I have built IAM systems for over twenty years. I have watched the same story play out at company after company: engineers start with something simple, a boolean isAdmin flag, graduate to roles, build a roles table, add a permissions table, create a junction table, add a tenant column, add a resource column, and eventually end up with a 47-table authorization schema that nobody fully understands and that takes 400 milliseconds to answer “can this user see this document.” At that point someone proposes a rewrite, and the cycle begins again.
The reason this keeps happening is that most authorization models are fundamentally the wrong shape for the problem. Google figured this out at scale and published their solution in 2019. That paper, describing a system called Zanzibar, changed how serious engineers think about authorization. What came out of it is now available to anyone, and if your authorization logic is getting complicated, you need to understand it.
The Problem with RBAC at Scale
Role-based access control works beautifully when your access patterns are simple and uniform. Every user has a role, every role has permissions, done. The classic admin/editor/viewer setup takes an afternoon to implement and years before it hurts you.
When it starts hurting you is the moment your authorization logic needs to reflect the structure of your data. Not “is this user an editor” but “is this user an editor on THIS document, in THIS workspace, shared BY someone who themselves has edit access on the parent folder.”
That is a graph traversal problem, and flat RBAC tables are not a graph.
I once worked with a collaboration platform, think Google Docs-like sharing semantics, that had built their authorization on top of a PostgreSQL roles table. By the time I got involved, their permission checks were joining seven tables, and they had a dedicated cache warming job that ran every five minutes to pre-compute common checks. The cache was frequently stale because the sharing model was complex enough that invalidating it correctly was itself a solved-incorrectly problem. Users would share documents and then spend the next few minutes watching their collaborators get access denied errors. The engineering team had spent eighteen months iterating on this. The root cause was not their implementation; it was their data model.
Understanding the difference between authentication and authorization is step one. Understanding that authorization itself has multiple fundamentally different models is step two.
Three Models: RBAC, ABAC, and ReBAC
Role-Based Access Control (RBAC) grants access based on roles assigned to a user. You are an admin, so you can delete things. Simple, fast, easy to audit. Falls apart when the same action on different objects requires different permissions based on ownership or organizational hierarchy.
Attribute-Based Access Control (ABAC) makes decisions based on attributes of the subject, object, and environment. You can edit a document if your department matches the document’s department AND the document is in draft status AND it is business hours. Extremely expressive, extremely hard to debug, and performance can get ugly when you are evaluating complex policies at every request. OPA and Cedar live in this world. Policy as code tools like OPA and Kyverno implement ABAC patterns for infrastructure, and they work well for that use case. For application-level authorization with dynamic relationship data, they can become awkward.
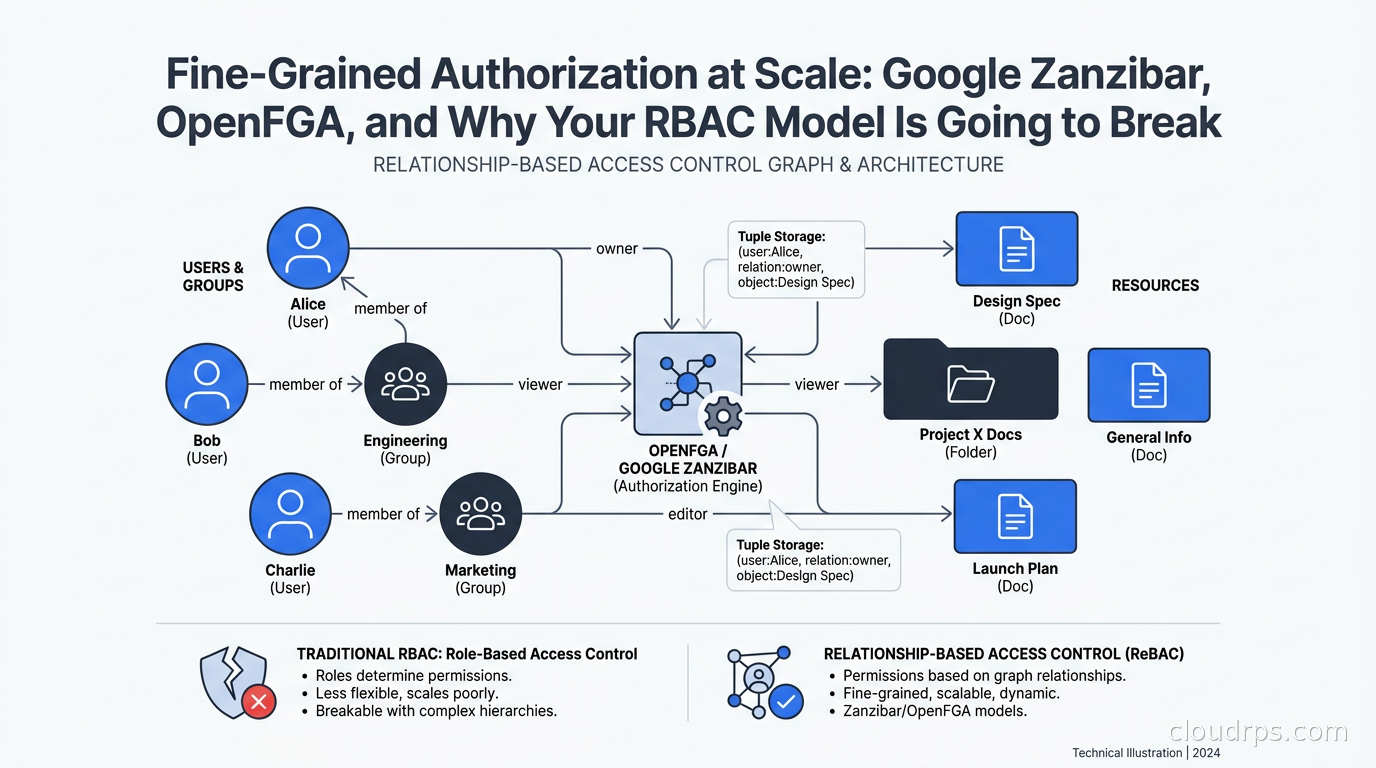
