Every platform team I have ever worked with goes through the same arc. You start with a Confluence page listing your services. Then someone adds a GitHub Wiki. Then a shared spreadsheet for on-call rotation. Then a Notion doc for runbooks. Then a Slack channel for “where does this service live.” Three years in, you have seventeen sources of truth and zero actual truth. New engineers spend their first two weeks just learning how to find things.
I have been building cloud infrastructure for twenty years, and the “developer experience problem” is one of the few categories where I have watched the industry converge on a real solution rather than just trading one mess for another. That solution is the internal developer portal, or IDP. Not to be confused with identity providers (also IDP, confusingly), these are platforms that give engineers a single pane of glass for their software estate: service ownership, documentation, infrastructure templates, CI/CD pipelines, and cost visibility all in one place.
Gartner has been predicting for a couple of years that 80% of large engineering organizations will run dedicated platform teams by 2026. The tooling to support those teams has matured substantially. You now have a real choice between building your own on top of Backstage or buying a commercial product like Port, Cortex, or OpsLevel. That choice has meaningful consequences for how fast you move and how much you pay, in engineering time if nothing else.
This article is the thing I wish I had read before spending eight months trying to get a Backstage deployment right at a previous company.
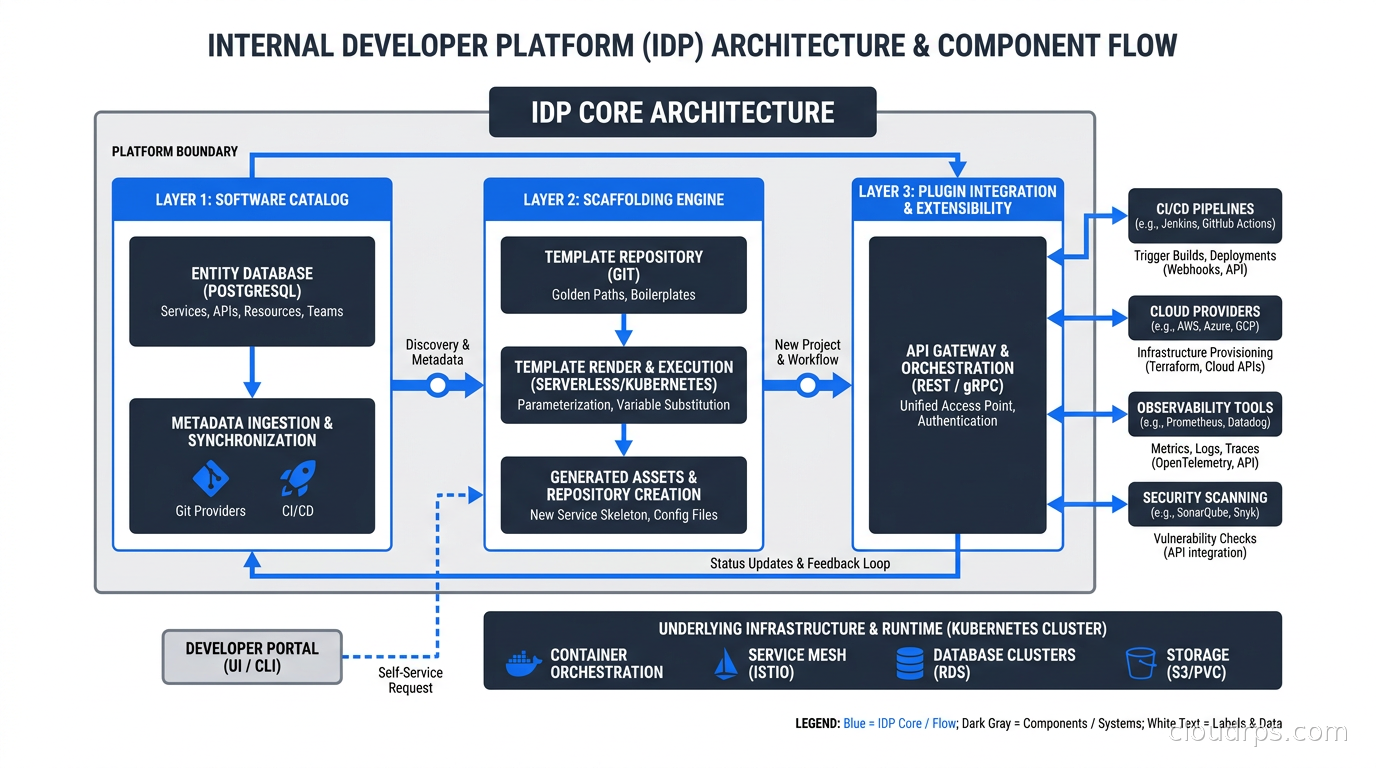
What an Internal Developer Portal Actually Does
An IDP is not a DevOps dashboard. A lot of teams confuse the two. A dashboard shows you metrics. An IDP is an operational system, one that engineers actually interact with to do their jobs.
