I adopted gRPC on a large microservices platform a few years ago after spending months watching our REST-over-JSON internal APIs become a maintenance nightmare. We had 30-something services, each with slightly different error response formats, slightly different field naming conventions, and documentation that was perpetually out of date. The schema contract was “whatever the code does today” and debugging was a constant exercise in reading source code.
After migrating the most critical service-to-service calls to gRPC, the experience was noticeably different. Schema enforcement caught breaking changes at compile time instead of production. Streaming simplified several real-time data flows that had required polling or WebSocket hacks. And the generated client libraries meant teams could start consuming a new service without reading documentation.
gRPC is not a silver bullet, and it’s not a drop-in replacement for REST. But for internal service-to-service communication, it solves real problems that REST over JSON doesn’t.
What gRPC Actually Is
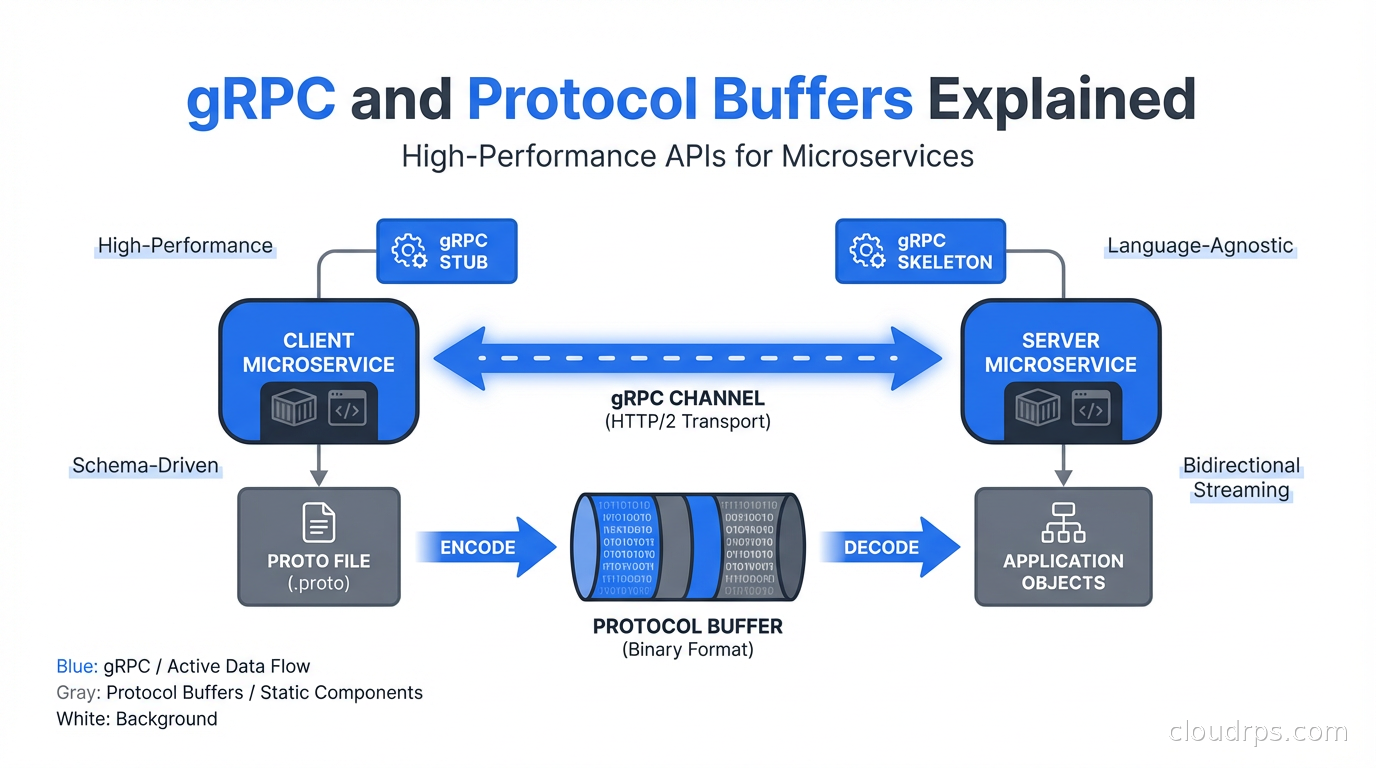
gRPC is an open-source remote procedure call framework developed by Google and open-sourced in 2015. The “g” originally stood for Google; later releases have rebranded it as a recursive acronym. The important details:
It uses HTTP/2 as the transport. This gives you header compression, request multiplexing (multiple in-flight requests over a single connection), and bidirectional streaming - none of which are available in HTTP/1.1.
