I have had the same conversation dozens of times. A team comes to me because their AWS networking is a mess. They cannot deploy a new service without a two-week ticketing process to get network access provisioned. Their VPC peering connections number in the hundreds. Half of their security groups are wide open to entire VPC CIDRs because nobody wanted to bother with fine-grained rules. And whenever they try to onboard a new account, they discover that the new VPC’s CIDR block overlaps with three existing ones.
The root cause is almost always the same: nobody made a deliberate decision about VPC connectivity architecture early on. They started with VPC peering because it was the obvious first option, kept adding more as the organization grew, and eventually ended up with an O(n^2) peering mesh that nobody fully understands.
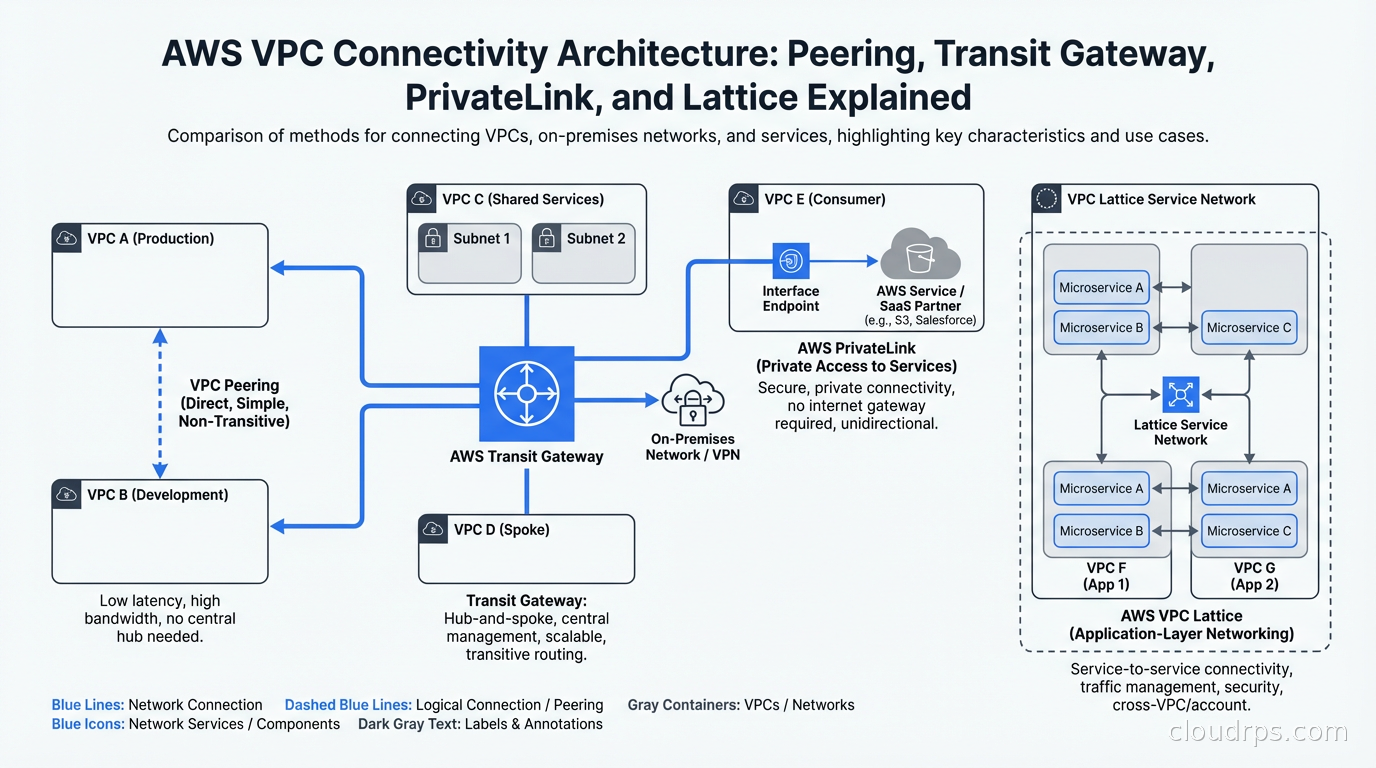
AWS offers four distinct connectivity mechanisms for VPC-to-VPC and service-to-service access: VPC Peering, Transit Gateway, PrivateLink, and the newer VPC Lattice. Each one solves a different problem. Choosing the right tool for the job is not complicated if you understand what problem each one is actually designed to solve.
