Three years ago I got a call from a team that had been live on AWS for ninety days. Their compute bill was $18k. Their storage was $4k. Their data transfer line item was $71,000.
Nobody on the team had budgeted for it. Nobody even knew what was generating it. When I dug in, the culprits were embarrassingly mundane: a logging sidecar that shipped structured logs from every container across availability zones to a centralized Elasticsearch cluster every fifteen seconds, a Kubernetes cluster with zero AZ-aware scheduling so every service call crossed zone boundaries as often as not, and an analytics pipeline that pulled raw event data from S3 in us-east-1 into a processing cluster in us-west-2 for no particular reason other than that it was where a developer had originally experimented.
Each of those three issues was fixable. Together they cost $852,000 a year. That is the cloud egress problem in a nutshell: it is invisible until it is catastrophic, and it is almost entirely architectural.
How Cloud Egress Pricing Actually Works
Before you can fix it you need to understand the pricing model, because it is more nuanced than most people realize. The major cloud providers all use layered pricing with roughly the same structure.
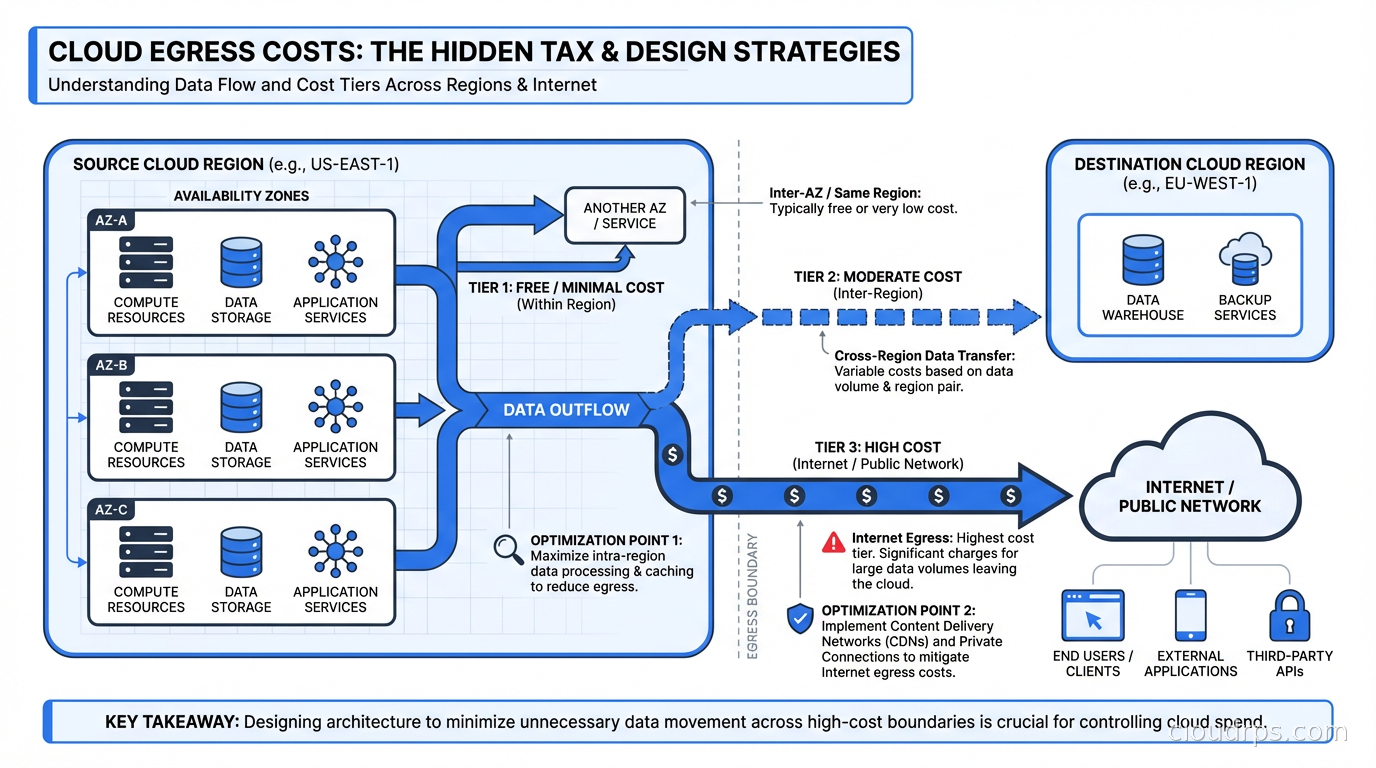
Same-AZ traffic within a VPC: Free. AWS, GCP, and Azure all charge nothing for traffic between resources in the same availability zone inside the same VPC.
