In 2018, I was brought in to fix a fraud detection pipeline that was running on a home-grown micro-batch system built on top of Spark Streaming. The latency was around 90 seconds end to end, which meant the fraud signals were arriving after the transaction had already cleared. By the time the alert fired, the money was gone. We migrated to Apache Flink over a three-month period. Processing latency dropped to under two seconds. That was the moment I understood that stream processing is not just “batch processing but faster.” It is a fundamentally different computational model, and Flink is one of the few systems built from first principles around that model.
Flink has since evolved into the dominant stateful stream processing engine. Flink 2.0 (released early 2025) was the biggest architectural shift since Flink 1.0, and Flink 2.2 followed with native AI inference in SQL, a disaggregated state backend, and a stable Kubernetes operator with blue/green deployment support. If you are running Flink in production or planning to, this article covers everything you actually need to know: how the architecture works, how state and checkpointing really function, the traps that will hurt you in production, and how to run it properly on Kubernetes.
What Makes Flink Different
Before diving into architecture, it is worth being precise about what Flink is and what it is not.
Flink is a distributed, stateful stream processing engine with exactly-once guarantees. The key word is “stateful.” If you just need to transform events as they arrive (add a field, parse a JSON string, route based on a condition), you do not need Flink. Kafka Streams or even a simple Kafka consumer handles that fine.
