The worst data quality incident I have ever been involved in did not involve a bad ETL job or a schema migration gone wrong. It involved a perfectly reasonable backend engineer who renamed a column in a PostgreSQL table from user_country to country_code. Totally sensible normalization. The column still existed. The data was still there. The change was deployed on a Tuesday afternoon.
By Thursday morning, the company’s fraud detection model had been silently ingesting null values for two days because the feature pipeline consumed that column by name. The model’s fraud flag rate dropped to near-zero. Accounts that should have been flagged were approved. The discovery came from a business analyst who noticed the numbers looked weird during a weekly review. The actual damage was only partially recoverable.
That incident introduced me to the concept of data contracts, and I have been a believer ever since.
What a Data Contract Actually Is
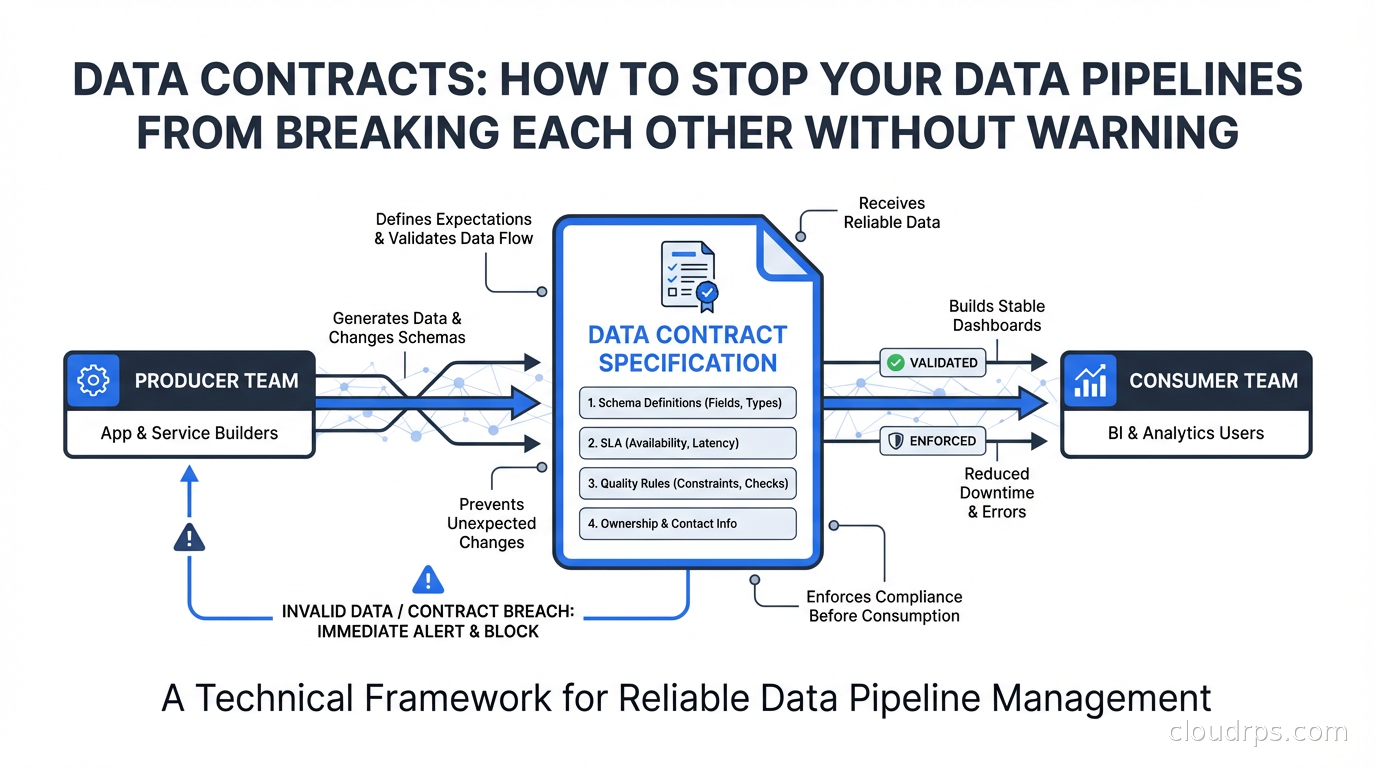
A data contract is a formal, versioned agreement between a data producer (a team, service, or system that generates or stores data) and one or more data consumers (pipelines, analytics, ML features, dashboards) that specifies exactly what the data looks like and what guarantees the producer makes about it.
