The first time I truly understood the importance of database replication was at 2:47 AM on a Tuesday in 2006. Our primary PostgreSQL instance, a single server holding 800 GB of financial transaction data, had its RAID controller fail. No replica. No streaming standby. Just backups that were six hours old. We lost six hours of transactions, and I spent the next three weeks helping reconcile the data manually with downstream systems.
I have never run a production database without replication since that night. Not once. And in the twenty years since, I have built and operated replication topologies across PostgreSQL, MySQL, Oracle, SQL Server, and half a dozen distributed systems. The technology has improved enormously, but the core concepts, and the ways teams get burned, have remained remarkably consistent.
Let me walk you through how replication actually works, when to use which type, and the operational lessons that only come from running this stuff in production for years.
What Replication Actually Does Under the Hood
At its core, database replication is about maintaining copies of data across multiple servers. But “copies” undersells the complexity. The real question is: what exactly are you copying, and how?
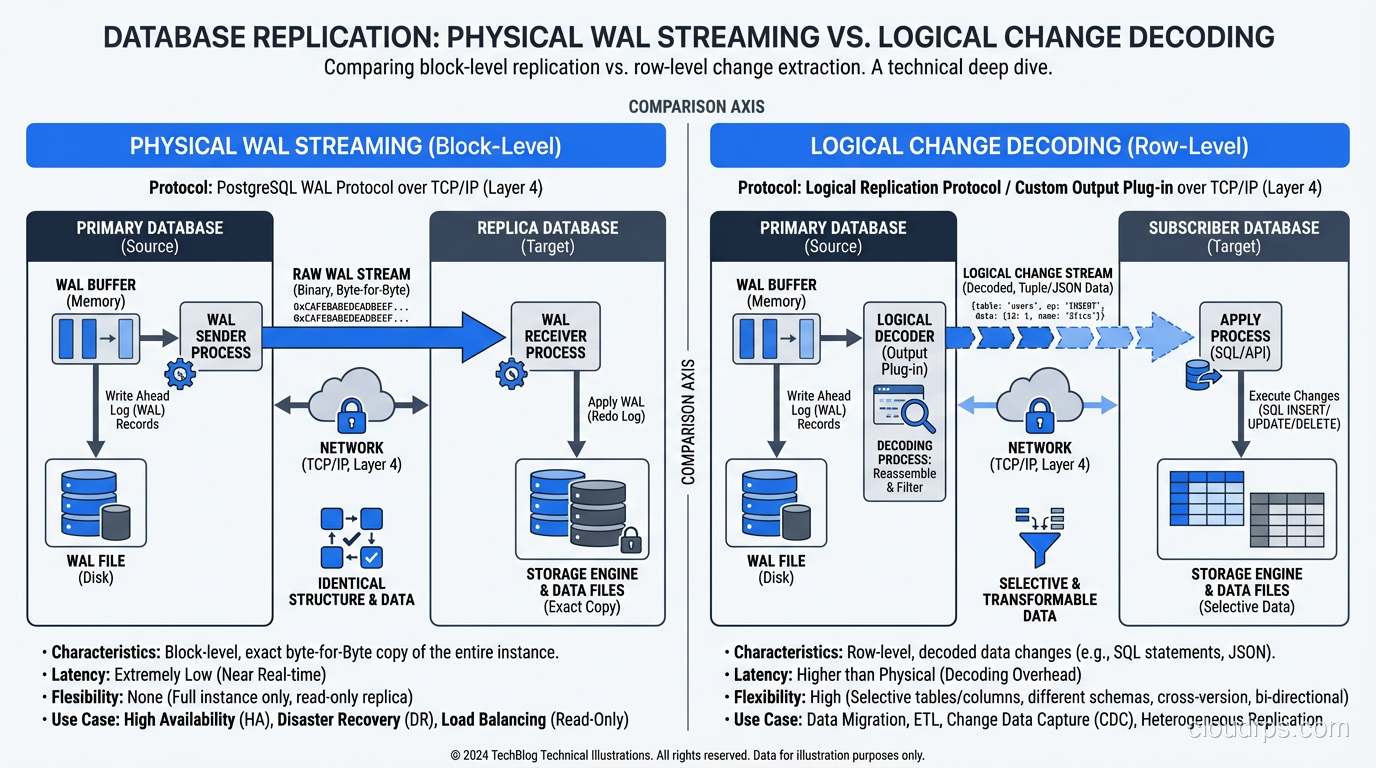
Physical (streaming) replication copies the raw bytes of the write-ahead log (WAL) from the primary to one or more replicas. The replica applies these WAL records to its own data files, producing a byte-for-byte identical copy of the primary. In PostgreSQL, this is streaming replication. In MySQL, the closest equivalent is semi-synchronous replication with row-based binary logging. In SQL Server, it is Always On Availability Groups.
