I spent most of 2024 helping a fintech company manage their OpenAI bill. They had dozens of product teams, each integrating directly with the OpenAI API using keys that lived in CI secrets and developer laptops. By the time I arrived, the monthly invoice was north of $80,000, nobody could tell you which feature was responsible for which chunk of that spend, and one engineer had accidentally looped a prompt in a script that ran for six hours before anyone noticed. Fixing this required exactly one thing: putting a proper gateway in front of every LLM call in the company.
That experience shaped how I think about AI gateway architecture. The gateway is not optional infrastructure. It is the control plane for your entire AI cost, reliability, and governance story, and the sooner you build it right, the less pain you absorb later.
What an AI Gateway Actually Is
A traditional API gateway handles authentication, rate limiting, and routing for REST and GraphQL services. An AI gateway does all of that, plus a set of problems that are unique to LLM workloads: token-based cost accounting, semantic caching, model fallback routing, prompt injection filtering, and output validation.
The distinction matters because LLM APIs are not like regular APIs. A single request might consume a few hundred tokens or fifty thousand, depending on context window size. Response latency ranges from 200ms to 90 seconds for complex reasoning models. Provider pricing changes constantly, with different rates for input tokens, output tokens, cached tokens, and batch versus real-time requests. None of these dynamics fit cleanly into traditional API gateway tooling without significant extension.
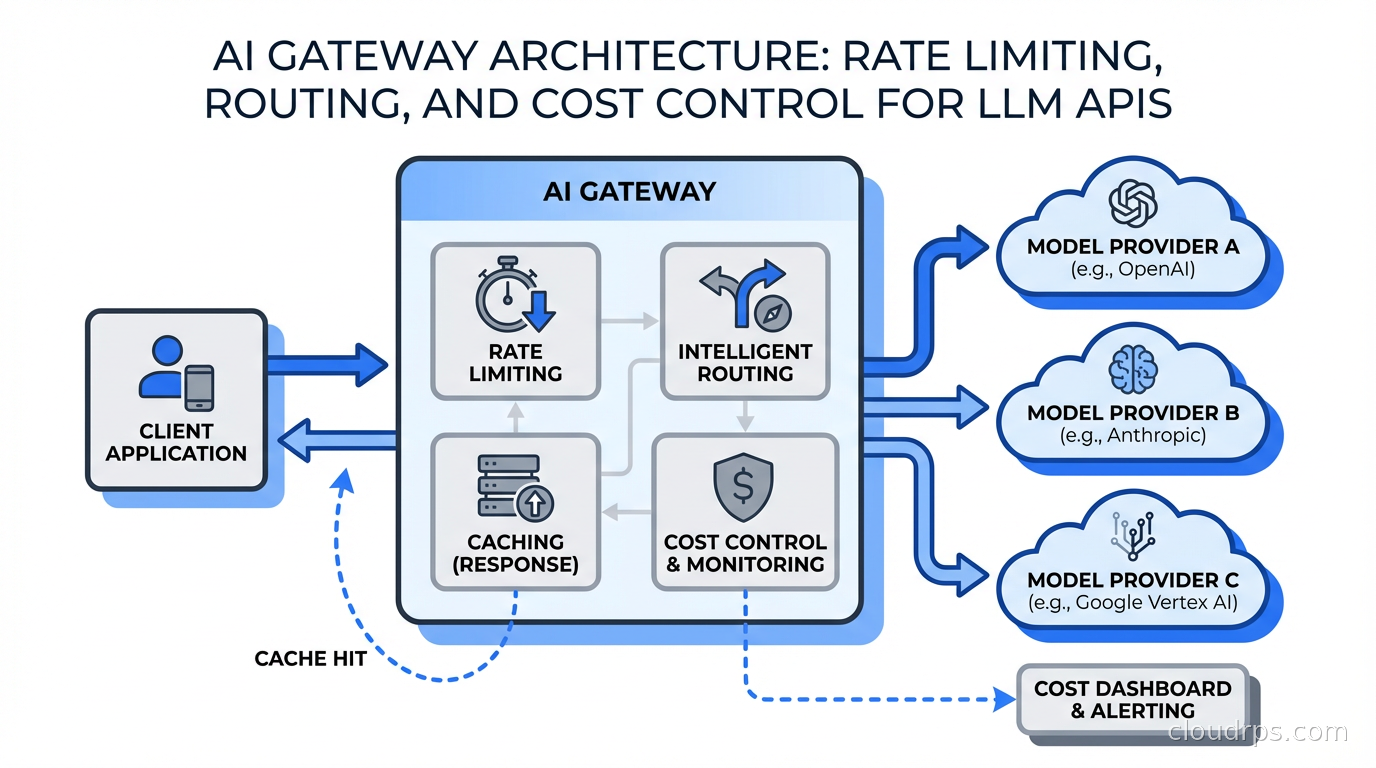
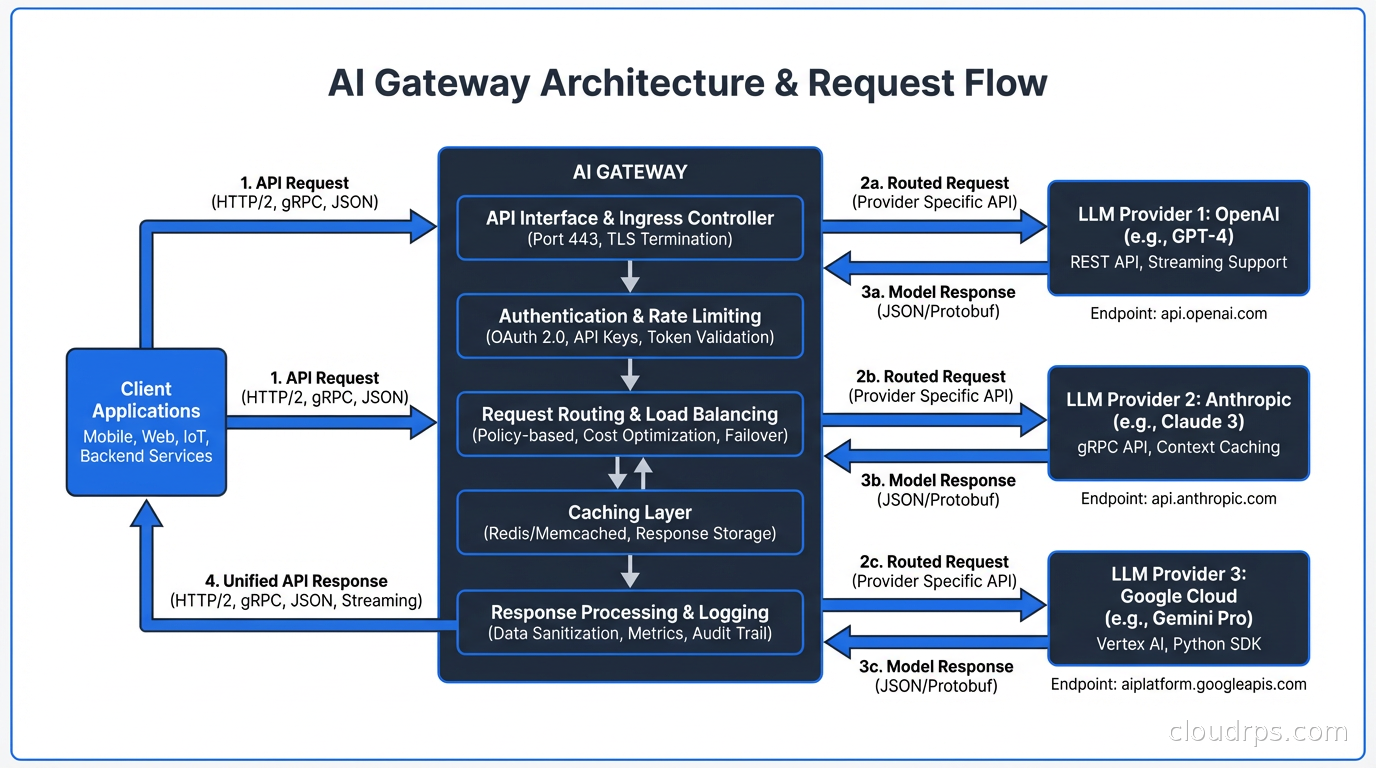
The AI gateway sits between your applications and the upstream model providers: OpenAI, Anthropic, Google Vertex AI, AWS Bedrock, Mistral, and your own self-hosted models. Every LLM call in the organization flows through it. This single choke point gives you control you cannot get any other way.