The four core capabilities of a mature IDP:
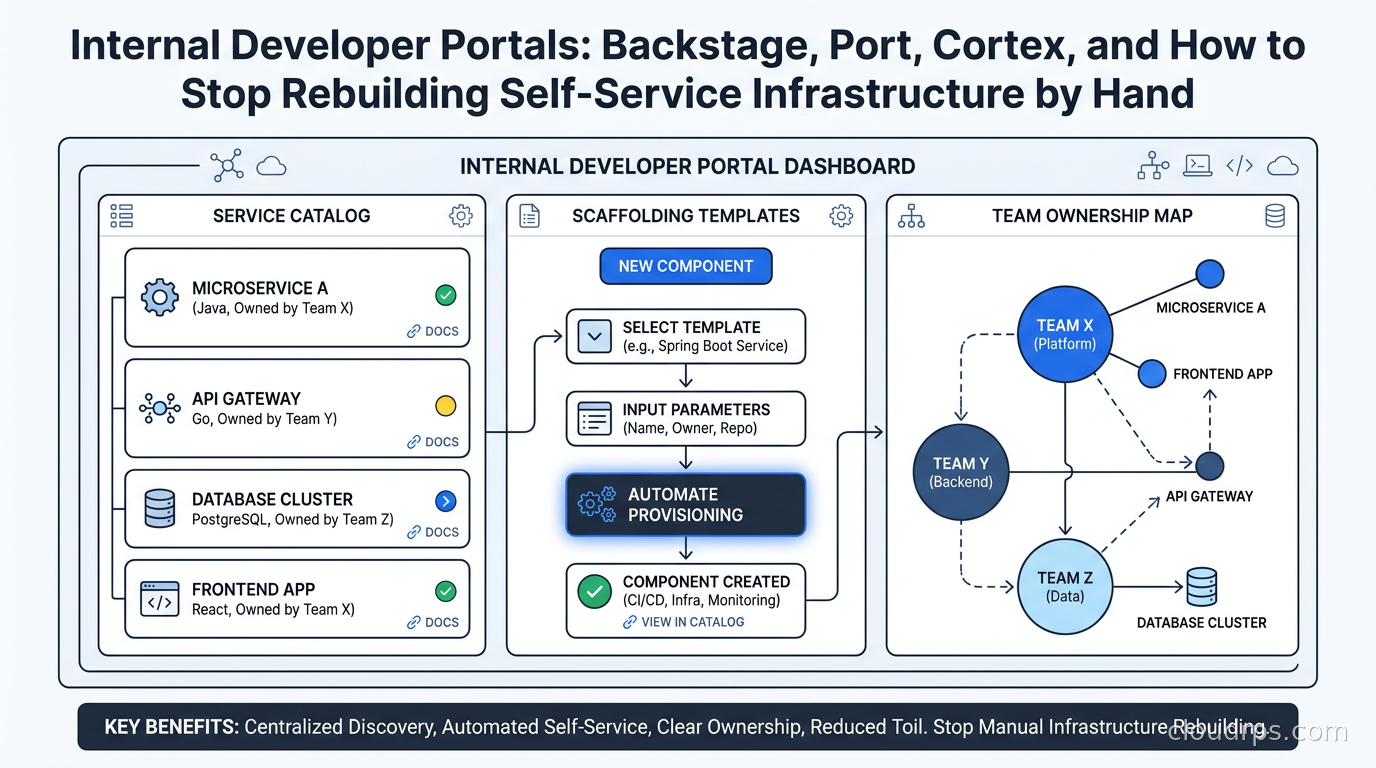
Software catalog. A live inventory of every service, library, website, API, database, and queue your organization owns. Each entity has an owner (a team), technical metadata (language, framework, cloud region), and links to its documentation, source code, deployments, and incident history. The catalog is the foundation everything else builds on. Without accurate ownership data, nothing else works.
