Every time you invoke an AWS Lambda function, a virtual machine boots in about 125 milliseconds. Not a container, not a process: a full virtual machine with its own kernel, its own network stack, its own filesystem. You almost certainly have never thought about this, and that is exactly the point.
I have been building cloud infrastructure for twenty years, and when Amazon open-sourced Firecracker in 2018, I spent an entire weekend reading through the source code and design documents. Understanding what actually runs your workloads is not trivia; it is the foundation of security reasoning, cold-start optimization, and informed vendor selection. If you are treating Lambda as a black box, you are flying blind on some of the most important tradeoffs in your architecture.
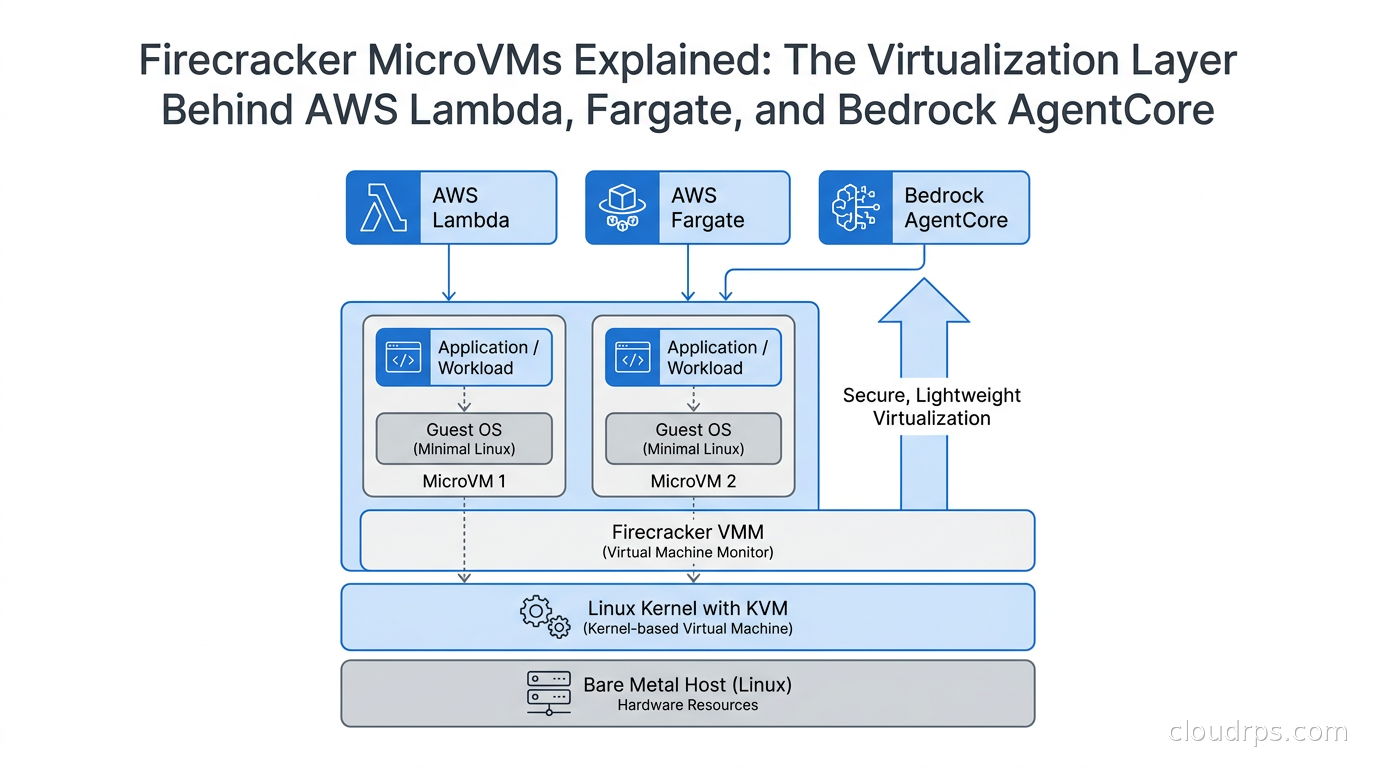
Firecracker is the reason AWS can offer multi-tenant serverless computing that is both genuinely fast and genuinely secure. It is also now powering AWS Bedrock AgentCore Runtime, meaning AI agents run inside Firecracker microVMs. This article explains what Firecracker is, how it works under the hood, and why the details matter to you as a cloud architect.