Logical replication copies the logical changes (INSERT this row, UPDATE that column, DELETE this record) rather than the raw bytes. The replica interprets these logical operations and applies them independently. This means the replica does not need to be byte-for-byte identical. It can have different indexes, different table structures, even different database engines.
This distinction sounds academic, but it has profound practical implications that I have watched trip up dozens of teams.
Streaming Replication: The Workhorse
Streaming replication is what I reach for first when building a high-availability database cluster. The reason is simplicity and reliability.
The primary writes WAL records as part of its normal transaction processing. These records flow over a TCP connection to the replica, which writes them to its own WAL and replays them. The replica’s data files end up identical to the primary’s. If the primary fails, the replica can be promoted to primary because it has an exact copy of the data.
In PostgreSQL, setting up streaming replication takes about fifteen minutes of configuration. You set wal_level = replica on the primary, create a replication slot, configure the replica’s primary_conninfo, and start it up. The replica connects, fetches any missing WAL, and begins streaming in near-real-time.
The performance overhead on the primary is minimal. WAL is being written regardless of whether replication is active; the database needs it for crash recovery. Streaming replication just adds the cost of sending those bytes over the network, which is typically negligible compared to the cost of generating them.
Synchronous vs Asynchronous Streaming
Here is where the first real architectural decision comes in.
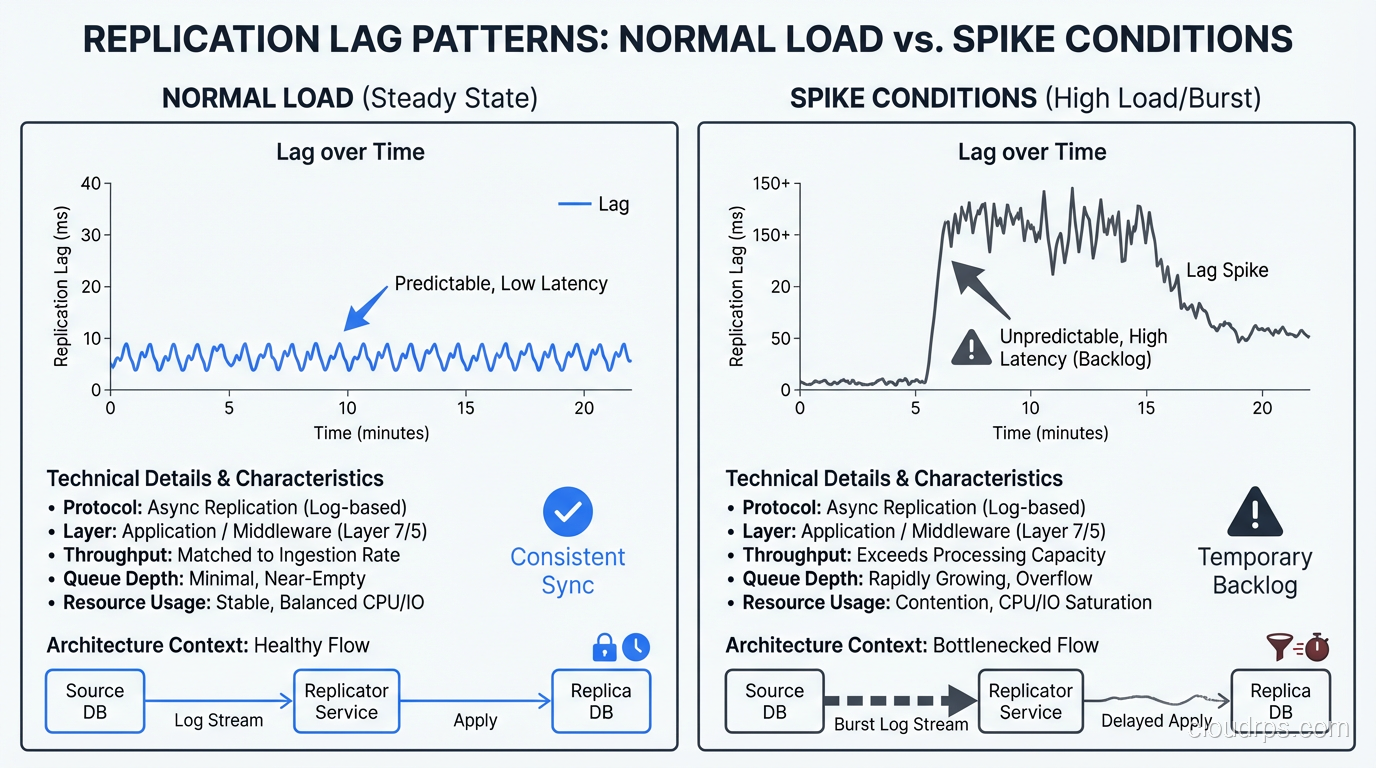
Asynchronous streaming replication means the primary does not wait for the replica to confirm receipt of WAL records before committing a transaction. This is the default in PostgreSQL and most other databases. The primary runs at full speed, and the replica follows behind, typically by a few milliseconds to a few seconds.
The risk is obvious: if the primary fails, any transactions that were committed on the primary but not yet replicated to the standby are lost. This is the replication lag window, and it represents your maximum data loss exposure (RPO).
Synchronous streaming replication means the primary waits for at least one replica to confirm that it has written the WAL to durable storage before the primary reports the transaction as committed. This gives you zero data loss. Every committed transaction is guaranteed to exist on at least two servers.
The cost is latency. Every commit now includes a round trip to the replica. If your replica is in the same data center, this adds 0.5-2 milliseconds per commit. If it is in another region, it adds 10-100+ milliseconds. For a workload that does 10,000 commits per second, that latency adds up fast.