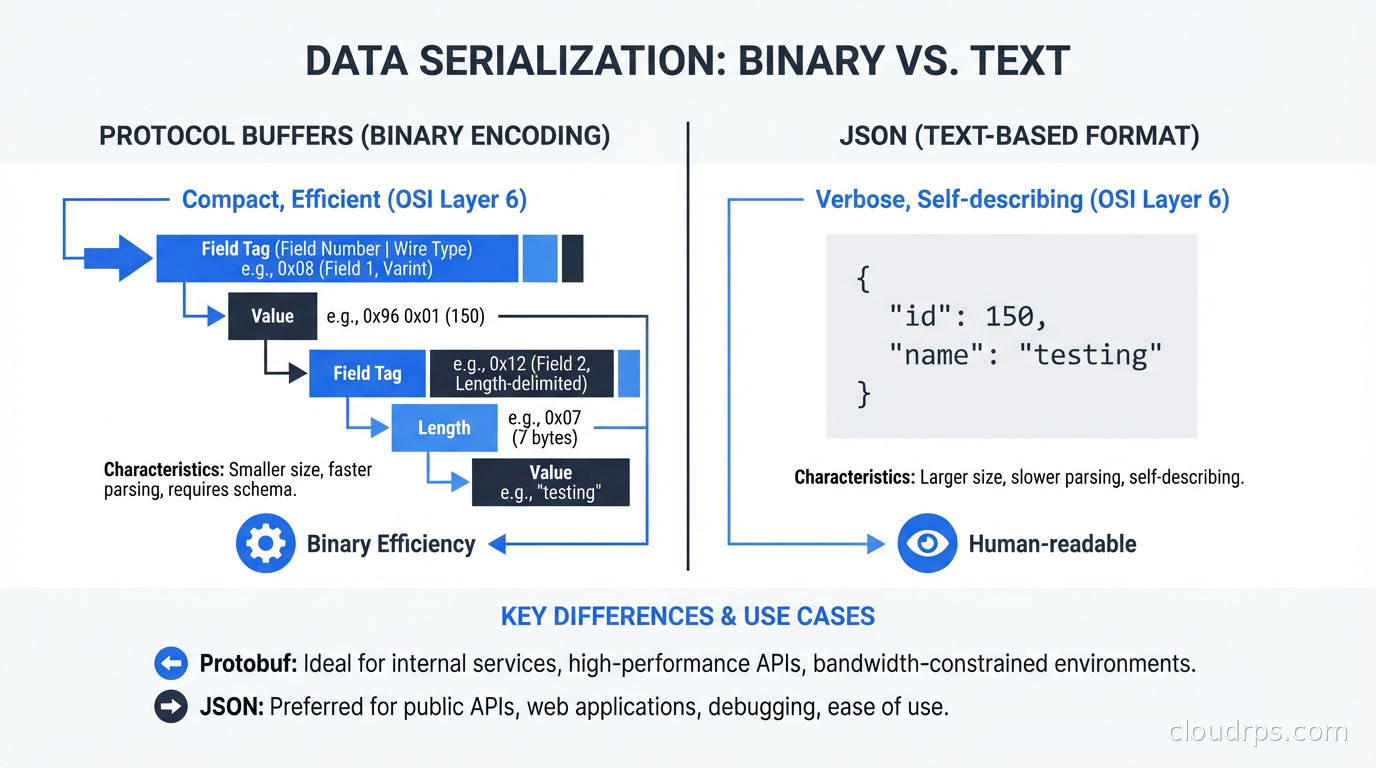
It uses Protocol Buffers (protobuf) as the default serialization format. Protobuf is a binary format defined by schema files (.proto files), which means the schema is explicit, versioned, and used to generate client and server code.