The Foundation: VPC Peering
VPC Peering is the oldest and simplest mechanism. You establish a direct, private network connection between two VPCs. Traffic flows over AWS’s backbone network without traversing the internet, and you configure route tables in each VPC to direct traffic to the peer.
The appeal is obvious. VPC Peering is free (no hourly charges, you pay only for standard data transfer rates). Setup is straightforward: you create the peering connection, accept it on the other side, and add routes. Traffic is encrypted in transit. There is no single point of failure and no bandwidth bottleneck.
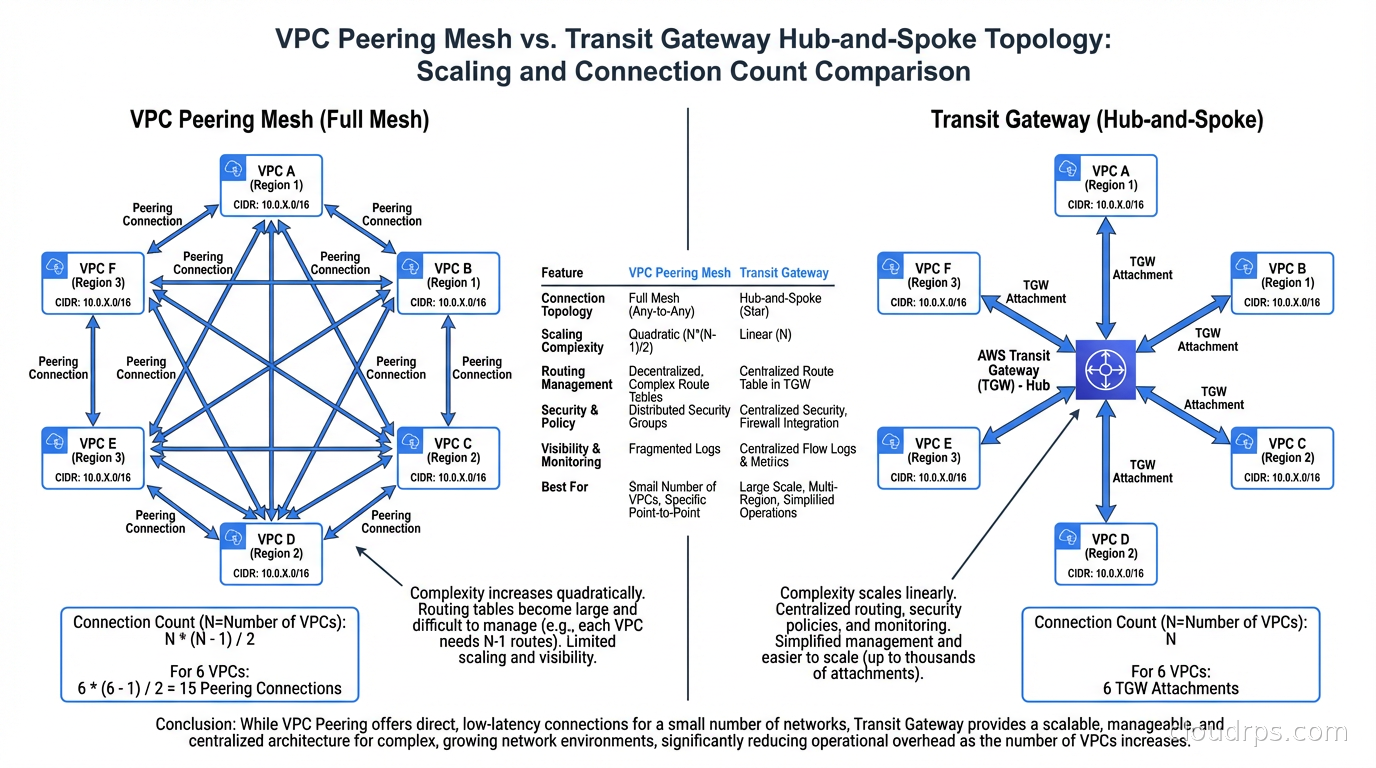
The problem is scale. VPC Peering is not transitive. If VPC A peers with VPC B, and VPC B peers with VPC C, traffic cannot flow from VPC A to VPC C through VPC B. Each VPC pair that needs connectivity requires its own explicit peering connection. The math here is brutal: n VPCs require n*(n-1)/2 peering connections for a full mesh. Twenty VPCs need 190 connections. Fifty VPCs need 1,225. At that scale, you are maintaining thousands of route table entries across hundreds of VPCs, and a single CIDR overlap anywhere in the mesh makes an entire segment of your connectivity impossible.
I use VPC Peering in two specific scenarios: connecting a small, fixed number of VPCs that will not grow (two or three at most), and connecting VPCs that need high-bandwidth, low-overhead connectivity where I want to avoid the per-byte processing fees that Transit Gateway adds. For a data-intensive workload transferring terabytes between two specific VPCs, VPC Peering is often the right answer. For anything that resembles a growing organizational network, it is a trap.
Understanding your CIDR block allocation strategy before creating any VPCs is critical here. Overlapping address spaces cannot be resolved after VPC Peering is established. I always recommend allocating from a dedicated corporate supernet before creating your first VPC, with clearly delineated ranges for each environment and region.
Transit Gateway: Hub-and-Spoke at Scale
Transit Gateway (TGW) is AWS’s managed network hub. Instead of connecting VPCs directly to each other, you connect each VPC to the Transit Gateway, and the TGW handles routing between them. The connection count scales linearly instead of quadratically: 100 VPCs need 100 attachments to the TGW, not 4,950 peering connections.