I run synchronous replication for financial and healthcare workloads where data loss is unacceptable. For everything else, I run asynchronous with careful monitoring of replication lag. The lag is almost always under one second, and the performance benefit of not waiting for the replica is significant.
The Limitations of Streaming Replication
Streaming replication has three significant limitations that push teams toward logical replication.
The replica is read-only. Because it is a byte-for-byte copy of the primary, you cannot write to it. You cannot even create a temporary index to speed up a reporting query. In PostgreSQL, you can run read queries against a streaming replica, but any attempt to write will fail.
You cannot replicate selectively. Streaming replication copies everything. If you only need one table replicated to a downstream system, you still have to copy the entire database. For large databases, this means the replica needs as much storage as the primary, even if you only care about 5% of the data.
Cross-version and cross-platform replication is not supported. The replica must run the same major version of the database software as the primary. You cannot stream from PostgreSQL 15 to PostgreSQL 16, or from PostgreSQL to MySQL. This makes major version upgrades more complex, because you cannot use streaming replication to set up a new-version replica and cut over.
Logical Replication: The Flexible Alternative
Logical replication solves all three of those limitations, at the cost of additional complexity.
Instead of shipping raw WAL bytes, the primary decodes the WAL into logical change events. In PostgreSQL, this is done by a logical decoding plugin (like pgoutput, which is built in since PostgreSQL 10). These change events contain the table name, the operation type, and the row data. A subscriber on the replica side receives these events and applies them as SQL operations.
Because the replica is applying logical operations rather than raw bytes, it can:
- Accept writes. The replica is a fully functional database. You can write to tables that are not being replicated, create indexes, run DDL, whatever you need.
- Replicate selectively. You can publish specific tables from the primary and subscribe to only those tables on the replica.
- Cross versions and platforms. Logical replication works between different PostgreSQL major versions and, with tools like Debezium, between entirely different database systems.
This flexibility makes logical replication ideal for several use cases I encounter regularly.
Zero-downtime major version upgrades. Set up a new-version PostgreSQL instance, configure logical replication from the old version, let it catch up, then cut over. I have done this dozens of times and it works beautifully. The cutover window is typically under a minute.
Data integration and ETL. When you need to feed specific tables to a data warehouse, a search index, or a downstream microservice, logical replication is cleaner than trying to parse WAL files or build custom change data capture pipelines.
