Early in my career I spent several months at a company that ran a public NTP service. We had a single server in a datacenter in Dallas, a single public IP, and thousands of clients around the world polling us every few minutes. The server was fine. The latency for someone in Tokyo or Frankfurt was not. A client in Japan was hitting a server 10,000 kilometers away, adding 150+ milliseconds of round-trip time to a protocol that is sensitive to single-digit millisecond jitter. When I brought up the idea of deploying regional instances, the networking lead asked a question that seemed simple at the time: “But how do all those servers share the same IP address?”
That question opened a door I have been walking through for twenty years: BGP anycast. It is the foundational routing technique behind Cloudflare’s 1.1.1.1, Google’s 8.8.8.8, the entire DNS root server system, and every major CDN on the planet. It is one of those concepts that sounds like magic until you understand it, and then it becomes one of the most elegant tools in cloud architecture.
The Four Delivery Models: Why Anycast Is Different
Before getting into mechanics, let me establish the vocabulary. IPv4 defines four fundamental ways to address traffic:
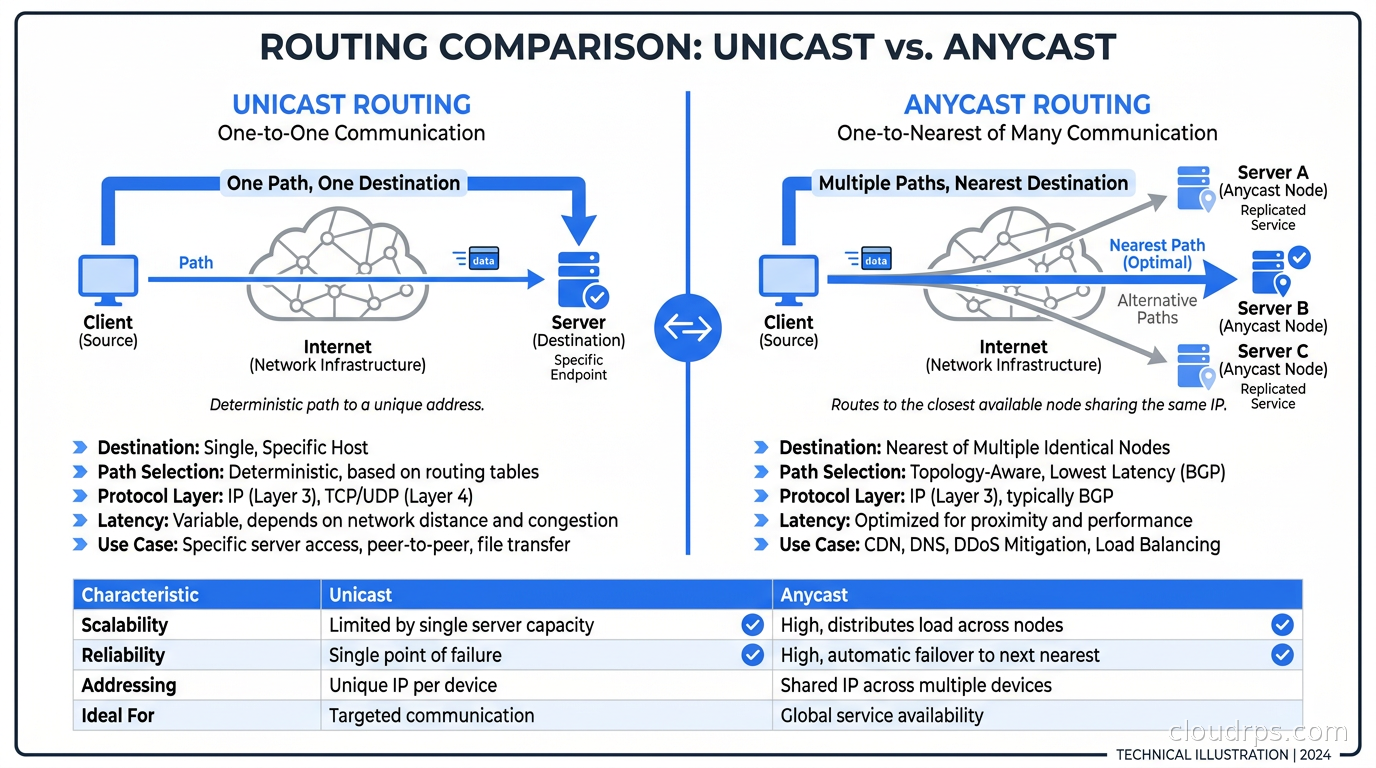
Unicast is the normal case. One source, one destination. When you SSH into a server, packets flow from your IP to exactly one remote IP.