Cross-AZ traffic within a region: Not free. AWS charges $0.01/GB in each direction, so a round-trip request-response costs $0.02/GB. GCP charges similar rates. Azure is slightly different but comparable. This sounds trivial until you run the math on a busy microservices cluster doing millions of calls per hour.
Cross-region traffic: More expensive. AWS charges $0.02/GB between regions in the same continent, up to $0.09/GB for inter-continental transfers.
Internet egress: AWS charges $0.09/GB for the first 10TB per month, with tiered discounts at higher volumes. GCP charges $0.08/GB. Azure is similar. For context: Scaleway charges nothing for internet egress, and Hetzner includes 20 TB free per server per month. That gap is one reason teams are moving egress-heavy workloads to European cloud providers like Hetzner and Scaleway rather than optimizing within hyperscaler pricing.
NAT Gateway processing: On AWS, every byte that passes through a NAT Gateway costs an additional $0.045/GB for processing, on top of whatever the destination transfer cost is. This is the hidden multiplier that catches teams off guard.
Exceptions and free paths: This is where knowledge pays off. S3 to Lambda in the same region is free. S3 to CloudFront is free. EC2 to S3 within the same region using a VPC Gateway Endpoint is free. Many managed AWS services have similar free-transfer paths that most engineers never learn because they are buried in pricing documentation.
The real problem is that “data transfer” shows up as a single line in your monthly bill. You might see $47,000 and have no idea whether it is cross-AZ chatter, NAT Gateway overhead, cross-region replication, or internet egress. Without attribution, you cannot fix anything.
The Four Patterns That Create Catastrophic Bills
In my experience auditing cloud architectures, the same patterns appear over and over as egress cost generators.
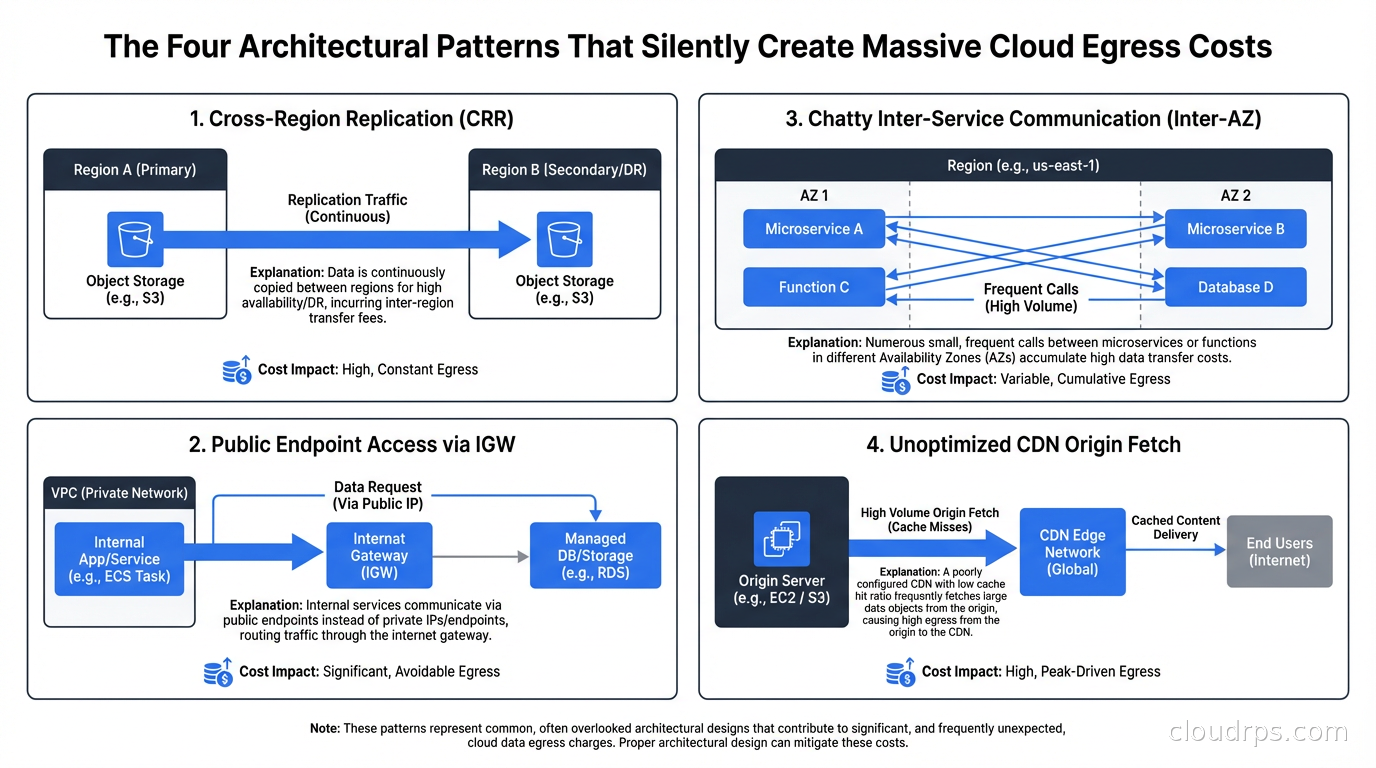
Pattern One: AZ-Unaware Microservices
