The question I get asked most in 2026 is some variation of: “We need to build AI into our product, we are already on AWS (or GCP, or Azure), which managed AI platform should we use?” It sounds simple. It is not.
I have spent the last two years helping enterprise teams evaluate and migrate onto managed AI platforms, and the honest answer is that Bedrock, Vertex AI, and Azure AI Foundry are all capable of shipping serious production AI systems. The choice depends on your existing cloud footprint, your model preferences, your compliance posture, and how much abstraction versus control you want. Get it wrong and you spend eighteen months re-platforming mid-project. I have watched that happen to three different companies in the past year alone.
This article is not a feature matrix. I am going to walk you through the architecture of each platform, explain where each one genuinely wins, and give you the decision framework I use with clients when they have to commit to one of these for a multi-year product build.
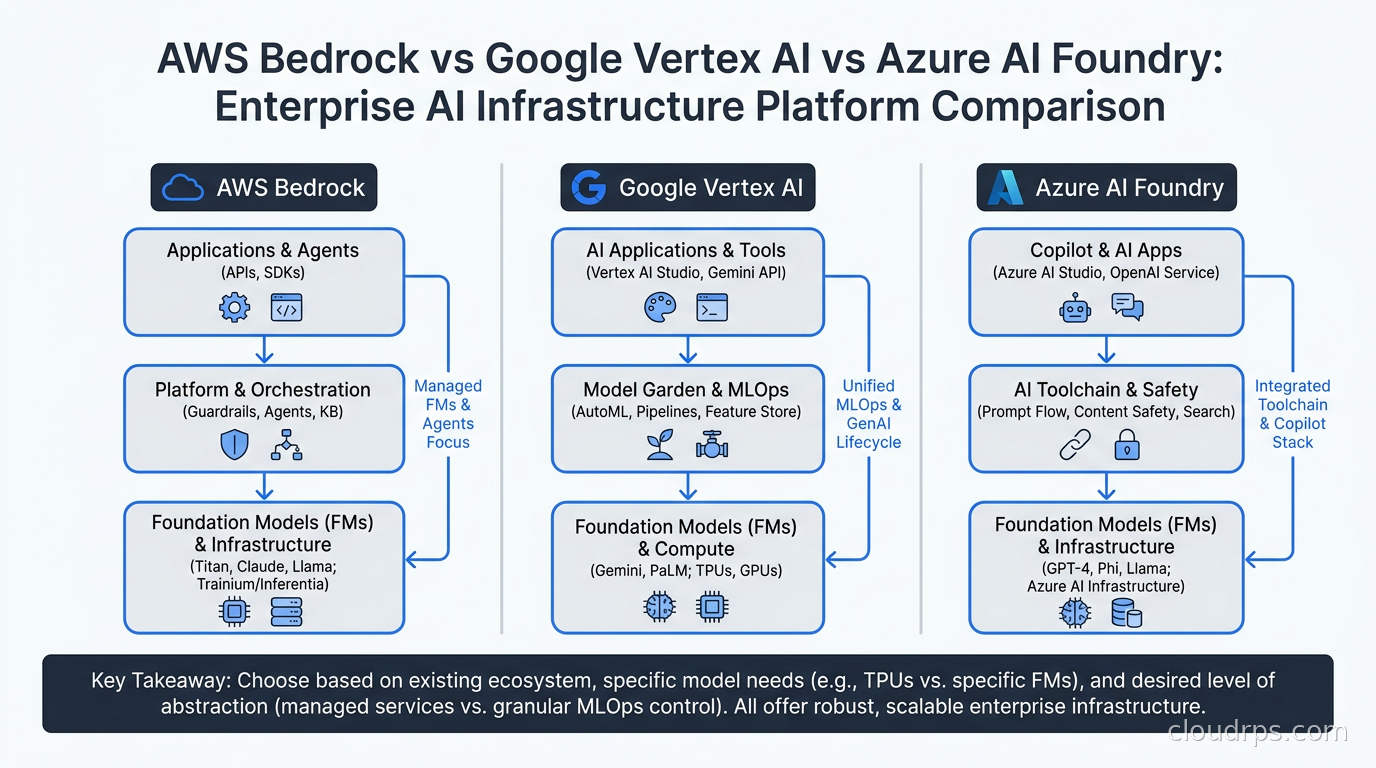
What These Platforms Actually Are Now
It is worth stepping back because the marketing has gotten ahead of the reality in both directions. All three platforms have evolved from “model API wrappers” into full-stack AI development environments. By 2026, each one ships:
- A model catalog spanning frontier models and open-weight alternatives
- A managed RAG pipeline with vector storage and knowledge base tooling
- An agent runtime that handles orchestration, tool use, and memory
- Fine-tuning infrastructure for adapting base models to domain-specific tasks
- Observability and evaluation tooling for production monitoring
- Enterprise compliance controls: VPC isolation, encryption, data residency, audit logging
The gap between them is not “which one has features.” It is architectural philosophy, model selection depth, ecosystem integration, and pricing mechanics. Each of those factors matters enormously at production scale.
