I spent three years fighting the polling problem before I finally gave up and embraced Change Data Capture. The polling problem is this: you have a source database and a destination system, and you need to keep them in sync. So you write a job that runs every five minutes, queries for rows where updated_at > last_run_time, and pushes those changes downstream. It works until it doesn’t. Then you have missed deletes, rows without update timestamps, race conditions during the query window, and a growing gap between what your upstream database actually contains and what everything downstream thinks it contains.
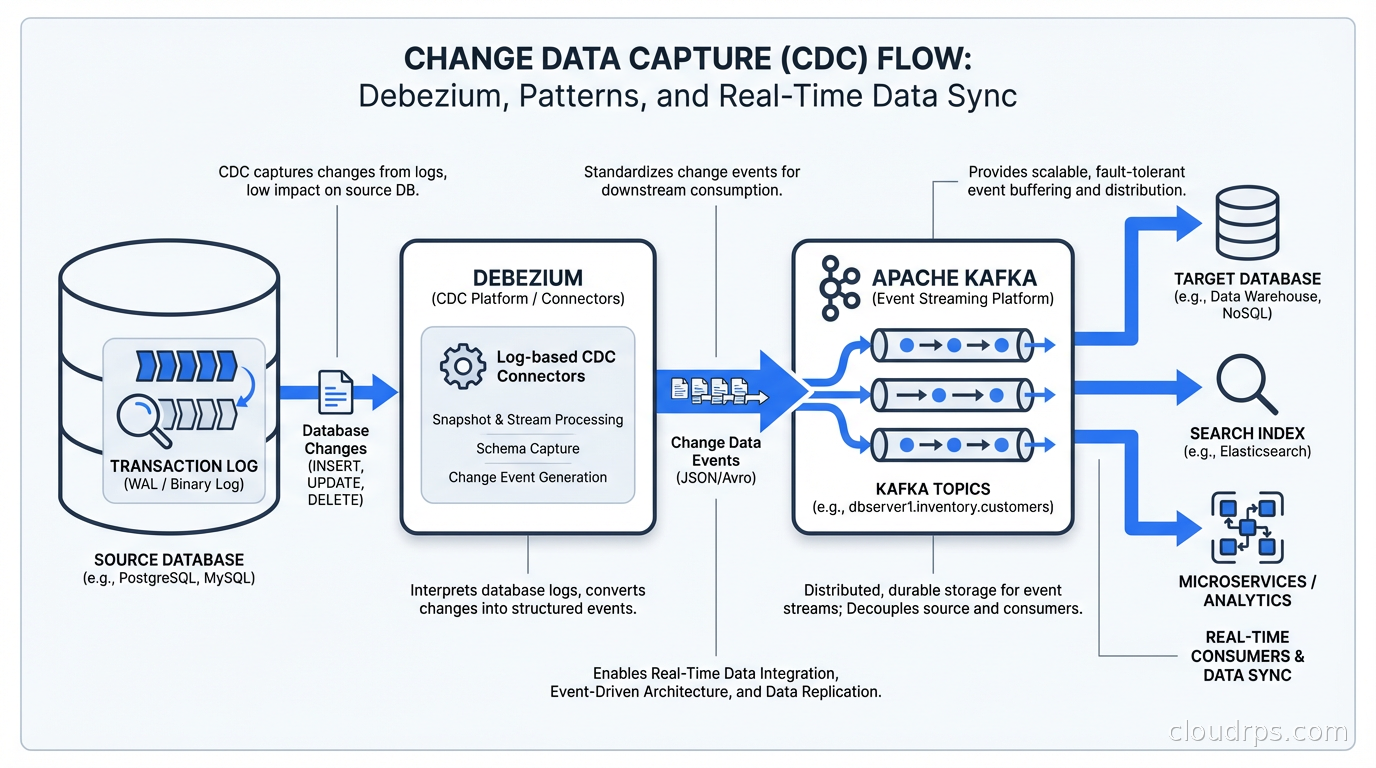
CDC is the fix. Instead of asking the database “what changed?”, you listen to the database’s own record of what changed: the transaction log. Every modern database keeps a log of every write operation for crash recovery and replication. CDC taps into that log and turns it into a stream of events your entire platform can consume. It’s not a new idea, but the tooling around it has matured enormously over the last few years, and in 2026 it’s table stakes for any serious data platform.