Broadcast sends to all hosts in a subnet. This is why ARP works the way it does. It does not scale beyond a local segment, which is why you never see broadcast routing on the internet.
Multicast delivers packets from one source to a group of subscribed receivers. Think IPTV or some financial data feeds. Multicast requires routers to maintain group membership state, which is operationally complex and barely deployed outside controlled networks.
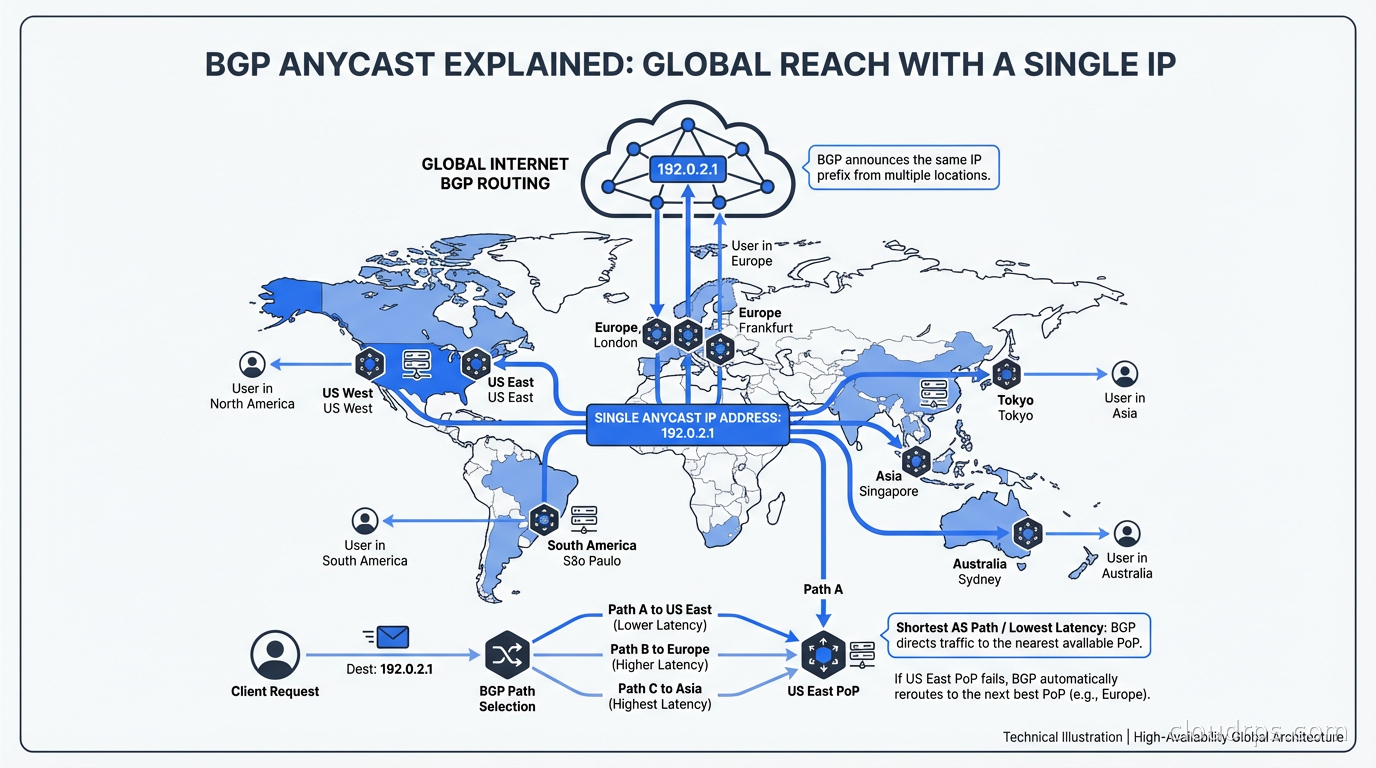
Anycast is the interesting one. The same IP address is assigned to multiple servers in different geographic locations. Routing protocols advertise the address from all those locations simultaneously. When a client sends a packet to an anycast address, the internet’s routing infrastructure delivers it to the topologically nearest instance, measured in BGP hop count and path attributes.
