A few years ago, I was working with a manufacturing client that ran a stamping press line producing automotive parts. Each press cycle took about 1.2 seconds, and the quality inspection system needed to make a pass/fail decision before the next cycle began. The original plan was to stream sensor data to a cloud-based ML inference endpoint in us-east-1. On paper, the round-trip latency was supposed to be 40-60ms. In practice, with network jitter, TLS handshakes, and the occasional GC pause on the inference server, we were seeing spikes of 200ms or more. That’s fine for a web app. It’s not fine when a bad part slips through and you’ve already stamped three more on top of it.
We moved the inference model to a hardened compute box sitting six feet from the press line. Latency dropped to under 5ms. Defect escape rate fell by 80%. And I became a true believer in edge computing.
But here’s the thing: we still used the cloud. A lot. The edge box handled real-time inference, but model training, historical analytics, fleet management across twelve plants, and long-term data storage all lived in AWS. That project taught me something I keep coming back to: edge computing is not a replacement for cloud computing. It’s a complement to it.
What Is Edge Computing, Really?
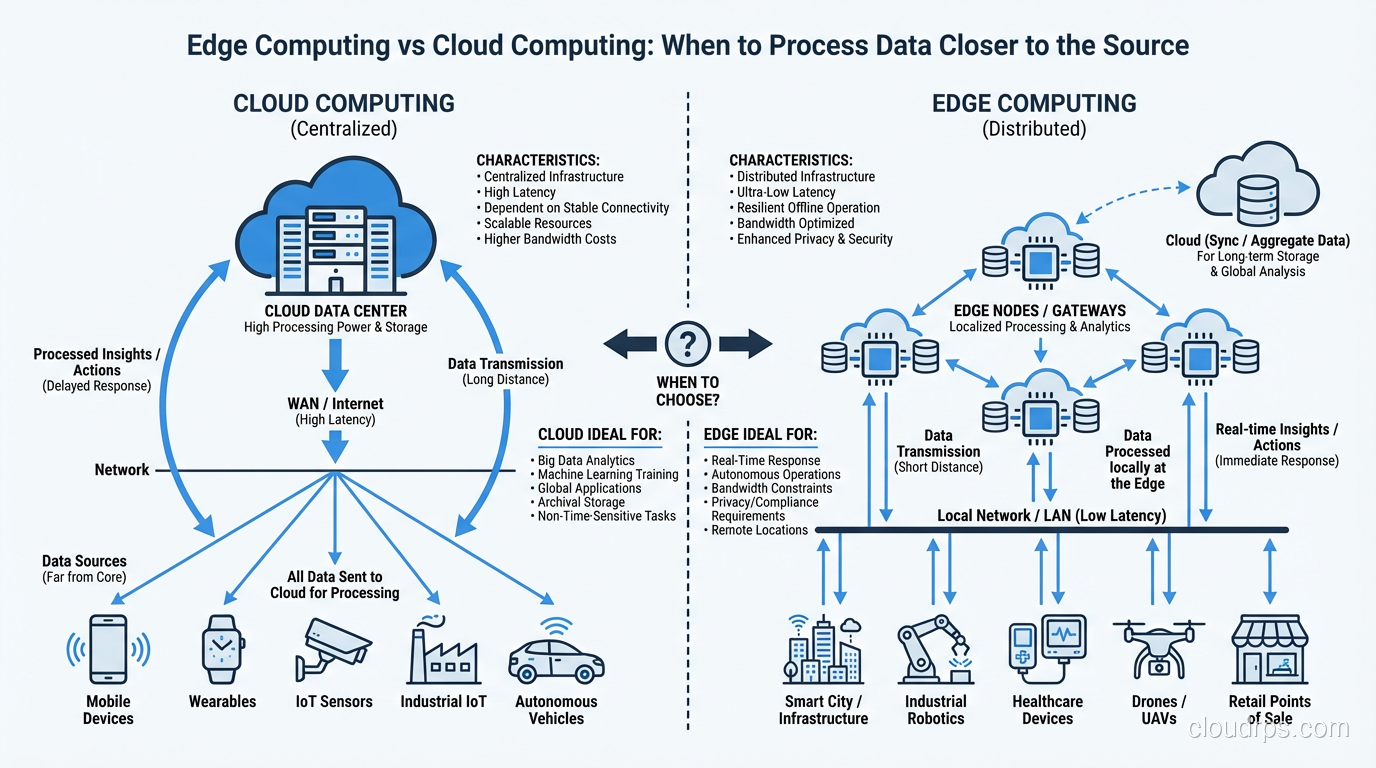
If you’re newer to cloud computing concepts, let me keep this simple. Edge computing means processing data closer to where it’s generated, rather than sending everything to a centralized data center or cloud region. “Closer” might mean on the device itself, on a local server in the same building, on a cell tower, or at a regional point of presence. The defining characteristic is that compute happens near the data source instead of far away from it.