Scaffolding and templates. When an engineer needs a new service, they should not be copying a five-year-old Python Flask app from GitHub and removing the hardcoded production credentials. They should fill out a form, click a button, and get a repository pre-wired with your organization’s standards: lint configs, CI/CD pipelines, observability instrumentation, Dockerfile, Helm chart, RBAC manifests, the works. This is where IDPs pay for themselves. I have seen this cut “time to first deployment” from weeks to hours.
TechDocs and documentation as code. Documentation that lives in Confluence gets stale. Documentation that lives next to the code, rendered by the portal, has a fighting chance of staying current. IDPs pull markdown from source repositories and render it in the portal alongside the service entry. Engineers update docs in the same PR as the code.
Actions, workflows, and self-service. Beyond scaffolding new services, platform teams can expose arbitrary operations through the portal: provision a database, rotate credentials, trigger a load test, promote to production, add a team member to a PagerDuty schedule. The IDP becomes the interface to your entire platform, not just the catalog.
Backstage: The Open-Source Foundation
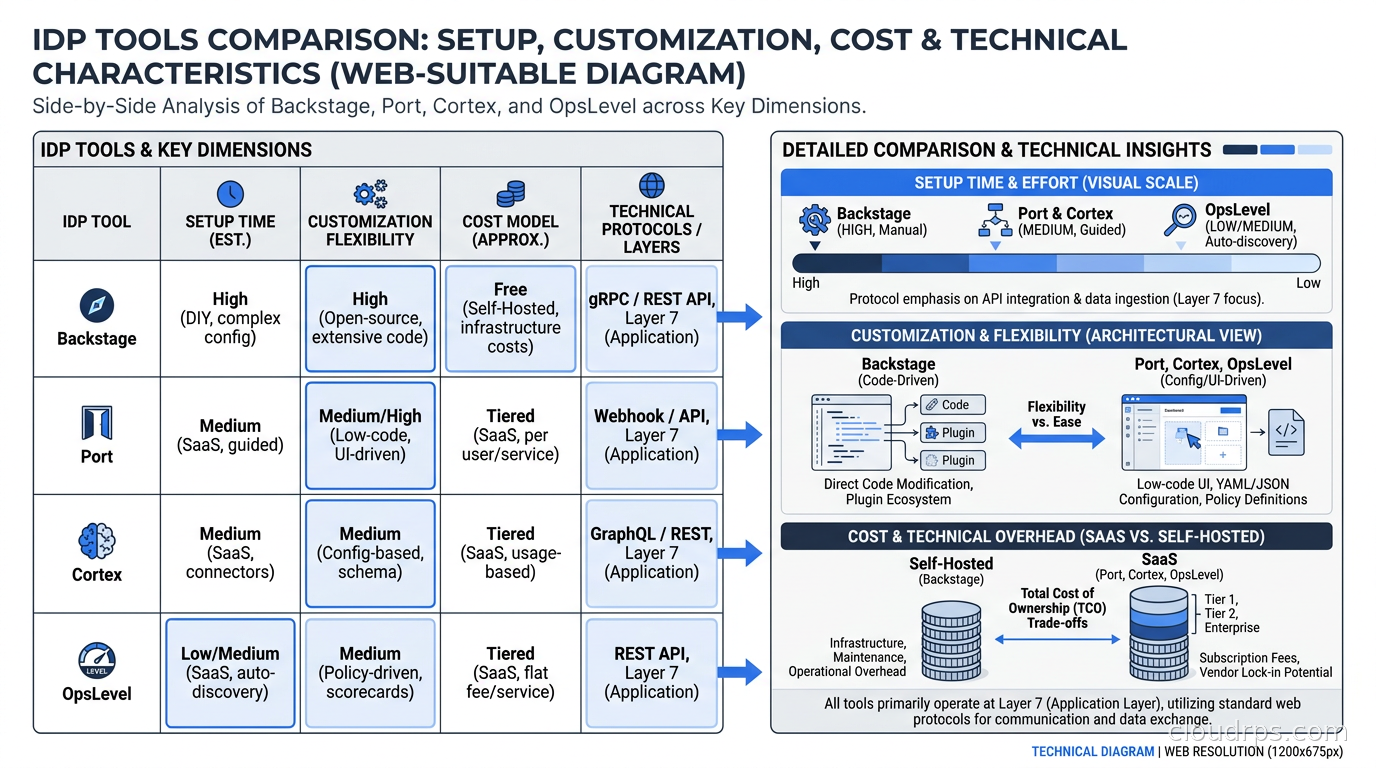
Backstage is the 800-pound gorilla in this space. Spotify open-sourced it in 2020, it graduated from the CNCF sandbox to incubation status quickly, and it has accumulated a massive plugin ecosystem. If you search “internal developer portal” on GitHub, you find Backstage forks, Backstage plugins, and Backstage tutorials. It has won mindshare the way Kubernetes won container orchestration mindshare: decisively, sometimes brutally.
The architecture is a React frontend backed by a Node.js backend, running on your own infrastructure (typically Kubernetes). It connects to your version control system, CI/CD, cloud providers, observability tools, and whatever else you wire up via plugins.
The plugin model is Backstage’s biggest strength and its biggest operational headache. There are over 1,400 community plugins in the catalog: integrations with AWS, GitHub Actions, PagerDuty, Datadog, Snyk, ArgoCD, and basically every tool your organization probably uses. You wire your entire ecosystem into one place.
Here is the thing nobody tells you clearly: maintaining a Backstage deployment is a non-trivial engineering job. At the previous company I mentioned, we had one and a half engineers dedicated to it for most of a year before it was stable enough that we stopped getting complaints. The plugin ecosystem, while vast, is inconsistent in quality. Some plugins are maintained by major companies with dedicated teams. Others are a single engineer’s weekend project from 2022. You will spend real time vetting, forking, and patching plugins that almost do what you need.