How CDC Actually Works
Every transactional database maintains a write-ahead log (WAL in PostgreSQL, binlog in MySQL, redo log in Oracle). Before any change is committed to the data files, the database writes it to this log. If the database crashes, it replays the log to recover. For replication, the primary streams these log entries to replicas. CDC tools read the same log, just as consumers rather than replicas.
When you insert a row, the WAL entry contains the table name, the operation type (INSERT), and the full row data. For an UPDATE, you get the before and after images. For DELETE, you get the deleted row. This is far richer than what you’d get from polling: you can see the exact sequence of every change, you can detect deletes without tombstone columns, and you get the change at the moment it happened rather than five minutes later.
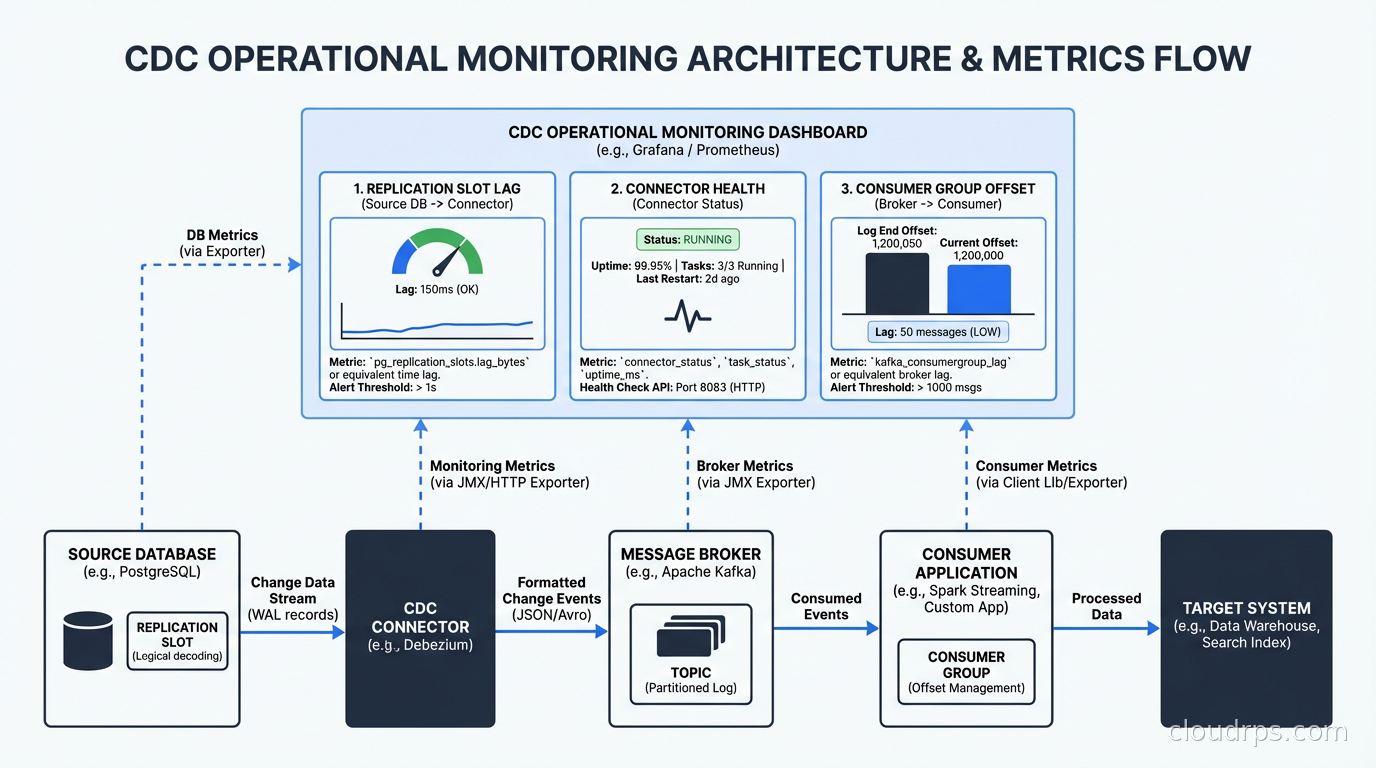
The core technical challenge is what happens to the log over time. Databases purge old log entries to reclaim disk space. A CDC consumer that falls behind risks losing events before it reads them. This is why CDC connectors maintain their position in the log (called an offset or LSN in PostgreSQL terminology) and why you need to configure log retention appropriately on your source database.