The word “edge” refers to the edge of the network, the boundary where your devices and users interact with the wider internet. Instead of every byte traveling hundreds or thousands of miles to reach a cloud data center, you intercept it closer to origin and do something useful with it right there.
This isn’t actually a new idea. CDNs have been caching content at the edge for decades (if you want a refresher, check out how CDNs work). What’s changed is that we’re now pushing compute, not just cached content, to those edge locations. We’re running application logic, ML inference, data filtering, and even lightweight databases at the edge.
The Latency Problem Edge Computing Solves
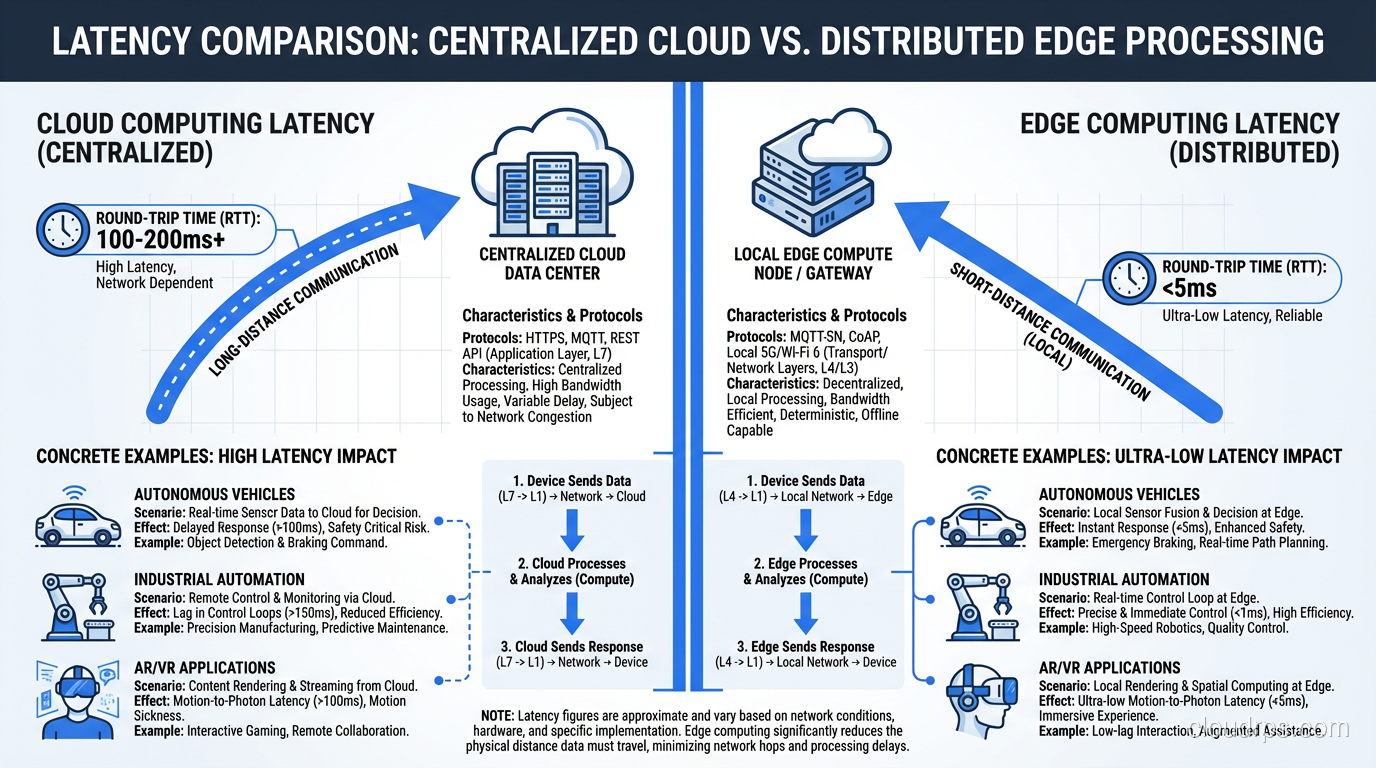
Let’s put some real numbers on this, because the latency argument is the single strongest case for edge computing.
