I have a confession that would horrify my college database professor: some of the fastest, most reliable production databases I have ever built are intentionally denormalized. Not because I do not understand normalization (I can recite the normal forms in my sleep after thirty years), but because I learned the hard way that textbook purity and production performance do not always live in the same house.
That said, I have also watched teams skip normalization entirely, build a spaghetti schema, and spend the next two years fighting data inconsistencies and update anomalies that would have been trivially prevented by following the rules they thought they were too clever to need.
The truth is that normalization and denormalization are both tools. Knowing when to use each one, and more importantly knowing when to switch from one to the other, is one of the most valuable skills a database architect can develop.
What Normalization Actually Solves
Before we talk about normal forms, let me explain the problem normalization exists to solve, because too many people learn the rules without understanding the motivation.
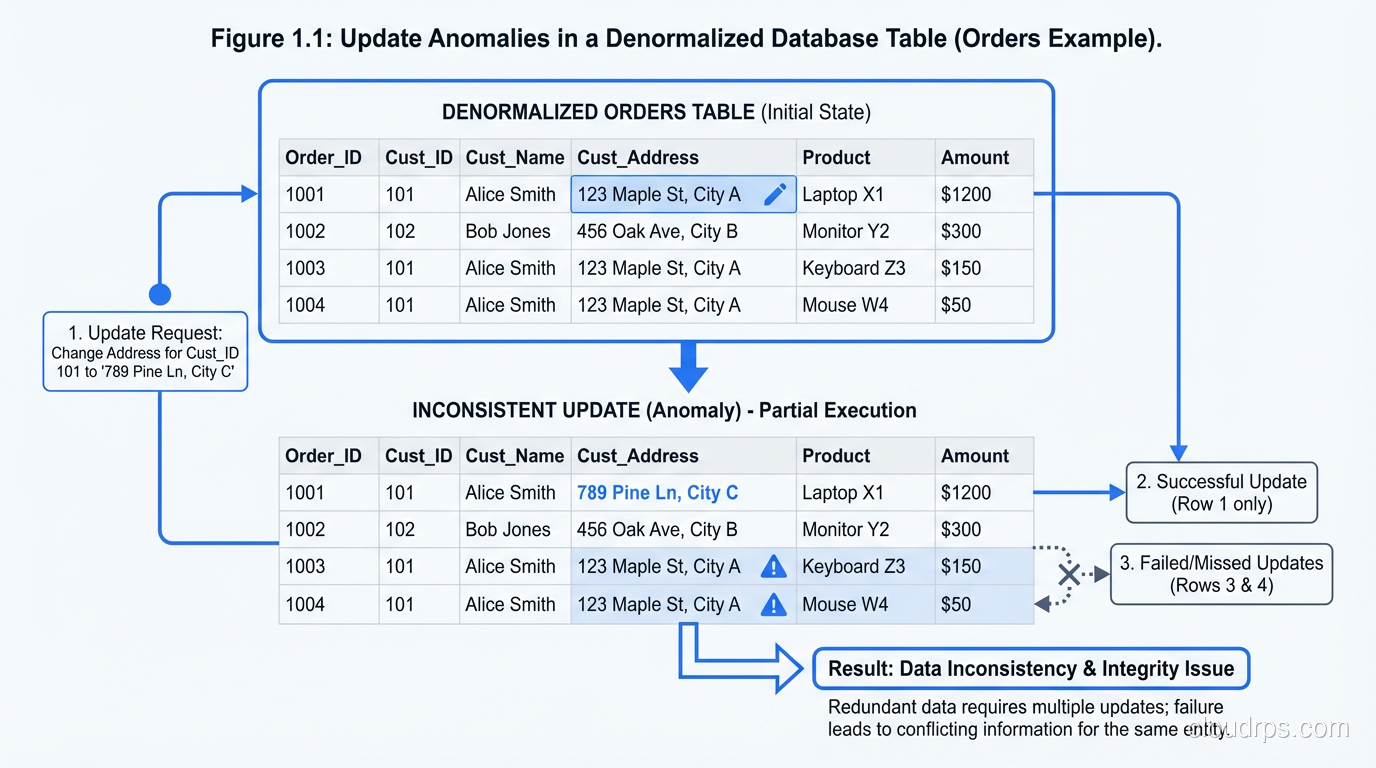
Imagine you have a table called orders with columns for order_id, customer_name, customer_email, customer_address, product_name, product_price, quantity, and order_date. Every time a customer places an order, you insert a new row with all of their information duplicated.