AWS Bedrock: The Breadth Play
Bedrock launched as a multi-model marketplace and has stayed true to that DNA. In 2026 the catalog covers models from Anthropic (Claude 4 Sonnet and Opus), Meta (Llama 4), Mistral, Cohere, AI21 Labs, Stability AI, Amazon’s own Nova family, and a handful of specialized providers. That breadth is genuinely useful when you want to route different workloads to different models based on cost, latency, or capability.
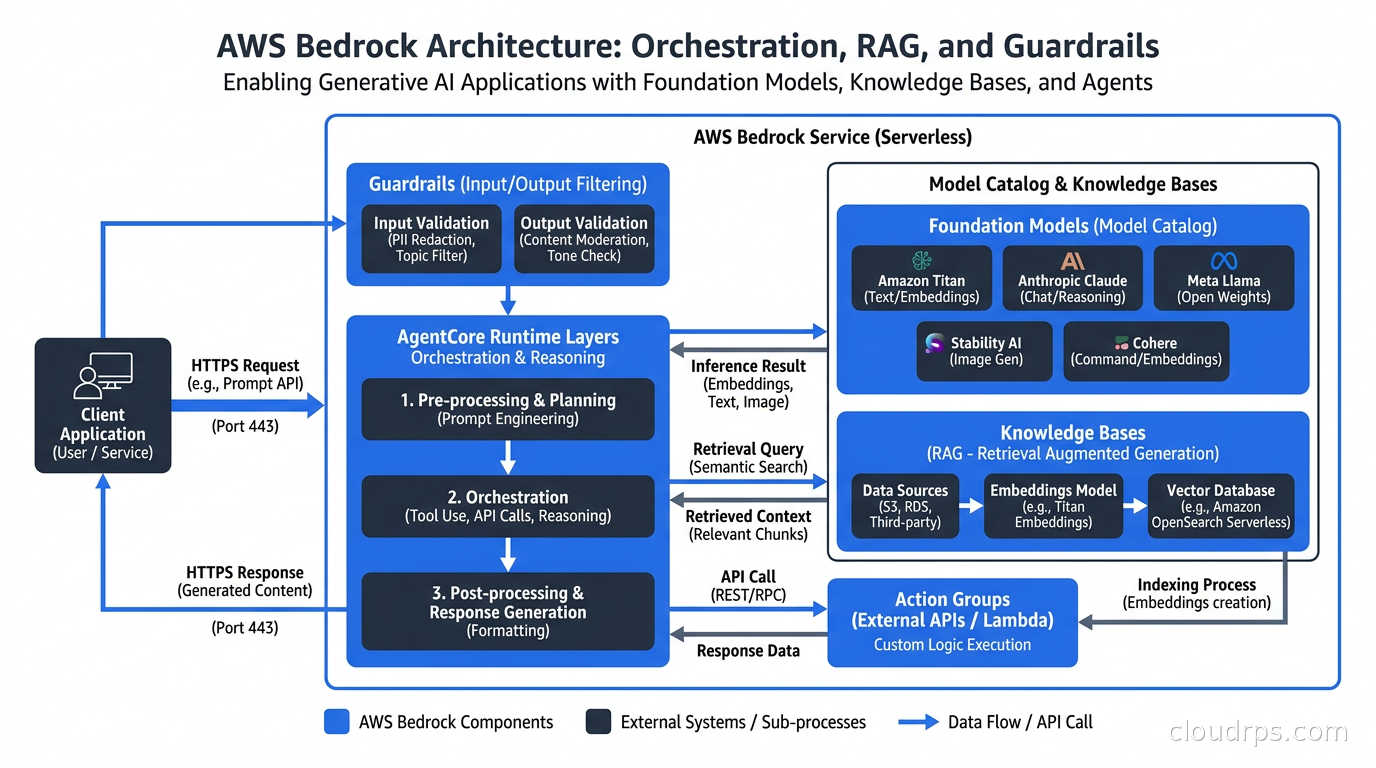
The architecture I deploy most often on Bedrock looks like this: API calls go through the Converse API (Bedrock’s unified interface that abstracts away provider-specific request formats), which is load balanced across the model endpoints. For RAG workloads, Knowledge Bases handles document ingestion, chunking, embedding, and storage in a managed vector store backed by OpenSearch Serverless. For agents, BedrockAgentCore provides the orchestration loop: the model reasons about what tool to call, AgentCore invokes the corresponding Lambda function, passes results back to the model, and repeats until the agent completes its task.
