Three years ago, I was brought in to help a financial services company figure out why their overnight reports were wrong. Not subtly wrong. Catastrophically wrong: risk numbers that were off by tens of millions of dollars. The underlying cause turned out to be a single upstream transformation that a junior engineer had quietly modified six months earlier to handle a new data source. Nobody knew that transformation fed thirty other downstream pipelines. Nobody knew because nobody had a data catalog.
We found the bug eventually. It took four people three days of manual tracing through Confluence docs, Jira tickets, and old Slack messages to reconstruct the lineage. The actual fix took about twenty minutes. That experience changed how I think about data infrastructure. A catalog and lineage system is not optional tooling for mature organizations. It is the prerequisite for operating a data platform without burning your team on incidents.
After twenty years watching organizations build data infrastructure, I have seen this pattern repeat endlessly: teams invest heavily in ingestion, storage, and transformation, then treat metadata as an afterthought. The data lake fills up with thousands of tables nobody can find. Pipelines break in ways nobody can trace. Engineers spend more time answering questions about data than actually engineering.
This article covers the architecture of data catalogs and lineage, the two most serious open-source options (OpenMetadata and DataHub), the emerging OpenLineage standard that connects everything, and how to integrate these tools into a real production data stack.
What a Data Catalog Actually Is
A data catalog is not a spreadsheet. It is not a wiki where you paste table schemas. It is not a README in your dbt project. Those are documentation; a catalog is active, connected metadata infrastructure.
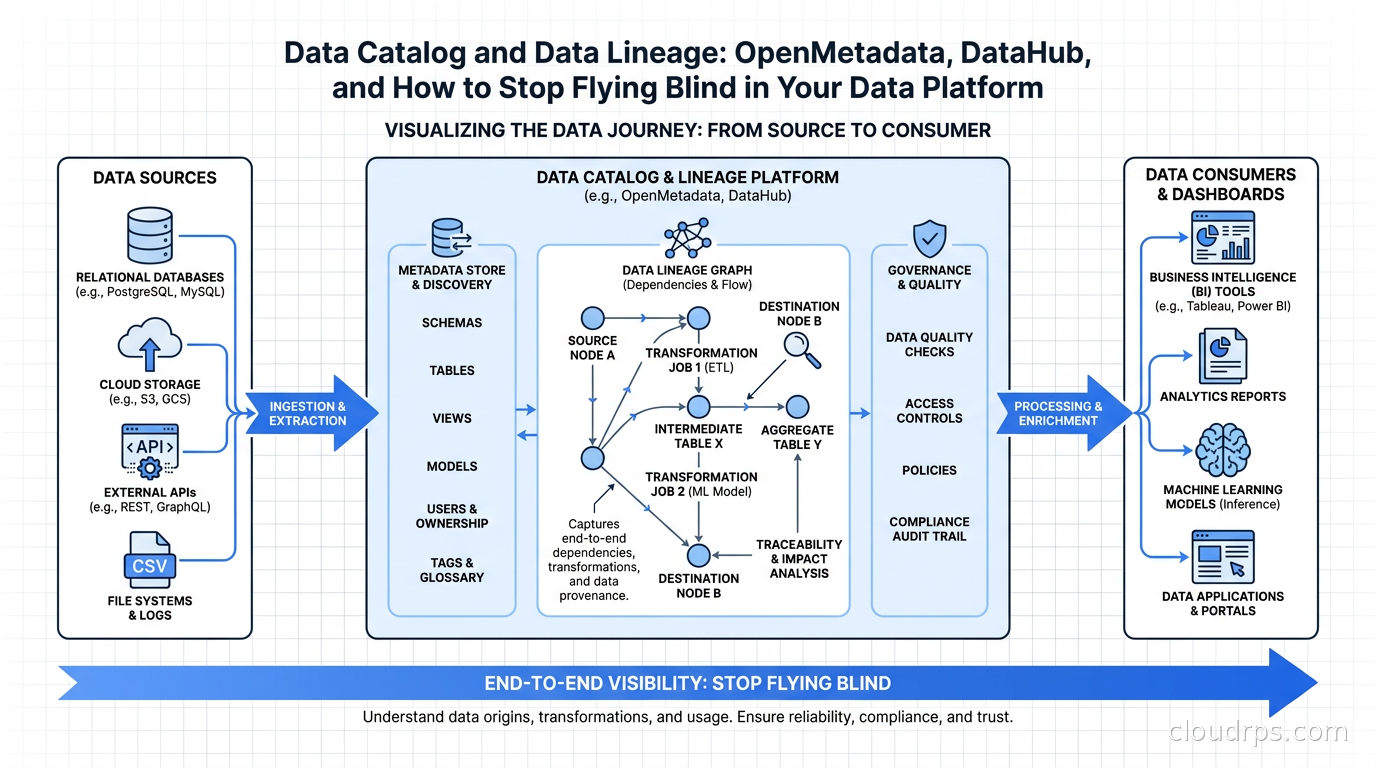
A production-grade data catalog does four things:
Discovery: Engineers can search for datasets by name, description, owner, tag, or column name. You type “customer revenue” and get back every table and view in your platform that contains revenue data for customers, ranked by usage and freshness.
