I’ve watched both of these patterns get cargo-culted into projects that didn’t need them. CQRS and event sourcing are powerful tools, but they’re also among the most misapplied patterns in distributed systems design. Teams hear about them at conferences, read the DDD books, and then decide their simple CRUD application needs to be rebuilt with a full event sourcing model. The result is an engineering marvel that’s three times more complex and twice as slow as what it replaced.
Let me give you the practitioner’s view: what these patterns actually are, when they genuinely help, and when to politely decline the architectural astronaut’s suggestion that you need them.
CQRS: The Core Idea
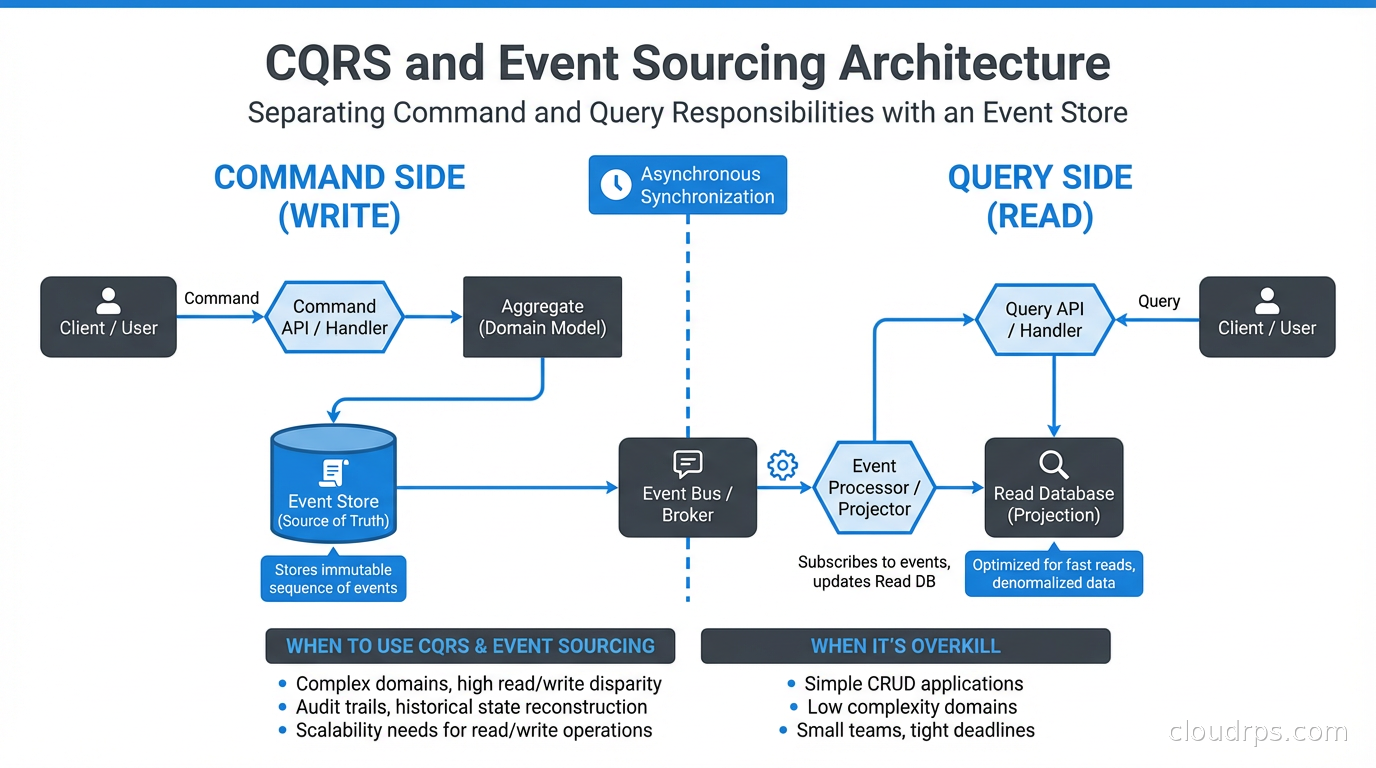
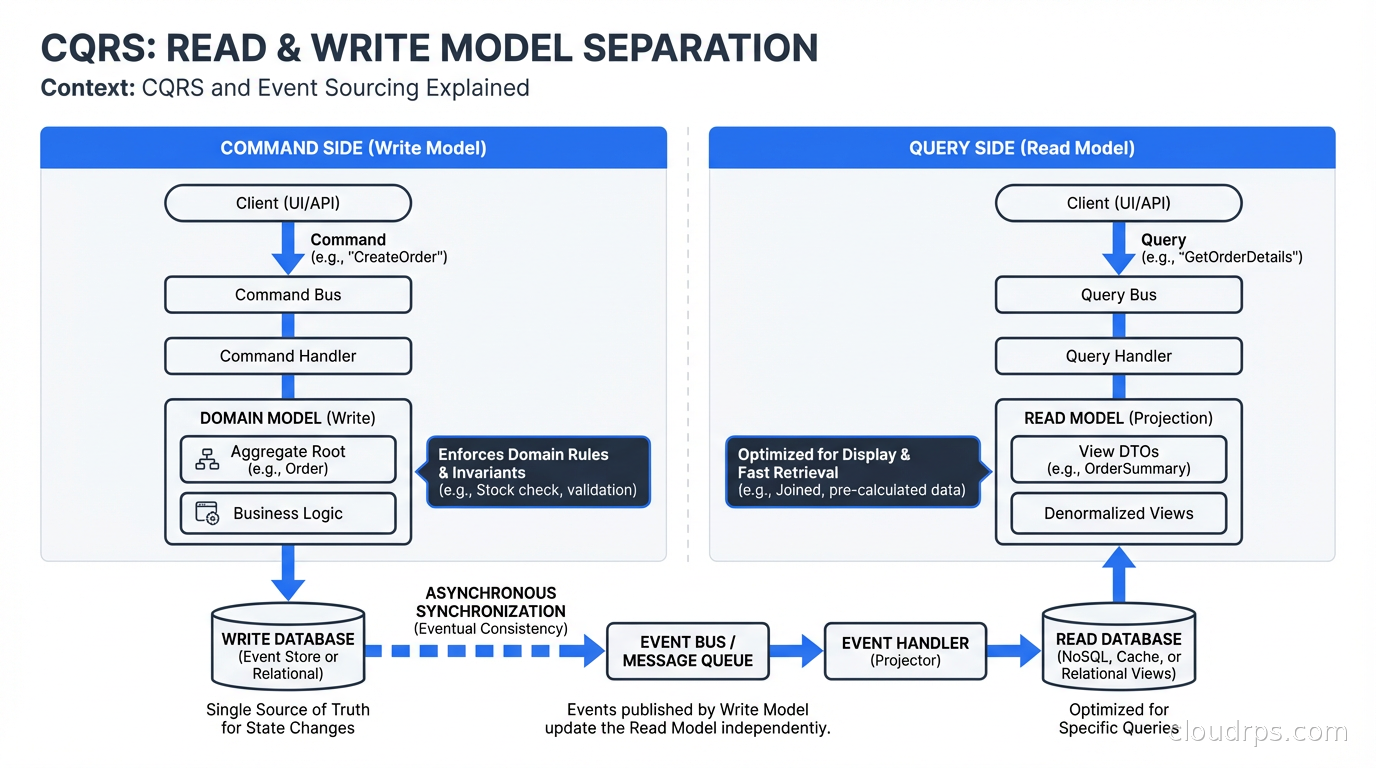
Command Query Responsibility Segregation (CQRS) is about separating the code and data models responsible for changing state from the code and data models responsible for reading state. That’s it. Commands mutate state. Queries return state. They use different models.
In a traditional CRUD application, you have one model: a User table, and you both read from it and write to it. CRUD works fine for many systems. Where it breaks down is when your read patterns and write patterns have fundamentally different requirements.
Consider an e-commerce order system. Writing an order requires validation, inventory checking, payment processing, and coordinating across multiple bounded contexts. Reading orders for a customer’s history requires joining orders, line items, product details, and shipping status, often with filtering, sorting, and pagination. These two operations have almost nothing in common. Yet in a traditional design, you’d have one Order model and one OrderRepository doing both.
