I still remember the exact moment I became an eBPF convert. It was 2 AM, I was debugging a networking issue in a 400-node Kubernetes cluster, and iptables had grown to over 25,000 rules. Every new Service we deployed made things measurably slower. The kube-proxy chain was a mess, latency was creeping up, and nobody could explain exactly where packets were being dropped. A colleague suggested we try Cilium. Within a week of migrating, our Service-to-Service latency dropped by 30%, and I could actually see what was happening at the kernel level for the first time. That was the moment I realized eBPF was going to change everything about how we run infrastructure.
If you’re running Kubernetes at any meaningful scale, eBPF is no longer optional knowledge. It’s the technology underpinning the next generation of networking, observability, and security tooling. Let me walk you through what it actually is, how it works, and why it matters for your infrastructure.
What Is eBPF, Really?
eBPF stands for extended Berkeley Packet Filter. The name is a bit misleading at this point because it has evolved far beyond packet filtering. At its core, eBPF is a technology that lets you run sandboxed programs inside the Linux kernel without changing kernel source code or loading kernel modules. Think of it as a safe, programmable extension point for the kernel itself.
The original BPF (Berkeley Packet Filter) was created in 1992 for packet capture. It was the engine behind tcpdump. You could write small filter programs that ran in the kernel to decide which packets to capture, which was dramatically faster than copying everything to userspace and filtering there. In 2014, Alexei Starovoitov and Daniel Borkmann extended BPF into what we now call eBPF, transforming it from a packet filter into a general-purpose kernel virtual machine. The “extended” prefix has mostly been dropped in conversation; when people say “BPF” today, they almost always mean eBPF.
Here’s why this matters: traditionally, if you wanted to add functionality to the Linux kernel (custom networking logic, security enforcement, performance tracing), you had two options. You could modify the kernel source and recompile, which is impractical for production. Or you could write a kernel module, which is risky because a buggy module can crash your entire system. eBPF gives you a third option: write a small program that the kernel verifies for safety before running it. No kernel recompilation. No risk of kernel panics. Just programmable infrastructure at the lowest possible level.
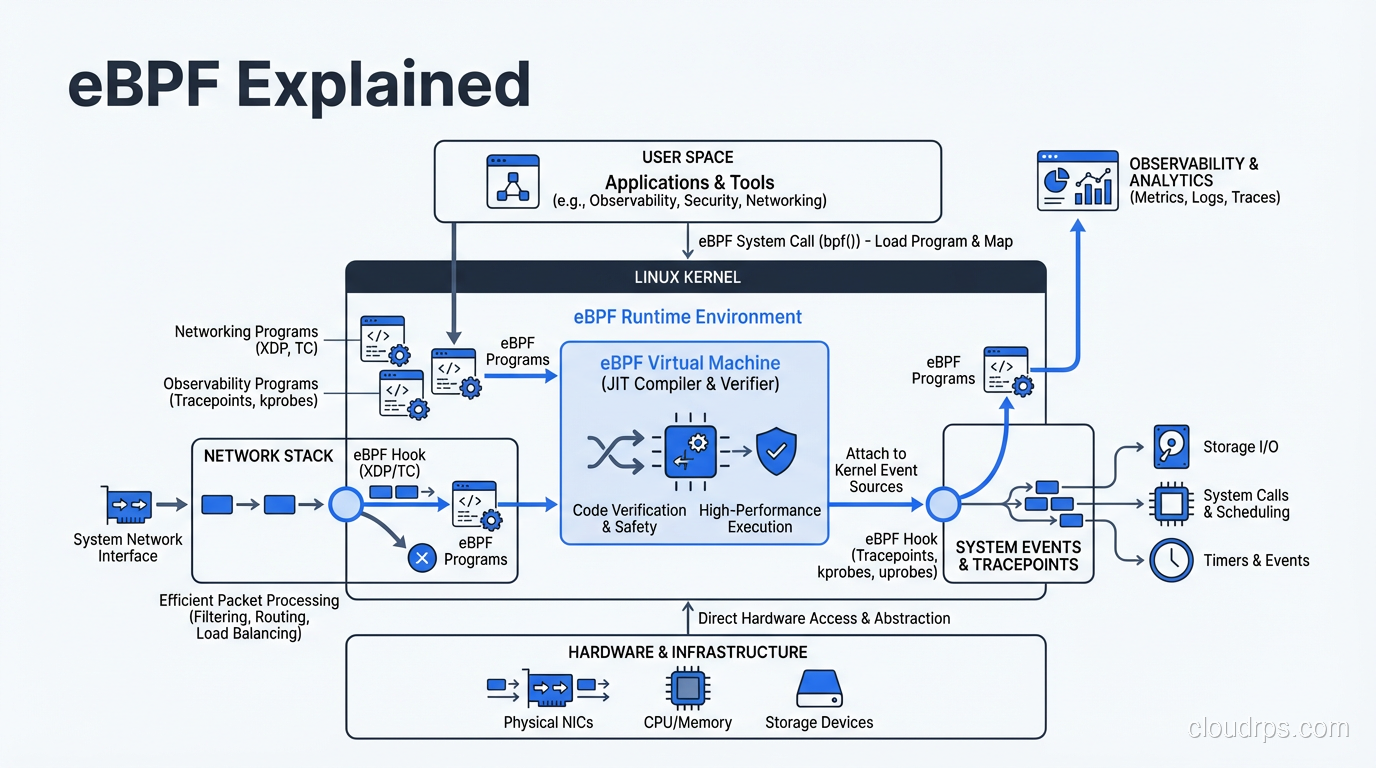
How eBPF Works Under the Hood
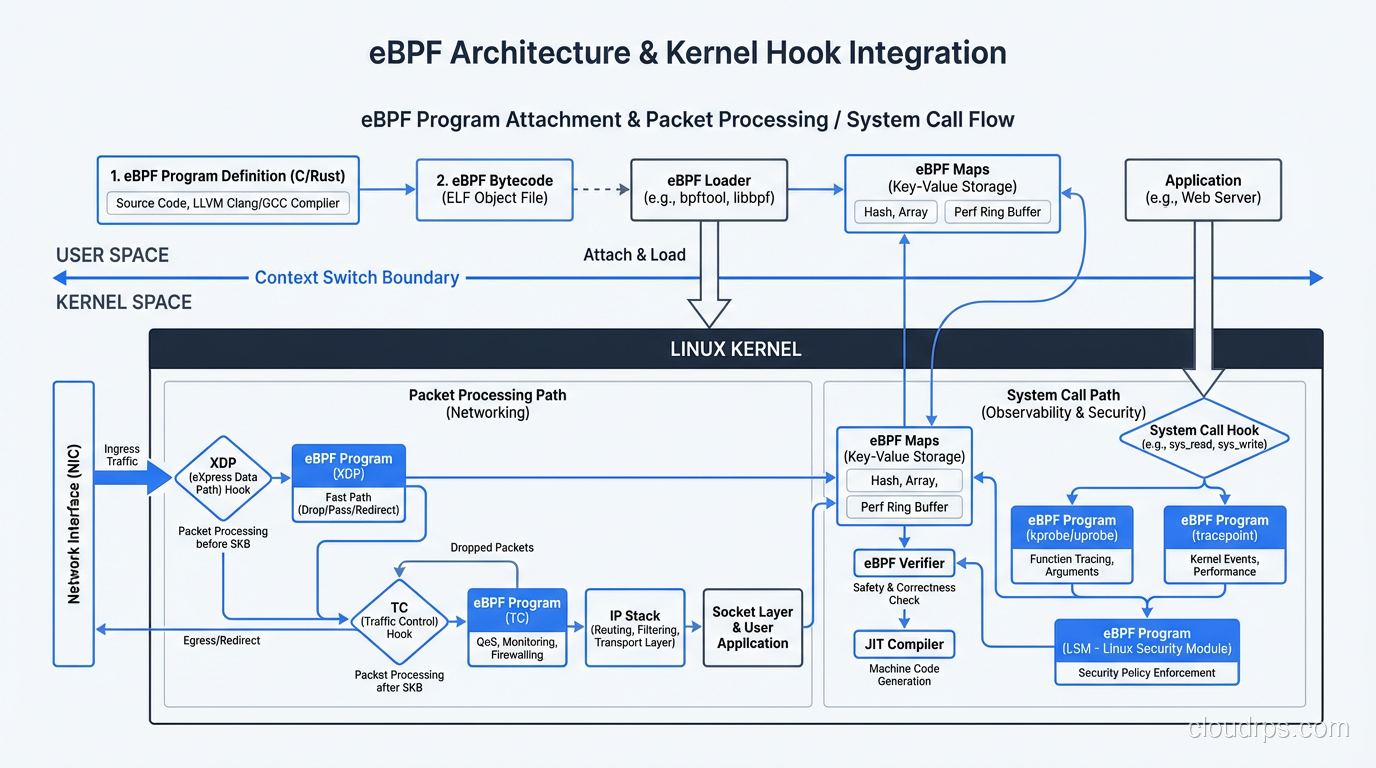
To understand why eBPF is so powerful, you need to understand its execution model. There are four key components: programs, maps, hooks, and the verifier.