Core Capabilities You Need from Day One
Unified Authentication and Key Management
The first thing a gateway gives you is a single place to manage provider API keys. Instead of every service holding an OpenAI key in its environment variables, every service authenticates to the gateway with an internal credential. The gateway holds the upstream provider keys and rotates them without touching application code.
This matters for security and for operational hygiene. If a provider key leaks, you rotate one secret in one place. If you need to audit which services called which models, you have a single log to query. Pair this with your secret management infrastructure and you have a complete access control story.
Per-Consumer Rate Limiting
Token-based rate limiting is where LLM gateways differ most from traditional ones. You cannot just count requests per second. A single request that sends a 100,000-token context window costs as much as 200 ordinary requests. Your rate limiting needs to operate on token counts, not just request counts.
The architecture that works in practice uses a hierarchical limit structure. At the top level, you have global limits per provider to prevent billing surprises. Below that, you have team-level or product-level quotas. At the bottom, you have per-user or per-service limits for granular control. When a consumer hits their token quota, the gateway returns a 429 with a retry-after header rather than letting the request through and charging the overage.
One client of mine set hard monthly token budgets per engineering team, enforced at the gateway. The first month, three teams ran out of budget in the second week and came to me asking for increases. That forced them to actually think about whether their implementation was efficient. Most of them rewrote their prompts and got the same quality at 40% of the token cost.
Cost Attribution and Chargeback
Without a gateway, your LLM spend is a single line item on a provider invoice. With a gateway, every request carries metadata: team ID, service name, feature flag, user segment, whatever dimensions matter to your organization. The gateway logs token counts for every request and aggregates them into a cost database.
This feeds into FinOps practices for AI workloads. When a product manager asks why the AI feature costs so much this quarter, you can break it down by feature, by model, by team, and by time. When you are evaluating whether to upgrade from GPT-4o to o3, you can run the comparison in production on real traffic and see the actual cost delta before committing.
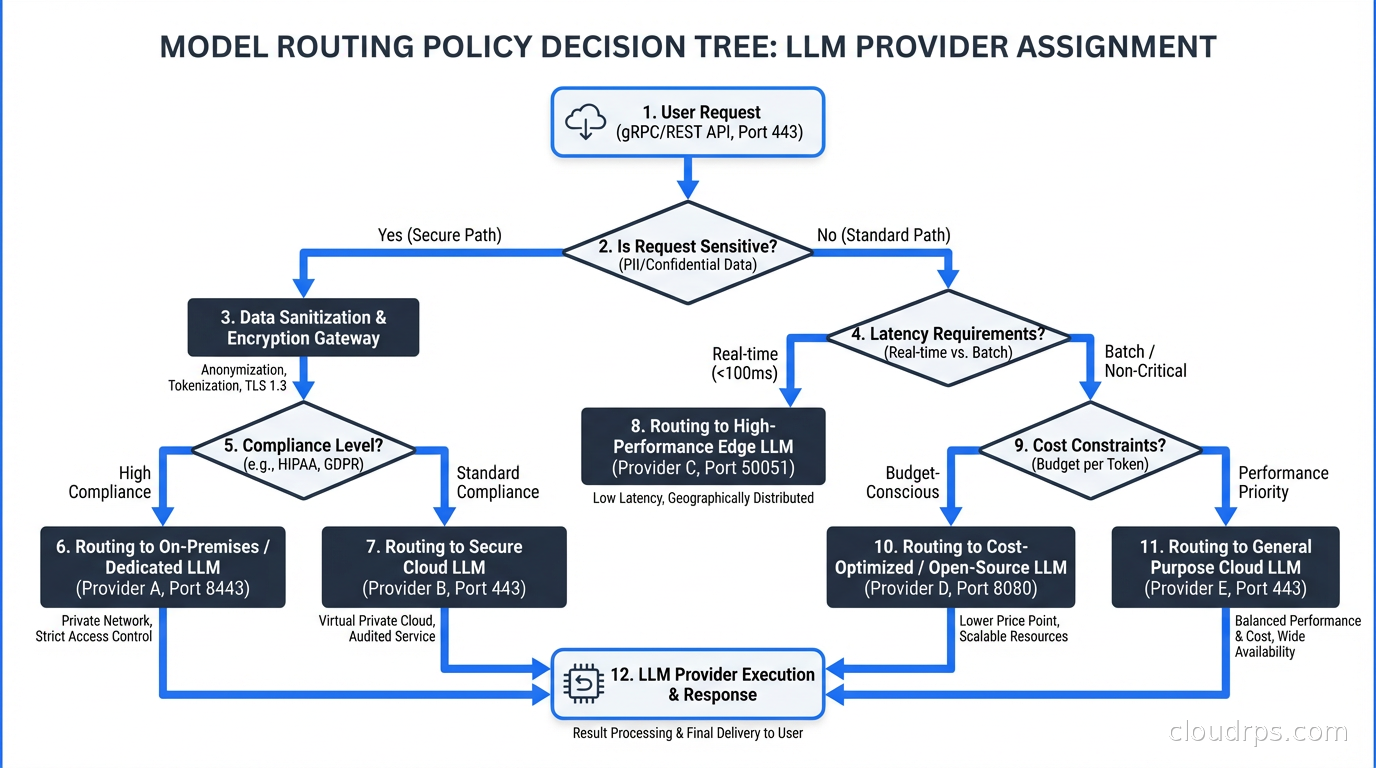