Multi-master architectures. Logical replication can (with careful design) support bidirectional replication, enabling writes in multiple regions. This is fraught with conflict resolution challenges, but for specific use cases (like sharded architectures where each region owns a partition of the keyspace), it works.
The Gotchas of Logical Replication
Logical replication is more powerful but also more fragile. Here are the operational pitfalls I have encountered.
Schema changes are not replicated automatically. If you add a column to a table on the primary, the logical replication stream will start sending rows with the new column, but the replica’s table does not automatically get the new column. If you do not coordinate DDL changes across primary and replica, replication breaks. I have been paged for this more than once.
Large transactions can cause problems. In PostgreSQL’s logical replication, a large transaction (say, a bulk UPDATE of 50 million rows) is decoded in memory on the primary. If your primary does not have enough memory, this can cause out-of-memory conditions. The logical_decoding_work_mem setting helps, but you need to be aware of it.
Sequence and DDL replication requires extra tooling. Logical replication in PostgreSQL handles DML (INSERT, UPDATE, DELETE) but not sequences, DDL, or large objects by default. If your application depends on sequences being in sync across primary and replica, you need to manage that separately.
Conflict resolution is your problem. If you are doing bidirectional logical replication and the same row is modified on both sides, the database does not resolve the conflict for you. You need to build conflict resolution logic, and getting that wrong corrupts data silently.
Replication Topologies I Have Actually Run in Production
Theory is useful, but let me describe the architectures that have actually worked for me at scale.
Primary with Two Synchronous Standbys (Financial Workloads)
For our payment processing system, I ran a PostgreSQL primary with two synchronous standbys in different availability zones. The synchronous_standby_names was configured with FIRST 1 (standby1, standby2), meaning the primary waited for the first standby to confirm each commit. If standby1 went down, commits would still succeed as long as standby2 was available.
