Early in my career I watched a production Oracle database go down mid-transaction during a storage failover. The operations team spent most of the night convinced data was lost. What saved them was the redo log, the Oracle term for what everyone else calls the write-ahead log. By morning, the database had replayed the log and recovered every committed transaction without losing a single row. I had read about durability in textbooks. That night I understood it.
Write-ahead logging is one of the most important ideas in database engineering, and it is remarkably underappreciated by the engineers who depend on it daily. If you run PostgreSQL, MySQL, CockroachDB, or nearly any serious relational database in production, WAL is doing constant work to keep your data safe. Understanding how it works changes how you think about performance tuning, replication, backup, and disaster recovery.
The Core Problem WAL Solves
Databases need to be durable: when a transaction commits, the data must survive a crash. The naive approach is to write every data change directly to the data files on disk before acknowledging the commit. This works, but it is catastrophically slow because random writes to disk are expensive. A database writing individual dirty pages for every transaction would top out at a few hundred transactions per second on spinning disk and not much more on SSD before I/O became the bottleneck.
The insight behind WAL is that sequential writes are far faster than random writes, on every storage medium that has ever existed. Instead of writing changed data pages randomly to their locations on disk, a database can write a sequential record of the change to the log first, acknowledge the commit, and flush the actual data pages later in the background. This is the write-ahead principle: write to the log before writing to the heap.
The log record is small and sequential. A batch of commits that would have required dozens of random page writes instead requires a single sequential append to the WAL file. Throughput goes from hundreds to tens of thousands of commits per second on the same hardware.
The tradeoff is that after a crash, the database cannot trust that data files reflect committed transactions. It must replay the WAL to reconstruct the committed state. This recovery procedure is the other half of the design.
The ARIES Algorithm
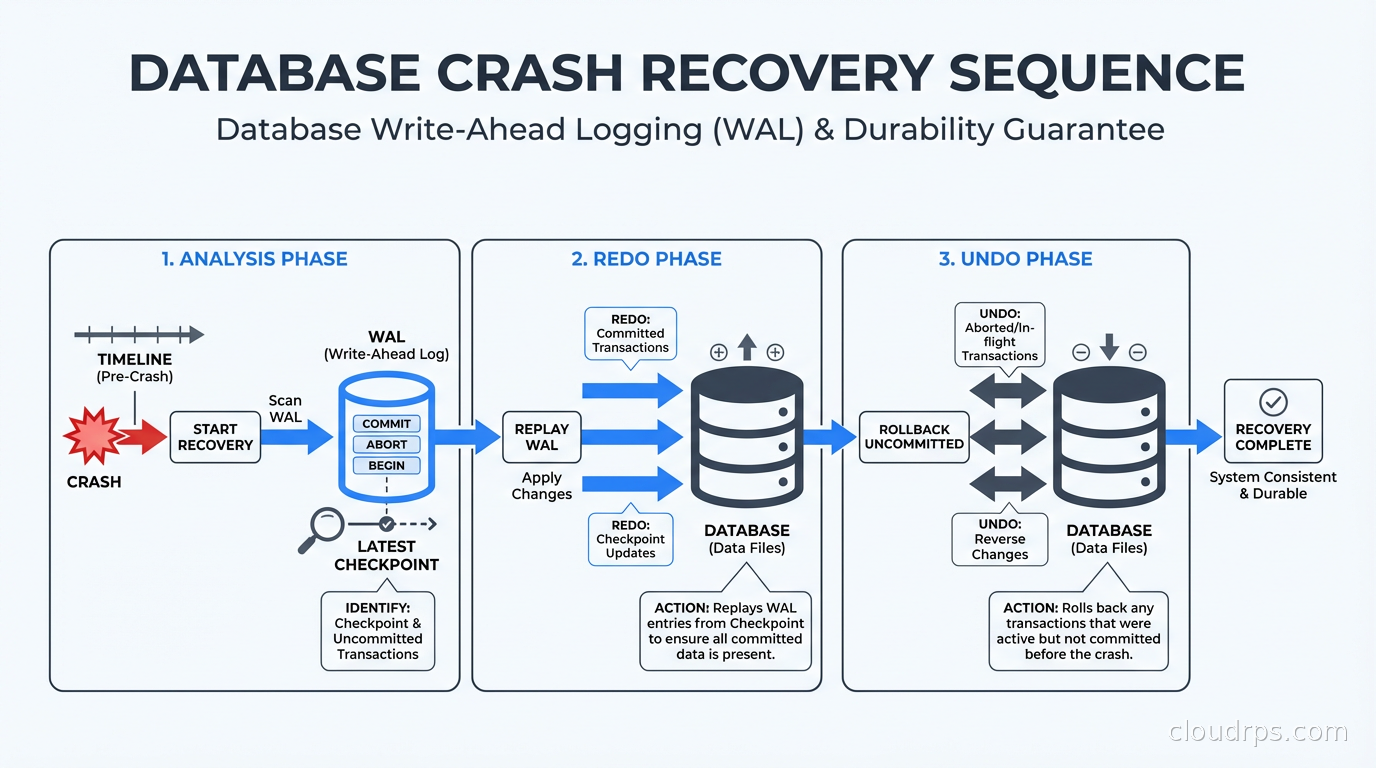
Modern WAL-based recovery is based on the ARIES algorithm, developed by researchers at IBM in the 1980s and published in a landmark 1992 paper. ARIES defines three recovery phases: analysis, redo, and undo.
