
Every microservices codebase I have ever worked with carries the same accidental complexity tax. The business logic is twenty percent of the code. The other eighty percent is retry logic, state management boilerplate, circuit breakers, pub/sub wiring, secrets loading, distributed tracing instrumentation, and all the other plumbing that has nothing to do with what the service is actually supposed to do.
I spent two years at a financial services firm where we had forty-seven microservices written across five languages: Go, Java, Python, Node, and some legacy C# that nobody wanted to touch. Every one of those services had its own slightly different Redis client configuration, its own half-baked retry implementation, its own way of subscribing to Kafka topics. When we wanted to swap Kafka for Pulsar on three services, it was a three-month project. Not because the business logic changed, but because the Kafka wiring was tangled through everything.
That is the exact problem Dapr was built to solve.
What Dapr Actually Is
Dapr stands for Distributed Application Runtime. It is a CNCF graduated project, originally released by Microsoft in 2019 and donated to the CNCF in 2021. Graduating from CNCF incubating status in 2023 means it has proven production adoption and governance maturity, not just promising GitHub stars.
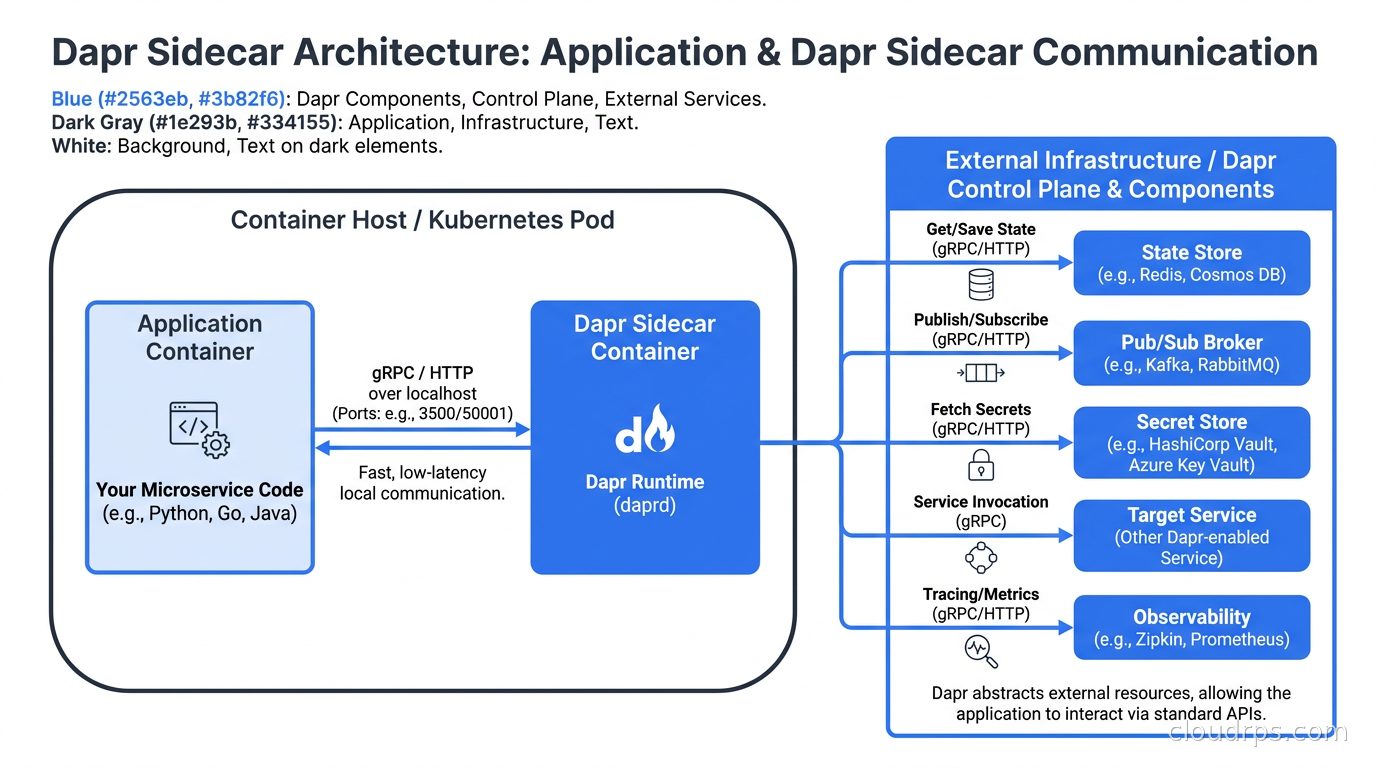
The core idea is deceptively simple: instead of every service directly integrating with Redis, Kafka, HashiCorp Vault, and whatever else your stack requires, every service talks to a Dapr sidecar over HTTP or gRPC on localhost. The sidecar handles the actual integration with your backing infrastructure. Your application calls a standardized building block API, and Dapr translates that into whatever the underlying system speaks.
