I get asked about the difference between fault tolerance and high availability at least once a month, and the confusion isn’t surprising. The terms get used interchangeably in marketing materials, certification study guides, and even some architecture documents. But they’re not the same thing, and conflating them leads to systems that are either under-engineered for their requirements or over-engineered for their budget.
Let me make the distinction clear with something from my own experience.
In 2015, I was running two different systems for the same financial services client. System A was their customer-facing trading platform. System B was their end-of-day reporting system. Both needed to be “reliable.” But what “reliable” meant was completely different for each.
When the trading platform went down, every second cost money. Literally. Traders couldn’t execute orders. The system needed to continue operating with zero interruption during component failures. That’s fault tolerance.
When the reporting system went down, someone noticed the next morning and it was restarted. If it missed a 15-minute window, nobody cared as long as the reports were eventually generated. That system needed to recover quickly from failures. That’s high availability.
Same word, “reliable.” Completely different requirements. Completely different architectures. Completely different costs.
Defining the Terms Precisely
High Availability (HA) means a system is designed to operate continuously with minimal downtime. When a component fails, the system recovers quickly, typically within seconds to minutes. There may be a brief interruption during failover, but the system comes back up automatically.
HA accepts that failures will cause brief disruption. The goal is to minimize the duration and frequency of that disruption.
Fault Tolerance (FT) means a system continues to operate correctly even when components fail, with zero interruption. No downtime. No degradation. Users don’t know anything went wrong.
FT demands that failures are completely invisible. The system must handle component failures in real-time without any observable impact on service.
If HA is about recovering from failure quickly, FT is about masking failure entirely.
For a deeper dive into HA patterns and implementation, I covered that in a dedicated post.
The Real-World Difference
Let me make this concrete with a database example.
High Availability Database
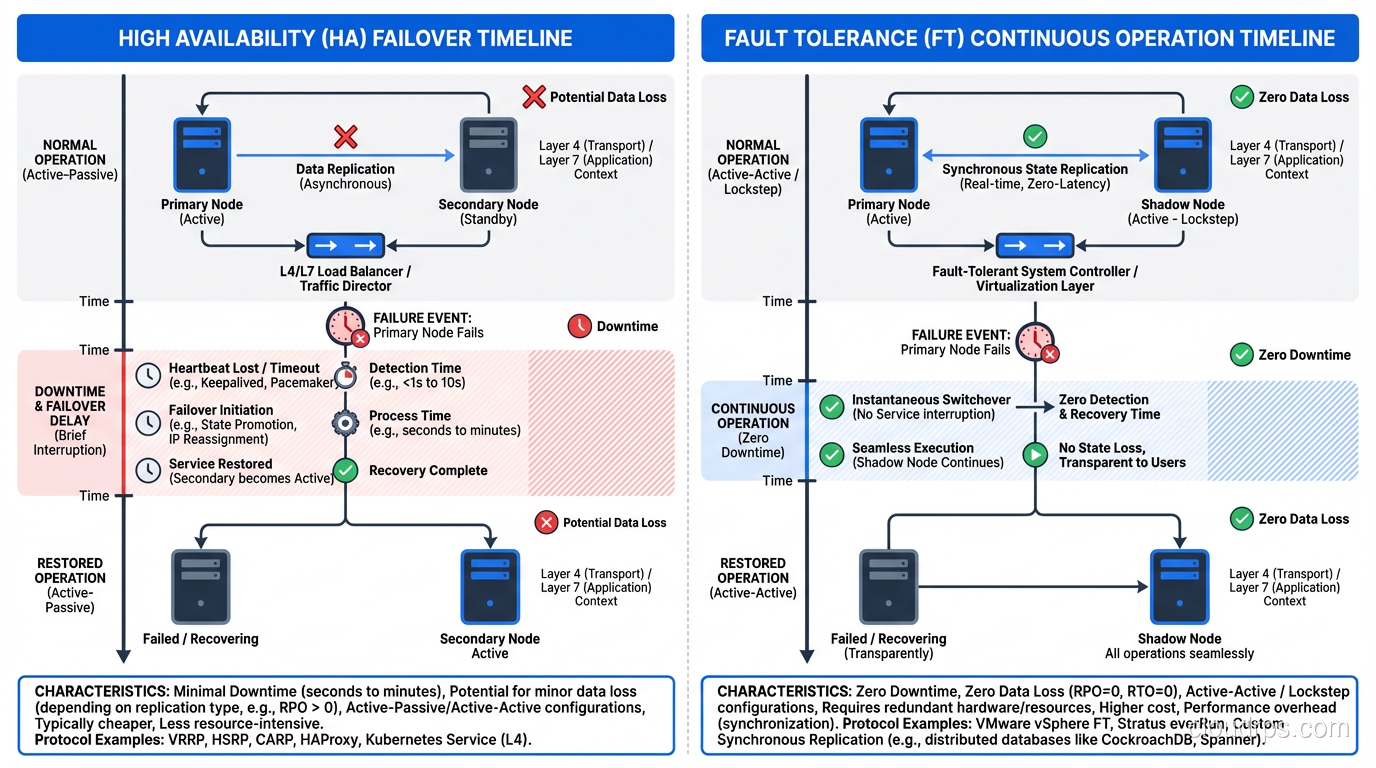
A typical HA database setup uses primary-standby replication:
- Primary database handles all traffic
- Standby database receives replicated data
- Primary fails
- Health check detects failure (5-15 seconds)
- Standby is promoted to primary (15-30 seconds)
