In twenty years of building and running cloud infrastructure, I have watched pricing conversations go in circles. A team notices their AWS bill is larger than expected, someone suggests “moving to a cheaper provider,” and then the conversation dies because nobody has the appetite to redo everything. But something shifted in the last couple of years. The gap between what AWS charges and what European cloud providers charge has become so wide that serious engineering teams are treating it as an architectural decision, not a cost curiosity.
I am talking about a CPX32 instance on Hetzner at roughly 14 euros per month versus a comparable m5.xlarge on AWS at around 170 dollars per month. That is not a rounding error. That is a 10x difference, and it changes the calculus on what is worth running where.
This article is not a hyperbolic pitch for abandoning AWS. I still run plenty of workloads there. But I have also spent the last few years migrating specific teams and services to Hetzner, OVHcloud, and Scaleway, and I want to give you an honest map of the terrain: what you get, what you give up, and the architectural patterns that make it work.
Why This Conversation Is Happening Now
The cloud market consolidated so fast in the 2010s that “cloud” became synonymous with AWS, GCP, and Azure. Those three hyperscalers have deep ecosystems, global reach, and services you genuinely cannot replicate elsewhere. But they also made a business decision to extract significant margin on compute and storage, and to charge aggressively for egress.
Egress costs in particular are a structural tax that compounds at scale. Every gigabyte of data leaving your cloud costs money. Hetzner includes 20 TB of egress per server per month for free. Scaleway’s outbound traffic to the internet is free entirely. That single difference can eliminate four-figure monthly charges for data-heavy workloads.
The GDPR and data sovereignty pressure added another dimension. European companies started asking serious questions about where their data resides and which legal jurisdiction governs it. US hyperscalers have European regions, but they are still US companies subject to laws like FISA and the CLOUD Act. EU-native providers operating under French, German, or Dutch law offer a different legal posture, which matters more in some sectors than others.
Then there is the Hacker News effect. Engineers at startups started publicly sharing what they pay to run the same workload on Hetzner versus AWS, and the numbers were shocking enough that it became a genre of post. That social proof removed the stigma from considering alternatives.
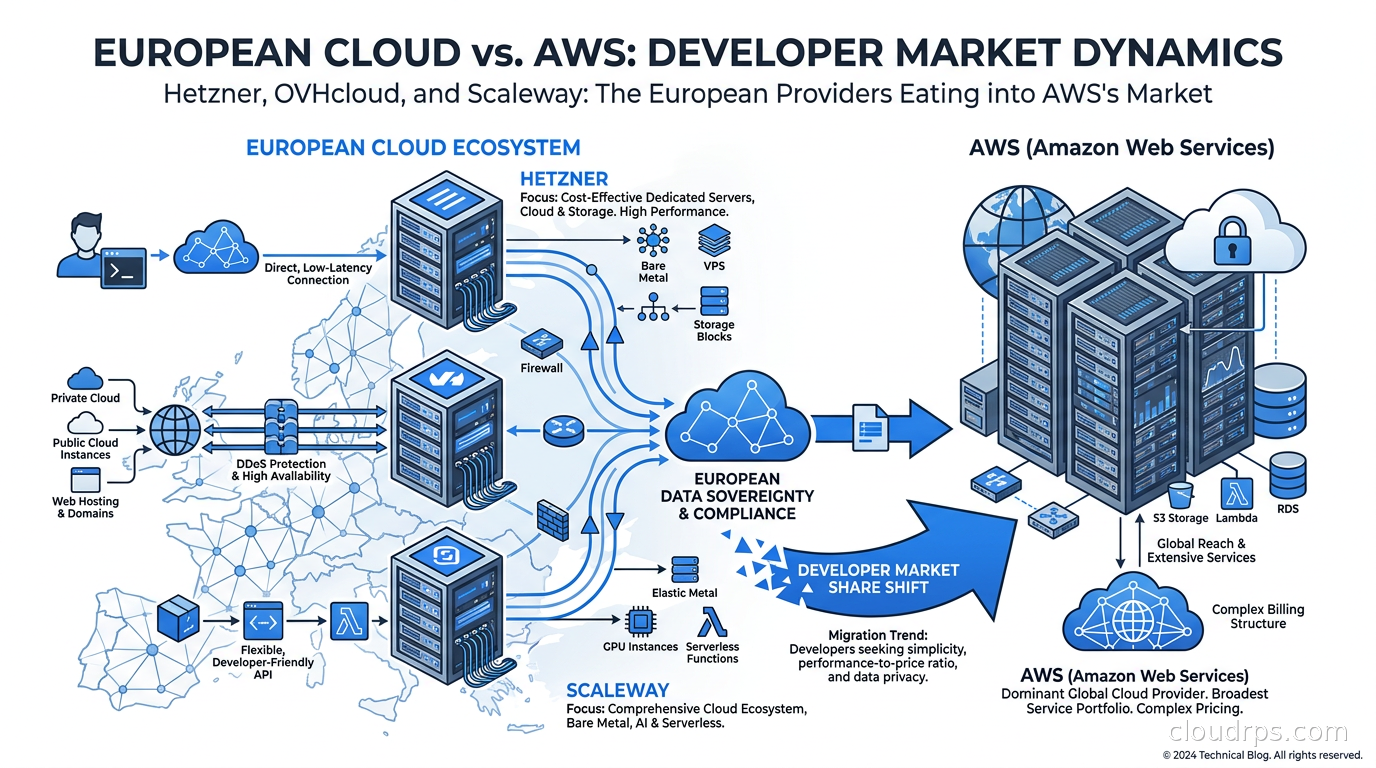
The Providers Worth Taking Seriously
Let me walk through the three I have direct production experience with.
Hetzner: Raw Compute at Absurd Value
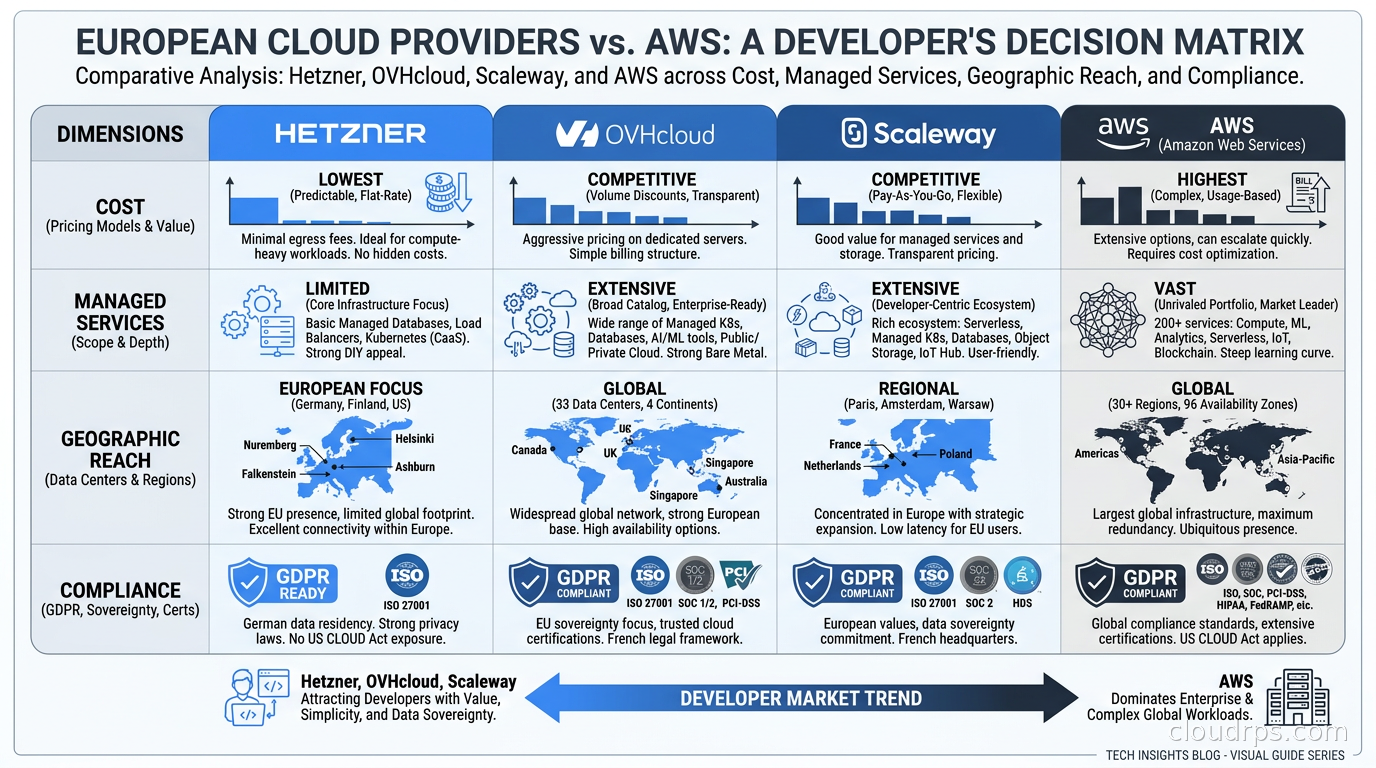
Hetzner is a German company founded in 1997 that runs its own data centers in Germany, Finland, and the US. Their value proposition is straightforward: they sell compute and storage at margins that reflect actual hardware costs, not a software platform premium.