Think of it as an adapter layer with batteries included. Your Go service does not know whether its state is stored in Redis, Azure Cosmos DB, or DynamoDB. It calls the Dapr state API and Dapr figures out the rest. Swap the backing store at deployment time through configuration, not code changes.
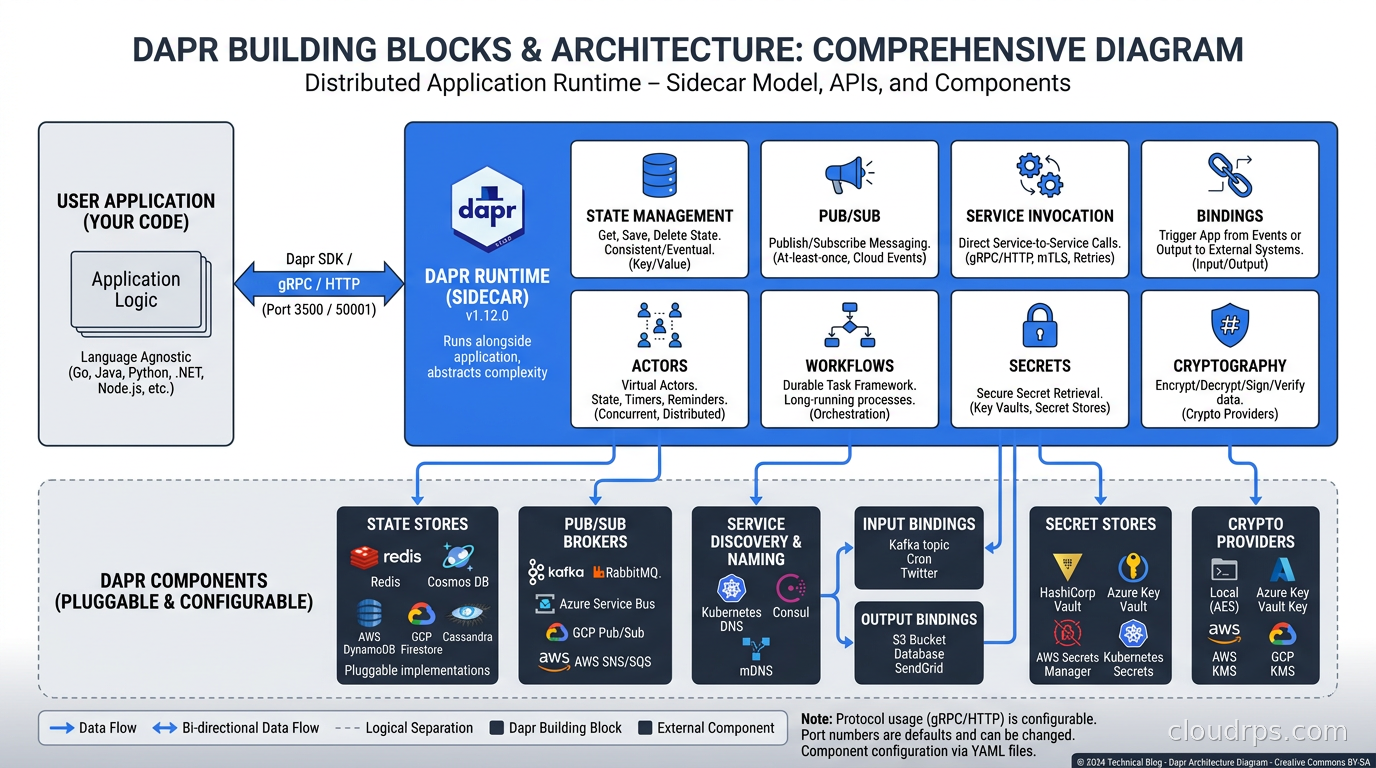
The Building Block Model
Dapr organizes its capabilities into discrete building blocks, each with a stable API surface and a pluggable component backend. As of 2025, the core building blocks are:
State Management. A key/value store API with support for optimistic concurrency, bulk operations, and transactional multi-key writes. Backed by Redis, DynamoDB, Azure Cosmos DB, CockroachDB, PostgreSQL, and about forty other stores. I have seen teams prototype on Redis and migrate to DynamoDB without touching a line of application code because Dapr handles the translation.
