The call came at 6:47 AM on a Saturday. Our client’s e-commerce platform was down. Not slow, not degraded – completely unreachable. The network operations center had already burned through their runbook: restart the web servers, check the load balancers, verify DNS. Nothing was wrong with any of those systems. What was wrong was that 40 Gbps of UDP traffic was hammering their upstream link, saturating the pipe before a single legitimate packet could get through.
That was my introduction to volumetric DDoS. The attack lasted 14 hours. The client lost an estimated $2 million in sales. And the attacker? We never identified them with certainty, but the timing – the day after the client publicly undercut a competitor’s pricing – was suspicious.
Since that Saturday morning, I’ve dealt with dozens of DDoS incidents across multiple industries. They’ve gotten bigger, more sophisticated, and more accessible to attackers. A 40 Gbps attack was terrifying in 2014. Today, attacks regularly exceed 1 Tbps. Let me explain how these attacks work and, more importantly, how to survive them.
What Makes DDoS Different From DoS
A Denial of Service (DoS) attack overwhelms a target with traffic or requests from a single source. These are relatively easy to mitigate – block the source IP and you’re done.
A Distributed Denial of Service (DDoS) attack uses thousands or millions of sources, making simple blocking impossible. The traffic comes from compromised IoT devices, rented botnets, amplification reflectors, and cloud instances distributed across the globe. You can’t block all of them without blocking the entire internet.
The “distributed” part is what makes DDoS devastating. It transforms a problem that’s solvable at the network edge into one that requires capacity that exceeds what most organizations can provision independently.
The Three Categories of DDoS Attacks
Every DDoS attack falls into one of three categories, defined by which layer of the stack it targets.
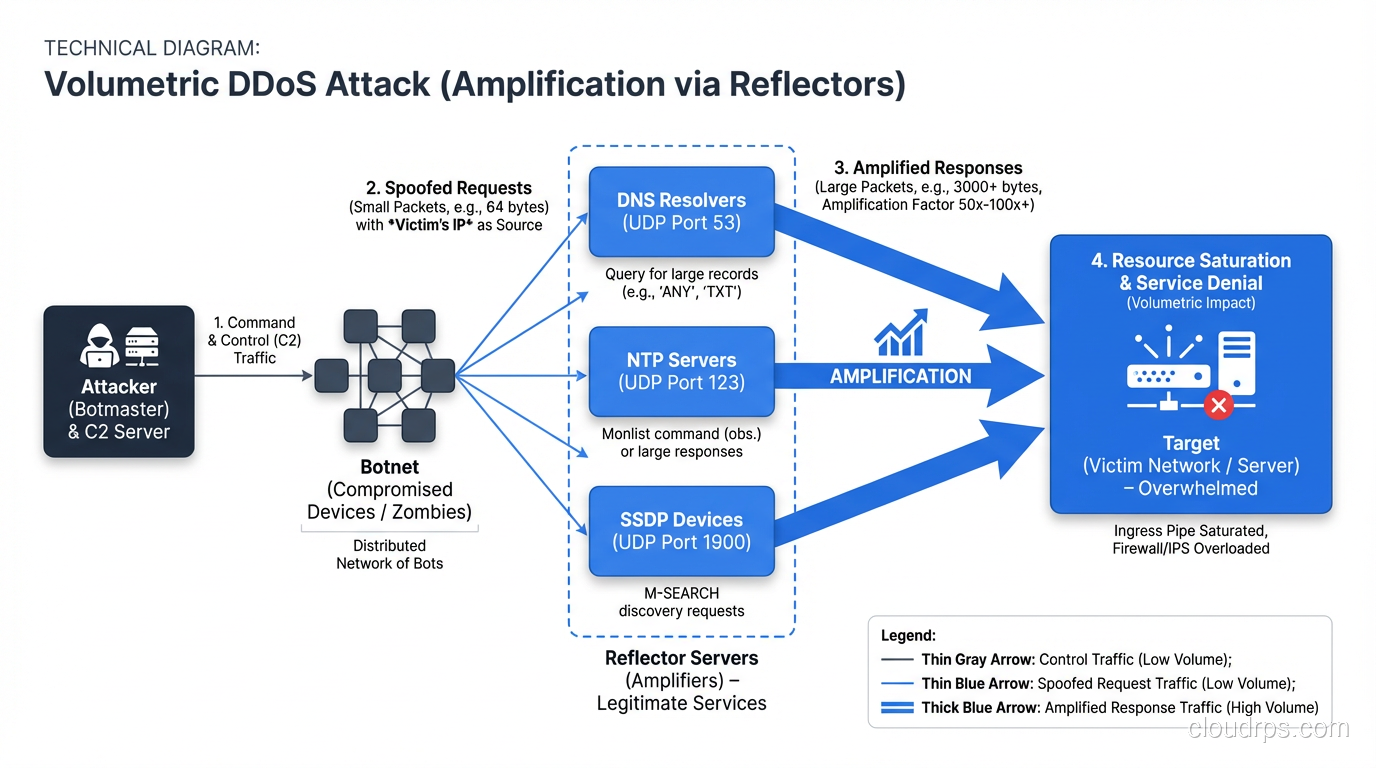
Volumetric Attacks (Layer 3/4)
The brute force approach. Flood the target’s network connection with more traffic than it can handle. The goal isn’t to exploit a vulnerability – it’s to fill the pipe.