What Flink is for is computations that require memory across events over time. Aggregations over sliding windows. Join operations between two event streams that arrive at different rates. Complex event pattern detection (find a sequence of events matching X followed by Y within 30 seconds). Stateful deduplication. Entity enrichment where you maintain a local cache of database records. These workloads require state, and managing distributed state with fault tolerance is what Flink does extraordinarily well.
Compared to Apache Spark Streaming, Flink is native streaming rather than micro-batch. Spark Streaming (and Structured Streaming) processes data in small batches at regular intervals. Flink processes each event as it arrives. This is not just a latency difference; it is a correctness difference for workloads that require true event-time processing. I will explain why in the watermarks section.
For a broader comparison of stream processing tools, the stream processing overview covers the landscape. This article goes deeper on Flink specifically.
Core Architecture: JobManager, TaskManagers, and Tasks
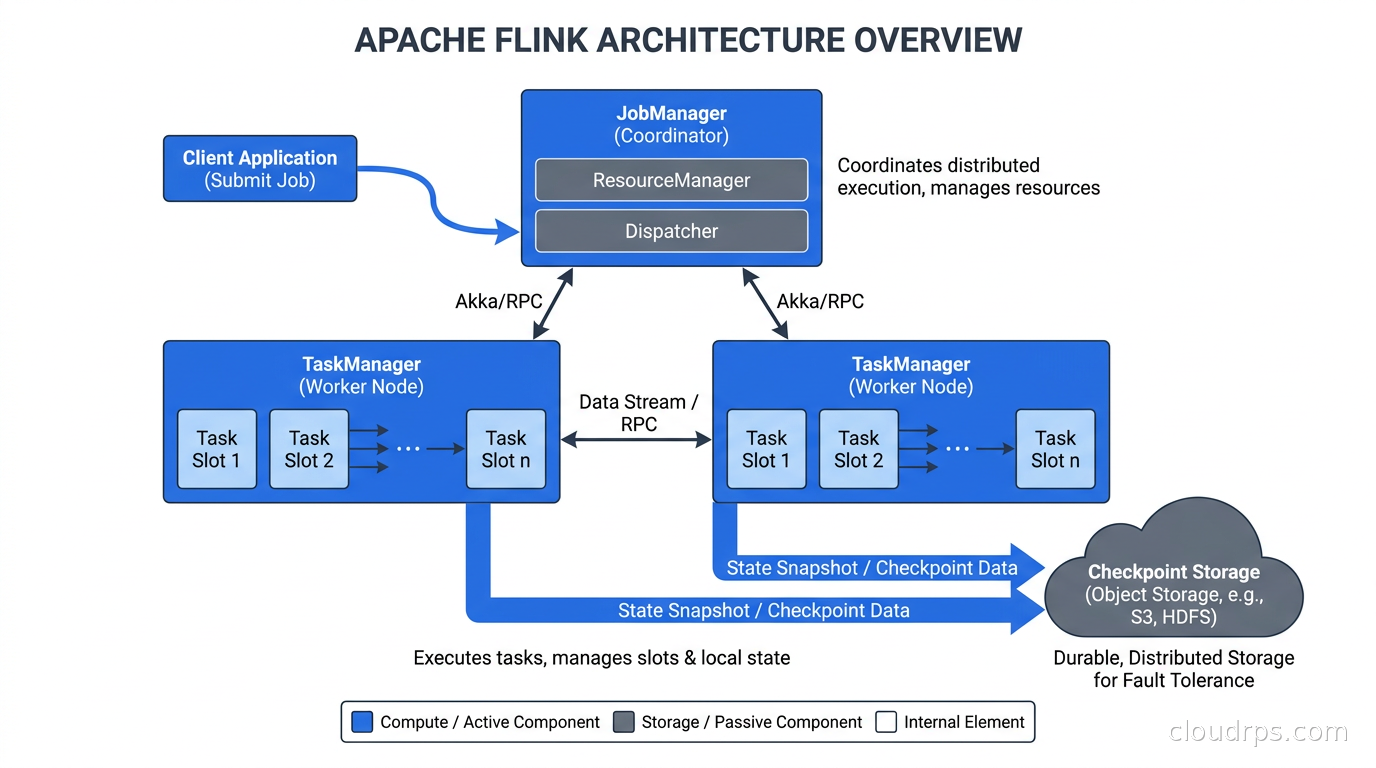
Every Flink deployment has two types of processes.
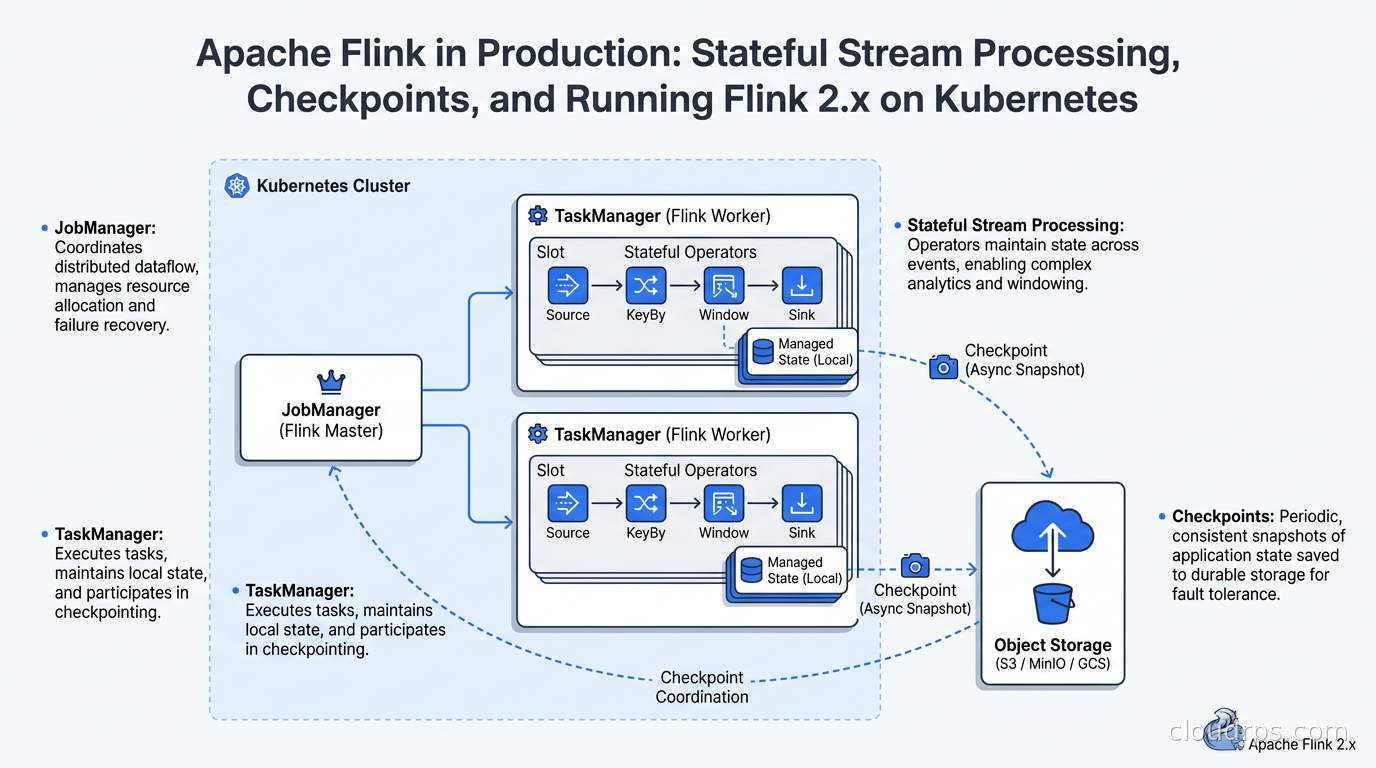
The JobManager is the coordinator. It receives the job submission, breaks the job into a parallel execution plan (the JobGraph), schedules tasks onto TaskManagers, coordinates checkpointing, and handles failure recovery. In production, you run the JobManager in high-availability mode backed by ZooKeeper or Kubernetes native leader election. A failed JobManager triggers an HA failover; Flink recovers from the last completed checkpoint and continues. You never lose processed state, only the in-flight events since the last checkpoint.
