I was sitting in a conference room in 2012 when a solutions architect from a database vendor tried to convince me that their product “beat the CAP theorem.” I knew right then that either they did not understand the CAP theorem, or they thought I did not. Either way, it was not a good look.
The CAP theorem is one of the most frequently cited and least understood concepts in distributed systems. People invoke it in architectural discussions like a magic incantation, often to justify decisions they have already made. But when you press them on what it actually says, and more importantly what it does not say, the understanding falls apart quickly.
I have spent the better part of two decades building and operating distributed database systems, and I want to give you the explanation I wish I had received when I first encountered this theorem.
What the CAP Theorem Actually States
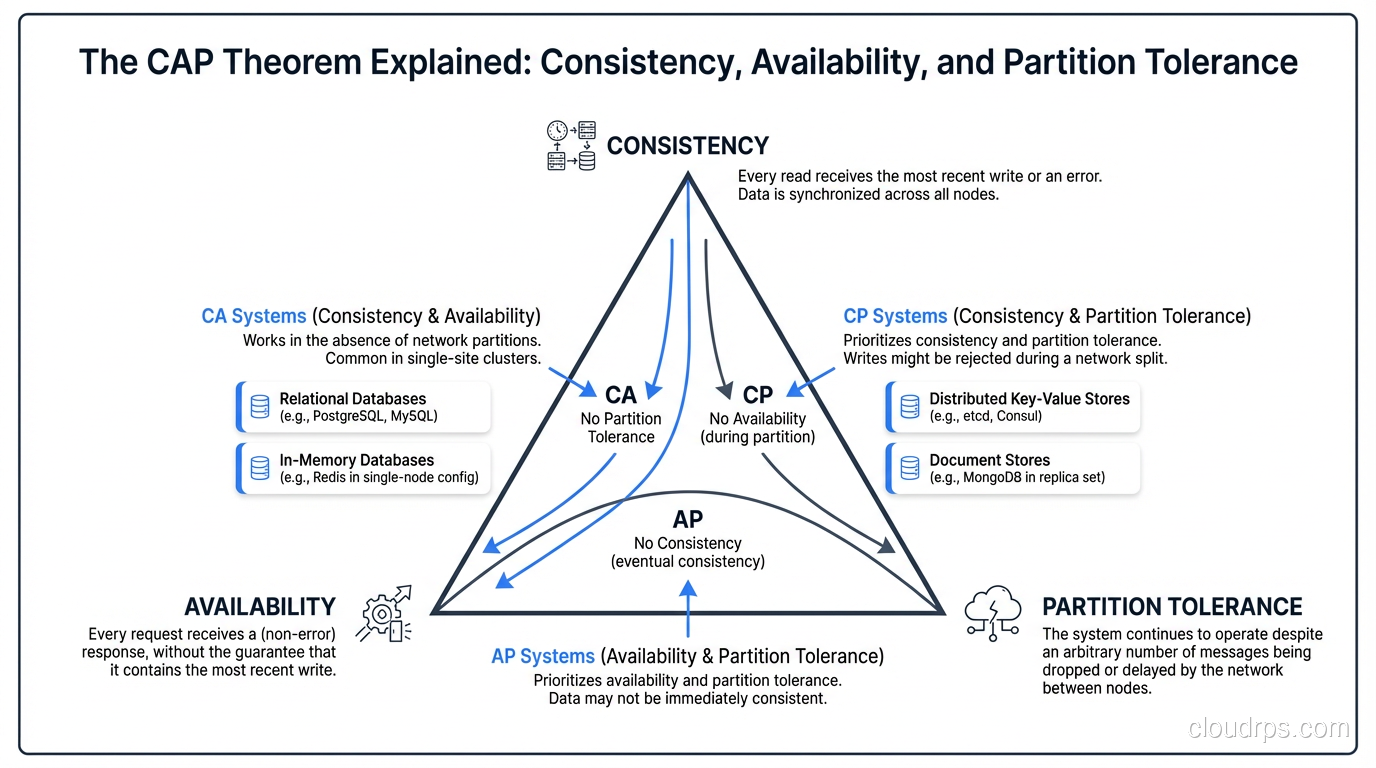
The CAP theorem, first conjectured by Eric Brewer in 2000 and formally proven by Seth Gilbert and Nancy Lynch in 2002, states that a distributed data store can provide at most two of the following three guarantees simultaneously:
Consistency (C): Every read receives the most recent write or an error. All nodes see the same data at the same time. If you write a value and then immediately read it from any node in the system, you get the value you just wrote.