Model Fallback and Routing
Running a single model provider in production is a reliability risk. OpenAI has had outages. Anthropic has had capacity constraints. Google Vertex AI has had regional incidents. A gateway with model fallback lets you define routing policies that automatically switch to a secondary provider when the primary is degraded.
The routing logic can be more sophisticated than simple failover. You can route based on request characteristics: send long-context requests to a model with a large context window, route latency-sensitive requests to a faster model, send batch summarization jobs to a cheaper model. I have seen teams run Haiku for simple classification, Sonnet for standard generation, and Opus or GPT-4o only for tasks where output quality is genuinely measured by users.
This kind of intelligent routing integrates naturally with your overall LLM inference infrastructure. Self-hosted models via vLLM or TGI can be one of the routing targets alongside commercial providers, letting you shift traffic to cheaper dedicated capacity when it is available.
Semantic Caching: The Highest-Leverage Optimization
Traditional caching returns the same response for identical requests. LLM caching is harder because no two prompts are exactly the same, but similar prompts often deserve the same answer. Semantic caching uses embedding similarity to match incoming requests against a cache of previous responses.
Here is how it works in practice. When a request arrives, the gateway embeds the prompt using a fast embedding model. It then queries a vector database for the nearest cached prompt above a similarity threshold, typically around 0.92 cosine similarity. If a match exists, the gateway returns the cached response without touching the upstream provider. If no match exists, the request goes upstream, and the response is stored in the cache with its embedding.
The hit rate depends heavily on your use case. For customer-facing chatbots where users frequently ask variations of the same questions, semantic cache hit rates of 30-60% are realistic. For coding assistants where every prompt is unique code context, cache hit rates might be 5%. For batch document processing where you are running the same summarization prompt on many documents, you might cache the prompt template and vary only the document content, which changes the calculus entirely.
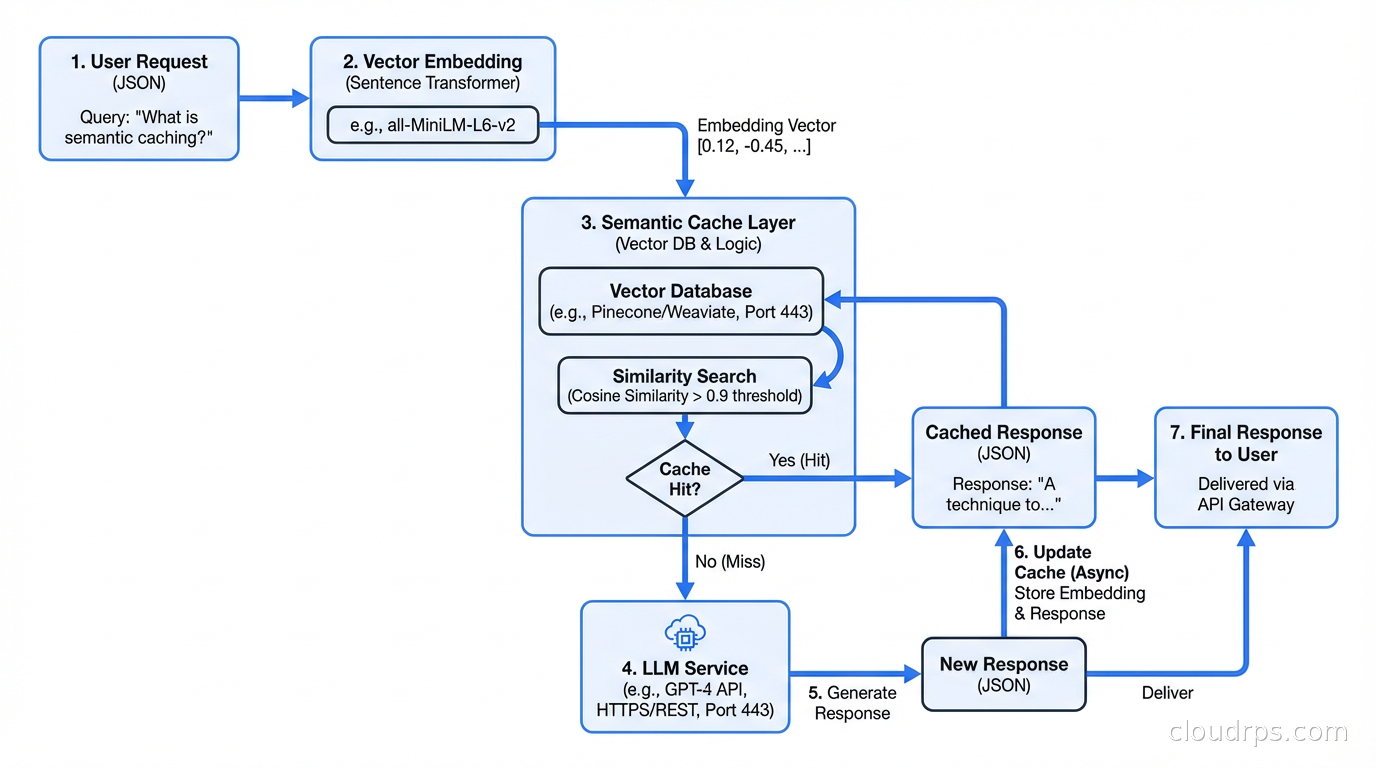