The architecture model is hub-and-spoke. The TGW is the hub. Each VPC, VPN connection, and Direct Connect gateway is a spoke. Traffic between any two spokes flows through the hub. For the on-premises side of this architecture, where you are connecting a data center to AWS, the Direct Connect gateway is what terminates the private circuit; see the dedicated cloud interconnects guide for how AWS Direct Connect, Azure ExpressRoute, and Google Cloud Interconnect work in practice.
Beyond topology simplification, Transit Gateway provides routing table separation that VPC Peering cannot. A TGW can have multiple route tables, and each attachment can be associated with a specific route table. This lets you enforce traffic segmentation: production VPCs can route to each other and to shared services, but development VPCs cannot reach production, even though all of them are attached to the same TGW. You implement this with association and propagation rules on the TGW route tables.
Centralized network inspection is where Transit Gateway architecture really pays off. By routing all inter-VPC traffic through a security VPC containing a firewall appliance (AWS Network Firewall, Palo Alto VM-Series, or Fortinet FortiGate are common choices), you get a single inspection point for all east-west traffic in your network. This is significantly cheaper and simpler than deploying firewall appliances in every VPC, and it gives your security team a single place to write and enforce policies.
The cost model is different from VPC Peering. Transit Gateway charges $0.05 per attachment per hour (about $36/month per VPC attachment) plus $0.02 per GB of data processed. On a large network, the attachment costs alone can be meaningful. An organization with 200 VPC attachments pays $7,200/month in attachment fees before any data transfer. For comparison, VPC Peering has no hourly charges. The architectural benefits of TGW are real, but the cost needs to be part of your decision. This is the same math I cover in detail in the cloud egress costs article when talking about VPC endpoints versus NAT Gateway.