Availability (A): Every request (read or write) receives a non-error response, without guarantee that it contains the most recent write. The system always responds, even if the response might be stale.
Partition Tolerance (P): The system continues to operate despite network partitions, meaning some nodes cannot communicate with other nodes due to network failures.
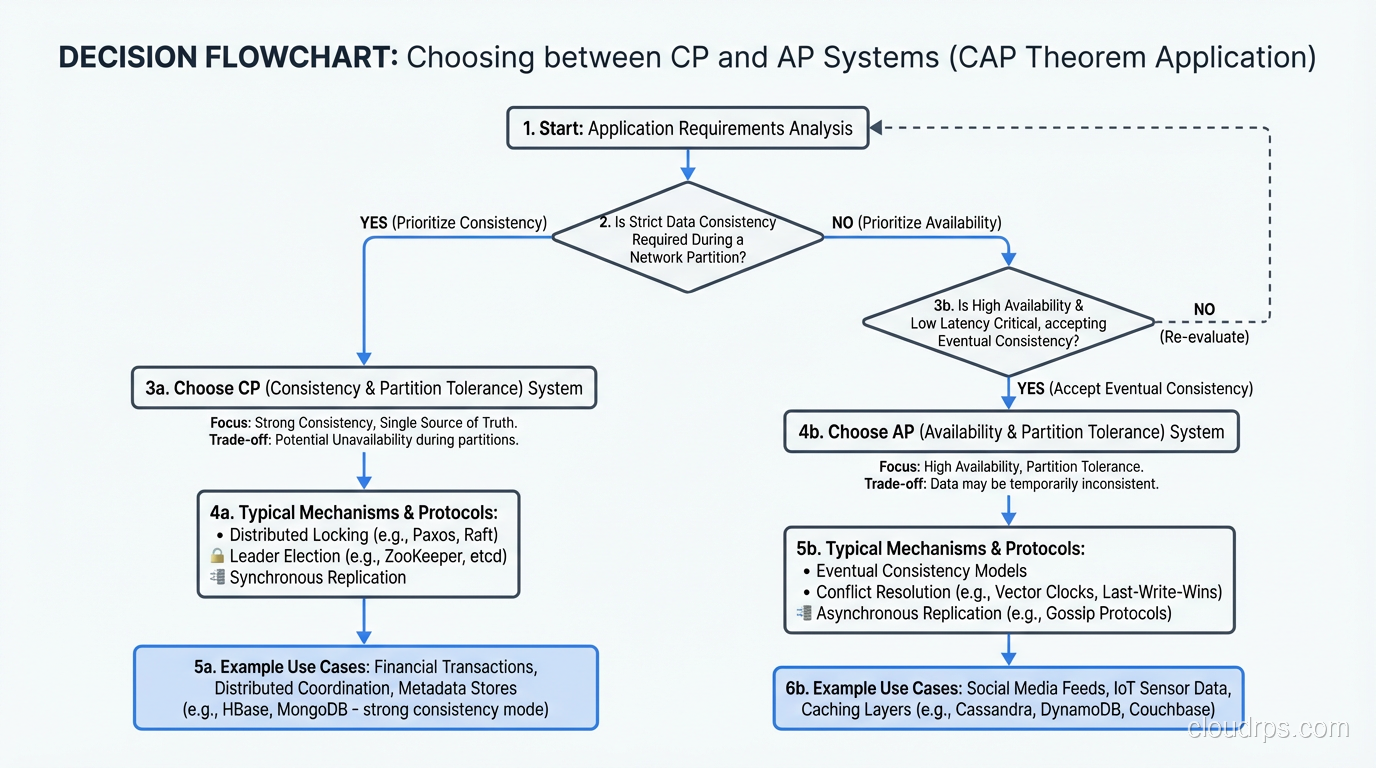
The theorem says you cannot have all three simultaneously. In the presence of a network partition, you must choose between consistency and availability.