The Multi-Tenancy Problem That Spawned Firecracker
Before getting to Firecracker, we need to understand the problem it was designed to solve.
When AWS launched Lambda in 2014, the fundamental engineering challenge was this: how do you run arbitrary customer code from thousands of different customers on the same physical server, without letting any customer affect any other customer? The answer needed to work at massive scale, at millisecond latency, and at a price point people would actually pay.
The two obvious options each had fatal flaws.
Containers are fast and lightweight, but they share the host kernel. This is both their strength and their weakness. A container escape, whether through a kernel vulnerability or a misconfigured syscall, puts an attacker directly on the host with access to every other container on that machine. At the scale AWS operates, this is not an acceptable risk. For internal workloads running your own code you might accept this tradeoff, but when strangers are submitting arbitrary code to execute on shared hardware, container-only isolation falls short. I covered the depth of this risk in detail in the container runtime security article; the short version is that containers are a process isolation mechanism dressed up as a security boundary, and they were never designed to be the latter.
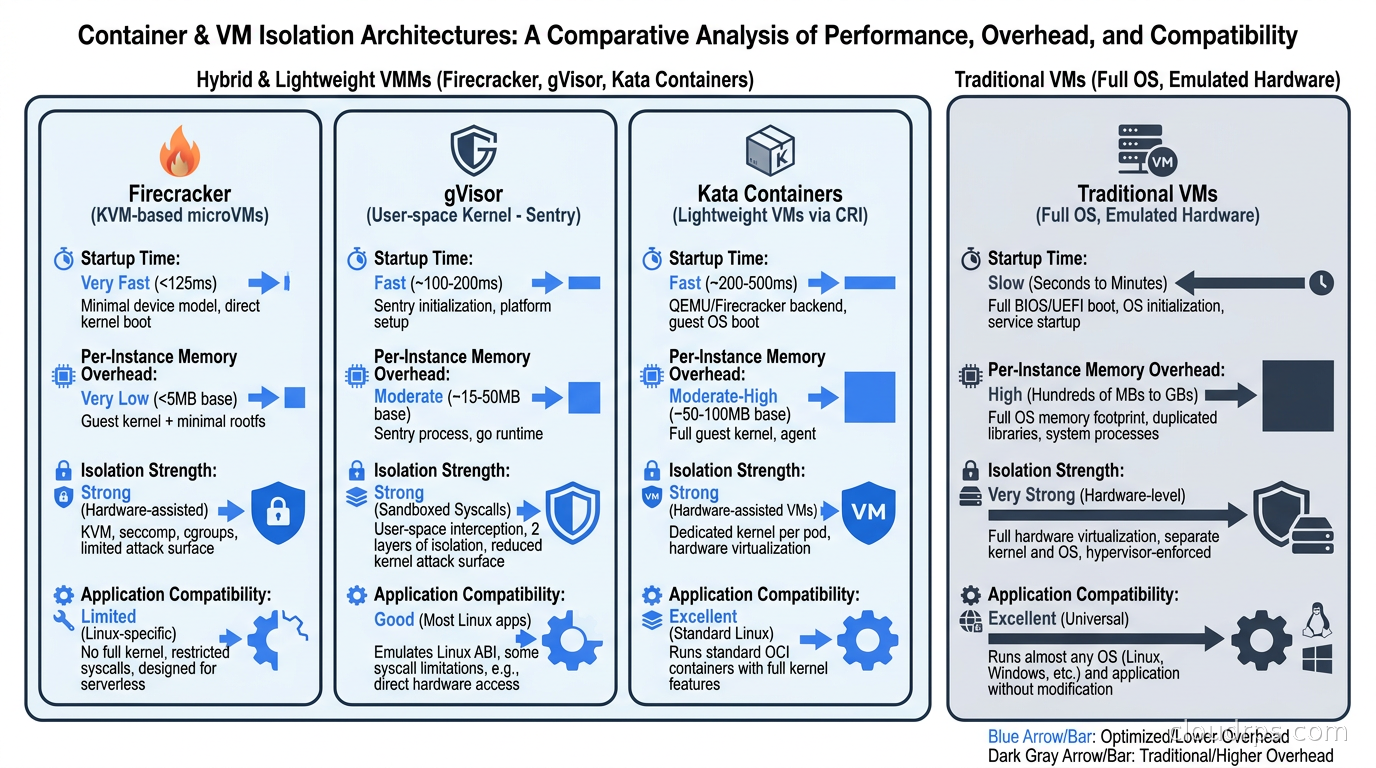
Traditional virtual machines give you genuine kernel-level isolation because each VM has its own kernel. If someone escapes their container, they are still inside their VM, not on the host. The problem is that traditional VMs are heavy. A standard Linux VM might take 30 to 60 seconds to boot, consume 200 to 500 MB of memory just for the guest OS, and require significant CPU overhead from the hypervisor. As I explained in the virtualization and hypervisors article, platforms like QEMU/KVM and VMware were designed for long-running workloads, not for ephemeral functions that need to start in milliseconds.
