I spent a good chunk of 2013 and 2014 trying to solve the cold start problem in what we were calling “serverless” functions back then, before AWS Lambda even had a public name. We were running workloads on then-experimental function-as-a-service prototypes and fighting the same war everyone fought for the next decade: the function goes cold, some user in Tokyo gets a 400ms delay loading a page that should take 12ms, and you spend your afternoon tuning provisioned concurrency knobs that feel more like cargo cult than engineering.
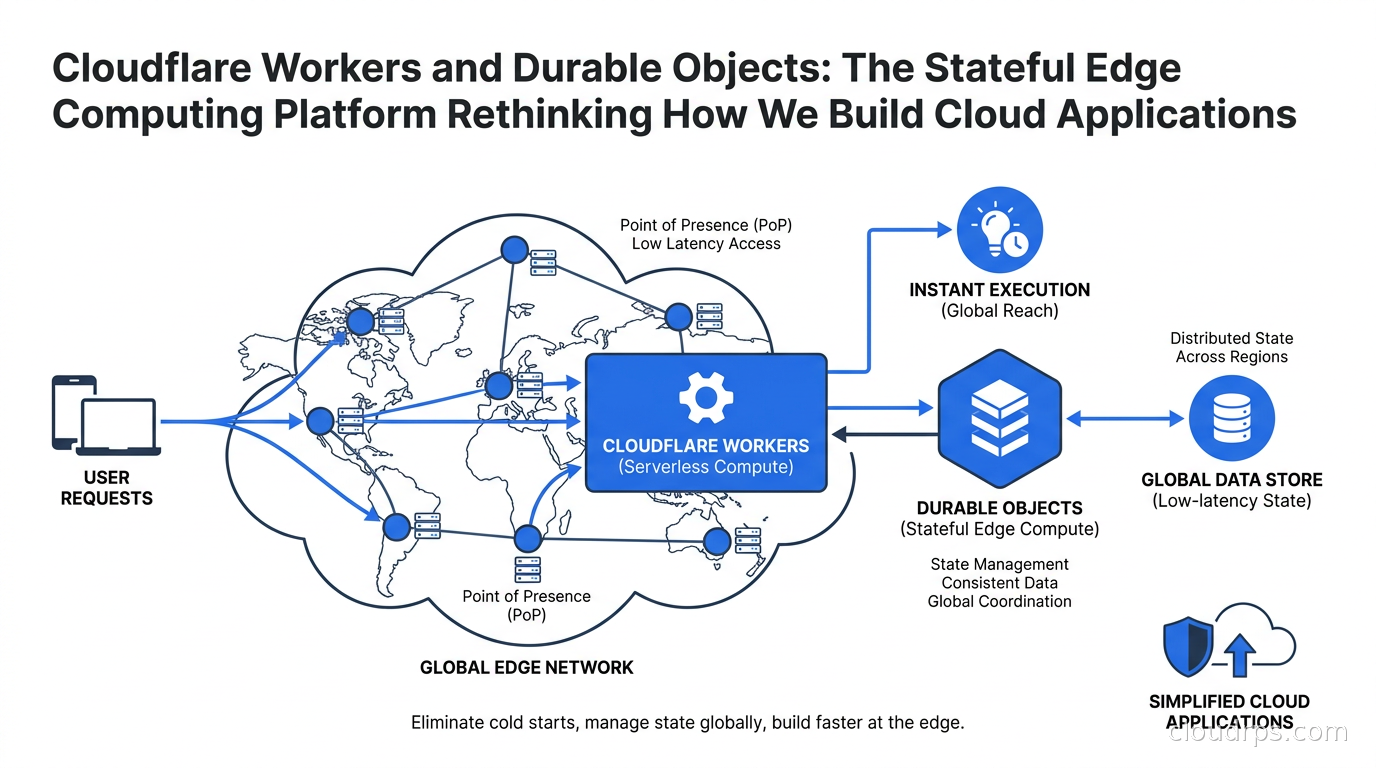
Cloudflare Workers came along in 2017 and I wrote them off. I assumed it was a CDN company doing edge functions as a feature, not a fundamental rethink of the runtime model. That was a mistake I did not repeat after actually running Workers in production. The cold start problem is not mitigated in Workers. It is architecturally eliminated. That distinction matters enormously and it took me longer than it should have to understand why.