Transit Gateway also supports inter-region peering. You can peer TGWs in different regions together, enabling traffic to flow between regions without going over the public internet. Cross-region TGW traffic has separate pricing but follows the same hub-and-spoke model. This is essential for multi-region architectures that need private connectivity between regions.
One nuance that trips people up: Transit Gateway does not automatically route all traffic between attached VPCs. You have to configure propagation rules to control which attachments are reachable from which route tables. A common mistake is attaching a new VPC to the TGW and assuming it can immediately reach other VPCs. Without the right route table entries on both sides, the connectivity does not exist.
PrivateLink: Service Access Without Routing
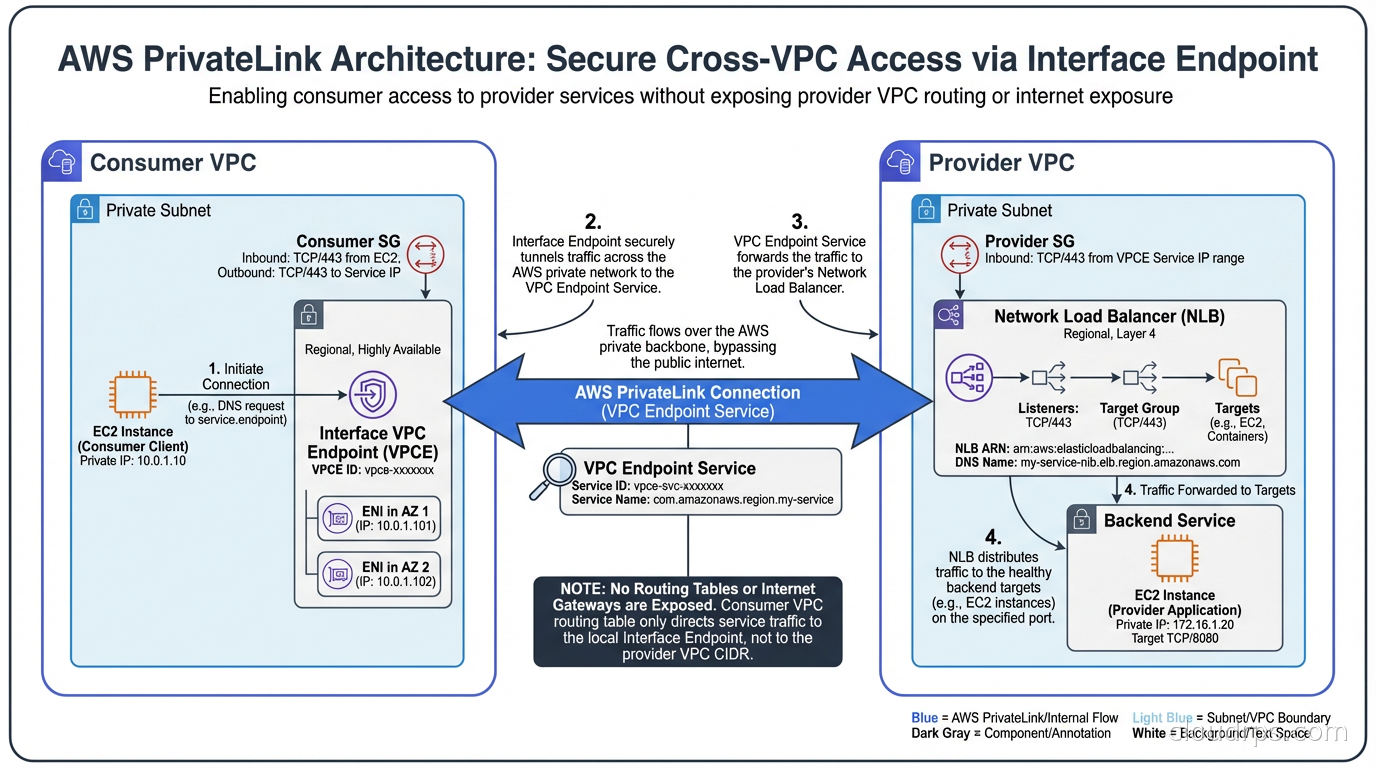
PrivateLink is a fundamentally different abstraction. VPC Peering and Transit Gateway give VPCs access to each other’s entire address space (subject to routing rules and security groups). PrivateLink exposes a specific service endpoint in one VPC to consumers in another VPC, without giving the consumer any routing access to the provider’s broader network.