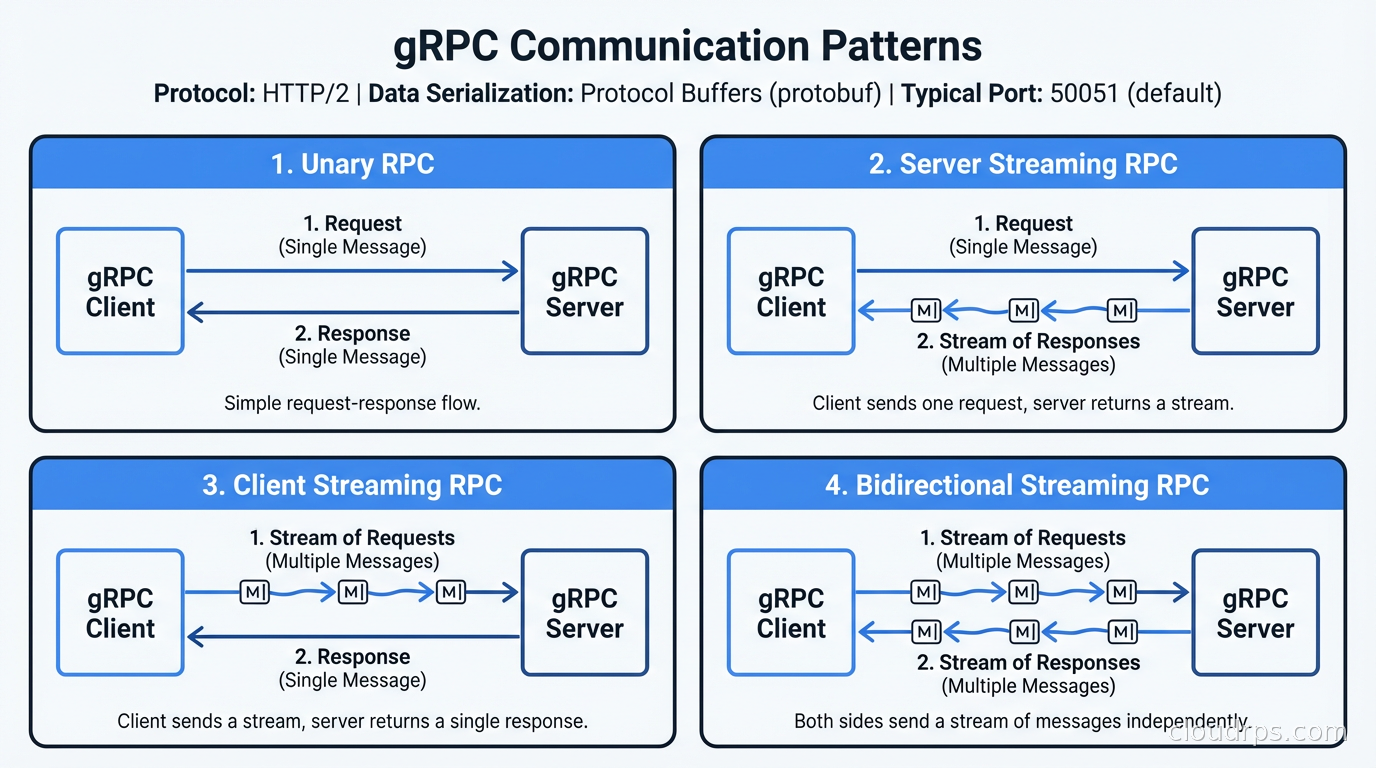
It supports four communication patterns: unary (single request, single response - like REST), server streaming (single request, stream of responses), client streaming (stream of requests, single response), and bidirectional streaming (streams in both directions). REST only does the first.
The combination of HTTP/2 and binary serialization makes gRPC significantly faster than JSON over HTTP/1.1 for the same workload. Typical benchmarks show 5-10x higher throughput and 2-5x lower latency compared to equivalent REST+JSON implementations. The actual numbers depend heavily on payload size, message frequency, and how much you’re paying in connection overhead.
