I’ve watched the same pattern play out at every large organization I’ve consulted for over the past decade. A company grows, data becomes critical, and leadership decides to centralize everything into one big data team. That team builds a data lake, maybe a warehouse on top, and for a while things work. Then the backlog grows. The central team becomes the bottleneck. Domain teams start hoarding data in shadow IT systems. Reports take weeks. Nobody trusts the numbers. Sound familiar?
Data mesh is Zhamak Dehghani’s answer to this organizational failure mode, and it’s one of the most important architectural paradigms to emerge in data engineering in the last five years. But it’s also one of the most misunderstood. I’ve seen companies adopt data mesh as a buzzword, slap “data product” labels on their existing mess, and declare victory. That doesn’t work. Let me walk you through what data mesh actually is, when it makes sense, and how to implement it without creating chaos.
The Problem: Why Centralized Data Teams Hit a Wall
Before we talk about data mesh, let’s understand the problem it solves. The traditional model looks like this: you have a central data engineering team that ingests data from all your operational systems, transforms it, and loads it into a centralized repository. Analysts, data scientists, and business users consume from that central store.
This model works brilliantly when you have 5 to 10 source systems and a handful of consumers. It falls apart when you hit enterprise scale, say 50+ microservices, each with their own SQL or NoSQL databases, dozens of streaming pipelines, and hundreds of consumers with different needs.
The central team becomes a translation layer. They don’t deeply understand the domain semantics of the data they’re ingesting. When the orders team changes their schema, the central team scrambles to update pipelines. When the marketing team needs a new dataset, they file a ticket and wait three weeks. The central team’s backlog becomes the company’s data bottleneck.
I saw this firsthand at a fintech company with about 200 engineers. Their central data team of 12 people had a six-week pipeline backlog. Domain teams were exporting CSVs and emailing them to each other. The CFO’s monthly reports used different numbers than the VP of Sales’s dashboard because they were sourced from different ad-hoc exports. It was a disaster.
What Data Mesh Actually Is
Data mesh is not a technology. It’s an organizational and architectural paradigm that applies four principles to how you manage analytical data at scale. Zhamak Dehghani introduced these principles in 2019, and they draw heavily from domain-driven design, product thinking, and platform engineering.
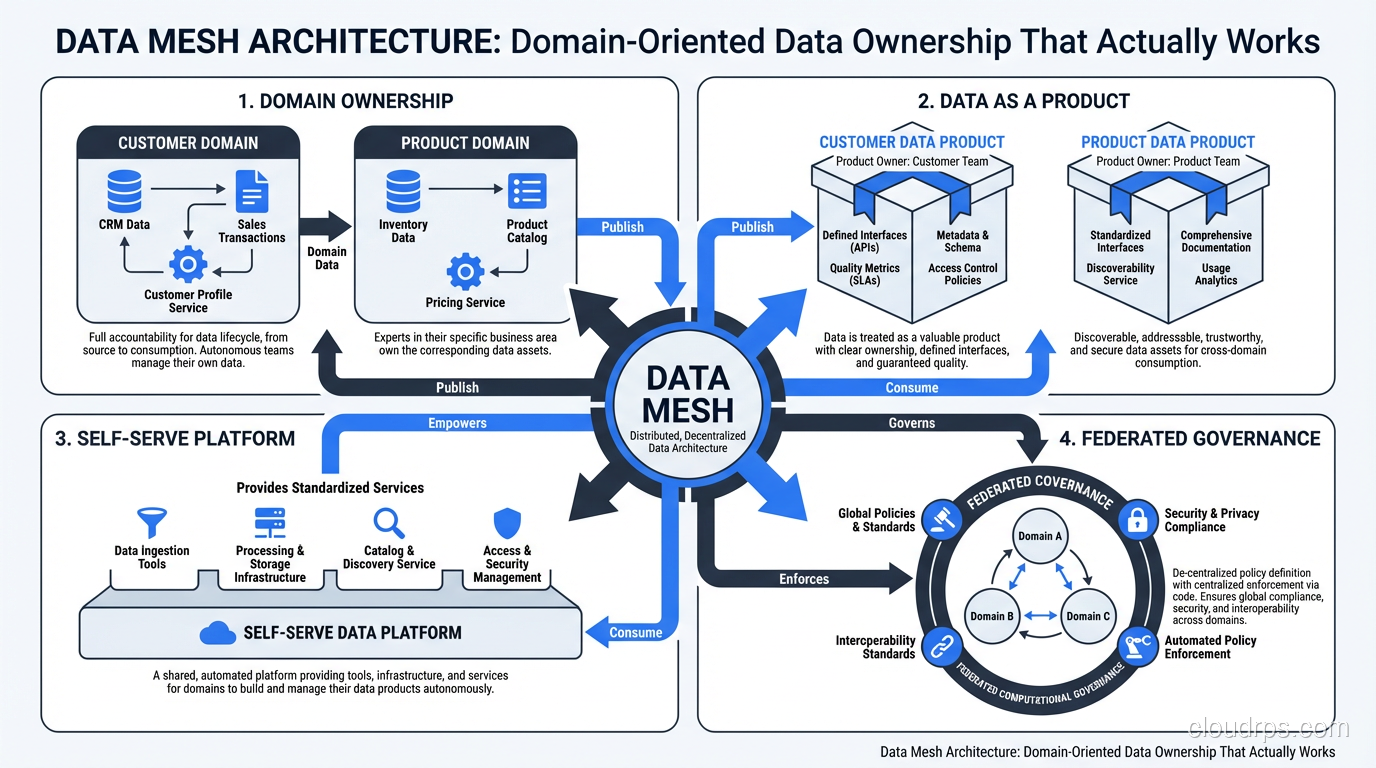
The four principles are:
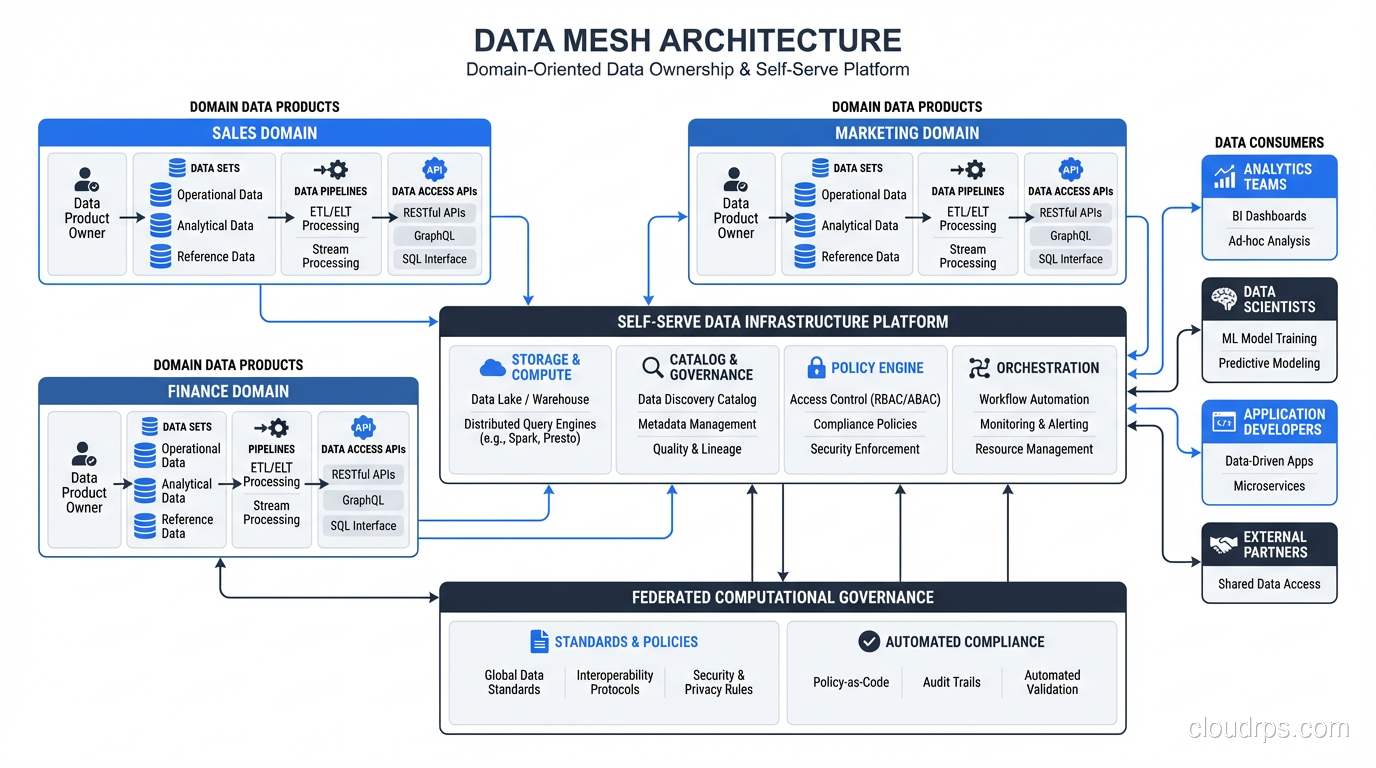
- Domain-oriented data ownership: The teams that produce data own and serve it as analytical data products.