Analysis reads the WAL from the last checkpoint forward to determine which transactions were active at crash time and which data pages might need recovery.
Redo replays all operations from the log, including uncommitted ones, to bring data files forward to the state they were in at crash time. The goal is physical consistency, not logical correctness yet.
Undo rolls back any transactions that were active but not committed at the time of the crash. It uses the WAL records to reverse the changes, leaving only committed data.
This sequence handles a range of failure modes correctly: crashes mid-write, crashes during checkpoint, even crashes during recovery itself. ARIES recovery is idempotent. You can replay the log multiple times and get the same result, which means a recovery that itself crashes can be safely restarted.
PostgreSQL’s recovery implementation follows ARIES closely, though with Postgres-specific terminology. MySQL’s InnoDB engine independently arrived at a similar design. The conceptual foundation is the same across most serious databases.
How WAL Works in PostgreSQL
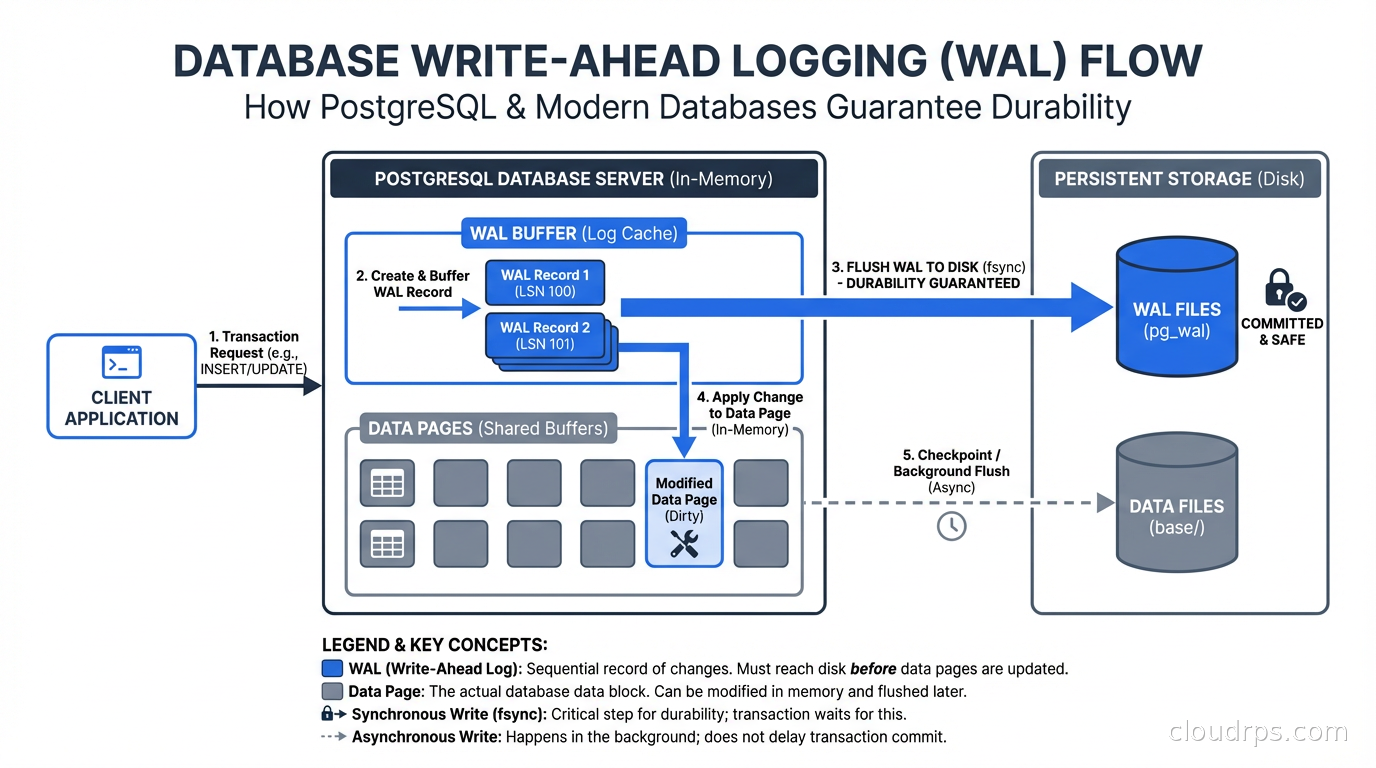
PostgreSQL writes WAL records to a sequence of 16MB segment files in the pg_wal directory (formerly pg_xlog before version 10). Each WAL record describes a change at the physical level: which page, which offset, what the new bytes are. The WAL record also includes the transaction ID and a log sequence number (LSN) that uniquely identifies this record’s position in the log.
The critical sequence for a write operation:
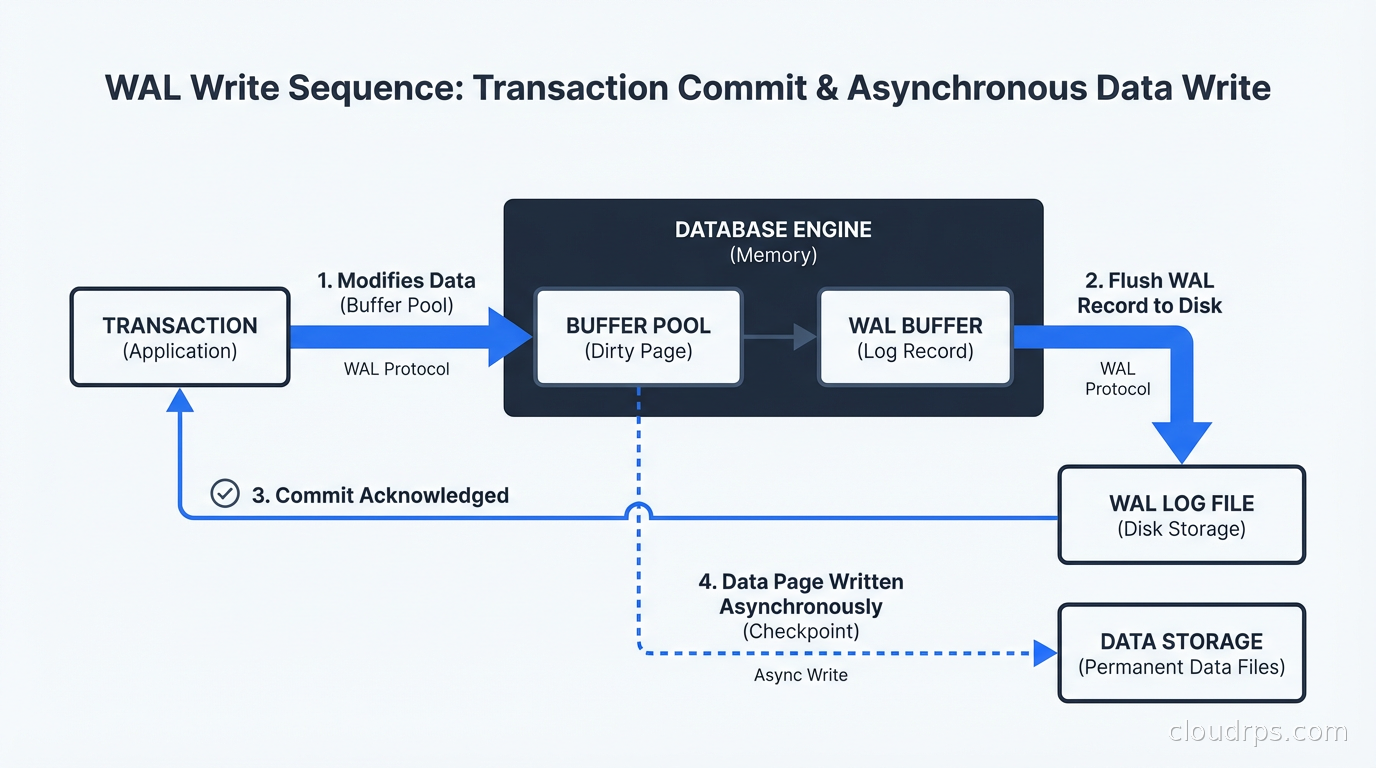
- A transaction modifies a data page in the shared buffer pool (in-memory cache).
