I spent the better part of twenty years watching teams adopt and then abandon service meshes. Not because the technology was bad at what it did. Mutual TLS between every pod, automatic traffic encryption, L7 observability, fine-grained authorization policies: these are genuinely useful capabilities. The problem was always the tax you paid to get them.
At a mid-sized fintech in 2021, we calculated the overhead at onboarding time. Every pod got an Envoy sidecar consuming 50-100 MB of memory and a non-trivial slice of CPU. On a cluster running 400 pods across 30 services, that was conservatively 20 GB of memory and meaningful CPU headroom gone before our actual application did a single unit of work. The ops team called it “paying the Istio rent.” At some point, someone always asks whether the rent is worth it.
Most teams answered “no” and either limped along with a half-configured mesh or ripped it out entirely. I watched the same pattern repeat at company after company. The potential was real. The operational reality was not.
In 2024, the Istio project shipped ambient mesh. It is the architectural rewrite that changes the calculus entirely. By late 2025, teams that had previously written off service mesh were revisiting it. In 2026, ambient mode has reached what I would call confident production maturity for single-cluster workloads. Here is what actually changed, why it matters, and how to think about adopting it.
Why Sidecars Were Always a Flawed Model
To understand why ambient mesh is significant, you need to understand why the sidecar model is structurally problematic. The existing service mesh overview covering Istio and Linkerd explains the concept well, but ambient mesh represents a genuinely different architecture rather than an incremental improvement to what came before.
Traditional Istio, Linkerd, and every first-generation service mesh worked by injecting a proxy container into every application pod. Istio used Envoy. Linkerd used its own lightweight proxy. The proxy intercepted all inbound and outbound traffic via iptables rules, transparently applying policies, collecting telemetry, and terminating mTLS.
The elegance of this model is that it requires no application changes. The application speaks plaintext to localhost. The sidecar handles encryption, retries, circuit breaking, and observability. Clean separation of concerns on paper.
The problems are structural, not implementation-level:
Resource overhead compounds at scale. Each sidecar consumes CPU and memory independently of whether it has any traffic. A pod doing nothing still pays the full proxy tax. At low scale, manageable. At 500 pods, you are running a meaningful shadow infrastructure whose sole purpose is to operate the mesh.
Rollout requires pod restarts. Adding or upgrading the mesh means restarting every pod to inject or update the sidecar. For large clusters with stateful workloads, this is painful. For organizations with strict change management, it is a coordination nightmare.
Latency increases are unavoidable. Every packet traverses an extra network hop: application to sidecar, sidecar to destination sidecar, destination sidecar to destination application. For high-throughput, latency-sensitive services, those two extra hops accumulate. I have seen 2-5ms added to P99 latencies from the proxy chain alone in production.
Debugging surface expands dramatically. When something goes wrong, you now have Envoy configuration issues, mTLS certificate problems, and iptables rules all potentially involved. I have spent hours on incidents where the actual problem was a sidecar injection webhook failing silently on a new node.
These are not problems that better Istio code can fix. They are inherent to injecting proxies into every application pod. That is the root cause ambient mesh addresses.
How Ambient Mesh Actually Works
Ambient mesh removes sidecars from the picture entirely. It splits service mesh functionality into two distinct layers deployed at the infrastructure level, not the application pod level.