At minimum, a data contract specifies:
- Schema: field names, types, nullability, and expected formats
- Semantics: what each field actually means (not just the type, but the business definition)
- Quality rules: expected value ranges, uniqueness constraints, referential integrity
- SLA: freshness guarantees (the data will be updated at least every N minutes), availability (this dataset will exist)
- Versioning policy: how the producer will communicate breaking changes and how much notice consumers get
Contracts are the difference between implicit coupling (everyone hoping the producer does not change things) and explicit coupling (a machine-readable agreement that can be validated, version-controlled, and monitored).
This is not a new idea. APIs have had formal contracts for decades. OpenAPI/Swagger describes REST interfaces. Protobuf and gRPC describe service contracts. Data engineers are just late to the party, largely because data has historically moved through pipelines in weakly typed formats (CSV files, untyped JSON) where schema enforcement was optional.
Why Data Teams Are Adopting Contracts Now
Two converging trends are driving adoption. First, data mesh architecture distributes data ownership to domain teams. When the payments team owns their data products and the fraud team consumes them, you need a formal interface. The mesh model without contracts creates a support nightmare where every downstream breakage turns into a finger-pointing session between teams.
Second, data observability tooling has matured enough to detect quality failures automatically. But detection after the fact is still reactive. Contracts shift quality enforcement upstream, to the point where a producer’s code changes are validated against consumer expectations before they ship.
The combination is powerful: data mesh defines ownership, data contracts define interfaces, data observability monitors compliance. Without all three, each independently is less effective.
The Anatomy of a Data Contract
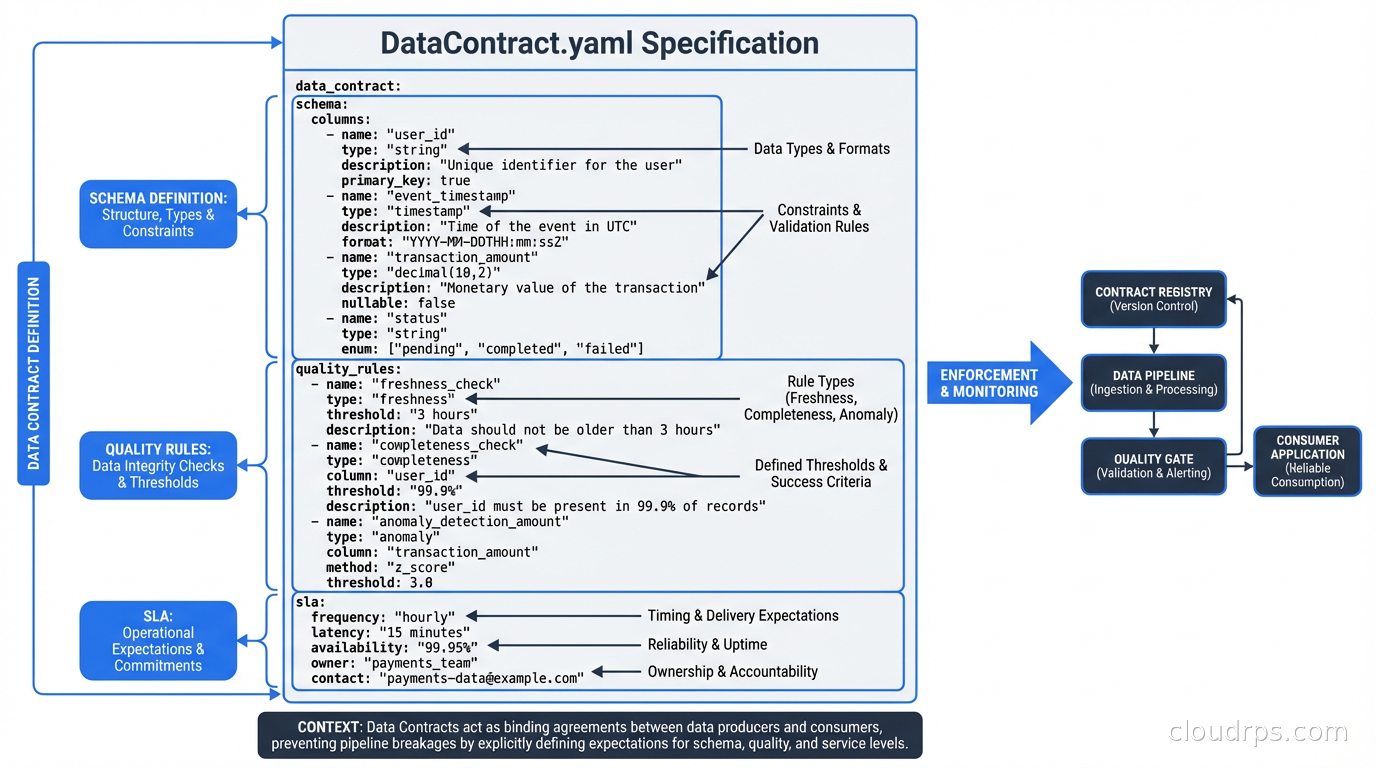
Let me show you what a concrete contract looks like. The Data Contract Specification (DCS), an emerging open standard backed by multiple vendors, defines contracts as YAML:
dataContractSpecification: 0.9.3
id: payments.transaction-events.v2
info:
title: Payment Transaction Events
version: 2.1.0
owner: payments-team@company.com
description: Stream of payment transaction events emitted after authorization
servers:
production:
type: kafka
host: kafka.company.internal:9092
topic: payments.transactions
models:
transaction:
fields:
transaction_id:
type: string
required: true
unique: true
description: UUID v4 identifier for the transaction
amount_cents:
type: integer
required: true