The architecture has two sides. The provider creates a VPC endpoint service backed by a Network Load Balancer or Gateway Load Balancer. The consumer creates a VPC interface endpoint (an Elastic Network Interface in the consumer VPC with a private IP from the consumer’s subnet). Traffic from the consumer to the service flows through this endpoint over AWS’s backbone. The consumer’s traffic never sees the provider’s VPC CIDR, and the provider has no ability to route traffic back into the consumer’s network.
This is a security architecture difference, not just a connectivity one. With VPC Peering or Transit Gateway, if the provider VPC is compromised, the attacker has potential routing access to all the VPCs connected to that network. With PrivateLink, a compromised provider can only affect the specific service it exposes. The traffic flow is unidirectional from a routing perspective.
PrivateLink is the right choice for three scenarios:
Consuming AWS services from private subnets. S3, DynamoDB, EC2, ECS, SQS, SNS, and dozens of other AWS services support VPC endpoints powered by PrivateLink. Configuring these endpoints keeps traffic to AWS services on AWS’s private network, eliminates NAT Gateway processing fees for that traffic, and reduces your internet exposure surface.
Exposing an internal platform service to other VPCs or accounts. If your platform team runs a shared authentication service, a secrets distribution service, or a common API gateway, PrivateLink lets you expose it to consuming teams without giving them routing access to your entire platform VPC. This is the right model for internal platform services in organizations with strong security boundaries.
Consuming third-party SaaS services with a private endpoint. Many SaaS vendors now offer PrivateLink-powered endpoints so their customers can connect without exposing data to the internet. This is increasingly common in regulated industries where data must not traverse public networks.
The operational model is worth understanding. PrivateLink endpoints require DNS configuration: the consumer uses the endpoint DNS name, which resolves to the private IP of the ENI in the consumer’s VPC. If you have split-horizon DNS or centralized DNS resolvers, you need to ensure these endpoint DNS names resolve correctly. This is a common source of confusion when PrivateLink connections seem established but connectivity does not work.
PrivateLink has an important limitation for cross-region use cases: by default, VPC Interface Endpoints are regional. A consumer in us-east-1 connecting to a service in us-west-2 via PrivateLink needs either a cross-region Private Link setup (using inter-region peering or Transit Gateway as a transport layer) or a regional deployment of the service. Plan for this before designing multi-region service access patterns.
VPC Lattice: Service Networking for Application Teams
VPC Lattice is the newest addition to the AWS connectivity toolkit, launched in 2023 and maturing quickly. It occupies a different layer than the other three options: while Peering, TGW, and PrivateLink are network-layer (L4) connectivity mechanisms, VPC Lattice operates at the application layer (L7) and provides service discovery, routing, and auth in addition to connectivity.
The core concept in VPC Lattice is the service network, a logical grouping of services that can communicate with each other. You register services into a service network, associate VPCs with that service network, and any resource in an associated VPC can reach any service in the network using a stable DNS name. The routing, load balancing, and TLS termination are handled by VPC Lattice, not by the application.
The features that differentiate it from PrivateLink are significant. VPC Lattice supports HTTP and gRPC path-based routing: you can route requests to different targets based on the URL path or headers, not just by service. It has built-in auth using IAM resource policies, so services can require callers to have specific IAM permissions before accepting requests, and this auth is enforced at the network layer without requiring the application to implement it. It supports canary deployments and weighted routing natively.