UDP Flood: The simplest volumetric attack. The attacker sends massive amounts of UDP packets to random ports on the target. The target’s system checks for applications listening on those ports, finds nothing, and responds with ICMP “destination unreachable” packets. At sufficient volume, the target’s bandwidth is consumed.
DNS Amplification: The attacker sends DNS queries to open resolvers with the source IP spoofed to the target’s address. A 60-byte DNS query can generate a 4000-byte response – a 65x amplification factor. Multiply that by thousands of open resolvers, and you get massive traffic volumes directed at the target.
NTP Amplification: Similar to DNS amplification but using NTP’s monlist command, which returns a list of the last 600 clients. Amplification factors can exceed 500x. A single NTP packet from the attacker generates 500x the traffic aimed at the victim.
Memcached Amplification: The most extreme amplification vector discovered, with factors exceeding 50,000x. The February 2018 attack on GitHub peaked at 1.35 Tbps using memcached amplification. This is what happens when services that should never be internet-accessible are left exposed.
Protocol Attacks (Layer 3/4)
These exploit weaknesses in network protocol handling to exhaust server resources like connection state tables, CPU capacity, or firewall session limits.
SYN Flood: The attacker sends a flood of TCP SYN packets with spoofed source addresses. The target allocates resources for each half-open connection and sends SYN-ACK responses to addresses that will never respond. The target’s connection table fills, and legitimate connections can’t be established.
Ping of Death / Fragmentation Attacks: Malformed or fragmented packets that exploit reassembly vulnerabilities. Less common today but still seen in the wild against legacy systems.
Smurf Attack: ICMP echo requests sent to a network’s broadcast address with the source IP spoofed to the target. Every host on the network responds to the target. Largely mitigated by modern network configurations but historically devastating.
Application Layer Attacks (Layer 7)
The most insidious category. These attacks target the application layer with traffic that looks legitimate, making them extremely difficult to distinguish from real users.
HTTP Flood: The attacker sends seemingly legitimate HTTP requests at a rate that overwhelms the web server or application backend. Each request might trigger a database query, a file read, or a computation-heavy operation. The traffic passes through the network layer without triggering volumetric defenses.
Slowloris: The attacker opens connections to the target and sends partial HTTP headers, keeping connections alive as long as possible. By slowly feeding header data, the attacker ties up all available connections without generating significant bandwidth.
DNS Query Flood: Unlike DNS amplification (which uses DNS as the weapon), DNS query floods target the victim’s DNS infrastructure directly. If an attacker can take down your DNS, your entire internet presence disappears regardless of how much server capacity you have.
Application Logic Attacks: Targeting expensive operations like search queries, report generation, or password reset endpoints. These require deep knowledge of the target application but can be devastatingly effective because a single request might consume disproportionate server resources.
Application layer attacks are why a WAF is part of the DDoS defense strategy, not just a web security tool. A WAF can identify and block malicious Layer 7 traffic that network-level DDoS defenses miss entirely.
