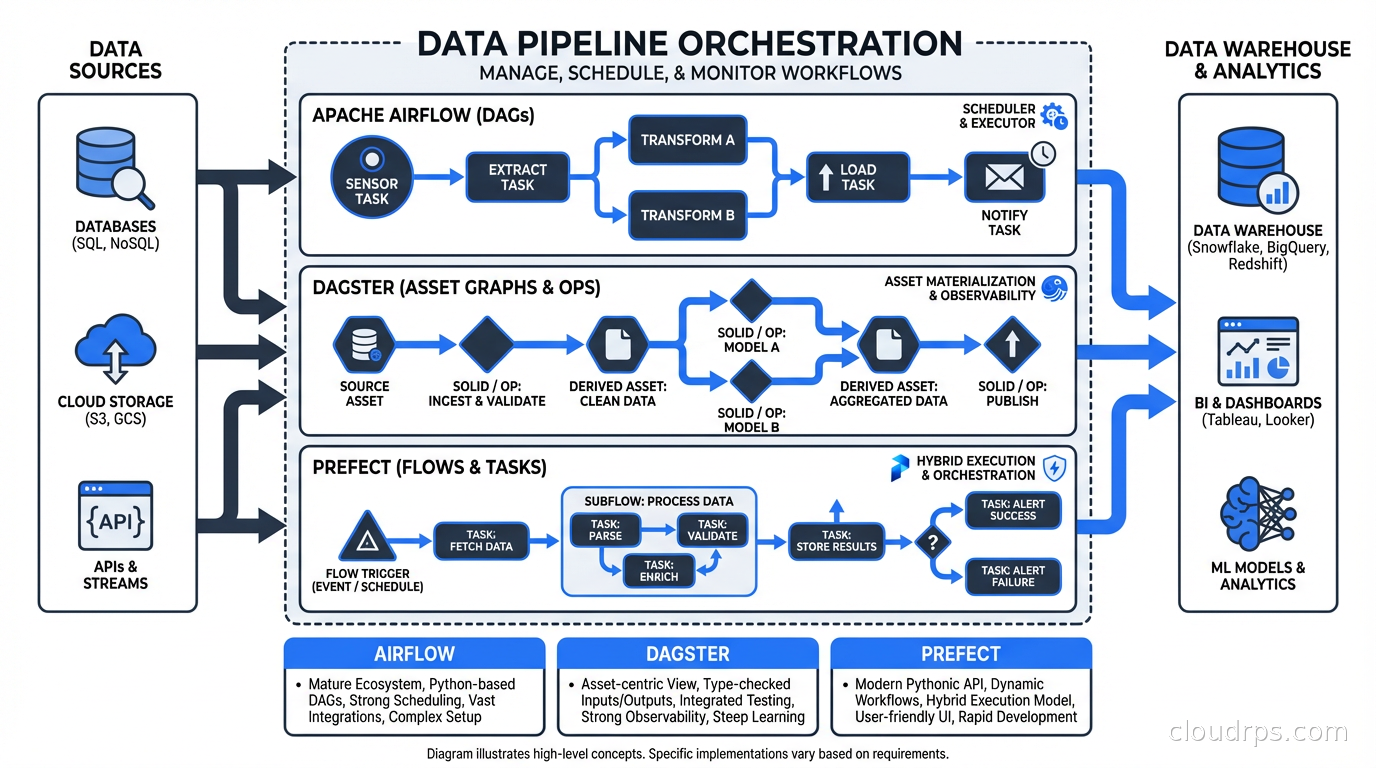
I’ve watched teams spend three months fighting their orchestration tool before realizing they picked the wrong one. The data pipeline orchestration space has a frustrating amount of overlap on the surface, but each tool has genuinely different DNA that makes it the right fit for very different types of teams and problems.
Apache Airflow, Dagster, and Prefect are the three serious contenders if you’re building production data pipelines in 2025. I’ve run all three in production at various scales. Here’s what I’ve learned.