- Application connections are redirected (5-10 seconds)
- Service resumes
Total interruption: 30-60 seconds. During that window, the application can’t write to the database. Depending on the application design, users might see errors, slow responses, or brief unavailability.
This is what RDS Multi-AZ provides. It’s HA, not FT. There’s a disruption during failover. For most applications, 30-60 seconds of disruption is acceptable. For some, it’s not.
Fault-Tolerant Database
A fault-tolerant database setup might use synchronous multi-primary replication:
- Multiple active database nodes handle traffic simultaneously
- Every write is synchronously committed to multiple nodes before acknowledgment
- One node fails
- Traffic automatically routes to remaining nodes
- Zero interruption. The application doesn’t notice
Systems like Amazon Aurora (with its multi-writer configuration), CockroachDB, or Google Spanner approach this model. The write is committed to multiple nodes before the application receives acknowledgment, so no committed data is lost and no interruption occurs when a node fails.
The cost is significant. Synchronous replication to multiple nodes adds write latency. Running multiple active database nodes costs more than primary-standby. The operational complexity of multi-primary conflict resolution is substantial.
When You Need Fault Tolerance
In my thirty years of building systems, I’ve only required true fault tolerance for a relatively small percentage of workloads. Here’s where it’s justified:
Financial Transaction Processing
Trading platforms, payment gateways, banking systems. When real money is moving, even a 30-second interruption can mean lost transactions, regulatory violations, or financial penalties. The cost of fault tolerance is trivial compared to the cost of losing transactions.
I once calculated the cost of a 60-second outage for a payment processor doing 10,000 transactions per minute at an average of $85 per transaction. Sixty seconds = 10,000 failed transactions = $850,000 in potentially lost revenue. The annual cost of fault-tolerant infrastructure was about $200,000. Easy math.
Safety-Critical Systems
Medical devices, aviation control systems, industrial process control. When human safety depends on system operation, fault tolerance isn’t optional; it’s a regulatory requirement. These systems use hardware-level redundancy: triple-modular redundancy (TMR), where three independent systems process the same inputs and vote on the output. If one disagrees, it’s outvoted and flagged for inspection.
Real-Time Communication Systems
911 dispatch systems, air traffic control communication, military command systems. These can’t go down, period. They use active-active architectures with automatic traffic redistribution.