A typical round trip from a user in Chicago to an AWS region in Northern Virginia (us-east-1) takes 20-40ms on a good day. To a region in Oregon (us-west-2), it’s 50-70ms. To a region in Frankfurt, you’re looking at 90-120ms. These numbers assume clean network paths and no congestion. In the real world, add TLS negotiation, DNS resolution, and application processing time, and you’re easily north of 100-200ms for a complete request-response cycle.
For most web applications, 100-200ms is perfectly acceptable. Your users won’t notice. But there’s a growing category of workloads where those numbers are a dealbreaker:
- Autonomous vehicles need to make steering decisions in under 10ms. Waiting for a cloud response means the car has already traveled several feet.
- Industrial automation systems like my stamping press example need sub-10ms response times to prevent defective output or safety incidents.
- AR/VR applications need under 20ms motion-to-photon latency or users get nauseous. Physics doesn’t care about your cloud architecture.
- Real-time gaming suffers noticeably above 50ms of added latency. Competitive players will abandon your platform.
Edge computing addresses this by putting compute resources within 1-5ms of the data source. Sometimes that means on-premise hardware. Sometimes it means a micro data center at a cell tower or ISP point of presence. The point is: fewer network hops, shorter physical distance, lower latency.
I wrote about latency vs bandwidth in a previous post. The short version is that bandwidth is a pipe you can make wider, but latency is constrained by the speed of light. You can’t fix physics with a bigger network pipe. You fix it by moving compute closer to the source.
Edge Computing Architecture: The Layers
Real-world edge deployments aren’t just “throw a server in a closet.” There’s a layered architecture that most mature implementations follow:
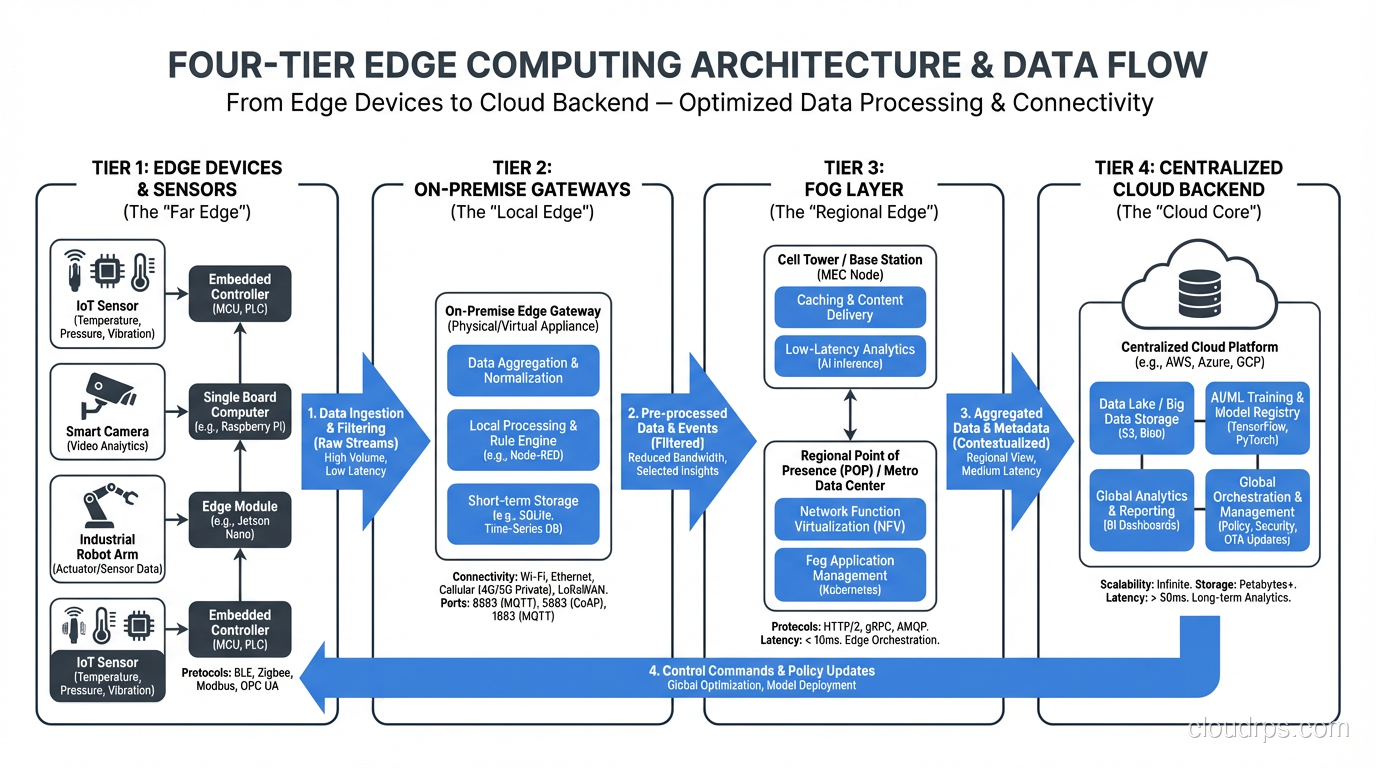
Device Edge (Tier 1)
This is the actual IoT device, sensor, camera, or endpoint. Processing here means running inference on a microcontroller, doing signal filtering on an FPGA, or running lightweight logic on a Raspberry Pi. The hardware is constrained (limited CPU, memory, power), but the latency is essentially zero because you’re processing right on the device.