Kubernetes by default does not guarantee that service-to-service traffic stays within an availability zone. If Service A has three replicas spread across three AZs and Service B also has replicas across three AZs, a request from Service A pod in AZ-a might be routed to Service B pod in AZ-b or AZ-c. With a default round-robin load balancing policy, roughly two thirds of your inter-service calls cross an AZ boundary.
At 1000 requests per second with a 10KB average payload size, that is roughly 5.7GB of cross-AZ traffic per hour per service pair. With 20 service pairs, you have 114GB/hour or about 81TB/month. At $0.01/GB each direction, that is $1,620/month in cross-AZ charges from a system that is otherwise correctly designed.
The fix requires two things: topology spread constraints to prefer same-AZ scheduling, and locality-aware load balancing in your service mesh (Istio’s locality load balancing directs traffic to same-AZ endpoints first, with cross-AZ fallback only when local endpoints are unhealthy). You can also configure Kubernetes CNI plugins and network policies to support topology-aware routing at the cluster level.
Pattern Two: NAT Gateway Abuse
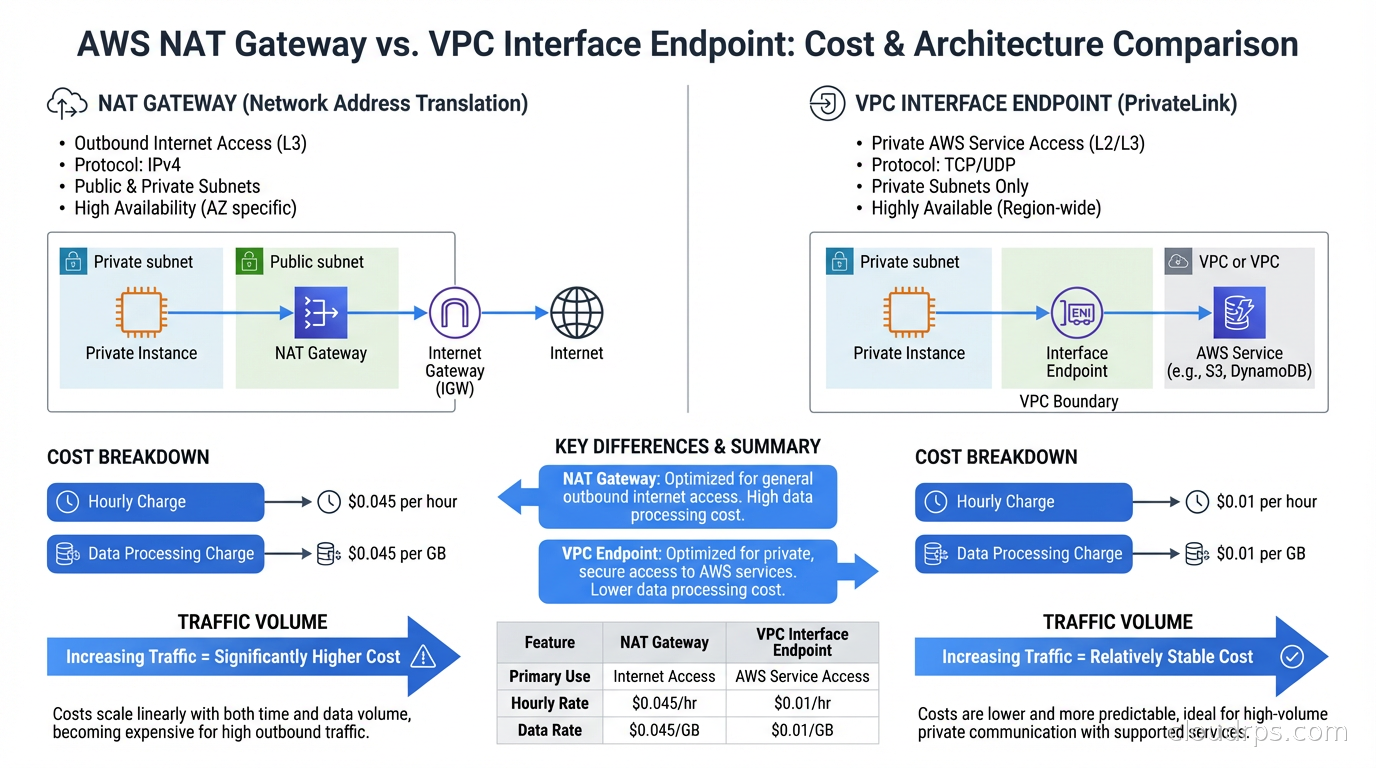
This one is specific to AWS but significant. Teams put a NAT Gateway in each AZ for high availability, which is correct. Then they route all outbound traffic through it, including calls to AWS services like S3, DynamoDB, SQS, Kinesis, ECR, CloudWatch, Secrets Manager, and SSM.
All of those services support VPC endpoints. A VPC Gateway Endpoint for S3 and DynamoDB is free. VPC Interface Endpoints for other services cost $0.01/AZ/hour (about $7.30/month per AZ), but they eliminate NAT Gateway processing fees for that traffic. VPC endpoint strategy is one component of a broader VPC connectivity architecture decision; for the full picture of how VPC Peering, Transit Gateway, PrivateLink, and VPC Lattice fit together, see the AWS VPC connectivity guide.