Now the customer changes their email address. You need to update every single row where that customer appears. If you miss one (because of a bug, a race condition, or a partial update), you now have inconsistent data. Customer #4521 has two different email addresses in your database, and you do not know which one is correct.
This is an update anomaly, and it is the fundamental problem that normalization prevents. By structuring your data so that each fact is stored exactly once, you eliminate entire categories of data integrity bugs.
The Normal Forms: A Practical Tour
I am going to walk through the normal forms the way I actually think about them in practice, not the way a textbook presents them.
First Normal Form (1NF): No Repeating Groups
A table is in 1NF if every column contains atomic values: no arrays, no comma-separated lists, no nested structures. Each row is unique.
This sounds obvious, but I still see violations regularly. The classic example is a phone_numbers column that contains “555-1234, 555-5678”. Or a tags column with “urgent,high-priority,customer-facing”. These seem convenient until you need to query them. Finding all orders tagged “urgent” requires string parsing instead of an index lookup.
In SQL databases, 1NF is essentially a requirement. In NoSQL document stores, nested arrays and embedded documents are first-class citizens, which is one of the fundamental design differences between the two paradigms.
Second Normal Form (2NF): No Partial Dependencies
A table is in 2NF if it is in 1NF and every non-key column depends on the entire primary key, not just part of it. This only matters for tables with composite primary keys.
Example: a table with a composite key of (order_id, product_id) and a column product_name. The product_name depends only on product_id, not on the full key. It should be in a separate products table.
In practice, 2NF violations are rare in modern schema designs because most teams use surrogate keys (auto-increment IDs) rather than composite natural keys. But when they do occur, they are sneaky. I have seen reporting tables with composite keys where columns depended on only part of the key, leading to inconsistencies that only surfaced months later when someone noticed conflicting product names in historical reports.
Third Normal Form (3NF): No Transitive Dependencies
A table is in 3NF if it is in 2NF and every non-key column depends directly on the primary key, not on another non-key column.
Example: a customers table with customer_id, zip_code, city, and state. The city and state depend on zip_code, not directly on customer_id. Strictly speaking, they should be in a separate zip_codes table.
This is where the real-world tradeoffs begin. Do you really want to join to a zip codes table every time you display a customer’s address? In a transactional system with millions of queries per second, that extra join has a measurable cost. In many systems I have built, I deliberately keep city and state in the customers table because the data rarely changes and the join cost is not worth the purity.
3NF is my default target for transactional schemas. It provides strong data integrity guarantees without the excessive decomposition of higher normal forms. Most experienced database architects I know share this view.
Beyond 3NF: BCNF and Higher
Boyce-Codd Normal Form (BCNF), 4NF, and 5NF address increasingly obscure dependency patterns. In thirty years, I have encountered a situation where BCNF mattered exactly twice, and the situations that require 4NF or 5NF are so rare that I would question the schema design long before reaching for those normal forms.
If your schema is in 3NF and you are still having data integrity problems, the issue is almost certainly in your application logic, not in your normalization level.
The Case for Denormalization
Now for the part that makes database purists uncomfortable.