- Data as a product: Analytical data is treated with the same rigor as customer-facing products, with SLAs, documentation, and quality guarantees.
- Self-serve data platform: A shared infrastructure layer that makes it easy for domain teams to build, deploy, and maintain data products without being infrastructure experts.
- Federated computational governance: Global standards enforced through automation, with local autonomy for domain-specific decisions.
Let me break each of these down with practical detail.
Principle 1: Domain-Oriented Data Ownership
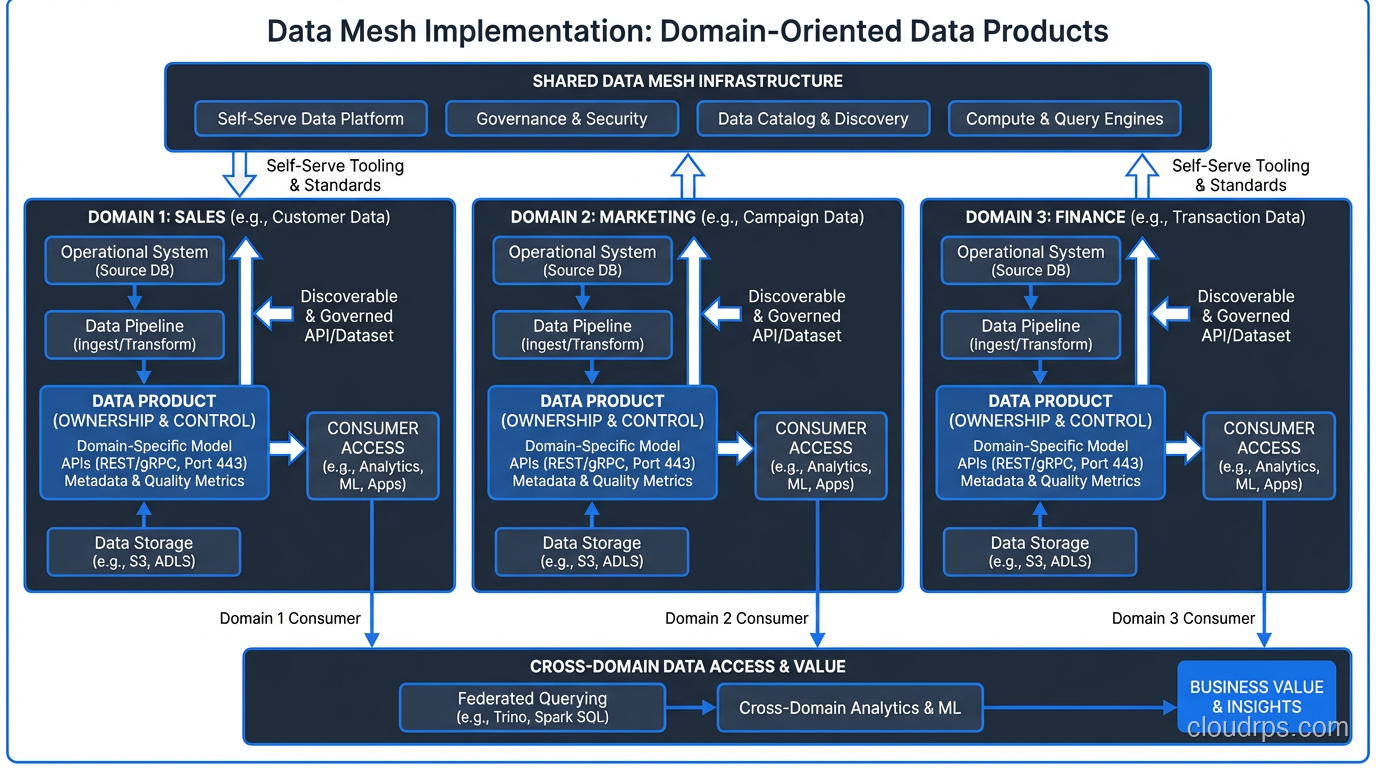
This is the most disruptive principle because it challenges the deeply ingrained idea that data should be centralized. In a data mesh, the team that knows the data best owns it. The orders team owns order data. The payments team owns payment data. The marketing team owns campaign data.