The critical insight: the client has no idea it is using anycast. From its perspective it is just sending packets to an IP. The routing fabric does all the work.
How BGP Makes Anycast Work
BGP, the Border Gateway Protocol, is the routing protocol that holds the internet together. It is how autonomous systems (ASes) exchange reachability information. Every major network operator has an AS number. When you announce a prefix via BGP, you are telling the rest of the internet “I can deliver packets destined for this IP range.”
Anycast exploits a fundamental property of BGP: nothing prevents two different ASes from announcing the same prefix. When two or more locations announce the identical prefix, BGP’s path selection algorithm kicks in and each upstream network chooses a best path. Since BGP prefers shorter AS paths (among other criteria), routers generally end up directing traffic to the geographically closest anycast node, though “closest” here means network-topology-closest, not necessarily geographic-closest.
Here is a concrete example. Cloudflare operates 1.1.1.1, their public DNS resolver. The prefix 1.1.1.1/32 (and the broader 1.0.0.1/32) is announced from every one of Cloudflare’s 300+ points of presence worldwide. When someone in Singapore queries 1.1.1.1, BGP routes their packets to the Cloudflare PoP in Singapore, not to one in San Jose. When someone in Amsterdam queries 1.1.1.1, they hit the Frankfurt or Amsterdam PoP.
Google does the same with 8.8.8.8 and 8.8.4.4. The DNS root servers have been anycast since 2002. The thirteen root server “letters” (A through M) are each operated by multiple organizations across hundreds of physical instances, all sharing the same anycast address per letter.
For DNS in particular, anycast is a perfect fit because DNS is stateless. Each query is an independent UDP exchange. The client sends a question, the server sends an answer. There is no connection to maintain, no session state. The fact that a subsequent query might hit a different anycast node is irrelevant.
The BGP Announcement Mechanics