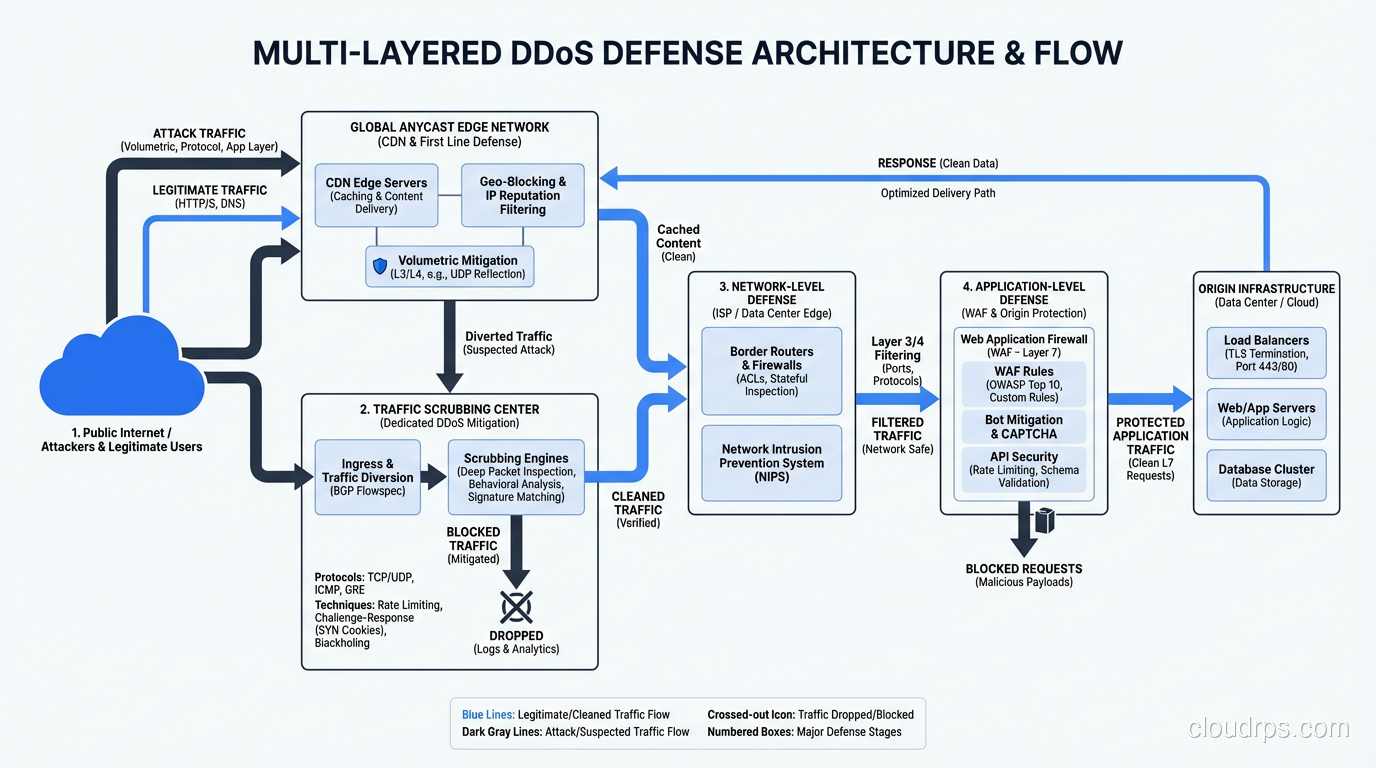
Mitigation Strategies: A Layered Defense
There’s no single defense against DDoS. Effective mitigation requires multiple layers, each addressing a different attack type.
Layer 1: Overprovisioning and Anycast
The most basic defense against volumetric attacks is having more capacity than the attacker. This isn’t practical for most organizations on their own, but it’s the foundation of CDN and DDoS mitigation services.
CDN providers like Cloudflare, Akamai, and AWS CloudFront distribute your content across hundreds of global edge locations. An attack that might overwhelm a single data center is absorbed across the CDN’s distributed network. Anycast routing ensures that attack traffic is handled by the nearest edge node, spreading the load geographically.
Layer 2: Upstream Filtering and Scrubbing
DDoS scrubbing services (Cloudflare, Akamai Prolexic, AWS Shield Advanced, Radware) route your traffic through their infrastructure during an attack. Their scrubbing centers – facilities with hundreds of gigabits of capacity – filter malicious traffic and forward only clean traffic to your origin.
The two deployment models:
Always-on: All traffic always routes through the scrubbing service. Higher latency during normal operations but instant protection during attacks. This is what I recommend for any business where downtime costs exceed the service cost.
On-demand: Traffic routes directly to your origin normally. When an attack is detected, BGP routes are changed to redirect traffic through the scrubbing service. The switchover takes minutes, during which you’re unprotected. Cheaper but riskier.