Why Partition Tolerance Is Not Optional
Here is where the first major misunderstanding lives. People sometimes read CAP as “pick any two” and imagine three equal categories: CA, CP, and AP. But in any real distributed system, network partitions happen. Cables get cut. Switches fail. Cloud availability zones lose connectivity. You do not get to choose whether partitions occur.
This means the actual choice is between CP (consistency when partitioned, at the cost of availability) and AP (availability when partitioned, at the cost of consistency). A “CA” system (one that provides consistency and availability but cannot tolerate partitions) is just a single-node system, because the moment you distribute data across a network, partitions are possible.
I have watched network partitions take down production systems more times than I can count. The question is never “will a partition happen?” but “what does the system do when it happens?”
CP Systems: Consistency First
A CP system responds to network partitions by sacrificing availability to maintain consistency. When nodes cannot communicate, the system either refuses to serve requests or only serves requests from the partition that has a quorum (majority of nodes).
What This Looks Like in Practice
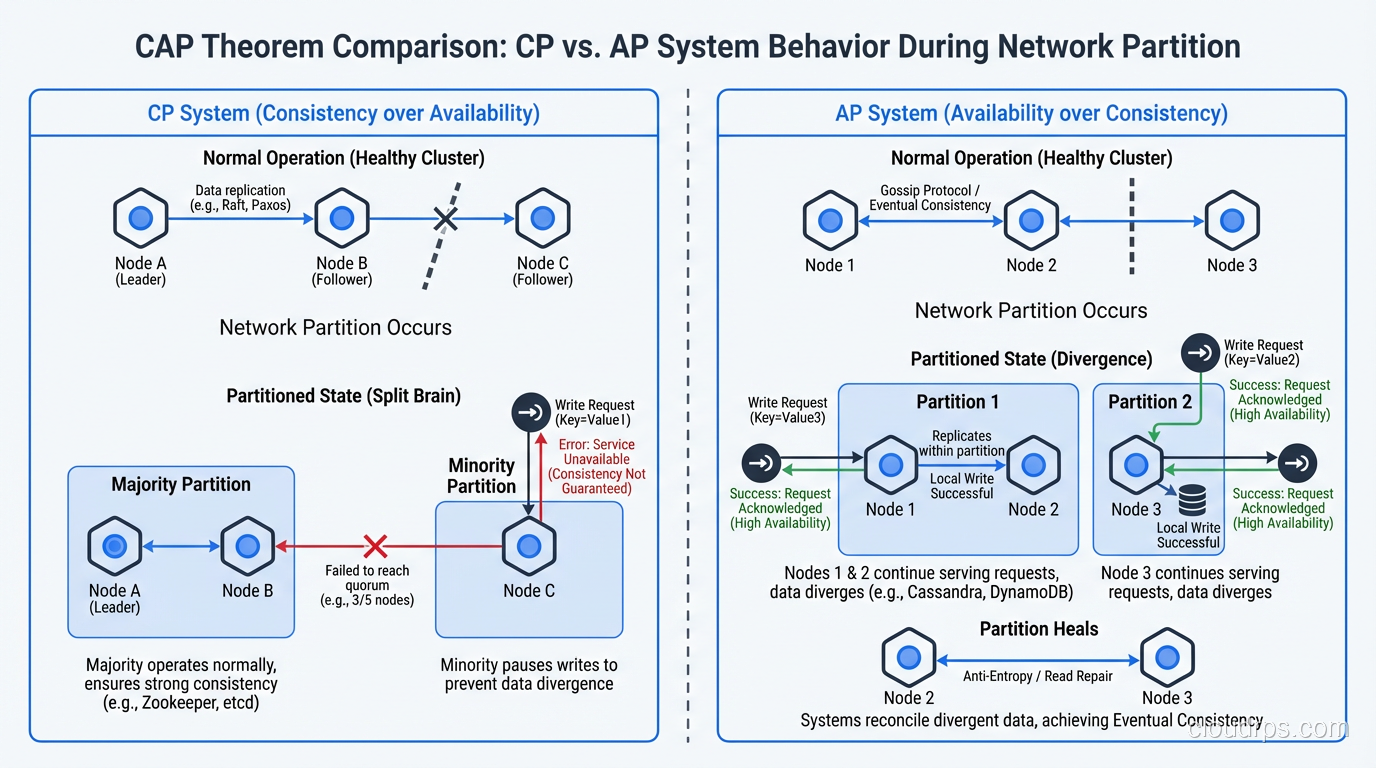
Imagine a three-node database cluster where nodes A, B, and C replicate data using a consensus protocol like Raft. If a network partition isolates node C from nodes A and B, the system must decide what to do.