Running anycast in practice means you need your own IP space (Provider Independent, or PI, space) and your own AS number, both obtained from a Regional Internet Registry like ARIN, RIPE, or APNIC. You cannot use IP addresses that your upstream provider assigned to you, because those belong to their routing table and cannot be announced independently from multiple locations.
Once you have PI space and an ASN, the architecture looks like this at each anycast site:
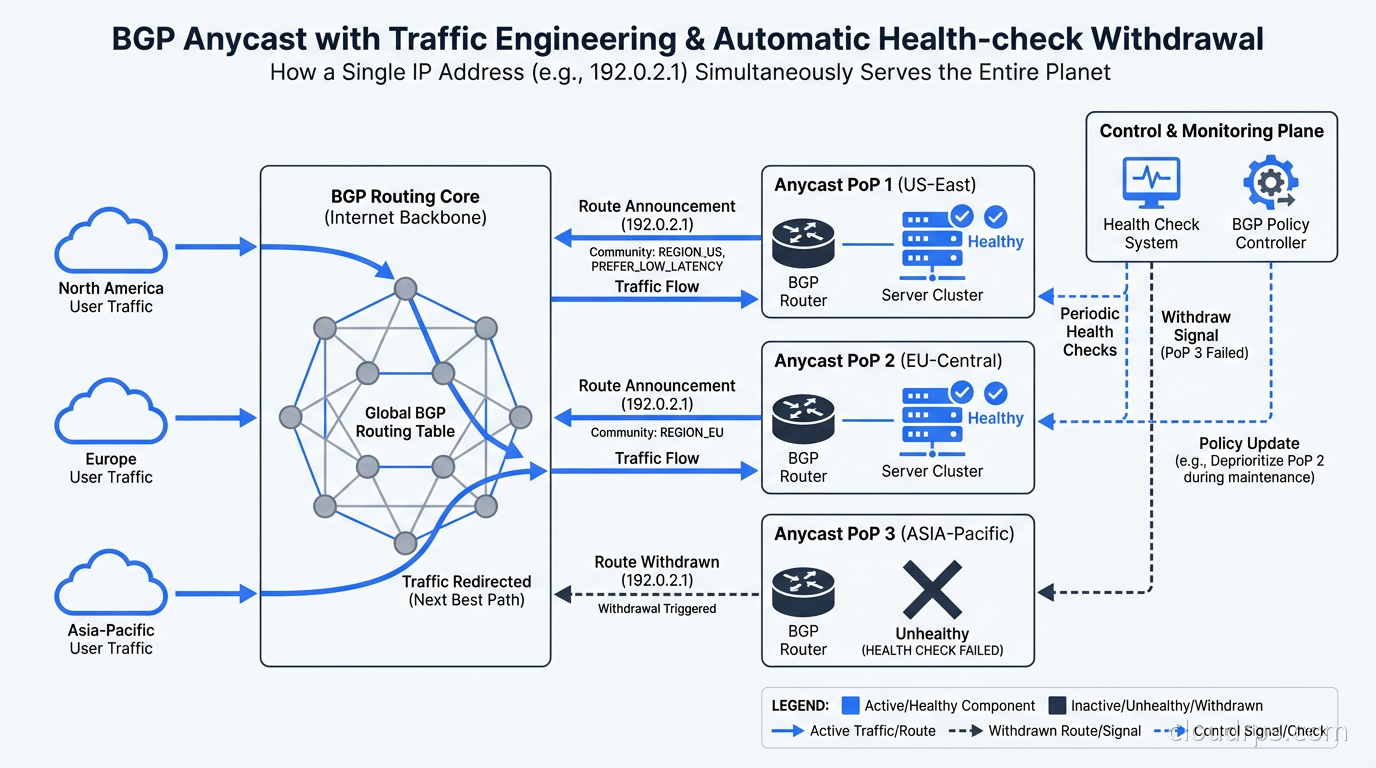
You peer with local transit providers (or an Internet Exchange Point) using BGP. You announce your prefix from that site. You do this at every location. The upstream providers propagate your announcement into the global routing table. Within minutes, the entire internet knows that your prefix is reachable from multiple ASes.
When a node goes down, you withdraw the BGP announcement from that site. BGP convergence typically propagates the withdrawal globally within 60-300 seconds, though modern networks with RPKI and optimized timers can do it faster. During that window, some traffic may black-hole, which is why anycast is generally paired with health checks that trigger automatic announcement withdrawal.
The most common operational tool for this is ExaBGP or BIRD. You run a routing daemon at each site that monitors the health of your service (a simple TCP check works) and conditionally announces or withdraws the prefix based on health state. If the service is healthy, announce. If it is down, withdraw. The internet routes around it automatically.
The flip side of this routing flexibility is that BGP has no built-in mechanism to verify whether an announcement is legitimate. Misconfigured or malicious networks can announce your prefix and divert your traffic, which is exactly what happened to YouTube in 2008 and Amazon Route 53 in 2018. RPKI (Resource Public Key Infrastructure) is the cryptographic solution to this problem; see the full guide on BGP security and RPKI for how to protect your prefix space.
Real-World Anycast Topology
Let me walk through what a real anycast deployment looks like for a company with moderate scale needs: say, a global SaaS product that wants low latency DNS and API ingress for users on six continents.