Layer 3: Network-Level Defenses
At your own network edge, you can implement:
Rate limiting: Cap the number of requests per source IP per time window. Effective against smaller attacks and application layer floods. Ineffective against distributed attacks using millions of sources.
Blackhole routing: When under attack, route the target IP’s traffic to null (a “black hole”). This kills the attack traffic but also drops all legitimate traffic to that IP. It’s a last resort that sacrifices availability of the target to protect the rest of your network.
Access control lists: Block known bad source networks, geographic regions you don’t serve, and protocols you don’t use. If your application doesn’t use UDP, block it at the network edge. This eliminates entire categories of volumetric attacks.
BGP Flowspec: If your upstream providers support it, Flowspec lets you push granular traffic filtering rules to the ISP’s routers. This stops attack traffic before it ever reaches your network.
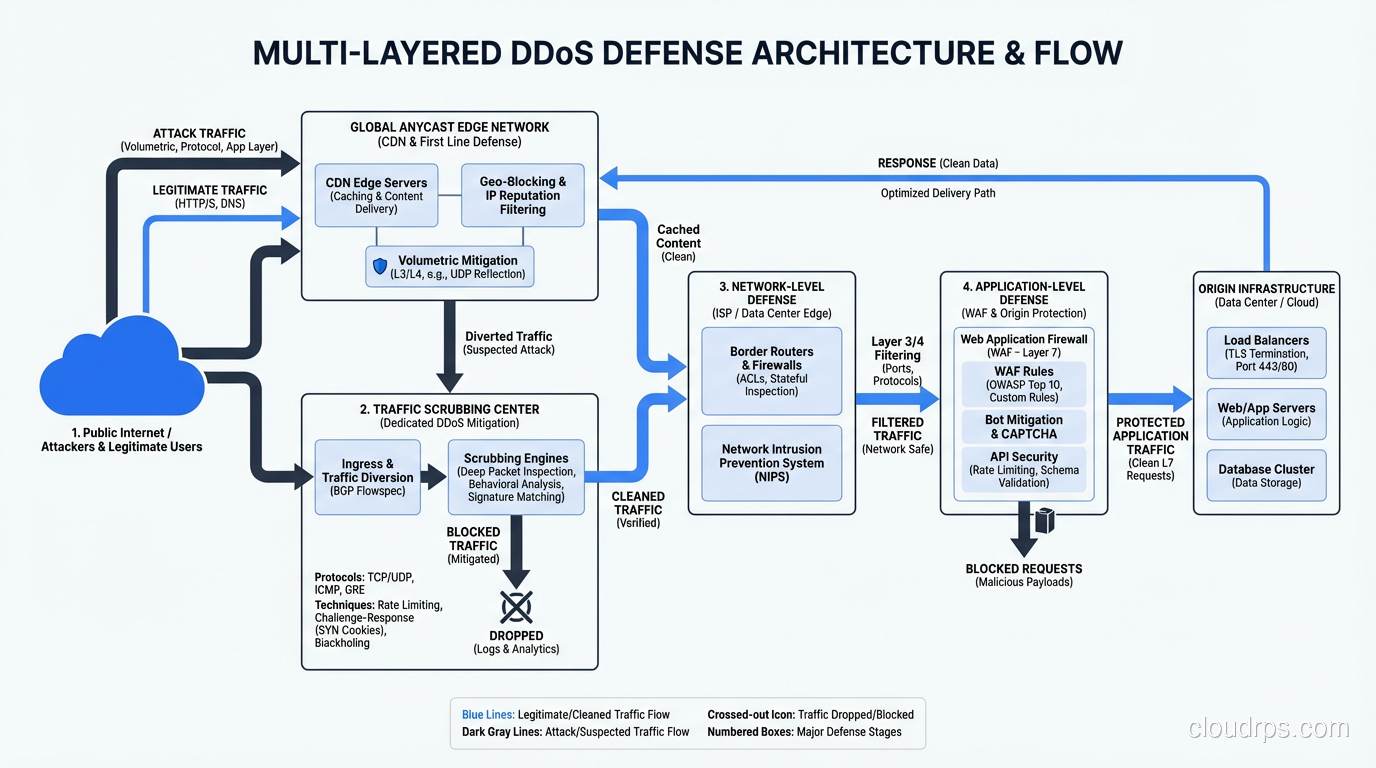
Layer 4: Application-Level Defenses
WAF rules: Block known DDoS tool signatures, enforce request rate limits, and filter traffic that violates your application’s expected patterns.