Context: Each asset carries metadata beyond just the schema. Ownership (who is the responsible team), quality (does this table pass its SLA, when was it last updated), classification (does it contain PII, is it GDPR-sensitive), and relationships (what upstream sources feed this, what downstream pipelines depend on it).
Governance: Access control policies, data retention tags, and compliance annotations are maintained in the catalog alongside the technical metadata. When your privacy team needs to answer “where do we store customer email addresses,” they can query the catalog instead of interrogating six different teams.
Lineage: This is the piece most people underestimate. Column-level lineage answers: if this source column changes, which downstream dashboards and models break? Which transformations touch PII fields? Which reports depend on this Kafka topic?
The catalog connects to your sources via crawlers and integrations. It does not store the data itself; it stores metadata about the data and the relationships between data assets.
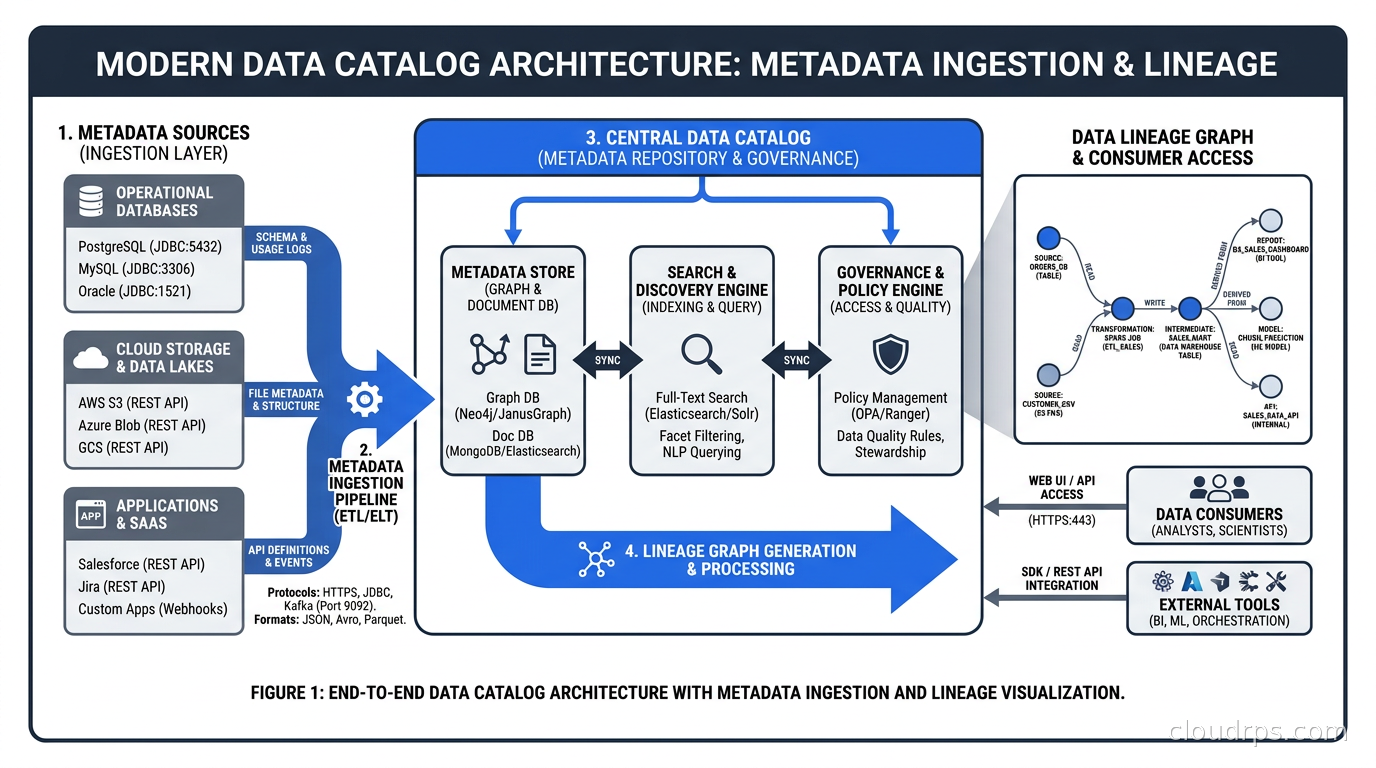
Data Lineage: The Feature You Need Before You Realize You Need It
Table-level lineage tells you “this dashboard reads from table A, which is produced by job B.” It is useful. Column-level lineage tells you “this revenue metric is computed from column unit_price in table A joined to quantity in table B, which originates from a CDC stream off the transactions database.” That is a different class of information.