CQRS says: separate them. Have a PlaceOrderCommand that goes through your domain logic and writes to a normalized transactional database. Have a CustomerOrderHistoryQuery that reads from a denormalized read model specifically shaped for displaying order history. The read model might be a pre-computed view in Redis, a materialized view in your database, or a separate read-optimized data store.
The immediate benefit is that you can optimize reads and writes independently. The write side uses whatever model is correct for your domain logic. The read side uses whatever model makes queries fast: often denormalized, pre-joined, and precomputed.
The cost is complexity. You now have two models to maintain, potentially two data stores, and you need a mechanism to keep the read model synchronized with the write model. That synchronization mechanism is where event sourcing often enters the picture.
Event Sourcing: State as a Stream of Events
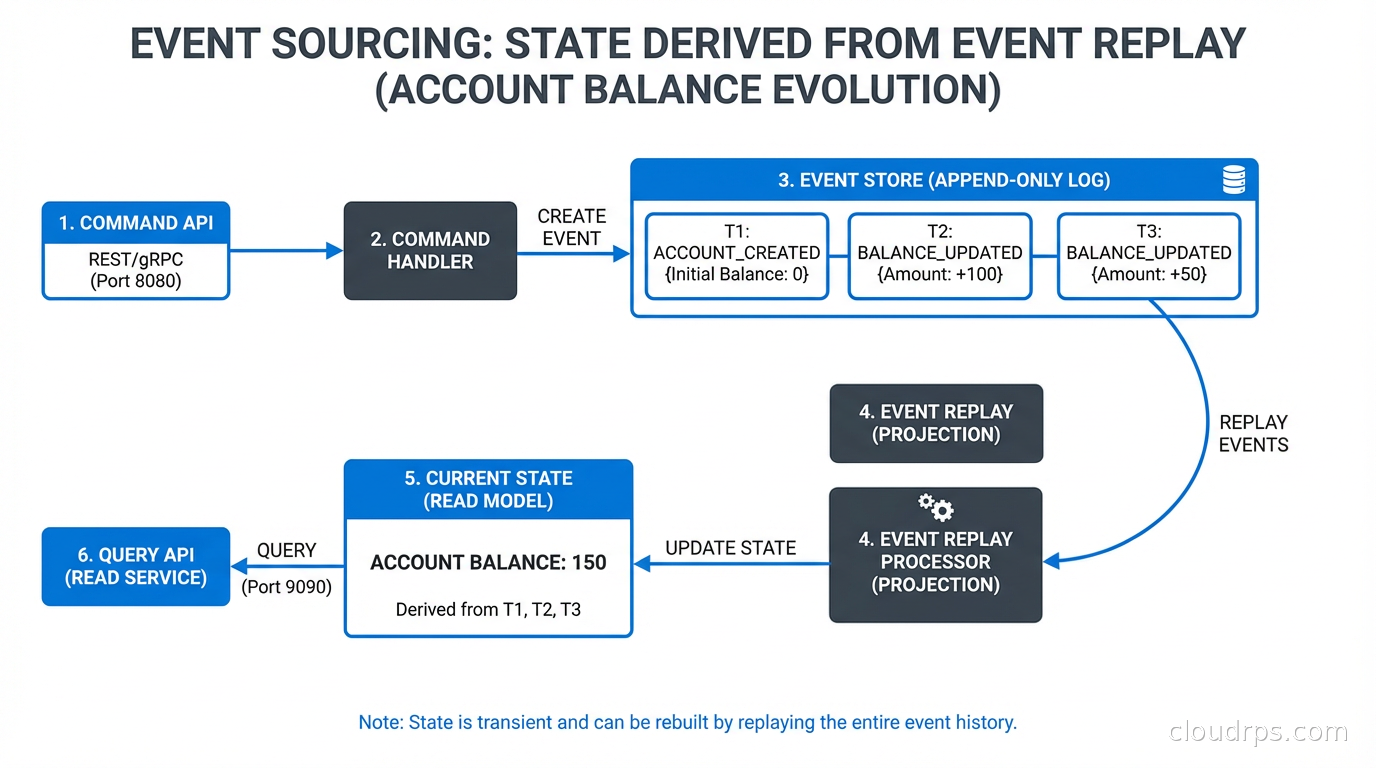
Event sourcing is a persistence strategy where you store state as an ordered sequence of events rather than as the current state. Instead of storing “User X has balance $500,” you store:
AccountCreated(userId: X, timestamp: ...)