Lambda needed something in between: the security isolation of a VM with the startup speed and density of a container. That is Firecracker.
What Firecracker Actually Is
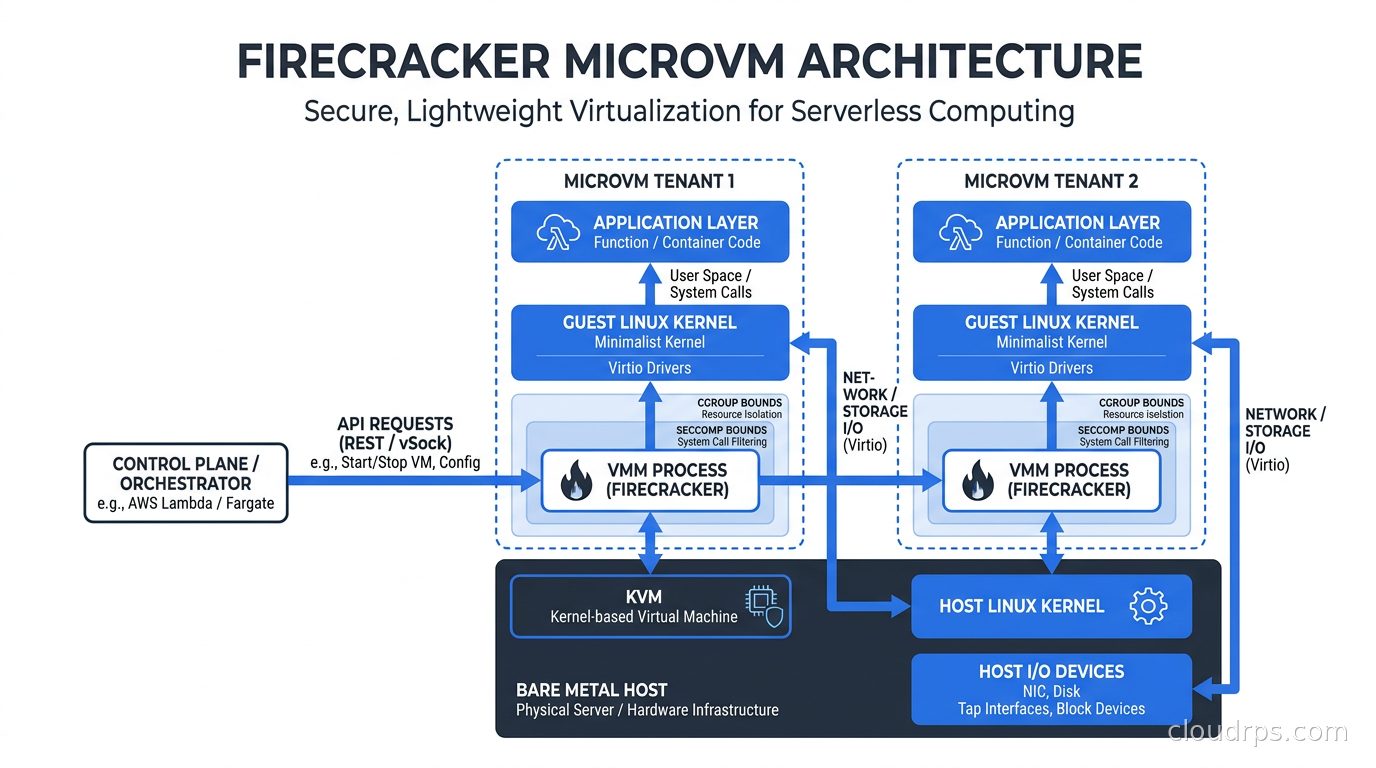
Firecracker is an open-source Virtual Machine Monitor (VMM) written in Rust, built by Amazon, and open-sourced in November 2018. It uses the Linux Kernel Virtual Machine (KVM) interface to create and run what AWS calls microVMs.