The catalog itself requires ongoing curation. Backstage can auto-discover entities from GitHub repos, Kubernetes namespaces, and other sources, but those integrations need maintenance. When your repo moves, when a team restructures, when a service gets deprecated, the catalog needs to reflect that. This is not a set-and-forget system.
That said, for organizations with the engineering capacity to invest in it, Backstage gives you complete control. You can build exactly the portal your engineers need. You are not constrained by a vendor’s roadmap. You can open-source your own plugins and contribute back to the community. The companies that are genuinely good at Backstage, and there are many, have something that no off-the-shelf product can match.
The Commercial Alternatives
If you do not have a dedicated platform engineering team with bandwidth to run Backstage, the commercial options have gotten genuinely competitive.
Port has become the most talked-about Backstage alternative over the last two years. Its central innovation is a flexible blueprint system: you define entity types (services, teams, environments, pipelines, whatever you need) and their relationships using a visual builder, then populate them from your existing tools via integrations or API. Port ships with pre-built integrations for GitHub, GitLab, Jira, PagerDuty, Datadog, Kubernetes, AWS, and several dozen others. Self-service actions are a first-class feature, not bolted on.
What I find compelling about Port is that a small team can actually get it working in days rather than months. The tradeoff is that you are working within Port’s data model and UI. If you have unusual requirements or need deep customization, you will eventually bump into the edges of what the product supports.
Cortex takes a different philosophical angle. Where Backstage and Port emphasize the catalog and self-service, Cortex is built around scorecards and service standards. You define what production-ready means at your organization: services must have an on-call rotation, pass security scans, have documentation, not use deprecated dependencies, etc. Cortex tracks compliance against those standards and gives teams dashboards showing where they stand. This works extremely well for organizations that have a maturity problem rather than a discovery problem. If engineers know where their services are but the services are not meeting reliability or security standards, Cortex’s carrot-and-stick scorecard approach is a good fit.