What Data Orchestration Actually Is
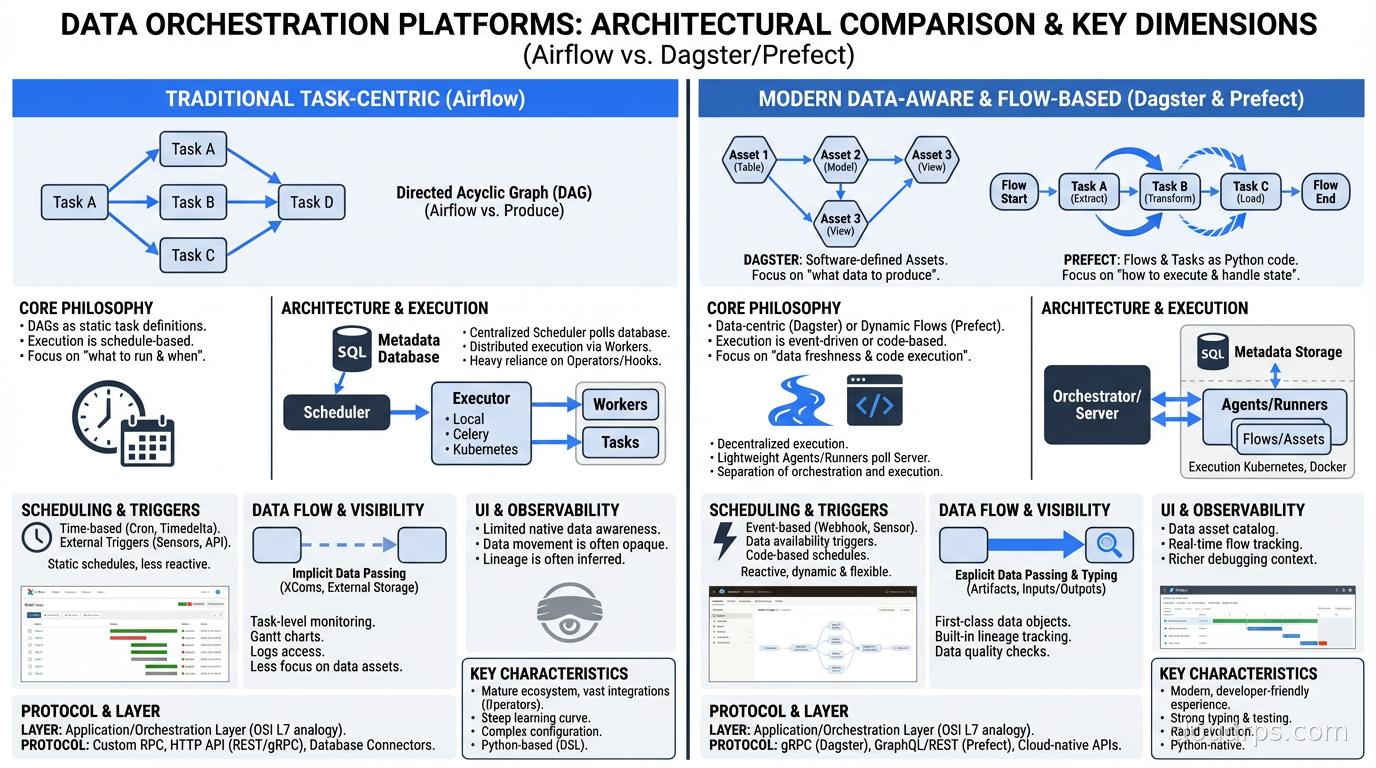
Before I get into the tools, let me clarify what we’re even solving. Data orchestration is the scheduling, coordination, and monitoring of data workflows: extract data from sources, transform it, load it somewhere, validate it, and make it available for consumption. The key word is “workflow” because these aren’t individual tasks running in isolation; they’re directed acyclic graphs (DAGs) of dependent steps where failure in one stage should stop downstream work.