eBPF Programs are small pieces of code written in a restricted C dialect (or Rust, increasingly). They compile down to eBPF bytecode, which is a custom instruction set designed to be both expressive and safe. Each program is typically small, often under a few hundred instructions.
Maps are key-value data structures shared between eBPF programs and userspace applications. They’re how you get data in and out of the kernel. A map might store per-CPU packet counters, connection tracking state, or security policy rules. Maps come in various types: hash maps, arrays, ring buffers, LRU caches, and more. The choice of map type matters a lot for performance.
Hooks are the attachment points where eBPF programs run. This is what makes eBPF so versatile. You can attach programs to network interfaces (XDP for raw packet processing), to the TCP/UDP socket layer, to system calls, to kernel functions (kprobes), to userspace functions (uprobes), to tracepoints, and to cgroup operations. Each hook gives you access to different kernel data structures and different levels of control.
The Verifier is arguably the most important piece. Before any eBPF program runs, the kernel’s verifier performs static analysis to guarantee safety. It checks that the program terminates (no infinite loops), that all memory accesses are bounded, that the program doesn’t access arbitrary kernel memory, and that it uses only allowed helper functions. If the verifier rejects your program, it doesn’t run. Period. This is what makes eBPF fundamentally different from kernel modules: the safety guarantee is built into the execution model.
After verification, the eBPF bytecode goes through JIT (Just-In-Time) compilation into native machine code for your architecture (x86_64, ARM64, etc.). This means eBPF programs run at near-native speed, not interpreted. On modern kernels, the JIT compiler produces code that’s essentially as fast as compiled C.
eBPF for Networking: Why Cilium Replaced kube-proxy
This is where eBPF has had the most visible impact in cloud infrastructure. To understand why, you need to understand the problem it solves.
Traditional Kubernetes networking relies on kube-proxy, which uses iptables (or IPVS) to implement Service routing. When a pod sends traffic to a ClusterIP Service, iptables rules handle the DNAT (destination NAT) to route the packet to a healthy backend pod. This works fine at small scale. At large scale, it becomes a nightmare.
Here’s the math that killed us. Every Kubernetes Service creates multiple iptables rules. In a cluster with 5,000 Services (not unusual for a large enterprise), you end up with tens of thousands of iptables rules. iptables is a linear lookup, meaning every packet that hits the chain walks through rules one by one until it finds a match. Service updates trigger a full rewrite of the iptables chain, which is an O(n) operation that briefly locks the entire table. I’ve seen Service endpoint updates take over 5 seconds in clusters with 10,000+ rules. During that window, new connections can fail.
Cilium replaces kube-proxy entirely by implementing Service routing with eBPF programs attached at the socket and tc (traffic control) layers. Instead of a linear chain of iptables rules, Cilium uses eBPF hash maps for O(1) Service lookups. Endpoint updates modify a single map entry, not the entire ruleset. The difference in performance at scale is not subtle; it’s dramatic.