The key design insight is radical minimalism. A traditional VMM like QEMU emulates hundreds of devices: PCI buses, USB controllers, BIOS firmware, sound cards, graphics adapters, and more. All of that emulation takes time and memory, and most of it is completely irrelevant to running a serverless function. Firecracker strips the device model down to the absolute minimum required to boot a Linux kernel and run user code.
A Firecracker microVM exposes exactly four things to its guest:
- A virtio network device for networking
- A virtio block device for storage
- A serial port for console output
- A minimal ACPI subsystem for power management
That is it. No PCI bus. No USB. No unnecessary legacy hardware emulation. This minimal attack surface is not just a performance optimization; it is a deliberate security decision. Every device you emulate is code that can contain vulnerabilities. Fewer devices means fewer bugs, and fewer bugs means fewer ways for a motivated attacker to escape the VM boundary.
The results from this minimalism are remarkable. A Firecracker microVM boots in approximately 125 milliseconds. Memory overhead per microVM sits below 5 MiB. A single host can provision up to 150 new microVMs per second. These numbers make it feasible to provision a fresh virtual machine for every function invocation at a cost that can be passed on to customers at a price they will actually pay.
The Jailer: Defense in Depth
Firecracker by itself is a VMM process running on a Linux host. To prevent the Firecracker process itself from being a liability if it gets compromised, AWS wraps each VMM instance in what they call the Jailer.
The Jailer applies multiple containment layers before the microVM starts:
cgroups limit CPU and memory usage. A compromised microVM cannot monopolize host resources and affect neighbors.
Linux namespaces give each Firecracker process its own mount namespace, network namespace, and PID namespace. The process cannot see the host filesystem, network interfaces, or other processes.
seccomp filters apply a strict allowlist of system calls. Firecracker needs maybe 50 specific syscalls to do its job. Anything outside that list kills the process. This is the same layered approach used in container runtime security with tools like Falco and AppArmor, but applied to the hypervisor process itself rather than the containers it runs.
chroot restricts filesystem access to a minimal directory, preventing the Firecracker process from traversing the host filesystem even if it somehow escaped the namespace.
You end up with layered containment: the application runs inside a microVM guest, the guest is isolated from the host by KVM hardware virtualization, the Firecracker VMM process is isolated by namespaces and chroot, and the process syscall surface is restricted by seccomp. Breaking through all of those independent layers simultaneously is an extraordinarily hard problem, which is why Firecracker’s security record over seven-plus years has been strong.
How AWS Lambda Uses Firecracker
Understanding Firecracker’s architecture is one thing. Understanding how Lambda actually uses it in practice reveals some clever engineering that explains Lambda’s performance characteristics and why the advice “put expensive initialization outside your handler” actually works.
When a Lambda function is invoked for the first time (a cold start), the following sequence occurs:
- Lambda’s Worker Manager identifies a physical host with spare capacity.
- The Worker Manager instructs Firecracker to boot a new microVM on that host.
- The Lambda execution environment initializes inside the microVM: this is your Init phase, where Python imports happen, database connections are established, and ML models are loaded.
- Your handler function runs and returns a response.
- The microVM does not terminate. Lambda suspends the execution environment and marks it warm.
If the same function is invoked again within a short window, Lambda reuses that same microVM. Your Init code ran once; the handler runs again, much faster. This is the fundamental mechanism behind Lambda’s warm start behavior, and it is implemented at the microVM level, not at the container level. The execution environment is genuinely frozen and thawed, not spun up fresh.