Column-level lineage is what makes impact analysis tractable. When a schema change propagates through your stack, you need to know exactly which downstream assets will break, not just which jobs touch the same tables. When a data quality check fails on an upstream source, you need to know which reports to take offline while you fix it.
Lineage also matters for compliance. GDPR and CCPA require that you can demonstrate how personal data flows through your systems. “We have an audit log somewhere” is not sufficient for regulators. A lineage graph that traces PII from ingestion through every transformation to every output surface is.
The traditional approach to capturing lineage was to parse SQL queries manually or require engineers to annotate pipelines by hand. Both approaches fail at scale. Parsing SQL is fragile; hand annotation rots as soon as the pipeline changes. The modern approach is to emit lineage events automatically as pipelines execute, using a standard protocol.
This is where OpenLineage enters the picture.
OpenLineage: The Standard That Finally Got Traction
OpenLineage is an open standard for lineage data collection. Think of it as what OpenTelemetry is to observability traces: a vendor-neutral protocol that tools emit and catalogs consume. Instead of every orchestrator and transformation tool inventing its own lineage format, OpenLineage defines a common event schema.
An OpenLineage event captures: the job that ran, the input datasets it consumed, the output datasets it produced, and rich facets covering schema, column-level lineage, data quality assertions, and custom metadata. Airflow, dbt, Spark, Flink, Great Expectations, and a growing list of other tools now ship OpenLineage integrations out of the box.
The practical benefit is that you can mix tools. You might have Airflow orchestrating Spark jobs that write to Iceberg tables that dbt models then transform. With OpenLineage, each tool emits lineage events to a common endpoint, and your catalog stitches together the full end-to-end graph without requiring anyone to manually document the connections.
OpenLineage events are sent to a Marquez-compatible API. Marquez is the reference implementation: a lightweight lineage service with a Postgres backend that accepts events and provides a search and visualization API. Many organizations use Marquez as the collection layer, then feed its data into a heavier catalog like DataHub or OpenMetadata for governance and discovery features.
If you are building a modern data stack and are not yet emitting OpenLineage events, start there before evaluating catalog tools. The cataloging is much easier once lineage is flowing automatically.
For teams already using Apache Iceberg tables and modern orchestration, OpenLineage integrates cleanly with both Airflow and Spark through existing plugins.
OpenMetadata: The API-First Challenger
OpenMetadata launched in 2021 and has rapidly become the most active open-source catalog community. Its distinguishing characteristic is that everything is an API. The entire metadata model is defined in a formal JSON schema standard, every entity type (tables, pipelines, dashboards, ML models, containers, databases) is a first-class object with a typed API, and the catalog is primarily a system for other systems to integrate with rather than a GUI for humans to click around in.
The architecture is simpler than DataHub. OpenMetadata uses a single Postgres instance as the primary metadata store. No Kafka, no Elasticsearch required by default (though Elasticsearch can be added for search). This makes it significantly easier to run in production: a single deployment with a handful of containers, and you are operational.
The connector ecosystem is extensive. OpenMetadata ships over 80 connectors covering cloud data warehouses (Snowflake, BigQuery, Redshift, Databricks), databases (Postgres, MySQL, SQL Server), orchestrators (Airflow, Dagster, dbt), BI tools (Looker, Tableau, Metabase, PowerBI), messaging (Kafka, Redpanda), and ML platforms (MLflow, SageMaker). Connectors run as scheduled ingestion workflows that pull metadata from each source on a configurable cadence.