Near Edge / On-Premise Edge (Tier 2)
A local server, gateway, or small cluster sitting in the same facility. This is where you’d run more substantial workloads: a Kubernetes cluster with a few nodes, a local database, or a heavier ML model. My manufacturing client’s inference box lived at this tier. You get single-digit millisecond latency with much more compute capacity than the device edge.
Far Edge / Fog Layer (Tier 3)
This sits between on-premise infrastructure and the cloud. Think cell tower compute (like AWS Wavelength), regional micro data centers, or ISP points of presence. Latency is typically 5-20ms. This tier is particularly relevant for mobile and connected vehicle use cases where you can’t control the physical location of the device.
Cloud Backend (Tier 4)
The traditional centralized cloud. This is where you do the heavy lifting: model training, big data analytics, long-term storage, centralized management, and anything that doesn’t have hard latency requirements.
The key insight is that data flows between these layers. Raw sensor readings might get filtered at the device edge, aggregated at the near edge, analyzed for trends at the fog layer, and stored permanently in the cloud. Each layer adds latency but also adds compute capacity and storage. Designing the right data flow between these tiers is where the real architectural skill comes in.
Where Edge Computing Wins
Not every workload belongs at the edge. But when it does, the advantages are significant.
IoT and Industrial Automation
This is the bread and butter of edge computing. Manufacturing plants, oil rigs, wind farms, and smart buildings generate massive volumes of sensor data. Sending all of it to the cloud is expensive (bandwidth costs), slow (latency), and fragile (what happens when the internet connection drops?). Edge computing lets you process locally, act on anomalies immediately, and only send summarized or relevant data to the cloud. I’ve seen edge deployments reduce cloud data transfer costs by 90% or more simply by filtering noise at the source.