Critically, VPC Lattice solves the overlapping CIDR problem. Because it is an L7 service proxy rather than an L3 routing mechanism, it does not care whether the consumer and provider VPCs have overlapping address spaces. Two VPCs with identical CIDRs that cannot be peered can both join a VPC Lattice service network and communicate through it fine.
Where VPC Lattice does not fit: it is HTTP/gRPC only. Non-HTTP protocols (database connections, custom TCP protocols, Redis or Kafka access) require PrivateLink or network-layer connectivity. It also adds latency compared to direct network-layer connectivity, because it is a proxy rather than a routing mechanism.
My current recommendation is to use VPC Lattice for new microservice architectures where the development teams want service-to-service communication without involving the network team for each new connection. The self-service model it enables is genuinely useful for platform engineering. For database access, legacy TCP services, and anything performance-sensitive at the network level, PrivateLink or Transit Gateway remain the right choices.
The Decision Framework
After working through enough AWS architectures to have strong opinions, here is how I think about which connectivity option to use:
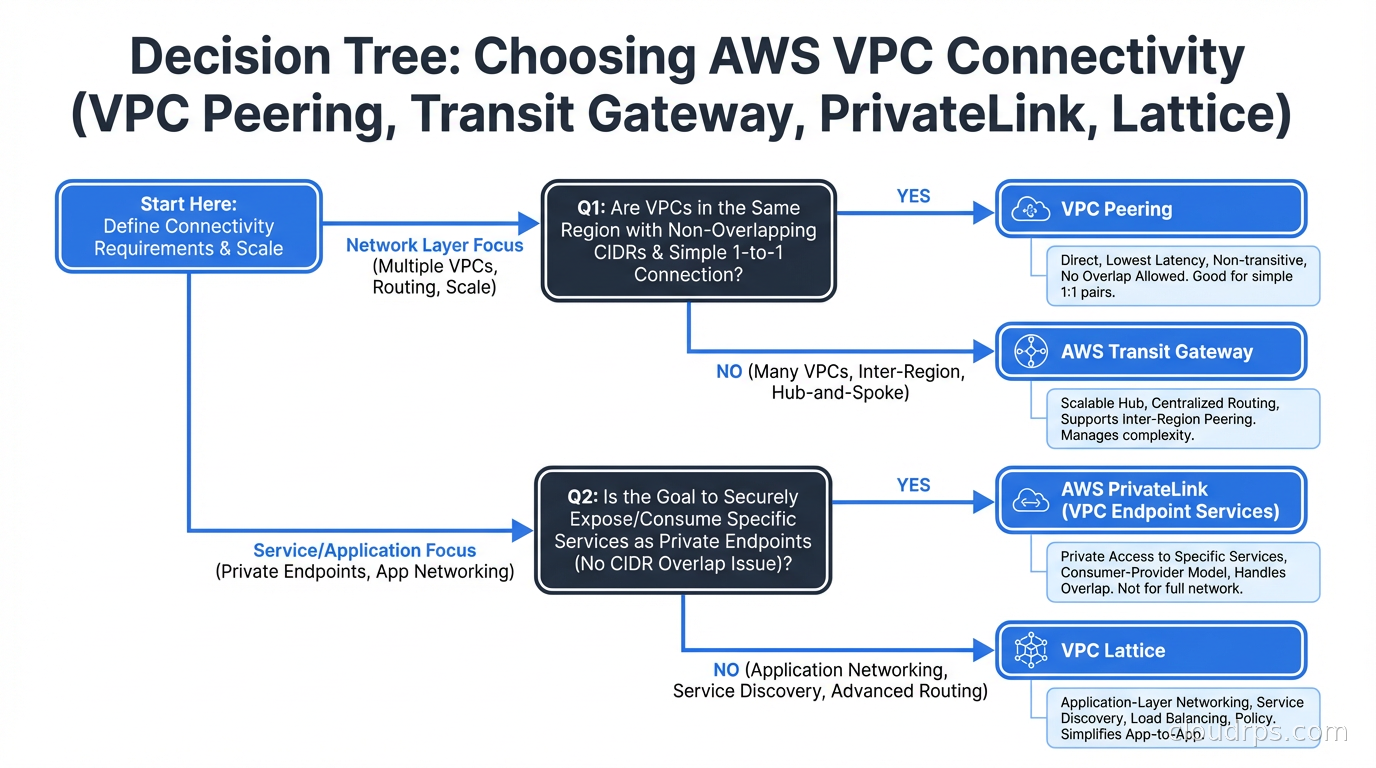
Start with the question: are you connecting two VPCs, or a service?