In a CP system, nodes A and B can continue serving reads and writes because they form a majority (2 out of 3) and can reach consensus. Node C, which is isolated, cannot serve reads or writes because it cannot verify that its data is current. Clients connected to node C will get errors or timeouts.
This is the behavior you see in systems like ZooKeeper, etcd, and (when configured with strong consistency) CockroachDB and Spanner. They prioritize data correctness over universal availability.
When CP Is the Right Choice
CP makes sense when incorrect data is worse than unavailable data. Financial transactions are the obvious example. If a bank’s distributed system experiences a partition and the isolated node does not know whether a balance has been updated, it is far better to reject the transaction than to allow a double-spend based on stale data.
I chose CP systems for every payment processing and financial reporting system I have ever built. The brief unavailability during a partition is inconvenient. The data inconsistency from an AP system in this context would be catastrophic.
This ties directly into the ACID properties that relational databases provide. The “C” in ACID and the “C” in CAP are related but distinct concepts. ACID consistency means conforming to database constraints, while CAP consistency means all nodes see the same data. But in practice, systems that provide strong ACID guarantees in a distributed setting are almost always CP systems.
AP Systems: Availability First
An AP system responds to network partitions by continuing to serve requests from all nodes, even though they might return stale or conflicting data. Every node is available, but there is no guarantee that all nodes agree on the current state.
What This Looks Like in Practice
Using the same three-node example: when node C is isolated from A and B, all three nodes continue serving reads and writes. But writes to node C will not be visible to A and B (and vice versa) until the partition heals. During the partition, clients might read different values depending on which node they connect to.
When the partition heals, the system must reconcile the conflicting writes, a process that can range from simple (last-write-wins based on timestamps) to complex (application-specific conflict resolution logic).
This is the behavior you see in systems like Cassandra, DynamoDB (with eventually consistent reads), CouchDB, and Riak. They prioritize staying available over maintaining a globally consistent view.
When AP Is the Right Choice
AP makes sense when stale data is acceptable and availability is paramount. A social media feed that shows a post a few seconds late is fine. A shopping cart that occasionally shows a slightly stale view of items is tolerable. A content delivery system that serves a cached version while the origin is unreachable is exactly right. Distributed caches like Redis and Valkey are inherently AP systems; understanding their TTL and invalidation tradeoffs is essential, and the distributed caching guide covers those patterns in depth.
I designed an IoT telemetry platform in 2019 on Cassandra specifically because availability was more important than perfect consistency. Sensors were sending temperature readings every second. If a network partition meant that some readings were slightly delayed or arrived out of order, the analytics pipeline could handle it. But if the system refused to accept sensor data during a partition, we would lose readings permanently, and that was unacceptable.
The Nuances That Everyone Misses
The CAP theorem as commonly stated is an oversimplification. The real picture is more nuanced, and understanding those nuances is critical for making good architectural decisions.
CAP Is About Partitions, Not Normal Operation
During normal operation, when there are no partitions, you can have both consistency and availability. The trade-off only applies during a partition event. A well-designed system should provide consistency and availability most of the time and degrade gracefully during the (hopefully rare) partition events.
This is why “pick two out of three” is misleading. In practice, you pick your behavior during partitions. The rest of the time, a good system provides both strong consistency and high availability.