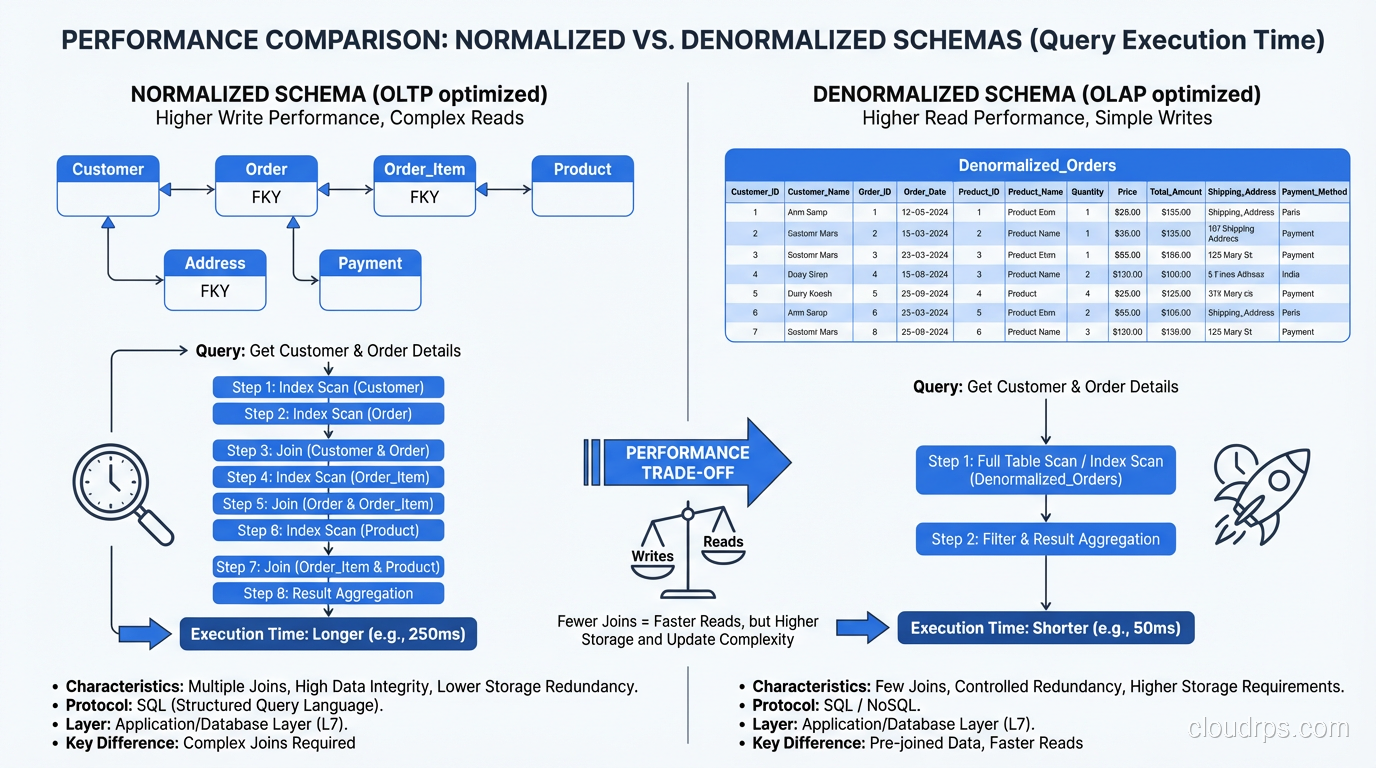
Normalized schemas are optimized for write correctness. Every fact stored once means every update touches one row. No anomalies, no inconsistencies. But reads, especially complex analytical reads, can become expensive because they require joining multiple tables to reassemble the complete picture.
In a normalized e-commerce schema, displaying an order summary might require joining orders, order_items, products, customers, addresses, and shipping_methods. That is five or six joins, each with its own index lookups and potential hash or merge join operations. For a single order detail page, this is fine. For a dashboard that aggregates ten million orders, it is a serious performance problem.