The infrastructure behind semantic caching is a vector store plus a key-value store. The vector store holds embeddings for lookup. The key-value store holds the actual responses, keyed by a hash of the matched prompt. Redis with vector search extensions works for moderate scale. For higher throughput, dedicated vector databases handle the similarity search more efficiently.
Cache invalidation is the nuanced part. LLM responses can become stale if the underlying model is updated or if your prompt templates change. A TTL-based approach with a maximum age of a few days handles most cases. For accuracy-critical applications, version your cache keys on the model version and prompt template version so cache entries are automatically invalidated when either changes.
Prompt Injection and Content Filtering
Your gateway is the right place to run safety checks on both inputs and outputs. Not because it replaces model-level safety systems, but because gateway-level filtering is fast, cheap, and gives you consistent enforcement across all models.
Input filtering catches obvious prompt injection attempts: instructions embedded in user input that try to override system prompts, jailbreak patterns, requests for content that violates your policies. A lightweight classifier running at the gateway can reject these before they ever reach the expensive upstream model.
Output filtering catches policy violations in responses: PII exposure, confidential data leakage, harmful content that slipped through model-level filters. Scan the response before returning it to the client. If it fails your filters, you can either redact the problematic content, return an error, or retry with a modified prompt.
This ties directly into the security story for agentic AI workloads. When your agents are calling LLMs to make decisions that have real-world consequences, gateway-level content filtering is one of the defensive layers that keeps an adversarial input from hijacking the entire workflow.
Observability: What to Instrument
A gateway without good observability is a black box you cannot manage. The instrumentation I always put in place covers three layers.
Request telemetry: Every request gets a trace ID that flows through to the upstream provider. Log the model, the token counts for input and output, the latency to first token and total latency, the consumer identity, and the routing decision. These records feed your cost dashboards and your debugging workflow.
Error tracking: Track provider errors separately from gateway errors. A 503 from OpenAI is different from a 429 you imposed because a consumer hit their rate limit. Track provider error rates over time so you can detect degradation before it becomes an incident and trigger fallback routing preemptively.