If you are giving two VPCs mutual network access (both can initiate connections to any resource in the other), you want Peering or Transit Gateway. If you are exposing a specific service endpoint from one VPC to consumers in other VPCs, you want PrivateLink or VPC Lattice.
For Peering vs Transit Gateway: how many VPCs and how often does the number change?
Two or three VPCs that are stable in number: use Peering. It is simpler, free per hour, and the operational overhead is manageable at small scale. Four or more VPCs, or any organization that expects to add accounts or VPCs over time: use Transit Gateway. The upfront operational investment in configuring TGW route tables pays off quickly at scale. This maps directly to the networking architecture in your cloud landing zone, where the hub-and-spoke pattern with Transit Gateway in a dedicated network account is the standard recommendation for organizations beyond startup size.
For PrivateLink vs VPC Lattice: do you need HTTP-layer features or is TCP enough?
If you need service discovery, L7 routing, or IAM auth at the network layer: VPC Lattice. If you need to expose a non-HTTP service, or if raw performance and simplicity matter more than application-layer features: PrivateLink.
For accessing AWS services (S3, DynamoDB, SQS, etc.): always use VPC endpoints.
Gateway endpoints for S3 and DynamoDB are free and eliminate internet routing for those services. Interface endpoints for other services cost $0.01 per AZ per hour but eliminate NAT Gateway processing fees and internet exposure. The break-even is surprisingly low. This is a separate consideration from VPC-to-VPC connectivity but often gets lumped in with the same decision.
IP Address Planning: The Problem That Bites You Later
No discussion of VPC connectivity is complete without addressing CIDR planning, because poor IP address planning is what forces organizations into expensive re-architecture projects. VPC Peering and Transit Gateway both require non-overlapping CIDR blocks across all VPCs that will ever need to connect. CIDR overlaps cannot be resolved without rebuilding the VPCs from scratch.
The mistake I see constantly is teams creating VPCs with /16 blocks from the default 10.0.0.0/8 space without any coordination. Eventually, two VPCs end up with the same CIDR, and now they can never be connected. Or a team uses 192.168.0.0/16 for an on-premises network and then discovers that a VPC they need to connect uses the same range.
The right approach is to define a corporate supernet before creating any VPCs, then carve allocations from it. For example: allocate 10.0.0.0/8 for all AWS resources, then sub-allocate 10.1.0.0/12 to us-east-1, 10.16.0.0/12 to eu-west-1, and 10.32.0.0/12 to ap-southeast-1. Within each region, individual VPCs get /16 or /20 allocations depending on expected size. Account vending automation should handle this allocation programmatically so no two VPCs ever get the same CIDR by mistake.
The infrastructure as code tooling for managing this at scale matters. Terraform modules that enforce CIDR allocation rules, check for overlaps at plan time, and register new allocations in a shared state backend prevent the class of IP overlap problems that I have seen sink organizations’ networking projects entirely. I strongly recommend building VPC CIDR management into your account vending process from day one, not retrofitting it after twenty VPCs exist.