The break-even calculation: at $0.045/GB for NAT processing, an Interface Endpoint in three AZs ($21.90/month) pays for itself at 487GB of monthly traffic to that service. Most teams using ECR at scale pull many terabytes of container images monthly. Switching ECR to a VPC Interface Endpoint typically saves thousands of dollars per month.
I keep a spreadsheet with breakeven volumes for each VPC endpoint type. It is the first thing I pull up during cost optimization engagements.
Pattern Three: The Centralized Logging Drain
Every container ships logs to a central aggregator. That aggregator lives in a specific AZ. If your logging architecture is a push model where agents on every node ship to a central endpoint, and that endpoint happens to be in a different AZ than half your nodes, you are paying cross-AZ rates on every log line.
The fix is a two-tier architecture: local aggregation on each node (or per-AZ) with a node-local log agent like Fluent Bit that buffers and batches, then ships compressed batches to the central store. This collapses thousands of small cross-AZ TCP connections into occasional large compressed transfers. At the same data volume, compressed batch shipping costs a tenth of what chatty real-time shipping costs.
Pattern Four: Cross-Region Analytics Pipelines
This is the pattern from my opening story. Teams build a data pipeline where the source of truth lives in one region and the analytics compute lives in another because that is where a developer happened to prototype it. The daily transfer of raw events from us-east-1 to us-west-2 at $0.02/GB can cost more than the compute doing the actual analysis.
The fix is data gravity: compute should live where the data lives. When you cannot move the data, compress aggressively before transferring and batch transfers to reduce per-transfer overhead. For ongoing change data capture streams across regions, compression typically reduces transfer volumes by 70-90%.
The NAT Gateway Math Nobody Does Upfront
I want to give you the actual numbers because until you see them concretely it is hard to prioritize this work.