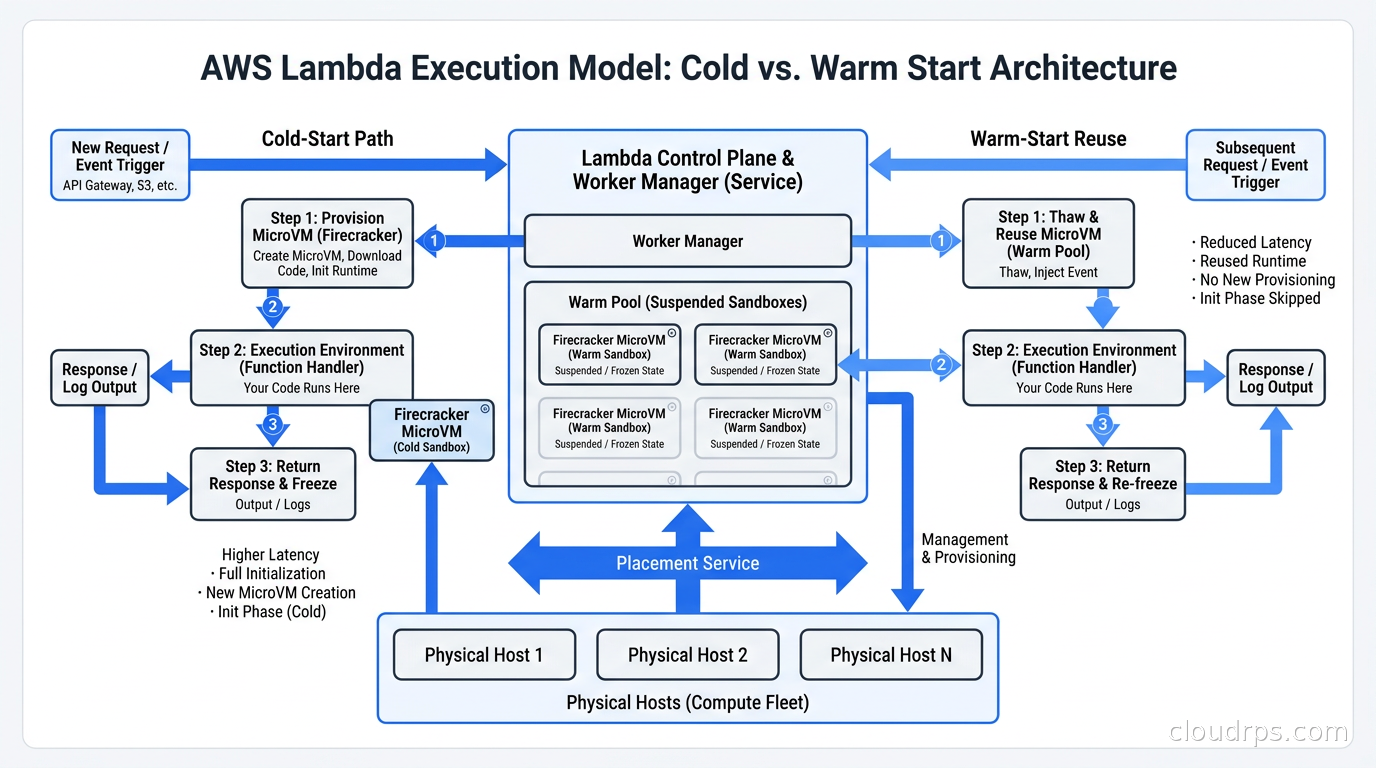
The cold start time you hear Lambda users complain about breaks down into components: provisioning the microVM (roughly 125ms, essentially fixed), initializing the Lambda runtime (varies by language), running your Init code (entirely under your control), and invoking your handler. Firecracker makes the first component negligible. The rest is your problem to optimize.
AWS also uses memory snapshotting to further speed up cold starts for managed runtimes. A snapshot of a microVM with a Python 3.12 runtime already initialized can be restored much faster than booting and initializing from scratch. This is conceptually similar to VM live migration in traditional virtualization, but applied to startup optimization rather than mobility. It is one reason why Lambda’s managed runtimes tend to have faster cold starts than container images you provide yourself.
For a clearer picture of how Lambda maps to physical infrastructure, I covered what EC2, EBS, EFS, and Lambda actually are at the hardware level, which gives useful context for where Firecracker fits in the resource stack.
AWS Fargate and the Shift to Firecracker
Fargate’s evolution is instructive. The original Fargate used a modified Linux container model with enhanced isolation. It was more isolated than standard Docker containers, but it was not full VM isolation. Kernel vulnerabilities on the shared host were a potential concern.
In 2023, AWS moved Fargate Tasks to run on Firecracker microVMs. The migration was largely invisible to users (AWS rarely announces infrastructure changes that do not affect the API surface), but it materially improved the security posture of Fargate workloads.
The engineering tradeoff was a slight increase in cold start latency for container startup, since provisioning a microVM takes marginally longer than spinning up a container. The security benefit, genuine kernel-level isolation between tenants with different customer accounts, was judged worth it. For teams running regulated workloads or processing sensitive customer data on Fargate, this migration was significant even if they never heard about it.
