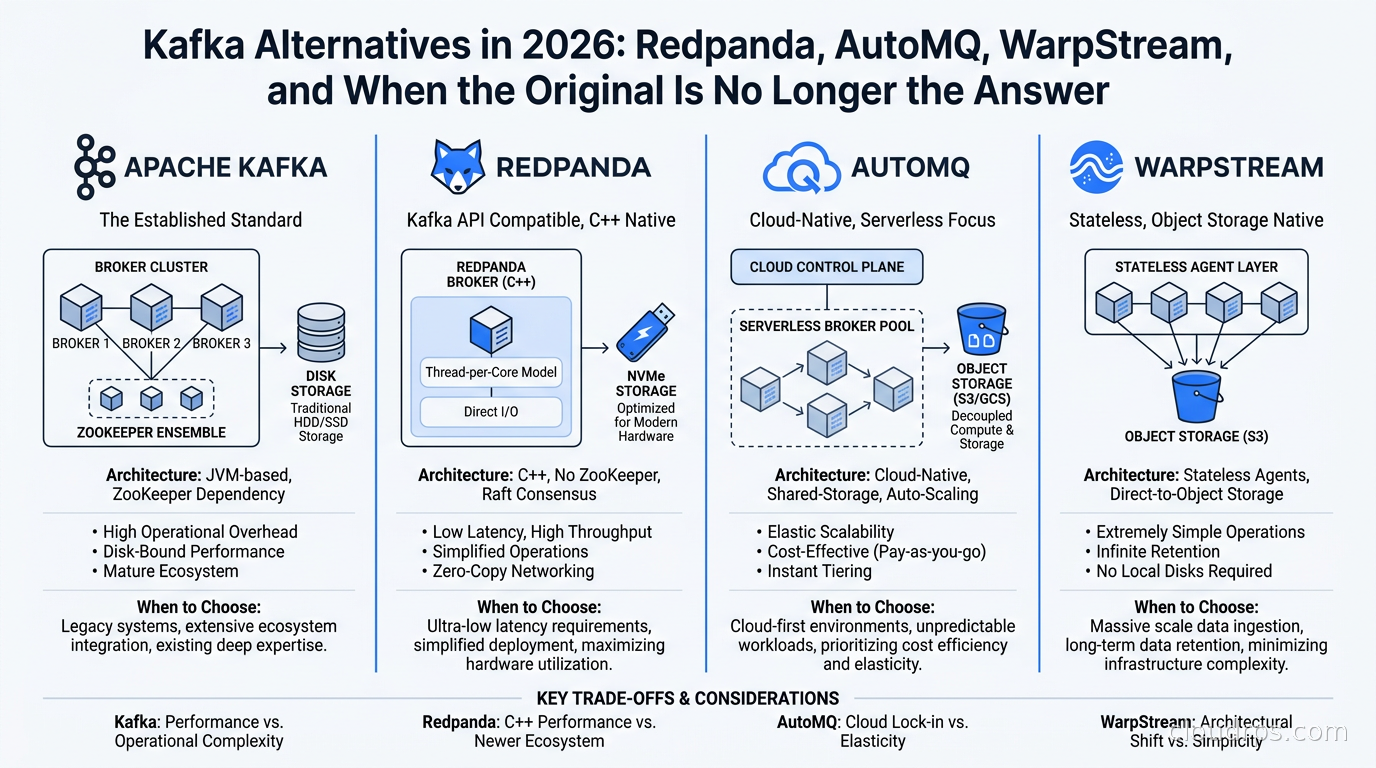
Three in the morning. My phone rings. The ZooKeeper quorum on our primary Kafka cluster has lost a node, the leader election is stalled, and three downstream services are buffering messages with nowhere to put them. I have been doing this for twenty years, and I can tell you with absolute certainty: that call is not about distributed systems theory. It is about operational complexity that nobody budgeted for.