minimum: 1
description: Transaction amount in cents, always positive
currency_code:
type: string
required: true
pattern: "^[A-Z]{3}$"
description: ISO 4217 three-letter currency code
country_code:
type: string
required: true
pattern: "^[A-Z]{2}$"
description: ISO 3166-1 alpha-2 country code of card issuer
status:
type: string
required: true
enum: ["authorized", "declined", "pending"]
quality:
type: SodaCL
specification:
checks for transaction:
- row_count > 1000: # Per 5-minute window
name: Minimum transaction volume
- missing_count(transaction_id) = 0
- duplicate_count(transaction_id) = 0
- invalid_count(amount_cents) = 0:
valid min: 1
The schema section defines the data model. The quality section defines SLAs. Both are machine-readable. Both can be executed in CI before a producer deploys changes.
If that payments engineer had a contract specifying country_code as a required string field, the rename from user_country to country_code would have been a contract-compatible change (the field exists with the right type). But if they had tried to remove the field or rename it to something else, a contract test run in CI would have caught it.
Tooling: Where the Theory Meets Practice
Several tools have emerged to make contracts operational rather than documentation-only:
Soda has built contract specification and testing directly into their platform. soda scan can validate data against contract-defined quality rules on a schedule or in CI. Soda’s contract tests run against the actual data, not just the schema definition, meaning you catch value-level violations (amounts below minimum, invalid currency codes) not just structural ones.
Great Expectations takes a test-first approach to data quality with “Expectation Suites” that look similar to contracts. It is more mature as a standalone quality tool, though its integration into the producer/consumer workflow requires more manual wiring. If you are already using it for data observability, extending it to cover contract use cases is tractable.
dbt contracts (introduced in dbt 1.5) allow you to enforce model contracts directly in your dbt transformation layer. When you declare a model’s contract, dbt will fail if a run would change column names or types in ways that break the contract:
models:
- name: fct_transactions
config:
contract:
enforced: true
columns:
- name: transaction_id
data_type: varchar
constraints:
- type: not_null
- type: unique
- name: amount_cents
data_type: integer
constraints:
- type: not_null
dbt contracts are schema contracts only; they do not enforce value-level quality rules. You still need Soda or Great Expectations for the quality SLA layer. But for SQL-based transformation teams, dbt contracts are a low-friction starting point.