OpsLevel sits somewhere between Port and Cortex: a managed SaaS portal with strong catalog capabilities, rubrics (their equivalent of scorecards), and service lifecycle features. It has a clean UI and a good Kubernetes integration. I have seen it work well at mid-sized companies (200-500 engineers) that need something production-ready faster than Backstage allows.
Roadie is worth mentioning separately because it is effectively managed Backstage: they run the infrastructure, apply security patches, and maintain the core, while you configure your instance via their UI. You get the Backstage plugin ecosystem without the operational burden of running it yourself. For organizations that want Backstage’s flexibility but not the maintenance overhead, Roadie hits a useful middle ground.
Build vs. Buy: The Framework I Actually Use
This question comes up in almost every platform architecture conversation I have. Here is the decision framework I have settled on after seeing it play out multiple ways.
Build (Backstage or custom) if:
- You have more than 500 engineers and deep platform team investment
- You have unusual data model requirements that commercial products cannot accommodate
- Your organization has the appetite to contribute to open source and build on top of community work
- Vendor lock-in is a primary concern (often in regulated industries)
- You need to integrate with internally-built tooling that no commercial product will ever support
Buy (Port, Cortex, OpsLevel, Roadie) if:
- You have fewer than 500 engineers or a small/new platform team
- You need something production-ready in weeks, not months
- Your toolchain is mostly standard (GitHub, AWS, Datadog, PagerDuty, etc.)
- Your primary goal is catalog accuracy and self-service, not deep customization
- You want ongoing product development from a vendor rather than maintaining OSS yourself
One pattern I have seen fail repeatedly: a two-person platform team decides to run Backstage because it is free and has the biggest community. They spend four months getting it deployed, discover they need three more plugins that do not quite exist, spend another two months writing those plugins, and by month seven, engineers have given up waiting and built their own workarounds. The “free” option cost more than three years of a commercial license would have.
The other failure mode: a large organization buys Port, gets it working fast, and then realizes they need to model their internal microservice dependencies in a way that Port’s blueprint system handles awkwardly. They spend a year making it work, when Backstage would have handled it natively.
Know your constraints before you choose.
Actually Getting Engineers to Use It
The technical choice matters less than adoption. I have seen beautiful Backstage deployments with a 15% active user rate. I have seen scrappy Port setups that every engineer in the organization uses daily. Adoption is harder than implementation.
A few things that actually work:
Start with the catalog, not everything. Do not try to launch the portal with scaffolding, TechDocs, and self-service actions all on day one. Launch the catalog. Make it accurate. Make it useful. Engineers start using it when they can rely on it to tell them who owns a service, where the repo is, and where the runbook lives. Everything else follows from that trust.
Mandate catalog entries for new services. If you launch without any policy, teams will not fill out catalog entries. Make it part of the deployment checklist for every new service: you cannot get to production without a catalog entry. This seeds the catalog and creates a habit.
Make the portal the source of truth, not a mirror. IDPs fail when they are read-only aggregators of data that lives elsewhere. If your portal shows service health pulled from Datadog but engineers have to go to Datadog to actually do anything, the portal is just friction. Build self-service actions so that engineers can accomplish things directly in the portal. Start with one high-value action (provision a dev environment, rotate API keys, add a service dependency) and build from there.
Track adoption metrics. Weekly active users, catalog completeness percentage, number of scaffolding templates used, number of self-service actions triggered. Review these in your platform team retros. IDPs that nobody measures do not get invested in.
This connects to the broader challenge of platform engineering organizational design: the portal is only as useful as the platform products it exposes. A bad platform with a beautiful portal is still a bad platform. The IDP is the interface layer, not the thing itself.
