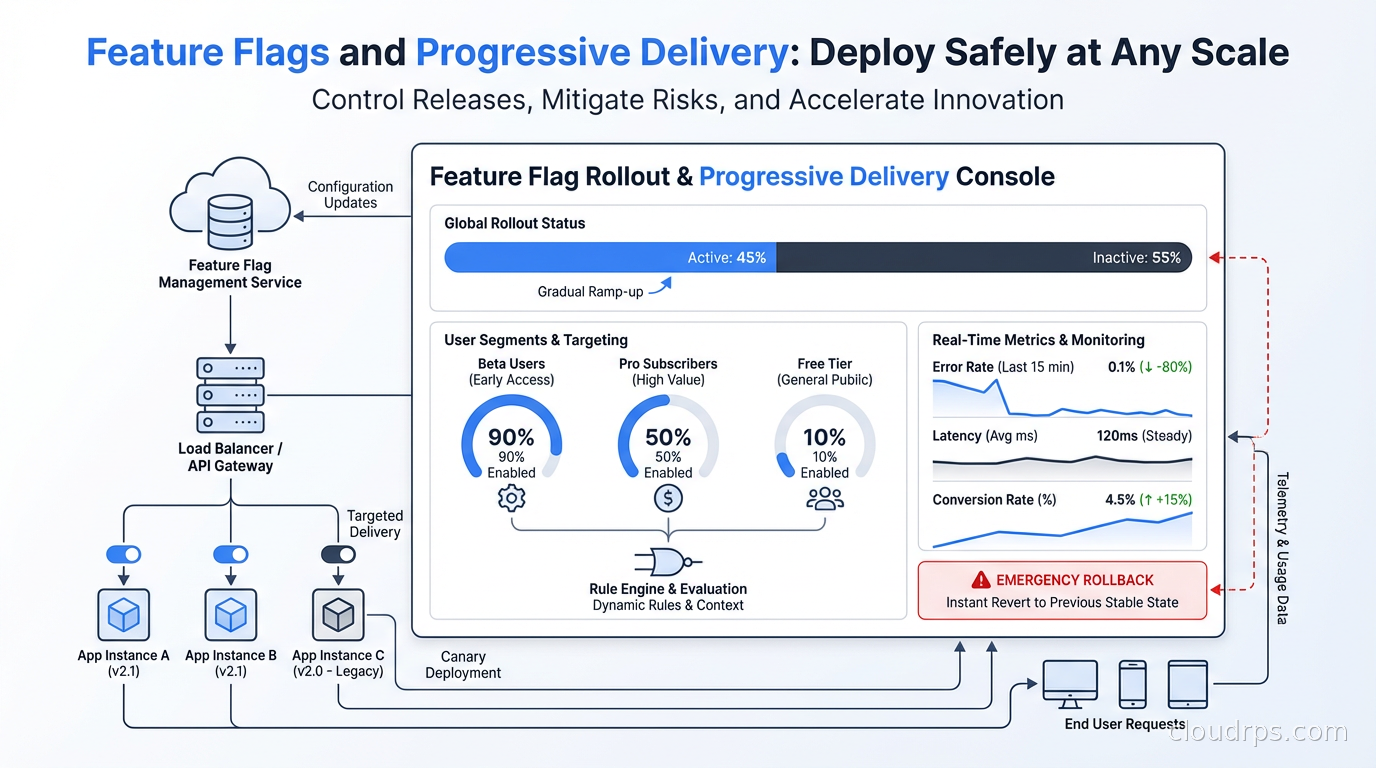
The first time I saw feature flags used at scale, I was visiting a team at a large e-commerce company. Their lead engineer showed me something I found almost unsettling: they were deploying to production dozens of times per day, and most of those deployments included code for features that weren’t “on” yet. The features shipped dark, completely invisible to users, until a product manager flipped a flag in a UI and they lit up. No deployment required. No coordination meeting. No maintenance window.
Coming from an environment where deployments were monthly events that required a 12-person sign-off process, this felt like science fiction. Feature flags are what made it possible, and they’re now the central mechanism behind how sophisticated engineering organizations do releases. Let me explain the architecture, the tooling, and the operational patterns that make this work.
