Your average case is fine; your P99 is burning money.
Outcome variation. The agent arrives at genuinely different results for the same input. This is the dangerous one, especially in domains where consistency matters (finance, healthcare, legal).
Catastrophic variation. The agent enters a loop, calls a destructive action it shouldn’t have, or hallucinates a tool call that doesn’t exist. This is rare but devastating, and it’s why fault tolerance patterns matter even more for agentic systems than for traditional services.
The temptation is to try to eliminate non-determinism entirely (setting temperature to zero, using rigid prompts, constraining tool access). This works to a degree, but you’re fighting against the fundamental nature of the system. Push too hard and you end up with something that’s basically a very expensive, very slow decision tree. The better approach is to accept non-determinism and build systems that handle it gracefully.
Token Cost Management
Let me give you some real numbers. A moderately complex agent task (say, researching a topic across multiple sources and synthesizing a report) might consume 50,000 to 200,000 tokens per execution. At current pricing for frontier models, that’s $0.50 to $5.00 per task. That might sound cheap until you’re processing 10,000 tasks per day and your monthly bill hits $500K.
The cost structure of agentic AI is fundamentally different from traditional compute. With a web service, you can look at CPU/memory usage and make reasonable predictions about scaling costs. With agents, your costs are driven by the agent’s reasoning process, which is variable, context-dependent, and sometimes irrational.
Here’s what I recommend for cost management:
Per-Task Token Budgets
Every agent invocation should have a hard token budget. When the agent hits the budget, it must produce its best answer with what it has or gracefully fail. Don’t let it keep reasoning indefinitely.
In practice, I set three thresholds:
- Soft limit (70% of budget): Agent receives a system message telling it to start wrapping up
- Hard limit (90% of budget): Agent must produce output on the next step
- Kill switch (100%): Execution terminates and returns an error
Circuit Breakers
Borrow the circuit breaker pattern from microservices architecture. If an agent’s average token consumption exceeds 2x the expected amount over a rolling window, trip the breaker. This prevents cost spirals from propagating through your system. If you’re familiar with scaling patterns for web applications, the concept is the same. You need backpressure mechanisms that prevent runaway consumption from taking down your budget.
Cost Allocation and Chargeback