Confluent Schema Registry handles contracts for Kafka-based event streams. It enforces Avro, Protobuf, or JSON Schema compatibility rules at the broker level. Producers cannot publish messages that violate the registered schema. This is the most automated form of contract enforcement: the infrastructure refuses non-compliant events before they ever reach consumers. The IBM acquisition of Confluent has changed the vendor risk calculus for Schema Registry, and there are now production-grade alternatives worth evaluating. For a deep dive on compatibility modes, Avro vs Protobuf trade-offs, and how to choose between Confluent, Apicurio, and AWS Glue Schema Registry, see the Kafka Schema Registry production guide.
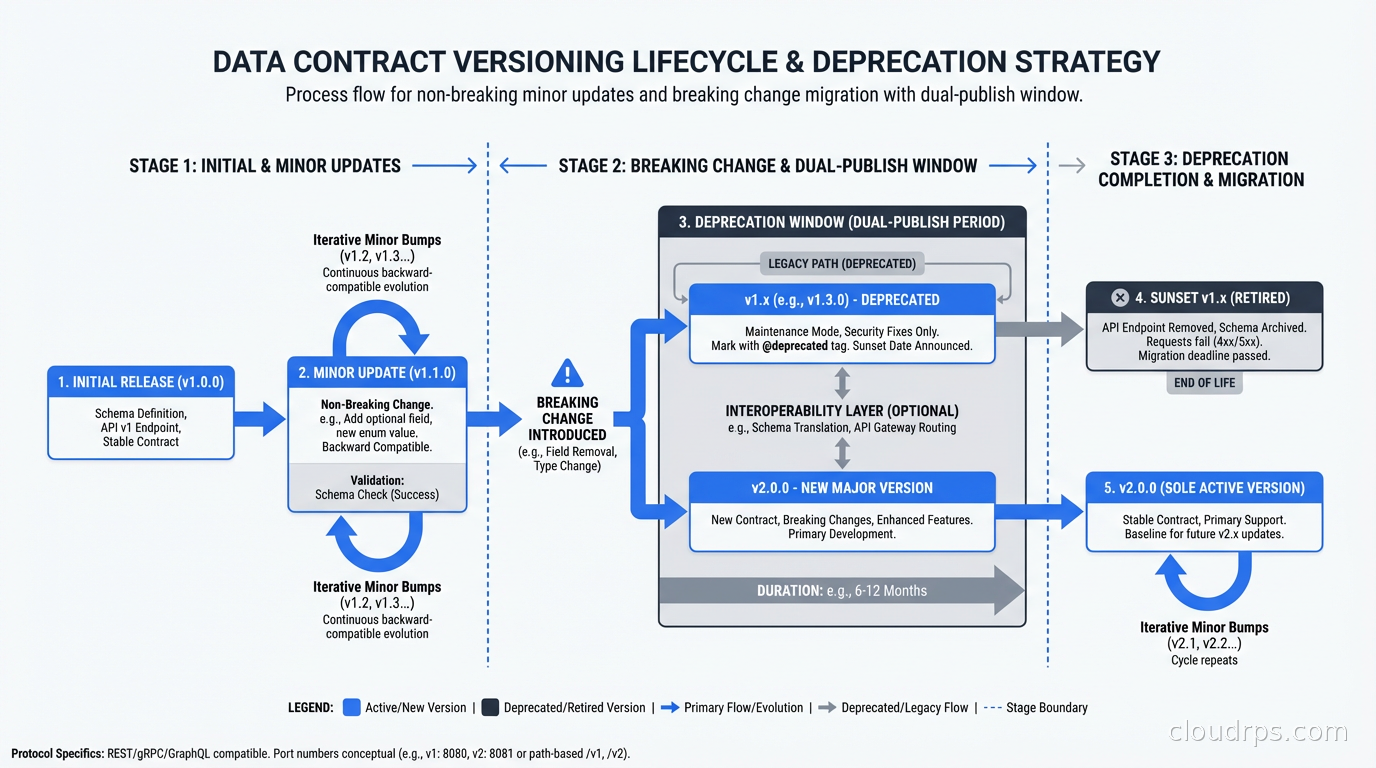
The Versioning Problem: Breaking vs. Non-Breaking Changes
Contracts only provide value if they have a clear versioning policy. Without one, you end up in negotiations every time a producer wants to change anything.