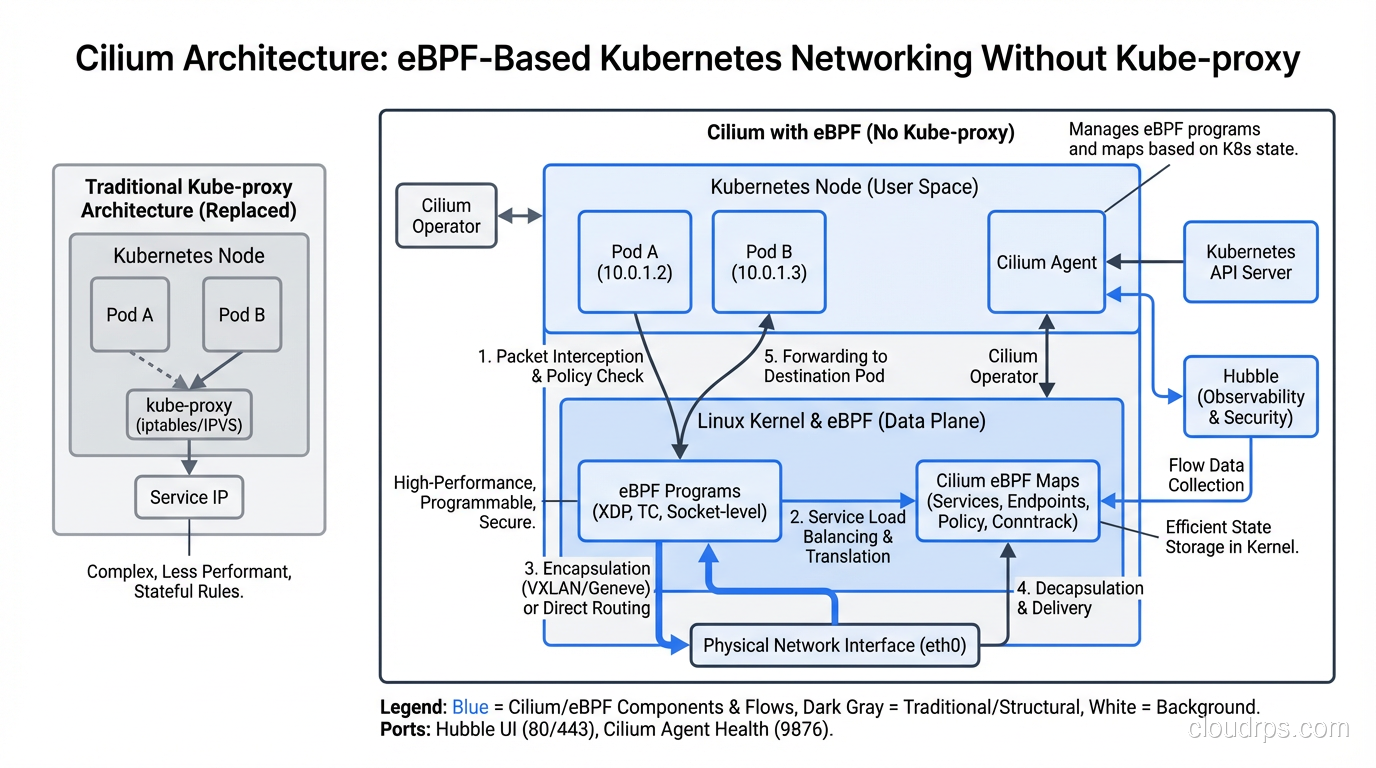
But Cilium does more than just replace kube-proxy. It implements the full Kubernetes CNI (Container Network Interface), handling pod-to-pod networking, network policy enforcement, and load balancing all through eBPF programs. Network policies, which traditionally relied on iptables or ipset, become eBPF map lookups. This means you can have thousands of granular network policies without measurable performance degradation.
XDP: Kernel-Bypass Networking Without Bypassing the Kernel
XDP (eXpress Data Path) is eBPF’s answer to kernel-bypass networking frameworks like DPDK. XDP programs attach to the network driver itself, before the kernel’s networking stack even sees the packet. This means you can process, redirect, or drop packets with minimal overhead.
The classic use case is DDoS mitigation. An XDP program can inspect incoming packets and drop malicious traffic at the driver level, achieving drop rates of millions of packets per second per core. Compare that to iptables-based filtering, which processes packets much higher in the stack and can’t match that throughput.
Cloudflare’s entire DDoS mitigation pipeline runs on XDP. They’ve published benchmarks showing XDP dropping 10 million packets per second on commodity hardware. Facebook uses XDP for their L4 load balancer (Katran), which replaced their previous IPVS-based solution with dramatically better performance.