Autonomous Vehicles and Robotics
A self-driving car generates roughly 1-2 TB of sensor data per hour. You’re not streaming that to the cloud for real-time decision making. The vehicle’s onboard computers handle perception, planning, and control locally. Cloud connectivity is used for map updates, fleet telemetry, and training data upload when the vehicle is parked and connected to Wi-Fi.
Content Delivery and Real-Time Personalization
CDNs have always been an edge technology. But modern edge platforms like Cloudflare Workers and AWS CloudFront Functions let you run actual application logic at edge locations. You can do A/B testing, geo-based personalization, authentication, and request routing without ever hitting an origin server. If you’re running a serverless architecture, edge functions are a natural extension.
AR/VR and Real-Time Gaming
These applications are latency-sensitive to the point where user experience degrades in physically perceptible ways. Edge compute at cell towers (via 5G MEC) or regional points of presence can shave critical milliseconds off response times.
Real-Time Video Analytics
Security cameras, traffic monitoring, retail analytics. Running computer vision models at the edge means you can detect events in real time without streaming high-bandwidth video feeds to the cloud. You send alerts and metadata instead of raw video, which is both faster and cheaper.
Where Cloud Computing Still Wins
I want to be clear: for most workloads, centralized cloud computing is still the right answer. Edge computing solves specific problems, but it comes with significant operational overhead. Here’s where the cloud remains king:
Machine Learning Training
Training a large model requires massive GPU clusters, petabytes of training data, and hours or days of compute time. You’re not doing this at the edge. You train in the cloud (or on-premise GPU clusters) and deploy the trained model to edge devices for inference.
Batch Processing and Data Warehousing
ETL pipelines, data lakes, business intelligence, historical analytics. These workloads are not latency-sensitive. They benefit from the virtually unlimited scalability of cloud platforms and the ability to spin up hundreds of nodes for a processing job and shut them down when it’s done.
Collaboration and SaaS Applications
Email, project management, document editing, CRM. These applications need centralized data stores that multiple users access from different locations. Edge computing doesn’t help here because the value comes from centralization, not distribution.
Disaster Recovery and Global Redundancy
Cloud providers offer multi-region replication, automated failover, and high availability patterns that are extremely difficult to replicate across a fleet of edge locations. For workloads that need strong fault tolerance, the cloud’s managed infrastructure is hard to beat.
Development and Testing Environments
Spinning up dev/staging environments on demand, running CI/CD pipelines, doing integration testing. The cloud’s elasticity and self-service provisioning make it the natural home for these workflows.
Hybrid Edge-Cloud Patterns
In my experience, almost every production edge deployment is actually a hybrid architecture. Pure edge or pure cloud is rare. Here are the patterns I see most often:
Edge Inference, Cloud Training
The most common pattern. You train ML models in the cloud using large datasets and GPU clusters, then deploy optimized versions of those models to edge devices for real-time inference. The edge devices send back telemetry and new training data, which feeds the next model iteration. This creates a continuous improvement loop.
Edge Filter, Cloud Store
Edge devices filter, aggregate, and compress raw data before sending it to the cloud. Instead of streaming 1000 temperature readings per second, the edge node sends one-minute averages and any anomaly events. This dramatically reduces bandwidth costs and cloud storage requirements.
Edge Act, Cloud Analyze
The edge takes immediate action (shut down a machine, alert an operator, adjust a parameter), while the cloud performs deeper analysis on historical data to find long-term trends and optimize processes. Real-time decisions happen locally; strategic decisions happen centrally.
Edge Cache, Cloud Serve
This is essentially the CDN model extended to dynamic content. Edge nodes cache frequently accessed data and serve it locally. Cache misses and writes go back to the cloud origin. This pattern works well for read-heavy applications with geographic distribution.
The Hard Parts: Challenges of Edge Computing
I’d be doing you a disservice if I didn’t talk about the challenges. Edge computing is genuinely harder to operate than centralized cloud infrastructure. Here’s what keeps me up at night on edge projects:
Management at Scale
Managing 10,000 edge devices spread across hundreds of locations is a fundamentally different problem than managing 50 EC2 instances in a single region. You need robust device management, remote provisioning, over-the-air updates, and health monitoring for devices that may have intermittent connectivity. Tools like AWS IoT Greengrass, Azure IoT Edge, and K3s help, but the operational complexity is real.
