Migrating ten applications to the cloud is a project. Migrating a thousand applications is an industrial operation. The difference isn’t just scale. It’s a fundamentally different organizational model, with different tooling, different roles, and different metrics.
I learned this distinction the hard way. On my first large-scale migration (400 applications for an insurance company), we started with a project-based approach. A small team would take on each application, figure out the approach, build the runbook, execute the migration, and move on. It worked fine for the first 20 applications. By application 50, we were drowning. The team couldn’t context-switch fast enough, every migration felt like the first one, and our velocity was declining instead of increasing.
That’s when we built a migration factory, and the pace changed overnight. We went from 4 applications per month to 40 applications per month within a single quarter. The factory model transformed migration from artisanal craftsmanship into a repeatable industrial process.
What a Migration Factory Is
A migration factory is an operating model for executing cloud migrations at scale. It standardizes the migration process into stages, assigns specialized roles to each stage, automates repetitive tasks, and measures throughput continuously.
Think of it like a manufacturing assembly line. In a car factory, you don’t have one person build an entire car from chassis to paint. You have specialized stations (welding, assembly, electrical, paint, quality) and the car moves through each station. Each station does one thing repeatedly and gets very good at it.
A migration factory works the same way. Applications move through a pipeline of stages, each staffed by specialists who execute their piece quickly and hand off to the next stage.
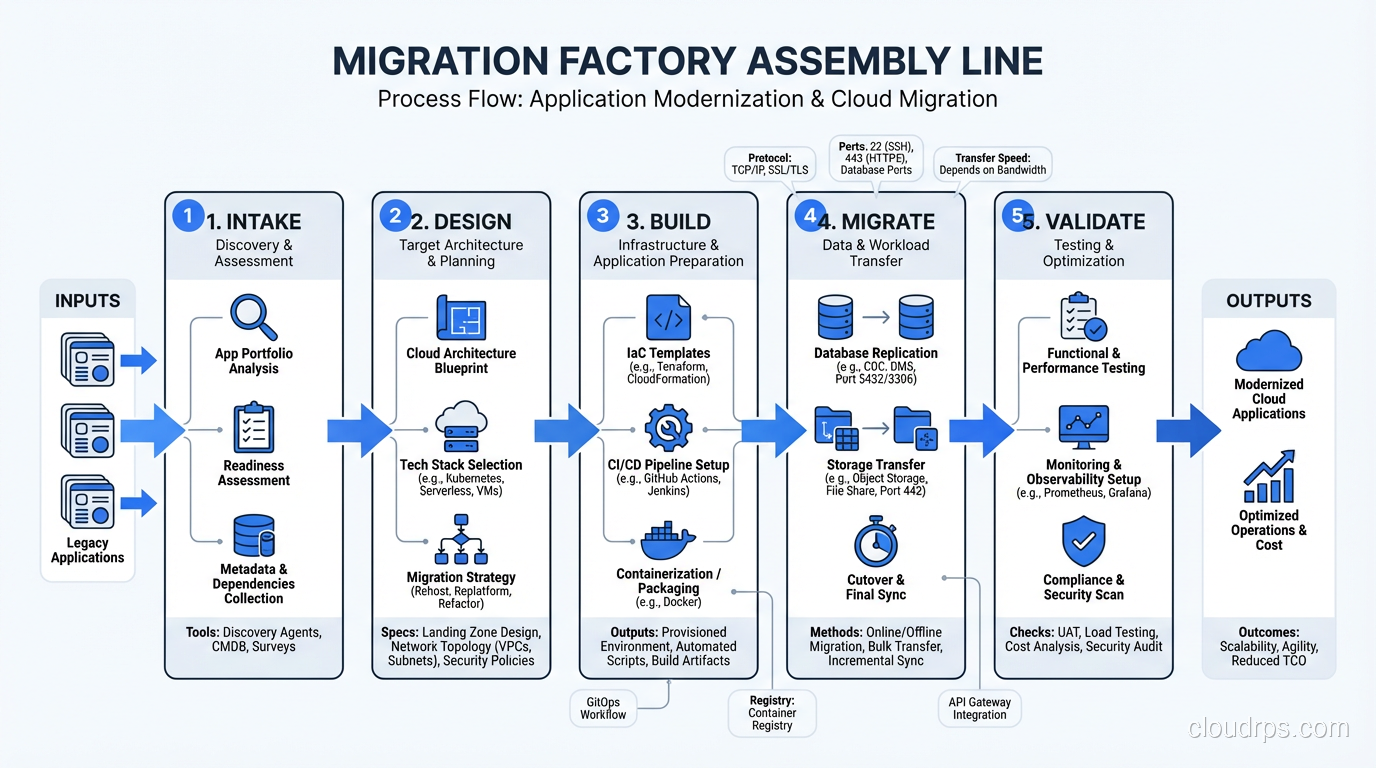
The Factory Stages
Based on the cloud migration process framework, here’s how the factory stages typically break down.