Pub/Sub Messaging. Publish messages to a topic, subscribe to topics, and receive messages through a push callback. Backed by Kafka, RabbitMQ, AWS SNS/SQS, Azure Service Bus, NATS, Google Pub/Sub, and more. The subscription model is declared in a Dapr component YAML, not embedded in your code, which means you can change brokers without refactoring your service.
Service Invocation. Direct synchronous calls between services with built-in service discovery, retries, and mutual TLS. This is Dapr’s answer to the service-to-service piece that service meshes like Istio and Linkerd also cover, though with important differences I will get into.
Bindings. Connect your services to external systems without writing custom clients. Input bindings trigger your service when something happens externally, say a new file lands in S3, a cron fires, or a message arrives in a queue. Output bindings let your service trigger external systems (send an email, write to a database, invoke a function) through a simple HTTP POST.
Secrets. Read secrets from HashiCorp Vault, AWS Secrets Manager, Azure Key Vault, GCP Secret Manager, or Kubernetes Secrets through a unified API. No provider-specific SDKs in your code. This pairs naturally with proper secret management infrastructure but removes the SDK coupling from your application code.
Configuration. Subscribe to configuration changes from stores like Redis or Azure App Configuration. Your service gets notified when config changes without polling or restarting.
Actors. An implementation of the virtual actor pattern (like Orleans or Akka). Each actor has a unique ID, a state store, and a single-threaded execution guarantee. The runtime activates actors on demand and deactivates them when idle. Useful for modeling per-entity state like order processing, user sessions, or IoT device state.
Workflows. Durable, resumable workflows built on top of the actor model. Similar in purpose to Temporal’s durable execution model but native to Dapr’s ecosystem. You write workflow code in your language of choice and Dapr persists the execution state so the workflow survives process restarts, pod evictions, and infrastructure failures.
Cryptography. Perform cryptographic operations (encrypt, decrypt, sign, verify) through the Dapr sidecar without storing keys in your application. Keys live in external key management systems like HashiCorp Vault or Azure Key Vault and never touch your application memory.
How the Sidecar Works in Practice
In Kubernetes, Dapr injects a sidecar container into your pod automatically when you annotate your deployment. The annotation is straightforward:
annotations:
dapr.io/enabled: "true"
dapr.io/app-id: "order-service"
dapr.io/app-port: "8080"
The Dapr sidecar runs alongside your application container and exposes its APIs on port 3500 (HTTP) or 50001 (gRPC). Your application calls http://localhost:3500/v1.0/state/statestore/order-{id} to get state. The sidecar handles the Redis (or DynamoDB, or Cosmos DB) call, retries, serialization, and encryption if configured.
The app ID you provide becomes your service’s identity in the Dapr mesh. When service A wants to call service B, it calls http://localhost:3500/v1.0/invoke/order-service/method/process. Dapr handles service discovery, the actual HTTP call, retries on transient failures, and mTLS encryption between sidecars.
Outside Kubernetes, Dapr runs in self-hosted mode where you launch dapr run alongside your process. This is excellent for local development because you get the same API surface without needing a full cluster.
Dapr vs Service Mesh: Not the Same Thing
This comparison comes up constantly and it trips people up. Dapr and service meshes like Istio solve different problems at different layers.
A service mesh (Istio, Linkerd, Cilium) operates at the network layer. It intercepts all TCP traffic between pods transparently, without any application knowledge. You get mTLS, traffic management, observability, and policy enforcement. Your application is completely unaware of the mesh.
Dapr operates at the application layer. Your application explicitly calls Dapr APIs. Dapr provides application-level capabilities like state management, pub/sub, and workflow orchestration that a network proxy simply cannot provide because they require application semantics.