- Before acknowledging the commit, the WAL record for that modification is written to the WAL buffer and then flushed to disk.
- The commit success is returned to the client.
- The modified data page in the buffer pool is eventually written to the heap file on disk, asynchronously, by the background writer.
The guarantee is that step 2 completes before step 3. The WAL record always reaches durable storage before the commit acknowledgment goes out. The data page write in step 4 can happen at any time after that, even minutes later.
The checkpoint process periodically flushes all dirty data pages to disk and writes a checkpoint record to the WAL. After a checkpoint, WAL records before the checkpoint are no longer needed for crash recovery because all the pages they describe are already on disk. This keeps the WAL from growing without bound and speeds up recovery by limiting how far back the redo phase needs to go.
WAL Levels in PostgreSQL
PostgreSQL exposes a wal_level configuration parameter that controls how much information is written to the WAL:
minimal: The minimum needed for crash recovery. WAL records describe physical page changes. This is the smallest WAL and the fastest write path, but it cannot be used for replication.
replica: Adds information needed to support streaming replication to standby servers. This is the default and what most production systems use.
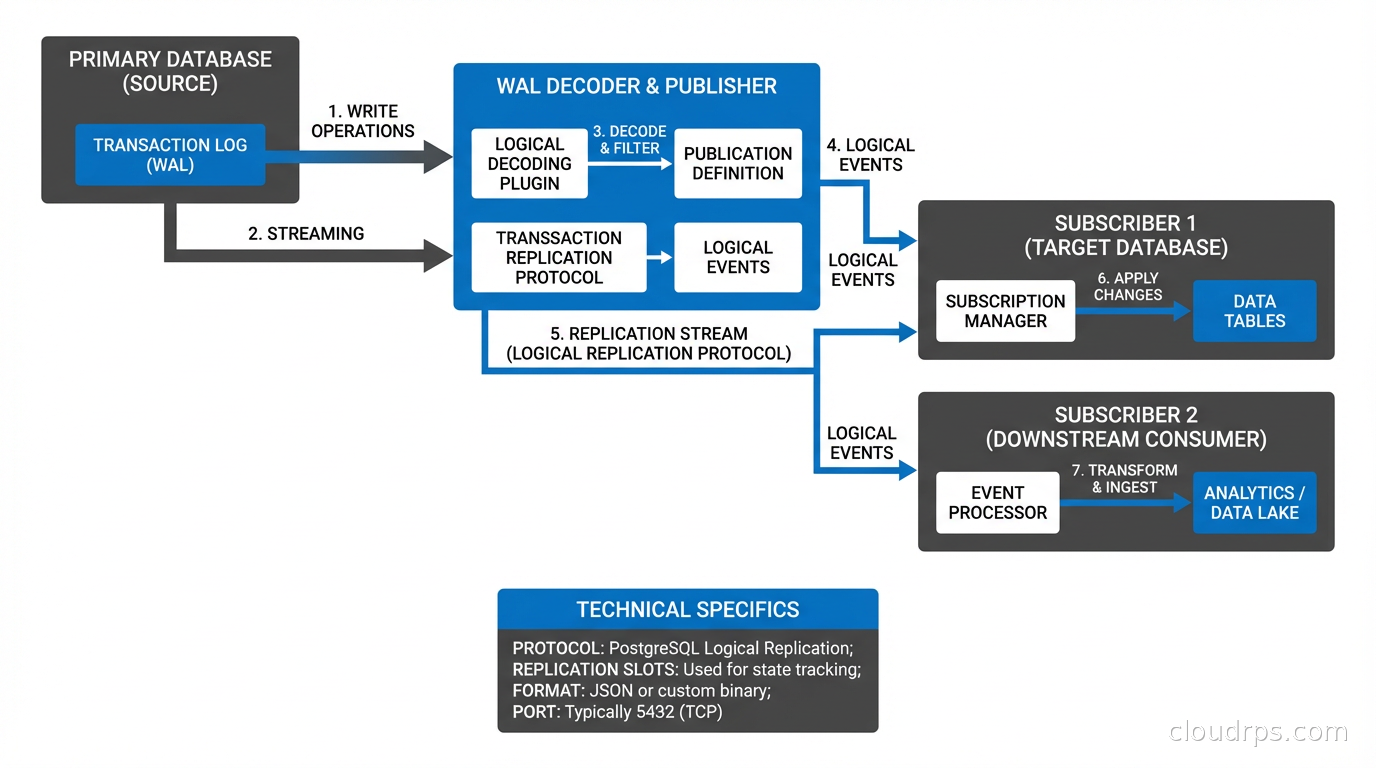
logical: Adds information needed to reconstruct the original logical operations (INSERT, UPDATE, DELETE) rather than just the physical page changes. This is required for logical replication and for change data capture tools like Debezium.