Stage 1: Intake and Assessment
A small team (2-3 people) receives application migration requests, validates the application inventory data, interviews application owners, and classifies each application using the 7 Rs framework.
This stage produces a Migration Design Document for each application, a standardized template that captures the migration approach, target architecture, dependencies, cutover requirements, and rollback plan.
Throughput target: 15-25 applications assessed per week, depending on complexity.
Stage 2: Design and Planning
Migration architects take the assessment output and produce detailed technical designs. This includes the target infrastructure specification (instance types, storage, networking), database migration approach, cutover procedure, testing plan, and dependency management strategy.
For rehost migrations, this stage is lightweight, often a half-day per application. For replatform or refactor, it can take a week per application.
Throughput target: 10-20 designs per week.
Stage 3: Build and Configure
The build team provisions the target infrastructure, configures networking, sets up monitoring, and prepares the replication tooling. In a mature factory, 80% of this is automated through Infrastructure as Code (Terraform, CloudFormation) and standardized templates.
This is where automation makes the biggest difference. If every rehost migration requires manually clicking through the AWS console, you’ll never reach factory velocity. Every common pattern needs a template.
Throughput target: 10-15 environments built per week.
Stage 4: Migration Execution
The migration team executes the actual move: starting replication, monitoring sync status, coordinating the cutover window with application owners, executing the cutover, and performing smoke tests.
This team needs to be laser-focused on execution. They don’t design, they don’t troubleshoot application issues, they don’t negotiate cutover windows. They execute migration runbooks.
Throughput target: 5-15 cutovers per week (this is the bottleneck, because cutovers require maintenance windows and business approval).
Stage 5: Validation and Handoff
After cutover, a validation team runs the full test suite: functional tests, performance tests, integration tests, security scans. They verify monitoring is working, alerts are firing correctly, and the application meets its SLA.
Once validated, the application is handed back to the application team, who takes operational ownership in the cloud.
Throughput target: Match migration execution throughput.
Stage 6: Decommission
The final stage: decommissioning on-premises resources after the retention period (typically 2-4 weeks of parallel running). This stage also handles license reclamation and updates the CMDB.
Don’t skip this stage. I’ve seen organizations continue paying for on-premises infrastructure months after migration because nobody formally decommissioned the old servers.
Factory Roles
The factory model requires specialized roles that don’t exist in traditional IT:
Migration Program Manager: Owns the overall factory throughput, manages the pipeline, removes blockers, and reports status to leadership.
Migration Architect: Designs the target architecture for each application. Needs deep cloud expertise and the ability to make quick, pragmatic decisions.
Migration Engineer: Executes the build, replication, and cutover. Needs strong operational skills and comfort with migration tooling.
Application SME (from the application team): Provides application-specific knowledge, validates functionality post-migration, and participates in the cutover. This is a part-time role; they don’t join the factory permanently.
Cloud Foundation Engineer: Maintains the landing zone, account vending, networking, and shared infrastructure. This role supports the factory but isn’t part of it.