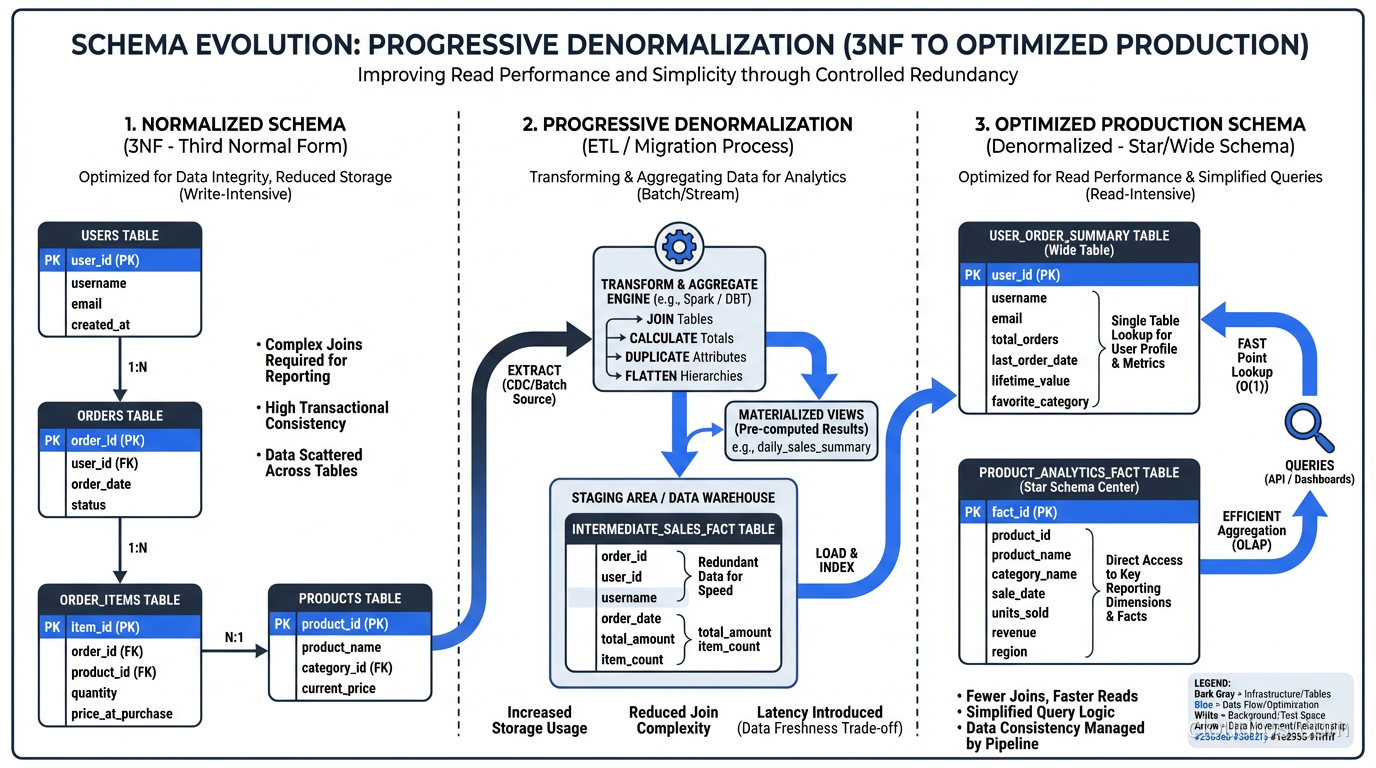
Denormalization trades write complexity for read performance. By pre-computing and storing redundant data, you reduce the number of joins required for common queries.
Denormalization Patterns I Use Regularly
Materialized aggregates. Instead of computing total_revenue by summing order_items at query time, store it as a column on the orders table and update it when items are added or removed. This trades a slightly more complex write path for dramatically faster reads.
Copied columns. Store customer_name and product_name directly in the order_items table alongside the foreign keys. This eliminates two joins for the most common query pattern (displaying order details) at the cost of storing the name twice and needing to handle name changes.
Precomputed lookup tables. Build summary tables that are refreshed on a schedule: daily revenue by region, monthly active users by plan, inventory counts by warehouse. These are essentially materialized views maintained by application logic or batch jobs.
Event sourcing with snapshots. Store the complete state of an entity at a point in time, rather than requiring the system to reconstruct it from a chain of normalized events. This is how I build audit logs that need to be queryable by historical state.
When to Denormalize: My Decision Criteria
I do not denormalize on a whim. I denormalize when all three of these conditions are met:
- A specific read query is too slow. Not hypothetically slow. Actually slow, measured in production, with evidence.
- The query cannot be optimized further within the normalized schema. Indexes, query rewrites, and database performance tuning have been exhausted.
- The cost of maintaining the denormalized data is acceptable. Keeping redundant data consistent adds complexity. If that complexity exceeds the read performance benefit, do not denormalize.
I emphasize condition #1 because premature denormalization is one of the most common mistakes I see. Teams denormalize during initial schema design because they anticipate a performance problem that may never materialize. They end up with the write complexity of a denormalized schema and discover that the read performance was never actually a bottleneck.