This is explicitly different from stream processing tools like Apache Kafka and Flink, which handle continuously flowing data in real time. Orchestration tools are primarily about scheduled, batch-oriented, or event-triggered workflows with defined start and end points. They’re also different from transformation tools like dbt, which handles the SQL transformation layer but needs something else to schedule and coordinate it.
The orchestration tool becomes the operational nervous system of your data platform. It’s where you see what ran, what failed, why it failed, and what’s blocked waiting for something upstream. Choose poorly and you’re debugging YAML at 2am wondering why your CEO’s dashboard is empty.
Apache Airflow: The Incumbent
Airflow was open-sourced by Airbnb in 2015 and has been the default choice for data engineering for almost a decade. The ubiquity is real: it runs inside hundreds of thousands of organizations, has a massive community, and every data engineer in the market knows it.
The fundamental abstraction in Airflow is the DAG (directed acyclic graph), defined in Python. You write a Python file that describes tasks and their dependencies, and Airflow schedules and executes them.
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
def extract():
# pull data from source
pass
def transform():
# process data
pass
with DAG('my_pipeline', start_date=datetime(2025, 1, 1), schedule_interval='@daily') as dag:
t1 = PythonOperator(task_id='extract', python_callable=extract)
t2 = PythonOperator(task_id='transform', python_callable=transform)
t1 >> t2
This is simple and it works. The problems emerge at scale.
The Airflow architecture is operationally heavy. You need a web server, a scheduler, a metadata database (typically PostgreSQL), and workers. The scheduler has historically been a bottleneck; Airflow 2.x improved this with a new scheduler design, but you’re still managing a non-trivial distributed system. I’ve spent more time tuning Airflow’s own infrastructure than I care to admit.
DAGs as code has an ugly side. In Airflow, DAGs are discovered by the scheduler scanning Python files in a folder. If your DAG file has an import error, the DAG silently disappears from the UI. I once had a critical pipeline go dark for two hours because a developer accidentally introduced a circular import. No alert, no error, just… gone.
Dynamic task generation is awkward. Airflow wasn’t designed with dynamic workflows in mind. The traditional pattern requires knowing all your tasks at DAG parse time. Airflow 2.3 introduced dynamic task mapping, which helps, but it’s still clunkier than what competitors offer natively.