Tag every agent invocation with the customer, feature, and task type that triggered it. You need to know not just “we spent $50K on LLM calls last month” but “customer X’s workflow Y is costing us $12 per execution because the agent consistently enters reasoning spirals on their data format.”
Model Tiering
Not every agent step needs a frontier model. Use a fast, cheap model for classification, routing, and simple extraction. Reserve the expensive model for complex reasoning, planning, and synthesis. I’ve seen teams cut costs by 60-70% just by routing simple sub-tasks to smaller models.
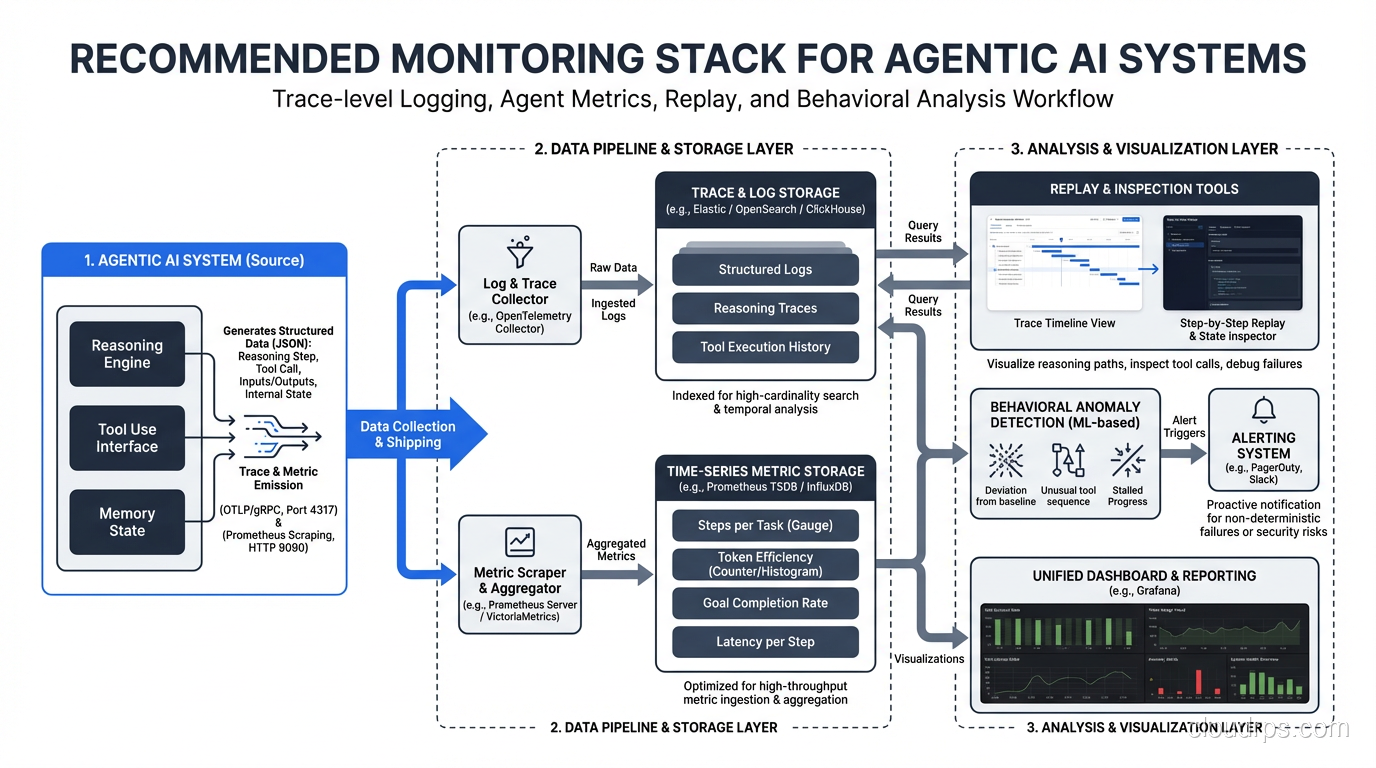
Observability and Tracing
Traditional monitoring and logging gives you metrics like request latency, error rates, and throughput. These matter for agentic systems too, but they’re woefully insufficient. When an agent produces a bad result, you need to understand why, and that means tracing through a multi-step reasoning process that might span dozens of LLM calls and tool invocations.
Here’s the observability stack I recommend for production agentic systems:
Trace-Level Logging
Every agent execution should produce a structured trace that captures:
- The initial input and goal
- Each reasoning step (the LLM’s chain-of-thought)
- Each tool call (input, output, latency, token count)
- Decision points (why the agent chose path A over path B)
- The final output and any metadata
Think of it like distributed tracing for microservices, but instead of tracking requests across services, you’re tracking reasoning across agent steps. Each step gets a span with parent-child relationships so you can reconstruct the full execution tree.
Agent-Specific Metrics
Beyond standard service metrics, track:
- Steps per task: How many reasoning/action cycles the agent takes
- Tool call distribution: Which tools get called and how often
- Reasoning loops: How often the agent revisits a previous step
- Token efficiency: Useful output tokens vs. total tokens consumed
- Outcome consistency: How often the same input produces the same classification/decision
- Abandonment rate: How often the agent gives up or hits a budget limit
Replay and Inspection
Build the ability to replay any agent execution with the exact same inputs, context, and tool responses. This is invaluable for debugging. When a customer reports a bad result, you should be able to pull up the trace, see exactly what the agent did, and replay it to understand the reasoning.
This is where the non-determinism gets tricky. Replaying with the same inputs won’t necessarily produce the same execution. What you want is a “deterministic replay” mode where you feed the agent the same tool responses it received originally, so you can see how it processed them. Think of it like a recorded debugging session.