You can and should run both together. A common production pattern is: Istio handles network-level security, traffic shaping, and observability; Dapr handles the application’s need for state, messaging, and service invocation. Dapr’s own service invocation goes through whatever network layer is present, so Istio’s mTLS still applies.
Where they overlap is service-to-service calls. Both can provide service discovery and mTLS for synchronous calls. Teams that are already heavy on Istio often disable Dapr’s service invocation mTLS to avoid double-encrypting traffic. Teams without a service mesh use Dapr service invocation as their first step toward secured service communication.
The Component Configuration Model
Dapr’s power is not just the APIs. It is that the backing infrastructure is defined in YAML component files completely decoupled from application code. Here is a pub/sub component pointing at Kafka:
apiVersion: dapr.io/v1alpha1
kind: Component
metadata:
name: orderpubsub
spec:
type: pubsub.kafka
version: v1
metadata:
- name: brokers
value: kafka-cluster:9092
- name: consumerGroup
value: order-service
Swap it to AWS SNS/SQS for your production environment:
apiVersion: dapr.io/v1alpha1
kind: Component
metadata:
name: orderpubsub
spec:
type: pubsub.aws.snssqs
version: v1
metadata:
- name: region
value: us-east-1
Your application code does not change. You publish to orderpubsub in both cases. The environment-specific configuration lives in Kubernetes manifests or a GitOps repository, separate from your service’s source code.
This is a genuinely big deal for teams managing multiple environments. Local development runs against Redis and a local Kafka container. Staging runs against managed Redis and MSK on AWS. Production runs against DynamoDB and SQS. The application code is identical across all three.
I have seen this pattern save weeks of environment-specific debugging. When a staging bug turned out to be a Kafka-specific message ordering assumption in the application code (not in the Dapr API call), it was immediately obvious because the local environment used a different broker and the bug did not reproduce there.
State Management in Depth
Dapr’s state API supports more than simple get/put/delete. The transactional API lets you write multiple keys atomically, which is critical for many business scenarios:
POST /v1.0/state/{storeName}/transaction
{
"operations": [
{"operation": "upsert", "request": {"key": "order-123", "value": {...}}},
{"operation": "upsert", "request": {"key": "inventory-456", "value": {...}}}
]
}
Whether this translates to an actual atomic transaction depends on the backing store. Redis and CosmosDB support it. DynamoDB has some limitations. Dapr documents this in component capability matrices, which I have found essential reading before committing to a state store.
State also supports ETags for optimistic concurrency control. You read a value, get its ETag back, include the ETag on your write. If another process updated the record between your read and write, Dapr returns a conflict error. This is the same pattern as DynamoDB condition expressions or PostgreSQL’s optimistic locking, just surfaced through a uniform API regardless of backing store.
State partitioning is another useful feature. Dapr can partition state across shards transparently, which matters when your state store (Redis, for example) needs to shard for scale. Your application calls the same API; Dapr routes to the correct shard.
Pub/Sub Patterns
Dapr’s pub/sub model covers the common patterns you need for event-driven architectures. Publishers post to a topic without knowing who is listening. Subscribers declare their subscriptions and Dapr delivers messages to a callback endpoint on the application.
Subscription declaration can be programmatic (your service returns its subscriptions from a well-known endpoint) or declarative (a Subscription CRD in Kubernetes). The declarative approach is cleaner for GitOps workflows because subscriptions are visible as Kubernetes resources rather than embedded in service startup logic.
Dead letter queues are configured per subscription:
apiVersion: dapr.io/v1alpha1
kind: Subscription
metadata:
name: orders-sub
spec:
topic: orders
route: /orders
pubsubname: orderpubsub
deadLetterTopic: orders-failed
bulkSubscribe:
enabled: true
maxMessagesCount: 100
The bulkSubscribe option is important for throughput-sensitive consumers. Without it, Dapr delivers one message at a time to your callback endpoint. With bulk delivery enabled, it batches up to the configured count, which can dramatically improve consumer throughput for high-volume topics.
Message filtering lets subscribers receive only messages matching specific criteria without pulling irrelevant messages across the wire. This is useful for fan-out scenarios where multiple services subscribe to the same topic but need different subsets.