What Bedrock does well:
Multi-model flexibility. If you need to run Claude for complex reasoning tasks and Nova Micro for high-volume low-latency classification tasks and Llama for on-premises edge deployments, Bedrock gives you a single SDK and billing surface. I have built systems where the same request router sends prompts to three different providers based on content type, and Bedrock makes that remarkably clean.
AWS ecosystem integration. Bedrock plays naturally with IAM, VPC, CloudWatch, EventBridge, Lambda, S3, and DynamoDB. If your team already knows how to secure an AWS workload, securing a Bedrock workload requires almost no new learning. The networking story (VPC endpoints, PrivateLink for all Bedrock traffic, no data leaving your VPC) is mature and well-documented. This matters a lot for regulated industries.
Guardrails. Bedrock’s content filtering layer is configurable at a granularity I have not seen elsewhere. You can define topic-level denylists, PII detection and redaction, grounding checks that validate model responses against your knowledge base, and word-level filters, all applied consistently across every model in the catalog. When a financial services client asks me “how do we make sure the model never discusses competitor products,” Guardrails answers that without custom middleware.
AgentCore for agent workloads. The multi-agent collaboration added in the 2025-2026 timeframe is genuinely useful. Supervisor agents can delegate subtasks to specialized sub-agents, with each sub-agent having its own tool access and memory context. Session memory persists across turns in DynamoDB. Trace-level observability flows into CloudWatch. For the teams I know building agentic workflows, Bedrock’s agent runtime competes well with what you would build manually on top of LangGraph or CrewAI.
Where Bedrock struggles:
The pricing model is per-token with no committed-use discount mechanism as strong as what GCP offers. For very high-throughput workloads, the economics get painful. Provisioned Throughput helps (you reserve model capacity at a fixed hourly rate), but it requires upfront commitment and the pricing math only works at meaningful volume. If you are doing fewer than a few million tokens per day, on-demand is fine. Above that, you need to model this carefully.
The ML training and serving stack is also deliberately thin. Bedrock is about inference and application building, not about training custom foundation models. If your team needs to run distributed training runs, manage custom serving infrastructure, or do serious MLOps on custom models, Bedrock is not where you do that work. SageMaker is still the right tool for training on AWS, and the Bedrock/SageMaker integration story requires stitching together two services that were built by different teams and still show the seams.
Google Vertex AI: The ML-Native Platform
Vertex AI comes from a different lineage. Google built it out of the old AI Platform and Cloud ML Engine services, and that heritage shows in how tightly integrated the full ML lifecycle is: data preparation in BigQuery or Dataflow, training on TPU or GPU clusters, model registry, online and batch serving endpoints, evaluation pipelines, and now a model garden with first-party Gemini models alongside third-party options through the Model Garden marketplace.
For teams doing serious custom ML, Vertex AI is the most complete managed environment I have used. The managed training infrastructure is excellent. Custom training jobs on A100 and H100 clusters just work. The experiment tracking, model versioning, and pipeline orchestration (Vertex AI Pipelines, backed by Kubeflow Pipelines) are production-grade. Feature Store for serving pre-computed features is genuinely useful for online prediction latency. If I am helping a team that trains their own models and wants to run the full MLOps lifecycle on managed infrastructure, I send them to Vertex AI without hesitation.