The Core Idea: Separate Deployment from Release
The fundamental insight behind feature flags is that deployment (shipping code to production servers) and release (making a feature available to users) are different things, and treating them as the same thing is the source of enormous operational pain.
When you conflate deployment and release, you get: big batches of code shipped at once (risky), coordination required between product, engineering, and ops for every release, all-or-nothing rollouts (it’s either on for everyone or off for everyone), and when something goes wrong you have to roll back the entire deployment even if 95% of the changes were fine.
Feature flags decouple these. You ship code continuously, features hidden behind flags. When you’re ready to release a feature, you turn on the flag, no deployment needed. If the feature has problems, you turn off the flag, no deployment needed. The code stays in production; it’s just inactive.
This sounds simple, and in a small application it is. At scale, the implementation gets interesting.
Flag Types and When to Use Each
Not all feature flags are the same. Martin Fowler’s taxonomy is still the most useful I’ve encountered:
Release flags are the most common type: a feature is hidden behind a flag until it’s ready, then the flag is turned on and retired. They’re temporary by nature. They should live in your codebase for days or weeks, not months. Long-lived release flags become tech debt: the branch diverges in your head even if not in version control, and eventually you have code paths that nobody understands.
Experiment flags (A/B test flags) control which users see which variant of a feature. They’re tied to analytics collection and statistical significance testing. The flag evaluates to different values for different users, and those variations are tracked against conversion metrics, engagement, or whatever you’re measuring. When the experiment concludes, the losing variant is removed and the flag is retired.