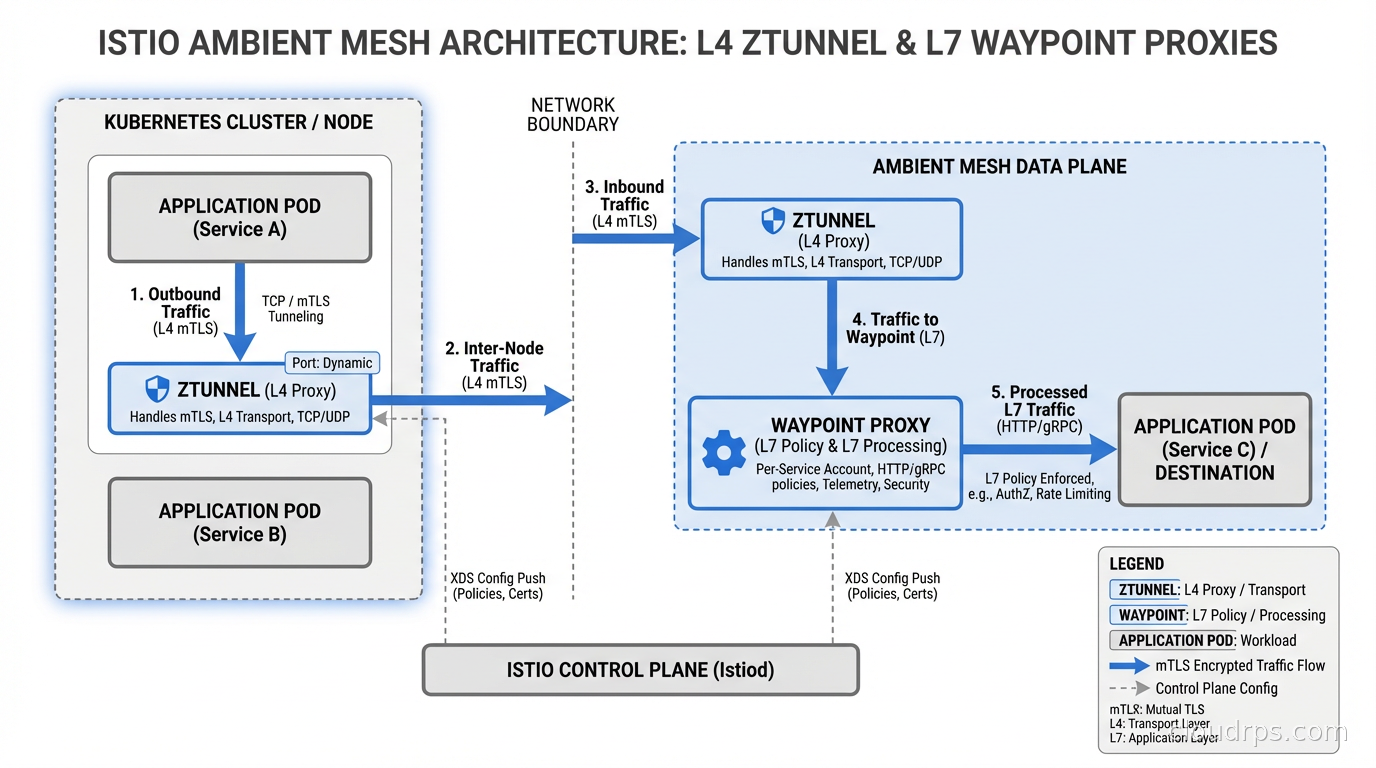
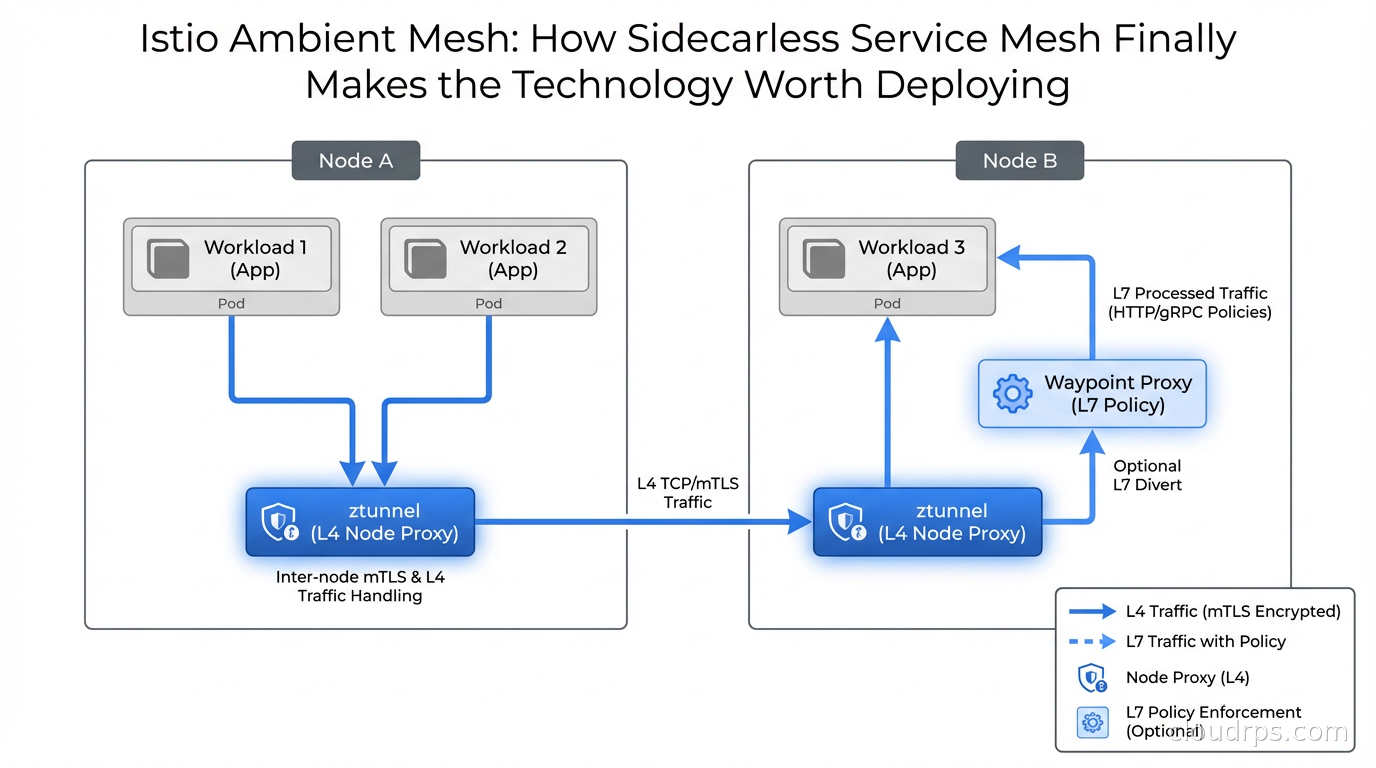
The first layer: ztunnel (zero-trust tunnel)
ztunnel is a lightweight per-node proxy deployed as a DaemonSet, one instance per Kubernetes node. It handles all L4 security: mutual TLS between all workloads, transport-layer telemetry, and simple authorization policies.
When a pod sends traffic to another pod, ztunnel on the source node intercepts it, establishes an encrypted HBONE (HTTP-Based Overlay Network Environment) tunnel to ztunnel on the destination node, and delivers the traffic securely. Neither application pod sees plaintext traffic leave the node boundary. All mTLS is handled by ztunnel transparently.
The resource cost of ztunnel is dramatically lower than per-pod sidecars. You pay for one proxy per node rather than one proxy per pod. On a 20-node cluster running 500 pods, you go from 500 proxy processes to 20. That math alone explains why ambient mode posts resource reductions in the 60-70% range for most real-world deployments.
The second layer: waypoint proxies
For L7 capabilities (HTTP routing, header-based authorization, retries, circuit breaking, traffic splitting), ambient mesh uses waypoint proxies. These are per-service-account or per-namespace Envoy proxies you opt into only when you actually need L7 features.
This is the part that matters most for cost-conscious teams: if you only need mTLS and basic telemetry, you deploy zero waypoint proxies. You get L4 security for free via ztunnel at dramatically reduced overhead. If a specific service needs HTTP-level policies (rate limiting, JWT validation, traffic mirroring), you deploy a waypoint proxy for that service alone.
The result is a tiered cost model. Low-value services pay almost nothing. High-value services that need rich L7 policies pay for that selectively. You stop paying for capabilities you do not use.
Why HBONE matters
The communication between ztunnel instances uses HBONE, which tunnels arbitrary TCP traffic over HTTP/2 with mTLS. This is significant for observability. Because all inter-node traffic flows through a defined tunnel protocol, you get structured telemetry without application involvement. Every connection produces metrics, traces, and logs at the ztunnel layer.
If you have worked with eBPF-based networking and observability, the mental model is similar: infrastructure-level instrumentation that does not require application cooperation. The application stays clean. The platform provides the observability. Your developers write services, not network code.
Real-World Performance Numbers
The benchmarks are compelling but they require careful interpretation. Performance depends heavily on workload characteristics, cluster size, and which features you actually use.