Protocol Buffers: The Schema-First Design
The core of gRPC is the .proto file. This is where you define your service interface, your message types, and the field types within each message. Here’s a simple example:
syntax = "proto3";
package inventory.v1;
option go_package = "github.com/mycompany/inventory/gen/go/inventory/v1;inventoryv1";
message Product {
string id = 1;
string name = 2;
int64 quantity = 3;
double price = 4;
repeated string tags = 5;
}
message GetProductRequest {
string id = 1;
}
message ListProductsRequest {
int32 page_size = 1;
string page_token = 2;
repeated string tags = 3;
}
message ListProductsResponse {
repeated Product products = 1;
string next_page_token = 2;
}
service InventoryService {
rpc GetProduct(GetProductRequest) returns (Product);
rpc ListProducts(ListProductsRequest) returns (ListProductsResponse);
rpc WatchInventory(WatchInventoryRequest) returns (stream InventoryEvent);
}
Those field numbers (= 1, = 2, etc.) are important. Protobuf uses field numbers, not field names, in the binary encoding. This means you can rename a field in your schema without breaking binary compatibility - the wire format references field 3 regardless of whether it’s called quantity or stock_count. This is a significant advantage over JSON schema evolution.
You run the protobuf compiler (protoc) with language-specific plugins to generate client stubs and server interfaces in Go, Java, Python, TypeScript, Rust, or any of the other supported languages. The generated code handles serialization, HTTP/2 framing, and connection management. You write the business logic; the generated code handles the communication layer.
The schema-first approach is both gRPC’s biggest strength and the biggest adjustment for teams coming from REST. With REST, you can add a new endpoint in minutes without touching any schema. With gRPC, you edit the .proto file, run code generation, commit the generated code, and update any consumers. It’s more friction per change, but it makes the contract explicit and enforced.
The Four Communication Patterns
This is where gRPC becomes genuinely different from REST, not just faster.
Unary RPC is the familiar request-response pattern. Client sends a request message, server returns a response message. This maps directly to REST GET/POST/PUT patterns and is the most common gRPC pattern.
Server streaming lets the server send back a sequence of messages in response to a single client request. This is perfect for scenarios like: “give me all events since timestamp X” where the result set is large, or “watch this resource for changes” where the server pushes updates as they happen. In REST you’d either paginate or use WebSockets or long polling. With gRPC you write returns (stream Response) and stream naturally.
Client streaming is the inverse: the client sends a sequence of messages and the server responds once when the client is done. This suits bulk upload patterns or progressively computed requests.
Bidirectional streaming gives you a persistent, full-duplex connection. Both sides can send messages in any order. This is useful for real-time collaborative features, chat applications, or any protocol that requires true back-and-forth interaction. Implementing this with REST requires WebSockets, which is a separate protocol with its own connection management complexity. With gRPC it’s a first-class capability built on HTTP/2.
Schema Evolution and Backward Compatibility
One of the most practical benefits of gRPC is structured schema evolution. Protobuf has rules for what changes are backward-compatible (adding new optional fields, adding new enum values) and what are breaking (removing fields, changing field types, renumbering fields).
The tooling ecosystem around this is maturing. Buf (buf.build) is the tool I’d recommend for modern protobuf development. It handles code generation, linting for proto style conventions, and crucially, breaking change detection. You can run buf breaking in CI to prevent developers from accidentally shipping proto changes that break existing clients.
This is a qualitative difference from REST API evolution. With REST, you typically version your API with URL prefixes (/v1/, /v2/) and maintain multiple versions in parallel indefinitely. With gRPC and careful proto design, you can evolve your schema within a single version because the field numbering system preserves binary compatibility for additive changes.
That said, proto schema governance requires discipline. The field number system only works if you never reuse field numbers after removing a field. The convention is to add a comment (// reserved 4;) or use the reserved keyword to mark removed field numbers as permanently off-limits. If you reuse field number 4 for a different field, old clients will misinterpret the data silently.
gRPC in Production: What They Don’t Tell You
The learning curve is real. Go to REST and you can test your API with curl. Go to gRPC and you need either grpcurl (a curl-equivalent for gRPC), a gRPC GUI client like Postman or Insomnia (both support gRPC now), or server reflection enabled. Browser support is limited: you can’t call a gRPC service directly from a browser because browsers don’t expose HTTP/2 at the level gRPC requires.