The beauty of XDP is that you get kernel-bypass-like performance while staying within the kernel’s security and management model. With DPDK, you hand the NIC entirely to a userspace process, losing all kernel visibility and tooling. With XDP, you’re still in the kernel, still using the kernel’s networking stack for traffic you want to process normally, and you can selectively fast-path only the traffic that needs it.
eBPF for Observability: Seeing Everything Without Changing Anything
This is the area where eBPF gets really interesting from an operational perspective. Traditional monitoring and observability requires instrumentation: you add metrics libraries to your application code, deploy sidecar proxies for network-level metrics, install agents that parse log files. Each layer of instrumentation adds overhead and complexity.
eBPF flips this model on its head. Because eBPF programs can attach to kernel hooks, they can observe system behavior without any application modification. No code changes. No library imports. No sidecars. No agent daemons parsing log files. Just kernel-level visibility into everything that happens on the system.
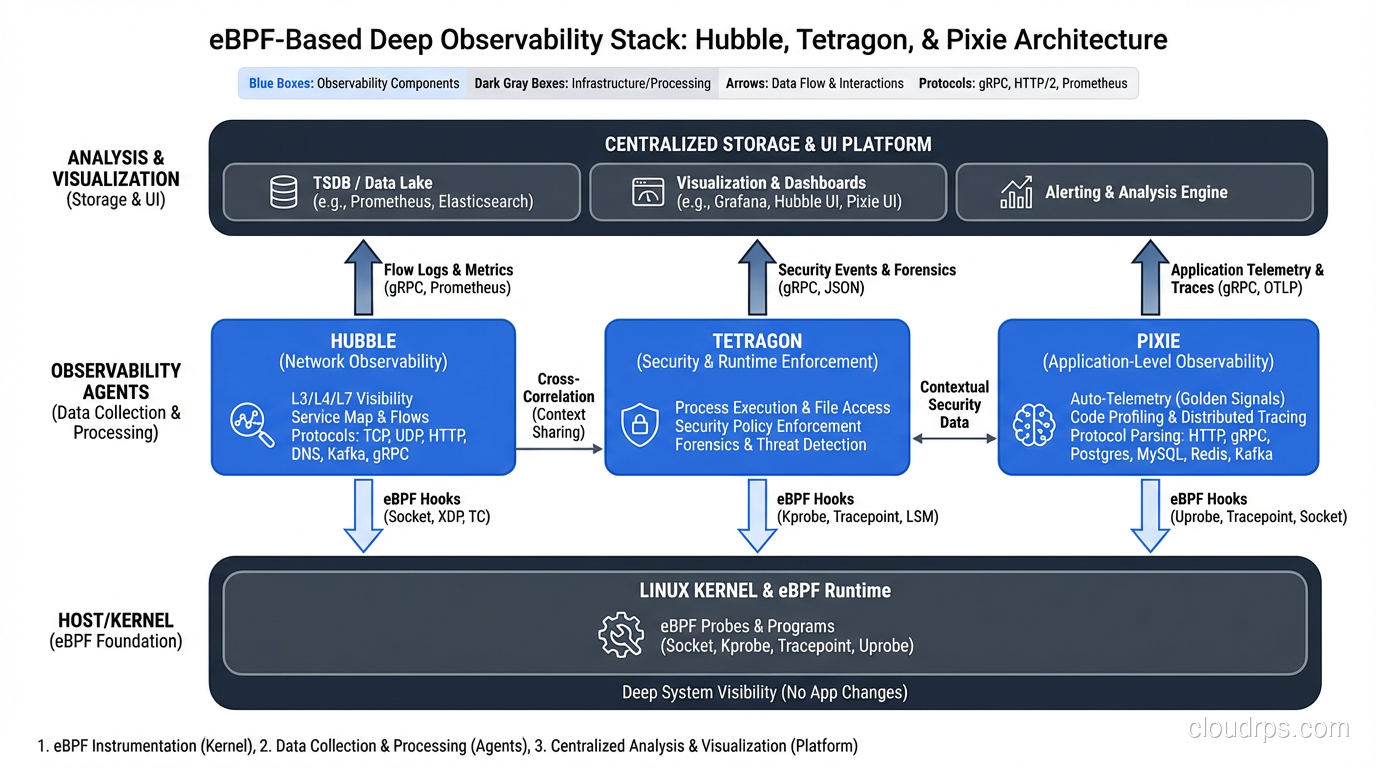
Hubble: Network Observability for Kubernetes
Hubble is Cilium’s observability layer. It uses eBPF to provide deep visibility into every network flow in your Kubernetes cluster: source pod, destination pod, protocol, HTTP method, response code, latency, DNS queries, and more. All without sidecars, all without application instrumentation.