Twenty years into this career, I have seen a lot of “cloud primitives” launched with fanfare that turned out to be rebranded virtual machines. Workers is genuinely different. So is the Durable Objects model built on top of it. This article is my attempt to explain both without hype, with the architecture underneath exposed.
Why V8 Isolates Change the Equation
Traditional serverless functions, whether Lambda, Cloud Functions, or Azure Functions, run your code inside a container or a lightweight VM. The container has to start, the runtime has to initialize, your application code loads, and then the first request comes in. If nobody has hit this function instance for a few minutes, the cloud provider recycles it to save resources. The next request pays the cold start tax. AWS invested enormous engineering effort into things like Firecracker microVMs and SnapStart to shave milliseconds off that startup time. But it is still a container paradigm.
Cloudflare Workers use V8 isolates. The JavaScript V8 engine, the same one inside Chrome and Node.js, supports a concept called an isolate: a sandboxed JavaScript execution context that shares a process with other isolates but is completely memory-isolated from them. Starting a new V8 isolate takes less than a millisecond. Not ten milliseconds, not two milliseconds. Sub-millisecond. There is no operating system boot, no container networking setup, no runtime initialization. The isolate spins up, runs your code, and that first request gets the same performance as the ten-thousandth request.
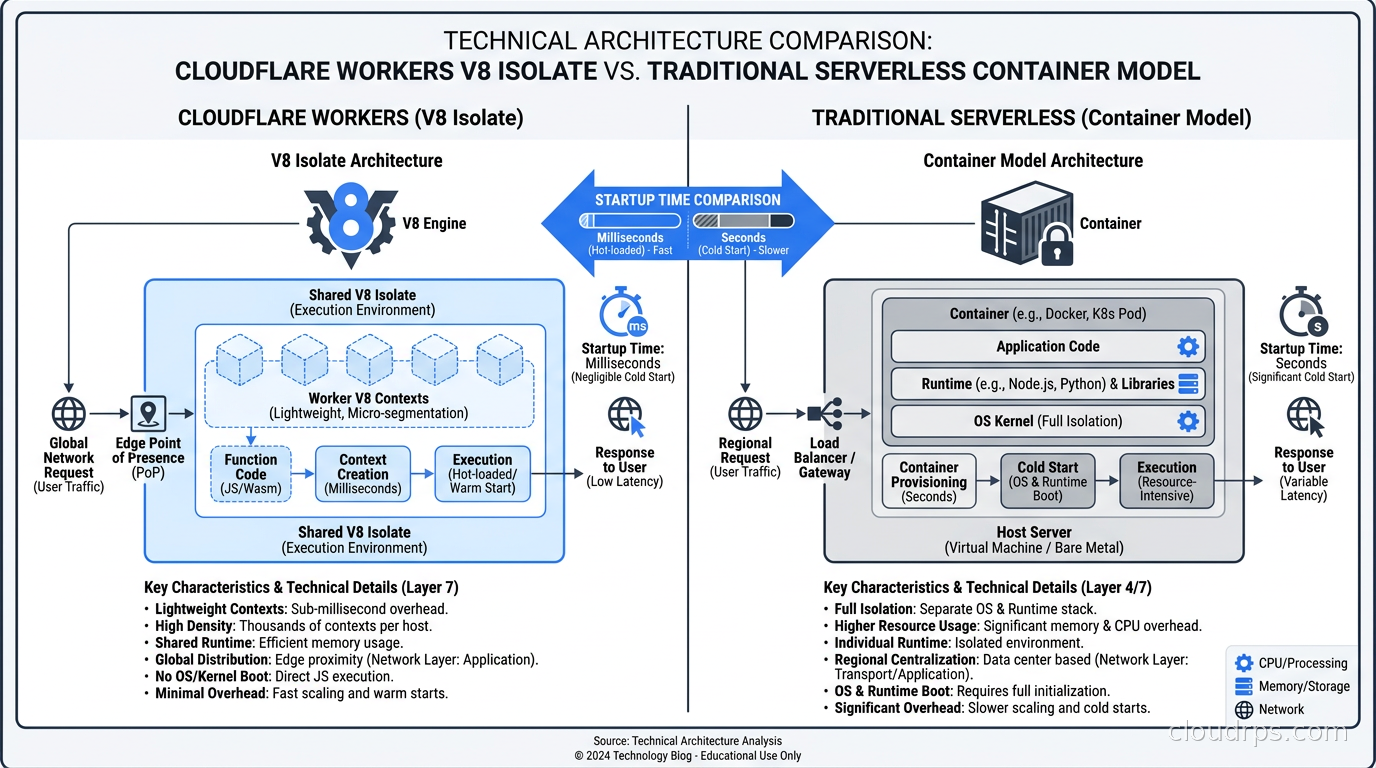
The tradeoff is real: isolates are not full Node.js environments. You do not get access to the filesystem, you cannot spawn child processes, and a lot of Node.js APIs you take for granted do not exist. Workers runs on a subset of the Web APIs spec plus Cloudflare-specific APIs. If your function does compute and HTTP calls, Workers is a great fit. If your function shells out to imagemagick or reads from the local filesystem, it is not. I have seen teams try to shoehorn Workers into use cases it is not suited for. The constraint is real, not theoretical.
The other dimension is deployment geography. When you deploy a Lambda function, you pick a region. When you deploy a Worker, it runs in every one of Cloudflare’s roughly 300 points of presence globally. The request routes to the nearest data center automatically. For latency-sensitive workloads where you care deeply about p95 response times, this is a fundamentally different operational posture than “pick us-east-1 and add CloudFront in front of it.” I