A typical multi-service application on EKS with ECR for container images, S3 for assets, DynamoDB for some data, and SQS for job queues might generate:
- ECR image pulls: 5TB/month (pulling fresh images on scaling events and deployments)
- S3 reads from Lambda and EC2: 10TB/month
- DynamoDB: 2TB/month
- SQS: 500GB/month
Routing all of that through NAT Gateway at $0.045/GB processing adds up to $787.50/month in processing fees alone, on top of whatever the NAT Gateway hourly charges are ($0.045/AZ/hour, about $99/month for three AZs).
Switch to VPC endpoints. The S3 and DynamoDB Gateway Endpoints are free. Interface Endpoints for ECR, SQS, and others at $0.01/AZ/hour for three AZs: three endpoints at $21.90/month each equals $65.70/month.
You go from $886.50/month to $65.70/month. Annual savings: almost $10,000, just from enabling VPC endpoints for services you are already using.
Now scale that to a team running dozens of services and the savings are substantial. The FinOps practice of tagging and attribution reveals these patterns, but the architectural fix is what actually changes the number.
Cross-Region and Multi-Cloud: Where It Gets Brutal
Cross-region replication is often necessary for disaster recovery and global distribution. The question is whether you are doing it efficiently.
A busy PostgreSQL database with active write workloads generates a WAL stream that can easily be 50-200GB per day. Replicating that across regions at $0.02/GB for cross-region transfer costs $1-4/day or $30-120/month. That sounds manageable until you factor in that the WAL stream is uncompressed and often contains a lot of relatively compressible data like JSON, repeated column names, and structured records. Compressing before transfer with zstd at a 5:1 ratio reduces that to $6-24/month. Over a three-year period, that compression optimization saves $2,000-3,456.
Multi-cloud is where egress costs become genuinely dangerous for budgets. I have reviewed architectures where a team decided to put their ML training on GCP for the TPUs while their primary infrastructure ran on AWS. Every byte of training data that had to move from AWS S3 to GCP paid internet egress rates on both ends. Depending on the architecture, you can pay AWS egress rates to send data out of AWS and GCP ingress rates to receive it, plus whatever the actual transfer bandwidth costs. At scale, this can cost more than the training compute itself.
The multi-cloud strategy guide covers the broader tradeoffs, but from a pure egress cost perspective, the rule is: data that needs to be processed together should live together. If you must span clouds, use a private backbone (Megaport, Equinix Fabric) to connect them rather than routing over the public internet. The circuit cost is predictable; per-GB internet egress is not. The dedicated cloud interconnects guide walks through how AWS Direct Connect, Azure ExpressRoute, and Google Cloud Interconnect work, including the egress pricing differences that make them worth the port fee for high-volume workloads.
CDN as an Egress Cost Reduction Tool
Most engineers think of CDNs as performance tools. They are also cost tools.
On AWS, data transfer from EC2 or S3 to CloudFront origin is charged at standard inter-region rates, but CloudFront to the internet is cheaper than direct EC2 internet egress at high volumes. More importantly, cached content served from a CloudFront edge does not generate any origin traffic at all. For a web application where a significant fraction of requests are for cacheable assets, moving those to CloudFront and tuning cache lifetimes can cut origin egress by 60-80%.
For S3-hosted content, the math is even simpler. S3 to CloudFront is free. CloudFront to the internet is $0.085/GB for the first 10TB, dropping to $0.08/GB above that. Compared to S3 direct internet egress at $0.09/GB, plus the performance benefits of edge caching, using a CDN is almost always the right call for user-facing content.
Zero-egress object storage providers like Cloudflare R2 push this even further. If your primary use case is serving static assets or user-uploaded content to end users over the internet, R2’s zero-egress pricing changes the economics entirely. The tradeoff is less ecosystem integration and fewer advanced features compared to S3, but for pure read-heavy workloads, the savings can be 80-90% compared to S3 internet egress. For teams running their own compute infrastructure or already doing cloud repatriation, self-hosted S3-compatible object storage is the logical next step: co-locate storage with compute and eliminate cloud egress on that data entirely.
Monitoring and Attribution: You Can’t Fix What You Can’t See
The first step in any egress cost reduction project is attribution. Without knowing which services, teams, and traffic patterns are generating costs, you are guessing at fixes.