Relationship-Based Access Control (ReBAC) models access as a graph of relationships between entities. “User Alice has the role editor on Document X” is a relationship tuple. “Folder Y contains Document X” is another relationship tuple. The authorization engine traverses this graph to answer questions. This is the Zanzibar model, and it handles the document-sharing problem elegantly because it was specifically designed for it.
Google Zanzibar: The Paper That Changed Authorization
Google published “Zanzibar: Google’s Consistent, Global Authorization System” at USENIX ATC 2019. The paper describes the system that powers Google Drive, YouTube, Maps, Calendar, Cloud, and essentially everything at Google that needs to ask “can user X do action Y on resource Z.”
The numbers in the paper are staggering: 10 billion tuples, trillions of ACL checks per day, 95th-percentile latency under 10 milliseconds. What is interesting is not the scale but the model they used to achieve it.
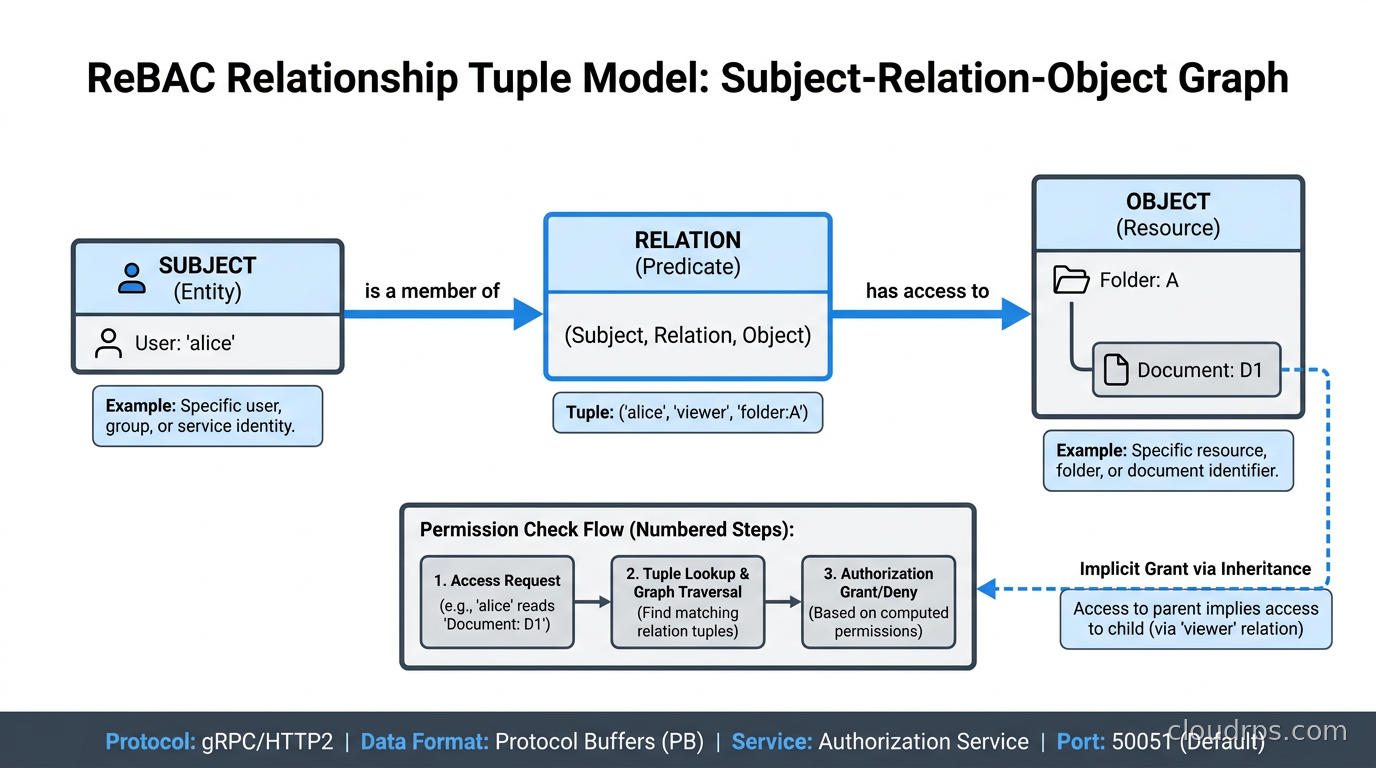
The core primitive is the relationship tuple: object#relation@user. Examples:
document:doc1#viewer@user:alice- Alice is a viewer of doc1document:doc1#viewer@group:eng#member- all members of the eng group are viewers of doc1folder:folder1#parent@document:doc1- doc1 is in folder1
Authorization checks resolve against these tuples using a type system that defines what relations exist on what object types and how they compose. The genius is the userset concept: you can say “viewers of a document include all viewers of its parent folder,” and the system handles the traversal.
Zanzibar also introduced the zookie (authorization consistency token) to solve the new enemy problem: if Alice shares a document with Bob and Bob immediately tries to access it, the check should see the new tuple even if it was just written milliseconds ago. Zookies bind a read to a specific version of the permission store, giving you consistency without always paying for strong reads.
