I’ve killed production databases by not having a cache. I’ve also caused production incidents by having a cache that was too aggressive. Distributed caching is one of those areas where the concept sounds simple but the operational reality has sharp edges everywhere.
Let me walk you through how this actually works: the architecture, the tradeoffs, the patterns that hold up under load, and the choices you’ll face picking between Redis, Memcached, and the increasingly relevant Valkey.
What Distributed Caching Actually Solves
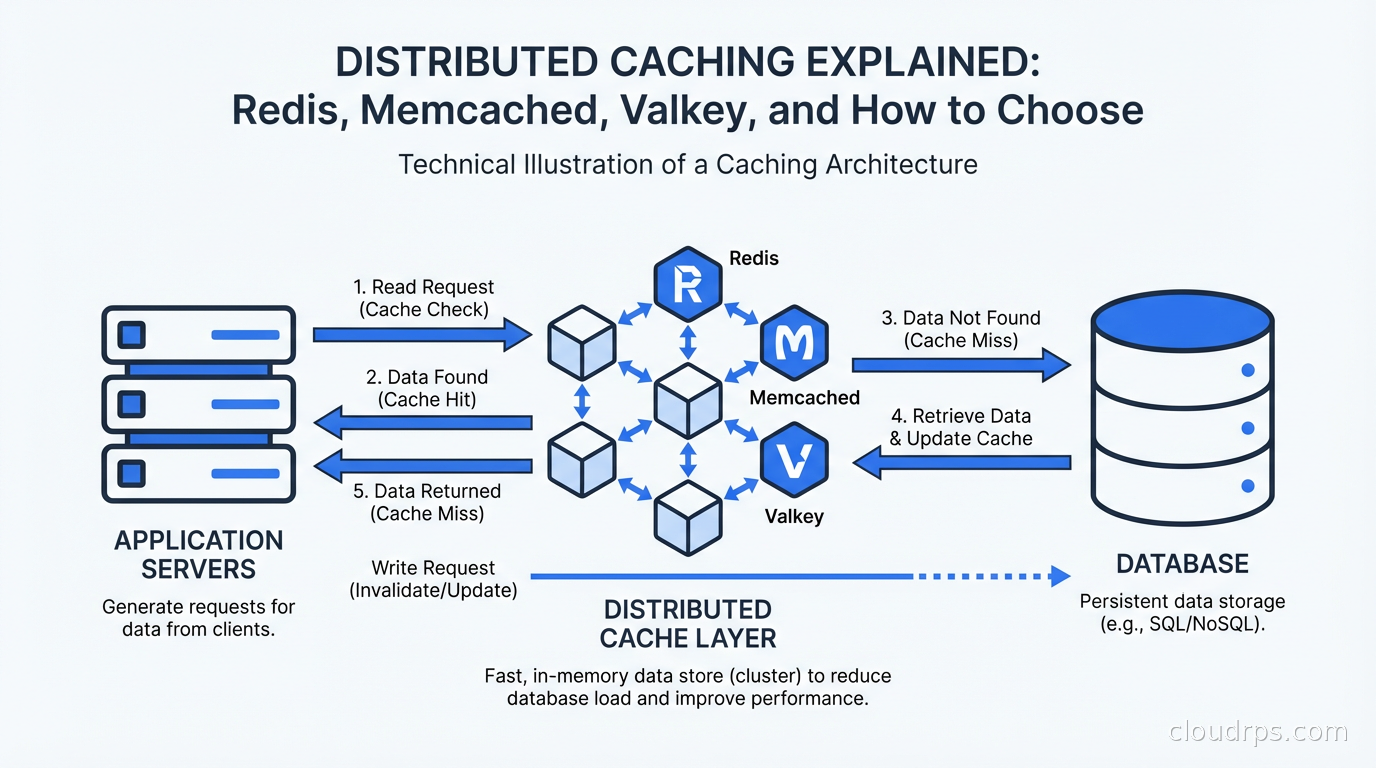
Before anything else, let’s be honest about what caching is for. A cache is a fast, temporary store that sits between your application and your slower data source. The goal is reducing latency and offloading read pressure from your database.