TaskManagers (formerly called workers or nodes) are where the actual computation happens. A TaskManager has a fixed number of task slots, and each slot runs one parallel instance of a task in your pipeline. Task slots share memory within a TaskManager process but each slot’s state is isolated. Parallelism in Flink is per-operator. If you set parallelism to 16 on a filter operator and 4 on an aggregation, those are scheduled independently across available task slots.
The execution model is a directed acyclic graph of operators connected by network channels. Flink tries to chain adjacent operators into a single task (called operator chaining) to avoid network overhead between operators that can run in the same JVM thread. Understanding chaining matters for performance tuning. You can force chain breaks when an operator is a bottleneck and you want to control its parallelism independently.
State: The Core Concept You Must Get Right
Flink provides two types of state, and choosing between them is the most consequential architectural decision in any Flink job.
Keyed State is partitioned by key. Each key owns its own state variables. If you are processing a stream of user events and computing “total spend per user in the last 7 days,” each user ID maps to a specific key partition, and that partition’s state contains only that user’s data. Keyed state scales horizontally because Flink can redistribute key partitions across TaskManagers when you rescale the job.
Operator State is per operator instance, not partitioned by key. A common use case is storing the current Kafka partition offsets that an operator is reading. Operator state is less common in typical business logic but important for source and sink connectors.
Within keyed state, Flink provides several state primitives: ValueState (single value), ListState (list of values), MapState (key-value map), ReducingState (a value that is updated via a reduce function), and AggregatingState. For most aggregation work, MapState is the workhorse. One thing I have seen trip up engineers: MapState is not a distributed map shared across all TaskManagers. It is local to each key partition. Think of it as “the map that belongs to this key,” not “a shared lookup table.”
State needs to be serialized, and Flink’s serialization framework is worth understanding. Flink uses its own binary serialization format for primitive types and type-erased Kryo serialization for complex objects. The Flink serializer is significantly faster than Kryo for types it can handle natively. Avoid relying on Kryo for hot state paths; define proper POJO types and use Flink’s TypeInformation system to get the optimized serializer.
State Backends: Where State Actually Lives
In Flink 1.x, you had three state backend options: MemoryStateBackend (for development only), FsStateBackend (state on TaskManager heap, snapshots to filesystem), and RocksDBStateBackend (state in RocksDB on disk, snapshots to filesystem).
Flink 2.0 consolidated and renamed these: HashMapStateBackend (in-memory, replaces MemoryStateBackend and FsStateBackend), RocksDB StateBackend (now called EmbeddedRocksDBStateBackend), and a new Disaggregated State Backend that is the major 2.x addition.
HashMapStateBackend: State lives on the JVM heap. Fast for small state jobs. The problem: JVM garbage collection. With large state (say, 10GB of user-session data per TaskManager), you will see GC pauses that cause checkpoint timeouts, back-pressure, and eventually instability. I have watched production jobs that ran fine at 1K events per second fall over at 10K because the state growth triggered full GCs.