Start normalized. Measure. Denormalize surgically where the measurements demand it.
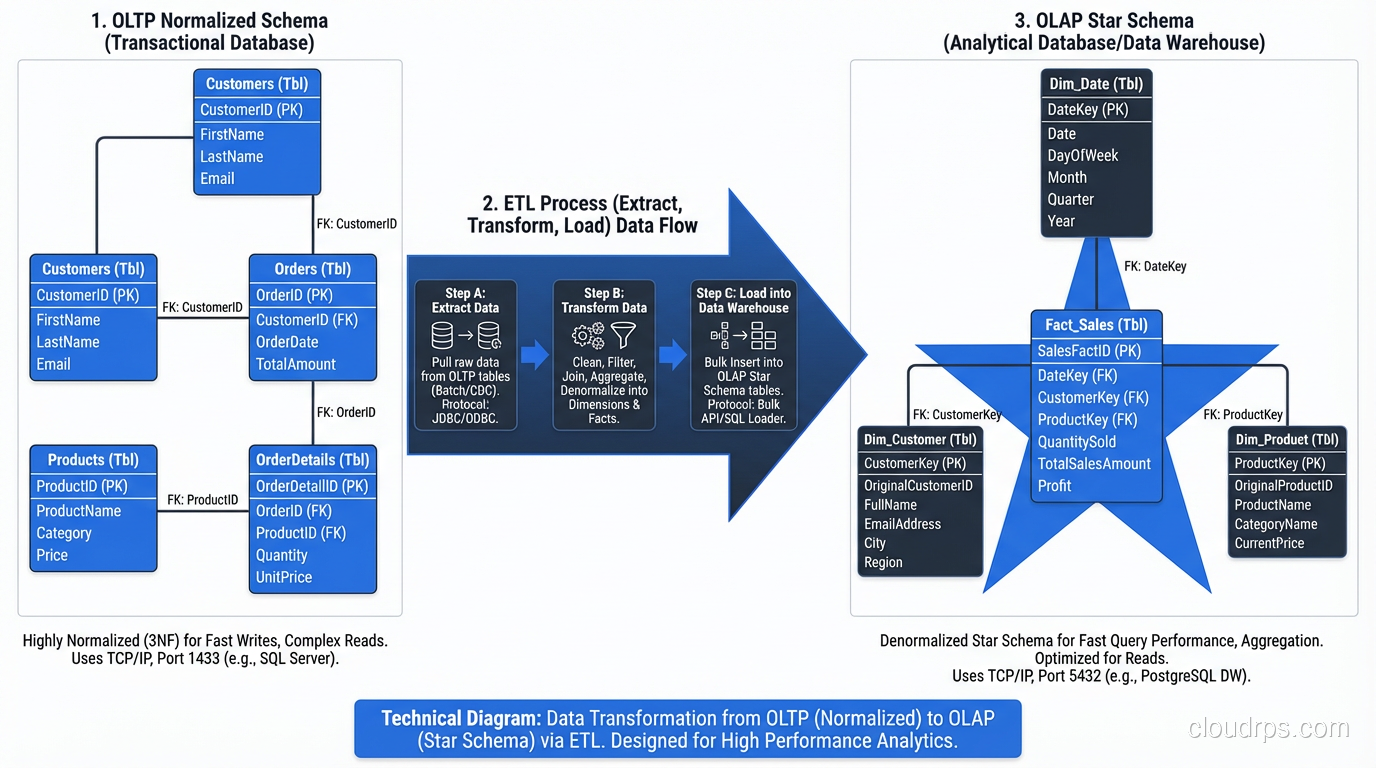
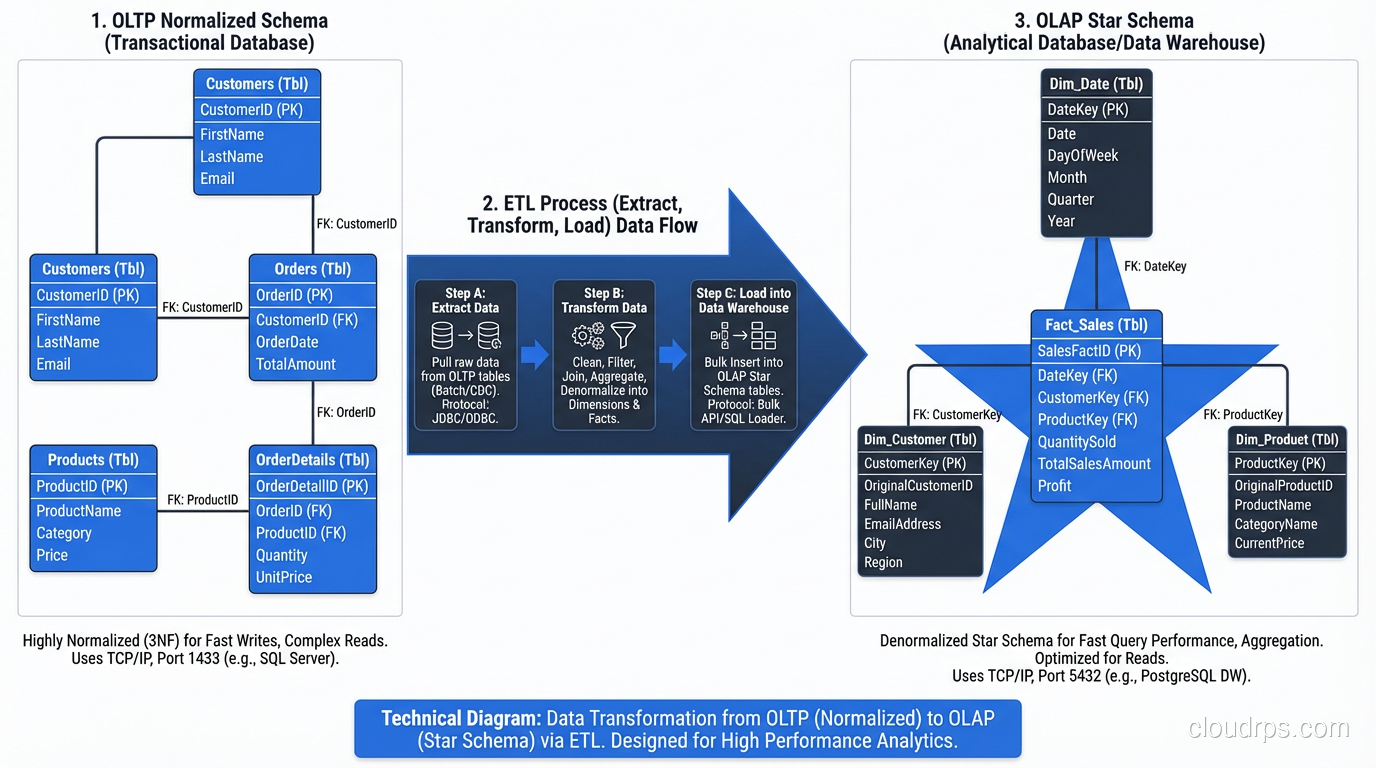
The OLTP/OLAP Split
The clearest pattern I have seen across hundreds of systems is that OLTP and OLAP workloads want fundamentally different levels of normalization.
OLTP (transactions): Normalize to 3NF. Your priority is write correctness, data integrity, and minimizing update anomalies. The queries are simple (fetch a customer, insert an order, update an inventory count) and the joins are small and fast.
OLAP (analytics): Denormalize aggressively. Your priority is read performance over massive datasets. Star schemas and snowflake schemas are specifically designed for analytical workloads, with a central fact table surrounded by dimension tables that contain denormalized, pre-joined data.
The right architecture is almost always to maintain both: a normalized OLTP database for your application and a denormalized OLAP database (or data warehouse) for analytics, with an ETL or CDC pipeline moving data between them.
This is not over-engineering. This is recognizing that two fundamentally different workload patterns need two fundamentally different data structures. Trying to serve both from a single schema is a compromise that satisfies neither.
For the core properties that make transactional systems reliable, I covered those foundations in my post on ACID properties.
Real-World War Story: The Over-Normalized Microservice
Let me tell you about a project where normalization went too far.
