The year was 2019, and the startup I was advising had a problem. Their PostgreSQL primary was hitting 80% CPU during peak hours, their read replicas were lagging by 30 seconds, and they had just signed a contract with a European customer that required data residency in the EU. Their existing architecture forced a choice between running two completely separate stacks or violating their new contract.
We considered adding more read replicas. We considered manual sharding. We even considered moving to DynamoDB. Then someone mentioned CockroachDB, and after three months of evaluation, we made the switch. It saved the company. It also taught me more about distributed systems than five years of reading papers had.
That experience is why I care deeply about this topic. Distributed SQL databases solve real problems that conventional approaches cannot, but they come with trade-offs that most blog posts gloss over.
What Distributed SQL Actually Means
The term “NewSQL” got coined around 2011 and promptly became a marketing term that meant everything and nothing. Let me be more precise.
Traditional SQL databases (PostgreSQL, MySQL, Oracle) run on a single node or in a primary/replica configuration. Manual sharding can distribute writes across multiple nodes, but it breaks referential integrity, makes cross-shard transactions painful, and requires your application to know where data lives. You end up with the database’s most important invariants punted into your application layer, which is where things go wrong at 3am.
Distributed SQL takes a fundamentally different approach. The database handles partitioning and replication internally, presents a single SQL interface to clients, and guarantees ACID properties across the entire cluster, including cross-node transactions. Your application writes SQL. The database figures out which nodes to talk to.
The key word is “guarantees.” Many systems claim distributed ACID compliance, then bury in the documentation that cross-region transactions have a 5-second timeout, or that linearizability only applies within a single datacenter. Real distributed SQL means the database is consistent everywhere, all the time, even when nodes fail.
This is much harder than it sounds. It requires distributed consensus, and the dominant algorithm powering these databases is Raft.
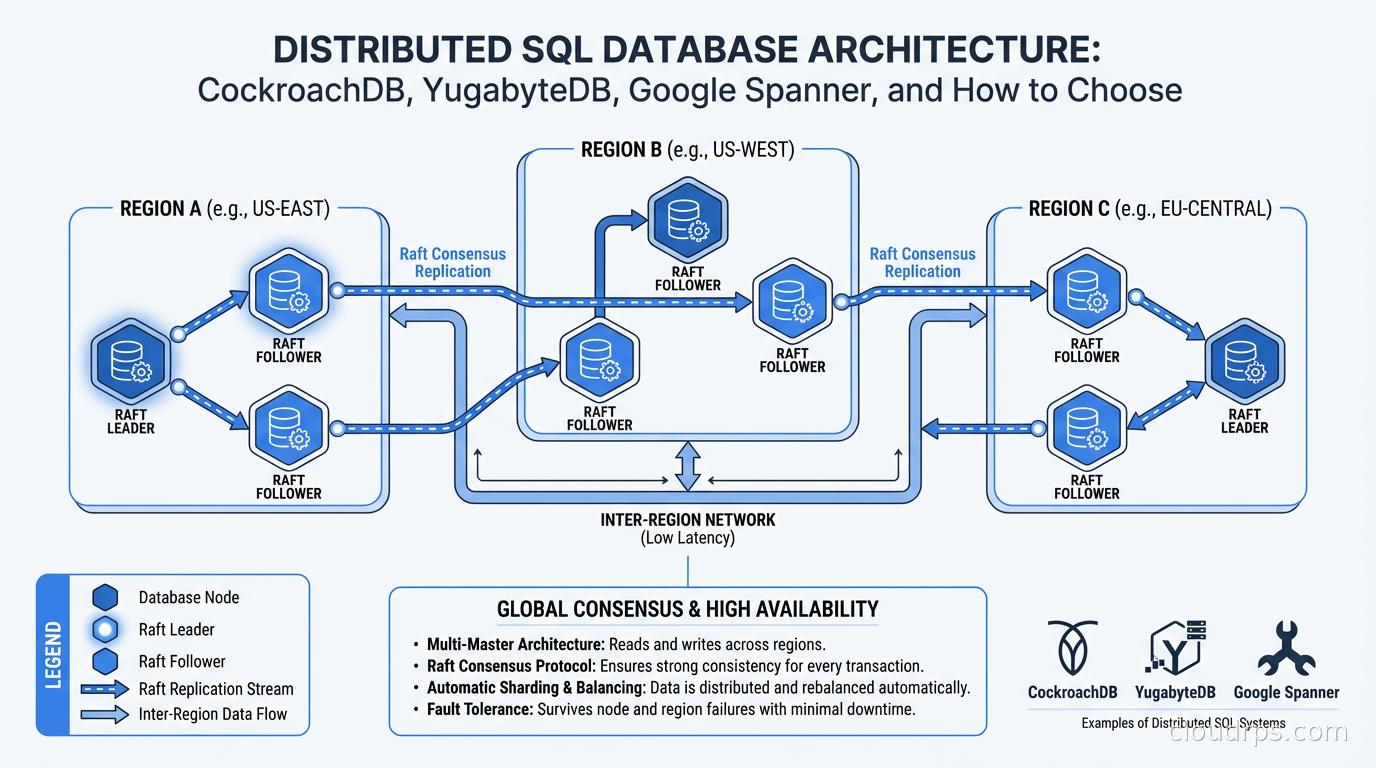
Raft Consensus: Why Your Database Has to Vote
Before comparing products, you need to understand the underlying mechanism. Every write in a distributed SQL database goes through a consensus protocol. The nodes vote on whether a write committed. A write only succeeds when a quorum (usually a majority) of nodes acknowledges it.