There’s also the initial snapshot problem. When you first set up CDC, your destination doesn’t have any existing data. You need to take a consistent snapshot of the source table first, then switch to streaming incremental changes. This snapshot-plus-streaming approach requires careful coordination to avoid gaps or duplicates at the transition point.
Debezium: The Open-Source CDC Standard
Debezium is the most widely adopted open-source CDC framework. It runs as a set of Kafka Connect connectors and supports PostgreSQL, MySQL, MongoDB, Oracle, SQL Server, and more. I’ve used it in production for PostgreSQL and MySQL pipelines, and it’s genuinely solid once you understand its operational model.
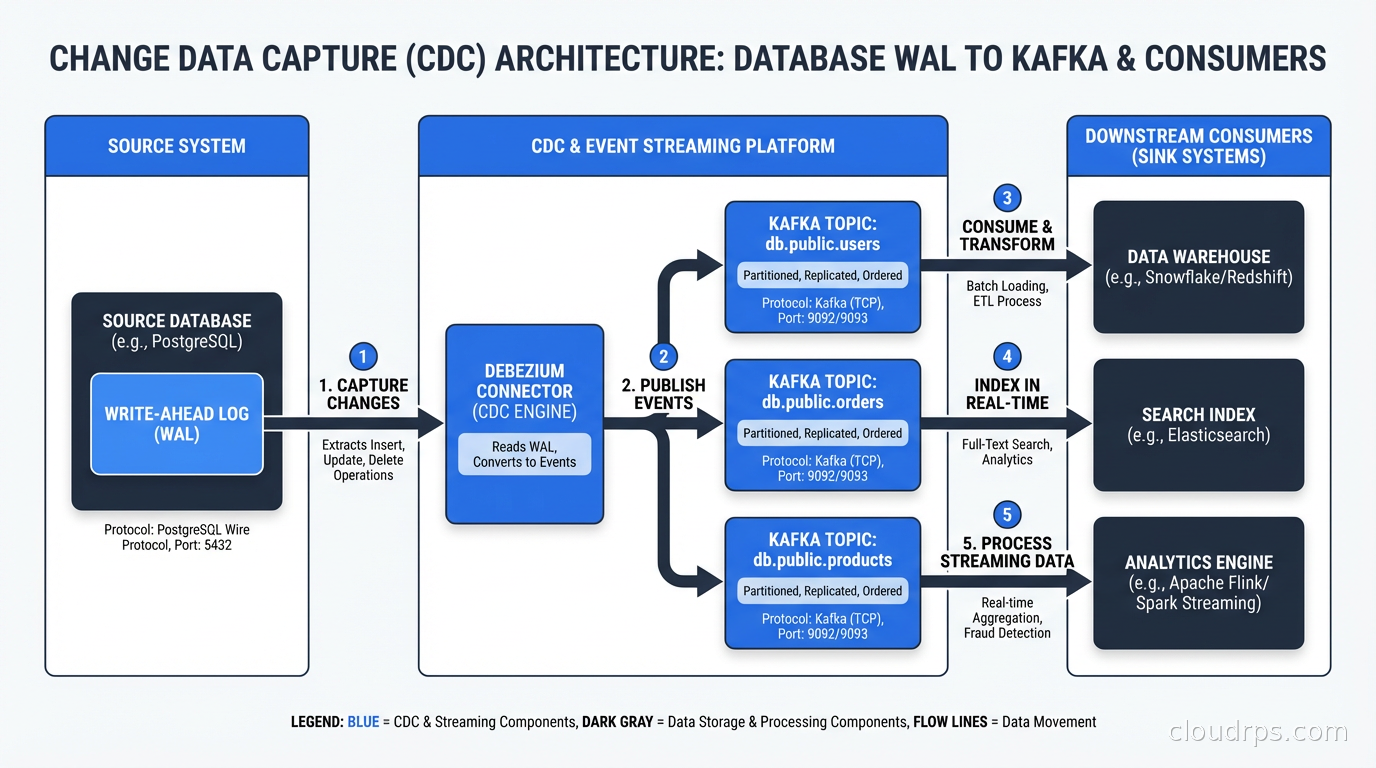
Debezium works by deploying a connector that connects to your source database, reads the transaction log, and publishes events to Kafka topics. By default, one topic per table. Each event is a JSON or Avro envelope containing the operation type, the before and after state, and metadata including the source database, table, timestamp, and transaction ID.