Where Airflow shines is ecosystem depth. There are official providers for every cloud service, database, SaaS tool, and data system you can name. If you need to pull from Snowflake, transform in Spark, load into BigQuery, and notify Slack on failure, there are maintained provider packages for all of it. That ecosystem maturity matters enormously in enterprise environments.
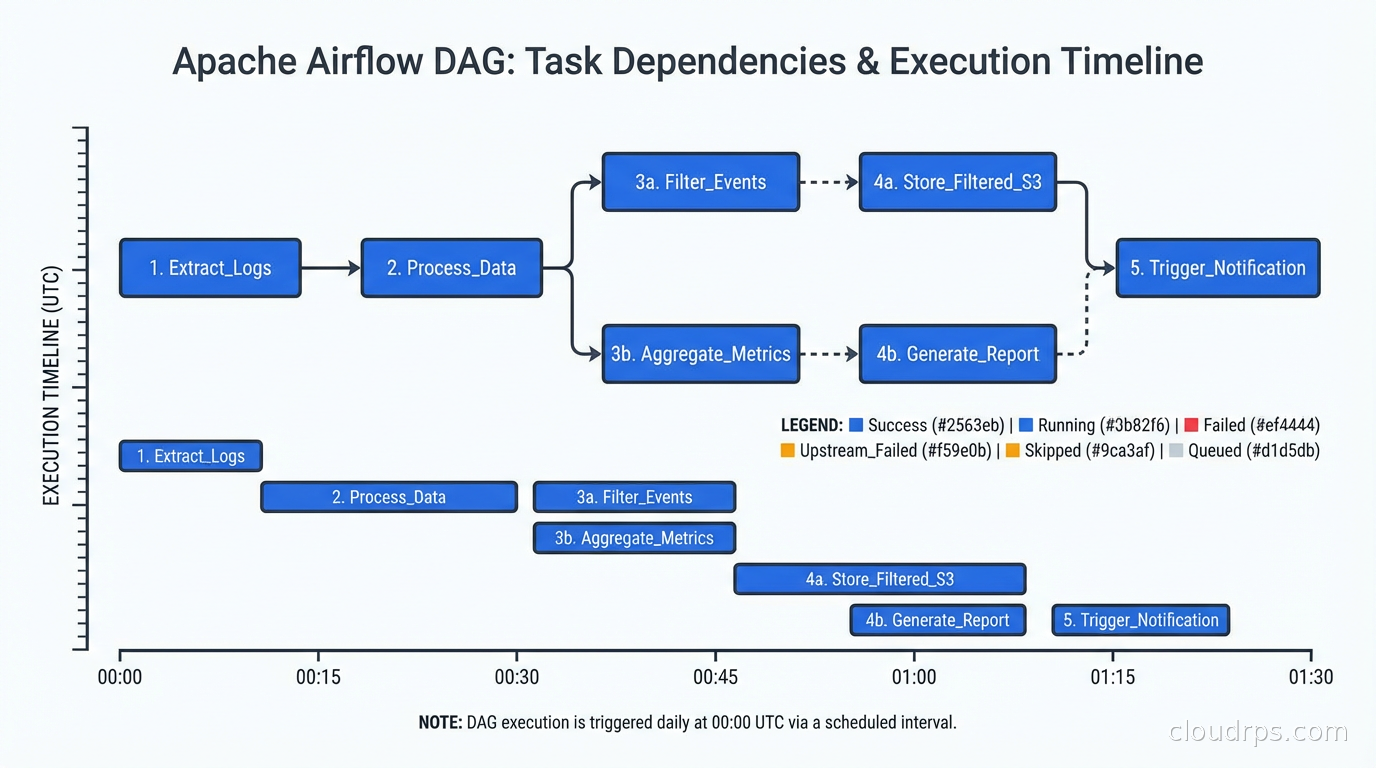
Managed Airflow options (Astronomer, MWAA on AWS, Google Cloud Composer) have reduced the operational burden significantly. If someone else is running the metadata database and scheduler for you, Airflow’s operational complexity becomes much more manageable.
When to choose Airflow: Large enterprises with existing Airflow deployments, teams that need maximum provider ecosystem coverage, organizations where most engineers already know Airflow, and situations where managed offerings like MWAA or Cloud Composer fit your cloud-native stack.
Dagster: The Software-Engineering-First Approach
Dagster launched in 2019 with a core thesis that data pipelines should be engineered like software products. The founders came from software engineering backgrounds and it shows in the design choices.
The most distinctive concept in Dagster is the software-defined asset (SDA). Instead of thinking about tasks that run, you think about data assets that are produced. An asset is a logical unit of data: a database table, a file in S3, a machine learning model. Your pipelines define how to produce and maintain those assets.
from dagster import asset
@asset
def raw_orders():
# returns a DataFrame
return fetch_orders_from_api()
@asset
def processed_orders(raw_orders):
# dagster automatically understands this depends on raw_orders
return raw_orders.dropna().assign(total=raw_orders.price * raw_orders.qty)
This asset-centric model has profound operational implications. Dagster knows what your data assets are, tracks when they were last materialized, shows which assets are stale, and can compute the lineage of any data asset across your entire platform. When something breaks, you don’t just know which task failed; you know which data assets are affected and what downstream consumers might be serving stale data.
The local development experience is significantly better than Airflow. You can run Dagster pipelines locally with minimal setup, test individual assets in unit tests, and the UI gives you an asset catalog that’s genuinely useful for understanding your data platform. I’ve shown the Dagster asset lineage graph to non-technical stakeholders and they immediately understood how data flows through the system, which is not something I’ve ever managed with an Airflow DAG view.