Alerting on Behavioral Anomalies
Standard alerting (error rates, latency P99) still applies, but add behavioral alerts:
- Agent taking more than N steps for a task type that usually takes 3
- Token consumption exceeding 3x the rolling average for a task type
- Agent calling a tool it has never called before for a given task type
- Significant shift in output distribution (e.g., suddenly classifying 40% of tickets as “urgent” when the baseline is 10%)
These behavioral alerts have caught real production issues that traditional monitoring would have missed entirely.
Guardrails and Safety
An agent with access to tools can do real damage. I’ve seen agents in staging environments delete database records, send emails to real customers (in what was supposed to be a sandbox), and make API calls that triggered rate limits on third-party services. In production, the stakes are higher.
The guardrails framework I use has four layers:
Layer 1: Tool-Level Permissions
Every tool the agent can access should have explicit permission levels:
- Read-only tools: Can query data but not modify it
- Write tools with confirmation: Can prepare a write action but requires human approval before execution
- Autonomous write tools: Can execute writes without approval (use sparingly)
Start with everything requiring confirmation. Move tools to autonomous mode only after you have high confidence in the agent’s judgment for that specific tool.
Layer 2: Action Validation
Before any tool call executes, run it through a validation layer:
- Does this action make sense given the task context?
- Is the action within expected parameters? (e.g., “send email to 1 recipient” is fine; “send email to 10,000 recipients” is not)
- Has the agent already attempted this action and failed? (Prevent retry storms)
- Does this action conflict with any business rules?
A lightweight, deterministic validation layer here is worth its weight in gold. Don’t use another LLM call for validation; use good old-fashioned if-statements and business logic.