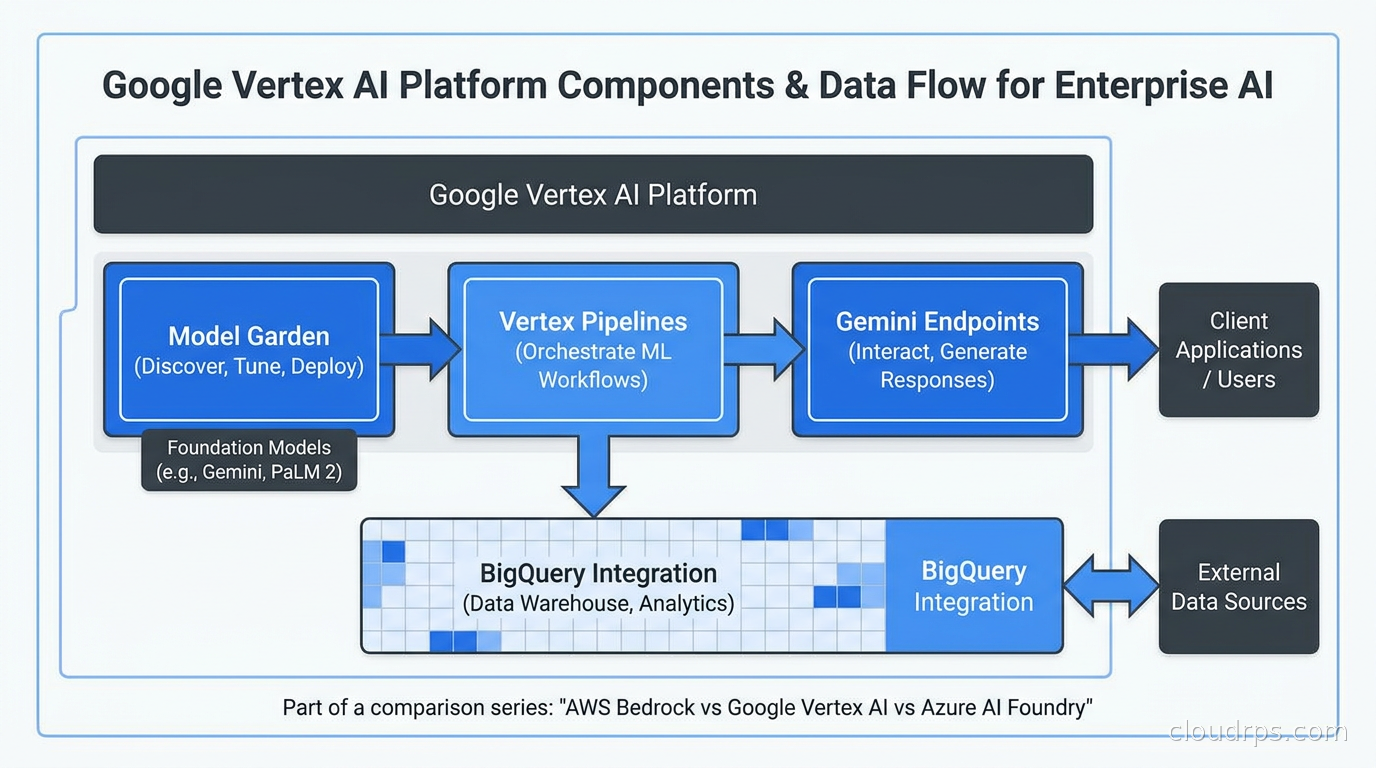
The Gemini integration is tight in ways that matter for performance. When you call Gemini 2.5 Pro through Vertex AI, you are hitting Google’s TPU infrastructure directly. You get the lowest latency path, context caching that reduces token costs dramatically on repeated prompts, the 1-million-token context window, and the best pricing on Gemini models (Gemini 1.5 Flash pricing in particular is competitive for high-volume workloads). If Gemini is your model of choice and cost per token at scale matters, Vertex AI is the right home.
The BigQuery integration deserves its own mention. If your team is already running analytics on BigQuery, Vertex AI’s ability to run inference directly in BigQuery SQL (BigQuery ML with Gemini remote models), or to pipe BigQuery tables directly into Vertex AI Pipelines without an ETL step, is a genuine productivity multiplier. I have seen data teams cut weeks off project timelines because they did not have to build a separate data export pipeline to feed the AI system.
Where Vertex AI struggles:
The developer experience outside the Google ecosystem is rougher. If your team is AWS-native and you are evaluating Vertex AI for a specific Gemini use case, expect a steeper ramp. The IAM model is different. The VPC networking approach (Private Service Access, VPC-SC) is powerful but has more moving parts than Bedrock’s VPC endpoint story. The SDK surface is well-designed for ML engineers but feels more complex to application developers who just want to call a model.