Consistency and Availability Are Not Binary
The CAP theorem as proven is a binary result: you cannot simultaneously guarantee perfect consistency, perfect availability, and partition tolerance. But real systems operate on a spectrum. You do not have to choose between “perfectly consistent” and “not consistent at all.”
Tunable consistency is a real thing. In Cassandra, you can configure consistency levels per query. A write with QUORUM consistency and a read with QUORUM consistency gives you strong consistency (as long as no more than one replica is unavailable). A read with ONE gives you higher availability and lower latency but weaker consistency. You tune the trade-off based on the requirements of each specific operation.
DynamoDB offers both eventually consistent reads (faster, cheaper, AP-flavored) and strongly consistent reads (slower, more expensive, CP-flavored) on the same data. You choose per request.
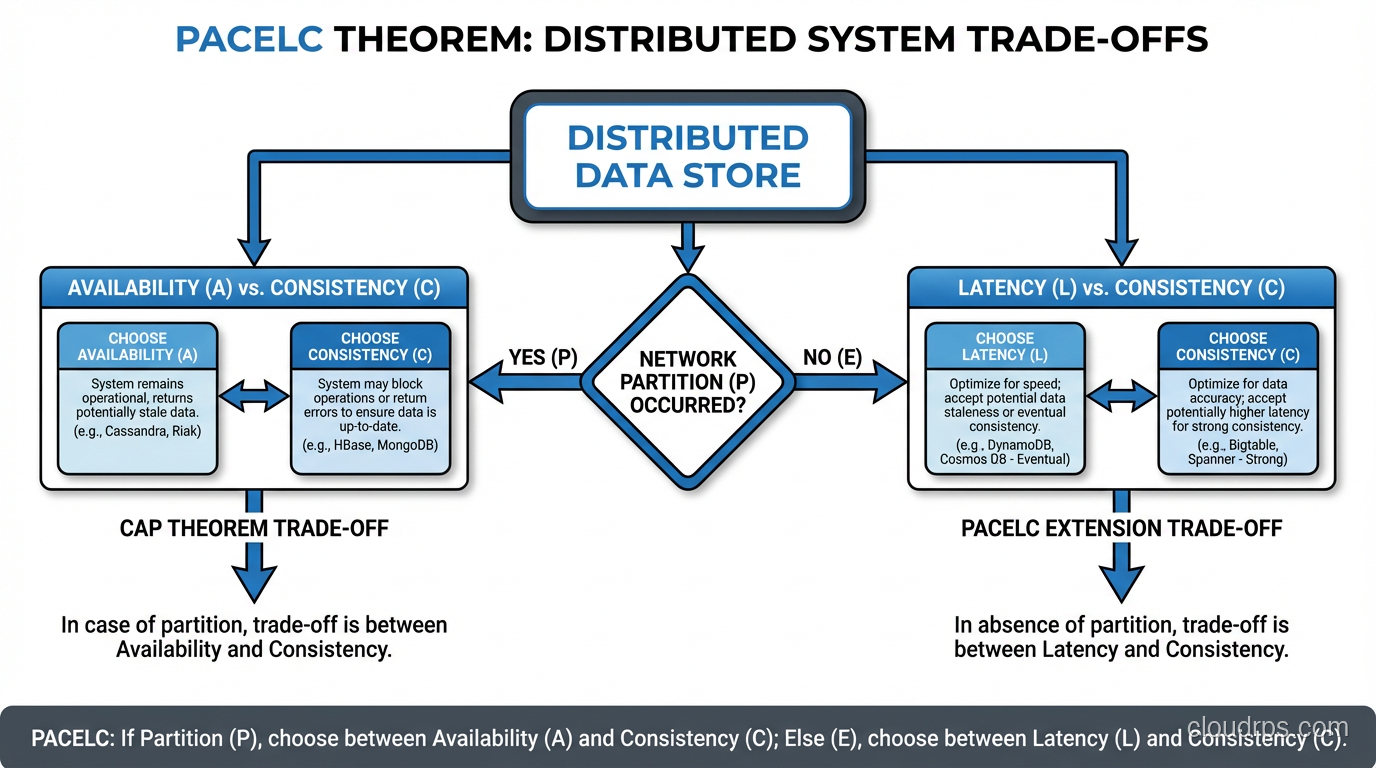
The PACELC Model
Daniel Abadi proposed an extension called PACELC that I find much more useful than raw CAP. It says: during a Partition, choose between Availability and Consistency; Else (during normal operation), choose between Latency and Consistency.