Dagster is opinionated about software engineering practices. Type annotations, I/O managers for abstracting storage, resource definitions for configuration, and a partition system that neatly handles incremental processing are all first-class concepts. This pays off for teams building data platforms as products. It’s more complex to learn upfront, but the complexity has a purpose.
The downside: Dagster has a steeper learning curve than Airflow, and the ecosystem of integrations (while good and growing) is smaller. If you need a niche connector, it might require more custom work than Airflow’s provider ecosystem would.
Dagster Cloud’s branching deployments deserve a mention. You can create isolated deployment branches for feature development, similar to what serverless database branching does for databases. Testing a new pipeline logic in an isolated environment before merging is a genuinely useful capability.
When to choose Dagster: Teams that want to treat data pipelines as software products, organizations investing heavily in a data platform with clear asset lineage requirements, data engineering teams with software engineering backgrounds, and organizations where data contracts and quality ownership are central concerns.
Prefect: Python-Native Dynamic Workflows
Prefect launched in 2018 with a different philosophy: orchestration should be as lightweight as possible, and Python code should remain Python code without heavy framework intrusion.
The Prefect model is dead simple. You decorate Python functions with @flow and @task:
from prefect import flow, task
@task
def extract_data():
return fetch_from_source()
@task
def transform_data(data):
return process(data)
@flow
def my_pipeline():
data = extract_data()
result = transform_data(data)
return result
That’s largely it. Your existing Python code becomes a Prefect workflow with minimal modification. This matters more than it sounds: I’ve migrated Python scripts that were running via cron to Prefect flows in an afternoon. With Airflow, that same migration takes days because you have to restructure around DAG abstractions.
Prefect 2.0 (released as Prefect 3.x continues the evolution) completely rearchitected the system around a hybrid model. The Prefect server (or Prefect Cloud) handles the orchestration control plane: scheduling, UI, state tracking. The actual task execution happens in your own infrastructure via workers that poll the control plane. This separation is architecturally clean: your code and data never leave your infrastructure even when using Prefect Cloud.
Dynamic task generation is a first-class citizen. Prefect handles dynamic workflows naturally because it executes code at runtime rather than parsing DAG definitions at schedule time. You can create tasks in a loop based on the output of a previous task without any special framework support.
@flow
def process_all_customers():
customers = fetch_customer_list() # runtime value
for customer_id in customers:
process_customer(customer_id) # spawns tasks dynamically
This flexibility makes Prefect particularly well-suited for ML pipelines, ETL patterns where the number of entities varies per run, and event-driven workflows where processing is triggered by incoming data.
The monitoring and observability story is solid. Prefect’s UI shows flow run history, task state, logs, and artifacts with a clean interface. The notification system integrates with Slack, PagerDuty, and other channels natively. For data observability across your pipelines, Prefect’s built-in state tracking gives you a reasonable starting point before you layer on dedicated tools.