When High Availability Is Enough
For most applications, HA provides sufficient reliability at a fraction of the cost. Here’s my rule of thumb:
If your system can tolerate 30-60 seconds of disruption during a failure without business-critical impact, HA is sufficient. This covers web applications, API services, content platforms, internal tools, e-commerce sites (with proper retry logic), and most SaaS applications.
If any interruption, even sub-second, causes unacceptable consequences, you need fault tolerance. This is a much smaller category than most people think.
I frequently push back on requirements that specify “fault tolerant” when “highly available” would suffice. The cost difference is substantial, and over-engineering wastes money that could be better spent elsewhere in the system.
Implementation Patterns
HA Patterns
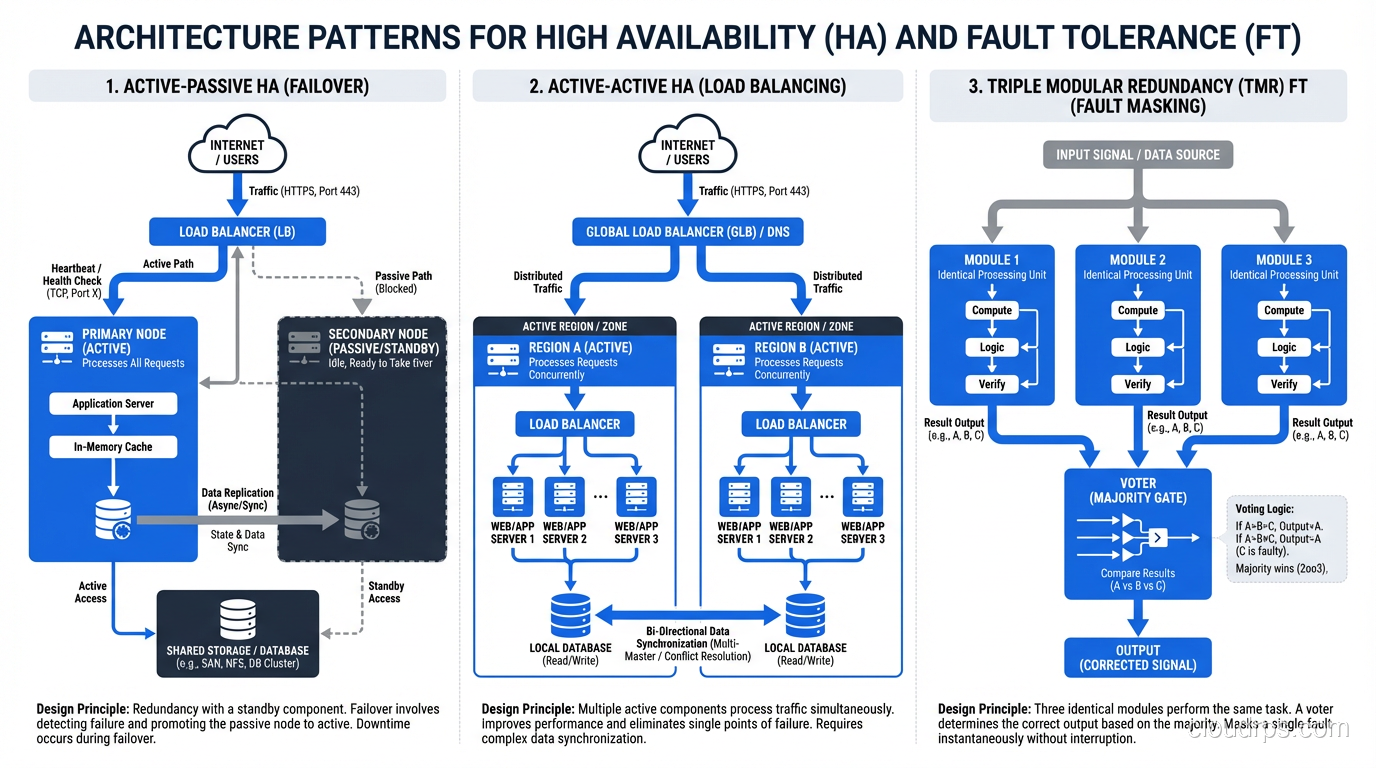
Active-Passive Failover: Primary handles traffic, standby waits. On primary failure, standby takes over. Simple, proven, and the most common HA pattern.