Non-breaking (backward-compatible) changes:
- Adding an optional field with a default value
- Relaxing a constraint (making a required field optional)
- Widening a type (int32 to int64)
Breaking changes:
- Removing a field
- Renaming a field
- Changing a type in a narrowing way (string to enum with specific values)
- Tightening a constraint (optional field becomes required)
The policy I recommend: non-breaking changes can ship with a minor version bump and no consumer notification required. Breaking changes require a major version bump, a deprecation period (I use 30 days minimum, 90 days for high-traffic consumers), and explicit consumer acknowledgment before the old version is retired.
During the deprecation window, the producer ideally runs both versions simultaneously. For Kafka topics, this means publishing to a new topic version while keeping the old one active. For database tables, it means keeping the old column while adding the new one. Change data capture tools like Debezium can help produce both formats from the same source of truth during transition periods.
The dual-publish approach is operationally more expensive than a hard cutover, but it decouples producer and consumer deployment timelines. The payments team can ship their breaking change without coordinating a synchronized deployment with every downstream team.
Who Owns What: The Social Contract Alongside the Technical One
The technical contract is the easier half. The organizational model is harder.
The clearest model I have seen: producers own their contracts and are accountable for not breaking them without notice. Consumers register their dependencies against contracts. A central data platform team maintains the registry and tooling. The platform team does not own the data or the contracts; they own the infrastructure that makes contracts discoverable and enforceable.
This sounds obvious but breaks down in practice when:
- Producers argue that a change is “not really breaking” because it is easy to adapt
- Consumers are slow to migrate off deprecated versions and block producer evolution
- No one is accountable when a contract violation slips through because the CI check was not mandatory
The fixes: make contract CI checks mandatory, not advisory. Set clear deadlines for consumer migration that are enforced by the platform team, not negotiated indefinitely. Treat contract violations in production with the same severity as API outages.
I have watched companies spend six months rolling out a data catalog and then see it ignored because publishing to the catalog was optional. Contracts only work if they are required. The first team that ships a breaking change without updating their contract and it causes a production incident is the forcing function that makes everyone else take it seriously.
Integrating Contracts Into Your Data Platform
In a modern data platform built on Apache Iceberg for table format and dbt for transformations, contracts fit naturally at two layers:
The source layer (raw data ingested from operational systems) needs contracts that define what the upstream APIs and databases are expected to produce. Change data capture pipelines from Debezium can be validated against these contracts before data lands in the lake.
The serving layer (marts and aggregates consumed by BI tools and ML models) needs contracts that specify what the downstream consumers depend on. dbt model contracts enforce these at build time.