Integrating the IDP Into Your Existing Stack
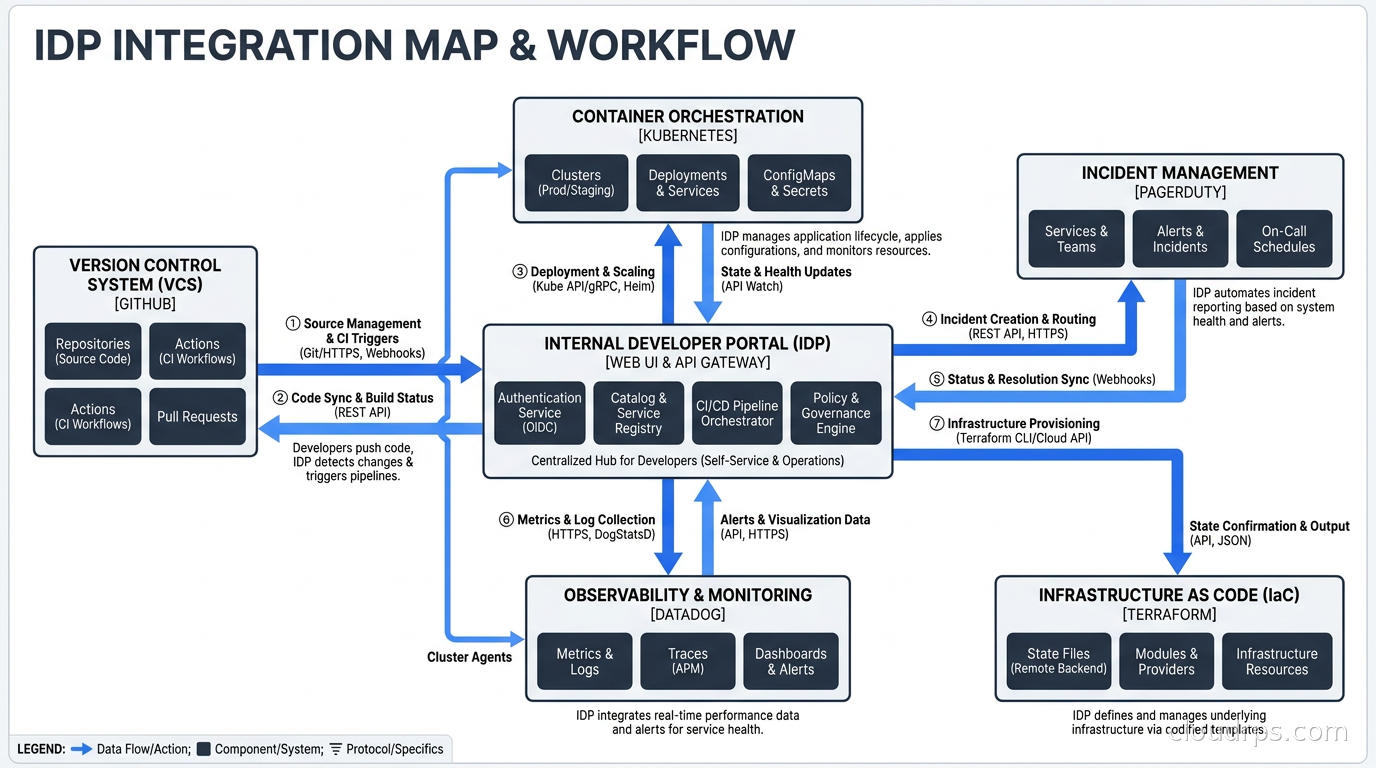
An IDP without integrations is a fancy Notion page. The value comes from connecting it to your existing toolchain.
The integrations that deliver the most value, roughly in order:
Version control (GitHub, GitLab, Bitbucket). This is table stakes. The IDP needs to know where your code lives, who last committed, and the health of your CI pipelines. Most IDPs auto-discover catalog entities from repository annotations or manifests.
Kubernetes. Your portal should show what version of a service is running in each environment, its resource consumption, and pod health. This is often where on-call engineers spend their first minute when something goes wrong. If they can get to this from the portal instead of running kubectl commands, you save time. For teams running GitOps workflows with ArgoCD or Flux, the IDP can surface sync status and deployment history directly in the service entry.
Incident management. Link each catalog entity to its PagerDuty or OpsGenie service. When someone hits a service entry during an incident, they should see open incidents and recent post-mortems in two clicks. This alone justifies the catalog to on-call engineers.
Observability. Pull in error rate, latency p99, and deployment frequency from your observability stack. When combined with DORA metrics tracking, the portal becomes a meaningful engineering effectiveness dashboard, not just a directory.