The multi-model story is thinner than Bedrock. Vertex has Model Garden with third-party models, but the depth and maturity of support varies. Claude on Vertex AI works well enough, but you are not getting the same first-class treatment you get on Bedrock. If your architecture requires mixing multiple frontier models across providers, Vertex AI requires more custom routing logic.
Because LLM inference infrastructure and fine-tuning are core Vertex AI strengths, teams doing LoRA and QLoRA fine-tuning workflows on Google Cloud will find fewer rough edges here than anywhere else.
Azure AI Foundry: The Enterprise Compliance Play
Azure AI Foundry (rebranded from Azure OpenAI Service and AI Studio in 2025) is the right choice when your organization’s primary constraint is enterprise compliance and your team is already deep in the Microsoft ecosystem. The OpenAI relationship is Azure’s core differentiator: GPT-4o, o3, and the latest OpenAI models land on Azure AI Foundry before anywhere else or simultaneously. If your use case requires the latest OpenAI models under your own enterprise terms of service (your data stays in your tenant, no training on your data, GDPR/HIPAA/FedRAMP High compliance), Azure AI Foundry is often the fastest path.
The compliance story is genuinely best-in-class. Azure AI Foundry inherits the full Microsoft compliance portfolio: FedRAMP High, HIPAA BAA, ISO 27001, SOC 2 Type II, GDPR data processor agreements. For US federal workloads and healthcare specifically, this matters. Vertex AI’s FedRAMP High availability has been more limited and GCP’s compliance portfolio, while growing, is thinner than Azure’s for specific regulated industry requirements.
The Microsoft stack integration runs deep. Entra ID (formerly Azure Active Directory) for identity means your existing enterprise identity governance flows directly into AI API access control. Azure Monitor, Azure Private Endpoints, Azure Defender for Cloud all integrate with AI Foundry in ways that make the platform feel like a native part of your existing security and compliance infrastructure. Content Safety (Azure’s content moderation service) plugs into Foundry cleanly. For enterprises already running Microsoft 365, Copilot Studio, and Power Platform, the Foundry integration creates a coherent AI application stack that is worth real money in integration cost savings.
The developer experience has improved substantially. The Azure OpenAI Python SDK follows OpenAI’s API contract closely enough that in many cases you can switch from OpenAI to Azure OpenAI with two lines changed: the endpoint and an API version header. That portability is useful for teams that want to hedge between OpenAI’s consumer API and Azure’s enterprise API.
Where Foundry struggles:
The model catalog outside of OpenAI models is thinner than Bedrock. Azure has Meta Llama, Mistral, and a selection of open-weight models through the model catalog, but if you need Anthropic’s Claude under enterprise terms via Azure (rather than Anthropic directly), the integration is not as clean as Bedrock’s. The multi-model routing story requires more custom work.
The agent framework (Azure AI Agent Service) is functional but less mature than Bedrock’s AgentCore or what you can build on Vertex AI with custom serving. For complex multi-agent workflows, most teams I have worked with end up building on top of the raw API rather than using the managed agent framework.
Cost is also worth noting. Azure OpenAI pricing for GPT-4o and o3 models at scale can be higher than equivalent Gemini or Claude pricing through their native platforms. The enterprise compliance premium is real and often worth paying, but it is a real cost.
The Real Decision Framework
Here is how I actually work through this with clients.