Dapr Workflows: Durable Execution Without the Temporal Learning Curve
Dapr’s workflow engine provides durable execution similar to Temporal, but with lighter infrastructure requirements. Temporal needs its own cluster. Dapr workflows run on the same Dapr infrastructure your services already use, backed by the state store you already have.
A Dapr workflow is just a function in your language of choice:
@workflow
def order_workflow(ctx: DaprWorkflowContext, order_id: str):
order = yield ctx.call_activity(fetch_order, input=order_id)
yield ctx.call_activity(reserve_inventory, input=order)
payment = yield ctx.call_activity(process_payment, input=order)
if not payment.success:
yield ctx.call_activity(release_inventory, input=order)
return {"status": "failed"}
yield ctx.call_activity(ship_order, input=order)
return {"status": "shipped"}
If the pod running this workflow crashes after process_payment completes but before ship_order starts, the workflow resumes from where it left off when the pod restarts. Dapr persists the execution history in the state store and replays it deterministically to reconstruct the workflow’s position.

The tradeoff vs. Temporal is capability depth. Temporal has a more mature ecosystem, richer query and search capabilities, better tooling for complex workflow patterns like child workflows and signals. Dapr workflows are simpler to get started with if you already run Dapr, and they cover the majority of workflow patterns adequately. For complex, long-running business processes with many participants, I would still evaluate Temporal. For straightforward orchestration within an existing Dapr deployment, the built-in workflow engine is often sufficient.
The Actor Model
The virtual actor building block is one of Dapr’s more distinctive features. If you have never worked with the actor model, the core idea is that each actor is a stateful object with a unique identifier. The Dapr runtime activates an actor instance on demand, routes calls to it, and deactivates (garbage-collects) it when it has been idle for a configurable period.
Critically, Dapr guarantees only one active instance of each actor at a time, which eliminates the need for distributed locks for per-entity operations. Multiple services can call actor/ShoppingCart/user-123/addItem concurrently and Dapr serializes the calls to that specific actor instance.
This is powerful for scenarios like:
- IoT device state (one actor per device, millions of devices)
- Shopping carts (one actor per cart, activated on first access)
- Rate limiting (one actor per user/IP, tracking request counts)
- Game session state (one actor per game session)
The actor state is automatically persisted to the configured state store. Calling self.state_manager.set("cart", items) inside an actor method persists to Redis or DynamoDB or wherever your state store is configured.
Running Dapr in Production
When I first deployed Dapr to production, the sidecar memory overhead surprised me. Each Dapr sidecar consumes roughly 50-80MB of memory by default, depending on the components loaded. On a cluster with two hundred pods, that is 10-16GB of memory overhead just for sidecars.
Tuning the component loading helps. By default, Dapr loads all configured components into every sidecar. You can scope components to specific app IDs to prevent every pod from loading every component:
scopes:
- order-service
- payment-service
Only pods with those app IDs will load the component, which reduces both memory consumption and the blast radius if a component configuration is misconfigured.
The mTLS configuration is important to review before you go to production. Dapr generates its own root certificate authority at install time, with a default validity of one year. That one-year expiry has caught teams off guard. I recommend setting up external certificate management through cert-manager or your PKI infrastructure before you hit production, not after. The Dapr documentation covers this but it is buried deep.
Observability works well out of the box. Dapr emits OpenTelemetry traces automatically for all API calls, which pairs with whatever tracing backend you are running. Prometheus metrics come included. You get request latency, error rates, and actor activation metrics without writing any instrumentation code. If you are running the Prometheus/Grafana observability stack, Dapr’s metrics slot in with minimal configuration.
Dapr and GitOps
Dapr’s component CRDs are just Kubernetes resources, which means they are first-class citizens in a GitOps workflow with ArgoCD or Flux. The component definitions live in your infrastructure repository alongside your Deployments and Services. Environment-specific components (dev uses Redis on port 6379, production uses ElastiCache on a private endpoint) live in environment-specific overlays.
This separation of concern, application code in one repo, infrastructure components in another, enforced by the Dapr API boundary, is one of the cleanest things about the architecture. Developers cannot accidentally hardcode a Redis connection string because there is no Redis connection string in the application code to hardcode.