Security at the Edge
Edge devices often sit in physically insecure locations: factory floors, retail stores, cell towers, vehicles. An attacker with physical access to a device can extract credentials, tamper with firmware, or use the device as a pivot point into your network. You need hardware security modules, secure boot chains, encrypted storage, and network segmentation. The attack surface at the edge is much larger than in a locked-down cloud data center. Make sure you understand how VPNs work and consider zero-trust networking models for edge-to-cloud communication.
Data Consistency
When you distribute processing across many locations, you inevitably face consistency challenges. If two edge nodes process related data independently, how do you reconcile conflicting results? If an edge node makes a decision while disconnected from the cloud, how do you sync that decision when connectivity returns? You’ll find yourself deep in distributed systems theory (CAP theorem, eventual consistency, conflict-free replicated data types) whether you planned to or not.
Software Updates and Versioning
Rolling out a new model or application version across thousands of edge devices is not like deploying to a Kubernetes cluster. Devices may be offline, running different hardware, or in the middle of critical operations that can’t be interrupted. You need staged rollouts, automatic rollback capabilities, and the ability to run multiple versions simultaneously during transitions.
Observability
When something goes wrong at the edge, you can’t just SSH into the box. The device might be on a factory floor in another country, connected via a cellular modem with 200kbps of upstream bandwidth. You need lightweight local logging with smart summarization, efficient telemetry protocols, and the ability to remotely diagnose issues without saturating narrow network links.
Key Vendors and Platforms
The edge computing market has matured significantly. Here’s a quick tour of the major players:
AWS offers several edge products depending on how close to the data source you need to be. AWS Outposts puts AWS hardware in your data center. AWS Wavelength embeds compute at telecom carrier 5G edge locations. AWS IoT Greengrass runs Lambda functions and ML models on IoT devices. CloudFront Functions and Lambda@Edge run code at CDN edge locations.
Microsoft Azure has Azure Stack Edge, which is a managed appliance for running Azure services on-premise. Azure IoT Edge handles containerized workloads on IoT devices. Azure Arc lets you manage on-premise and edge Kubernetes clusters from the Azure portal.
Google Cloud offers Google Distributed Cloud (GDC), which runs Google Cloud services at the edge or on-premise. For lighter workloads, Google Cloud IoT (now migrated to partner solutions) and integration with Anthos for hybrid management.