That was 2019. By 2021 we had moved to KRaft mode in staging. By 2023 we had a Redpanda cluster in production for our latency-sensitive path. Today I run a mixed fleet and I have strong opinions about when each tool earns its keep. The Kafka ecosystem has changed dramatically, especially with the release of Kafka 4.0 and the emergence of serious alternatives that were not ready for prime time two years ago. Let me walk you through what I have actually seen work.
The Kafka Tax Nobody Fully Admits
Apache Kafka is extraordinary software. I have built systems on it that processed hundreds of billions of events per day, and it delivered. But there is an honest accounting that does not always make it into the architecture decision docs.
The JVM is the first tax. Kafka brokers are memory-hungry, and JVM garbage collection pauses translate directly into latency spikes. You can tune G1GC or ZGC until you are blue in the face, and you will still see tail latencies in the hundreds of milliseconds during compaction. For most use cases that does not matter. For payment processing, real-time fraud detection, or anything driving a user-facing interface, it absolutely does.
The second tax is operational complexity. Even after Kafka 4.0 finally retired ZooKeeper in favor of the native KRaft consensus layer, running Kafka in production requires serious investment. You need to understand partition rebalancing, ISR (in-sync replica) management, retention policies, log compaction, and consumer group offset management. When something goes wrong, the blast radius is significant. The tools have gotten better but the knowledge requirement has not dropped.
The third tax is cost architecture. Kafka was designed for on-premises deployment on fast local SSDs with predictable I/O. In the cloud, that model gets expensive quickly. Each broker needs EBS-backed storage sized for your peak retention window. Partition counts multiply replication traffic. Cross-AZ replication, which you absolutely need for production, generates egress charges at cloud provider rates. A cluster handling 2 GB/s of ingest with three replicas spread across availability zones can generate surprising monthly bills before you have written a single consumer. See our guide on cloud egress costs for the math on why this compounds faster than most teams expect.
None of this means you should abandon Kafka. It means you should know what you are buying. And in 2026, the alternatives have matured enough that for some workloads, you are buying too much.
Kafka 4.0 and What Actually Changed
Before diving into alternatives, let us acknowledge what Kafka 4.0 actually delivered. The removal of ZooKeeper is not a minor cleanup, it is a significant architectural simplification. ZooKeeper was a distributed coordination service that Kafka used for broker registration, leader election, and configuration management. Running it separately meant two systems to monitor, two failure domains to manage, and a set of ZooKeeper-specific operational knowledge that had nothing to do with streaming.
KRaft (Kafka Raft) replaces all of that with a consensus protocol built directly into the broker. The controller is now a first-class Kafka role, the metadata is replicated through the Kafka protocol itself, and single-binary deployments are finally achievable. Kafka 4.0 also shipped significant improvements to partition scalability, with the practical limit on partitions per cluster increasing substantially due to reduced controller overhead.
This matters for the alternatives discussion because ZooKeeper removal was Redpanda’s loudest architectural claim for years. “We don’t need ZooKeeper” was half their pitch deck. That advantage evaporated on the day Kafka 4.0 shipped.
Redpanda: The C++ Rewrite That Found a New Identity
Redpanda started as a Kafka-compatible streaming platform written in C++ using the Seastar framework. No JVM, no garbage collection, one thread per core. The architecture is genuinely different: each CPU core owns a fixed set of partitions and an independent networking stack, which eliminates cross-core synchronization overhead and produces remarkably consistent tail latencies.