With three nodes across three availability zones, you can lose one node and keep operating. With five nodes across five zones, you can lose two. This is the foundation of fault tolerance in distributed SQL systems, and it is why these databases can survive infrastructure failures that would take down a traditional primary/replica cluster.
The trade-off is latency. Every write requires at least one round-trip between the leader and a quorum of followers before it can acknowledge success to the client. If your replicas are in the same datacenter, that round-trip is measured in microseconds. If they are across regions, you are looking at 50-150ms per write, minimum.
This is not a bug. It is the price of global consistency. Anyone claiming sub-millisecond cross-region strongly consistent writes is either redefining “strongly consistent” or selling you something.
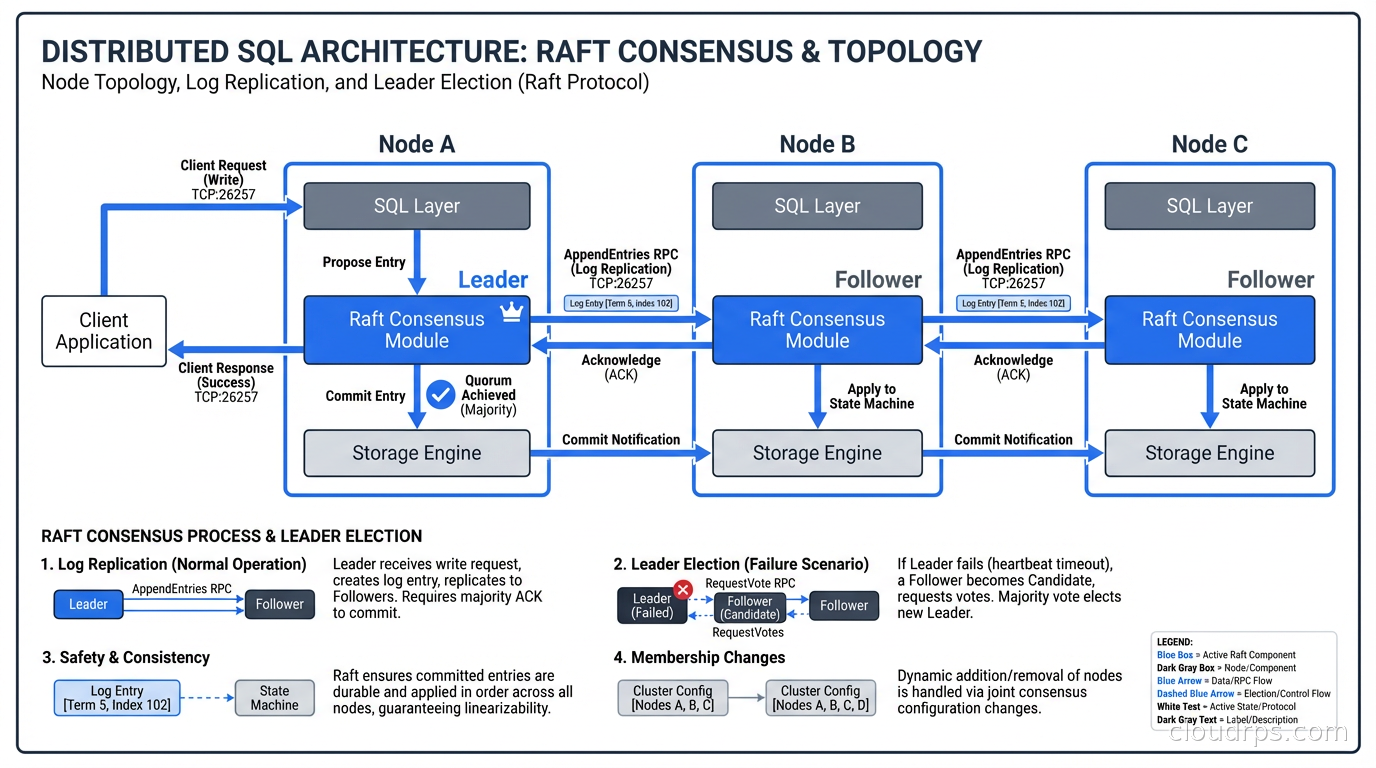
CockroachDB, YugabyteDB, and TiDB all use Raft or variants of it. Google Spanner uses a proprietary variant backed by atomic clocks called TrueTime, which gives it a unique consistency guarantee I will discuss shortly.
The Four Serious Contenders
There are four distributed SQL databases worth evaluating in 2026. Each has a different heritage, different operational model, and a different sweet spot.
CockroachDB
CockroachDB came out of a team of ex-Google engineers who worked on Spanner and wanted an open-source version. It stores data in a key-value store (originally RocksDB, now their own Pebble engine), runs a distributed SQL layer on top, and replicates everything via Raft.
The PostgreSQL wire protocol compatibility is real but imperfect. Basic queries, indexes, transactions, and most of the SQL standard work correctly. Advanced PostgreSQL features including certain stored procedure syntaxes, some window function edge cases, and specific pg_catalog queries occasionally require workarounds. In practice, migrating a standard OLTP application takes weeks, not months. Migrating a complex application that uses pg-specific features takes longer.
The 2022 license change from Apache 2.0 to BSL (Business Source License) upset a segment of the open-source community. The restriction prevents competing cloud services from selling CockroachDB as a managed product without a commercial agreement. For most enterprises building internal systems, this license difference is irrelevant. For companies building a managed database product on top of CockroachDB, it matters enormously.