This isn’t just about moving pipelines around. It’s about shifting accountability. The domain team is responsible for making their data available to the rest of the organization in a consumable format. They understand the business context, they know when “order_status = 7” means “partially refunded,” and they can answer questions about edge cases that a central team never could.
The key distinction here is between operational data and analytical data. Domain teams already own their operational databases. Data mesh extends that ownership to the analytical plane. The orders team doesn’t just run the orders microservice; they also produce and maintain an analytical dataset of order events that other teams can consume.
This maps closely to how multi-tenant architectures handle isolation, where each tenant (in this case, each domain) owns and manages their own slice of the system while sharing underlying infrastructure.
Principle 2: Data as a Product
This is where most data mesh implementations fail. Teams slap a “data product” label on a raw database dump and call it a day. A real data product has specific characteristics:
Discoverable: Other teams can find it. You need a data catalog or marketplace where teams can browse available data products, understand their schemas, see sample data, and read documentation. If people can’t find your data, it doesn’t exist.
Addressable: Each data product has a stable, unique address. Think of it like an API endpoint. Consumers don’t need to know which S3 bucket or database table backs it. They access it through a consistent interface.
Trustworthy: This means SLAs. How fresh is the data? What’s the latency? What’s the expected uptime? If your data product promises hourly updates and it hasn’t refreshed in three days, that’s a breach. You need monitoring and alerting on data quality metrics just like you monitor API response times.
Self-describing: The schema, semantics, and lineage are part of the product. A consumer should be able to understand what “customer_ltv” means without sending a Slack message to the producing team.
Interoperable: Data products should work together. This requires shared conventions for identifiers, time zones, currency codes, and other cross-cutting concerns.
Secure: Access controls, data classification, and privacy compliance are built in, not bolted on.
I worked with a retail company that nailed this. Their inventory domain team published three data products: real-time stock levels (a streaming product), daily inventory snapshots (a batch product), and inventory movement history (a historical product). Each had a published schema, freshness SLA, quality checks that ran automatically, and a dedicated Slack channel for consumers. When the product page team needed to show “only 3 left in stock,” they consumed the streaming product with confidence because the inventory team stood behind its accuracy.
Principle 3: Self-Serve Data Platform
Here’s where the rubber meets the road. You can’t tell 20 domain teams to go build their own data infrastructure from scratch. That would be insanity. You’d end up with 20 different pipeline frameworks, 20 different storage solutions, and zero interoperability.
The self-serve data platform is the shared infrastructure layer that provides domain teams with the tools they need to build, deploy, monitor, and maintain data products without becoming infrastructure experts. If you’re familiar with platform engineering and internal developer platforms, this is the same concept applied to data.