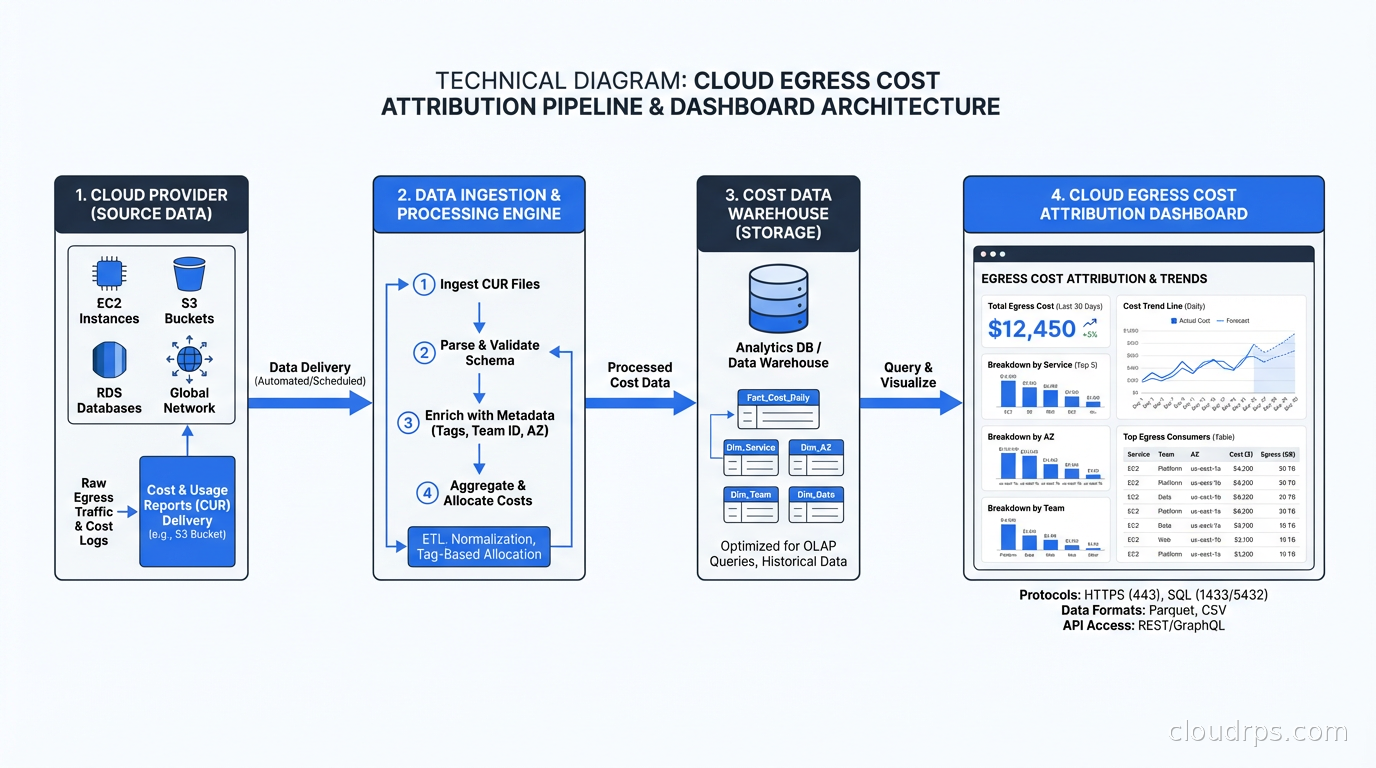
VPC Flow Logs plus Athena is the baseline. Enable flow logs for your VPCs, ship them to S3 with a sensible prefix structure, and query them with Athena. You can identify which ENIs are generating the most cross-AZ traffic, which are generating the most internet egress, and which are hitting NAT Gateways the hardest. The queries are not complex; the value is enormous.
Cost allocation tags are mandatory. Every resource should have at minimum: environment (production, staging, dev), team, and service. AWS Cost Explorer lets you break down data transfer costs by tag. Without tags, your $47k data transfer line item has no attribution and no path to accountability.
Kubecost for Kubernetes environments. Kubecost instruments network traffic at the pod level and attributes egress costs to namespaces, deployments, and services. Combined with Karpenter’s topology-aware node provisioning, you can see which workloads are generating cross-AZ traffic and correlate with scheduling decisions.
Third-party tools like CloudZero and Infracost integrate with your cost data and can surface anomalies that raw Cost Explorer would not highlight. Anomaly detection on data transfer costs is particularly valuable because egress often grows gradually as traffic scales and can go unnoticed until the monthly bill arrives.