CAPTCHA and JavaScript challenges: Force clients to prove they’re human browsers, not bots. Effective against application layer floods but degrades user experience.
Connection rate limiting: Limit the number of concurrent connections per IP. Effective against Slowloris-style attacks.
Intelligent load shedding: When under attack, prioritize authenticated users over anonymous traffic. Serve cached content instead of hitting the database. Degrade gracefully rather than fail completely.
Layer 5: IDS/IPS Integration
Your intrusion detection and prevention systems can identify DDoS patterns and trigger automated responses. Modern NGFW and IPS platforms include DDoS-specific signatures that detect amplification traffic, SYN flood patterns, and application layer attack tools.
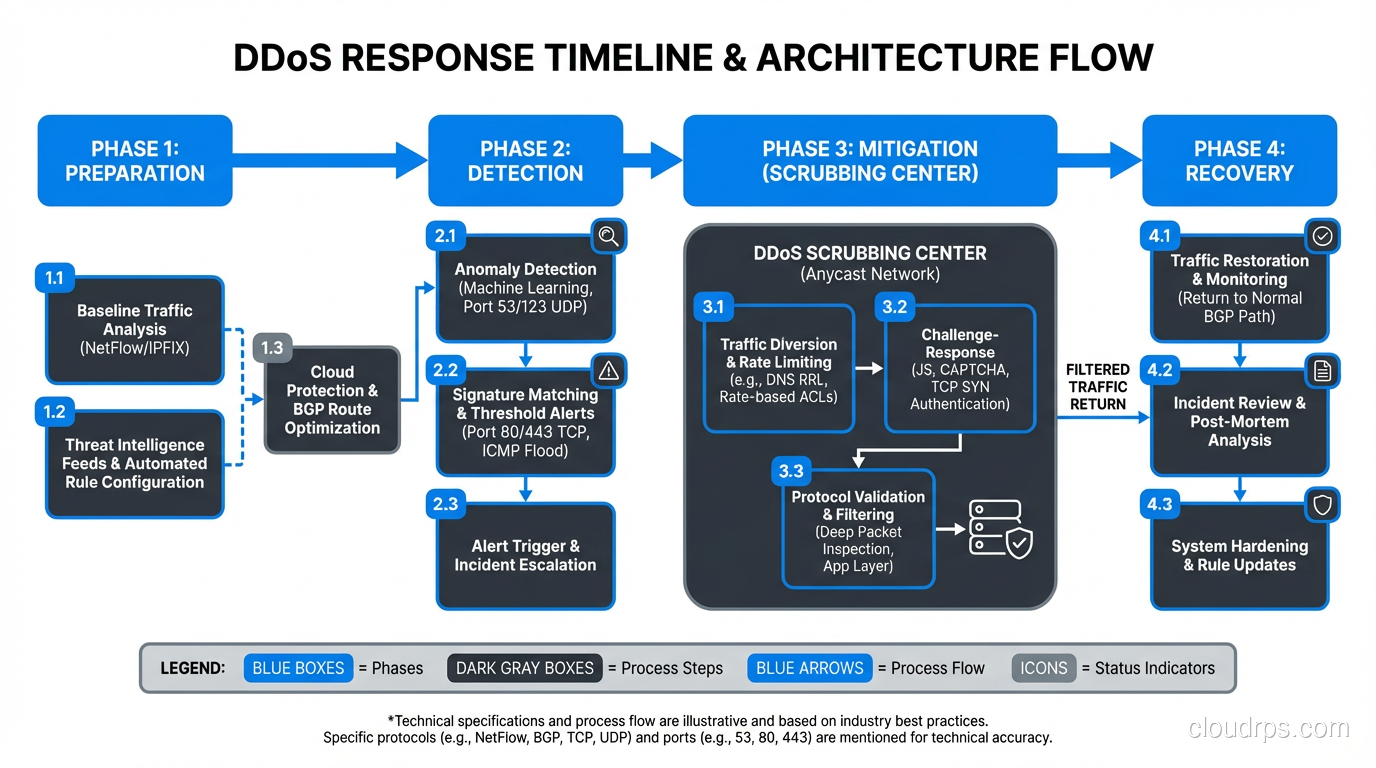
Building a DDoS Response Plan
Technical defenses are necessary but not sufficient. You need a response plan that your team can execute under pressure at 3 AM.