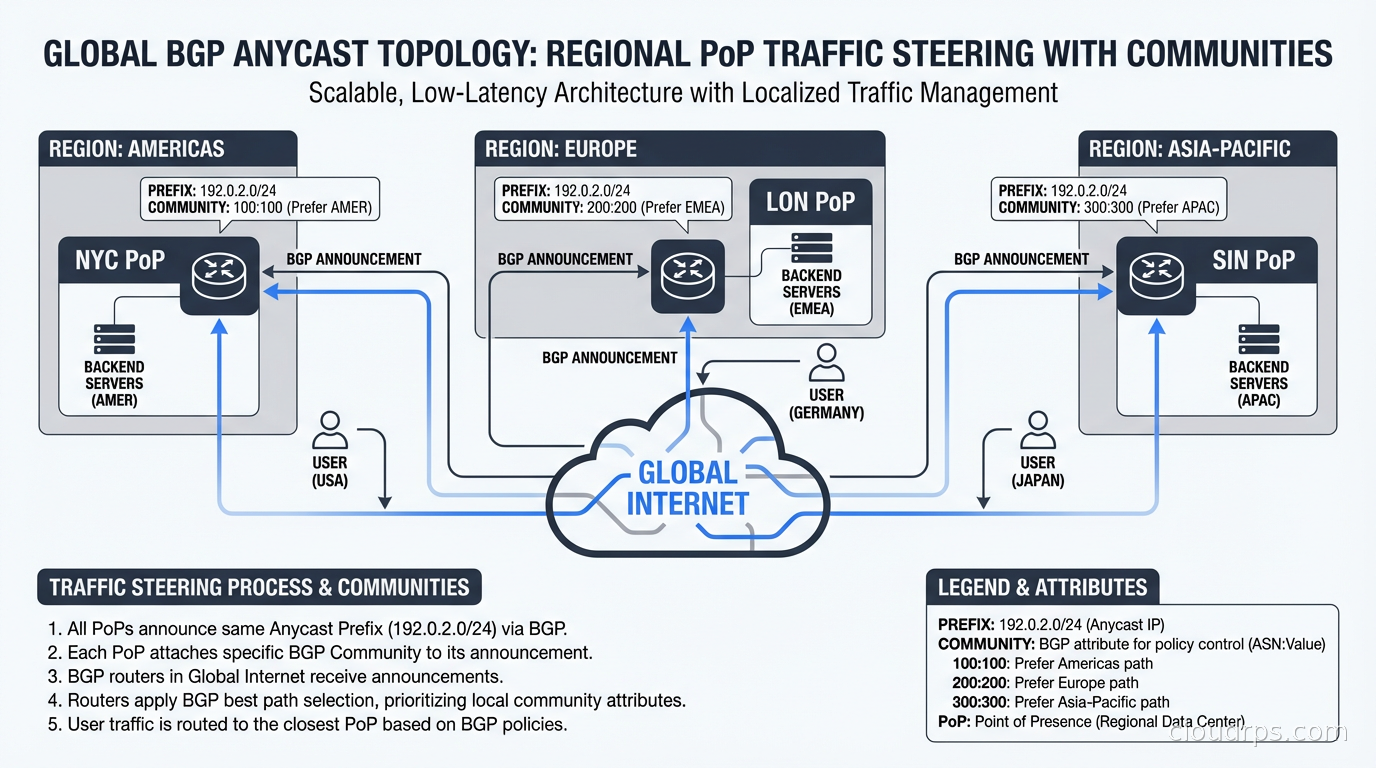
You would provision anycast nodes in four to six regions: North America (two sites for redundancy), Europe, Asia-Pacific, South America, and possibly Africa and Middle East if traffic warrants it. Each node peers with multiple upstream transit providers (two at minimum, for redundancy) and announces your /24 PI prefix.
Traffic engineering via BGP communities lets you shape how announcements propagate. The most common technique is to tag announcements with “no-export” communities to limit propagation to specific regions. This is called geo-anycast or regional anycast. You announce your prefix globally from your North American sites, but you tag your European announcement so it only propagates to European transit networks. Users in Europe hit European nodes; users elsewhere hit American nodes.
This matters for data residency compliance. If your application cannot serve European user data from a US datacenter, you can use BGP communities to ensure European users always reach European infrastructure. The data sovereignty requirements that GDPR imposes become a routing engineering problem as much as a legal one.
Anycast and DDoS Mitigation
One of the most powerful applications of anycast is DDoS mitigation. This took me a few years to fully appreciate, but the math is compelling.
If you have a single-site unicast IP and someone launches a 500 Gbps volumetric attack at it, your upstream provider’s pipes fill up and you go offline. There is nowhere for the traffic to go.