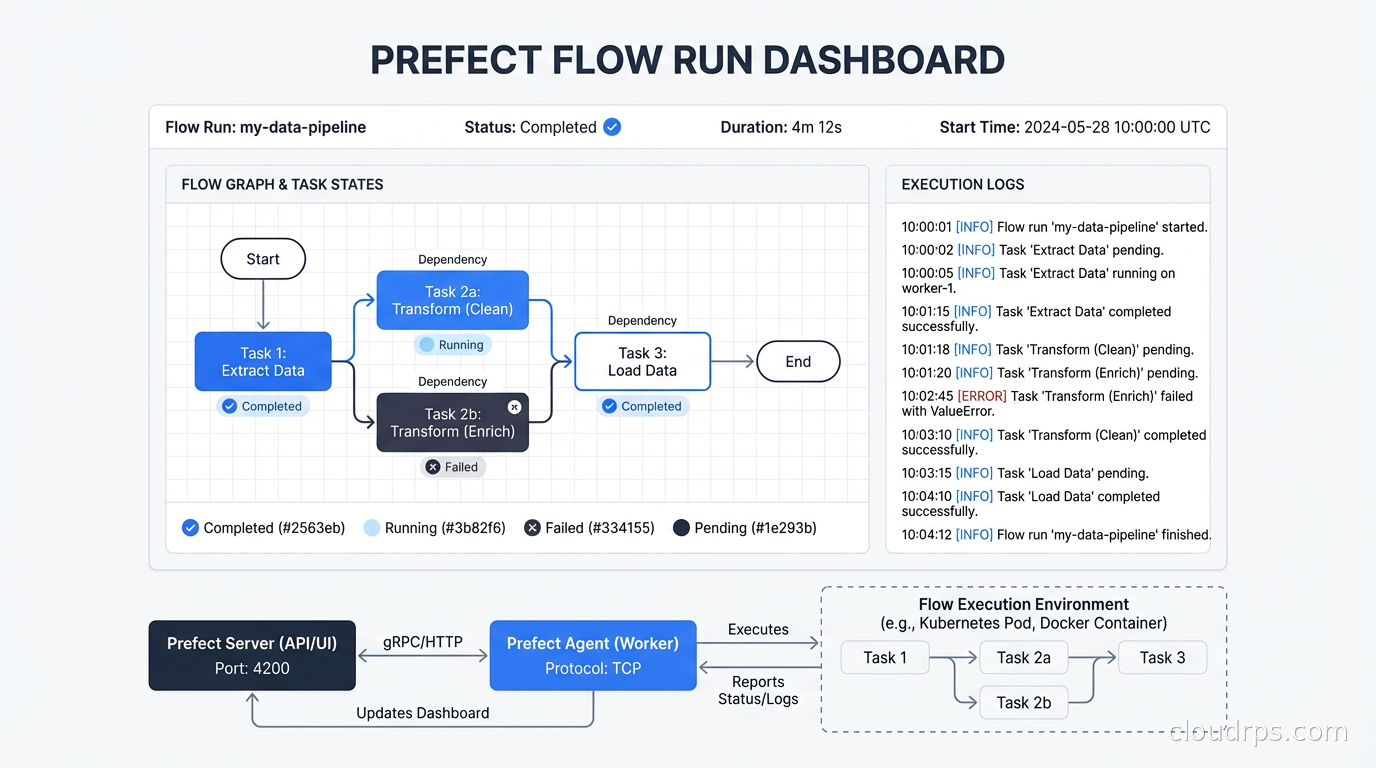
Where Prefect is weaker: The asset lineage story is less developed than Dagster. If you need a comprehensive view of what data assets exist, when they were last updated, and what depends on what, Dagster’s asset catalog is deeper. Prefect is also younger than Airflow, so you’ll occasionally find integration gaps.
When to choose Prefect: Teams migrating from cron jobs or ad-hoc Python scripts, workflows with dynamic task graphs that vary at runtime, ML engineering pipelines where Python flexibility matters, and organizations that want the operational simplicity of Prefect Cloud without giving up data sovereignty.
Head-to-Head: The Real Differences
Let me be concrete about where these tools actually diverge, beyond the marketing.
Operational complexity (ascending order): Prefect Cloud (lowest), Dagster Cloud, self-hosted Prefect, self-hosted Dagster, Airflow (highest). If you’re self-hosting, the difference is significant. Airflow’s metadata database needs careful tuning, the scheduler needs dedicated resources, and DAG parsing overhead grows with DAG count.
Learning curve: Prefect is fastest to onboard for Python developers with no prior orchestration experience. Airflow is fastest for teams where someone already knows it. Dagster has the steepest initial curve but the concepts pay dividends over time.
Data lineage: Dagster wins clearly with software-defined assets. Airflow and Prefect provide task-level lineage but not asset-level lineage without additional tooling like OpenLineage.