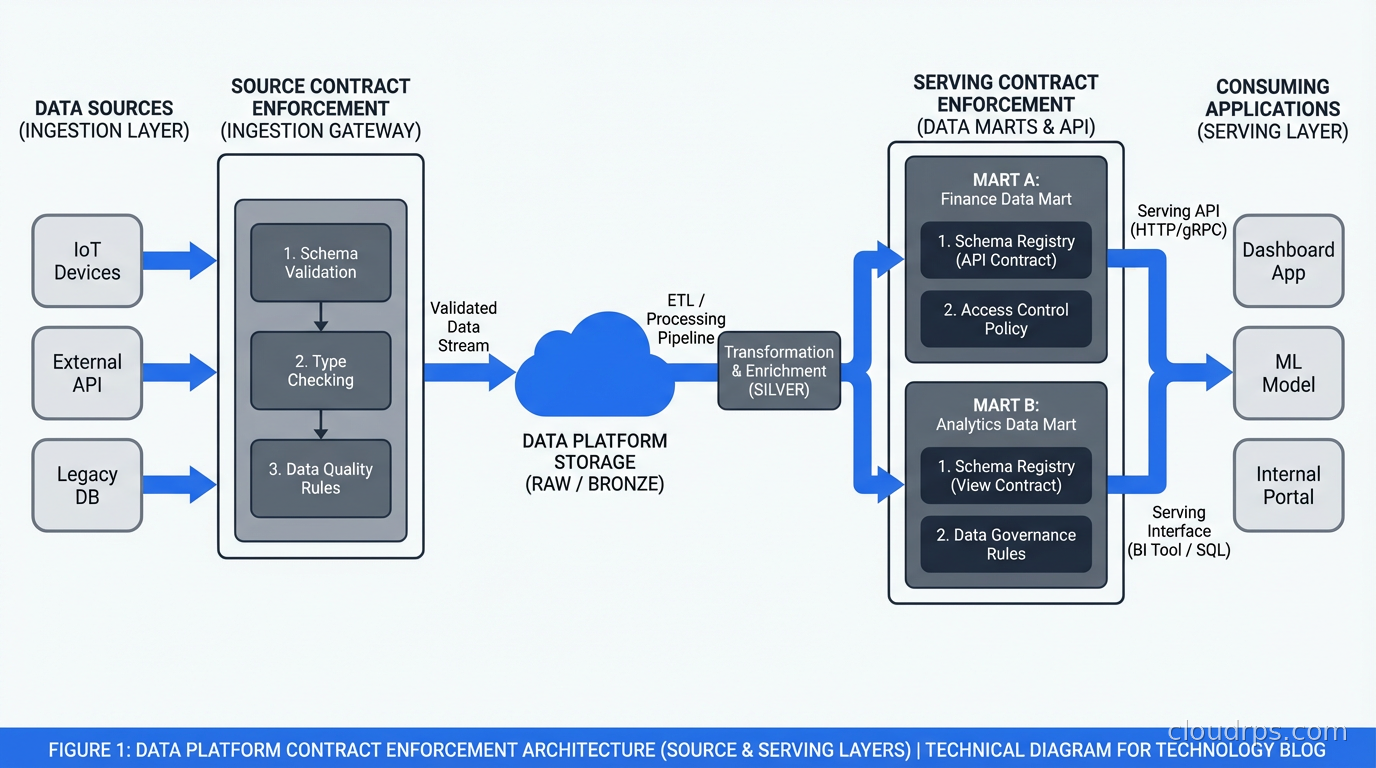
The gap in most implementations is the middle layer: the staging and intermediate transformations. These are often poorly documented and change frequently. In practice, you do not need contracts on every intermediate table. Focus contract enforcement on the boundaries: source intake and serving output. Everything in between can evolve more freely as long as it does not violate the boundary contracts.
Starting From Zero
If your organization currently has zero contracts, the practical path is:
- Identify your highest-value, most-consumed datasets (usually the ones with the most downstream breakage incidents)
- Write contracts for those datasets based on what consumers currently expect, even if the producer did not intend those guarantees
- Get the producer team to review and formally acknowledge the contract
- Add contract validation to the producer’s CI pipeline as a non-blocking check first, so you surface violations without blocking deployments immediately
- After a month of running the non-blocking check and fixing any discovered violations, flip it to blocking
Starting with the high-value, high-breakage datasets gives you the biggest risk reduction for the initial investment. It also builds the organizational muscle memory around contract-first data development before you roll out to lower-stakes datasets.
Data contracts will not fix bad data. They will not fix cultural problems around ownership. What they do is make the implicit explicit, and give you a machine-enforceable interface between teams that previously relied entirely on word of mouth and Slack messages. In organizations with more than one data team, that shift is worth a significant amount of engineering time to implement.
The payments engineer who renamed that column was not careless. He did not know about the downstream dependency because no one had told him, and there was no system for telling him. Data contracts create that system.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.