The Fargate migration also validated Firecracker’s operational maturity. Running tens of thousands of microVM provisions per second across Lambda and Fargate is not a small-scale experiment. When AWS bets two of its flagship compute services on a piece of technology and it works reliably for years, that is a stronger endorsement than any benchmark.
Bedrock AgentCore: Firecracker for AI Agents
The most recent expansion of Firecracker’s role is AWS Bedrock AgentCore Runtime, announced at re:Invent 2024 and going GA in 2025.
When an AI agent uses a Code Interpreter or Browser tool through AgentCore, AWS provisions a dedicated Firecracker microVM for that entire session. The isolation model is strict: one session, one microVM. The microVM persists for the session duration (up to 8 hours), executes all operations the agent requests, and is completely destroyed when the session ends. No filesystem artifacts, memory contents, or execution state survive between sessions.
This design is exactly right for what AI agents do. An agent using a Code Interpreter might execute arbitrary Python, install packages, read and write files, make network requests, and interact with external APIs. Allowing that activity in a shared environment with other users’ agent sessions would be indefensible. The production AI agent architectures people are building today require strong isolation guarantees, and Firecracker provides them without requiring the platform team to build a custom isolation layer.
The cold start for an AgentCore session is typically 2 to 5 seconds on first invocation, longer than a Lambda cold start because the execution environment is larger and more capable. Within the session, subsequent operations are fast. This is a reasonable tradeoff given what you get: a sandboxed execution environment for arbitrary agent-generated code that provides VM-level isolation between every customer’s sessions.
The pattern is worth internalizing as AI workloads mature: the more capable and autonomous your agents become, the more important the isolation substrate underneath them becomes. Firecracker was the right answer for Lambda in 2018, and it turns out to be the right answer for AI agents in 2025.
Firecracker vs. gVisor vs. Kata Containers
Firecracker is not the only approach to the problem of secure multi-tenant compute isolation. Comparing alternatives clarifies when each is the right choice.
gVisor (used by Google Cloud Run) takes a different approach entirely. Rather than running a real kernel inside a VM, gVisor implements a user-space kernel written in Go (called Sentry) that intercepts system calls and reimplements them in user space. The guest application believes it is talking to a normal Linux kernel, but it is actually talking to Sentry, which makes a restricted set of host kernel calls on its behalf. The host attack surface is dramatically reduced because the guest cannot make arbitrary kernel syscalls directly. The downsides are that not every syscall is implemented (obscure applications may not work), and syscall-heavy workloads run slower due to interpretation overhead.
Kata Containers is architecturally closest to Firecracker. Kata also uses hardware virtualization to run containers inside lightweight VMs, providing kernel-level isolation while integrating with standard container tooling like Docker and Kubernetes. Traditional Kata used QEMU as its VMM, which is heavier. Modern Kata supports Firecracker directly as a runtime, making the line blurry. Kata’s value proposition is fitting into existing container workflows (Kubernetes deployments work without modification) while getting stronger isolation than standard runtimes provide.
The practical guidance for cloud architects:
If you are running Lambda, Fargate, or Cloud Run: the platform handles isolation for you. Know what you are getting, but you do not need to configure anything.
If you are building a self-managed multi-tenant compute platform (an internal FaaS, a hosted execution environment, a platform where customers run code), Kata with Firecracker is the current best practice for strong isolation without abandoning Kubernetes tooling. Standard containers are not enough for this use case. For a detailed walkthrough of deploying gVisor and Kata Containers in Kubernetes using RuntimeClass, including production architecture patterns and the gVisor-vs-Kata decision framework, see the Kubernetes sandbox isolation guide.
If you need Kubernetes workloads with stronger isolation than containers but your applications are compatible with gVisor’s syscall coverage, Cloud Run or Knative with gVisor is a viable option.
If you are comparing managed serverless containers, I covered the platform differences in depth in the serverless containers vs Kubernetes article, including isolation as one of the evaluation axes.
Building Directly on Firecracker
Outside AWS, Firecracker has been adopted as the compute foundation by several cloud platforms.
Fly.io built their entire compute platform on Firecracker. Every application deployed to Fly runs in a Firecracker microVM. This was a deliberate architectural choice: strong tenant isolation without the weight of a traditional hypervisor. Fly’s published boot time numbers are consistently in the 200 to 500ms range for application startup, of which the microVM provision is a small fraction.