Column-level lineage is a particular strength. OpenMetadata parses SQL from your transformation tools (particularly dbt) and constructs column-to-column lineage graphs automatically. Combined with OpenLineage emission from Airflow and Spark, you get quite complete lineage coverage across most modern data stacks.
The governance features are solid for an open-source tool: role-based access control, glossary terms (so “revenue” means the same thing across your entire organization), data classification (tagging columns with sensitivity levels), and data quality integration (connecting Great Expectations or dbt test results to table metadata).
The UI is modern and usable. Engineers can search, browse, see lineage visually, annotate tables with descriptions, and set ownership. Non-engineers can find datasets without filing a ticket to the data team.
One real limitation: OpenMetadata’s governance enforcement is lighter than DataHub’s. You can annotate and classify, but if your organization needs approval workflows for schema changes or fine-grained policy enforcement tied to access control decisions, you will hit gaps. For most data engineering teams, this is fine. For organizations with heavy compliance requirements, it matters.
DataHub: LinkedIn’s Battle-Tested Approach
DataHub originated inside LinkedIn, was open-sourced in 2019, and formally separated from LinkedIn into an independent project in 2025. LinkedIn’s scale shaped the architecture significantly: DataHub is built around Kafka for event streaming, Elasticsearch for search, and a graph database model (running on top of Elasticsearch or a dedicated graph store) for representing metadata relationships.
The graph model is DataHub’s conceptual foundation. Every entity in your data platform (a Snowflake table, a dbt model, a Looker dashboard, a Kafka topic, a feature in a feature store) is a node in a graph, and relationships between entities are edges. Lineage is a specialized set of edges. The graph representation makes certain queries very fast: “show me all downstream dependencies of this table” is a graph traversal, and graph stores are optimized for exactly that.
DataHub’s ingestion works via Metadata Change Proposals (MCPs): structured events that describe metadata changes, which are emitted to a Kafka topic and consumed by DataHub’s backend services. This event-driven approach means DataHub naturally supports real-time metadata updates. When a dbt run completes and emits lineage events, they appear in DataHub within seconds.
The governance capabilities are more mature than OpenMetadata. DataHub supports fine-grained access control, governance policies that determine who can see or modify which datasets, approval workflows for sensitive data access requests, and structured governance programs. If you are in a regulated industry where metadata management is subject to audit, DataHub’s governance depth is an advantage.
DataHub also has strong ML and AI lineage support. MLflow, SageMaker, and Kubeflow integrations allow you to track which datasets trained which models, connect model versions to their feature sources, and trace the data provenance of production predictions. For organizations building serious ML platforms, this is a real differentiator.
The operational overhead is the honest downside. A production DataHub deployment requires Kafka, Zookeeper, Elasticsearch, MySQL or Postgres, and several DataHub-specific services. That is a meaningful amount of infrastructure to maintain. The DataHub team offers a managed cloud version (DataHub Cloud) that handles this, but self-hosted DataHub at scale requires real operational investment.