have built global rate limiting systems on Workers where the enforcement point is within 15ms of almost every user on the planet. Building equivalent latency guarantees on Lambda would require multi-region deployments, global DynamoDB tables, and a lot of operational complexity that Workers handles for you structurally. For more on how serverless compares to managed container platforms, see our analysis of serverless containers vs Kubernetes.
KV: The Eventually Consistent Foundation
Cloudflare KV is the simplest storage primitive in the Workers ecosystem. It is a key-value store distributed across Cloudflare’s global network. Writes propagate to all edges within about 60 seconds. Reads are served from the nearest edge. This is eventual consistency with aggressive read performance: global read latency is typically under 10ms from anywhere with a Cloudflare presence.
KV works well for data that changes infrequently and where a 60-second propagation window is acceptable: feature flags, configuration, static content caching, API response caching. It is terrible for anything that needs strong consistency. If you try to use KV as a counter or a lock, you will have race conditions. I have seen this mistake exactly twice in production, both times with engineers who understood eventual consistency intellectually but underestimated how often it actually bites you under concurrent write load.
The pricing model on KV is worth understanding before you commit. Reads are cheap (under a dollar per million after the free tier). Writes are more expensive and, more importantly, KV has a per-key write rate limit of approximately one write per second per key. This is not a soft limit you can burst through; it is a hard constraint from the replication model. If you are updating a high-traffic counter, you need a different tool. That tool is Durable Objects.
Durable Objects: The Breakthrough for Stateful Edge
Durable Objects are the most architecturally interesting primitive in the Cloudflare platform, and I use that word carefully after two decades of seeing features marketed as architectural breakthroughs.
The problem Durable Objects solve is coordination at the edge. Edge functions are, by their nature, distributed: your Worker runs in 300+ locations simultaneously. If two users in different cities simultaneously try to modify the same piece of state, you need coordination. With pure KV, you hope eventual consistency is okay. With a traditional centralized database, you take the latency hit of going back to a single region. With Durable Objects, you get a different model entirely.