The difference between replica and logical WAL matters when you are building event streaming pipelines. Physical replication can replay WAL to a standby, but only an identical copy of the database. Logical replication decodes the WAL into logical operations that can be applied to different database structures, different versions of PostgreSQL, or streamed to a message queue.
Crash Recovery in Practice
After an unclean shutdown, PostgreSQL enters recovery mode automatically on restart. It reads the control file to find the latest checkpoint location, then replays all WAL records from that checkpoint forward.
During redo, PostgreSQL applies each WAL record to the data pages. It checks the LSN on each page against the LSN in the WAL record: if the page LSN is already at or past the record’s LSN, the change has already been applied and is skipped. This idempotency means you cannot double-apply changes even if recovery is interrupted and restarted.
After redo completes, any transactions that were in progress at crash time are rolled back using the WAL records in reverse order. The database is then consistent and ready to accept connections.
How long does recovery take? It depends on how far back the last checkpoint was and how much WAL accumulated since. PostgreSQL’s checkpoint_completion_target and checkpoint_timeout parameters control checkpoint frequency. More frequent checkpoints mean faster recovery but more I/O during normal operation. In a well-tuned production system, recovery from a crash typically completes in under a minute.
WAL as the Foundation of Replication
Physical streaming replication in PostgreSQL works by shipping WAL records from the primary to one or more standby servers, which replay them continuously. The standby maintains its own WAL position, the replay LSN, and stays as close to the primary as the network and standby hardware allow.
This is how database replication achieves its durability guarantees. In synchronous replication mode, the primary waits for at least one standby to confirm WAL receipt before acknowledging the commit. Your data is in two places before the client sees success. In asynchronous mode, the primary does not wait, which is faster but means a small window of potential data loss if the primary fails before the standby catches up.
Logical replication, available natively since PostgreSQL 10, builds on the logical WAL level. A publication on the primary defines which tables to replicate. A subscription on the destination pulls the decoded logical operations. This allows replicating selected tables, replicating to a different schema structure, replicating to a different database version, or streaming changes into Kafka for downstream consumers.
The ACID property of durability is only as strong as your WAL configuration. If synchronous_commit is set to off, PostgreSQL acknowledges commits before the WAL is flushed to disk. You get better write throughput but lose the durability guarantee. For a cache or a session store where you can tolerate losing the last second of data on a crash, this is a reasonable trade. For financial transactions or user data, it is not.
MySQL Binlog and InnoDB Redo Log
MySQL has two logging mechanisms that serve overlapping roles. The InnoDB redo log (sometimes called the InnoDB WAL) handles crash recovery at the storage engine level, functioning similarly to PostgreSQL’s WAL with physical page records. The binary log (binlog) handles replication and point-in-time recovery at the MySQL server level with logical event records.
When you commit a transaction in MySQL, both logs must be written in a coordinated two-phase commit. The InnoDB redo log is prepared first, then the binlog is written and flushed, then the InnoDB redo log is committed. This two-phase protocol ensures that the two logs stay consistent with each other even through a crash. It is also a source of complexity that PostgreSQL avoids by having a single WAL that serves both purposes.