The math is simple. If your Postgres query takes 50ms, and you serve 10,000 requests per second, that’s 500,000 queries per second hitting your database. Most of those queries are for the same data. A cache with even a 90% hit rate drops that to 50,000 queries per second, which is a 10x reduction in database load. A 99% hit rate makes it 100x.
That’s the happy path. The problems come from the “temporary” part. Caches hold copies of data, and copies get stale. Your entire application’s consistency model depends on how you handle that staleness. This is why “cache invalidation” is famously listed as one of the two hard problems in computer science (the other being naming things and off-by-one errors).
Distributed caching adds another layer of complexity: you’re now managing shared state across a network. The cache isn’t a local variable; it’s a remote service with its own failure modes, eviction policies, and consistency semantics.
How a Cache Works: The Core Concepts
Every cache operates on a few fundamental principles you need to internalize before making architectural decisions.
Cache hit vs. cache miss. A hit means the requested data is in the cache; you return it without touching the database. A miss means it’s not there; you fetch from the database, store it in the cache, then return it. Your hit rate is the percentage of requests served from cache. For most web applications, you want this above 90%. Below 80% and you’re paying the cost of a caching layer without getting the benefit.
Eviction policies. Caches have finite memory. When they’re full, they need to discard something to make room. The policies:
- LRU (Least Recently Used): Evict the entry that hasn’t been accessed in the longest time. Good default for most workloads.
- LFU (Least Frequently Used): Evict the entry accessed least often. Better for workloads where access frequency matters more than recency.
- TTL (Time To Live): Every entry has an expiration timestamp. After that time, the entry is gone. Often combined with LRU.
- FIFO: Evict the oldest entry. Simple but rarely optimal.
TTL vs. explicit invalidation. Two strategies for keeping cache data fresh. TTL-based expiration is easy: set every entry to expire after N seconds, and stale data eventually clears itself. The downside is that stale data can linger until expiration. Explicit invalidation means you delete cache entries when the underlying data changes. More precise, but requires coordination between your application code and cache, and you can have bugs where you forget to invalidate something.
Most real systems use both: TTL as a safety net, explicit invalidation for known data changes.
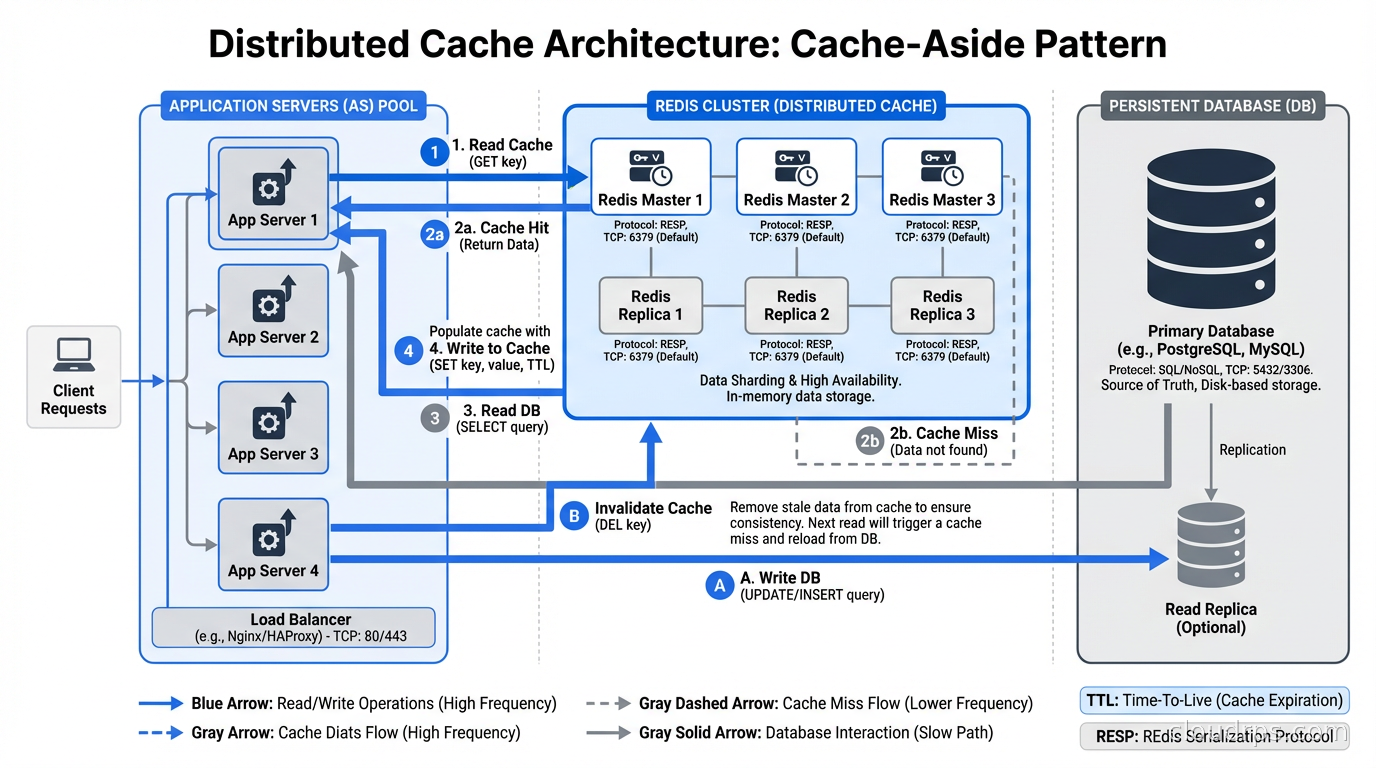
The Four Core Caching Patterns
The pattern you choose affects everything: consistency, complexity, write performance, and failure behavior.