The staffing ratio depends on your throughput target. For migrating 30-40 applications per month, I typically staff: 1 program manager, 2-3 architects, 4-6 engineers, and engage application SMEs on a rotating basis.
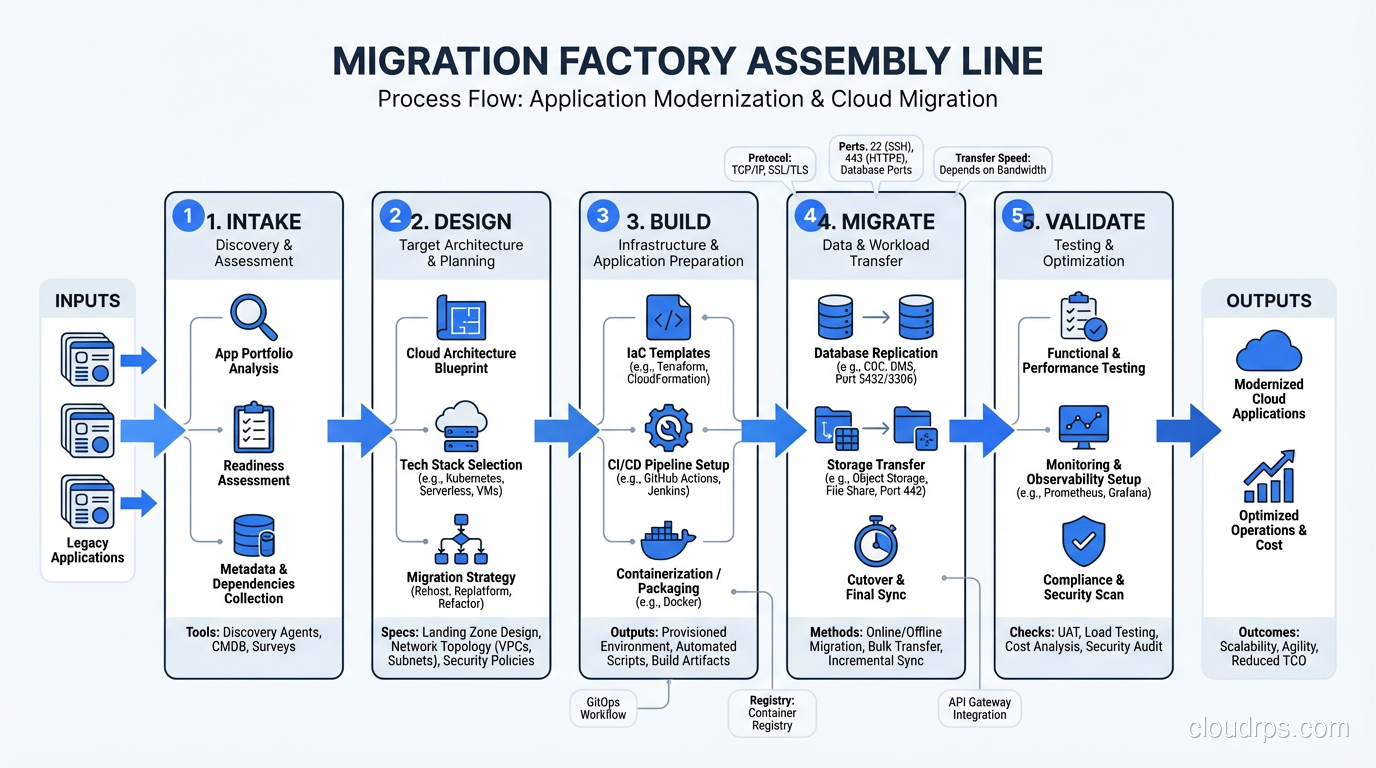
The Toolchain
A migration factory runs on automation. Here’s the toolchain I’ve standardized on:
Discovery and Assessment
- AWS Application Discovery Service or Azure Migrate for automated infrastructure discovery
- Custom assessment questionnaires (I use a Jira-based workflow)
- Dependency mapping tools (ServiceNow, Flexera, or custom scripts)
Migration Execution
- AWS Application Migration Service (MGN) for server replication
- AWS Database Migration Service (DMS) or native database replication for databases
- CloudEndure (now part of MGN) for continuous replication
- Custom scripts for application-specific data migration
Infrastructure as Code
- Terraform modules for every common pattern (web server, application server, database, load balancer)
- Account vending automation
- CI/CD pipelines for infrastructure deployment
Tracking and Reporting
- Migration portfolio tracker (I’ve used Jira, Smartsheet, and custom dashboards)
- Automated status reporting
- Factory metrics dashboard
Factory Metrics That Actually Matter
You can’t manage what you don’t measure. These are the metrics I track daily:
Pipeline velocity: How many applications move from intake to validated in production per week. This is the headline metric.