Setting up Debezium for PostgreSQL requires a few steps. First, you need to configure your database to use logical replication with the pgoutput or wal2json plugin. This means setting wal_level = logical in your PostgreSQL config and creating a replication slot:
SELECT pg_create_logical_replication_slot('debezium', 'pgoutput');
Then you deploy a Kafka Connect worker with the Debezium PostgreSQL connector JAR, and configure the connector:
{
"name": "postgres-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "your-db-host",
"database.port": "5432",
"database.user": "debezium",
"database.password": "secret",
"database.dbname": "your-database",
"database.server.name": "myserver",
"table.include.list": "public.orders,public.customers",
"plugin.name": "pgoutput",
"slot.name": "debezium"
}
}
The connector will first snapshot existing data (reading all rows and publishing them as INSERT events), then switch to streaming from the replication slot.
One gotcha I hit early on: Debezium creates a replication slot that holds the WAL in place while it’s active. If your connector goes down for days, PostgreSQL will keep accumulating WAL until Debezium catches up. I’ve seen this fill disk on production databases. You need to monitor replication slot lag and set max_slot_wal_keep_size to prevent runaway disk usage.
The Kafka Connect Ecosystem
Debezium is designed to run as Kafka Connect source connectors, which means your CDC events flow into Kafka and you consume them from there. This is a great design because Kafka provides durable event storage, consumer group semantics, and a massive ecosystem of sink connectors for every destination you can imagine.
This fits naturally with the stream processing patterns I covered in our stream processing guide. Once your CDC events are in Kafka, you can enrich them with Flink, aggregate them, join them with other event streams, or route them to multiple destinations simultaneously.
Kafka Connect sink connectors let you write to Elasticsearch, BigQuery, Snowflake, S3, PostgreSQL replicas, Redis caches, and more, all from the same Kafka topic. This fan-out capability is one of the biggest wins from CDC: you publish changes once and consume them many ways. Your analytics warehouse gets updates, your search index gets updates, your cache gets invalidated, all from a single stream of events.
The schema registry piece matters too. Debezium can serialize events as Avro with schemas registered in Confluent Schema Registry or the Apicurio equivalent. This means downstream consumers get strongly-typed events and schema evolution is handled consistently. When you add a column to a source table, the schema in the registry updates, and consumers that care about that field can pick it up automatically.
Alternatives to Debezium
Debezium isn’t the only option, and it’s not always the right one.