Operational flags (circuit breakers, kill switches) are permanent infrastructure. A flag that lets you disable a third-party integration when it’s flaky, a flag that turns off a compute-intensive feature under extreme load, a flag that enables a fallback pricing calculation when your pricing service is down. These are operational tools, not temporary shipping mechanisms.
Permission flags control feature access by user segment: beta users, paying customers, internal employees, specific organizations. These can be long-lived and are often tied to your entitlement and subscription system.
Keeping these categories clear in your architecture matters because they have different lifecycle expectations, different flag evaluation patterns, and different retirement processes.
The Flag Evaluation Architecture
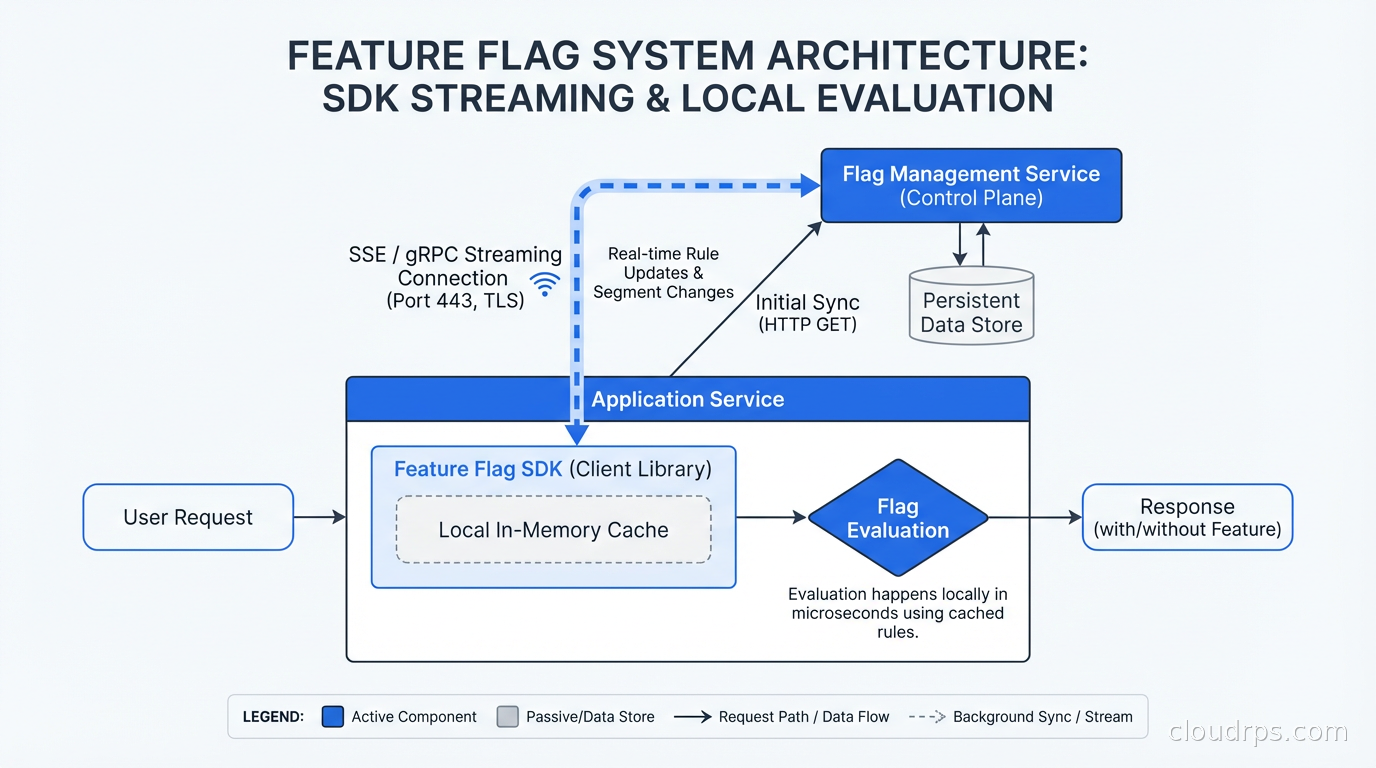
How you evaluate flags affects both performance and correctness. The naive implementation hits a database or API on every flag check in user-facing request paths. This adds latency to every request, creates a single point of failure, and doesn’t scale.
Production flag systems use a streaming architecture. The flag evaluation SDK maintains a local in-memory copy of all flag configurations, updated in near-real-time via a streaming connection to the flag service. Flag evaluations happen entirely in-process with no network calls: sub-millisecond evaluation latency, no network dependency in the hot path. When flag configurations change in the central service, the stream pushes the update to all SDK instances within seconds.
The flag service (LaunchDarkly, Flagsmith, Unleash, or your own) stores flag definitions, targeting rules, and variation percentages. SDK initialization downloads the full flag state. Subsequent evaluations use the cached state. The streaming connection keeps it current.