EmbeddedRocksDBStateBackend: State lives in RocksDB, an embedded key-value store running on local disk. This eliminates heap pressure from state. RocksDB uses an off-heap memory pool that you configure explicitly. The tradeoff is that state access is slower (local disk I/O plus serialization/deserialization for every read and write) and RocksDB has its own operational complexity. For large state jobs (anything over a few GB of state per TaskManager), RocksDB is the right choice.
RocksDB gotchas from production: First, RocksDB’s write-amplification from compaction competes with checkpoint writes. Schedule heavy compaction windows carefully and monitor disk I/O saturation. Second, RocksDB memory is not tracked by the JVM; you must account for it explicitly in your TaskManager container memory limits or you will get OOM kills from the Linux kernel without a clean JVM crash log. Third, incremental checkpoints save only the delta since the last checkpoint, which dramatically reduces checkpoint size for large-state jobs. Enable incremental checkpointing on RocksDB jobs by default.
Disaggregated State Backend (Flink 2.x): This is the architectural breakthrough. Instead of keeping state on TaskManager local disk, the disaggregated backend uses remote object storage (S3, GCS, Azure Blob) as the primary state store via a custom async access layer. State is paged in and out as needed. This decouples state size from TaskManager disk capacity and makes rescaling faster because you do not need to redistribute state files; TaskManagers just start reading from different key partitions in remote storage. The tradeoff is higher state access latency than local RocksDB for cache misses. Flink 2.0’s async execution model was built specifically to tolerate this latency without blocking the processing pipeline.
Checkpoints: How Fault Tolerance Actually Works
This is the mechanism I spend the most time explaining to engineers who are new to Flink.
Flink’s checkpointing is based on Chandy-Lamport distributed snapshots. The JobManager periodically injects special records called checkpoint barriers into each source partition. These barriers flow through the entire job graph alongside regular data records. When an operator receives a barrier from all its input partitions, it snapshots its current state and forwards the barrier downstream.
Because barriers flow at the same rate as data and every operator waits for barriers from all inputs before snapshotting, the checkpoint captures a globally consistent state. If the job fails and restarts from a checkpoint, it is guaranteed to replay from a point where all operator states are consistent with each other.
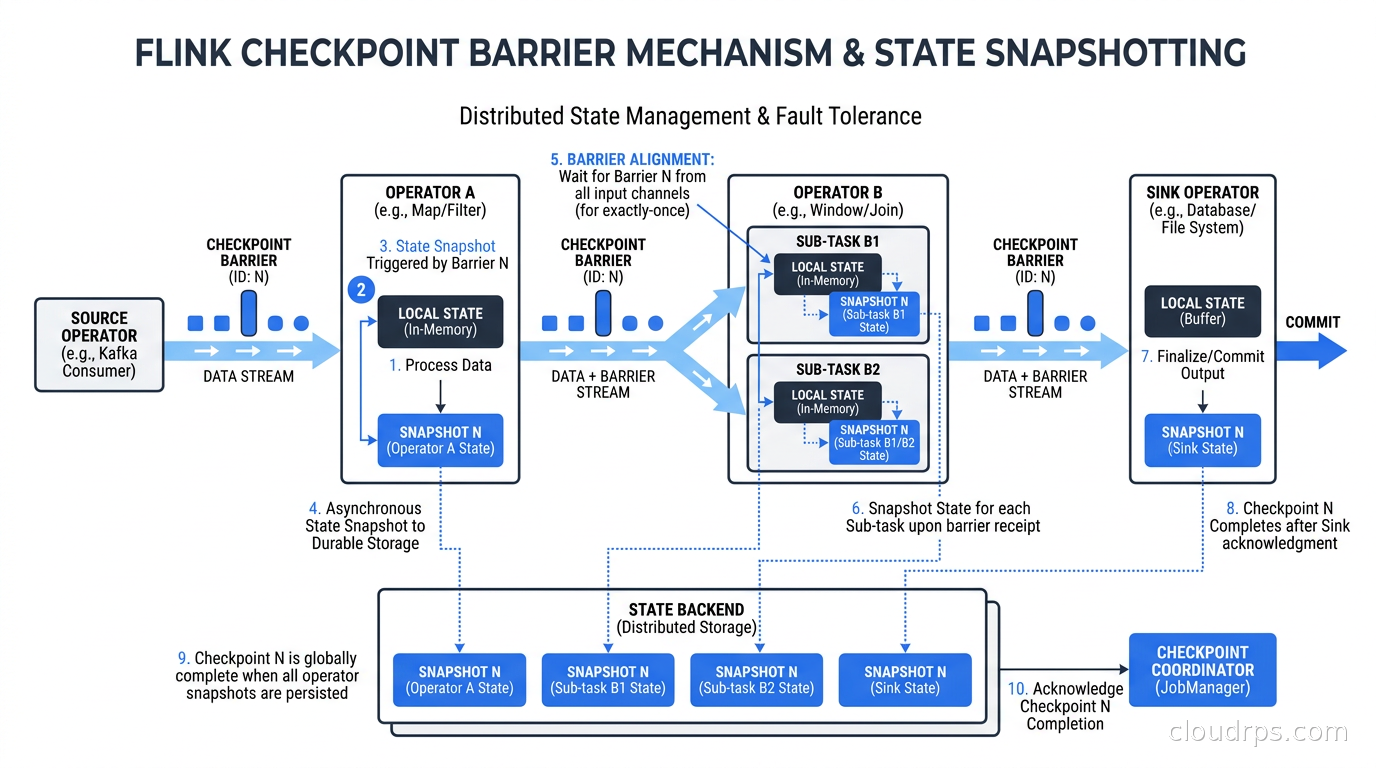
Exactly-once semantics: Flink’s exactly-once guarantee means each event is processed exactly once, even on failure and restart. There is an important distinction: exactly-once processing semantics (Flink’s guarantee) versus exactly-once output semantics (whether your sinks are idempotent or transactional). For Kafka sinks, Flink uses Kafka transactions to achieve end-to-end exactly-once. For database sinks or custom sinks, you need to implement the TwoPhaseCommitSinkFunction pattern, which commits writes only after the checkpoint that included those writes completes. This is non-trivial to implement correctly.