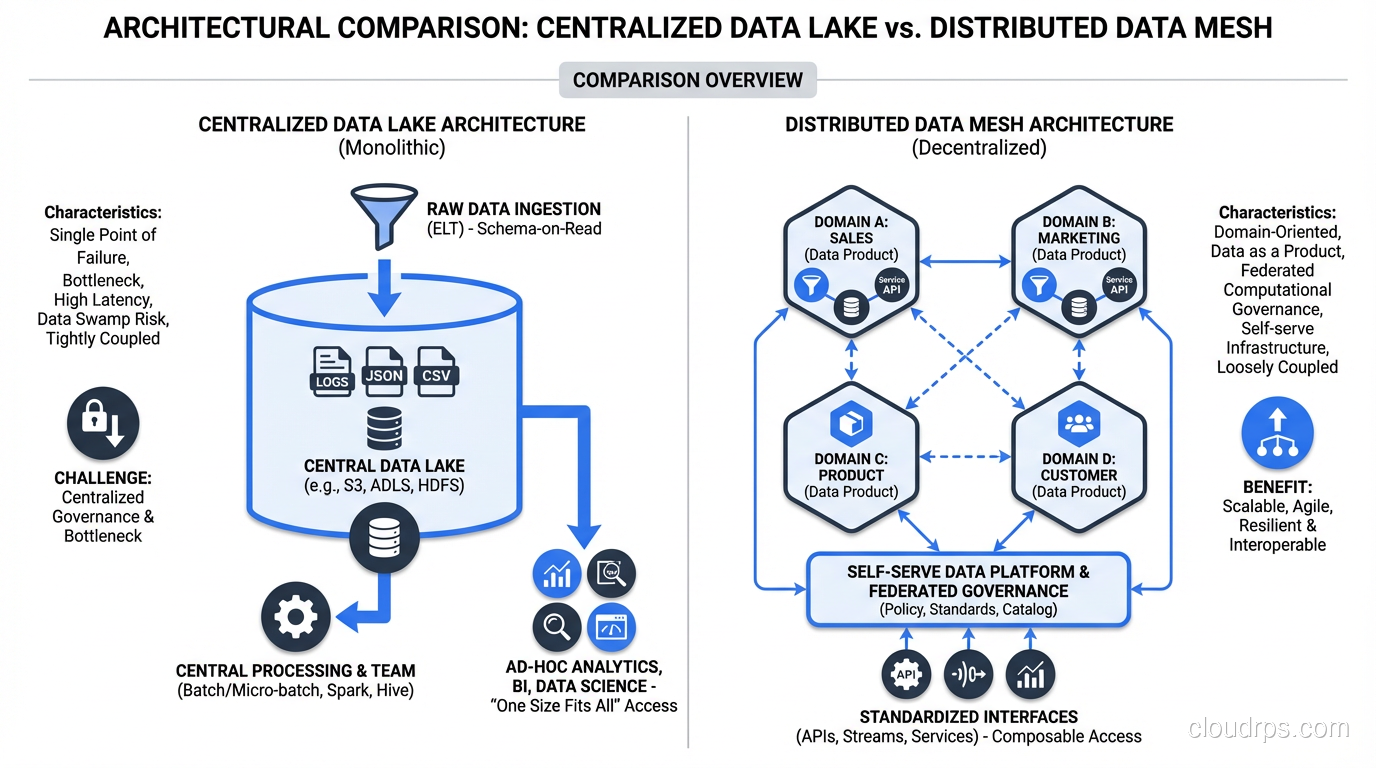
A good self-serve data platform provides:
Data product templates: A domain team should be able to spin up a new data product by filling in a configuration file. The platform handles provisioning storage, setting up ingestion pipelines, configuring quality checks, registering it in the catalog, and setting up monitoring.
Polyglot storage: Different data products have different storage needs. Some are best served by columnar databases for analytical queries, others by object storage for raw events, others by streaming topics for real-time consumption. The platform should abstract this while still letting teams choose the right tool.
Compute infrastructure: Managed Spark clusters, Flink jobs, or dbt projects that domain teams can use without worrying about cluster management.
Quality and observability: Built-in data quality frameworks (Great Expectations, dbt tests, Monte Carlo) that domain teams configure but don’t have to build from scratch. Dashboards, alerts, and lineage tracking come out of the box.
Access management: A way to define and enforce who can access which data products, with self-serve access request workflows.