Layer 3: Output Filtering
Before the agent’s output reaches the user or downstream system, filter it:
- Check for PII or sensitive data that shouldn’t be in the output
- Validate that the output conforms to expected schema/format
- Run content safety checks if the output is customer-facing
Layer 4: Human-in-the-Loop Escalation
Define clear escalation criteria. The agent should recognize when it’s uncertain and escalate to a human rather than guessing. This is closely related to building high availability into your systems. Your agent pipeline needs a fallback path that keeps the overall system functional even when the agent can’t handle a particular case.
In practice, I’ve found that agents are often worse at knowing when they’re uncertain than they are at actually performing tasks. Explicitly training the agent to say “I’m not confident enough to handle this” and routing to a human queue is one of the highest-leverage safety investments you can make.
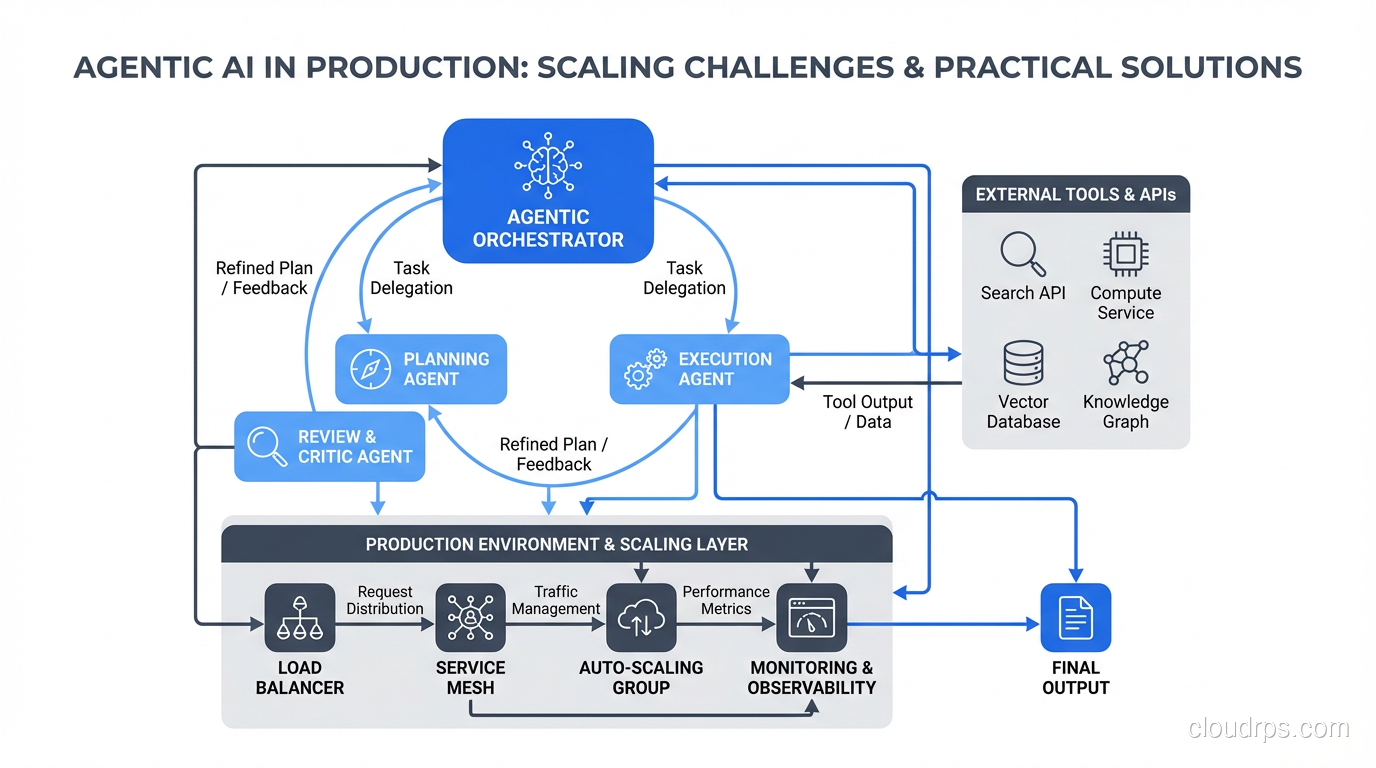
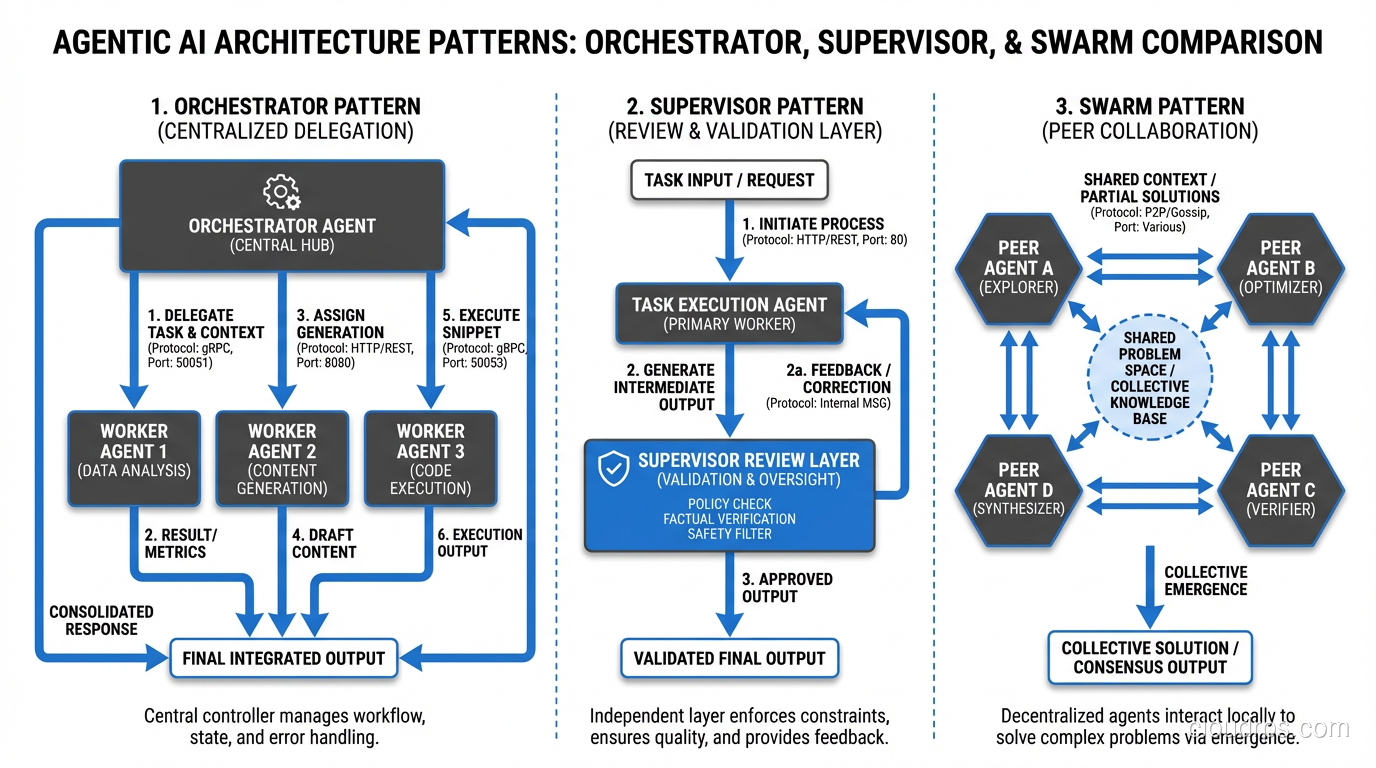
Architecture Patterns for Production
After building several production agentic systems, I’ve settled on three architecture patterns that cover most use cases.
The Orchestrator Pattern
One “orchestrator” agent receives the task, breaks it into sub-tasks, delegates each sub-task to a specialized worker agent, and synthesizes the results. This is the most common pattern and the one I recommend starting with.
The orchestrator handles planning and coordination. Worker agents are specialists: one handles data retrieval, another handles analysis, another handles writing. Each worker has a narrow tool set and a focused prompt.
Benefits:
- Each worker agent is simpler and more predictable
- You can set per-worker token budgets
- Failed workers can be retried without restarting the entire task
- Different workers can use different models (cost optimization)
Drawbacks:
- The orchestrator itself can become a bottleneck