Their Cloud offering covers virtual machines from 1 vCPU and 2 GB of RAM at around 4 euros per month up to machines with 48 vCPUs and 192 GB of RAM. Their dedicated servers are where it gets interesting for specific workloads. An AX41 with a six-core AMD Ryzen, 64 GB RAM, and two 512 GB NVMe drives runs around 38 euros per month. I have built Kubernetes clusters on Hetzner dedicated servers that would have cost fifteen times more on AWS.
Hetzner’s managed Kubernetes service (Hetzner Kubernetes) works with their Cloud API and integrates with Hetzner Load Balancers and Volumes. It is not as feature-rich as EKS or GKE, but for teams running Kubernetes workloads that are not deeply coupled to cloud-provider APIs, it functions well.
The network is solid for European traffic. Their Frankfurt and Helsinki data centers have good connectivity within the EU. The US data center (Ashburn and Hillsboro) works, but latency to European users from US infrastructure is obviously not their strength.
What you give up: global reach (no APAC, no South America), the deep managed service catalog, and some operational maturity in their control plane. Support is good but not enterprise-level with SLA guarantees.

OVHcloud: Europe’s Largest Cloud, With Public Cloud Muscle
OVHcloud is the largest European cloud provider by server count and infrastructure footprint. They own and manufacture their own servers, run their own fiber network, and operate data centers across Europe, North America, and Asia-Pacific. Founded in 1999 by Octave Klaba, they have grown to operate more than 43 data centers globally.
Their positioning is different from Hetzner. OVHcloud is trying to be a serious enterprise alternative to AWS, not just cheap compute. They offer managed Kubernetes (OVH Managed Kubernetes), managed databases (PostgreSQL, MySQL, Redis), object storage with an S3-compatible API, and a public cloud platform that covers most of what a growing startup needs.
The pricing is not as aggressive as Hetzner but is meaningfully cheaper than AWS. A B2-7 instance (2 vCPU, 7 GB RAM) runs around 0.04 euros per hour. More importantly, OVHcloud includes anti-DDoS protection in all their plans, which is a real cost on other providers, and their network egress pricing is substantially lower than AWS or Azure.
OVHcloud has had some high-profile reliability issues, including a major fire at their Strasbourg data center in 2021 that destroyed servers. They have invested heavily in infrastructure redundancy since then, but if you are considering OVHcloud for production, you need to architect for multi-region resiliency more deliberately than you might with a hyperscaler. That is good practice anyway, but do not assume the same durability guarantees.
Their GDPR and data sovereignty story is strong for European companies. Data stays in EU jurisdiction, governed by French law, under the CLOUD Act’s non-reach. For regulated industries like healthcare, finance, or public sector, this is a genuine architectural differentiator.
Scaleway: Developer-Friendly, With Real Cloud Primitives
Scaleway is OVHcloud’s French cousin in spirit: a European provider, part of the Iliad group, with a genuine commitment to building developer-friendly infrastructure. They are smaller than OVHcloud but have earned a strong reputation among developers.