If you are building an internal platform that needs to run untrusted or semi-trusted code (customer-provided scripts, sandboxed CI jobs, third-party plugins), Firecracker is production-ready and well documented. The API is clean: configure a microVM (vCPU count, memory size, kernel image, root filesystem, network interface), start it via a REST API on a Unix socket, and it is running. Orchestrating fleets of Firecracker microVMs at scale requires building the control plane that AWS has already built, but the VMM itself is a solved problem.
One important infrastructure note: Firecracker requires hardware with KVM support. This means bare metal hosts, or VMs with nested virtualization enabled. As I discussed in the bare metal cloud article, AWS’s bare metal instance types (c5.metal, m5.metal, and similar) are specifically designed to expose KVM to the tenant, which is why they are popular for running Firecracker directly and for nested virtualization use cases.
Security Implications for Your Architecture
For most teams using managed AWS services, the security takeaway is that the isolation model is significantly stronger than the word “serverless” might imply. Lambda and Fargate workloads run in hardware-isolated microVMs with their own kernels. A neighboring tenant’s function cannot directly affect yours through a kernel exploit or shared-memory attack the way they theoretically could in a purely container-based model.
This matters for compliance conversations. When a security auditor asks about your serverless isolation model, “each invocation runs in a dedicated hardware-isolated microVM using KVM virtualization, bounded by seccomp and cgroup controls” is a materially different answer than “containers with namespace isolation.” For workloads where data residency and tenant separation are compliance requirements, understanding the actual isolation substrate is not optional.
For teams building their own multi-tenant platforms, Firecracker raises the bar on what secure shared compute means. The standard “we isolate our customers with containers and network policies” answer is not adequate for high-risk workloads. Firecracker-grade isolation should be the floor, not an aspirational goal.
Confidential computing with hardware TEEs goes even further, protecting data in use from the hypervisor and cloud provider. But Firecracker is the more practical starting point for teams that need strong isolation without the compatibility constraints of SGX or AMD SEV workloads.
What Changes When You Know This
Understanding Firecracker changes how you reason about several concrete decisions:
Cold start optimization. The 125ms microVM provision time is essentially fixed; you cannot optimize it away. The variable cost is your Init code: library imports, connection establishment, model loading. This is where your engineering time should go. Lazy imports, connection pooling, and pre-loading models as Lambda extensions all address the controllable portion of cold start.
Function memory sizing. Lambda’s memory allocation affects more than available memory. CPU allocation scales proportionally with memory. Running microVMs at 128MB is extremely tight and often slower in wall-clock time than running at 512MB or 1GB, because the faster execution can offset the higher per-GB-second price. Profile before you pick a size.
Multi-tenancy design decisions. If you need to run customer-provided code in your platform, Firecracker-based services give you strong isolation without building your own security layer. Reach for Lambda or a Firecracker-based platform before you build a custom sandboxing solution. The isolation you get from these services is better than most engineering teams would build on their own in a reasonable timeframe.
Vendor comparisons. Google Cloud Run uses gVisor. Azure Container Apps uses container-based isolation for most tiers. When comparing serverless platforms, the isolation model is a legitimate technical differentiator, particularly for workloads with strong security or compliance requirements.
Conclusion
Firecracker is one of the more elegant pieces of systems engineering to come out of the cloud era. The core insight, that you can strip a VMM to its absolute minimum and get VM-grade isolation at container-grade performance, was not obvious. It required deep systems expertise and the willingness to throw away decades of accumulated QEMU complexity.
For most engineers, Firecracker is invisible. You write a Lambda function, deploy it, and it works. But knowing that your function runs inside a hardware-isolated microVM with its own kernel, bounded by cgroups and seccomp, gives you a fundamentally more accurate mental model of what you are building on.
That accurate mental model matters when you are designing multi-tenant systems, evaluating the security posture of cloud services, or explaining to a CISO why your serverless architecture does not have the tenant isolation risks they are worried about. Knowing your stack at this level is part of what separates cloud architects who make good security tradeoff decisions from those who just trust that the defaults are fine.
The Bedrock AgentCore integration is a preview of where things are heading. As AI agents gain more capability and autonomy in cloud environments, the isolation substrate becomes more important, not less. Firecracker was the right solution for Lambda in 2018. It is the right solution for AI agents in 2025. That kind of longevity in a fast-moving field is the strongest possible endorsement of the underlying design.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.