OpenFGA: Zanzibar for Everyone
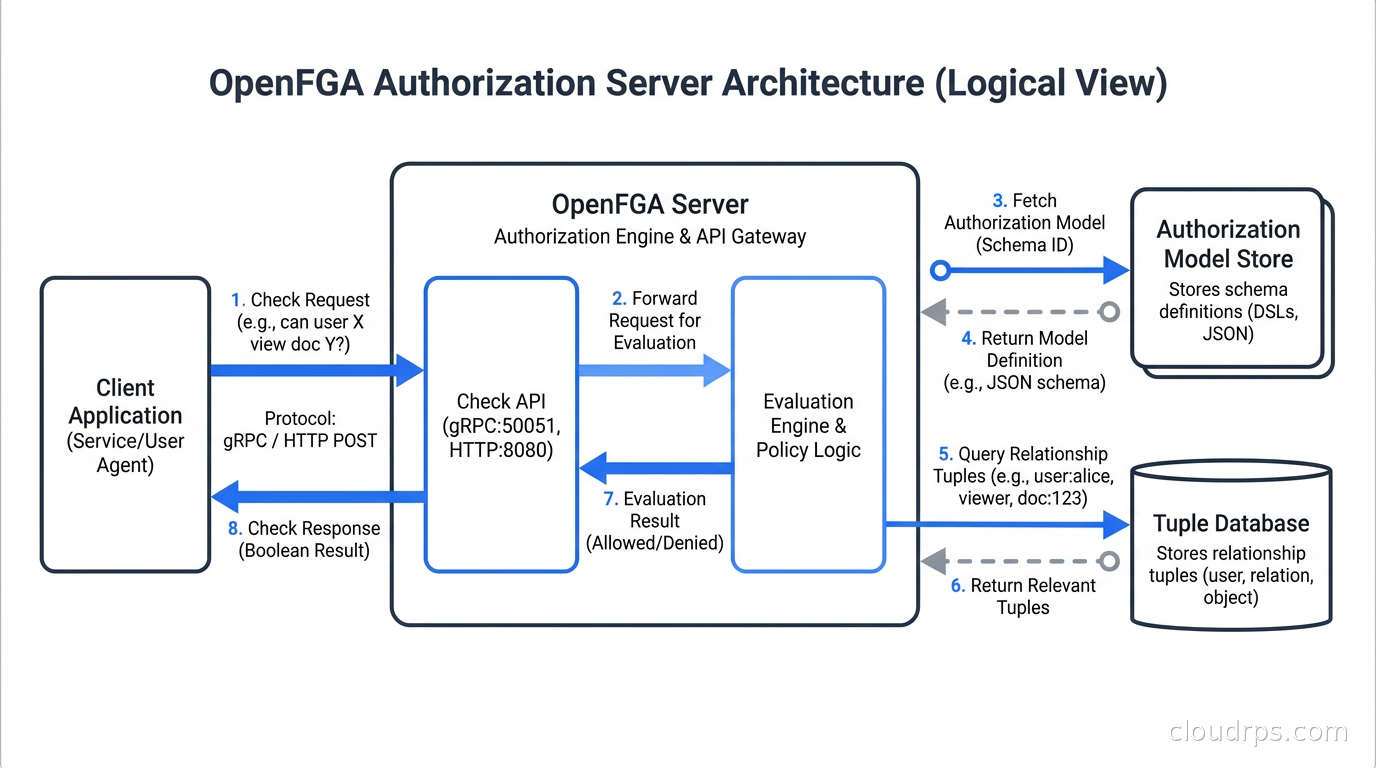
Google did not open source Zanzibar, but Auth0 built an open-source implementation they called Fine-Grained Authorization, or OpenFGA. It is now a CNCF sandbox project and the most widely deployed Zanzibar-inspired system outside of Google.
OpenFGA gives you:
- A gRPC and HTTP API for writing tuples and checking authorization
- A type system called the Authorization Model that you define in a DSL
- A read API for listing what objects a user can access (useful for filtering UI)
- A changes API for streaming tuple changes
- Backends for PostgreSQL, MySQL, and an in-memory store for testing
Here is a simple Authorization Model in the OpenFGA DSL for a document management system:
model
schema 1.1
type user
type document
relations
define owner: [user]
define editor: [user] or owner
define viewer: [user] or editor
define parent: [folder]
define can_view: viewer or viewer from parent
define can_edit: editor or editor from parent
type folder
relations
define owner: [user]
define editor: [user] or owner
define viewer: [user] or editor
define parent: [folder]
That model captures the “inherits from parent folder” logic in three words: viewer from parent. Writing the equivalent in SQL takes a recursive CTE and a lot of prayer.
To check if Alice can view doc1, you send:
{
"tuple_key": {
"user": "user:alice",
"relation": "can_view",
"object": "document:doc1"
}
}
OpenFGA traverses the graph, checking direct assignments, group memberships, and inherited relations from parent folders, and returns allowed: true or allowed: false. Sub-100-millisecond in most deployments with a warm cache.
SpiceDB, Permify, and the Ecosystem
OpenFGA is not the only option. The Zanzibar ecosystem has matured considerably.
SpiceDB from Authzed is the other major open-source Zanzibar implementation. It uses a schema language called Zed and has a strong story around its Kubernetes operator and enterprise support. SpiceDB tends to be more opinionated about consistency and has a more sophisticated caching model. If you are starting fresh and want production-grade support, SpiceDB is a legitimate choice. The company offers AuthZed, a managed version, which removes operational burden.