At-least-once semantics: Faster checkpointing with less overhead. On recovery, some events may be processed twice. For idempotent sinks (writes that can be safely repeated without side effects), this is often the right operational choice.
Checkpoint configuration in production: Set checkpoint interval based on your RTO tolerance, not arbitrarily. A 60-second interval means on failure you replay up to 60 seconds of data. Set the minimum time between checkpoints (not interval) to avoid checkpoint storms when a long checkpoint runs. Enable unaligned checkpoints (Flink 1.14+) when you have high back-pressure situations; unaligned checkpoints persist in-flight data as part of the snapshot, which means barriers do not pile up behind back-pressured buffers.
Savepoints vs checkpoints: Savepoints are manually triggered snapshots that you use for intentional operations: draining a job before rescaling, upgrading application code, migrating to a new cluster. Checkpoints are automatic and managed by Flink. The data format is the same but savepoints include additional metadata to support operator state versioning. Always test that your savepoint restores cleanly on code changes before doing a production upgrade.
Event Time and Watermarks
This is where Flink’s correctness advantages over micro-batch systems become concrete.
Event time is the timestamp embedded in the event when it was created (at the source). Processing time is when the event arrives at Flink. For most real-world stream processing, you want to aggregate by event time, not processing time. A user clicked a button at 14:30:00 UTC. The event arrived at Kafka at 14:30:01 and arrived at Flink at 14:30:03. If you are computing “clicks per minute,” you want 14:30:00 to count for the 14:30 window, not the 14:30 or later window when Flink happened to see it.
Late events are the problem. Networks delay events. Mobile clients batch events and send them when they regain connectivity. Kafka consumer lag means events arrive out of order relative to event time even if they arrived at Kafka in order. If you wait forever for late events, you never produce window results. Watermarks are Flink’s solution.
A watermark is a special record that says “I am confident that all events with timestamps earlier than T have arrived.” When a window’s watermark crosses its end time, Flink fires the window computation. Events that arrive after the window fires can be handled via an allowed lateness configuration (Flink holds the window open for a configured extra time) or a side output that routes late events for separate handling.
Watermark strategy is an application-specific decision. The built-in strategies are BoundedOutOfOrderness (watermark = max seen event time minus a fixed delay) and MonotonousTimestamps (watermark = max seen event time, assumes events arrive in order). For real-world production jobs, I almost always use BoundedOutOfOrderness with a delay tuned based on actual observed lateness in the data. Measure your P99 event lateness over a week of production traffic before picking a watermark delay; guessing causes either dropped late events (delay too small) or excessive memory from holding too many open windows (delay too large).