Failover was automated through Patroni, which handles leader election via a distributed consensus store (etcd in our case). When the primary failed, Patroni promoted the most up-to-date standby within 10-15 seconds. Because replication was synchronous, there was zero data loss.
Primary with Async Standbys Plus Logical Replication to Analytics (SaaS Workloads)
For a SaaS product with 2 TB of data, I ran a primary with two async streaming standbys for read scaling and HA, plus logical replication of key tables to a separate PostgreSQL instance that fed our analytics pipeline. The streaming standbys handled read traffic. The logical replica fed Kafka, which fed our data warehouse.
This topology gave us HA, read scaling, and real-time analytics without overloading the primary. The key was keeping the logical replication publication narrow, covering only the tables the analytics pipeline actually needed.
Cascading Replication for Geo-Distribution
For a global application, I set up cascading streaming replication: primary in US-East, streaming standby in US-West, and a second standby in EU-West that streamed from US-West rather than directly from the primary. This reduced the network load on the primary and put the cross-Atlantic latency on the cascade rather than the primary’s commit path.
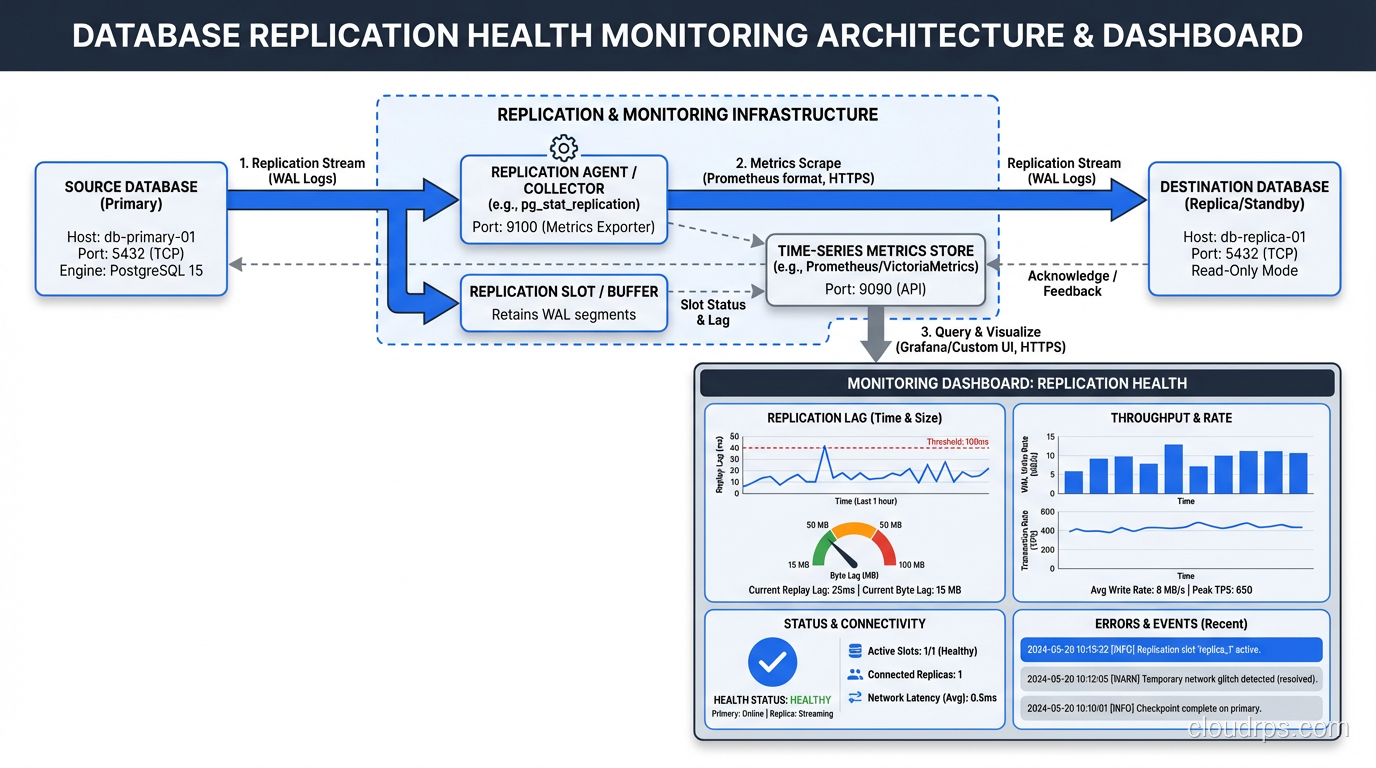
Monitoring Replication: The Non-Negotiable Metrics
If you are not monitoring these metrics, you are flying blind.
Replication lag. The time difference between the primary’s current WAL position and the replica’s applied position. For streaming replication in PostgreSQL, query pg_stat_replication on the primary. For logical replication, check pg_stat_subscription on the subscriber.
WAL generation rate. How fast the primary is producing WAL. If this spikes (due to a bulk load or a runaway update query), replication lag will increase. Watch for sustained rates that exceed your network bandwidth to the replica.
Replay rate on the replica. How fast the replica is applying WAL. If this drops below the generation rate for an extended period, the replica is falling behind and may never catch up without intervention.
Replication slot retention. In PostgreSQL, replication slots prevent the primary from discarding WAL that the replica has not yet consumed. If a replica goes down for an extended period, the primary’s WAL accumulates on disk. I have seen primaries run out of disk space because a forgotten replication slot held back WAL for days. Monitor pg_replication_slots and set max_slot_wal_keep_size to prevent this.