This is the architecture you need for high-traffic applications. Evaluating flags in the request path should be as cheap as reading a map entry.
Progressive Delivery: The Actual Rollout Strategy
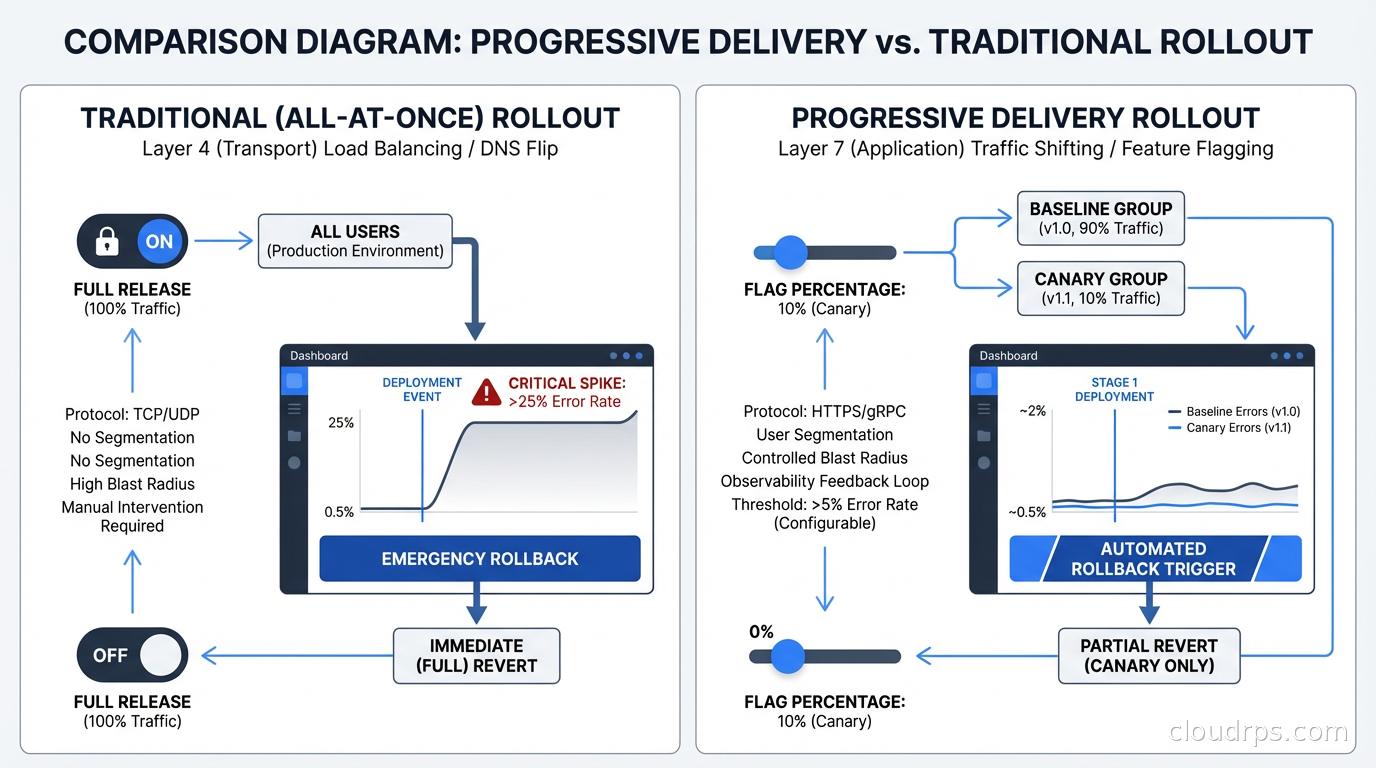
Feature flags enable progressive delivery: gradually rolling out a feature to increasing percentages of users while monitoring for problems.
The typical progression: 1% canary, 10%, 25%, 50%, 100%. At each stage, you hold for some period (anywhere from minutes to days depending on feature complexity and risk) and watch your metrics. Error rates, latency, business metrics, user-facing errors. If anything looks wrong, you kill the flag and instantly roll back to 0% without a deployment.
This is the key difference from blue-green deployments and canary deployments at the infrastructure level: flag-based progressive delivery gives you instant, zero-cost rollback. Blue-green requires keeping a standby environment warmed up. Infrastructure canary deployments route traffic at the load balancer or service mesh level. Flag-based delivery is cheaper and faster because the rollback is a configuration change, not an infrastructure operation.
The targeting for percentage rollouts should be sticky: the same user should consistently see either the old or new behavior, not a random flip on each request. Sticky bucketing is usually done by hashing the user ID (or device ID, or session ID) against the flag key. User ID 12345 with flag “new-checkout-flow” always evaluates to the same bucket, so they get a consistent experience.
Segment-based targeting adds power: roll out to internal employees first, then beta users, then users in a specific geographic region, then all users. This gives you progressively larger testing populations while limiting exposure of risky changes.