Active-Active with Partition Tolerance: Multiple instances handle traffic simultaneously. If one fails, the others absorb its share. This is more resilient than active-passive but requires stateless design or distributed state management.
Auto-Scaling Groups: Maintain a minimum number of healthy instances. If an instance fails, the auto-scaler launches a replacement. This provides HA through rapid replacement rather than pre-positioned standbys.
FT Patterns
Synchronous Replication: Every state change is committed to multiple nodes before acknowledgment. No data loss on node failure. Adds write latency proportional to network round-trip time between nodes.
Active-Active Multi-Primary: Multiple nodes process requests simultaneously. Traffic is distributed across all nodes. Any node failure is transparent because the others continue serving. Requires conflict resolution for concurrent writes.
Triple Modular Redundancy (TMR): Three independent systems process the same inputs. Results are compared through voting logic. A single failure is masked because the other two systems outvote the failed one.
Checkpoint and Restart: System state is periodically saved. On failure, a standby resumes from the last checkpoint. This isn’t true zero-interruption FT but provides very fast recovery for batch processing systems.
The CAP Theorem Connection
You can’t discuss fault tolerance in distributed systems without addressing the CAP theorem. CAP states that a distributed system can provide at most two of three guarantees: Consistency, Availability, and Partition Tolerance.
Since network partitions are inevitable in distributed systems, you’re really choosing between consistency and availability during a partition.
CP systems (Consistency + Partition Tolerance): During a partition, the system refuses to serve requests rather than risk returning inconsistent data. This is the fault-tolerant choice for financial systems. It’s better to reject a trade than to execute it incorrectly.
AP systems (Availability + Partition Tolerance): During a partition, the system continues serving requests but may return stale or inconsistent data. This is the HA choice for content platforms. It’s better to show a slightly stale product page than to show an error.
Understanding this trade-off is essential for designing the right level of fault tolerance for your system.
The Cost Reality
Let me put real numbers to this because the cost differential matters:
HA Architecture (typical web application on AWS):
- 2 application instances across 2 AZs: ~$300/month
- RDS Multi-AZ: ~$400/month
- ALB: ~$50/month
- Total: ~$750/month
FT Architecture (same application, fault-tolerant):
- 3+ application instances across 3 AZs: ~$450/month
- Aurora Multi-Master or CockroachDB cluster: ~$1,200/month
- Global Accelerator + ALB: ~$100/month
- Additional monitoring and alerting: ~$150/month
- Total: ~$1,900/month
That’s roughly 2.5x the cost for fault tolerance over high availability for a modest application. For large-scale systems, the multiplier can be 3-5x.
But cost isn’t just infrastructure. Fault-tolerant systems are more complex to design, build, test, and operate. Engineering effort is easily 2-3x for FT compared to HA. Ongoing operational complexity is higher because there are more components, more failure modes, and more edge cases to handle.