MySQL 8.0 introduced a redesigned redo log that is a circular buffer of two files, compared to the older fixed-size redo log files. The size is configurable with innodb_redo_log_capacity. A redo log that is too small causes excessive checkpoint pressure and hurts write throughput; too large and crash recovery takes longer. Sizing it correctly for your write load is one of the InnoDB tuning levers that actually moves the needle.
WAL and Backup Strategy
WAL archiving is how PostgreSQL implements point-in-time recovery (PITR). You configure archive_mode and an archive_command that copies completed WAL segments to a backup location, typically object storage. Combined with a base backup of the data directory, you can restore the database to any point in time by replaying WAL from the base backup forward.
This is fundamentally different from logical backups like pg_dump, which capture a consistent snapshot but require downtime proportional to database size for large databases and cannot recover to an arbitrary point in time. WAL-based PITR can recover to any second, not just the last backup window.
The implication for disaster recovery planning is that your RPO for WAL-archived PostgreSQL is bounded by your WAL archival frequency. If you archive WAL segments continuously to S3 and they arrive within 30 seconds, your worst-case data loss on a total primary failure is 30 seconds. This is typically far better than what you can achieve with scheduled backups.
Tools like pgBackRest and Barman automate WAL archiving, compression, encryption, and retention management. For production PostgreSQL, using one of these tools rather than a hand-rolled archive command is worth the operational investment.
Performance Implications
WAL is not free. Every write transaction pays a WAL write cost before it can complete. The main levers:
wal_compression: Compresses WAL records using lz4 or zstd. Reduces WAL volume (good for replication network bandwidth and archive storage costs) at the cost of some CPU. Worth enabling in almost all cases on modern hardware.
wal_buffers: Controls the in-memory WAL buffer before it is flushed to disk. The default is 1/32 of shared_buffers, capped at 16MB. For write-heavy workloads, increasing this to 32MB or 64MB reduces the frequency of partial WAL writes.
Synchronous commit: Setting synchronous_commit = local means the WAL is written to local disk before commit acknowledgment but standby confirmation is not required. This gives you durability against local crashes while allowing some replication lag without delaying commits.
Group commit: PostgreSQL automatically batches WAL flushes when multiple transactions commit close together. If your write workload is concurrent, group commit dramatically increases effective throughput by amortizing the flush cost across many commits. This is why write benchmarks often show PostgreSQL performing much better under concurrent load than under sequential single-threaded load.
Common WAL-Related Production Issues
WAL accumulation during long-running transactions: A transaction that has been open for hours prevents WAL cleanup. The database must retain all WAL generated since the transaction started because recovery would need to roll it back. This can fill your pg_wal directory and cause the database to stop accepting writes. Monitor pg_stat_activity for long-running transactions in production.
Replication slot lag: Replication slots hold WAL on the primary until the subscriber confirms receipt. If a subscriber falls behind or disconnects without dropping its slot, WAL accumulates indefinitely. Set max_slot_wal_keep_size to limit how much WAL a slot can hold, at the cost of the subscriber needing to resync if it exceeds the limit.
WAL level changes requiring restart: Changing wal_level requires a PostgreSQL restart. If you need to add logical replication to a running production database, plan for a maintenance window. This is not something you can do online.
Archive command failures: If your archive_command starts failing (S3 outage, disk full on the archive host), WAL segments accumulate locally. PostgreSQL will never delete a WAL segment that has not been successfully archived. Watch archive success rate as a production metric, not just an afterthought.
Connecting WAL to Database Architecture Decisions
WAL is why connection pooling with PgBouncer matters at the database level. Each connection that holds an open transaction holds WAL records in place. High connection counts with long-lived transactions are the primary cause of WAL directory bloat in my experience.
WAL is why sharding does not eliminate the need for careful WAL management: it distributes the WAL across shards, but each shard still has its own WAL with the same failure modes. A globally distributed system like CockroachDB uses a Raft-based log that is conceptually similar to WAL but operates across a consensus group rather than a single node.
The CAP theorem intersection with WAL shows up in how synchronous replication is configured. Synchronous commit to a quorum of standbys gives you durability and partition tolerance guarantees, but adds latency to every write. It is a real trade-off, not a free lunch.
Understanding WAL mechanics gives you better intuitions about your database’s behavior under load, during failures, and across upgrades. When something goes wrong in production at 2 AM, that understanding is what separates a 20-minute recovery from a six-hour one.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.