This captures an important reality: even without partitions, there is a trade-off between consistency and latency in distributed systems. Achieving strong consistency requires coordination between nodes (consensus protocols, distributed locks), which adds latency. Relaxing consistency eliminates that coordination, reducing latency.
A system like Spanner is PA/EC: during partitions, it prioritizes Availability (within its Paxos groups); during normal operation, it prioritizes Consistency over Latency. Cassandra with weak consistency is PA/EL: it prioritizes Availability during partitions and Latency during normal operation.
How Real Databases Navigate CAP
Let me describe how some common databases handle the CAP trade-off, because the reality is more interesting than the textbook classifications.
PostgreSQL with Streaming Replication
A single PostgreSQL instance is not a distributed system, so CAP does not apply. With streaming replication to read replicas, you have an eventually consistent system where replicas lag behind the primary. If the primary fails and you promote a replica, you might lose recent transactions. This is essentially an AP behavior for reads (replicas are available but potentially stale) with CP behavior for writes (writes only go to the primary).
CockroachDB
CockroachDB is a CP system. It uses a Raft consensus protocol for replication. During a partition, the partition with the majority of replicas continues serving reads and writes. The minority partition becomes unavailable. This gives you strong consistency (it is even ACID-compliant with serializable isolation) at the cost of availability during partitions.
Cassandra
Cassandra is fundamentally an AP system, but with tunable consistency it can behave like a CP system for specific operations. At consistency level ONE, it is AP: any available replica can serve the request. At consistency level ALL, it is CP: all replicas must respond, and any unavailable replica means the request fails. QUORUM sits in between, providing strong consistency as long as a majority of replicas are available.
DynamoDB
DynamoDB is AP by default (eventually consistent reads) with an option for CP behavior (strongly consistent reads). The SQL vs NoSQL distinction matters here. DynamoDB is a NoSQL key-value and document store that chose availability as its default because most of its use cases prioritize responsiveness over perfect consistency.
Practical Advice From the Trenches
After twenty years of building distributed systems, here is what I tell teams when the CAP theorem comes up.
Do not start with CAP. Start with your requirements. What are the consequences of stale data? What are the consequences of unavailability? How frequently do partitions actually occur in your infrastructure? These practical questions matter more than theoretical classifications.
Default to consistency for data that has financial, legal, or safety implications. The cost of inconsistency in these domains is almost always higher than the cost of brief unavailability.
Default to availability for data where staleness is tolerable. User profiles, social feeds, product catalogs, metrics, logs: all of these can tolerate seconds or even minutes of staleness without meaningful business impact.
Do not over-distribute. A single well-provisioned database server avoids the CAP trade-off entirely. Distribute data across multiple nodes only when you have a genuine need: scale, geographic distribution, or high availability requirements that a single node cannot meet. Every node you add brings you further into CAP territory.
Test your partition behavior. Use network partition injection tools (like Jepsen, or simply iptables rules) to simulate partitions and observe how your system actually behaves. I have found production systems that were supposed to be CP but actually lost data during partitions because of configuration errors. Trust but verify.
The Theorem Is a Compass, Not a Map
The CAP theorem tells you that trade-offs exist. It does not tell you which trade-off to make, and it does not capture the full complexity of distributed system design. Latency, durability, throughput, operational complexity, and cost all matter alongside consistency and availability.
Use CAP as a starting point for understanding the fundamental constraints of distributed data. Then go deeper into the specific consistency models, failure modes, and recovery mechanisms of whatever database you are evaluating. The theorem gives you the vocabulary. Experience gives you the judgment.
And if anyone ever tells you their database “beats the CAP theorem,” smile politely and walk away. Physics does not negotiate.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.