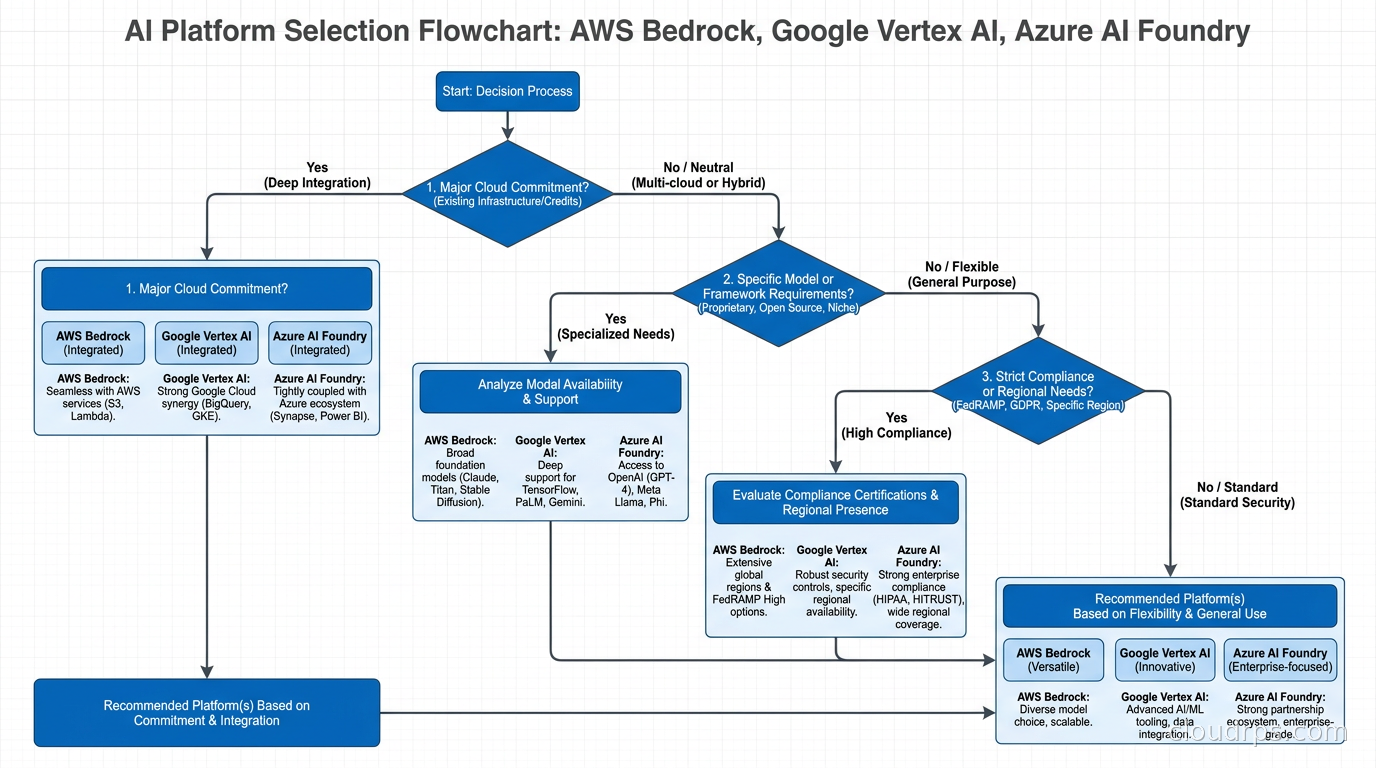
Start with your existing cloud commitment. If you are 80% on AWS and your team knows IAM, VPC, and CloudWatch in their sleep, Bedrock is almost always the right default. The productivity multiplier from not having to learn a new cloud’s networking and security model is significant. The same logic applies to GCP and Vertex AI. The “pick the platform that matches your cloud” advice sounds obvious but I have seen teams spin up Azure AI Foundry while running everything else on AWS and then spend three months debugging cross-cloud networking and credential management. That time comes out of feature velocity.
Then assess model requirements. If Gemini models are genuinely superior for your use case (multimodal workloads, long-context document analysis, BigQuery-integrated analytics) or if you need the absolute lowest per-token cost on high-volume inference, Vertex AI makes a strong case even for non-GCP-native teams. If your use case requires the latest OpenAI models under enterprise terms, Azure AI Foundry is the path. If you need multi-model flexibility (routing different task types to different providers), Bedrock wins.
Compliance requirements narrow the choice fast. US federal agencies and heavily regulated financial services firms on Microsoft infrastructure should default to Azure AI Foundry for its compliance depth. Healthcare organizations on AWS should evaluate Bedrock’s HIPAA compliance carefully (it is there, but the BAA scope matters). GCP’s compliance is catching up but trailing.
For RAG workloads, all three platforms have managed retrieval pipelines. Bedrock’s Knowledge Bases is the easiest to operate for teams already familiar with OpenSearch. Vertex AI’s Search and Retrieval is tightly integrated with BigQuery and Cloud Storage. Azure AI Foundry’s Azure AI Search integration is mature and enterprise-ready. The differences matter less than whether the underlying vector search performance and freshness requirements match your use case. I wrote a deeper guide to the retrieval patterns themselves in the RAG architecture article.