Cache-Aside (Lazy Loading). The application checks the cache first. On a miss, it fetches from the database, writes to cache, returns to caller. This is the most common pattern and what most engineers mean when they say “caching.” Pros: only cache what’s actually requested; cache failures don’t break reads (you fall through to the database). Cons: first request always misses; under load, a cache miss storm can hammer the database (the thundering herd problem).
Write-Through. Every write goes to both cache and database synchronously. Reads always hit the cache. Pros: cache is always fresh. Cons: write latency increases because you write twice; you cache data that may never be read.
Write-Behind (Write-Back). Writes go to cache immediately, then asynchronously to the database. Pros: low write latency. Cons: you can lose data if the cache crashes before the async write completes. Appropriate for workloads where some data loss is acceptable (like session counters).
Read-Through. The cache itself is responsible for loading from the database on misses. The application only talks to the cache. This abstracts the loading logic into the cache layer. Requires your cache client to support it, which some do.
In practice, cache-aside is what 80% of teams use. It’s the most predictable, the most debuggable, and the easiest to reason about when something goes wrong at 2am.
Redis: The Swiss Army Knife
Redis started as a “Remote Dictionary Server” and has evolved into something much more powerful. It’s in-memory storage with persistence options, a rich set of data structures, Lua scripting, pub/sub messaging, and now streams.
The data structures are what make Redis genuinely different from a simple key-value store:
- Strings: The basics. Store anything up to 512MB as a value.
- Hashes: Store multiple fields under one key. A user object with name, email, last_login stored as a hash rather than serialized JSON.
- Lists: Ordered sequences. Push/pop from both ends in O(1). Good for queues, recent activity feeds.
- Sets: Unordered collections with uniqueness guarantees. Membership checks in O(1). Good for tracking users who’ve seen something.
- Sorted Sets: Sets where each member has a score. Range queries by score. The classic use case is leaderboards.
- Streams: Append-only log structures. Kafka-lite for simpler use cases.
I’ve used sorted sets for a rate limiter that tracks request counts with timestamps as scores. I’ve used pub/sub for cache invalidation signals across multiple application instances. These aren’t features you can fake with Memcached.
Redis persistence. By default Redis is in-memory only, which means a restart loses all data. You have two persistence options:
- RDB (Redis Database): Point-in-time snapshots. Fast restarts, but you can lose writes since the last snapshot.
- AOF (Append Only File): Log every write command. Slower restarts but near-zero data loss.
For a pure cache, you often disable persistence entirely. If Redis is your primary data store for sessions or other important state, use AOF with fsync always for durability, accepting the write latency cost.