What makes Scaleway distinct is their developer experience and their networking economics. Their internet egress is free, full stop. For workloads serving web traffic, that is a massive operational win. They have object storage with a simple API, a managed Kubernetes service called Kapsule, managed databases, and GPU instances for inference workloads.
Scaleway’s GPU instances include access to H100s and L4s for inference and lighter training work. The pricing per GPU-hour is competitive with what AWS charges, but when you factor in free egress on serving model outputs, the total cost of ownership for inference workloads often works out better.
They have data centers in Paris, Amsterdam, and Warsaw, which covers most EU regulatory zones reasonably well. Their control plane is modern, their Terraform provider works well, and their API is clean.
Where Scaleway falls short is the depth of managed services compared to OVHcloud or, obviously, AWS. If you need a managed Kafka cluster, a fully managed data warehouse, or dozens of specialty services, Scaleway is not going to replace AWS. It is good at what it does and honest about what it does not do.
The Architecture Pattern That Actually Works
Here is what I have seen succeed when teams make this move. It is not “rip out AWS and replace everything.” That is a project that fails. The pattern that works is narrowing the scope to what you are actually optimizing for.
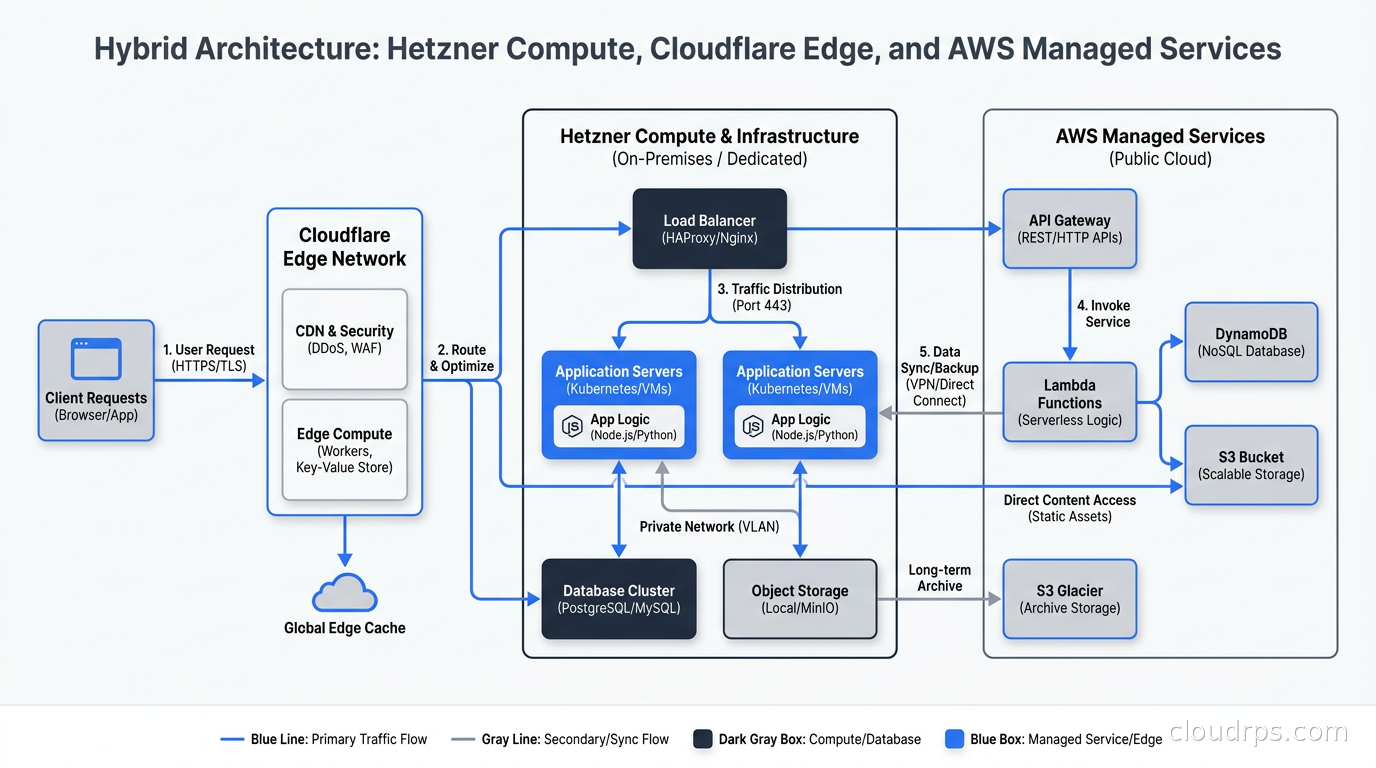
The typical architecture looks like this: Hetzner or Scaleway for compute-heavy, egress-heavy, or EU-resident workloads. Cloudflare as the CDN, DDoS layer, DNS, and edge. An S3-compatible object store (Hetzner Object Storage or Scaleway Object Storage) for application assets and backups. A hyperscaler for anything that genuinely requires their managed services: AWS SES for transactional email, Route 53 if you need complex routing policies, or GCP Vertex AI for model serving that would be painful to self-host.