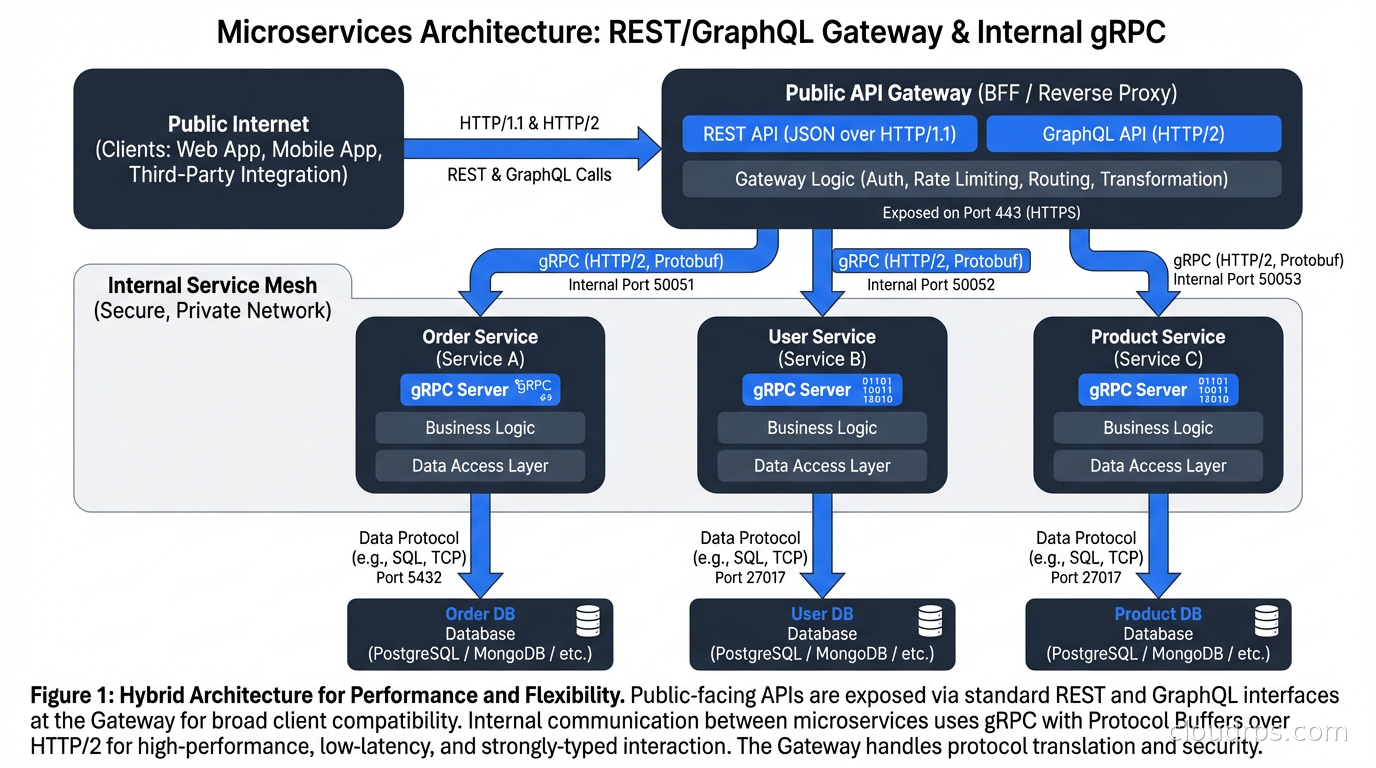
For public-facing APIs or browser clients, you have two options. The API gateway approach: put an API gateway in front of your gRPC services that translates HTTP/JSON to gRPC. grpc-gateway is a popular Go plugin that generates a REST gateway from your proto files automatically, so you maintain one schema and get both REST and gRPC endpoints. The gRPC-Web approach: a modified version of the gRPC protocol that works over HTTP/1.1, supported by an Envoy proxy, that lets browser clients call gRPC services directly.
Observability requires some setup. Standard HTTP access logs don’t capture gRPC semantics well. You want your gRPC servers instrumented with interceptors that log method names, status codes (gRPC has its own status code system, separate from HTTP status codes), and request/response sizes. OpenTelemetry has good gRPC instrumentation support, and the distributed tracing story is actually better with gRPC than REST because the binary framing makes context propagation more consistent.
Load balancing gRPC requires understanding HTTP/2. Because HTTP/2 multiplexes requests over a single connection, your standard L4 TCP load balancer will pin all of a client’s requests to a single backend. You need L7-aware load balancing that understands HTTP/2 and distributes individual RPC calls, not connections. Envoy, Linkerd, and Istio all handle this correctly. Plain Nginx or HAProxy in TCP mode do not. The service mesh context here is important: one of the reasons service meshes are popular in gRPC-heavy environments is exactly this L7 load balancing requirement.