Each Durable Object instance is a stateful singleton. It has its own persistent storage, its own WebSocket connections, and, critically, a single-threaded execution model. When multiple requests need to talk to the same Durable Object, they are routed to a single instance of that object running in a single data center (the one geographically closest to the first request that created it, or one you designate). The object processes requests sequentially. There is no concurrent mutation. No locks to manage. No compare-and-swap race conditions.
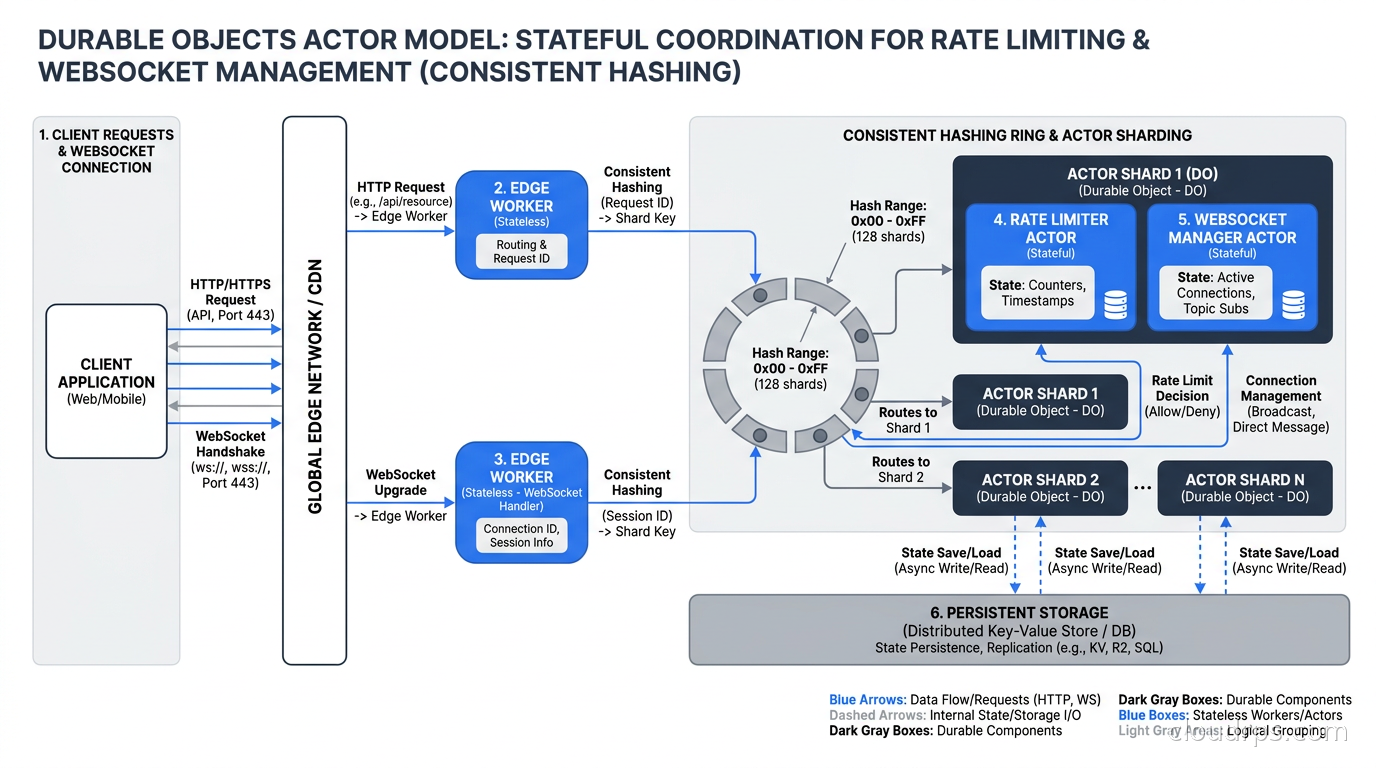
This is an actor model. If you have read about Erlang processes or Akka actors, the mental model maps directly. The Durable Object is an actor. Messages (HTTP requests from other Workers) arrive in a mailbox and are processed one at a time. The actor has private state that no other code can touch directly.