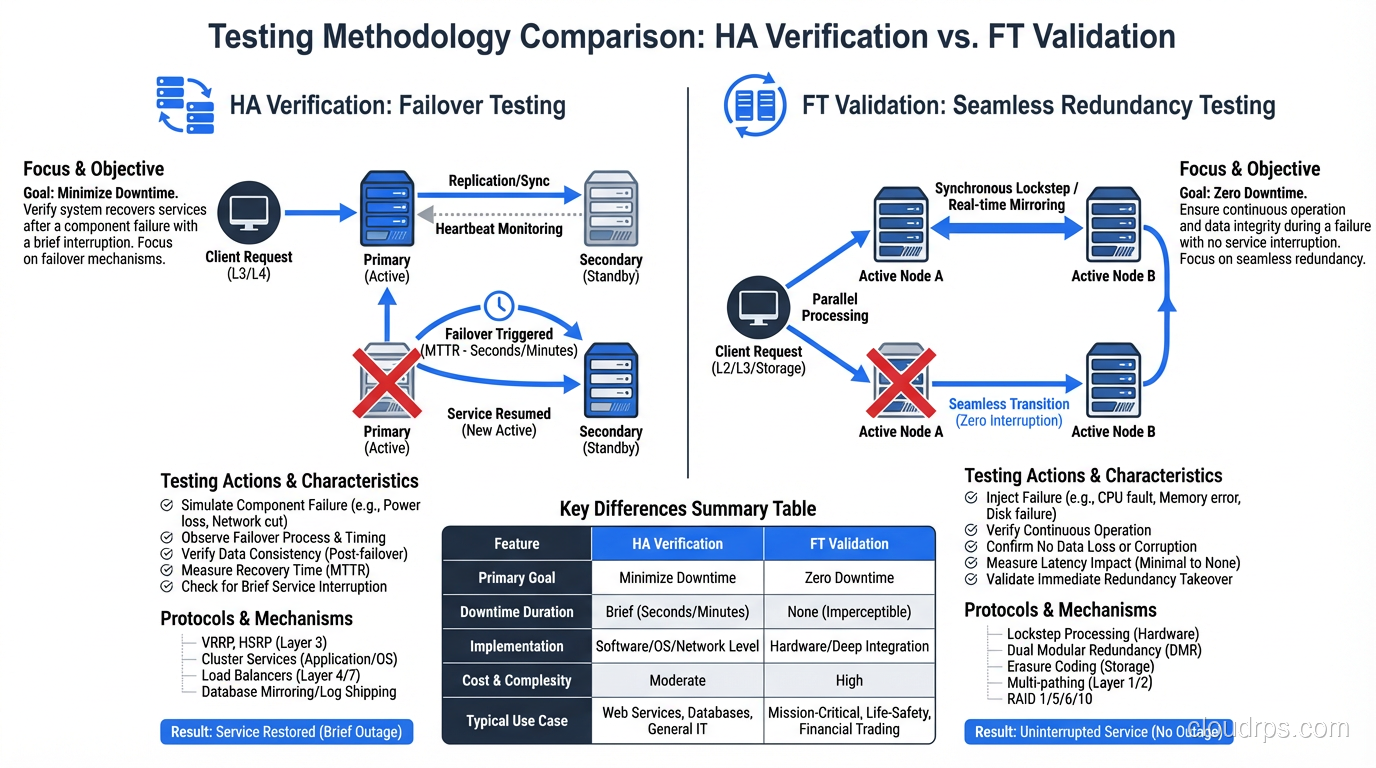
Testing: The Critical Difference
Testing HA means verifying that failover works and measuring recovery time. Kill a component, measure how long until the system recovers.
Testing FT means verifying that failure is invisible. Kill a component while generating traffic, and verify that zero requests fail, zero latency spikes occur, and zero errors appear.
FT testing is substantially harder because you’re proving a negative: proving that nothing bad happened during a failure. This requires comprehensive request-level monitoring, latency distribution analysis, and automated validation that no requests were lost or corrupted.
I test HA quarterly with chaos engineering exercises. I test FT continuously in production with ongoing failure injection at low rates. The testing investment for FT is significantly higher than for HA. If you want a deep dive into how to structure these failure injection experiments, including tools, game day planning, and building organizational buy-in, check out my guide to chaos engineering and resilience testing.