MoneyDeposited(userId: X, amount: $1000, timestamp: ...)
MoneyWithdrawn(userId: X, amount: $500, timestamp: ...)
The current balance is derived by replaying these events. The current balance of $500 isn’t stored anywhere: it’s computed when needed.
This is how accounting has worked for centuries. The ledger doesn’t store your current balance: it stores every transaction, and your balance is the sum. Event sourcing brings this model to software.
The benefits are real and meaningful for the right use cases.
Complete audit trail: Every state change is recorded with full context. Not “balance changed to $500” but “MoneyWithdrawn by user X from account Y at timestamp Z because of transaction T.” You can reconstruct the exact state of any entity at any point in time.
Event-driven integration: Events are naturally shareable. Other services can subscribe to your event stream and build their own projections without coupling to your write model. Your order service emits OrderPlaced events and your shipping service, analytics service, and notification service all react independently.
Temporal queries: “What was the state of this order at 2 PM yesterday?” is trivially answered by replaying events up to that timestamp. In a traditional system, answering this requires either audit tables (which you have to maintain separately) or restoring from backup.
Debugging production issues: When something goes wrong, you have the full event history. I’ve used this to debug subtle concurrency bugs by replaying the exact sequence of events that led to corrupted state. With a traditional database, the evidence is overwritten by the time you investigate.
How CQRS and Event Sourcing Work Together
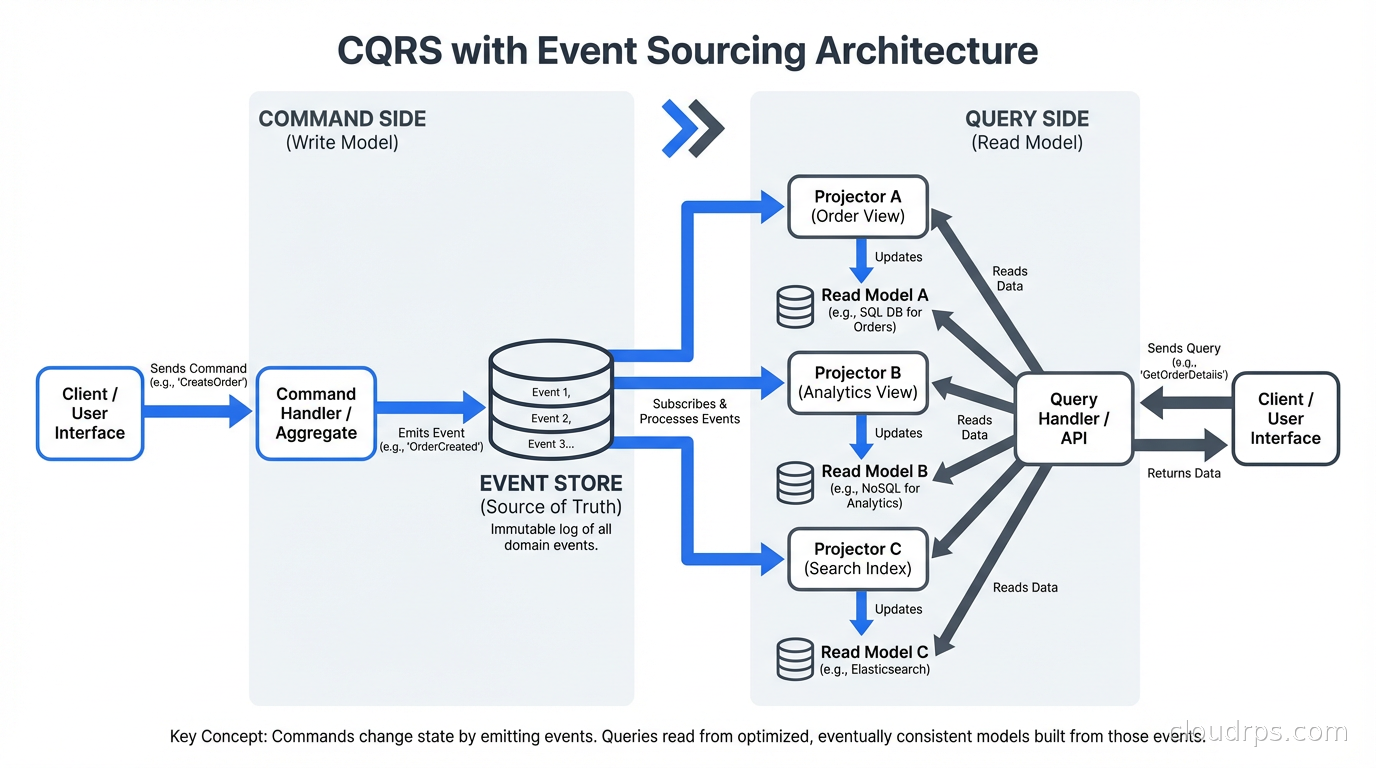
They don’t have to go together. CQRS without event sourcing is common and useful. Event sourcing without CQRS is less common but valid. But they compose naturally.
In the combined pattern: the command side processes commands, validates them against domain rules, and emits domain events to an event store. The event store is append-only: events are never updated or deleted. Event handlers (projectors) subscribe to the event stream and update read models optimized for specific query patterns. Queries read from these pre-built read models.
The synchronization between the write side (event store) and read side (projections) is usually asynchronous, which means your system is eventually consistent: there’s a window (typically milliseconds to a few seconds) where a query might return stale data after a write.
This eventual consistency is often the biggest resistance point from teams evaluating these patterns. “Our users expect to see their changes immediately.” Usually this is manageable: you can return the written data directly from the command response without querying the read model, or you can use optimistic UI updates. In the very few cases where strong consistency is required between write and read, full CQRS with event sourcing is probably the wrong tool.