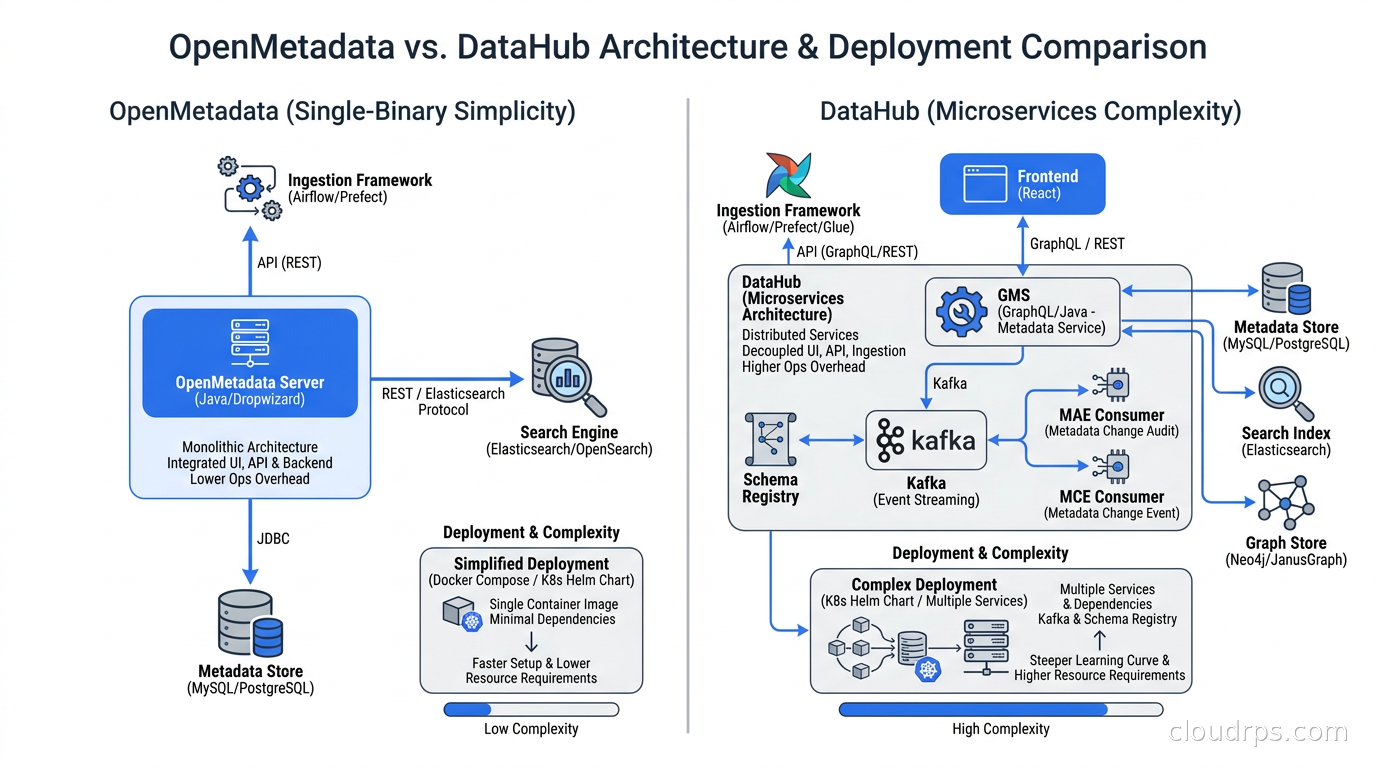
Head-to-Head: How to Choose
The choice between OpenMetadata and DataHub is not which is better; it is which architectural tradeoff fits your situation.
Choose OpenMetadata if: You want to get to production in a day. Your stack is modern (dbt, Airflow, Snowflake or BigQuery, maybe Iceberg). Your team does not have platform engineering capacity to maintain a Kafka-backed system. You need strong lineage and discovery but do not have heavy governance requirements. OpenMetadata’s simplicity is a genuine advantage for teams that want catalogs without catalog operations becoming a job.
Choose DataHub if: You have a complex, heterogeneous environment that spans many different systems including older tools. You have governance and compliance requirements that need approval workflows and audit trails. You are running ML at scale and need model provenance tied to data lineage. You have the engineering capacity to run a more complex system, or you plan to use DataHub Cloud. DataHub’s maturity and feature depth are real, and they matter for certain organizational contexts.
Both tools integrate with OpenLineage, both support dbt integration for SQL lineage, and both have APIs that let you build custom integrations. Neither decision is irreversible.
A decision I have seen work well at mid-sized organizations: start with Marquez for lineage collection from Airflow and Spark (lightweight, easy to run), integrate dbt with its native catalog output, and then evaluate OpenMetadata or DataHub once your team has a clearer sense of what governance features you actually need. Starting with a heavy catalog before you have good lineage flowing is backwards.
Integrating with Your Existing Stack
The catalog does not live in isolation. It integrates with every layer of your data platform.
dbt integration is typically the highest-value first integration. Both OpenMetadata and DataHub have native dbt parsers that ingest model definitions, test results, column descriptions, and SQL-derived lineage from your dbt project. The result is that every dbt model appears in the catalog with its columns, its documentation, its test pass/fail status, and its full lineage graph automatically. Teams using dbt for analytics engineering get most of their catalog populated for free.
Airflow integration captures pipeline-level lineage. OpenLineage’s Airflow provider instruments your DAGs to emit input/output dataset information for each task. Combined with dbt lineage, you can trace data from the source system through Airflow orchestration through dbt transformations to downstream dashboards.