When Dapr Is Worth It
Dapr adds complexity. There is no pretending otherwise. You are adding a sidecar to every pod, learning a new set of CRDs and component configurations, debugging through an additional network hop, and accepting that all your Dapr API calls go through localhost.
It pays for itself in these situations:
Polyglot teams. When you have services in Go, Python, Java, and Node, the alternative to Dapr is maintaining idiomatic, well-configured SDK integrations in every language. The Dapr HTTP/gRPC API is language-agnostic. Write once, use everywhere.
Infrastructure migration. If you are moving from on-premises Kafka to AWS MSK, or from self-managed Redis to ElastiCache, Dapr’s component model turns a code migration into a configuration migration. I have seen this argument alone justify Dapr adoption for teams doing cloud migrations.
Regulated environments. When your secrets, state, and messaging must route through specific approved infrastructure, the Dapr component model makes compliance auditing easier. You audit the components, not every service’s SDK configuration.
Building new microservices. Greenfield services on Dapr avoid the “let me copy the Redis client setup from that other service” problem from day one.
When Dapr Is Probably Not Worth It
Small teams with one or two services in a single language do not need Dapr’s abstraction layer. The complexity overhead is not justified when you can just configure a Redis client directly and be done in thirty minutes.
Latency-sensitive hot paths should not use Dapr without benchmarking. The localhost network hop through the sidecar adds a few hundred microseconds. For most operations this is invisible. For a service calling Redis ten thousand times per second with single-digit millisecond latency requirements, that overhead is measurable.
Legacy services you are not actively modifying are poor candidates for Dapr adoption. The migration cost of instrumenting a stable service that works fine is rarely worth it unless you are rewriting it anyway.
The Ecosystem in 2025
Dapr has a rich component catalog. At last count, there are over 100 pluggable components spanning state stores, pub/sub brokers, bindings, and secret stores. The quality varies. The core components (Redis, Kafka, AWS services, Azure services) are battle-tested. Some of the less-used components have rough edges.
The multi-app run feature, which lets you start multiple Dapr applications locally with a single manifest file, has dramatically improved the local development experience. You define all your services and their Dapr configurations in a single YAML, run dapr run -f dapr.yaml, and your entire service mesh starts locally. Combined with Docker Compose for dependent services (Kafka, Redis, Postgres), this gives you a production-like environment on a laptop.
The workflow engine, introduced in Dapr 1.10, is still maturing. The API stabilized in 1.14, and I would now consider it production-ready for straightforward workflows. Complex workflows with hundreds of parallel activities or workflows that run for months should still be validated carefully.
Dapr’s actor model, by contrast, is very mature and has been used in production at significant scale (Microsoft’s Azure IoT Hub uses a variation of it internally). If the virtual actor pattern fits your use case, it is one of the most reliable parts of Dapr.
Getting Started
The quickest way to evaluate Dapr is locally with Docker and the Dapr CLI:
# Install Dapr CLI
wget -q https://raw.githubusercontent.com/dapr/cli/master/install/install.sh -O - | /bin/bash
# Initialize Dapr with Docker containers for Redis and Zipkin
dapr init
# Run a service with Dapr sidecar
dapr run --app-id myapp --app-port 8080 -- python app.py
This gives you a local Redis for state and pub/sub, a Zipkin instance for tracing, and a Dapr runtime. The quick-start guides on the Dapr website are genuinely good and cover the core building blocks with working code examples in multiple languages.
For production Kubernetes deployment, the Helm chart is the standard approach. Dapr’s Helm chart has good defaults but the cert-manager integration for certificate rotation is worth setting up before you scale.
The Bottom Line
Dapr earned its CNCF graduation. Twenty years of distributed systems work has taught me that the hardest problems are not the business logic ones. They are the “which version of the Kafka client works with this broker, and why is our retry logic slightly different in the Go service than the Java service” problems. Dapr takes a credible swing at solving that class of problem.
It is not the right choice for every team. But if you are running a polyglot service landscape, planning infrastructure migrations, or building greenfield services that will need to talk to multiple backing systems, Dapr’s building block model is worth a serious evaluation. The abstractions hold up in production, and the pluggable component model delivers on its promise in ways that most cross-cutting frameworks do not.
The sidecar overhead is real. The learning curve for the component model is real. The payoff, when your team can swap a state store backend through a config file change and redeploy, is also real.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.