With anycast, that same 500 Gbps attack is automatically distributed across every node announcing your prefix. If you have 20 PoPs, each absorbs roughly 25 Gbps on average (the actual distribution depends on where the attack traffic originates). A well-resourced anycast network can absorb terabit-scale attacks because the capacity is distributed globally. This is precisely why Cloudflare can advertise 321 Tbps of DDoS mitigation capacity: that number is the sum of bandwidth across all their anycast nodes.
There is a subtlety here: anycast only distributes traffic across sites based on the source of the attack. If 100% of the attack traffic originates from one AS in Eastern Europe, all of it routes to your nearest European node. You have not gained any distribution benefit for that traffic. True DDoS mitigation at anycast scale requires attack traffic that is globally distributed (as most modern botnets are) or the ability to selectively blackhole announcements from affected regions.
The other technique is BGP blackholing or RTBH (Remote Triggered Black Hole). When under attack, you announce the target IP with a specific BGP community (typically 666) that signals upstream providers to drop traffic to that destination at their edge, before it ever reaches your network. You sacrifice availability for the targeted IP in exchange for protecting your other infrastructure. It is a nuclear option, but sometimes the right one.
When Anycast Breaks: TCP and Stateful Protocols
Here is the gotcha I have watched bite three different teams over the years. Anycast is fundamentally designed for stateless protocols. DNS over UDP works perfectly. NTP works perfectly. ICMP (and therefore ping) works perfectly.
TCP is trickier.
TCP requires a stateful three-way handshake and subsequent packet delivery to the same endpoint. If routing changes mid-connection (because BGP reconverges, or because you traversed a path where ECMP hashed your packets differently), your TCP connection breaks. For short-lived connections like HTTP/1.0 requests, this is usually acceptable: the connection completes before routing can shift. For long-lived TCP connections (WebSockets, persistent database connections, file uploads), anycast instability can cause hard-to-diagnose connection resets.
Cloudflare and other major anycast operators have largely solved this with intelligent path stability mechanisms, ECMP flow hashing, and by combining anycast at the edge with unicast for long-lived session backends. The anycast IP accepts the TCP SYN and establishes the connection; backend traffic is then forwarded over stable unicast paths to origin servers.
For your own implementation, the practical guidance is: use anycast for DNS, for DDoS scrubbing ingress, and for short-lived HTTP request dispatch. Do not put a PostgreSQL database behind an anycast IP. Do not use anycast for WebSocket-heavy applications without session pinning at the anycast layer.
Anycast vs DNS-Based Global Load Balancing
A common question I get from architects designing global systems is: “Why use anycast instead of just GeoDNS?” It is a fair question. DNS-based global load balancing (what AWS Route 53 latency routing, Cloudflare Load Balancer, and similar services provide) also routes users to the nearest endpoint based on geography or latency measurements.
The difference comes down to speed, precision, and failure handling.
DNS changes propagate subject to TTL. If you set a 60-second TTL, you get minute-level failover at best, and many resolvers do not honor low TTLs. BGP anycast withdrawal propagates in seconds to tens of seconds.
DNS resolution also adds a round-trip before the actual connection. With anycast, the routing happens at the packet level in the network fabric, adding zero latency overhead to the connection itself.
DNS-based routing is also limited by geographic database accuracy. The GeoIP databases that DNS providers use to determine “where is this resolver” are imperfect. Anycast routing follows actual network topology, which is a more accurate proxy for real-world latency.
That said, GeoDNS is dramatically simpler to operate. You do not need PI space, an ASN, or relationships with multiple upstream providers. For most teams, DNS-based load balancing is the right starting point. Anycast is a tool you reach for when you need sub-second failover, true DDoS absorption capacity, or are building global infrastructure at CDN scale.
You can combine the approaches: use DNS with a short TTL to direct users to your nearest regional anycast cluster, then use anycast within each region for intra-region load distribution and DDoS mitigation. This is roughly what major CDN architectures look like, as described in the CDN internals guide.
IP Addressing and the /24 Rule
A practical note for teams looking to deploy anycast: you need a minimum of a /24 prefix (256 IP addresses) to be accepted into the global routing table. Many networks filter more-specific prefixes to keep the global routing table manageable. The current global routing table has over 950,000 prefixes and the industry applies strict filters to prevent further explosion.