Think of it this way: just as a cloud platform lets application teams deploy services without managing physical servers, a self-serve data platform lets domain teams produce data products without managing infrastructure.
The platform team in a data mesh is smaller than a traditional central data team, but their scope is different. They’re not building pipelines for every domain. They’re building the platform that enables every domain to build their own pipelines.
Principle 4: Federated Computational Governance
This is the principle that prevents data mesh from becoming total anarchy. “Federated” means there are global standards that everyone follows, but individual domains have autonomy over domain-specific decisions.
Global standards include things like: how data products are versioned, what metadata is required, what SLA tiers exist, how PII is classified and handled, which identifiers (like customer_id) must be consistent across domains, and what interoperability standards apply.
The “computational” part is key. These standards should be enforced through code, not through review boards. When a domain team deploys a data product, automated checks verify that it meets the global standards. Does it have required metadata fields? Does it pass schema validation? Does it have quality checks configured? Are PII columns tagged and encrypted?
This is similar to how a well-run database replication setup enforces consistency. You don’t rely on humans to keep replicas in sync; the system handles it automatically.
A governance council (representatives from domain teams plus the platform team) sets the standards and evolves them over time. But enforcement is automated. Human governance is for policy decisions, not for reviewing every data product deployment.
Data Mesh vs Data Lake vs Data Warehouse vs Data Lakehouse
This comparison trips people up because data mesh operates at a different level of abstraction. Let me clarify:
- A data warehouse is a technology choice: a structured, schema-on-write analytical store (Snowflake, BigQuery, Redshift).
- A data lake is a technology choice: a schema-on-read storage layer, typically on object storage (read more about data lakes).
- A data lakehouse is a technology choice: combines lake storage with warehouse-like performance (Databricks, Apache Iceberg on S3).
- A data mesh is an organizational architecture. It’s about who owns the data and how it’s governed.
You can absolutely implement data mesh using a data lakehouse as your underlying technology. In fact, that’s a common pattern. Each domain team gets a namespace in the lakehouse. They produce their data products there, using the self-serve platform. The lakehouse provides the compute and storage engine; data mesh provides the ownership model.
I’ve seen data mesh implementations on Snowflake (using separate databases per domain), Databricks (using Unity Catalog for domain-level governance), and even on AWS with S3 plus Glue plus Athena. The technology matters less than the organizational model.
When Data Mesh Makes Sense (And When It Doesn’t)
Data mesh is not for everyone. I’ve talked companies out of it as often as I’ve recommended it. Here’s my honest assessment:
Data mesh makes sense when:
- You have 50+ engineers working on 10+ distinct business domains
- Your central data team is a documented bottleneck (backlog measured in weeks, not days)
- Domain teams already have strong engineering cultures and some data literacy
- Your data problems are primarily organizational (ownership disputes, context loss, slow delivery), not technical
- You’re willing to invest in a platform team and give them 6 to 12 months to build the self-serve layer
Data mesh is overkill when:
- You have fewer than 50 engineers total
- You have a small number of data sources (under 10)
- Your central data team is keeping up with demand
- Domain teams don’t have the engineering maturity to own data products
- You’re looking for a quick fix (data mesh is a multi-year journey)
A startup with 20 engineers and a single product doesn’t need data mesh. A centralized data team of 2 or 3 people using dbt and a warehouse will serve them perfectly. Data mesh is a solution for organizational scaling problems, and if you don’t have those problems yet, it’s premature complexity.
Implementation Patterns That Work
Having helped three organizations implement data mesh, here are patterns I’ve seen succeed:
Start with one or two domains, not a big bang. Pick domains that have strong engineering teams, clear data products, and motivated leadership. Let them be the proof of concept. Other domains will see the benefits and want to participate.
Invest heavily in the platform before scaling. If you try to onboard 10 domains before your platform is ready, every domain will build their own bespoke solution. Then you have 10 snowflakes to consolidate later. Get the platform right with the first two domains, then scale.
Define “data product” precisely. Create a checklist: schema documentation, SLA definition, quality checks, access policies, catalog registration, monitoring dashboards. A data product isn’t a data product until it meets all criteria. Be strict about this.