When to Use CQRS
Pure CQRS (without event sourcing) is appropriate when:
Your read and write load patterns are significantly different. High-write, low-read or high-read, low-write systems benefit from independent scaling of the read and write paths. A system where 90% of operations are reads and the data is expensive to join can precompute read models that serve queries cheaply.
Your read models require significant shaping. If every read requires joining 8 tables and computing derived fields, it’s often better to precompute that into a denormalized read model.
You’re working in a domain with complex business logic. CQRS naturally aligns with domain-driven design because it separates the domain model (write side, enforces business rules) from query concerns (read side, optimized for display).
CQRS is NOT appropriate when: your application is simple CRUD with straightforward reads and writes, your team is small and operational simplicity matters more than theoretical scalability, or you’re in the early stages of a product where requirements are changing rapidly. Premature CQRS is a real problem.
When to Use Event Sourcing
Event sourcing adds value specifically when:
Auditability is a hard requirement. Financial services, healthcare, legal, regulatory compliance contexts: any domain where you need to know exactly what happened and when. Event sourcing gives you this without bolting on a separate audit log that might be incomplete.
You need temporal queries. If “show me the state as of date X” is a real use case (think audit reports, regulatory lookups, debugging), event sourcing makes this trivial instead of expensive.
Your system is genuinely event-driven with multiple downstream consumers. If you’re already doing event streaming with Kafka or Flink, event sourcing is a natural fit because your command side already produces events. The leap to using those events as the primary persistence mechanism is smaller.
You have complex domain logic with aggregate-level consistency requirements. Domain-driven design aggregates map cleanly to event-sourced entities: each aggregate has its own event stream, events are the source of truth, and aggregate state is always reconstructed from its event history.
Event sourcing adds significant complexity when: your domain is simple (CRUD), your team is small, you don’t need audit trails, events are hard to define meaningfully (not all domains have clear events), or event schema evolution is going to be painful (and it often is). Once you emit an event and downstream consumers depend on it, changing that event’s shape is painful.