I’ve used Hubble to debug issues that would have taken hours with traditional tools. One time, we had intermittent 503 errors that only happened between specific pods. Hubble showed us the exact DNS resolution failure causing the issue within minutes. The troubleshooting process went from “let’s add more logging and wait for it to happen again” to “here’s exactly what’s happening right now at the network level.”
Hubble’s UI gives you a service map that’s automatically generated from actual network traffic, not from configuration or manual documentation. You see the real communication patterns between your services, which is invaluable for understanding complex microservice architectures.
Pixie: Full Application-Level Observability
Pixie (now a CNCF sandbox project) takes eBPF observability even further. It captures full protocol traces for HTTP, gRPC, MySQL, PostgreSQL, Cassandra, Redis, Kafka, and DNS, all using eBPF. No sidecars, no agents, no code changes. It can show you individual SQL queries hitting your database, complete with latency distributions, without you having to configure anything.
Pixie attaches eBPF programs to the socket layer, where it can see unencrypted application protocol data (it captures data before TLS encryption on outbound and after decryption on inbound). This means you get application-layer tracing across your entire cluster by deploying a single DaemonSet.
Tetragon: Security Observability and Runtime Enforcement
Tetragon (also from Isovalent/Cilium) uses eBPF for security observability and runtime enforcement. It can trace process execution, file access, network connections, and privilege escalation at the kernel level. Think of it as a next-generation replacement for auditd that actually works in containerized environments.
Tetragon doesn’t just observe; it can enforce policies in real time. You can write policies like “alert if any process in this namespace opens /etc/shadow” or “kill any process that tries to execute a shell inside a production container.” The enforcement happens at the kernel level, so there’s no userspace process to bypass. This ties directly into how modern security teams think about security groups and access controls but operates at a much more granular level within the host itself.
Why eBPF Is Replacing Sidecars
If you’ve worked with a service mesh like Istio or Linkerd, you know the sidecar model. Every pod gets an Envoy proxy sidecar that handles mTLS, traffic management, and observability. This works, but it comes with real costs: memory overhead (each Envoy sidecar uses 50-100MB), CPU overhead (every packet traverses userspace twice), added latency (typically 1-3ms per hop), and operational complexity (sidecar injection, lifecycle management, version upgrades).
eBPF-based service meshes eliminate sidecars by moving mesh functionality into the kernel. Cilium Service Mesh implements mTLS, traffic management, L7 policy enforcement, and observability using eBPF programs, with no per-pod sidecars required. Istio’s ambient mesh mode takes a similar approach, using a per-node ztunnel daemon with eBPF for traffic interception instead of per-pod sidecars.
The performance difference is meaningful. In benchmarks, Cilium Service Mesh shows 40-60% lower latency compared to sidecar-based meshes for L4 traffic. For L7 traffic (where Envoy is still used as a shared per-node proxy rather than per-pod), the improvement is smaller but still significant because you eliminate one hop through the networking stack.
I’ve migrated two production clusters from sidecar-based Istio to Cilium’s service mesh, and the reduction in resource usage alone justified the effort. We reclaimed roughly 15% of cluster memory that was being consumed by Envoy sidecars. That’s real money at scale.
Understanding the Protocol Stack
To fully appreciate what eBPF does for networking, it helps to understand where it sits in the OSI model. XDP operates below Layer 3 (at the driver level, before the kernel even parses IP headers). TC (traffic control) eBPF programs operate at Layer 3/4. Socket-level eBPF programs can see up to Layer 7 application data. This flexibility across the stack is what makes eBPF suitable for everything from raw packet filtering to application protocol parsing.
Traditional networking protocols and their tooling operated in distinct layers with limited cross-layer visibility. eBPF breaks down those barriers. A single eBPF program can correlate a Layer 3 packet drop with a Layer 7 HTTP request, something that previously required stitching together data from multiple tools.
Getting Started: Practical Steps
If you want to start using eBPF in your infrastructure, here’s the practical path I’d recommend.