Latency distributions: LLM latency is not normally distributed. A p50 of 800ms and a p99 of 45 seconds is a common profile. Median-based dashboards hide the long tail completely. Track p95, p99, and p999 latency, and alert on the p99 crossing thresholds, not the median.
Deployment Patterns
Sidecar vs. Centralized Gateway
Two main deployment topologies exist. A centralized gateway is a dedicated service that all LLM traffic routes through. It is operationally simple, easy to reason about, and gives you a single place to apply policy changes. The downside is that it is a potential single point of failure and a potential latency bottleneck if not sized correctly.
A sidecar pattern deploys a gateway proxy as a sidecar container alongside each application, similar to how service meshes handle service-to-service traffic. Each sidecar handles local caching, rate limiting enforcement (consulting a central state store), and routing. Policy updates push to all sidecars via a central control plane. This pattern adds operational complexity but reduces the blast radius of gateway failures and eliminates the centralized latency bottleneck.
Most teams start with a centralized gateway and move to a more distributed model as they grow. The centralized model is correct for the first 18 months in almost every organization I have worked with.
Running the Gateway
Popular open-source options include Kong AI Gateway (which extends Kong’s existing plugin ecosystem with LLM-specific plugins), LiteLLM (a Python-based proxy that normalizes the API surface across providers), and Portkey (a managed service with an open-source core). Netflix and several other large companies have built bespoke internal gateways.
For self-hosted deployments, the gateway needs to run with at least three instances for availability, behind a load balancer. The semantic cache and rate limit state live in a Redis cluster shared across all gateway instances. The cost accounting database is typically a columnar store like ClickHouse or BigQuery that can handle high write throughput and complex aggregation queries.
The Organizational Dimension
Building the technical gateway is the easier half. The harder half is getting every engineering team to route their LLM calls through it.
The approach that has worked for me is making the gateway the path of least resistance. If using the gateway gives you better observability, handles retries and fallbacks automatically, and manages credential rotation, teams will use it because it makes their lives easier, not because a policy mandates it. Mandate adherence is fragile. Infrastructure that earns adoption is robust.
Build client libraries in the languages your teams use that default to hitting the gateway endpoint. Make the gateway transparent to existing OpenAI SDK code by implementing the OpenAI API schema and accepting the same request format. Teams can switch from hitting api.openai.com to hitting ai-gateway.internal.company.com by changing one environment variable.
The fintech team I started with went from unattributed chaos to full cost visibility in six weeks. The gateway took two weeks to build and deploy. The remaining four weeks were spent migrating services and convincing holdouts. Three months after rollout, their monthly bill dropped from $80,000 to $34,000, mostly from semantic caching and the rate limits forcing engineers to write more efficient prompts. The gateway paid for itself in the first billing cycle after migration was complete.
What the Mature Architecture Looks Like
A fully mature AI gateway organization has:
Policy as code: Routing rules, rate limits, and filtering policies defined in version-controlled configuration, deployed via CI/CD. No manual changes to the running gateway.
Shadow mode testing: New models evaluated by routing a percentage of traffic to them and comparing outputs against the production model without exposing the results to users. This gives you quality benchmarks on real traffic before cutting over.
Budget enforcement: Hard stops, not just soft alerts. When a team exhausts their monthly token budget, their requests fail gracefully until the next budget period. This sounds harsh but it forces economic discipline that produces better software.
Feedback loops: The gateway logs whether downstream systems flagged LLM responses as incorrect or unhelpful. That feedback feeds model selection and routing policy tuning. You learn which models perform best for which tasks in your specific context, not just on generic benchmarks.
The AI gateway is infrastructure that pays compounding returns. The longer it runs, the more cost data you accumulate, the better your routing policies become, and the more your semantic cache fills up with useful entries. Teams that build it early end up with a significant operational advantage over teams that bolt it on after the LLM bill becomes a crisis. Build it before the crisis, not after.
Further Reading
If you are building out AI infrastructure beyond the gateway layer, the companion piece on LLM inference infrastructure covers GPU selection, model serving frameworks, and batching strategies for self-hosted models. For the distributed systems challenges that come with agentic workloads that your gateway will be serving, agentic AI in production covers orchestration patterns, failure modes, and observability for multi-step agent workflows. The foundational API gateway concepts apply directly to AI gateways, especially the sections on authentication and plugin architecture.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.