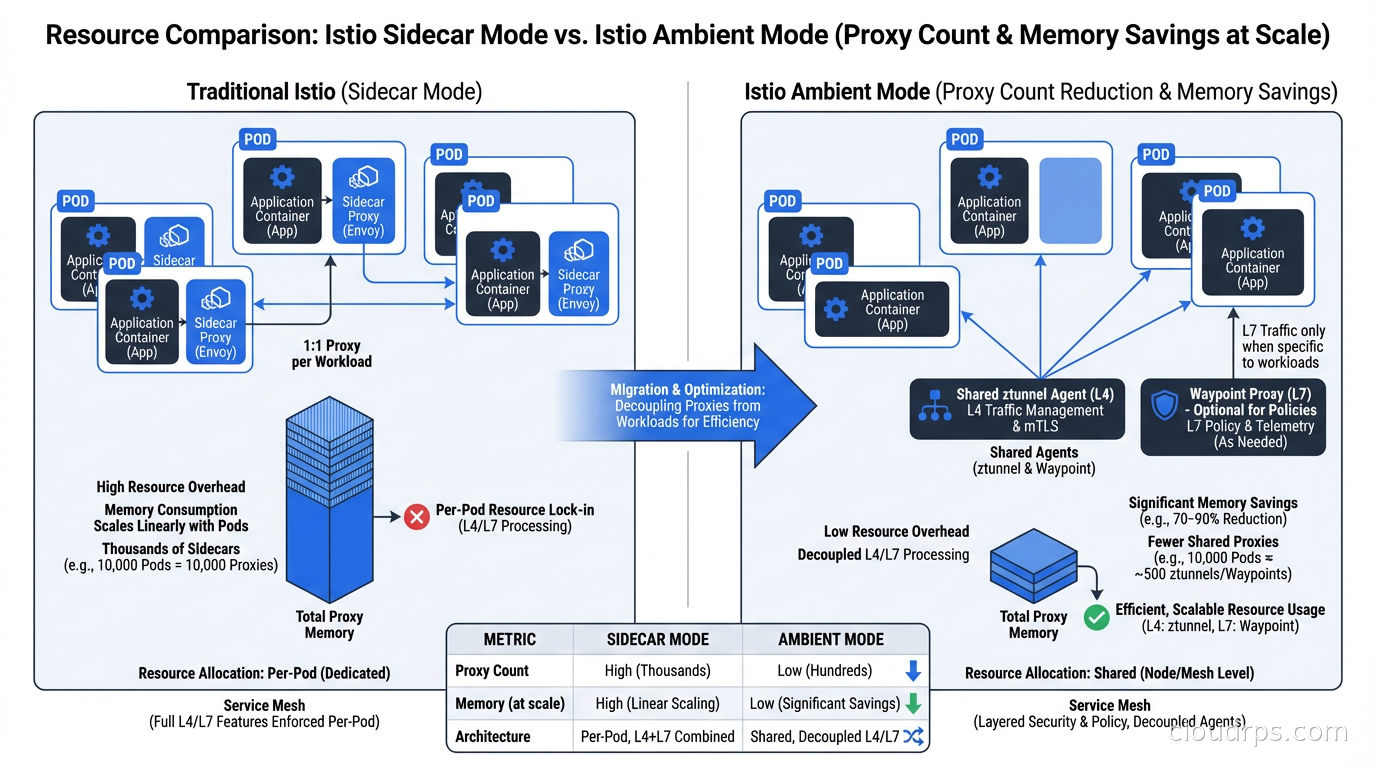
Consistent findings across the Istio project benchmarks and independent measurements:
- 60-75% reduction in data-plane memory consumption for typical workloads
- 30-50% reduction in CPU overhead for typical workloads
- Latency improvements ranging from marginal to significant depending on request patterns
I have run ambient mesh against production-like workloads where sidecar mode was consuming roughly 18 GB of memory for proxy processes across a 30-node cluster. The same workload under ambient mode ran ztunnel at under 5 GB total. That freed capacity either translates to smaller node counts (direct cost savings) or to more headroom for actual application workloads.
Where ambient mesh does add latency compared to running no mesh at all is the ztunnel HBONE tunneling overhead. For most services this is noise: under 0.5ms in typical benchmarks. For extremely latency-sensitive, high-throughput gRPC services doing sub-millisecond P99 work, benchmark carefully before committing.