The practical applications are significant. Rate limiting is the canonical use case: one Durable Object per user or per API key, with a counter and a sliding window implementation. The DO handles all requests for that key sequentially, so the counter is always correct. No Redis, no distributed locking protocol, no Lua scripts to make operations atomic. I wrote about the complexity of distributed rate limiting in our rate limiting at scale guide, and Durable Objects eliminate about 80% of that operational complexity for use cases where the bounded geographic latency of routing to a single DO instance is acceptable.
WebSocket coordination is the other killer use case. Cloudflare supports WebSockets through Workers, and Durable Objects can hold open WebSocket connections. A collaborative editing tool, a multiplayer game room, a live dashboard with real-time updates: these all become architecturally clean when each “room” is a Durable Object. All clients connecting to room-42 route to the same DO instance. The DO can broadcast to all connected clients because it holds references to all their WebSocket connections. No Redis Pub/Sub, no self-managed WebSocket gateway, no sticky load balancing. The platform handles the coordination primitive; you write business logic.
Durable Objects have their own storage layer, separate from KV, with strong consistency guarantees and a simple key-value API for persistence within an object. Writes are transactional within a single DO instance. You can store state, read it back, and know it is current. The storage is co-located with the DO instance for low-latency reads and writes.
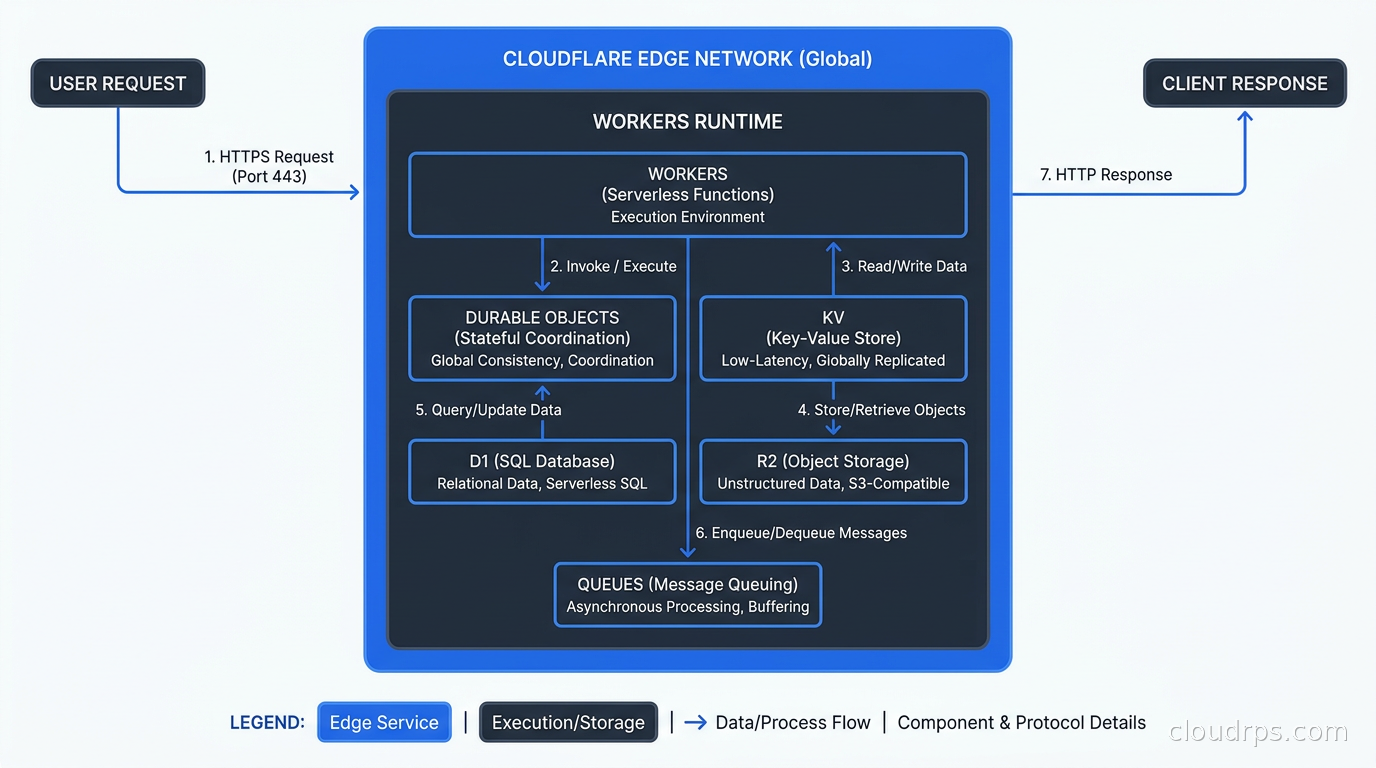
R2, D1, and Queues: Completing the Platform
Cloudflare has been building out a full cloud platform around Workers, and three of the additional primitives are worth understanding.