Stage cycle time: How long applications spend in each stage. If applications are piling up in the design stage, you need more architect capacity. If they’re stuck waiting for cutover windows, you need better business coordination.
Cutover success rate: Percentage of cutovers that complete without rollback. Target: 95%+. Below 90% indicates systemic problems in design or testing.
Defect rate: Post-migration issues found in the first 30 days. Categorize by severity and root cause to drive process improvements.
TCO realization: Actual cloud costs vs projected costs for migrated workloads. This validates your business case and identifies optimization opportunities.
Team utilization: Are specialists idle between stages or overloaded? Factory efficiency requires balanced throughput across stages.
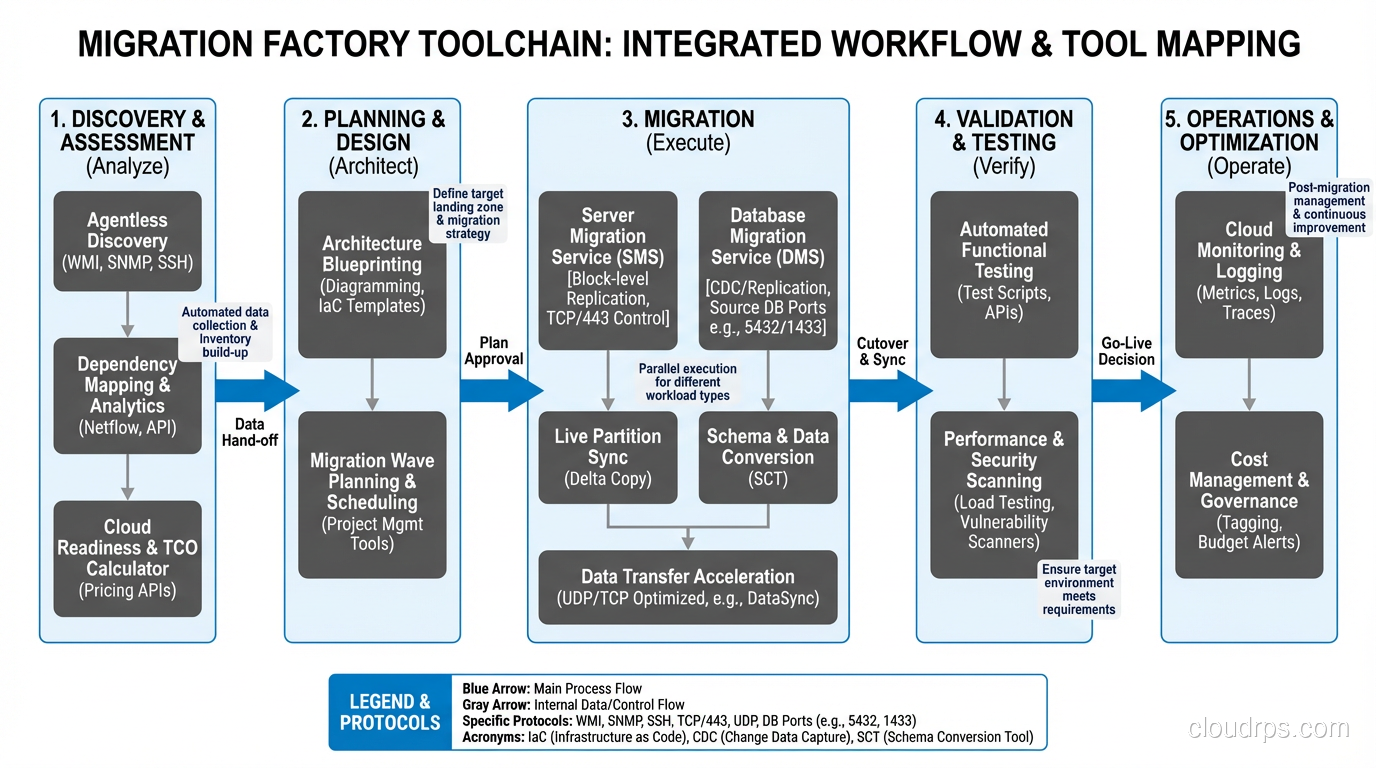
The S-Curve of Migration Velocity
Every migration factory follows an S-curve. The first month produces low throughput while the team learns the tools, establishes processes, and migrates simpler workloads. Months 2-3 see rapid acceleration as the team builds muscle memory and automation matures. Months 4+ level off at peak throughput.
I set expectations with leadership based on this curve. Don’t promise peak velocity in month one. It creates unhealthy pressure and incentivizes cutting corners.
Common Factory Anti-Patterns
The Snowflake Trap
Every application owner believes their application is unique and requires special handling. Some genuinely are. Most aren’t. If you let every application be treated as a custom project, you don’t have a factory. You have a consulting practice.
My approach: 80% of applications fit into standard patterns (web app rehost, database replatform, etc.) and go through the factory assembly line. 20% genuinely require custom handling and get assigned to a dedicated team outside the factory.
The fight is always over which applications fall into the 20%. Application owners push to be in the special category. Resist this. Every “exception” slows the factory.
The Automation Gap
Some teams set up the factory process (stages, roles, handoffs) but don’t invest in automation. They have a factory in name but a manual process in practice. Without Infrastructure as Code, automated testing, and migration tooling, the throughput ceiling is maybe 10 applications per month regardless of team size.