One subtlety that causes production incidents: watermark progress is per source partition. If one Kafka partition goes idle (no events), its watermark does not advance. This blocks watermark progress for the entire job because Flink takes the minimum watermark across all source partitions. This is the “idle partition” problem. Use the withIdleness parameter in your watermark strategy to let Flink skip idle partitions when computing the minimum.
Connecting Flink to Kafka and CDC Sources
Flink works best when paired with an event streaming backbone. The Kafka connector is the most common Flink source. The connector manages offset commits back to Kafka automatically on checkpoint, which is what gives you the exactly-once semantics between Kafka and Flink.
A powerful pattern is combining change data capture (CDC) from databases with Flink for real-time analytics and data synchronization. Debezium streams row-level changes from PostgreSQL or MySQL into Kafka topics. Flink consumes those topics, joins them with other event streams, and produces enriched outputs. The Flink CDC connector can also connect directly to database binlogs without an intermediate Kafka hop, which reduces latency but introduces an operational coupling I generally avoid for production workloads.
For writing outputs, Flink supports Apache Iceberg as a sink via the flink-iceberg-connector. This is an increasingly common pattern: real-time event enrichment in Flink, writing to Iceberg tables in object storage, queryable by downstream analytics tools. The Iceberg sink handles partition management, schema evolution, and the ACID semantics needed to make streaming writes queryable without reading partial batches.
If you are evaluating event streaming infrastructure, the Kafka alternatives comparison is worth reading. Flink works with Redpanda and AutoMQ through the same Kafka connector since they are Kafka protocol-compatible.
Running Flink on Kubernetes
In 2019, we were still running Flink on YARN clusters. In 2026, the default deployment target for new Flink jobs is Kubernetes. The Flink Kubernetes Operator (now at version 1.15.x with Flink 2.2 support) is mature and handles the full lifecycle.
The operator manages FlinkDeployment and FlinkSessionCluster resources. A FlinkDeployment is a single-application cluster running one Flink job per deployment, which is the recommended pattern for production: one job per cluster means failures and rollouts are isolated. A FlinkSessionCluster runs a shared Flink cluster where you submit multiple jobs, which is more resource-efficient but means jobs share fate on cluster failures.
The operator handles: deploying the JobManager and TaskManagers, configuring checkpoint storage, monitoring job health via the Flink REST API, triggering savepoints for upgrades, and tearing down the cluster when the job finishes. It integrates naturally with GitOps workflows because your FlinkDeployment manifest is declarative YAML.
Blue/green deployments (Flink Operator 1.14.0+): This was a long-requested feature. Before blue/green support, upgrading a stateful Flink job required stopping it, taking a savepoint, and restarting with new code, which created a processing gap. Native blue/green starts the new version of the job in parallel (reading from the same Kafka topics but from independent consumer groups), lets you validate it produces correct output, then drains the old version. This is the pattern for zero-downtime stateful job upgrades.
For persistent storage used by RocksDB checkpoints, you configure an S3-compatible object storage path in the Flink config. The CSI driver and Kubernetes persistent storage setup matters for the local RocksDB data directories if you are using the embedded backend; those need fast local SSDs, not network-attached storage. Mount the RocksDB working directory on ephemeral local NVMe for best performance and checkpoint state separately to object storage. Understanding Kubernetes operators in general helps you understand what the Flink operator is doing under the hood.