Apache Iceberg tables register in the catalog as first-class assets, with partition specs, snapshot history, and schema evolution tracked as metadata. If you are using Iceberg with Spark or Trino, the catalog becomes the authoritative metadata store for table schemas across different query engines. This matters especially for data lakehouse architectures where the same tables are queried by multiple engines.
Kafka and streaming is where lineage gets interesting. OpenLineage supports streaming datasets, so Kafka topics appear as input/output nodes in your lineage graph alongside batch datasets. This closes the gap for organizations that mix streaming and batch, which is increasingly common. For teams running Apache Flink for stream processing, this means your real-time pipelines are visible in the same lineage graph as your batch jobs.
Data quality integration connects test results to the catalog. Great Expectations and dbt test outcomes can be pushed to both OpenMetadata and DataHub, so quality status is visible alongside discovery and lineage metadata. When a table fails a data quality check, it shows up in the catalog as degraded, and downstream teams can see it before they pull data for their dashboards.
This integration with data observability tooling is what makes the catalog a live system rather than a static documentation layer. The metadata updates as your pipelines run.
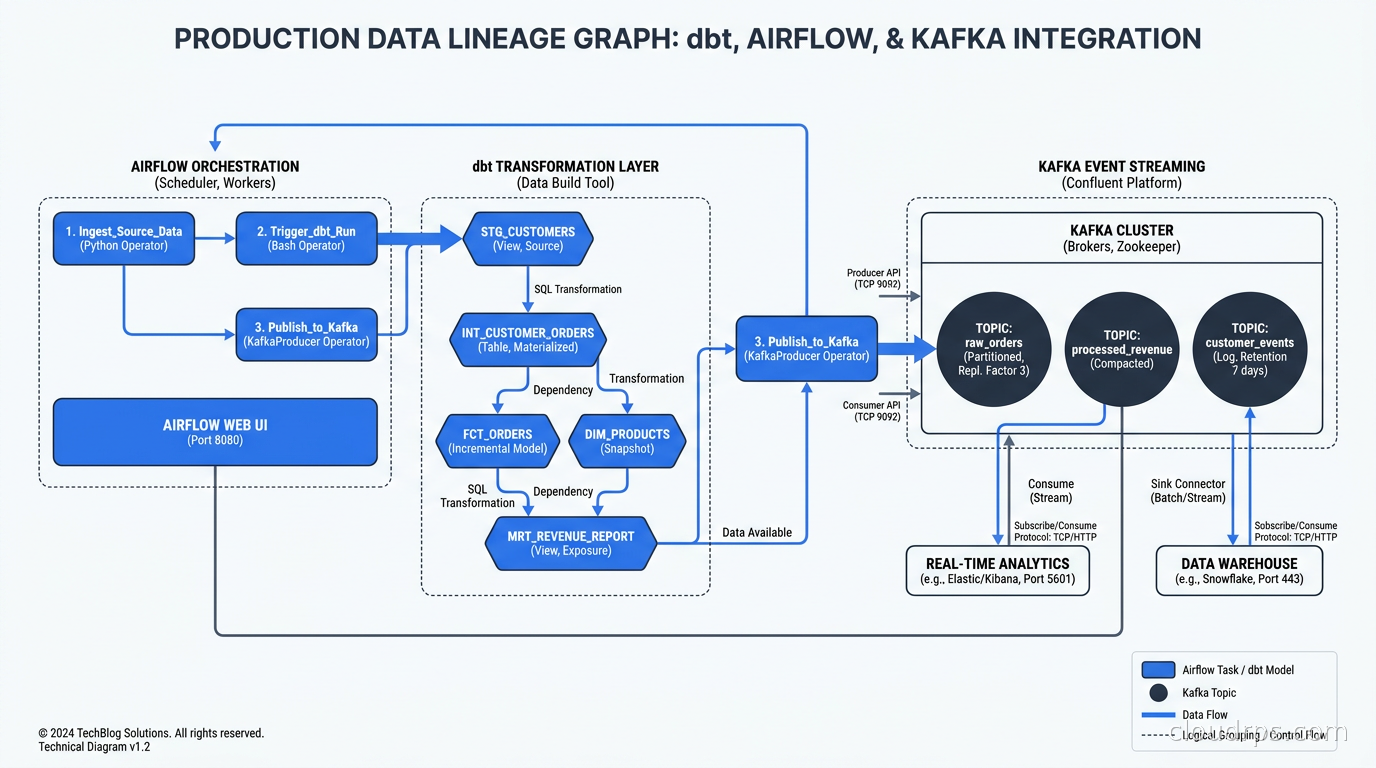
Production Deployment Considerations
Running a catalog in production means thinking about availability, performance, and the metadata ingestion pipeline.