Making the Right Choice
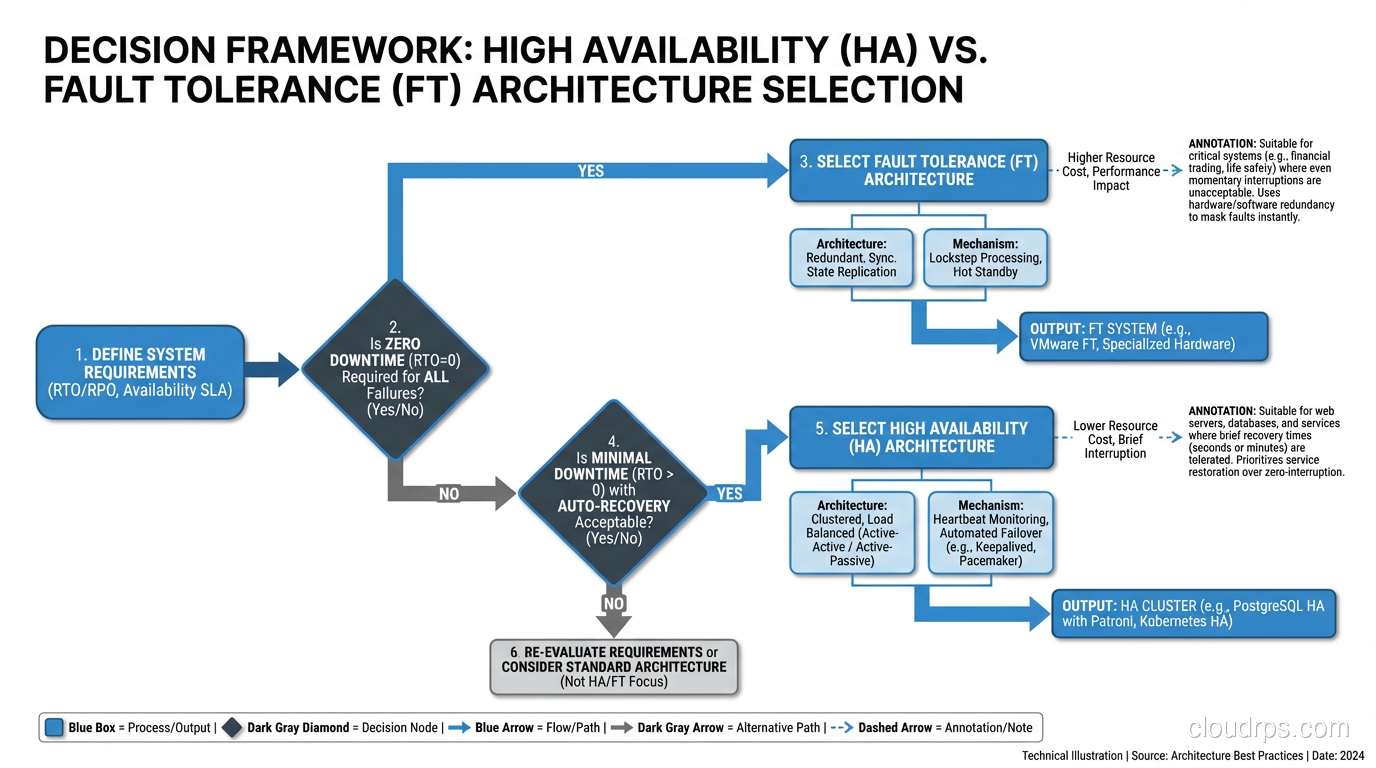
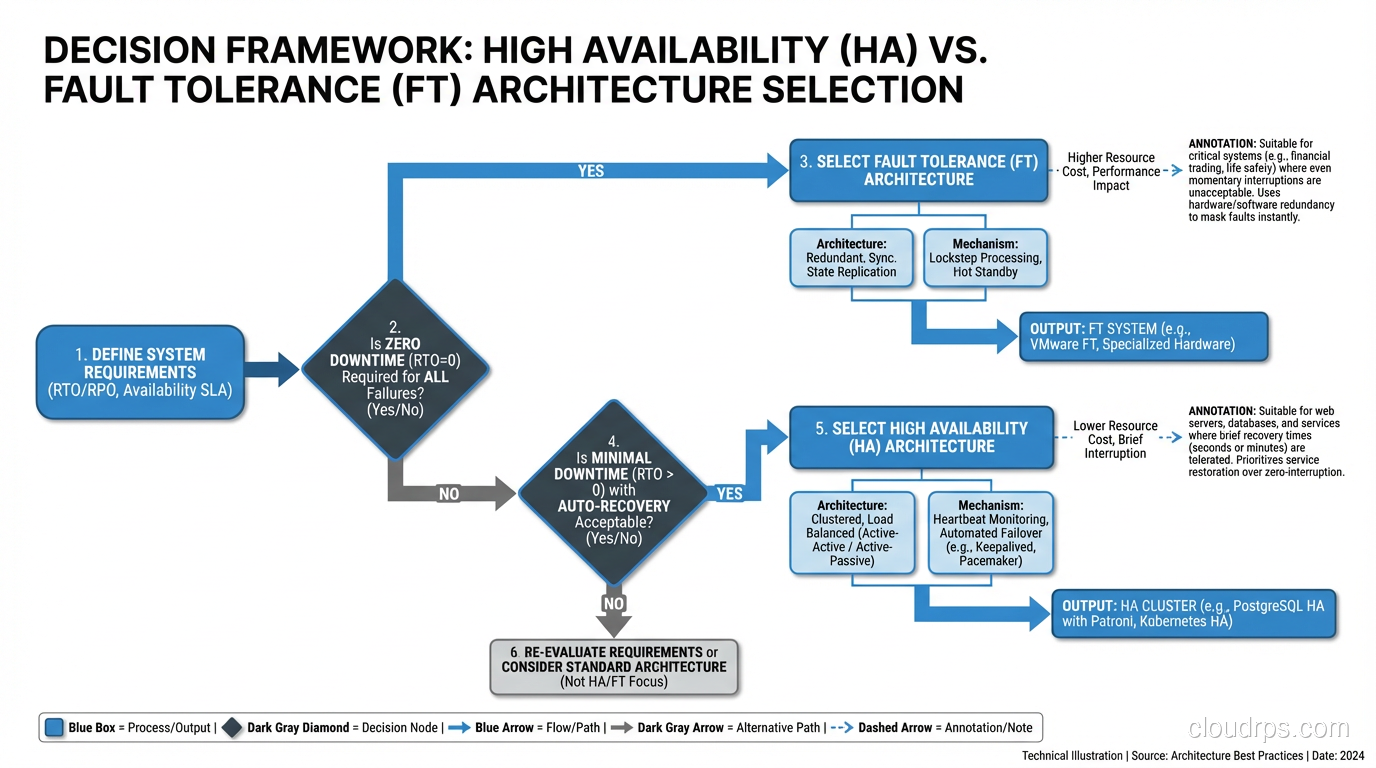
Here’s the decision framework I use:
- Define the cost of downtime, not just financial, but regulatory, reputational, and safety costs.
- Define the minimum acceptable recovery time. How long can the system be disrupted before unacceptable consequences occur?
- If the answer is “zero”, you need fault tolerance. Prepare for the cost and complexity.
- If the answer is “seconds to minutes”, high availability is sufficient. Design accordingly.
- Apply FT selectively. Most systems have components that need FT and components where HA is sufficient. The payment processing path might need FT while the admin dashboard only needs HA.
The most common mistake I see is applying a uniform availability target across the entire system. Different components have different requirements. A tiered approach (FT for critical paths, HA for important paths, and basic reliability for everything else) is more cost-effective and more achievable than trying to make everything fault-tolerant.
Understanding single points of failure is essential for both HA and FT. You can’t be either if you have components whose failure takes down the entire system.
Build what you need. Test what you build. And be honest about the difference between what you need and what sounds impressive on an architecture slide. That honesty will save you money, complexity, and late-night pages.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.