The Event Store Implementation
If you decide to use event sourcing, the event store implementation matters. An event store needs to be append-only, ordered per aggregate, and capable of efficiently replaying events from any position.
Common implementations:
EventStoreDB: Purpose-built for event sourcing. Native support for projections, subscriptions, and competing consumers. This is the reference implementation if you want a mature dedicated event store. Greg Young (who coined CQRS) built it.
PostgreSQL: You can implement an event store in PostgreSQL with an events table (aggregate_id, aggregate_version, event_type, data, metadata, timestamp). It’s not as feature-rich as EventStoreDB but is operationally simpler for teams already running PostgreSQL. I’ve used this approach in several projects and it works well at moderate scale. The key is the append-only constraint and optimistic concurrency check on aggregate_version.
Apache Kafka: Kafka topics as event stores work for scenarios where you have existing Kafka infrastructure and want to reuse it. Kafka’s log compaction can approximate “current state” for key-value style entities. But Kafka lacks per-aggregate ordering guarantees without partition-level discipline, and it’s not optimized for reading an individual aggregate’s event history.
DynamoDB or Cosmos DB: Viable for cloud-native implementations where you want managed infrastructure. DynamoDB with aggregate_id as partition key and aggregate_version as sort key gives you efficient aggregate event reads and optimistic concurrency via conditional writes.
The critical requirement regardless of implementation: optimistic concurrency control. When you write events, you specify the expected version of the aggregate. If someone else wrote events to the same aggregate concurrently, the version won’t match and the write fails. The caller retries. This is how you maintain aggregate consistency without pessimistic locking.
Event Schema Evolution: The Hard Part
Nobody talks about this enough. Once you’re in production with an event sourcing system, your events are permanent. You will never be able to change the past events. When your domain evolves and event schemas need to change, you have limited options.
Upcasting: When reading old events, transform them to the new schema before passing to the domain model. Your aggregate’s apply methods see the current schema. Old events are stored as-is but upcasted on read. This is my preferred approach for minor changes (adding optional fields, renaming fields).
New event types: Instead of changing OrderPlaced, introduce OrderPlacedV2 with the new schema. Old code handles OrderPlaced, new code handles both. Messy but explicit.
Schema versioning in metadata: Store a schema version with each event. Deserializers check the version and apply the appropriate mapping.
The lesson from production: design your event schemas carefully before you go live. Use JSON with optional fields where possible (easier to evolve than Protobuf or Avro in event sourcing contexts). Avoid embedding identifiers or constants that might change. And document your events: they’re the primary interface other services consume.
A Practical Recommendation
My guidance for teams evaluating these patterns: start with a question.
“Do I have a specific problem that CQRS/event sourcing solves?”
If you can’t point to a concrete problem (different read/write scaling requirements, audit trail requirements, complex event-driven integration), you probably don’t need these patterns yet. Build the simpler thing. A well-structured application using a relational database with read replicas and good indexing handles enormous load before CQRS becomes necessary.
If you’re building a distributed system with multiple microservices that need to stay loosely coupled, event sourcing for integration (producing and consuming domain events) makes sense even if you don’t event-source your persistence layer.
If you’re in a domain with strict audit requirements (financial, healthcare, regulated industries), event sourcing for the audit trail alone is worth the complexity, even if CQRS doesn’t add value for you specifically.
The Temporal workflow engine is an interesting alternative for workflow-heavy use cases: it gives you durable execution, audit history, and replay without requiring you to implement event sourcing from scratch. If your primary use case is long-running workflows rather than domain modeling, Temporal might be a better fit than a custom event sourcing implementation.
And finally: whatever you build, plan for the eventual consistency conversation with your product team. The “why can I see my old data when I just saved?” question will come up. Have a good answer ready. Usually it involves explaining that the delay is under a second and the tradeoffs are worth it. Sometimes it means finding a part of the system where strong consistency is actually necessary and applying a simpler pattern there instead.
These are powerful patterns. Use them when they fit the problem. Don’t use them because they sound sophisticated.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.