CI/CD pipelines. Show pipeline status for the last N deployments. This lets engineers see at a glance whether the thing they are about to debug has been deployed recently and whether that deployment succeeded.
Infrastructure as Code. If your org uses Terraform or OpenTofu to provision infrastructure, the IDP can show what infrastructure a service depends on and expose self-service actions to provision new resources via approved Terraform modules.
The Scorecard Pattern: Driving Standards at Scale
One feature I have seen deliver disproportionate value, especially at larger organizations, is the scorecard or rubric system that Cortex popularized and most other IDPs have now adopted in some form.
The idea: you define what a production-ready service looks like at your organization. Common criteria include:
- Has an owner team with a valid on-call rotation
- Has a runbook linked in the catalog entry
- Passes automated security scanning (Snyk, Trivy, or similar)
- Has SLOs defined and monitored
- Does not use deprecated dependencies or base images
- Has been deployed in the last 90 days (or has a documented deprecation plan)
- Has automated tests with >= 80% coverage
- Exposes health check endpoints
The portal evaluates every service against these criteria continuously and gives teams a score. Platform teams can set target scores, track progress over time, and celebrate improvements in eng-wide channels. Services that repeatedly fail checks get flagged for engineering manager review.
This works because it makes invisible technical debt visible. Engineers are not unwilling to improve their services; they often just do not know the standard or where they fall short. A scorecard gives them a clear signal and a specific action.
I have seen security teams use this to drive DevSecOps adoption without needing a mandate: services in the bottom quartile of security scores get a gentle automated Slack message each Monday, and most teams fix the issues rather than keep getting the message. No audits, no compliance theater.
Realistic Timelines and What Success Looks Like
Here is an honest view of what adoption looks like in practice.
Months 1-3: Catalog is deployed and seeded with your top 50 services. Early adopters are using it to find on-call contacts and documentation links. Basic integrations (GitHub, CI/CD) are live. A few teams have tried scaffolding but the templates need work.
Months 4-6: Catalog has grown to 200+ entities through a mix of auto-discovery and manual entry. Scaffolding is generating new services consistently. You are tracking catalog completeness as a KPI. Weekly active users are at 20-30% of engineering.
Months 7-12: Scorecards are live and showing measurable improvement in service quality. Self-service actions beyond scaffolding are available (provision environments, rotate secrets, create PagerDuty services). Weekly active users are 50-70% of engineering. New engineers cite the portal as their primary onboarding tool.
Year 2+: The portal is organizational infrastructure in the same way Slack is organizational infrastructure. Platform team is building new features rather than maintaining basics. Cost visibility, capacity planning, and incident history are integrated. External teams are requesting integrations.
That timeline assumes consistent investment. Platforms that get deprioritized in months 4-6 typically stall at the catalog phase and never reach the self-service phase where the real leverage lives.
What I Would Do Today
If I were starting a new platform team at a 200-engineer company right now, I would evaluate Port seriously before committing to Backstage. Port’s setup speed would let me show value in weeks and get budget and headcount for the second year of the work. I would use that second year to determine whether Port’s constraints were a problem or whether we had outgrown them.
If I were starting at a 1000-engineer company with five platform engineers already, I would probably go with Backstage plus Roadie to reduce the operational maintenance burden while keeping the ecosystem flexibility. The 1000-engineer company almost certainly has enough unusual requirements that a commercial product’s edges would become painful.
Whatever platform I chose, I would not build the scaffolding templates before the catalog was accurate. And I would not measure success by whether the portal was beautiful. I would measure it by whether a new engineer on their first day could find the service they were assigned to debug, understand who owned it, and open a PR in the right repository. If they can do that in under ten minutes without asking anyone, the portal is working.
The internal developer portal problem is ultimately a knowledge management problem dressed up as a tooling problem. The tools help. But the tools only work when your organization has invested in keeping the knowledge accurate and current. That investment is organizational, not technical. No SaaS product ships a shortcut for it.
For teams building out self-service infrastructure beyond the portal layer, Crossplane’s Kubernetes-native approach to cloud provisioning and Temporal’s durable workflow engine are both worth understanding as backend primitives that IDPs can expose through their self-service action systems.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.