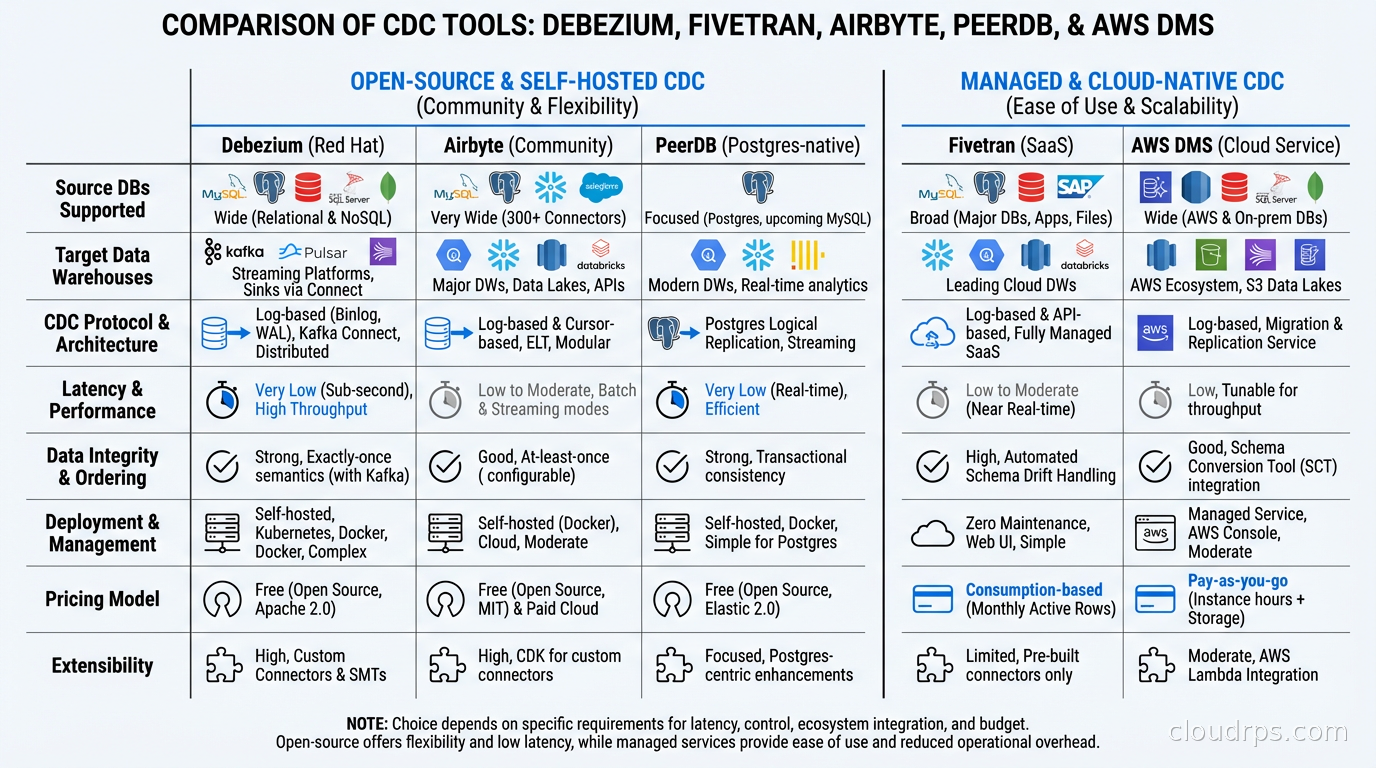
Fivetran and Airbyte offer managed or self-hosted CDC connectors that handle the operational complexity for you. You configure your source credentials, pick your destination, and they manage the connectors, offsets, and schema mapping. The tradeoff is cost (Fivetran’s pricing can get painful at scale) and reduced flexibility (you get the destinations they support, with their transformation model). For teams that don’t want to operate Kafka Connect clusters, these managed options make a lot of sense.
PeerDB is a newer open-source CDC tool focused specifically on PostgreSQL to PostgreSQL (and some other destinations). It recently achieved 16x faster replication than the traditional logical replication approach by using custom binary wire protocol optimizations. Worth watching if your use case is primarily Postgres.
AWS Database Migration Service (DMS) offers CDC for databases running in or migrating to AWS. It’s not as flexible as Debezium but it’s fully managed and integrates well with the rest of the AWS ecosystem. I’ve used it for large-scale migrations and it’s reliable for that use case.
Oracle GoldenGate and IBM InfoSphere DataStage are the legacy enterprise options. They’re expensive, complex, and mostly exist in organizations that haven’t moved on yet. If you’re in that situation and need to integrate CDC data with your data mesh architecture, Debezium or a managed service is almost certainly a better path forward.
CDC Patterns and Use Cases
CDC enables several architectural patterns that are difficult or impossible to implement cleanly with polling.
Event sourcing integration. Your application writes to a regular database, and CDC turns those writes into events automatically. This is sometimes called “outbox pattern via CDC.” Instead of having your application explicitly publish to a message queue (which creates dual-write problems), you write to a database outbox table and let CDC pick it up. The database write and the event publication are atomic.
Cache invalidation. Cache invalidation is famously one of the hardest problems in computer science, but CDC makes it tractable. When a row changes in your database, the CDC event triggers cache invalidation for that specific key. No more TTL-based staleness or manual cache-busting logic in your application code. This integrates nicely with a Redis caching layer that sits in front of your primary database.
Search index synchronization. Keeping Elasticsearch or OpenSearch in sync with your source database is a classic CDC use case. Traditional approaches involve writing to both the database and the search index simultaneously (fragile) or running periodic full re-indexing jobs (slow and resource-intensive). CDC lets you push incremental changes to the search index as they happen.