R2 is Cloudflare’s object storage service, built to be API-compatible with AWS S3. The headline feature is that R2 charges zero egress fees. If you are storing large objects and serving them globally, egress fees from S3 can be substantial. We covered how cloud egress costs can silently kill your architecture budget in our cloud egress cost analysis. R2 eliminates that class of cost entirely for Cloudflare-served traffic. The tradeoff: R2 is a newer service with fewer features than S3, fewer ecosystem integrations, and no equivalent of S3 Event Notifications that trigger Lambda functions natively (you can approximate this with Cloudflare Queues, but it requires more wiring). For pure object storage with heavy read traffic, R2 is genuinely compelling on cost. For a complex data pipeline that depends on S3’s event model and ecosystem, staying on S3 is reasonable.
D1 is SQLite at the edge. This is more interesting than it sounds. Each D1 database is a SQLite file that replicates across Cloudflare’s network with a primary write location and read replicas at edges. You write SQL. Cloudflare handles replication and consistency. For applications that need relational queries at the edge without managing a database fleet, D1 covers a real gap. The scale limits are real (D1 is not Postgres; the row count and storage limits are designed for application databases, not data warehousing), but for the right workload: a content management system, a configuration store with relational structure, a lightweight SaaS application with per-tenant SQLite databases, D1 fits elegantly.
Cloudflare Queues are exactly what they sound like: a durable message queue service for Workers. A Worker can enqueue a message; another Worker (the consumer) processes it. Messages are delivered at least once. The integration with Workers is tight: you define the queue in your Worker configuration and bind it directly. No separate SDK, no connection string to manage. For background job processing at the edge, offloading slow operations from request handlers, or building simple pipelines, Queues fill the need. The feature set is intentionally simpler than SQS with its DLQ options, FIFO guarantees, and extensive configurability, but for many use cases, simpler is better.
AI Agent Infrastructure: Why 2026 Changed the Framing
Cloudflare’s “Agents Week” in early 2026 reframed the Workers platform around AI agent workloads. The primitives Cloudflare shipped for agents are extensions of things that already existed, but the patterns they enable are worth understanding.
AI agents need durable state across long-running multi-step tasks. A Durable Object is a natural container for an agent’s working memory: you get persistent storage, a sequenced execution model, and WebSocket support for streaming responses back to clients. The single-instance guarantee means the agent’s state is always consistent even if the agent takes many minutes to complete a task.
Agents need to call tools, which means making outbound HTTP requests to APIs, to databases, to other services. Workers are excellent HTTP clients with a clean fetch API. The Model Context Protocol (MCP), which we covered in depth in our MCP architecture guide, can be implemented in a Worker that exposes tools to an AI agent. Cloudflare has published reference implementations of MCP servers running entirely on Workers.
Rate limiting and authorization for agent-facing APIs is a natural fit for the Durable Objects pattern I described earlier. Each agent gets a Durable Object that enforces its rate limits and tracks its budget. The enforcement is global, consistent, and sub-millisecond. For production AI systems where cost control is critical, this is not a theoretical benefit.