Dynamic workflows: Prefect is the natural fit. Airflow 2.3+ can do it but it’s more verbose. Dagster handles it through its partitioning and dynamic outputs system.
Ecosystem breadth: Airflow wins on sheer number of integrations. Dagster and Prefect are catching up but there are still gaps for niche systems.
Local development: Dagster and Prefect both win over Airflow here. Getting Airflow running locally for development is a multi-step process. Dagster and Prefect spin up in minutes.
Integrating with the Modern Data Stack
None of these tools exist in isolation. The real question is how they integrate with Apache Spark for distributed processing, Apache Iceberg for data lakehouse storage, and dbt for SQL transformations.
All three orchestrators have solid dbt integration. The pattern is typically: orchestrator triggers dbt runs, monitors completion, and handles failures. Dagster’s dbt integration is the tightest, exposing dbt models as Dagster assets so you get unified lineage across your Python pipelines and your dbt transformations. Prefect and Airflow treat dbt as an external process to invoke, which is simpler but loses the lineage connection.
For MLOps pipelines, Prefect has become popular because the Pythonic API fits naturally with ML engineering workflows, and the dynamic execution model handles parameter sweeps and model evaluation patterns well.
The Migration Question
Teams often ask me whether to migrate from Airflow to Dagster or Prefect. My honest answer: it depends on your pain.
If your team is fighting Airflow’s operational complexity and spending more time managing the scheduler than building pipelines, migration is worth considering. If you’re struggling with dynamic workflows, Prefect’s flexibility might justify the migration cost. If you want asset lineage and a data catalog built into your orchestration layer, Dagster is worth the investment.
But if Airflow is working fine and your team knows it, the migration cost is real. Rewriting hundreds of DAGs is a multi-month project. I’ve seen teams spend six months migrating to Dagster only to realize they could have invested that time in actual pipeline improvements. Don’t migrate for aesthetic reasons.
If you do migrate, the safest path is running both systems in parallel for a period. New pipelines go in the new tool, existing pipelines stay in Airflow until they need changes. This avoids the big-bang migration risk.
Operational Considerations
Whichever tool you choose, a few practices apply universally.
Treat your orchestration code like production software. DAGs and flows should go through code review, have tests, and be deployed via CI/CD rather than directly copying files to a folder. Airflow especially suffers when teams treat DAG files as second-class code.
Set up alerting at the orchestration layer. All three tools support failure notifications. Use them. The failure of a scheduled pipeline that nobody notices for six hours is a data quality incident waiting to happen.
Monitor metadata database size. Airflow and Dagster both use PostgreSQL to store run history. Without periodic cleanup (Airflow’s airflow db clean command, or equivalent), this database grows indefinitely and degrades performance.
Think about idempotency from day one. Pipelines will fail and need to be re-run. Tasks that can be safely re-executed without producing duplicate data save enormous amounts of debugging time. This is especially relevant when working with change data capture patterns where exactly-once semantics matter.
Making the Decision
Here’s my simple heuristic after running all three in production:
Start with Prefect if you’re a small team, migrating from scripts, or building primarily event-driven or dynamic pipelines. The ramp-up time is lowest and Prefect Cloud removes the operational overhead.
Choose Dagster if you’re building a serious data platform and want asset lineage, testability, and software engineering rigor as core requirements rather than afterthoughts. Invest in the learning curve; it pays back.
Stick with Airflow if your team already knows it, you’re in a large enterprise where the ecosystem coverage matters, or you’re using a managed service that reduces its operational burden.
The worst choice is picking whichever one has the prettiest demo. These tools will run your company’s most important data workflows. Pick based on where you’re going to be in two years, not where you are today.
Related: Stream Processing with Kafka and Flink for real-time data, dbt for SQL Transformations for the transformation layer, Apache Iceberg and the Data Lakehouse for storage architecture, and MLOps in Practice for machine learning pipeline patterns.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.