Keep the governance council small and empowered. 5 to 7 people, with decision-making authority. Representatives from major domains plus the platform team lead. They meet biweekly, make decisions, and move on. Large committees produce bureaucracy, not governance.
Use a data catalog as the connective tissue. Atlan, DataHub, OpenMetadata, or even a well-maintained internal wiki. This is how consumers discover data products. Without it, data mesh degenerates into “every team has data somewhere, good luck finding it.”
Common Failure Modes
Let me be real about what goes wrong, because I’ve seen all of these:
“We did data mesh” but really just decentralized the chaos. Teams produce data with no standards, no quality checks, and no discoverability. This is worse than a centralized model because at least the central team had some consistency.
Platform underinvestment. Leadership approves data mesh but doesn’t fund the platform team. Domain teams are told to own their data but given no tools to do it well. They spend half their time fighting infrastructure instead of building products.
Domain teams that don’t want to own data. This is a real issue. Some teams view data ownership as an unfunded mandate. “We’re the payments team, we build payment features, and now you want us to also build and maintain analytical datasets?” Without executive support and adjusted team goals, you get resentful compliance at best.
Governance that’s too heavy or too light. Too heavy, and you’ve recreated the central bottleneck with a committee. Too light, and you get incompatible data products that can’t be joined or compared. Finding the right balance takes iteration.
Ignoring the people side. Data mesh is 70% organizational change and 30% technology. You need to change incentives, team structures, hiring profiles, and career paths. A backend engineer who now owns a data product needs different skills. Training, mentorship, and role evolution matter more than tool selection.
A War Story: The Insurance Company That Got It Right
The best data mesh implementation I’ve seen was at a mid-size insurance company, about 400 engineers across claims, underwriting, policy management, billing, and customer service. Their central data team of 15 was drowning in a 10-week backlog, and the Chief Data Officer was ready to try something different.
They started with the claims domain because that team had strong engineers and their data was the most requested across the organization. The platform team (carved out from the central data team) spent three months building the first version of their self-serve platform on Databricks with Unity Catalog.
The claims team produced three initial data products: claims events (streaming), claims snapshots (daily batch), and claims aggregations (weekly summaries with loss ratios). Each product had a published contract, quality tests that ran on every refresh, and monitoring in Datadog.
Within six months, three more domains had onboarded. The former central data team had split: half became the platform team, and the other half embedded into domains as data coaches, helping teams build their first data products before stepping back.
The key metric: time from “we need this data” to “it’s available in production” dropped from 10 weeks to 8 days. Not because of technology, but because the team that understood the data was the team producing it. No more translation layer.
Getting Started: A Practical Roadmap
If you’re considering data mesh, here’s a realistic roadmap:
Month 1 to 2: Assessment. Map your current data architecture. Identify bottlenecks. Assess domain team maturity. Decide if data mesh is the right approach. Be honest with yourself here.
Month 3 to 5: Platform foundation. Stand up the core self-serve platform. Define your data product specification. Build templates and tooling. Select your first pilot domain.
Month 6 to 9: First domain. Work closely with the pilot domain to produce their first data products. Iterate on the platform based on real feedback. Document everything.
Month 10 to 14: Expand to 3 to 5 domains. Onboard additional domains using lessons from the pilot. Establish the governance council. Refine standards.
Month 15+: Scale and mature. Continue onboarding domains. Invest in advanced platform capabilities (automated lineage, self-serve access workflows, cost attribution). Shift the governance council’s focus from basics to optimization.
This is a multi-year commitment. If your leadership wants results in a quarter, data mesh isn’t the answer. But if they’re willing to invest in a fundamental shift in how data is owned and managed, data mesh can transform an organization’s relationship with its data.
Final Thoughts
Data mesh isn’t a silver bullet. It’s a set of principles that, when applied with discipline and patience, can solve the organizational scaling problems that plague enterprise data teams. The technology matters far less than the cultural and organizational changes required.
The question isn’t “should we use data mesh?” The question is “do we have the organizational problems that data mesh solves, and are we willing to make the organizational changes it requires?” If the answer to both is yes, data mesh might be exactly what you need. If you’re just looking for a new label for your existing data lake, save yourself the trouble.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.