Analytics and data warehouse updates. Instead of running overnight ETL jobs, CDC enables near-real-time data warehouse updates. Your analytics team gets fresher data and your ETL jobs are smaller and faster because they only process what actually changed. This is a major factor in the data observability story: fresher data means you detect anomalies sooner.
Database migration with zero downtime. CDC is the standard technique for live database migrations. You set up CDC from the old database, sync changes to the new database, and when the lag drops to near-zero, you cut over. I’ve done this to migrate from MySQL to PostgreSQL and from single-region to multi-region setups, and it works well when you respect the operational details.
Operational Challenges You Will Hit
Let me be honest about the operational complexity, because it’s real.
Schema changes are the main headache. When you add a column to a source table, Debezium handles it automatically. When you drop a column or rename one, things get complicated. Downstream consumers that expect the old schema will break. You need a schema evolution strategy before you go to production: either strict compatibility enforcement through the schema registry, or a transformation layer that absorbs schema changes before exposing events to consumers.
High-cardinality tables generate enormous event volumes. A table with millions of writes per day generates millions of CDC events. Kafka handles this fine, but your consumers need to be able to keep up. I’ve seen downstream Kafka consumers become the bottleneck, not the CDC connector itself. Profile your consumers under realistic load before going live.
The initial snapshot can be disruptive. Snapshotting a 10TB table takes time and puts load on your source database. Use snapshot modes that minimize impact (initial_only, exported, or never if you’re okay with not backfilling history). Schedule snapshots during low-traffic windows and monitor database CPU and I/O during the process.
Exactly-once delivery is hard. Debezium gives you at-least-once delivery by default. Your consumers need to be idempotent, or you need to implement deduplication. This is especially important for systems like analytics databases where duplicate events create incorrect aggregates. The database replication challenge around consistency applies here too.
Monitoring matters. You need alerts on replication lag (how far behind is the connector), consumer group lag (how far behind are your consumers), and connector health. The Debezium connector status API and JMX metrics are your friends here. Wire them into your existing monitoring and alerting setup.
When to Use CDC vs. When Not To
CDC is not always the right tool. Here’s my honest framework:
Use CDC when you need real-time or near-real-time data sync between systems, when you need to capture deletes, when you’re syncing to multiple destinations from one source, or when you’re implementing event-driven patterns on top of an existing relational database.
Don’t use CDC when a daily batch job is genuinely sufficient, when your source database doesn’t support logical replication (some hosted database services restrict it), when you only have a few thousand rows changing per day (polling is simpler), or when your team doesn’t have the operational bandwidth to manage Kafka and connector infrastructure.
For many teams, the right progression is: start with polling-based ETL, hit its limitations (usually missing deletes or data freshness requirements), then graduate to CDC. By the time you need CDC, you usually know why you need it.
The data lake architecture question matters here too. If your destination is a data lake on S3 or GCS, CDC events land as small files that can compound your small-file problem in Parquet format. Use Hudi, Delta Lake, or Iceberg as your storage layer to get merge-on-read semantics and automatic compaction.
The Production Setup I Actually Recommend
For a production CDC setup based on my experience: run Debezium connectors in Kafka Connect distributed mode with at least three workers for fault tolerance. Use Avro serialization with a schema registry. Set a connector heartbeat interval so you can monitor lag even during quiet periods. Configure max.queue.size and max.batch.size based on your table write rates. Put your Kafka topics on a longer retention (at least 7 days) for the CDC topics so consumers can catch up after an outage.
For PostgreSQL specifically: create a dedicated replication user with minimal permissions, use pgoutput instead of wal2json (it’s the native plugin, more reliable), and monitor your replication slot lag with a query against pg_replication_slots. Set wal_sender_timeout appropriately to detect stale connections.
This setup has served me well across multiple production deployments. The learning curve is real, but once it’s running, CDC is remarkably stable. It’s boring infrastructure in the best possible way: it just continuously streams your database changes without drama.
CDC has become the connective tissue of modern data platforms. If you’re building anything that requires multiple systems to stay in sync with a primary database, it’s worth understanding deeply and deploying carefully. The days of polling-based data sync should be behind you.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.