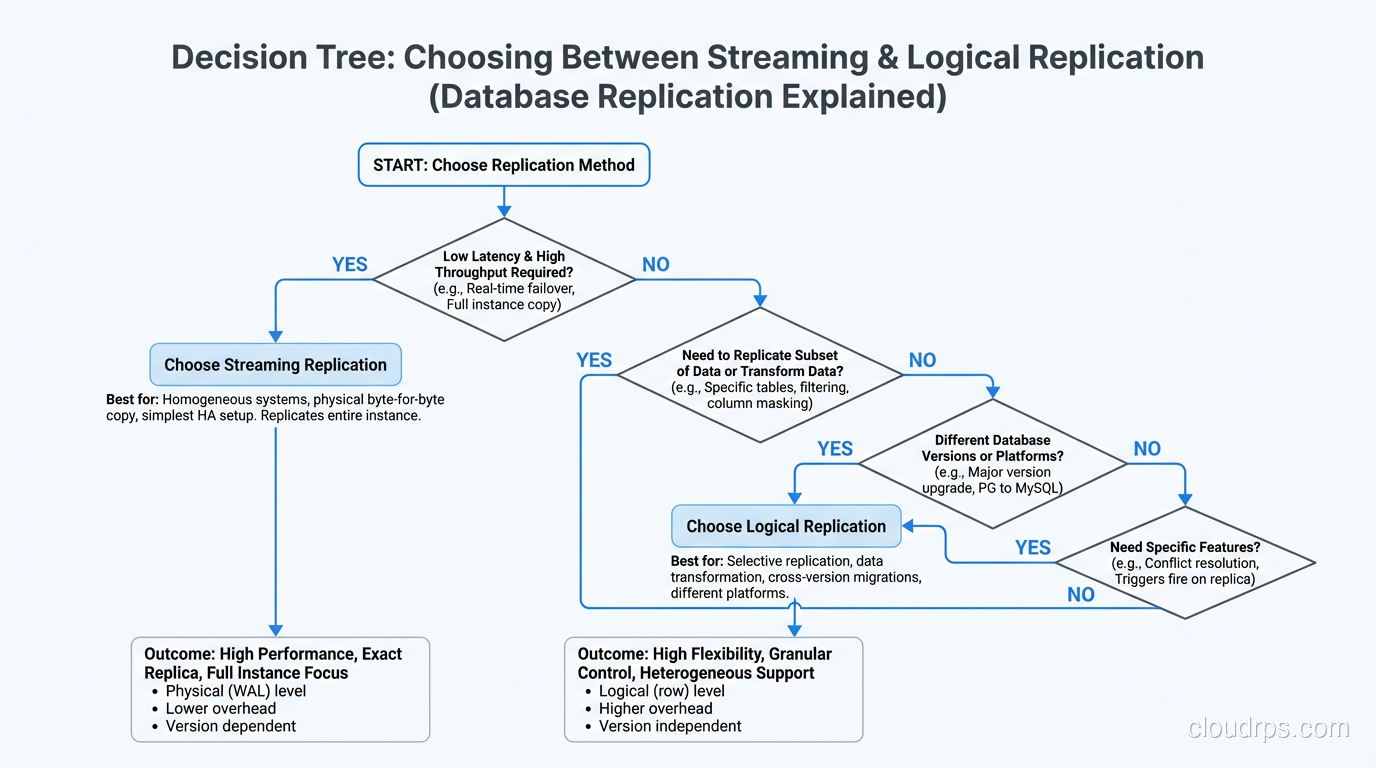
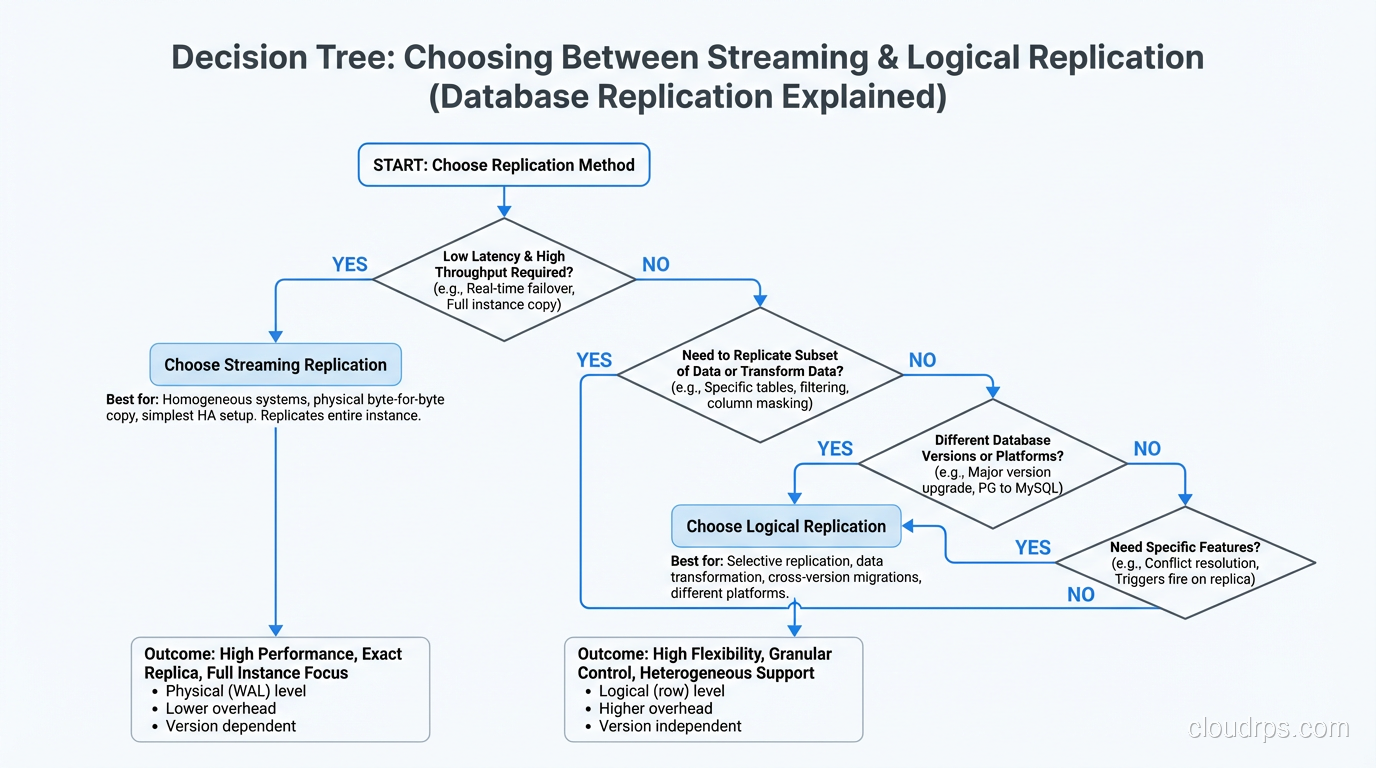
Choosing Between Them: My Decision Framework
After running both types of replication for years across many different workloads, my decision process is straightforward.
Default to streaming replication for high availability and disaster recovery. It is simpler to set up, simpler to operate, and the failover story is well-understood. If your primary concern is “the database should survive a server failure with minimal data loss,” streaming replication is the answer.
Add logical replication when you need selective replication, cross-version compatibility, or write capability on the replica. But go in with your eyes open about the operational complexity. Schema change coordination, conflict resolution, and monitoring are all more involved.
Never skip replication entirely. I do not care if it is a development database, a staging environment, or a “non-critical” internal tool. If the data matters to someone, replicate it. Disk is cheap. Rebuilding lost data from scratch is not.
For teams choosing between SQL and NoSQL databases, it is worth noting that replication architectures differ significantly between these worlds. NoSQL systems like Cassandra and MongoDB have replication built into their core architecture, while SQL databases treat it as an add-on feature. Neither approach is inherently better; they are different tradeoffs.
The Future: Change Data Capture and Event-Driven Architectures
Logical replication is evolving into something broader: change data capture (CDC). Tools like Debezium sit on top of a database’s WAL and emit every change as an event to Kafka or another message broker. Downstream consumers (search indexes, caches, analytics pipelines, other microservices) subscribe to these events and maintain their own views of the data.
This is where I see the industry heading. The primary database becomes the source of truth, and replication is not just for HA anymore. It is the backbone of the entire data architecture. Every write to the primary automatically propagates to every system that needs it.
I have been building CDC pipelines for the last five years, and the maturity of the tooling has improved enormously. Debezium with PostgreSQL’s logical decoding is production-ready and handles schema evolution, snapshotting, and exactly-once delivery (with some configuration work).
But CDC does not replace traditional streaming replication for HA. You still want a streaming standby that can be promoted in seconds. CDC is for data distribution; streaming replication is for database availability. They complement each other.
Parting Thoughts
Replication is one of those infrastructure topics where the setup takes a day and the operational knowledge takes years. The configuration is straightforward. Knowing what to do when replication lag spikes to 30 minutes at 2 AM, or when a logical replication slot fills up the primary’s disk, or when a network partition causes a split-brain scenario. That knowledge only comes from experience.
My strongest advice is to practice failure regularly. Take down a replica. Promote a standby. Break replication and fix it. Do all of this in a staging environment until the team can handle it without thinking. Because when the primary goes down in production, you need the response to be muscle memory, not a panicked search through documentation.
The data you are protecting is almost always more valuable than the infrastructure you are protecting it with. Invest in replication accordingly.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.