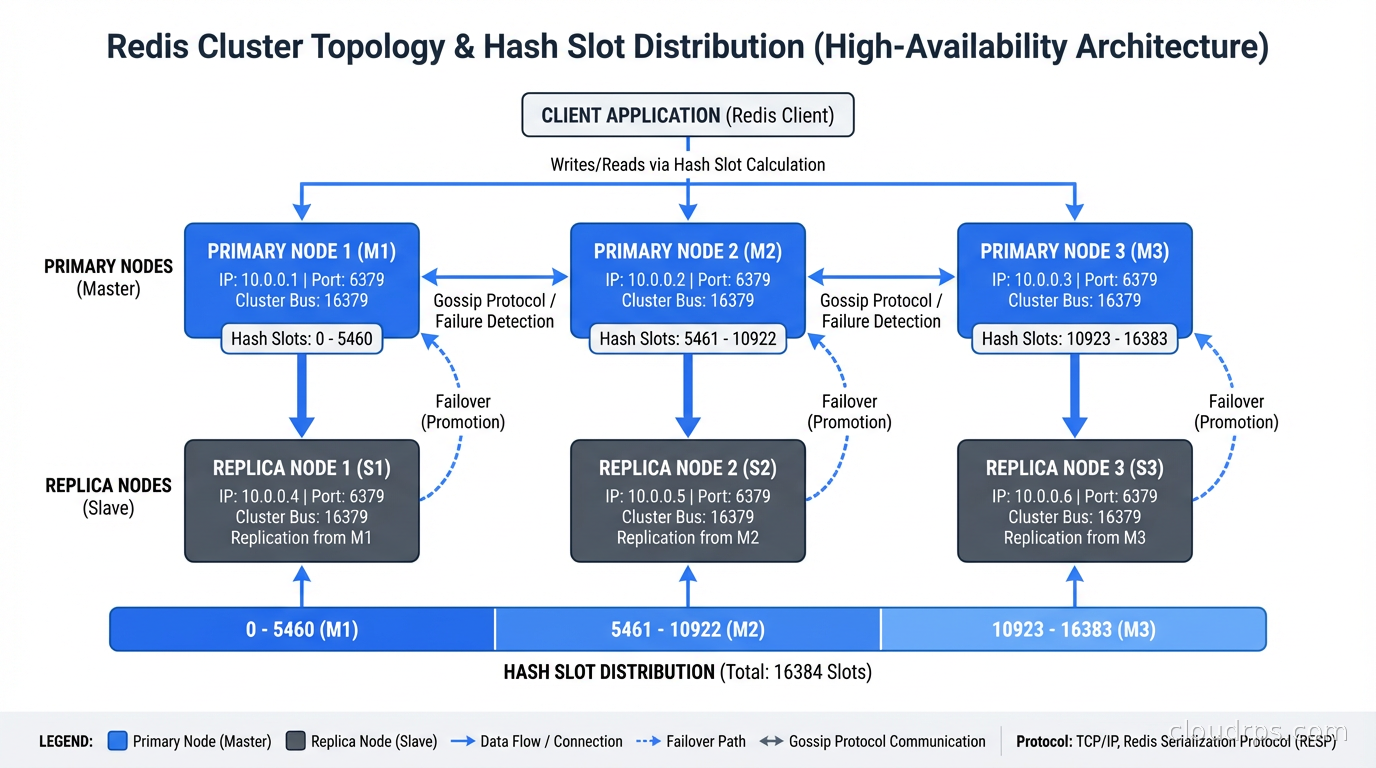
Redis Cluster. For horizontal scaling, Redis Cluster shards data across multiple nodes using consistent hashing. Data is split into 16,384 hash slots, distributed across your nodes. The cluster handles rebalancing when you add or remove nodes. Practical limit is around a few hundred GB before cluster overhead becomes a concern. For most teams, a well-tuned Redis Sentinel setup (primary plus replicas with automatic failover) is simpler to operate than a full cluster.
Memcached: The Honest Option
Memcached has been around since 2003 and does exactly one thing: key-value caching of arbitrary byte strings. No persistence. No data structures beyond strings. No pub/sub. Just fast, simple, distributed caching with a protocol that hasn’t changed much in twenty years.
The simplicity is a feature. Memcached uses a slab allocator for memory management, which avoids memory fragmentation and makes memory usage extremely predictable. Under heavy write workloads, Memcached can outperform Redis because it has less overhead: no persistence logging, no complex data structure management, just “here’s a key, here’s a value, here’s a TTL.”