The attribution work is not glamorous. I have spent afternoons writing Athena queries against VPC flow logs trying to track down a rogue process generating 500GB/day of unexpected cross-AZ traffic. But finding it saved $4,200/month, which paid for that afternoon about 2,000 times over.
Data Sovereignty and Egress: The Compliance Trap
One underappreciated dimension of egress costs is regulatory compliance. GDPR requires that EU personal data stay within the EU. Similar requirements exist in dozens of countries. If your architecture was designed without data residency in mind, you can find yourself in a situation where the path to compliance involves significant data movement costs.
The cloud sovereignty guide covers the compliance side in depth. From an architectural perspective, the right answer is regional data isolation from the beginning: EU user data lives in EU regions, is processed in EU regions, and never crosses borders except in pre-aggregated, non-personal summary form. Retrofitting this onto an existing single-region architecture is expensive both in engineering time and in the temporary egress costs during migration.
Teams that get this right upfront use a federated data architecture: each region has its own data stores, its own processing pipelines, and its own caches. Cross-region data sharing is limited to pre-approved, anonymized aggregates. This avoids both compliance risk and the egress costs that come from constantly shuffling data across borders.
The Architectural Principles I Apply From Day One
After enough egress surprises, I added egress cost modeling as a required section in my architecture review process. Here is what I look for:
Collocate compute and data. Before approving any new service design, I ask: where does the data live, and where is the compute that processes it? If they are in different AZs without a strong technical reason, I push back.
Design for locality in Kubernetes. Topology spread constraints and pod affinity rules should guide workloads to the same AZ as the data they consume. Distributed caching with AZ-local replicas means cache hits never cross zone boundaries. A service mesh configured for locality-aware routing means internal RPC calls prefer same-AZ endpoints.
Use the free paths. Know which service-to-service transfers your cloud provider does not charge for, and design your hot paths to use them. S3 to Lambda, S3 to CloudFront, EC2 to managed database in same region via VPC endpoint: these are the paths that should carry your highest-volume traffic.
Compress at every boundary. Any inter-AZ or inter-region call with variable-size payloads should be compressed. Add this to your API contracts. Make it a standard middleware component in your internal frameworks so developers do not have to think about it individually.
Batch over stream for cross-region transfers. Real-time streaming of events from us-east-1 to eu-west-1 is expensive and often unnecessary. Batching events into five-minute or hourly files and shipping them once compresses the API call overhead and enables better compression ratios on the payloads.
Model the math in architecture reviews. “How many bytes will cross an AZ boundary per day?” should be a standard architecture review question, alongside questions about latency, availability, and data model. Teams that answer this question during design make fundamentally different choices than teams that discover the answer on their monthly bill.
Putting It Together: The Audit Playbook
When I walk into an egress cost reduction engagement, here is my process:
First, I enable or validate VPC Flow Logs and build the Athena queries to understand the traffic matrix: what is talking to what, across which boundaries, at what volume.
Second, I check NAT Gateway usage against the list of services that could use VPC endpoints instead. This is almost always the fastest win with the least risk.
Third, I look at cross-AZ traffic within Kubernetes clusters, specifically whether AZ-aware scheduling and locality routing are configured.
Fourth, I check cross-region data flows for compression, batching efficiency, and whether the data needs to be in multiple regions at all or whether a CDN or caching layer would serve the same purpose.
Fifth, I look at internet egress patterns: what is going to CloudFront, what is going direct from EC2 or Lambda, and whether the CDN cache hit ratio could be improved with better cache configuration.
In my experience, teams that have never done this audit typically find 40-60% cost reduction opportunities. The engineering effort to implement the fixes is usually two to four weeks for a focused team. The payback period is measured in months.
Egress is not a FinOps problem you solve by negotiating a discount with your cloud provider. It is an architecture problem you solve by designing systems that move data efficiently. The engineers who understand this build systems that scale without their data transfer costs scaling proportionally. The ones who learn it the hard way, well, I tend to get a call about ninety days after launch.
The good news is that every pattern I have described is fixable. The fixes are not exotic engineering; they are table stakes for running infrastructure at scale. Build the attribution, find the patterns, apply the fixes, and put egress cost modeling into your architecture review process so the next system starts from a better baseline.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.