For OpenMetadata: the minimal production setup is two instances of the OpenMetadata server behind a load balancer, a Postgres primary with read replica, and Elasticsearch for full-text search. Kubernetes deployment via the Helm chart is well-documented and works reliably. Persistent volume claims for Elasticsearch are the main operational concern. Total resource footprint at moderate scale (100-500 data assets) is modest: a few GB of memory across services.
For DataHub: plan for more. A production DataHub deployment needs Kafka (at least three brokers for durability), Elasticsearch, MySQL or Postgres, and at minimum four DataHub-specific pods (GMS, MAE Consumer, MCE Consumer, Frontend). At large scale (thousands of assets, frequent metadata updates), Kafka becomes the operational complexity center: topic sizing, consumer lag monitoring, and partition tuning. If your platform team does not have Kafka operational experience, DataHub Cloud is worth considering seriously.
Both tools benefit from having a dedicated ingestion scheduler. OpenMetadata has one built in; for DataHub the datahub-actions framework handles automated ingestion. Build your ingestion schedules to run after your pipeline windows complete, not on fixed hourly schedules that may produce stale metadata if pipelines are delayed.
Schema and metadata freshness is a common failure mode. If your catalog shows yesterday’s schema for a table that changed this morning, engineers stop trusting the catalog and stop using it. Frequent, automated ingestion is more important than fancy features.
For teams thinking about data ownership and data mesh architecture, the catalog becomes the registry where domain teams publish their data products. OpenMetadata and DataHub both support the concept of data products as first-class entities, with ownership, SLAs, and consumption contracts attached.
When to Move to a Commercial Catalog
Open-source catalogs work well for many organizations. But there are specific triggers where commercial options (Atlan, Collibra, Alation, Secoda) are worth the cost.
The first trigger is governance enforcement at scale. Open-source catalogs let you annotate data with policies. Commercial catalogs integrate those policies into access control decisions: the catalog determines what you can see, not just labels data with what you should see. If regulators are asking you to prove that access to sensitive data is controlled at the metadata layer, commercial governance capabilities close that gap.
The second trigger is AI-powered metadata. Generating descriptions for thousands of undocumented tables is tedious. Commercial catalogs have invested heavily in LLM-assisted metadata generation: auto-describe tables based on column names and sample data, auto-suggest tags, auto-detect PII. The open-source tools have some of this, but the commercial implementations are more polished.
The third trigger is support burden. If your data team is spending meaningful engineering time maintaining catalog infrastructure rather than building data products, the operational cost of self-hosting has exceeded the licensing cost of a managed service.
For ML operations teams specifically, model lineage (tracing predictions back to their training data and feature sources) is a governance requirement that commercial platforms handle better than most open-source options.
What This Actually Changes
In the financial services incident I opened with, we eventually built out a DataHub instance connected to the firm’s Hive, Spark, and BI layer. The next time a transformation changed unexpectedly, the on-call engineer ran a lineage query in DataHub and had the full impact analysis in about ninety seconds. What previously took four people three days became a ninety-second query.
That is the business case for a data catalog. Not better documentation. Faster incident response, shorter blast radius assessment, clearer ownership when something breaks, and actual visibility into where data goes in your platform.
The tooling for this is mature and open-source. OpenMetadata or DataHub will serve most organizations well. OpenLineage means lineage collection is no longer a bespoke integration project; it is a configuration setting in Airflow and a dbt command. The barrier to getting a catalog running is lower now than it has ever been.
The only real mistake is treating catalog infrastructure as something you will add later, once the platform matures. Lineage and discovery need to be wired in from the beginning. Retrofitting them into a data platform with hundreds of existing undocumented pipelines is significantly harder than building them in from day one.
For teams working through data contract implementation, the catalog is the natural home for publishing and enforcing those contracts. The metadata infrastructure and the data contract machinery are the same infrastructure.
Start with OpenLineage emission from your orchestrators. Get dbt connected to your catalog of choice. Then watch your team’s incident response time drop.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.