CockroachDB’s most compelling feature is automatic geo-partitioning. You can pin rows to specific regions based on column values using SQL. A user registered in Germany gets their account data stored in EU nodes. A user in California gets their data stored in US nodes. The database enforces this transparently, and you define the policy in a single ALTER TABLE statement. When my startup client needed EU data residency, this was the feature that made the decision straightforward.
YugabyteDB
YugabyteDB comes from ex-Facebook engineers, and the architecture reflects that heritage. The design is more modular, with a clear separation between the query processing layer (YSQL, which reuses PostgreSQL’s actual query engine code from upstream) and the storage/replication layer (DocDB, their distributed storage engine built on RocksDB).
The PostgreSQL compatibility story is stronger than CockroachDB’s in several areas precisely because YSQL literally runs the PostgreSQL query executor. Many queries that do not work on CockroachDB work on YugabyteDB without modification. Extensions are better supported. The pg_catalog tables behave more like standard PostgreSQL expects. Teams with significant PostgreSQL operational muscle memory will find the transition less jarring.
YugabyteDB is fully open-source under Apache 2.0. The company sells cloud hosting and enterprise features, but the core database has no license restrictions. For teams that consider vendor lock-in a hard constraint, this matters. Apache 2.0 means you can fork it, modify it, and run it forever without worrying about licensing terms changing under you.
The YCQL API offers a Cassandra-compatible interface for teams migrating from Cassandra. Whether you need that depends entirely on your legacy stack.
Google Cloud Spanner
Spanner is the benchmark that everyone else measures against. Google has been running it internally since 2012, and it powers Gmail, Google Photos, Google Play, and Spanner’s own control plane. The operational maturity is simply in a different league from any self-hosted option.