The pattern I find most compelling: a Worker as the entry point for an AI agent API, a Durable Object per active agent session holding state, D1 for durable agent history, R2 for storing large artifacts the agent produces, and Queues for passing work to background processing Workers. This is a complete AI agent backend, and it runs entirely on Cloudflare with no containers to manage, no Kubernetes cluster to operate, and a global deployment footprint from day one.
Operational Reality: What I Have Learned in Production
Workers observability has historically been weak compared to Lambda and GCP Cloud Functions. The Workers dashboard gives you invocation counts and error rates, but for anything beyond basic metrics you need to push logs to an external system. Cloudflare’s Workers Logpush service can send logs to S3, Datadog, or Splunk, but setting it up and managing the log schema is something you have to do yourself. Lambda’s native CloudWatch integration is more plug-and-play. If your organization has mature observability infrastructure, this is manageable. If your team was expecting cloud-native logging out of the box, budget time to wire it up.
Debugging Workers is also different from debugging Node.js. The runtime is a subset of the web platform, not Node.js. You cannot use most Node.js debugging tooling. Wrangler, Cloudflare’s CLI tool, has a dev mode that simulates the Workers runtime locally and proxies requests through Cloudflare, which works well for most cases. But the environment is never perfectly faithful to production (for example, Miniflare, the local simulator, has subtle behavioral differences with Durable Objects). I have caught bugs in staging that local dev missed.
The resource limits are strict. A single Worker invocation gets 128MB of memory, up to 30 seconds of CPU time (for paid plans), and bounded outbound connections. If you are doing CPU-intensive work, like running a model inference step or processing a large document, Workers may not be appropriate. The constraint is not bandwidth or I/O bound work; it is raw CPU time. Cloudflare has started to address this with their GPU inference products and with specific support for running smaller WASM-compiled models, but the Workers runtime itself is not a general-purpose compute environment.
Pricing deserves a note. Workers has a very generous free tier (100,000 requests per day) and the paid plan pricing is competitive with Lambda at low-to-moderate scale. At very high scale, the per-request pricing model can get expensive compared to provisioned Lambda concurrency or containers. The economics depend heavily on your traffic patterns. Bursty, unpredictable traffic favors Workers. Sustained high-volume predictable traffic often favors reserved capacity elsewhere. For a thorough framework on evaluating total cloud costs, our FinOps guide covers the methodology for making this comparison rigorously.
When to Choose Workers vs When Not To
Workers is the right choice when you need global low-latency execution with no cold starts, when your function fits the web platform API surface, and when you want to eliminate operational overhead at the cost of runtime flexibility.
Workers is wrong when you need arbitrary Node.js or Python runtime APIs, when your function does heavy CPU computation for more than a few hundred milliseconds, when you need full POSIX compatibility, or when your existing infrastructure is deeply integrated with Lambda’s event source mappings and you do not want to rebuild that integration.
The Durable Objects model is right when you need stateful coordination at the edge: rate limiting, WebSocket rooms, per-tenant state management, agent session state. It is architecturally elegant for these use cases in a way that is genuinely hard to replicate cheaply with traditional serverless and a centralized datastore.
If you are building from scratch and your workload fits the constraints, the full Cloudflare stack (Workers plus Durable Objects plus R2 plus D1 plus Queues) is worth serious evaluation. The operational simplicity is real. The deployment model (push code, it runs everywhere) is genuinely different from managing Lambda functions per region or orchestrating a Kubernetes cluster across AZs, which we covered in our Kubernetes vs serverless comparison.
The thing I keep coming back to after twenty years is that the most important architectural decisions are usually the boring ones about operational complexity. The Workers platform trades runtime flexibility for a radically simplified operational model. For the right workload profile, that is a trade worth making.
The Cloudflare platform is not a replacement for everything. It is a replacement for a specific category of problems where the old answer was “Lambda function plus ElastiCache for state plus CloudFront for distribution.” For that category, which is larger than most people initially think, Workers plus Durable Objects is architecturally cleaner, faster, and often cheaper. Start with a simple Worker, understand the runtime constraints, and reach for Durable Objects when you need stateful coordination. The platform rewards engineers who work with its constraints rather than against them.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.