For AI agent workloads, think carefully about what you need from the managed agent runtime versus what you will build yourself. Bedrock AgentCore is the most complete managed option. If you are already comfortable building on LLM orchestration frameworks, you may prefer to bring your own orchestration layer and use whichever platform gives you the best model access. The security controls for agents (prompt injection defense, tool authorization, session isolation) work differently across platforms and deserve specific evaluation if agent security is a concern.
Cost: The Thing Nobody Talks About Clearly
I have had more post-deployment conversations about AI infrastructure cost than any other topic in the past two years. Token pricing is the obvious variable, but there are three other cost drivers that teams consistently underestimate.
Egress and data transfer. Sending large documents or images to a model API, especially from services running in another cloud or on-premises, generates egress costs that add up fast. Running Vertex AI while your data lives in S3 means paying cross-cloud egress on every inference call. The cloud egress cost architecture article covers the general pattern; for AI workloads, the same principles apply and the volumes are often higher than you expect.
Embedding costs. RAG systems call embedding models constantly: at ingestion for documents, at query time for each user query. Embedding API costs often exceed generation API costs for read-heavy RAG applications. All three platforms charge for embedding calls separately from generation. Model the full request flow before committing to a budget.
Provisioned throughput. Once you are running consistent production volume, the on-demand pricing tiers stop making sense and you need reserved capacity. Bedrock’s Provisioned Throughput, Vertex AI’s committed-use model endpoints, and Azure’s Provisioned Throughput Units all require upfront commitment. The pricing structures differ enough that at high volume, one platform can be 30-40% cheaper than another for the same workload. Run the numbers with your actual expected token counts before signing anything.
For LLM observability and cost attribution, all three platforms expose token usage per call, but getting that data into a cost allocation system that maps to teams, features, or customers requires additional tooling. None of the managed platforms solve the chargebacks problem for you out of the box.
Vendor Lock-in and Escape Hatches
Twenty years of cloud architecture has made me allergic to deep vendor lock-in, and I say that knowing full well that some lock-in is acceptable. The question is: which coupling points are you comfortable with?
All three platforms use different API conventions. The Converse API on Bedrock, the Vertex AI SDK with Gemini-specific parameters, and the Azure OpenAI API (which follows the OpenAI spec closely) are not trivially interchangeable. If you build directly against the native SDK, migrating to a different platform is a multi-week engineering effort, not a configuration change.
The escape valve most teams use is an AI gateway layer sitting between your application code and the model APIs. Tools like LiteLLM, Kong AI Gateway, and PortKey translate between provider APIs and give you a routing layer where you can switch backends without changing application code. If you are committing to a three-year product build on one of these platforms, seriously consider whether a gateway layer makes sense. The operational overhead is real but so is the flexibility.
The RAG and agent infrastructure creates deeper lock-in than the model API. Migrating a Knowledge Base from Bedrock to Vertex AI Search is a real data migration project. Migration from AgentCore to a DIY agent framework means rewriting orchestration logic. Plan the scope of your platform commitment before you build deep integrations.
What I Actually Recommend
For teams starting new AI projects in 2026, my default recommendations:
AWS-native teams: Start with Bedrock. Use the Converse API. Build Guardrails from day one, not as an afterthought. Use Knowledge Bases for RAG unless you have specific requirements that push you to a different vector store. Evaluate Provisioned Throughput at 90 days if volume warrants it.
GCP-native teams with ML heavy workloads: Vertex AI, especially if you have BigQuery as your data platform. The full MLOps lifecycle integration is worth the investment.
Microsoft-ecosystem enterprises with compliance requirements: Azure AI Foundry, especially for OpenAI-model-dependent applications and US federal or healthcare workloads.
Multi-cloud teams or teams with complex model routing needs: Consider an AI gateway layer from day one so your application code stays provider-agnostic. Pick the platform that hosts your most critical model dependency and route everything else through the gateway.
The platform decision is real, but it is not permanent. I have helped teams migrate between all three platforms as requirements evolved. It is expensive and disruptive, which is exactly why you should make the initial choice carefully using your actual constraints rather than benchmark blog posts or what your favorite cloud vendor’s sales team told you. Go talk to engineering teams who have shipped production AI on whichever platform you are evaluating. The war stories you hear from practitioners are worth more than any feature comparison table.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.