The TrueTime API is what makes Spanner architecturally unique. Google operates atomic clocks and GPS receivers in each of its datacenters. TrueTime gives each transaction a bounded timestamp with a known uncertainty (currently in the range of 4-7ms). This allows Spanner to order transactions globally without distributed coordination in the critical path for many reads, resulting in external consistency that is stronger than what Raft-based systems can provide by default.
The PostgreSQL interface (Spanner’s PG dialect) is available but secondary to the native Spanner API. If you’re building new applications against Spanner, the native API is more expressive and performs better. Migrating existing PostgreSQL applications to Spanner is messier than migrating to CockroachDB or YugabyteDB because the SQL dialect diverges more significantly.
The catch is cost. Spanner charges per processing unit plus storage. A single-region, one-node Spanner instance costs around $65/month before traffic. A globally distributed configuration with nine nodes runs $500-800/month before you serve a single query. Compare that to running CockroachDB or YugabyteDB on commodity VMs where a three-node cluster costs $150-300/month depending on the instance types. For Google-scale workloads where the operational savings justify the cost, Spanner is outstanding. For startups and mid-size companies, the math frequently does not work.
TiDB
TiDB comes from PingCAP and is the most underrated option in Western engineering circles. The architecture cleanly separates compute (TiDB nodes), storage (TiKV nodes), and coordination (PD, the Placement Driver). This separation allows independent scaling of compute and storage, which the other databases do not handle as elegantly. When your query volume spikes but your data size stays flat, you scale TiDB nodes without touching TiKV.
The MySQL compatibility is excellent. If you are running MySQL at scale and hitting the limits of Vitess or manual sharding, TiDB is likely the most practical migration path because your SQL dialect, your tooling, and your team’s muscle memory all carry over.
TiDB also supports HTAP workloads through TiFlash, a columnar storage engine that replicates from TiKV in real time. You can run analytical queries against live OLTP data without a separate ETL pipeline or a separate analytical database. That capability is genuinely interesting for teams that need both.
The geopolitical question about a China-headquartered company will come up in certain industries. I will leave that evaluation to your compliance team, but surface it early rather than after three months of evaluation.
Comparing the Key Dimensions
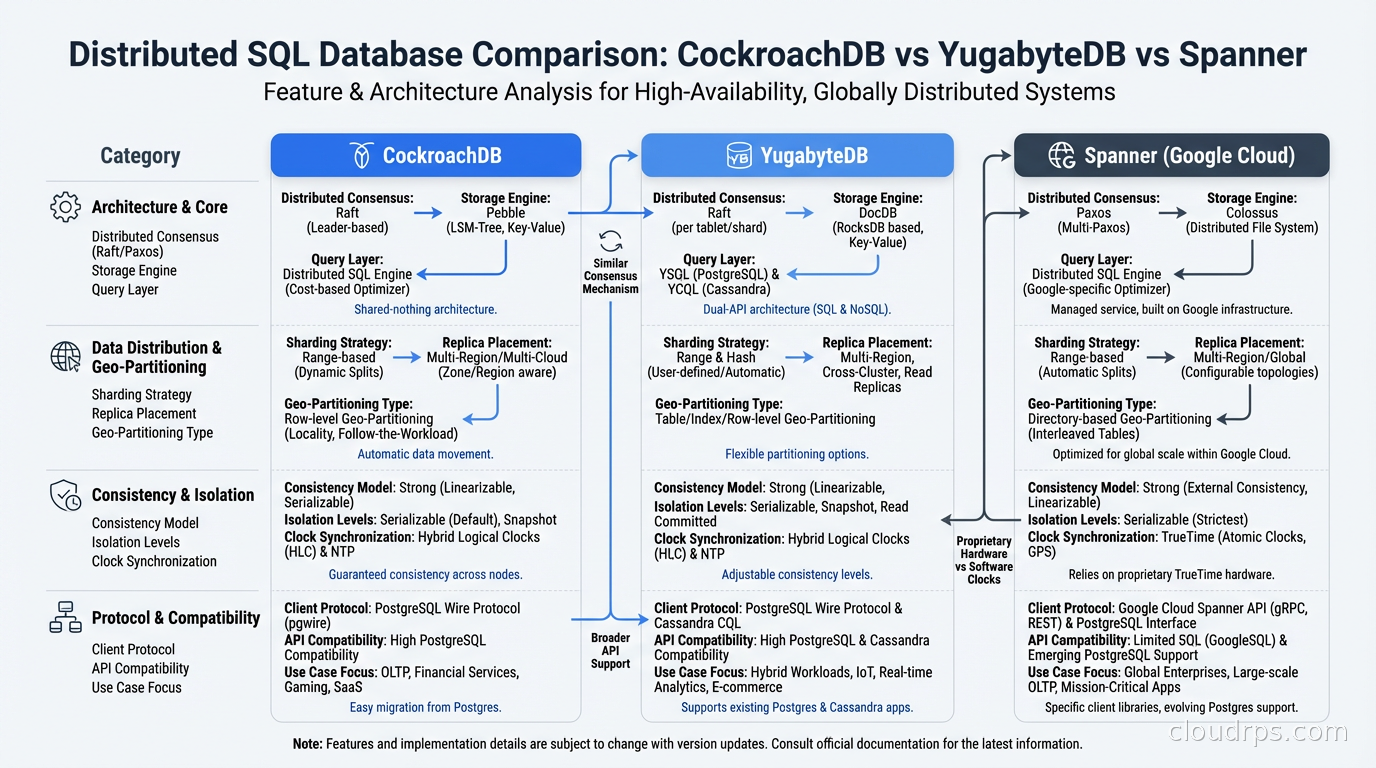
These databases diverge most meaningfully across five dimensions:
PostgreSQL compatibility. YugabyteDB is highest because it reuses the PostgreSQL query engine. CockroachDB is second, with solid compatibility for standard workloads. Spanner’s PG dialect is the thinnest layer of the four. TiDB is MySQL-compatible, not PostgreSQL.