A team I inherited had built a customer management microservice with a beautifully normalized schema. The customers table had a foreign key to addresses, which had a foreign key to cities, which had a foreign key to states, which had a foreign key to countries. Phone numbers were in a separate table. Email addresses were in a separate table. Even customer names were decomposed into first_name, middle_name, last_name, suffix, and salutation columns in a separate person_names table.
Every query to display a customer profile required seven joins. The 95th percentile latency for the customer profile API was 340 milliseconds. The team had added read replicas and connection pooling and query caching, but the fundamental problem was that reassembling a customer from seven tables is inherently expensive when you do it millions of times a day.
We denormalized. We merged the address, name, and primary contact information back into the customers table. We kept the normalized structure for the portions of the schema that needed it (order history, multiple shipping addresses) but stopped pretending that a customer’s name needed its own table.
The p95 latency dropped to 12 milliseconds. The team eliminated two read replicas. The code got simpler. Nobody missed the purity.
Real-World War Story: The Under-Normalized Startup
The opposite cautionary tale. A startup had a single transactions table with 47 columns, including redundant copies of merchant information, customer information, product details, and computed totals. No foreign keys. No separate tables. Everything flat.
It was blazingly fast for reads, at first. Then the business grew. They needed to update merchant addresses and discovered they had to update millions of rows. They found that different rows had different addresses for the same merchant because some had been inserted before an address change and some after. Their financial reports did not add up because the precomputed totals were sometimes stale.
They spent four months refactoring to a normalized schema. Four months of careful migration, dual-writing, data reconciliation, and testing. It would have taken two weeks to design the normalized schema from the start.
Practical Guidelines for Schema Design
After thirty years, here is how I approach schema design for a new system.
Start with 3NF for your transactional database. Map your entities, define relationships, assign primary keys, and normalize. Do not skip this step. Even if you know you will denormalize later, the normalized model is the source of truth for understanding your data.
Identify your hot read paths early. What are the top five queries by frequency and criticality? If any of them require more than three joins, flag them as candidates for future denormalization. But do not denormalize yet. Build the normalized schema, deploy it, and measure.
Denormalize with a plan. When you denormalize, document what you denormalized, why, and how the redundant data is kept consistent. Is it updated synchronously in the same transaction? Is it updated asynchronously via a trigger or a background job? Is it eventually consistent? These details matter enormously when someone needs to debug an inconsistency two years from now.
Use database features to manage denormalization. PostgreSQL materialized views, MySQL generated columns, SQL Server indexed views: these features let you denormalize at the database level rather than the application level. The database maintains consistency for you, which is almost always more reliable than application code doing it.
Keep your normalized schema as the source of truth. Even when you have denormalized views and summary tables, the normalized tables should be authoritative. If there is ever a discrepancy, the normalized data wins and the denormalized data is rebuilt.
The NoSQL Angle
It is worth mentioning that the entire normalization conversation is rooted in relational database assumptions. Document databases like MongoDB, wide-column stores like Cassandra, and key-value stores operate on fundamentally different principles.
In MongoDB, the recommended approach is often to embed related data in a single document rather than normalizing it into separate collections. A customer document might contain their orders, addresses, and contact information in nested arrays. This is not denormalization in the traditional sense; it is a different data modeling paradigm entirely.
But the underlying tradeoffs are the same. Embedding (denormalizing) makes reads fast and writes complex. Referencing (normalizing) makes writes simple and reads require multiple queries. The physics does not change just because you switched databases.
I covered the broader SQL vs NoSQL decision in depth in a separate post if you want to dig into that comparison.
Final Thoughts
The normalization debate is not really a debate. It is a continuum. Every production database sits somewhere on the spectrum between fully normalized and fully denormalized, and the right position depends on the specific workload, the specific query patterns, and the specific consistency requirements.
What I push back on is dogma in either direction. The architect who insists on 5NF for everything will build a system that is correct but slow. The architect who insists on a flat schema for performance will build a system that is fast but wrong. The best systems I have worked on found the right balance: normalized where correctness matters, denormalized where performance demands it, and rigorously measured so that every deviation from the normalized ideal is justified by data rather than assumptions.
Start normalized. Measure ruthlessly. Denormalize surgically. That is the entire philosophy, and it has served me well for three decades.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.