OpenFeature: The Emerging Standard
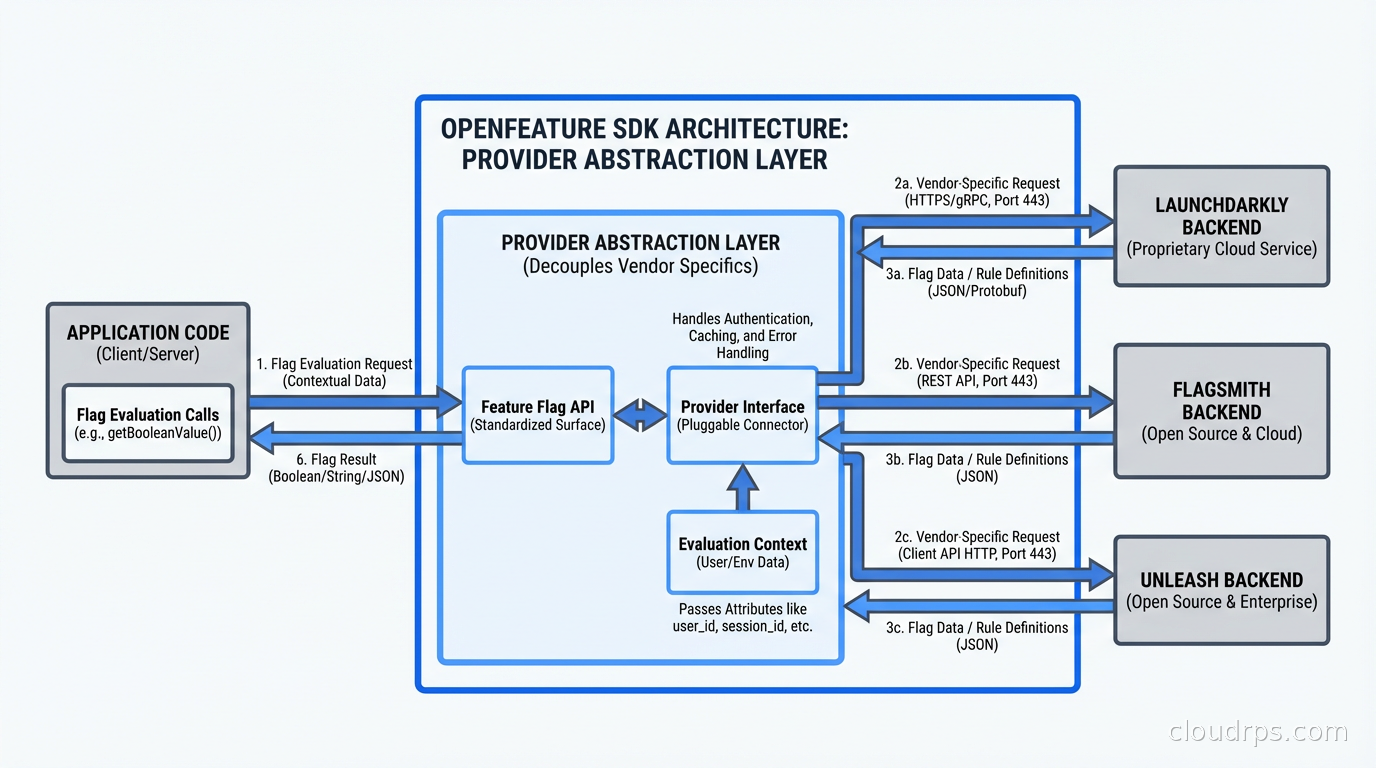
One frustration with feature flags has been vendor lock-in. Every vendor has their own SDK with their own API. Switching vendors means updating every flag evaluation call across your codebase.
OpenFeature is a CNCF-incubating project that defines a standard SDK interface for feature flag evaluation. Your application code calls the OpenFeature SDK. The OpenFeature SDK talks to a provider that wraps your actual flag backend: LaunchDarkly, Flagsmith, Unleash, Harness, or anything else. Switching vendors means swapping the provider, not rewriting your application code.
import { OpenFeature } from '@openfeature/server-sdk';
// Initialize with your provider (e.g., LaunchDarkly, Flagsmith)
await OpenFeature.setProvider(new MyFlagProvider());
const client = OpenFeature.getClient();
// Evaluate a flag - same API regardless of vendor
const showNewCheckout = await client.getBooleanValue('new-checkout-flow', false, {
targetingKey: userId,
customAttributes: { plan: 'enterprise', region: 'us-east' }
});
OpenFeature is gaining rapid adoption, especially in Kubernetes environments where the ecosystem tool integration (flagd as a sidecar, Kubernetes-native flag configuration via CRDs) fits the GitOps workflow well. If you’re starting a new flag implementation, I’d build on OpenFeature from day one.
Tooling Landscape
LaunchDarkly is the market leader. It’s polished, reliable, and has excellent SDKs for every language. The targeting rules, analytics integration, and workflow approvals are best-in-class. It’s also expensive: pricing scales with Monthly Active Users and can get painful for high-traffic consumer applications. For enterprise B2B with known user counts, it’s often worth it.