The waypoint proxy latency profile is worth understanding separately. When you opt a service into L7 processing, traffic routes through an additional Envoy proxy. For services that were already running sidecar-mode Envoy, this is roughly a wash on latency since you are replacing two sidecar hops with one waypoint hop. For services coming from no mesh at all, adding a waypoint adds overhead comparable to what a sidecar would have added. The difference is you only pay that cost on services that genuinely need L7 features.
One operational note: the waypoint proxy is a standard Kubernetes Deployment. It scales horizontally. For high-traffic services, you can set replica counts and resource limits explicitly. This is a significant improvement over sidecar mode where you had no direct control over the Envoy proxy sizing in individual pods.
Migrating from Sidecar Mode to Ambient
This is where most teams I talk to have the hardest questions. If you have an existing Istio sidecar installation serving production traffic, how do you migrate without a big-bang cutover?
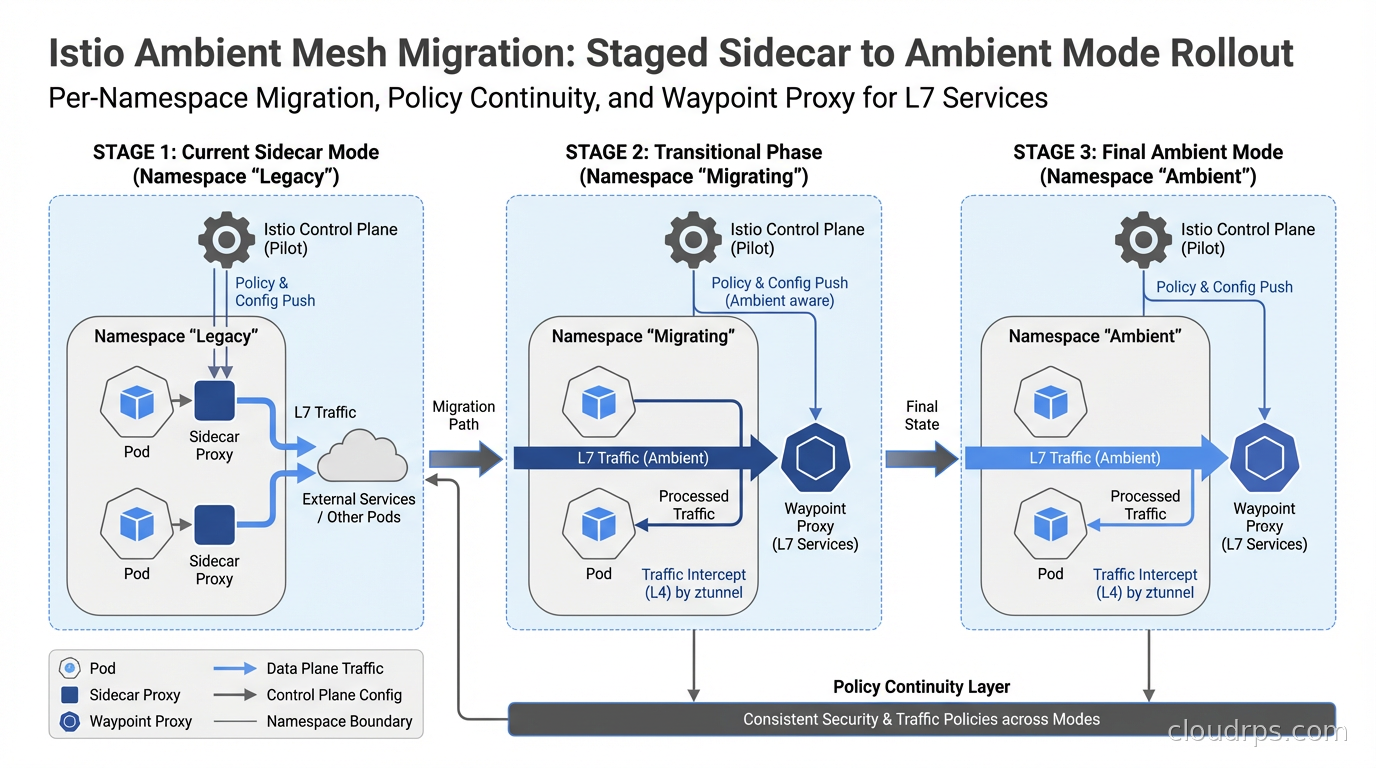
Ambient mesh and sidecar mode are interoperable within the same Istio-managed cluster. Istio 1.21 and later support running both modes simultaneously. This means you can migrate namespace by namespace, or even service by service, over time.