Permify is a newer entrant with a developer-friendly experience and good REST API ergonomics. They have invested heavily in the schema playground and documentation. For teams that want to evaluate the concept quickly without deep Kubernetes integration, Permify is worth looking at.
AWS Verified Permissions is Amazon’s managed implementation based on the Cedar policy language. If you are all-in on AWS and want a fully managed service with IAM integration, this is worth evaluating. Cedar is ABAC rather than pure Zanzibar ReBAC, but it handles most of the same use cases with a different modeling approach.
Warrant (now part of WorkOS) and Cerbos round out the ecosystem. Cerbos takes a different approach, processing policies as YAML files in a sidecar, which some teams find more familiar.
My honest take: if you are building something new and you want the full Zanzibar model with open-source flexibility, OpenFGA is the most mature choice with the strongest community. If you need managed infrastructure and want to stay on AWS, Verified Permissions is worth the investigation. SpiceDB is excellent if you want commercial support for open-source.
Modeling Your Authorization Schema (The Hard Part)
The technical implementation is the easy part. Authorization modeling is the hard part, and getting it wrong is expensive because migrations of authorization schemas are painful.
The most common mistake I see is trying to mirror your database schema directly in your authorization model. Just because you have a workspace_members table does not mean you should model workspace membership as a tuple. Think instead about the semantic relationships: ownership, membership, inheritance.
Start with the questions you need to answer, not the data you have. “Can user X edit resource Y?” and “What resources can user X see?” are the primary queries. Work backwards from those to the relationships you need to store.
Second mistake: over-normalizing. Some teams try to remove all redundancy from their tuple store. The tuple store is not a relational database; it is an adjacency list optimized for graph traversal. Denormalization is fine and sometimes necessary for performance.
Third mistake: trying to move ALL authorization logic into the FGA system. Coarse-grained, non-relational decisions (“is this user an admin”) work fine in your IdP or a simple role table. Move the relational authorization into the FGA system. Mixing the two in the right way keeps the FGA model clean.
When you need to implement zero trust principles at the application layer, fine-grained authorization is a core component. Zero trust requires authorization decisions at every request, and those decisions need to reflect the actual structure of your data.
Integration Patterns
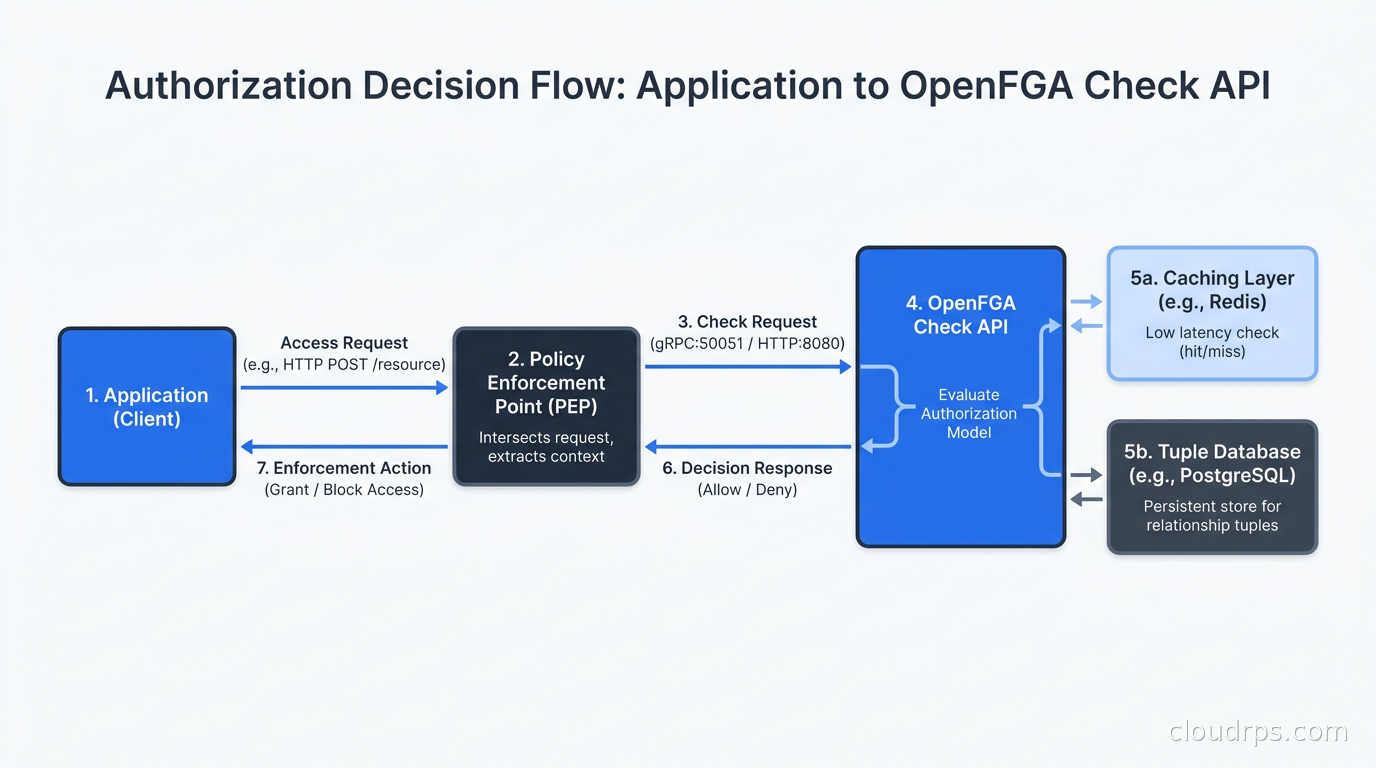
There are three main ways to integrate an authorization service:
SDK integration: Call the authorization API directly from your application code at decision points. The simplest approach. OpenFGA has SDKs for Go, Python, JavaScript, Java, .NET, and PHP. You make a check call and branch on the result. Works well for most applications.
Middleware/sidecar: Put authorization enforcement in a middleware layer or sidecar so your application code does not have to make explicit calls. Cerbos and some Envoy configurations support this. Appealing from a separation-of-concerns perspective, but it can be tricky to pass the right context (the object being accessed) from the network layer into the authorization decision.
PEP/PDP pattern: Policy Enforcement Point in your application, Policy Decision Point as a separate service. The formal XACML pattern. More commonly seen in enterprise contexts. OpenFGA and SpiceDB both work as PDPs.
The API gateway is a natural enforcement point for coarse-grained checks (is the user authenticated, is the API key valid), but fine-grained authorization typically requires application-level enforcement because the gateway does not have the business context to evaluate “can this user edit this specific document.”
One integration decision worth getting right early: where does tuple synchronization happen? Your application has state (user creates a document, shares it, adds someone to a team), and that state needs to be reflected in the tuple store. Two patterns work: write tuples synchronously as part of your application’s mutations, or publish events and have an async consumer sync tuples. The synchronous approach is simpler and ensures consistency. Async is more resilient to authorization service outages but introduces lag and requires careful handling of the consistency window.
Performance Considerations
The “lists” operations, meaning “what objects can user X access,” are the expensive ones. A check (“can user X access object Y”) is a point lookup with graph traversal that typically resolves in one or a few round trips to the tuple store. A list (“all documents user X can view”) requires traversing the entire reachable subgraph.
OpenFGA handles lists with a streaming response and a continuation token model. At scale, you need to index your tuples carefully. The out-of-the-box schema for most FGA systems works fine up to tens of millions of tuples. Beyond that, you need to think about partition strategies, caching, and whether you want to pre-compute certain common traversals.
Caching is critical. OpenFGA has a built-in cache for the check API, configurable with a TTL. For most applications, 30-second to 5-minute cache TTLs on check results are acceptable and dramatically reduce database load. The tradeoff is a consistency window: if Alice removes Bob’s access, Bob might still pass checks for up to the cache TTL.
The zookie concept from Zanzibar helps here. If you need strong consistency after a write (the new enemy problem), you can pass a consistency token with your checks. Most applications do not need this and can tolerate eventual consistency.