Flagsmith is the strong open-source option. You can self-host entirely (important for regulated industries or sovereignty requirements) or use their managed cloud. The feature set covers everything you need for serious production use: percentage rollouts, segment targeting, A/B testing, audit logs. The self-hosted option means you control your flag data completely.
Unleash is another solid open-source option with a long track record. Strong community, good SDKs, and the activation strategies (which is what they call targeting rules) are flexible. Similar self-host vs. cloud options to Flagsmith.
Growthbook specializes in the A/B testing and experimentation side. If your primary use case is running product experiments with statistical rigor rather than operational feature management, Growthbook is worth evaluating.
Flipt and flagd are newer, CNCF-adjacent projects focused on the Kubernetes-native, GitOps-friendly use case. Flag definitions live in Git, applied via CI/CD, evaluated by a sidecar or in-process via the OpenFeature SDK. This approach fits naturally into infrastructure-as-code workflows.
For most teams starting out: Flagsmith self-hosted or LaunchDarkly (if budget allows and you want a managed service). Build on OpenFeature interfaces from the start to preserve flexibility.
The Technical Debt Problem
Feature flags are one of the sneakiest forms of technical debt in software engineering. They accumulate silently. A flag that was “temporary” six months ago is still in the codebase. You now have an if/else branch that represents a code path nobody tests anymore. The old code path is dead but not deleted. Multiply this by 50 flags and your codebase becomes a maze of conditional logic with branches that nobody can confidently reason about.
The solution is treating flag retirement as a first-class engineering task:
Every release flag should have a defined expiry: a date by which it will either be retired (turned on permanently, old code deleted) or explicitly extended. Put it in a ticket at flag creation time.
Use static analysis tooling to find dead flag code. When a flag is removed from the flag service, your CI pipeline should catch evaluations of that flag in code and fail the build.
Track flag age in your metrics. Any flag older than your defined SLA triggers a review. Flags older than 90 days for release flags is a reasonable threshold.
Assign ownership. Every flag should have a team or person responsible for retiring it. Flags without owners accumulate forever.
The CI/CD pipeline is the right place to enforce flag hygiene: lint for old flags, fail builds on undefined flags, and automate the retirement PR when a flag is removed from the service.
Testing with Feature Flags
Testing gets more complex with feature flags because your code has multiple valid code paths. The naive approach is to run your test suite twice: once with the flag on, once with the flag off. This doubles test time.
Better approach: unit test each flag variant in isolation. Test the new code path with the flag mocked to true, the old code path with it mocked to false. Integration tests and end-to-end tests run against specific flag configurations (usually “flags in the released state”).
Many flag SDKs have test-friendly APIs that let you override flags in tests without hitting the flag service:
# In tests, override flag values without network calls
with feature_flags.override({'new-checkout-flow': True}):
result = checkout_service.process(cart)
assert result.status == 'success'
The hardest testing challenge is flags that affect infrastructure behavior rather than application behavior: a flag that switches your database connection pool implementation, or changes your caching strategy. These need integration tests that verify both paths work under realistic conditions.
Connecting to Your Observability Stack
Progressive delivery only works if you can tell whether the rollout is healthy. This requires connecting your flag system to your observability stack.
Every request that evaluates a flag should emit a trace attribute or log tag indicating which variation was evaluated. This lets you split your metrics by flag variation in your observability platform: “P99 latency for users in new-checkout-flow=true vs. false”, “error rate for users in new-checkout-flow=true vs. false”.
OpenTelemetry is the right integration point here. The OpenFeature SDK hooks emit span attributes for flag evaluations. Wire these into your existing OTel pipeline and you get flag-variation-aware traces and metrics automatically.
Set up pre-built dashboards for monitoring rollouts before you start using progressive delivery for risky changes. You should be able to pull up the “new-checkout-flow rollout health” view in under 30 seconds when you’re staring at an alert at 2am.
Feature flags and progressive delivery are now considered standard engineering practice at companies that take deployment safety seriously. The investment in tooling and discipline pays off every time you catch a regression at 1% exposure rather than at 100%, and every time a product manager can safely experiment without dragging engineers into a deployment for every A/B test. Get the foundation right, retire your flags diligently, and progressive delivery becomes one of the most powerful levers you have for moving fast without breaking things.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.