The migration sequence I have validated in production-like environments:
Step 1: Install ambient components alongside your existing control plane. Deploy the ztunnel DaemonSet and updated CNI plugin. Your existing sidecar pods are completely unaffected at this stage. There is no traffic impact.
Step 2: Audit your existing AuthorizationPolicies before touching any namespaces. This step saves you from surprises. Run istioctl analyze on your policy objects. Identify which policies use HTTP-layer conditions (methods, paths, headers, JWT claims) versus transport-layer conditions (source principal, namespace, IP ranges). HTTP-layer policies require a waypoint proxy. Transport-layer policies work at ztunnel natively.
Step 3: Migrate low-criticality namespaces first. Label the namespace with istio.io/dataplane-mode: ambient and remove the istio-injection: enabled label. Existing pods immediately start using ztunnel for their traffic. No pod restarts are required for the ztunnel takeover itself. You will need pod restarts later to remove the now-unused injected sidecar containers and reclaim their memory.
Step 4: Deploy waypoint proxies for services requiring L7 policies. For each service account that had HTTP-layer AuthorizationPolicies, create a Gateway resource with gatewayClassName: istio-waypoint to provision a waypoint. The waypoint integrates natively with Kubernetes Gateway API, which is the right long-term investment for traffic management in any Kubernetes environment.
Step 5: Roll production namespaces progressively. By this point you have the migration pattern well understood from lower-stakes namespaces. Production rollout becomes procedural.
One thing I want to be direct about: the migration is not zero-friction. Policy auditing takes time. You will hit edge cases around how PeerAuthentication objects translate to ambient mode (most behaviors are preserved, but the model is subtly different). You may find that some of your policies were never actually doing what you thought they were, which is useful information but occasionally alarming to discover.
The payoff is that this is a one-time cost. Once fully on ambient, you never manage sidecar injection again. Pod restarts for routine updates do not involve proxy version concerns. Scaling up adds capacity without proxy overhead. The operational surface shrinks significantly.
Comparing Ambient Mesh, Linkerd, and Cilium in 2026
Teams evaluating service mesh options in 2026 have three serious contenders. Here is an honest assessment of each.
Istio Ambient Mesh is the right choice if you need the richest L7 policy model, are already invested in the Istio ecosystem, or need broad CNI compatibility. Ambient mode works with essentially any CNI plugin including Flannel, Calico, and AWS VPC CNI. The tradeoff is complexity: Istio’s policy model is powerful but verbose. Istiod is still a meaningful control plane component to operate, and the learning curve for the full policy model is steep.
Linkerd remains compelling for teams that want simplicity above all. Linkerd’s proxy is purpose-built in Rust and lighter than Envoy even in sidecar mode. Linkerd has been shipping sidecarless capabilities via its own eBPF-based node proxy work, though it is less mature than Istio’s ambient mode as of early 2026. If your requirements are basic mTLS, observability, and simple retries without complex authorization policies, Linkerd’s operational simplicity often wins the argument.
Cilium with Hubble observability is the right choice if you want to consolidate CNI and service mesh into a single eBPF-based control plane. As I covered in depth in the article on Kubernetes CNI plugins and network policies, Cilium’s kernel-native approach means it can enforce network policies without any userspace proxy overhead at all. The tradeoff is that Cilium’s service mesh L7 feature set is less complete than Istio’s, and you are betting on a single vendor’s roadmap for both networking and mesh capabilities. For a deeper look at what Cilium brings as a production networking platform, the Cilium production guide walks through kube-proxy replacement, Hubble observability, and Tetragon security enforcement in detail.
My honest recommendation: if you are starting from scratch and want the best long-term coverage of enterprise security requirements, Istio Ambient is where to put your energy. If you are a lean team that needs mTLS and observability without operational overhead, Linkerd. If you are already running Cilium as your CNI, use Cilium’s service mesh mode rather than introducing a second control plane. Do not run two mesh systems. The operational complexity compounds faster than the benefit.