Operational complexity. Spanner has the lowest because it is fully managed. CockroachDB and YugabyteDB are self-managed with mature Kubernetes operators (CockroachDB Operator, YugabyteDB Operator), but you own the operational burden. TiDB has the most components to manage when self-hosted (TiDB, TiKV, PD, TiFlash if you use HTAP).
Cost at scale. Self-hosted TiDB and YugabyteDB have the lowest infrastructure costs if you have the operational bandwidth. CockroachDB self-hosted is comparable. Spanner is the most expensive at small-to-medium scale, potentially cost-effective at genuinely large scale because you eliminate dedicated database operations headcount.
Cross-region write latency. This is where everyone faces the same physics. Multi-region active-active architectures incur cross-region network latency on every synchronous write. CockroachDB’s geo-partitioning minimizes this by keeping writes local when rows are pinned to specific regions. Spanner’s TrueTime allows it to commit certain transactions with reduced cross-region synchronization for reads.
Consistency guarantees. All four guarantee serializable isolation and full ACID compliance. Spanner additionally provides external consistency (a stronger property than serializability that includes real-time ordering) by default, backed by TrueTime. For most applications, this distinction does not change anything. For financial systems where you need provable global transaction ordering across datacenters, it can matter.
The CAP Theorem Reality Check
Every distributed SQL evaluation surfaces the CAP theorem question: which side does this database choose during a network partition?
For distributed SQL databases, the answer is always consistency over availability (CP). When a Raft leader cannot reach a quorum, writes stop. The database does not serve stale data or accept potentially conflicting writes. It waits until the network heals or a new leader is elected.
This is the correct choice for financial transactions, inventory management, order processing, seat reservations, and anything where split-brain would cause real damage. It is the wrong choice for session data, product catalogs, and anything where eventual consistency is acceptable and the priority is staying available during network partitions.
If you are replacing a system that was intentionally designed for eventual consistency (DynamoDB, Cassandra, Riak), think carefully before moving to distributed SQL. You might be trading a feature for a bug. The database replication patterns that work for eventually consistent systems often need to be redesigned from scratch.
When Distributed SQL Is Not the Answer
I have talked two clients out of distributed SQL evaluations in the past 18 months. This probably cost me consulting time, but it saved them months of unnecessary complexity.
The first had a PostgreSQL instance running at 30% CPU with a single read replica. Their real pain point was slow reporting queries running against the same instance as their OLTP workload. The solution was routing reporting queries to a read replica and adding PgBouncer for connection pooling. Total engineering cost: a weekend. The distributed SQL evaluation they had queued up would have taken three months and introduced significant operational complexity for a problem that did not exist.