Step 1: Check your kernel version. eBPF features depend heavily on kernel version. For basic networking, you need at least kernel 4.15. For the full feature set (BTF, CO-RE, ring buffers), you want kernel 5.8 or later. Most modern distributions (Ubuntu 22.04+, Amazon Linux 2023, RHEL 9) ship with sufficiently recent kernels. If you’re on an older kernel, this is your first blocker.
Step 2: Install Cilium. The easiest way to get eBPF benefits in Kubernetes is to install Cilium as your CNI. On a new cluster, this is straightforward. On an existing cluster, you’ll need to migrate from your current CNI, which requires careful planning (Cilium has a migration guide). Use the Cilium CLI tool for installation and health checks:
cilium install --version 1.15
cilium status --wait
cilium connectivity test
Step 3: Enable Hubble for observability. Once Cilium is running, enable Hubble to get network observability:
cilium hubble enable --ui
cilium hubble port-forward &
hubble observe --namespace production
Step 4: Explore with bpftool. For lower-level eBPF exploration, bpftool is your friend. It lets you inspect loaded eBPF programs, maps, and attachments:
bpftool prog list
bpftool map list
bpftool net show
Step 5: Write your first eBPF program. When you’re ready to write custom eBPF code, start with libbpf (C) or Aya (Rust). The BCC (BPF Compiler Collection) toolkit is good for prototyping but libbpf is preferred for production due to its CO-RE (Compile Once, Run Everywhere) support.
Limitations and Gotchas
I’d be doing you a disservice if I didn’t talk about where eBPF falls short or causes headaches.
Kernel version fragmentation is the biggest practical issue. Not all eBPF features are available on all kernels, and the feature matrix is complex. If you’re running a mix of kernel versions across your fleet (common in large enterprises), you’ll need to carefully test which features work where. Cilium handles this reasonably well by detecting kernel capabilities at startup, but custom eBPF programs need to handle this explicitly.
Debugging is hard. When an eBPF program doesn’t work as expected, debugging it is significantly harder than debugging userspace code. The verifier’s error messages are notoriously cryptic. Tools like bpftool prog dump help, but you’re often staring at eBPF bytecode or JIT-compiled assembly. The ecosystem is improving here (bpftrace for quick tracing, libbpf-tools for common use cases), but it’s still not as mature as userspace debugging.
The verifier can be frustrating. The verifier is conservative by design, which means it will sometimes reject programs that are actually safe. You’ll spend time restructuring code to satisfy the verifier, especially with complex control flow or large programs. Bounded loops were only added in kernel 5.3, and even now, the verifier imposes strict complexity limits.
Not a silver bullet for all networking. eBPF excels at packet processing and policy enforcement, but it’s not a replacement for all networking functionality. Complex L7 protocol handling (think full HTTP/2 parsing with connection pooling) is still better suited to userspace proxies like Envoy. The sweet spot for eBPF is high-performance, relatively simple per-packet or per-connection logic.
Observability overhead exists. While eBPF observability is lower overhead than sidecar-based approaches, it’s not zero overhead. Attaching tracing programs to hot code paths can impact performance. You need to be deliberate about what you trace and how often. In production, I’ve seen poorly written eBPF tracing programs add 2-5% CPU overhead.
The Bigger Picture
eBPF represents a fundamental shift in how we think about kernel functionality. Instead of a monolithic kernel that you take as-is, or extend dangerously with modules, you get a programmable kernel that you can safely customize for your specific workload. This is why every major cloud provider and infrastructure company is investing heavily in eBPF: AWS uses it in their VPC networking, Google uses it in GKE Dataplane V2, Microsoft uses it in Azure CNI, and Meta uses it across their entire fleet.
For cloud architects and infrastructure engineers, the practical takeaway is clear. If you’re running Kubernetes, evaluate Cilium for your CNI and service mesh needs. If you’re doing network observability, look at Hubble and Pixie before deploying another sidecar-based solution. If you’re doing runtime security, Tetragon and Falco (which also uses eBPF) deserve evaluation.
The eBPF ecosystem is maturing rapidly, and the tools built on top of it are production-ready today. You don’t need to write eBPF bytecode to benefit from it. You just need to understand what it is and choose the right tools that leverage it. The kernel is programmable now, and that changes everything about what’s possible in cloud infrastructure.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.