Memcached scales horizontally through client-side sharding. There’s no cluster mode; your client library handles distributing keys across multiple Memcached instances. This is simpler to operate but means the client is responsible for consistent key distribution when you add or remove nodes.
I’d choose Memcached when: the workload is pure caching with no need for data structures, the team values operational simplicity, or you’re already running it and Redis’s features don’t justify migration. If you’re starting fresh today, most teams default to Redis because the ecosystem is richer and the operational overhead difference is smaller than it used to be.
Valkey: The Fork That Matters
In March 2024, Redis Ltd changed the license for Redis from the BSD open-source license to a dual license: Server Side Public License (SSPL) and the Redis Source Available License (RSALv2). Both licenses restrict cloud providers from offering Redis as a managed service without a commercial agreement.
This was aimed squarely at AWS, Google, and Azure, who had been offering managed Redis services without paying Redis Ltd. The response from those cloud providers and the broader open-source community was to fork Redis 7.2.4 under the BSD license and create Valkey, now a Linux Foundation project.
AWS ElastiCache and MemoryDB for Redis have both announced Valkey support. Google Cloud Memorystore supports Valkey. The managed service future is Valkey, not Redis.
For most engineers, the practical differences between Redis 7.x and Valkey are minimal today. The APIs are compatible, the data structures are the same, and most client libraries work with both. Valkey development is accelerating: the project has added performance improvements and features that Redis hasn’t (including some multi-threading improvements for I/O).
The decision framework:
- Existing Redis deployment: Stay on Redis if it’s working, migrate to Valkey when you’re doing a major version upgrade or infrastructure change.
- New deployment on AWS/GCP/Azure: Use the managed Valkey service. You’ll get security patches and version upgrades without maintaining the infrastructure.
- Self-hosted new deployment: Valkey is the better long-term choice. Redis Enterprise has commercial value; open-source Redis has a more uncertain trajectory.
The one place Redis still clearly wins is Redis Enterprise, the commercial product. If you need active-active geo-distribution, Redis on Flash (using SSDs as an extension of RAM), or enterprise support SLAs, Redis Ltd’s commercial offering has features Valkey doesn’t yet match.
Cache Invalidation: Where Things Go Wrong
I’ve seen production bugs where users could see other users’ data, billing systems that showed wrong amounts, and product pages that showed prices that had been updated but were still serving the old price. All cache invalidation failures.
The approaches, ranked by reliability:
Time-based expiration. Every cache entry has a TTL. Stale data naturally expires. Simple, predictable, and forgiving of application bugs. The tradeoff is accepting that data can be stale for up to TTL seconds. For product catalog data where prices change infrequently, a 60-second TTL is fine. For inventory counts, maybe not.
Event-driven invalidation. When data changes, send an event that triggers cache deletion. Your order service publishes “product:123:updated” and subscribers delete “product:123” from cache. This is precise but adds coupling and complexity. You need to make sure all code paths that update data also send invalidation events. The bugs come from code paths you forgot.
Write-through invalidation. The service that owns the data always updates the cache when it updates the database. One code path, one place to maintain. This works well when data has a clear owner.
Cache versioning. Instead of invalidating, change the cache key when data changes. Append a version number or content hash to every cache key. Old entries expire naturally via TTL. No invalidation logic needed. The downside is you accumulate stale entries in the cache until they expire, which wastes memory.
The worst pattern I’ve seen: invalidation via database triggers. Someone adds a trigger that fires when a row is updated, and the trigger calls a stored procedure that… somehow needs to reach out to a cache. This creates tight coupling between your database and your cache infrastructure, and it behaves terrifyingly when the cache is unreachable.