- Communication overhead between orchestrator and workers adds latency and token cost
- Debugging requires tracing across multiple agents
The Supervisor Pattern
Similar to the orchestrator, but the supervisor doesn’t do the work directly. Instead, it reviews the output of each step and decides whether to accept it, request revisions, or escalate. Think of it as adding a quality control layer.
This pattern works well for high-stakes domains. In a disaster recovery context, for example, you might want an agent that generates a recovery plan but a supervisor agent that validates every step against your runbooks before execution.
The supervisor pattern roughly doubles your token costs (since every output gets reviewed), but it catches errors that would otherwise reach production. For most teams, the cost is worth it in high-stakes scenarios.
The Swarm Pattern
Multiple peer agents work on the same problem simultaneously and compete or collaborate. You might have three agents independently research a topic and then synthesize their findings, or have agents propose competing solutions that get evaluated.
This pattern is expensive but produces the highest quality output. I use it for tasks where accuracy matters more than cost: financial analysis, legal document review, critical infrastructure decisions.
The swarm pattern also gives you a natural confidence signal. If all three agents agree, you can be more confident in the result. If they disagree significantly, that’s a signal for human review.
Testing Strategies for Non-Deterministic Systems
Traditional unit tests (given input X, expect output Y) don’t work well for agentic systems. Here’s what does.
Property-Based Testing
Instead of testing for exact outputs, test for properties the output should have. “The agent’s response should contain a valid order number,” not “the agent’s response should be this exact string.” This approach accommodates non-determinism while still catching real bugs.