The second had a genuine sharding problem but needed data in only one region. Vitess (MySQL horizontal sharding) solved their write scaling problem with far less operational complexity than CockroachDB would have introduced. They had strong MySQL operations expertise and zero Raft consensus knowledge. The right tool for their context was not the most sophisticated tool available.
Distributed SQL is the correct choice when you need: globally distributed writes with strong consistency across all nodes, automatic data rebalancing as you scale without application changes, or data residency enforcement by policy rather than application logic. If you do not have at least two of those three requirements, reconsider.
The Migration Reality
Every migration to a distributed SQL database encounters the same three surprises regardless of which product you choose.
The first surprise is transaction size limits. CockroachDB has historically limited transactions to 64MB. YugabyteDB has similar constraints at the RPC layer. Long-running batch jobs that load millions of rows in a single transaction need to be broken into smaller batches before you migrate. This is almost always an improvement architecturally, but it requires engineering time upfront.
The second surprise is cross-node query performance. A query that joins two large tables where the data lives on different nodes requires network round-trips during execution. Query plans that work fine on a single-node PostgreSQL can perform poorly on a distributed SQL database until you understand how to co-locate related data using zone configurations, table localities, or hash partitioning strategies. The query optimizer makes different decisions than you expect, and the EXPLAIN output looks different than what your team knows.
The third surprise is the observability learning curve. Your existing PostgreSQL monitoring dashboards, slow query logs, and pg_stat_statements queries do not translate directly. CockroachDB has its own console with distributed query insights. YugabyteDB has YSQL query insights. You need to learn a new set of metrics and new debugging workflows. Budget two weeks for this alone, minimum.
The migrations that go smoothly are the ones where teams spent eight weeks on a staging environment before moving any production traffic, ran their complete production workload against it, and then moved a low-criticality service first before touching anything customer-facing.
Geo-Distribution in Practice
The geo-distribution capability is what makes these databases transformative rather than just “PostgreSQL but harder to run.”
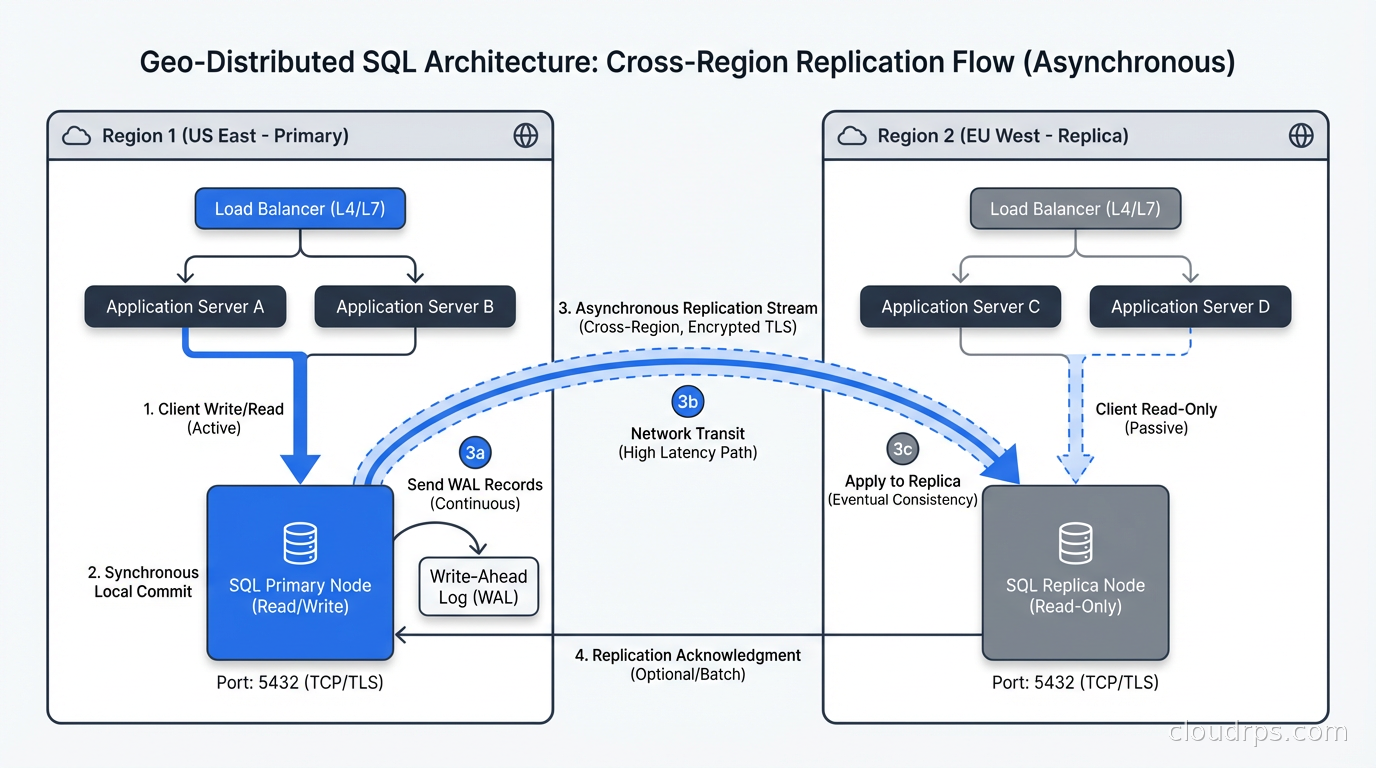
With CockroachDB’s zone configurations, you define where data lives at the table or partition level in SQL. A European user’s account data stays in EU regions. A US user’s data stays in US regions. A global table gets replicas in every region. The database enforces this through partition assignments, and the geo-partitioning is completely transparent to the application layer. Your app connects to any node and runs standard SQL.
This is materially different from the traditional approach of running separate database instances per region and handling synchronization at the application layer. That traditional approach requires your application to know which database to query, maintain cross-region foreign keys manually, handle eventual consistency between regions explicitly, and debug the inevitable case where a row ends up in the wrong region. I have supported that architecture at two different companies. It becomes unmaintainable within 18 months as the codebase grows.