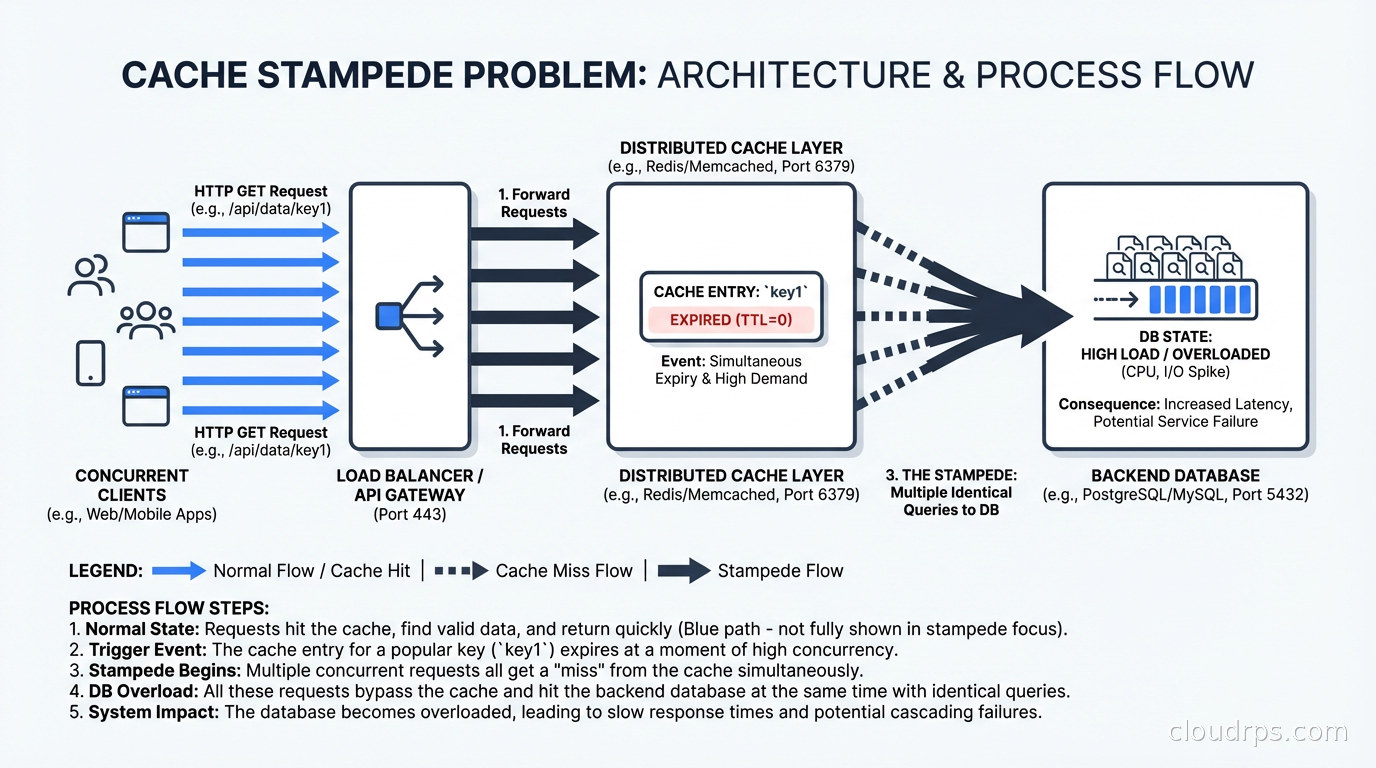
The Cache Stampede Problem
A cache stampede (also called thundering herd) happens when a popular cached item expires and many concurrent requests simultaneously find a cache miss. All of them query the database at once, which can overwhelm it.
Imagine a product page that serves 5,000 requests per second. The cache entry expires. For the next 50ms while the first request is fetching from the database, every other request also misses the cache and also queries the database. You’ve just sent 250 requests to a database that normally handles 500 requests per second total.
Solutions:
Mutex/locking. When a thread encounters a cache miss, it acquires a lock, fetches the data, writes to cache, releases the lock. Other threads wait on the lock instead of hammering the database. Redis has SET NX PX (set if not exists with expiry) for implementing this. The risk is lock contention under high concurrency.
Probabilistic early expiration. Before an entry fully expires, some percentage of requests preemptively refresh it. The algorithm by Vattani et al. gives each request a small probability of treating a non-expired entry as expired. Elegant but less commonly used in practice.
Background refresh. A background job refreshes popular cache entries before they expire. This requires knowing which entries are popular, which you can track with access counters.
Stale-while-revalidate. Return the stale cached value immediately while asynchronously refreshing it in the background. The caller gets a fast (possibly stale) response; the cache refreshes in the background. Most HTTP caching systems support this via Cache-Control: stale-while-revalidate. You can implement the same pattern in application-level caches.