Monitoring VPC Connectivity
VPC Flow Logs are the primary observability tool for VPC connectivity troubleshooting. They record metadata about accepted and rejected connections: source and destination IP, port, protocol, bytes transferred, and whether the connection was accepted or rejected. Flow logs can be published to CloudWatch Logs or S3, and in aggregated form they let you understand actual traffic patterns, identify blocked connections, and audit which services are actually communicating.
Transit Gateway Flow Logs work similarly for traffic traversing the TGW. If you have centralized inspection architecture, you want flow logs both on the TGW attachments and on the inspection VPC interfaces to correlate what was inspected versus what was dropped.
For PrivateLink, the NLB access logs behind the endpoint service are your visibility into service-level connections. CloudWatch metrics for the NLB give you connection counts, latency, and error rates. The consumer side does not produce separate logs beyond what the VPC Flow Logs capture.
Reachability Analyzer is AWS’s path analysis tool. Given a source and destination, it traces the logical network path and identifies where connectivity is blocked if it fails. I use this routinely when debugging Transit Gateway routing issues or security group misconfigurations. It runs in minutes and saves hours of manual route table tracing. Network Access Analyzer builds on the same engine to run compliance checks: verify that production resources are not accessible from development VPCs, or that all public-facing resources go through an inspection path.
Managing All of This at Scale
The operational burden of maintaining complex VPC connectivity grows quickly without automation. Every new VPC needs route table updates. New service endpoints need DNS entries. TGW route tables need propagation rules updated. Security groups need source references updated when new CIDRs appear.
The pattern that scales well is treating all VPC connectivity as code in your infrastructure repository. Terraform AWS provider modules for Transit Gateway are mature. I keep a central networking module that encodes the organization’s routing policies: production-to-production is allowed, dev-to-production is blocked, all traffic from workload VPCs to inspection VPC is mandatory. When the networking module is applied, it configures TGW route tables, VPC endpoint associations, and security group rules across all accounts.
The security groups and ACLs that protect resources inside VPCs are a separate layer from VPC connectivity, but they interact. Even if two VPCs are connected via TGW, a security group on the target instance that does not allow the source CIDR will block the connection. A common debugging mistake is assuming that because the VPC connectivity is configured, the connection should work, when the actual block is a security group on the EC2 instance or RDS cluster that predates the new connectivity.
Common Mistakes and How to Avoid Them
Reaching for VPC Peering as a default then regretting it at scale. The simplicity of VPC Peering is appealing, but once you have ten or more VPCs, you will spend more engineering time managing the peering mesh than you would have spent setting up Transit Gateway correctly from the start.
Using Transit Gateway when you only need PrivateLink. If you just need to expose a specific API or service endpoint to another account, a PrivateLink endpoint service is simpler, cheaper, and more secure than connecting the two accounts’ VPCs via Transit Gateway and then using security groups to restrict access. Use the right tool for the access pattern.
Skipping CIDR planning. I cannot overstate how often this causes expensive problems. Spend two hours on CIDR allocation before creating your first VPC. Build it into your account provisioning automation. It is the most impactful preventive measure in AWS networking.
Forgetting that DNS matters. PrivateLink endpoints and VPC Lattice services both use DNS for discovery. In organizations with centralized DNS resolvers (Route 53 Resolver forwarding rules, Active Directory DNS, or custom resolver infrastructure), private endpoint DNS names often fail to resolve in consuming VPCs. Always test DNS resolution from the consumer as part of PrivateLink setup validation.
Not planning for asymmetric routing. In Transit Gateway architectures with centralized inspection, traffic from VPC A to VPC B might flow through the inspection VPC in one direction and take a different path in the other direction. This breaks stateful firewalls. Ensure your routing is symmetric: traffic for a given flow takes the same inspection path in both directions.
The AWS VPC connectivity decisions you make early have a disproportionate impact on your long-term operational burden. Getting the architecture right means understanding what each tool is actually designed for, planning your IP address space deliberately, and treating network configuration as code from day one. The teams that do this have networking that just works. The teams that do not spend years untangling the mess.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.