YugabyteDB’s tablespaces offer similar functionality with a slightly different configuration model. Spanner handles geo-distribution through replication configuration at instance creation time plus the database-level placement policies. TiDB’s placement rules are newer but functional for the common case.
The compliance use case drives most of these evaluations in 2026. GDPR data residency requirements, financial sector data localization mandates, and healthcare data sovereignty rules all become significantly simpler to implement when the database can pin data to specific geographic locations by policy rather than application logic. The alternative, building residency enforcement into your application, creates a class of compliance bugs that are extremely difficult to audit and almost impossible to prove correct.
Choosing Between Them
After running distributed SQL in production at multiple clients, here is my actual decision framework:
Choose CockroachDB if you need geo-partitioning with PostgreSQL compatibility, you are comfortable with the BSL license (or you need commercial support anyway), and you want the most mature self-hosted option with the deepest documentation and community resources.
Choose YugabyteDB if PostgreSQL extension compatibility matters (PostGIS, pg_partman, specific pg_catalog behavior), if open-source licensing is a hard requirement, or if you are migrating a complex PostgreSQL application where query-level compatibility is critical to a manageable migration timeline.
Choose Spanner if you are all-in on Google Cloud, you need the strongest available consistency guarantees, and your scale genuinely justifies the cost premium. Spanner’s fully managed operations model saves real engineering time at sufficient scale. I would not choose it for anything under a few hundred gigabytes unless you have a compliance requirement that specifically benefits from TrueTime.
Choose TiDB if you are migrating from MySQL, if you need HTAP capability (OLTP and analytical queries against the same live data without ETL), or if your team has strong TiDB operational expertise.
Choose none of them if your existing PostgreSQL or MySQL instance is not near its capacity ceiling, if you are operating in a single region, or if your read-heavy workload can be addressed with better indexing, caching, and read replicas. Distributed SQL adds real operational complexity. It should earn that complexity by solving a problem you actually have.
The distributed SQL space has matured significantly since I first evaluated it in 2019. The databases are more stable, the tooling is better, the documentation is deeper, and the migration paths are clearer. But mature does not mean simple. These systems reward teams that invest in understanding how Raft consensus works, how zone configurations affect query planning, and how cross-node joins behave under load. They penalize teams that treat them as drop-in PostgreSQL replacements and wonder why performance is inconsistent.
The investment pays off when the problem fits. When you genuinely need globally consistent distributed writes with automatic rebalancing and geo-partitioned data residency, there is no better tool class. The engineers who understand these systems deeply have an architectural capability that is genuinely difficult to replicate with any other approach.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.