This is not a purity play. It is an optimization play. You land on the cheapest compute you can run reliably, offload the things where the hyperscaler genuinely adds value that you cannot replace, and build the connections between them.
For multi-cloud networking between these environments, the simplest approach is Cloudflare Tunnel or WireGuard. I have used both. Cloudflare Tunnel is simpler to operate because you do not manage keys and peers manually. WireGuard is cheaper and gives you more control if you want it.
Infrastructure as Code Works Fine Here
A common objection I hear is that Terraform coverage for these providers is not as mature as for AWS. That has gotten significantly better. The Hetzner Terraform provider is well-maintained and covers their full Cloud API. OVHcloud has an official Terraform provider. Scaleway’s provider is solid.
The bigger difference is the ecosystem around infrastructure as code tooling. AWS has native integrations with CDK, CloudFormation, and a large ecosystem of third-party modules. On Hetzner, you are often writing more of your own modules. That is not a blocker, but it is work that a team new to the platform needs to budget for.
For Kubernetes specifically, Hetzner and Scaleway both expose cluster APIs that work with standard GitOps tooling. I have run ArgoCD and Flux on Hetzner clusters without modification. The cluster behaves like a cluster. The differences are in how the control plane handles node scaling and how storage classes integrate with their block storage.
The Total Cost of Ownership Honest Math
I want to give you a real example without disclosing confidential client numbers. A mid-size SaaS company serving European users had the following workload: a Kubernetes cluster running about 20 services, a PostgreSQL database with significant read traffic, around 30 TB of monthly egress, and object storage for user-generated content.
On AWS (eu-west-1), their bill was approximately 18,000 dollars per month. The big line items were EC2 compute, RDS, and data transfer. On a migration that moved their cluster to Hetzner Cloud with their PostgreSQL to a managed PostgreSQL instance on OVHcloud, and kept their CDN on Cloudflare, the monthly cost dropped to around 2,800 euros. A difference of roughly six times, saving over 150,000 euros annually.
The migration took three months for a team of four engineers. That is not trivial. But payback period at that delta is measured in weeks, not years. A real total cost of ownership analysis has to factor in migration engineering cost, ongoing operational overhead of a less managed platform, and the opportunity cost of the engineer time. Even with those costs included, the math was still strongly favorable.
The operational overhead is real. When something breaks on AWS, you file a support ticket and AWS tells you what is wrong with their service. On Hetzner, when something breaks, you are often diagnosing it yourself. That cost is non-zero. For a team that is already comfortable operating infrastructure, it is manageable. For a team that depends heavily on AWS’s operational support, it is a bigger change.
What You Should Not Move
There are workloads I do not move and I would advise against trying.
Anything with deeply integrated AWS service dependencies. If you have spent years building on DynamoDB, Step Functions, EventBridge, or AWS-native data services, the migration cost to neutral alternatives is high and the operational risk is significant. That stack is part of your application architecture now and ripping it out does not have a clean payback calculation.