Understanding CIDR notation and how prefix aggregation works is essential background here. If you have a /24, you announce exactly that /24. If you try to announce a /28 from multiple locations, most providers will drop it.
This has a practical implication: you cannot easily do anycast with a single IP unless you announce a covering /24 that contains it and then use host routes (/32) internally. The /32 announcements will not propagate globally, but the /24 will, and as long as your service IP is within that /24, you are fine.
Anycast in Kubernetes and Cloud-Native Infrastructure
Modern Kubernetes networking has started incorporating anycast concepts, particularly in the context of MetalLB for bare-metal LoadBalancer services and Cilium’s BGP control plane. If you are running Kubernetes on bare metal or in a colocation facility without a managed cloud load balancer, you can use BGP to advertise service IPs directly from your nodes.
Cilium, which I covered in the context of CNI plugins and network policies, has a mature BGP control plane feature that turns your Kubernetes nodes into BGP speakers. Each node announces service VIPs, effectively creating a form of anycast where packets for a service are routed to whichever node is advertising the service IP. Combined with ECMP, this creates a simple but effective distributed load balancing mechanism without requiring an external load balancer appliance.
This pattern is particularly common in edge computing deployments where you want consistent IP addresses for services running across a fleet of geographically distributed Kubernetes clusters. The same service VIP is announced from every cluster, users reach the nearest one, and BGP handles failover automatically.
For multi-region active-active architectures, anycast provides the routing glue that makes transparent failover possible at the IP layer, below the application. Combined with a distributed database that can handle writes from multiple regions, anycast is one component of a stack that can survive complete regional failure without user-visible downtime.
Operational Realities and Gotchas
After running anycast infrastructure in production for a significant chunk of my career, here are the operational realities nobody tells you about:
BGP session management is your pager enemy. Every anycast site needs stable BGP sessions to multiple upstreams. When a BGP session flaps, your prefix gets withdrawn and re-announced, causing a brief routing disruption. Invest in session monitoring and alerts.
Asymmetric routing is normal and confusing. A packet might enter your network in New York but leave via Frankfurt because of BGP path selection. Your firewall and stateful inspection tools need to handle asymmetric flows. Many teams get burned by stateful firewalls dropping return traffic that comes back via a different path.
Debugging is harder. When a user reports a connection issue, their traffic might be going to any one of your PoPs. Your distributed tracing and logging need to be robust enough that you can reconstruct which PoP served a given request. OpenTelemetry with a consistent request ID header, combined with centralized logging, is the minimum viable setup.
Test withdrawals regularly. BGP announcement withdrawal is the core of your failover mechanism. Test it. Run game days where you deliberately pull announcements from a site and verify that traffic reroutes correctly and quickly. The first time you discover your withdrawal mechanism does not work should not be during an actual outage.
RPKI matters now. Route Origin Authorization (ROA) and RPKI (Resource Public Key Infrastructure) are the standard for preventing BGP hijacking. If you are running anycast with your own PI space, you should create ROA records in your RIR’s RPKI system. Without it, anyone can announce your prefix and steal your traffic.
Choosing Anycast for Your Architecture
To wrap up with practical guidance: anycast is the right tool when you have stateless global traffic that needs low latency and fast failover, when you need DDoS absorption distributed across many PoPs, or when you are building infrastructure that resembles a CDN or DNS resolver.
It is not the right tool when your traffic is dominated by long-lived stateful connections, when you need strict geographic segmentation (GeoDNS handles that more simply), or when you are a small team without dedicated networking expertise.
The minimum viable anycast setup requires PI space from your RIR, an ASN, at least two geographically separated sites each with two upstream BGP peers, and a health-check-driven announcement mechanism. At that point you have a functional global anycast network. Everything beyond that: more PoPs, BGP communities for traffic engineering, ECMP for intra-site load distribution, is additive.
When my NTP project lead asked how multiple servers could share a single IP address, the answer turned out to be elegant and surprising: you just announce the same prefix from all of them, and let BGP figure out the rest. Twenty years later, that same mechanism is powering the most critical networking infrastructure on the planet. Understanding it is not optional for anyone building infrastructure that operates at global scale.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.