For most teams, mutex locking is the pragmatic answer. It’s well understood, easy to implement with Redis, and handles the stampede at the cost of some lock contention.
Sizing and Memory Management
How much memory do you need? The honest answer is: measure before you guess.
A practical approach: run your application for a week, collect access logs, and analyze which database queries are most frequent and what their result sizes are. The top 20% of queries often account for 80% of your database load. Cache those, measure your hit rate, and adjust.
Memory sizing rules of thumb:
- Start with 20% of your dataset size for a cache that handles typical access patterns
- Monitor your hit rate and eviction rate, not just memory usage
- If your eviction rate is high, you need more memory or a better key design
- If your hit rate plateaus below 90%, you may have a cache invalidation problem, not a memory problem
Redis memory overhead is significant. A string value of 100 bytes doesn’t cost 100 bytes; with Redis’s internal metadata, string keys, and memory allocator overhead, it can cost 150-300 bytes. For workloads with many small values, Hashes with multiple fields share per-key overhead and are significantly more memory efficient than individual string keys.
Monitor these metrics in production: used_memory, used_memory_rss, evicted_keys, keyspace_hits, keyspace_misses. The ratio of keyspace_hits to total requests is your hit rate. evicted_keys increasing rapidly means you’re memory-constrained.
When Not to Cache
Caching has costs: complexity, operational overhead, eventual consistency, cache invalidation bugs. There are workloads where it’s genuinely not worth it.
Don’t cache if: your data is unique per user and doesn’t repeat (personalized feeds that are fully dynamic), your data changes every request (real-time stock quotes, sensor data), your read volume is low enough that the database handles it fine, or the data consistency requirements make even seconds of staleness unacceptable.
The high availability design principles that apply to your database also apply to your cache. If your cache becomes a single point of failure, you’ve introduced a new reliability risk. Always design for cache failure: your application should degrade gracefully (slower, but functional) when the cache is unavailable, not return errors or serve wrong data. The fault tolerance patterns for distributed systems directly apply here.
Also think carefully before caching security-sensitive data. Permissions, authentication tokens, access control lists: caching these can create windows where revoked access is still honored. If you cache authentication and authorization decisions, make sure your TTLs are short and your invalidation on permission changes is explicit. Related: the zero trust security model explicitly warns against implicit trust based on cached state.
Connecting to the Broader Architecture
Caching is one layer in a broader data access strategy. Understand where it fits:
For your relational database, caching query results reduces load, but also look at database indexing and normalization before assuming you need a cache layer. Slow queries with proper indexes often outperform uncached unindexed queries.
For microservices, caching is a cross-cutting concern. The service mesh architecture can help with service-level caching policies, but application-level caches still require careful coordination to avoid serving different users stale data from different caches.
For scalability, a cache extends how far you can scale read-heavy workloads before hitting database limits. Horizontal scaling of your application tier is much more effective when your database load is mostly cache hits.
The performance tuning discipline starts with profiling: measure your database query times, identify the slowest queries with the highest frequency, and cache those first. Don’t pre-optimize by caching everything.
Practical Recommendations
Start with Redis unless you have a specific reason not to. The data structures are useful, the ecosystem is mature, and managed services (ElastiCache for Redis, Upstash, Momento) make it easy to get started without operating infrastructure.
For new deployments on major cloud providers, use the managed Valkey service. The operational overhead savings are real, and Valkey’s trajectory is healthier than open-source Redis given the license situation.
Use cache-aside as your default pattern. Add write-through or explicit invalidation for data where staleness is a real problem (prices, inventory, permissions).
Set TTLs on everything. Never cache without expiration. It prevents endless accumulation of stale data and limits the blast radius of invalidation bugs.
Treat your cache as a performance optimization, not a source of truth. Design your application to function without it. Test cache failure in your staging environment. The chaos engineering practice of injecting cache failures is underused and highly valuable.
Instrument everything. You need hit rate, miss rate, eviction rate, and memory usage as time-series metrics. These numbers tell you when your cache is undersized, when you have an invalidation bug, and when a traffic pattern has changed.
Distributed caching done right is one of the highest-leverage optimizations in your stack. Done carelessly, it’s a source of consistency bugs and outages. The architecture is not complicated; the operational discipline is what separates systems that scale gracefully from ones that fall over when traffic spikes.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.