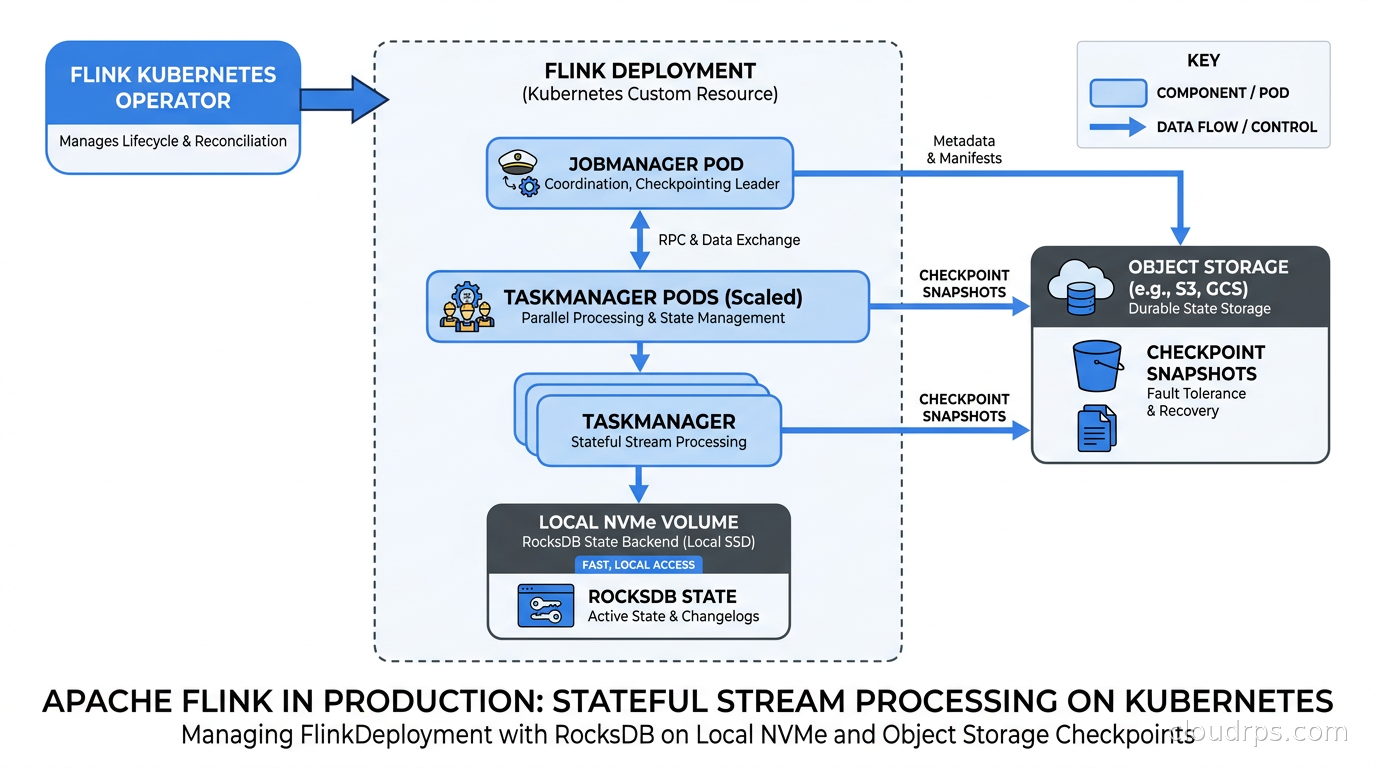
A few operational lessons from running Flink on Kubernetes: First, resource requests and limits need to account for RocksDB off-heap memory. Set taskmanager.memory.managed.fraction to give RocksDB a fixed managed memory pool and size the container limits above that. Second, use PodDisruptionBudgets to prevent TaskManager pods from being evicted during rolling node upgrades in the middle of a checkpoint; a TaskManager eviction during checkpoint barrier collection causes a checkpoint failure and job restart. Third, liveness probes for the JobManager should check the Flink REST API health endpoint, not just TCP port availability, because the JVM can be alive while the application is deadlocked.
Flink SQL and Materialized Tables
Flink has had SQL support for years, but Flink 2.x Materialized Tables are a significant addition for analytics engineers. A Materialized Table is a Flink-managed streaming or batch query result that is automatically refreshed as source data changes. You define the table once, and Flink maintains it continuously or on a schedule.
The practical use case: instead of writing a DataStream API job to maintain a rolling 7-day aggregation, you write a SQL query and Flink manages the state, checkpointing, and refresh logic. Materialized Tables bridge the gap between Flink’s operational complexity and the SQL interface that analytics teams are comfortable with. The schema and query updates in Flink 2.0 mean you can alter the definition of a running Materialized Table without reprocessing all historical data for compatible changes.
Flink SQL is also where the AI integration story for Flink 2.2 lives. The MODEL DDL statement lets you define a reference to an ML model (local, or via API call to an inference endpoint), and then call it inline in SQL: SELECT user_id, ML_PREDICT(fraud_model, transaction_amount, merchant_category) FROM transactions. This is not a replacement for dedicated inference infrastructure, but for simple scoring of streaming events with existing models, it reduces operational complexity significantly.