Timeouts are different. In gRPC, the client sets a deadline (an absolute timestamp by which the entire call must complete). This deadline propagates through the call chain: if service A calls B calls C with a 500ms deadline, and the deadline has already consumed 200ms when B calls C, then C’s deadline is 300ms. This is semantically cleaner than the REST pattern of configuring per-service timeouts independently, but it requires all your services to respect and propagate deadlines, which takes discipline to implement correctly.
Comparing gRPC, REST, and GraphQL
The GraphQL vs REST comparison is about client-driven data fetching vs server-defined resources. gRPC is a different axis entirely.
REST is ideal for: public APIs consumed by external developers, browser-based applications, any context where human readability of the protocol matters, and teams that need the lowest possible learning curve.
GraphQL is ideal for: flexible data fetching where clients have diverse and variable data requirements, avoiding over-fetching and under-fetching in complex object graphs, and frontend teams that want autonomy over what data they request.
gRPC is ideal for: internal service-to-service communication where performance matters, streaming use cases, any context where schema enforcement and generated clients are valuable, and polyglot environments where you need clients in multiple languages generated from a single schema.
These are not mutually exclusive. A common architecture is gRPC for all internal service communication, REST/GraphQL at the API gateway for external consumers. This gives you high-performance internal communication with the schema benefits of protobuf, while exposing a developer-friendly interface to the outside world.
What gRPC is not good for: CRUD APIs where REST is perfectly adequate, teams that lack protobuf toolchain familiarity, services that need to be directly consumed by browsers without a gateway layer, and systems where the operational complexity of gRPC doesn’t justify the performance benefit.
The Buf Ecosystem and Modern Proto Development
Protobuf development has gotten significantly better over the last few years. Buf is the tool that modernized the ecosystem. Before Buf, protobuf development involved hand-managing complex protoc invocations with language-specific plugins, inconsistent code generation across teams, and no standardized way to share proto files across organizations.
Buf provides: a buf.yaml configuration that replaces protoc command lines, buf lint for proto style enforcement (consistent naming, field numbering conventions), buf breaking for CI-enforced breaking change detection, and the Buf Schema Registry (BSR) for sharing proto schemas across teams and organizations.
A buf.gen.yaml for generating Go and TypeScript clients looks like:
version: v2
plugins:
- remote: buf.build/protocolbuffers/go
out: gen/go
opt:
- paths=source_relative
- remote: buf.build/grpc/go
out: gen/go
opt:
- paths=source_relative
- remote: buf.build/bufbuild/es
out: gen/ts
The remote plugins pull the correct version of each code generator without you having to install or manage them locally. This is the workflow I’d recommend for any new gRPC project today.
For error handling, follow the gRPC error model carefully. gRPC status codes (OK, INVALID_ARGUMENT, NOT_FOUND, UNAVAILABLE, etc.) map to HTTP status codes at the gateway layer and are what clients use to handle errors programmatically. The google.rpc.Status message type supports attaching error details (ValidationError, RetryInfo, DebugInfo) as Any fields, which is far more structured than typical REST error responses. Use this consistently and your API becomes much easier to consume correctly.
Getting Started Without Boiling the Ocean
My recommendation for teams evaluating gRPC: start with one internal service that has clear performance requirements or is already frustrating to work with due to REST API evolution problems. Pick an existing service that has well-defined semantics and migrate it to gRPC while keeping the REST gateway for any existing external consumers.
Measure the results. If you see meaningful latency reduction, happier client teams who get generated libraries, and fewer schema-related bugs in production, you have your answer. Expand from there.
Don’t try to migrate all your services at once. The operational learning curve - setting up protoc toolchains or Buf, writing interceptors, getting L7 load balancing right - is real. Taking on that curve for 30 services simultaneously is a recipe for a bad time. The same staged approach that I’d apply to adopting any infrastructure as code tooling applies here: start small, build confidence, then scale the approach.
gRPC rewards investment. The first proto schema takes longer than a REST endpoint. By the tenth, you’re faster than REST because the generated clients and server stubs handle so much for you. The schema enforcement catches mistakes that would otherwise make it to production. The streaming capabilities solve problems that require significant custom code in REST. It’s a different model, and teams that understand it deeply build better distributed systems.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.