For workload identity scenarios where services need to authorize other services, FGA works but the token passing can be complex. In practice, I separate workload-to-workload authorization (use SPIFFE/SPIRE with mTLS and attribute checks) from user-to-resource authorization (use FGA). Trying to model everything in one system creates unnecessary coupling.
When to Actually Use This
Fine-grained authorization is not for every application. Here is when you actually need it:
Use it when your access control logic reflects relationships between entities (documents in folders, users in organizations, resources owned by tenants), you have more than two or three levels of permission inheritance, you need to answer “list all resources user X can see” efficiently, or you are building a collaboration product with sharing semantics.
Do not use it when your application has a simple admin/member/viewer model that does not need inheritance, your access decisions are purely attribute-based without relational traversal, or you have fewer than ten thousand users and the complexity is not yet warranted. I have seen teams introduce OpenFGA into a five-person startup’s application and spend three weeks on the authorization model when a roles table would have been fine for another three years.
When you ARE working on securing AI agents in production, fine-grained authorization becomes increasingly important. AI agents that can act on behalf of users need authorization checks that respect the user’s actual permissions, not just the agent’s. An agent should not be able to read documents the user cannot read. Modeling this correctly in a FGA system, where the agent acts as the user and relationships are enforced by the authorization service, is much cleaner than trying to thread permission checks through prompt engineering.
Running OpenFGA in Production
OpenFGA ships as a single Go binary. For production, you need:
- A PostgreSQL or MySQL database for the tuple store
- Horizontal scaling behind a load balancer (stateless)
- A cache layer, which OpenFGA provides built-in as a write-through layer
- HTTPS/TLS for the API
- A pre-shared key or OIDC configuration for API authentication
The Helm chart is well-maintained and the deployment is straightforward. Kubernetes resource requirements are modest for most workloads: 256MB memory and half a CPU core per replica is a starting point.
One operational consideration: the authorization model store. You define models per store, and model changes are additive. You cannot remove a relation from a model and expect it to break existing code gracefully; old code still uses the old model ID. This is the right behavior (you do not want a model deployment to break running services), but it means you need a deliberate migration strategy when you evolve your authorization model. Plan for this before you go to production.
Monitoring matters. Instrument your check and write latency, your tuple store growth rate, and your cache hit rate. If cache hit rate drops suddenly, something changed in your access patterns and you should understand why.
The Migration Path
If you have an existing RBAC system and are considering migrating to FGA, do not do it all at once. The path that works:
- Stand up OpenFGA alongside your existing system.
- Start writing tuples for new resources as they are created, without reading from FGA yet.
- Once tuples are populated for a resource type, shadow-check: make the old authorization decision AND the FGA check, log any discrepancies, but serve the old result.
- Resolve discrepancies, which are usually either modeling bugs in the FGA schema or gaps in your tuple sync logic.
- Flip to serving the FGA result for that resource type.
- Repeat for each resource type.
This takes longer than a flag day migration but it is far safer. I have seen organizations run shadow mode for three months to build confidence before cutting over. The discrepancy logs are valuable: they reveal edge cases in your existing access control logic that you may not have even known about.
The zero-downtime migration patterns that work for databases apply to authorization migrations too. Dual-write, verify, cutover is the safe path regardless of what system you are migrating.
Zanzibar Becomes the Standard
Three years after the OpenFGA launch, Zanzibar-inspired authorization is becoming the default approach for anyone building a multi-tenant SaaS product with complex sharing semantics. The days of reinventing a custom authorization schema per application are numbered. The tooling has matured enough that the question is no longer “should I use a dedicated authorization service” but “which one, and what should my model look like.”
The problems are real: teams that build custom RBAC systems spend disproportionate engineering time on authorization edge cases that should be a solved problem. Fine-grained authorization services let you separate the policy model from the enforcement logic, query across your permission graph efficiently, and audit exactly who can access what and why.
If your application is showing the signs, complex permission queries, a growing authorization table schema, mysterious access bugs after sharing actions, then the time to migrate is before the complexity gets worse. The schema modeling is still hard work, but at least you are building on a foundation designed for the problem.
For a broader look at how identity and access control fit into modern cloud security, see our guides on authentication versus authorization fundamentals and Kubernetes RBAC for container workloads.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.