Common Production Failures and How to Debug Them
After twenty years of building distributed data infrastructure, I have a mental catalog of how Flink jobs die in production.
Back-pressure cascades: Flink has a back-pressure mechanism where slow downstream operators signal upstream operators to slow down. This is correct behavior. The problem is when back-pressure causes checkpoint barrier delays, which causes checkpoint timeouts, which causes more back-pressure, which causes a job restart spiral. Use the Flink web UI’s back-pressure visualization to identify which operator is the bottleneck. Nine times out of ten it is a network call inside a map function, a slow database write, or a GC pause.
State explosion: A job that runs fine for days starts slowing down and eventually OOMs. The culprit is almost always unbounded state. A window with an event-time trigger that is never firing because watermarks are stalled, accumulating state indefinitely. Or a MapState that is keyed on a dimension with unbounded cardinality (raw IP addresses, for example) that you forgot to expire. Enable state TTL on all state objects where stale entries are acceptable. Flink’s state TTL support is per-entry, not per-key, which gives you fine-grained control.
Savepoint incompatibility: You change a class that is used in state, rebuild the job, and the savepoint restore fails with a serialization error. This happens when you change the structure of a state-serialized class (add a field, rename a field) without following Flink’s schema evolution rules. The fix is either a full state migration (process-intensive) or schema evolution via RegisteredPojoSerializer if you set it up before needing it. Design your state classes for evolution from day one: use POJOs with optional fields rather than compact data structures.
Kafka consumer lag growth: Flink is not keeping up with Kafka production rate. This is a capacity problem, not a bug. The solution is to increase job parallelism or Flink cluster capacity. Before doing that, check whether the bottleneck is deserialization (cheap, parallelism helps), operator logic (might be cheap, check first), state access (RocksDB-specific; more slots per TaskManager helps), or output sink (often the real bottleneck that is missed in profiling).
When to Choose Flink vs the Alternatives
Flink is the right choice when you need stateful, exactly-once stream processing with complex windowing and low latency. It is not always the right choice.
For simple stateless transformations and routing, Kafka Streams is often sufficient and operationally simpler because it runs inside your application process with no separate cluster. For large-scale batch processing where latency above a few minutes is acceptable, Spark’s unified batch/streaming model may serve you better if your team already knows it. For simple real-time metrics aggregations over short windows, ClickHouse can ingest from Kafka directly and handle the aggregations in the database engine, which eliminates the Flink layer entirely.
Flink shines for: fraud detection and anomaly detection requiring complex pattern matching across events, streaming ETL with stateful enrichment (join events with a local cache of database state), real-time recommendation systems updating user feature vectors, and any workload where per-event latency matters and state size is in the gigabytes per TaskManager.
The answer I have given in architecture reviews for twenty years: pick the simplest tool that satisfies your correctness and latency requirements. Flink is not simple. If your stream processing needs genuine statefulness, genuine exactly-once guarantees, and genuine event-time correctness, Flink’s complexity is justified. If you are just filtering and routing events, you are paying for a fighter jet when a bicycle will do.
Getting Started in Production
Start with the Flink Kubernetes Operator, not standalone or YARN. It is the officially supported deployment path and the operational investment pays for itself quickly.
Configure checkpoints to a remote object storage backend from day one, not local disk. Even in development, testing your checkpoint restore path early avoids painful surprises. Set checkpoint interval to 60 seconds initially and tune from there based on your state size, state backend, and RTO requirements.
Instrument your Flink jobs with the Metrics API from the start. Expose custom metrics: operator throughput, state size per key group, end-to-end event latency. Flink reports built-in metrics to Prometheus via the metrics reporter; use the Prometheus and Grafana observability stack to build dashboards and set up checkpoint duration alerts, which are the most reliable early warning of production problems.
Apache Flink 2.x is genuinely powerful infrastructure. The disaggregated state backend, the Kubernetes operator maturity, and the SQL improvements make 2026 a genuinely good time to adopt it for production workloads that need what Flink does. Understand the checkpointing model deeply, design your state for evolution, and size your RocksDB memory correctly. Do those three things and Flink will be one of the most reliable pieces of infrastructure in your stack.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.