Cloudflare Workers deserves special mention. It runs JavaScript/WASM at over 300 edge locations worldwide with sub-millisecond cold starts. For web-facing edge compute (personalization, authentication, routing, API gateways), it’s hard to beat on simplicity and performance. If you’re already running a serverless architecture, Workers can extend it to the edge with minimal effort.
Fastly Compute offers a similar model using WASM at the CDN edge, with strong support for Rust and Go.
Making the Decision: A Practical Framework
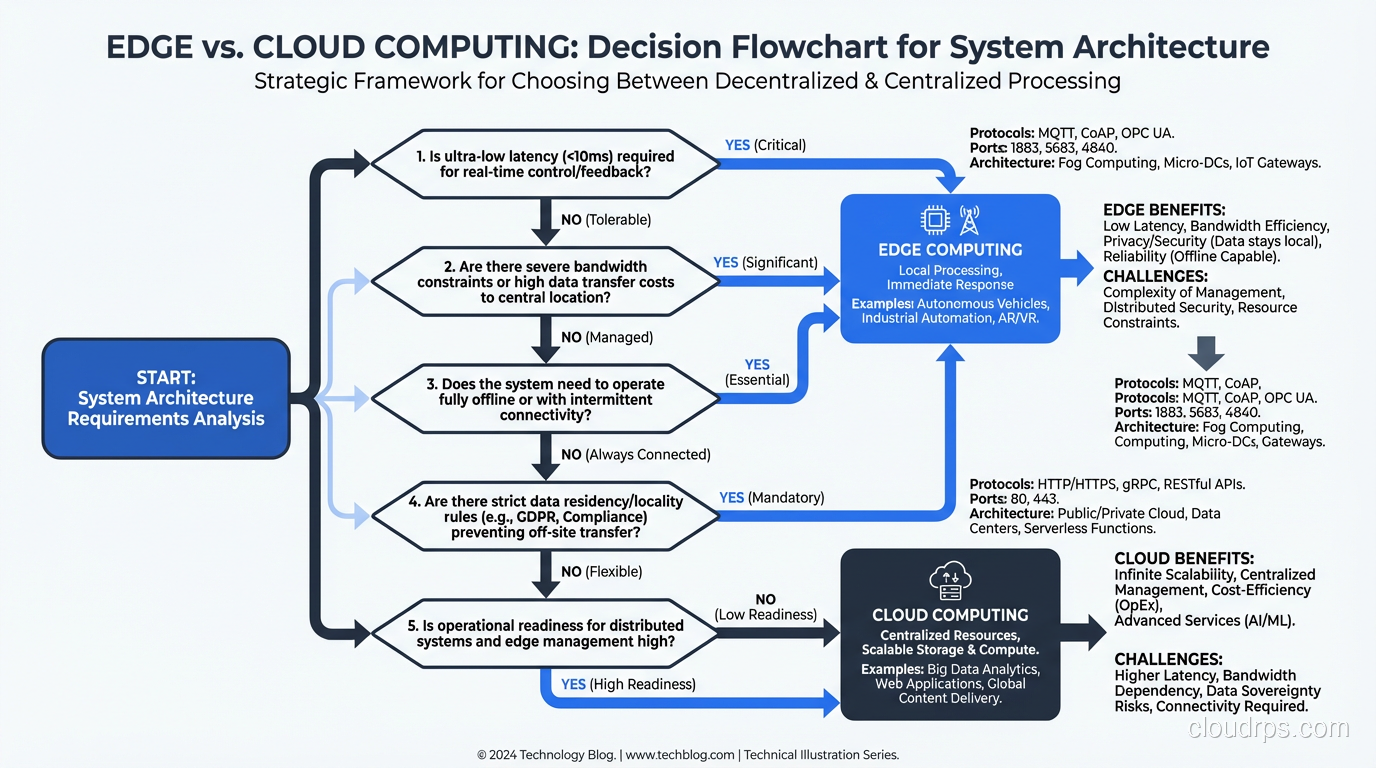
After building both edge and cloud systems for years, here’s the decision framework I use with my clients. It comes down to five questions:
1. Is latency critical? If your application breaks, degrades, or becomes dangerous above 50ms of round-trip latency, you need edge compute. If 200ms is fine, stay in the cloud. It’s cheaper and simpler.
2. Is bandwidth a constraint? If you’re generating gigabytes of data per hour at each location and only have a 10Mbps uplink, you physically cannot send everything to the cloud. Process locally, send summaries.
3. Does the application need to work offline? If your system must function when internet connectivity is lost (and in industrial and mobile environments, it will be lost), you need local processing capability. The cloud is not available when the network is down.
4. Is the data sensitive to location? Data sovereignty regulations (GDPR, industry-specific requirements) may require that certain data never leaves a geographic boundary. Edge processing can keep sensitive data local while still sending anonymized or aggregated insights to the cloud.
5. Can you handle the operational complexity? This is the honest question that doesn’t get asked enough. Edge deployments require specialized skills, tooling, and processes. If your team is already stretched thin managing a cloud environment, adding an edge tier will make things harder before they get easier. Start small, prove the value, and build operational maturity incrementally.
Wrapping Up
Edge computing is not a trend or a buzzword. It’s a practical architectural pattern that solves real problems around latency, bandwidth, and availability. But it’s also not a silver bullet. The best architectures I’ve built combine edge processing for time-critical, bandwidth-constrained, or offline-capable workloads with cloud backends for heavy compute, long-term storage, and centralized management. Start by identifying which of your workloads actually need to run closer to the data source. If the answer is “none of them,” save yourself the operational headache and stay in the cloud. If the answer is “this specific use case needs sub-10ms response times and can’t tolerate network outages,” then edge computing is your friend. Just go in with your eyes open about the complexity you’re signing up for.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.