Workloads requiring significant APAC coverage. Hetzner and Scaleway do not have regions in Asia. OVHcloud has some, but the coverage is thinner than AWS or GCP. If you have meaningful traffic from Japan, Singapore, or Australia, you need that geographic presence.
Anything with regulatory requirements for specific certifications that the smaller provider does not carry. OVHcloud and Scaleway are ISO 27001 certified and have various compliance attestations, but they do not have the breadth of AWS compliance programs. If your customers require a specific certification that only hyperscalers carry, you have your answer.
ML training workloads at scale. The managed ML infrastructure on AWS (SageMaker), GCP (Vertex AI), or Azure (Azure ML) has genuinely better tooling for large-scale training pipelines. Scaleway has GPU instances, but building a serious training infrastructure on European indie cloud requires significantly more self-management. For LLM fine-tuning at real scale, I still use hyperscaler GPU fleets with spot instances.
Making the Decision
The decision framework I use is simple. Start by looking at your bill and identifying where the money goes. If compute and egress represent more than 60% of your bill, you are a candidate for this kind of migration. If the majority is managed services (RDS, SageMaker, SQS, Lambda, etc.), the savings opportunity is lower and the disruption is higher.
Then look at your team’s operational maturity. A team that has never managed a Kubernetes cluster themselves, relies heavily on AWS console, and does not have strong infrastructure-as-code practices will struggle more with the transition. A team that runs their own infrastructure as code and treats their cloud provider as a commodity layer is well-positioned.
Finally, look at your geographic requirements. If you primarily serve European users, Hetzner’s Frankfurt and Helsinki presence covers you well. If you have global requirements, the European indie providers are a piece of the puzzle but not the whole answer.
The FinOps Angle Worth Understanding
There is a FinOps lens that does not get enough attention here. The cloud cost optimization discipline grew up inside companies trying to optimize within hyperscaler pricing models: reserved instances, savings plans, spot fleets, rightsizing. All of those techniques are real and valuable.
But they operate within a pricing ceiling set by the hyperscaler. Hetzner’s CX22 costs 4.50 euros per month. AWS’s equivalent costs 10-15 times more at list price, and even with reserved instance discounts you might get to 5-6 times more. No amount of rightsizing gets you from 5x to 1x.
What European providers offer is not a better discount structure. It is a fundamentally different pricing model based on lower margin and lower operational overhead. Hetzner makes money on volume and efficiency. AWS makes money on margin and ecosystem lock-in. Those are different business models and they produce different price points for the same underlying hardware.
Understanding that distinction matters when you are building a FinOps practice. The conversation shifts from “how do we optimize our hyperscaler spend” to “what should be on a hyperscaler at all.”
An Honest Assessment of Operational Risk
I want to close with something I see skipped in most “move to Hetzner” posts. These providers are smaller businesses. Hetzner has been operating for over 25 years and is financially stable, but they do not have the resilience depth of AWS. Their control planes have had outages. Their managed Kubernetes service has had API availability issues.
If you are running workloads where even a brief period of control plane unavailability creates serious business impact, you need to architect accordingly. That means not depending on the Hetzner Cloud API for things that need to keep running during an outage, using immutable infrastructure patterns, and having runbooks that assume the provider’s management plane is unavailable.
This is also why the hybrid pattern works. When AWS has a control plane outage in us-east-1, your us-east-1 instances keep running. The same is true on Hetzner. The risk is not that your VMs disappear, it is that you cannot provision new ones or change configurations until the API comes back. Build for that and the risk profile is manageable.
Twenty years into this career, I have seen vendors come and go. I have seen “challenger cloud” become “legacy infrastructure” faster than anyone expected. The European providers I described have solid track records, good technical foundations, and business models that do not depend on land-and-expand tactics to survive. I do not think they are going anywhere. But they are also not AWS. Calibrate accordingly.
The developers and engineering teams running production SaaS on Hetzner and Scaleway today are not cowboys taking reckless risks. They are practitioners who have looked at the cost structure, evaluated the trade-offs, and made rational decisions about where to run their compute. In 2026, that conversation is completely mainstream. The interesting question is not whether to consider European cloud providers, but how to structure the boundary between them and the hyperscalers you will always use for something.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.