Statistical Testing
Run the same test case 20 or 50 times and evaluate the distribution of results. You’re looking for:
- Success rate above threshold (e.g., 95% of runs produce a correct result)
- Cost distribution within budget (e.g., P95 token cost below $X)
- No catastrophic failures (e.g., zero runs that call a forbidden tool)
This is expensive and slow compared to traditional tests, so reserve it for critical paths.
Evaluation Frameworks
Build (or adopt) an eval framework that scores agent outputs on multiple dimensions: correctness, completeness, safety, cost efficiency, and latency. Track these scores over time. When you change a prompt, swap a model, or modify tool definitions, rerun your eval suite and compare.
Think of evals as the agentic AI equivalent of your CI/CD test suite. They should run automatically on every change that affects agent behavior.
Chaos Testing for Agents
Inject failures into tool responses and see how the agent handles them. Return errors from APIs. Inject latency. Return garbage data. A well-built agent should degrade gracefully, not spiral into a retry loop that burns your token budget.
This is the agent equivalent of chaos engineering, and it’s just as important. The first time one of your downstream APIs has a real outage, you’ll be glad you tested for it.
Shadow Mode
Before deploying a new agent version to production, run it in shadow mode alongside the existing version. Both process the same inputs, but only the existing version’s output reaches customers. Compare the outputs offline.
Shadow mode is the single best practice for safe agent deployment. Yes, it doubles your LLM costs during the comparison period. The alternative is discovering problems in production. Every team that has told me “we can’t afford shadow mode” has ended up spending more on incident response.
Understanding Latency in Agent Systems
Agent latency is fundamentally different from traditional API latency, and it’s worth understanding why. A typical agent task involves multiple sequential LLM calls (each taking 1 to 5 seconds) plus tool calls (variable latency depending on the tool). A 10-step agent task might take 30 to 60 seconds end-to-end.
This changes your architecture. You can’t have users staring at a spinner for a minute. You need:
- Streaming output so users see progress as the agent works
- Async processing with webhooks or polling for long tasks
- Progress indicators that show which step the agent is on
The distinction between latency and bandwidth matters here too. Agent systems are latency-bound, not bandwidth-bound. You can’t compensate for slow sequential reasoning by throwing more bandwidth at it. The critical optimization is reducing the number of reasoning steps, not making each step faster.
For user-facing agents, consider a hybrid approach: use a fast, simple model to generate an immediate response, then have the full agent pipeline run asynchronously and update the response when it’s ready.
Practical Recommendations for Getting Started
If you’re just starting with agentic AI in production, here’s my honest advice after deploying these systems across several organizations.
Start with a narrow, well-defined task. Don’t try to build a general-purpose agent. Pick one specific workflow where an agent can add clear value, constrain its tools and scope tightly, and get that working reliably before expanding.
Budget for 3x your expected LLM costs. Whatever your back-of-the-envelope cost estimate says, triple it. The reasoning spirals, retries, and edge cases will eat your budget faster than you expect.
Build observability from day one. Don’t add tracing later. Instrument your agent pipeline before your first production deployment. You will need those traces within the first week, guaranteed.
Use the orchestrator pattern first. It’s the simplest to reason about, debug, and scale. Move to supervisor or swarm patterns only when you have a specific need that the orchestrator can’t meet.
Keep humans in the loop. Start with human approval for all write actions. Relax the approval requirement gradually as you build confidence. Never remove the ability for the agent to escalate to a human.
Treat prompt changes like code changes. Version your prompts. Review them in PRs. Test them with your eval suite. A small prompt change can dramatically alter agent behavior in ways that aren’t obvious until you see the effects at scale.
Agentic AI is the most exciting and the most operationally demanding pattern in modern cloud architecture. The teams that succeed with it are the ones who respect its complexity, invest in observability and safety from the start, and resist the temptation to deploy fast and fix later. The cost of “fix later” in an agentic system is measured in dollars, customer trust, and occasionally, data that can’t be undeleted. Take the time to get it right.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.