Production Hardening You Cannot Skip
Before labeling your first namespace and calling it done, there are production considerations that trip up teams repeatedly.
Certificate management architecture. ztunnel manages mTLS certificates via the Kubernetes CSR API or an Istio-integrated certificate authority. The default is istiod’s built-in CA. For production, integrate with an external CA: HashiCorp Vault, AWS ACM Private CA, or Google Certificate Authority Service. The same principles that apply to secret management in cloud infrastructure apply here. Your certificate hierarchy must be auditable, rotation must be automated, and you must know exactly how long a compromised certificate would remain valid before being rotated out.
Security tool compatibility. Tools that rely on sidecar injection for security telemetry may need reconfiguration. If you are running Falco for container runtime security, check whether your Falco rules depend on observing network traffic through sidecar syscalls. Ambient mesh shifts where in the stack traffic is observable: from per-pod sidecar to per-node ztunnel. Your Falco rules may need updating to reference the ztunnel process rather than per-pod Envoy instances.
Multi-cluster topology limitations. Single-cluster ambient mesh is production-ready in Istio 1.22 and later. Multi-cluster ambient with flat networking (same VPC or interconnected VPCs with unified Pod CIDR) works reliably in 1.24. Multi-cluster with distinct network segments (non-flat networking) is still maturing. If you are designing a multi-region active-active architecture that depends on service mesh policies spanning clusters, test your specific topology exhaustively before committing to ambient in that configuration.
Policy regression testing. Before migrating any namespace, write explicit integration tests that verify your authorization policies are working as intended. Service mesh security is only valuable if you can verify that unauthorized service-to-service calls are actually being rejected. I have found policy gaps during ambient migrations that had also been silently failing in sidecar mode. The migration is an opportunity to audit, not just a migration.
Resource limits for ztunnel. ztunnel is a DaemonSet. On large nodes with high pod density and significant traffic, ztunnel memory usage grows. Set resource requests and limits on ztunnel, and monitor it as you would any other critical infrastructure component. A ztunnel OOMKill is a node-wide network disruption event, not a per-pod impact.
Why This Changes the Zero Trust Calculus
I want to close with what I think is the most underappreciated aspect of ambient mesh.
For most of the past decade, implementing zero trust security at the network layer in Kubernetes meant one of three things: require every application team to implement mTLS themselves (politically difficult and operationally inconsistent), deploy a service mesh and pay the sidecar tax (economically painful), or accept that east-west traffic in your cluster was effectively unencrypted and unauthenticated (the choice most teams made by default).
Ambient mesh removes that false dilemma. When you can get wire-level mTLS between every pod for the cost of a per-node DaemonSet with modest memory requirements, the cost-benefit analysis shifts materially. You are paying a fixed infrastructure cost that scales with nodes, not workloads. A cluster with 10 nodes and 500 pods pays 10 ztunnel instance costs, not 500 sidecar costs.
For teams building internal developer platforms, ambient mesh enables delivering authenticated, encrypted service communication as a platform capability rather than an application requirement. Your developers write services. The platform handles the encryption and identity enforcement. Security teams get the audit trail they need. Neither group has to negotiate over sidecar injection configuration.
The sidecar model served its purpose for a decade. It proved that service mesh as a concept was worth building. It delivered mTLS and observability at scale when the only alternative was “add TLS everywhere in application code.” But the operational cost was always too high for most teams at most scales.
Ambient mesh is the architecture that makes the concept worth operating broadly. If you evaluated Istio three or four years ago and walked away because the operational complexity did not justify the security benefit, the math has genuinely changed. The technology is not just incrementally better. The underlying architecture is fundamentally different.
For net-new Kubernetes deployments in 2026, I would not start with sidecar-mode Istio. I would start with ambient mode or not start with Istio at all. The choice between service mesh and no service mesh used to be a resource and complexity question. With ambient mesh, it is primarily a question of whether you need what the mesh provides: mTLS, identity-based authorization, and structured observability across service-to-service communication. If you do need those things (and most production systems eventually do), the barrier to getting them has finally dropped to a level where the answer can comfortably be yes.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.