Pre-Attack Preparation
Know your baseline. You can’t identify abnormal traffic if you don’t know what normal looks like. Establish baseline metrics for bandwidth utilization, request rates, connection counts, and application response times.
Document your architecture. During an attack is not the time to figure out what IP addresses your application uses, who your ISP contacts are, or how to change your BGP routes. Document everything and keep it accessible (not behind the infrastructure that’s being attacked).
Establish vendor relationships. If you’re going to use a scrubbing service on demand, sign the contract and test the onboarding before you’re under attack. I’ve watched organizations try to sign up for DDoS mitigation while under attack. It doesn’t go well.
Run tabletop exercises. Walk through attack scenarios with your team. Who makes the call to engage the scrubbing service? Who communicates with customers? Who handles the press inquiry? Practice these decisions when the pressure is off.
During the Attack
Classify the attack. Is it volumetric, protocol-level, or application layer? This determines your response. Volumetric attacks need upstream mitigation. Application layer attacks need WAF and application-level defenses.
Engage your mitigation providers. If you have a scrubbing service, activate it. If you need your ISP to blackhole traffic, call them. If you need to enable always-on CDN proxying, do it.
Communicate proactively. Customers, stakeholders, and leadership need to know what’s happening. A status page that says “we’re aware of the issue and actively mitigating” is infinitely better than silence.
Preserve logs. Attack traffic logs are essential for post-incident analysis and potentially for law enforcement. Make sure your logging infrastructure can handle the volume.
Post-Attack
Conduct a thorough post-mortem. What was the attack vector? How long until detection? How long until mitigation was effective? What worked? What didn’t?
Update your defenses. Every attack teaches you something about your weak points. Implement improvements while the lessons are fresh.
Consider attribution and law enforcement. For significant attacks, involve law enforcement. DDoS-for-hire operators have been successfully prosecuted, and the intelligence you provide helps disrupt these services for everyone.
The Economics of DDoS
Understanding the economics helps explain why DDoS is so prevalent:
Attack cost: DDoS-for-hire services (called “booters” or “stressers”) charge as little as $20 for a short attack. Sophisticated botnets can be rented for hundreds of dollars per hour. The barrier to entry is negligibly low.
Defense cost: Enterprise DDoS mitigation services range from $3,000 to $100,000+ per month. The asymmetry is staggering.
Motivation: DDoS attacks are used for extortion (pay us or we’ll keep attacking), competitive sabotage (take down a rival during a sales event), hacktivism (political statements), and distraction (DDoS the SOC while exfiltrating data through a different vector).
The economic asymmetry means DDoS will remain a threat indefinitely. The cost to attack will always be dramatically lower than the cost to defend. This is why defense-in-depth with proper planning beats trying to buy your way to safety.
Architectural Patterns for DDoS Resilience
Beyond reactive defenses, certain architectural choices make your infrastructure inherently more resistant to DDoS:
Geographic distribution. Run your application in multiple regions. An attack targeting one region doesn’t affect the others if you can shift traffic.
Microservices with independent scaling. If your search function is being targeted, scale that service independently rather than scaling your entire application.
Separate your DNS from your application infrastructure. Use a DNS provider with Anycast and DDoS protection (Cloudflare, Route 53, NS1). If your DNS is served from the same infrastructure as your application, a single attack takes down both.
Hide your origin. Put your application behind a CDN or proxy. If attackers don’t know your origin server’s IP address, they can’t bypass your CDN and attack directly. Scrub your DNS history, use different IPs for origin and public services, and never expose origin IPs in email headers or API responses.
Design for degradation. Your application should degrade gracefully under load. Serve cached content, disable expensive features, queue non-critical operations. A degraded application is better than a dead one.
What I’ve Learned Fighting DDoS for Twenty Years
DDoS defense is not a technology problem. It’s an operational readiness problem. The organizations that survive attacks aren’t necessarily the ones with the most expensive mitigation services. They’re the ones with the best preparation, the clearest runbooks, and the most practiced response teams.
Every DDoS incident I’ve worked has reinforced the same lesson: the time to prepare is before the attack. By the time traffic is flooding your network, your options are limited to whatever you’ve already put in place. Build the defenses, test the defenses, and practice the response. Then when Saturday morning comes and the phone rings at 6:47 AM, you’ll be ready.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.