Invest in automation early. The ROI is enormous. A Terraform module for a standard three-tier web application takes a week to build and saves hours on every subsequent migration.
The Cutover Bottleneck
The single biggest bottleneck in every migration factory is the cutover stage, because cutovers require:
- A maintenance window (often weekends or late nights)
- Business stakeholder approval
- Application team availability
- Rollback readiness
I address this by batching cutovers, running 5-8 cutovers in a single maintenance window. This requires coordination, but it’s far more efficient than individual cutover windows for each application.
Ignoring the Feedback Loop
The factory must have a continuous improvement loop. After every wave, conduct a retrospective. What worked? What broke? Where did the process slow down? Feed those insights back into the process.
The factory in month six should be measurably more efficient than the factory in month one. If it’s not, your feedback loop is broken.
When You Need a Migration Factory
Not every organization needs a factory. The factory model makes sense when:
- You’re migrating 100+ applications
- The migration has a hard deadline (data center lease expiration, contract end)
- You need predictable throughput for planning purposes
- Multiple teams are involved and coordination overhead is significant
If you’re migrating 20 applications over a year, a project-based approach is fine. But if you’re migrating 500 applications in 18 months (and I’ve done this several times), the factory is the only model that works.
The Human Side of the Factory
I want to close with something the technical guides never mention. A migration factory is a high-pressure environment. Teams are under throughput targets, cutovers happen on weekends, and unexpected issues are constant. Burnout is a real risk.
Rotate people between stages so nobody is stuck in the same role for the entire program. Celebrate milestones; every hundredth application migrated deserves recognition. And protect the team’s time off, because migration fatigue leads to mistakes, and mistakes lead to failed cutovers.
The factory model works because it applies industrial principles to infrastructure work. But it only works sustainably when you treat the people running it with the same care you give the process itself.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.