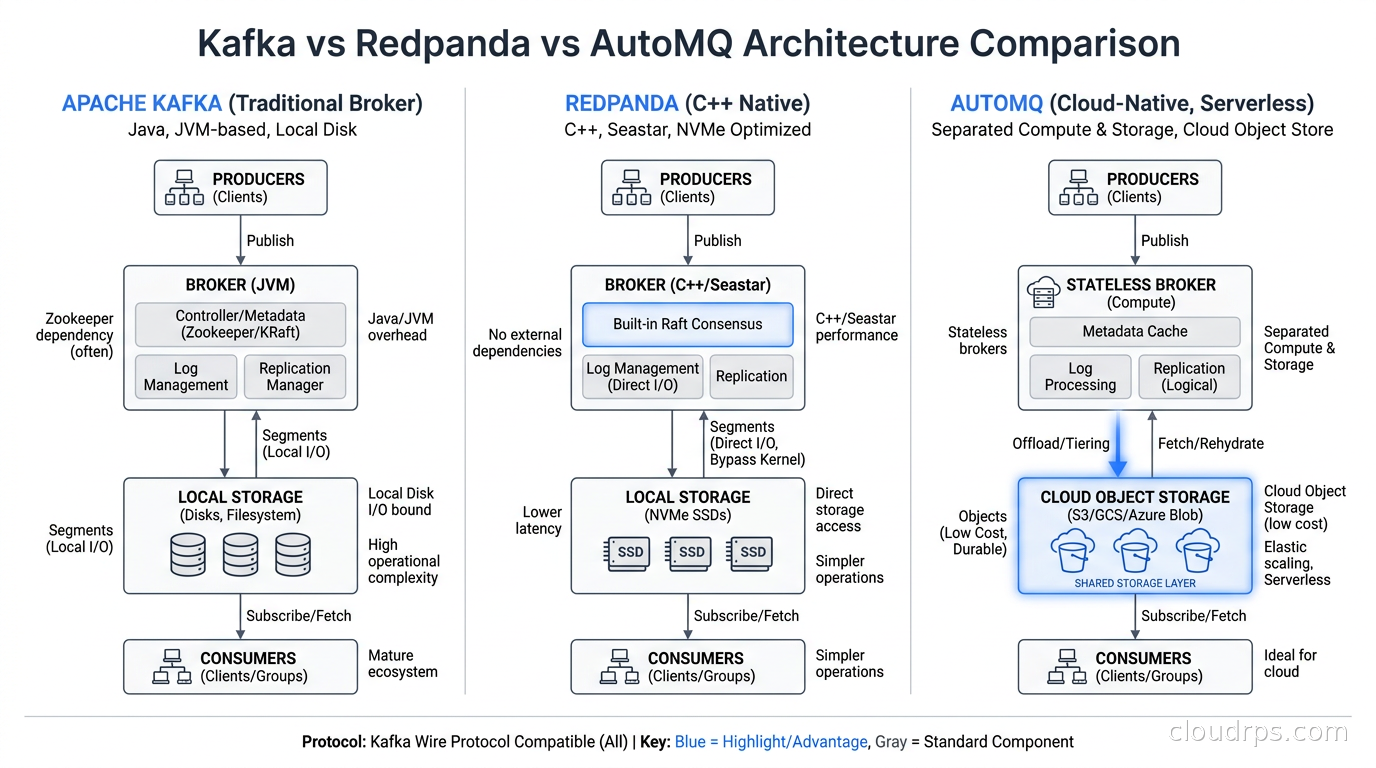
I ran benchmarks on Redpanda in 2022 that showed p99 write latencies of around 5ms at 500k messages per second on commodity hardware, compared to Kafka’s 40-80ms p99 on equivalent hardware with equivalent tuning. That gap was real. For latency-sensitive workloads, Redpanda genuinely delivered.
The Kafka compatibility story is also solid. Redpanda implements the Kafka wire protocol, so your existing producers, consumers, and administrative tooling work without modification. I have migrated Kafka workloads to Redpanda without touching a line of application code. The Schema Registry API is compatible. Kafka Connect connectors run against it. In practice, the main compatibility friction I have encountered is around Kafka Streams applications, which rely on internal topics that Redpanda handles slightly differently.
So why am I not recommending Redpanda for everything? A few reasons.
The first is the 2026 pivot. Redpanda has rebranded its product as the “Agentic Data Plane,” positioning Kafka compatibility as a legacy feature and emphasizing AI agent workflows, data pipelines for LLM applications, and real-time feature stores. This is a reasonable strategic bet, but it signals something about where the company’s development focus is going. If you are betting a production architecture on a vendor, the vendor’s roadmap alignment with your use case matters.
The second is that Redpanda’s managed cloud offering, Redpanda Cloud, is still catching up in enterprise features compared to Confluent Cloud. Things like fine-grained RBAC, audit logging depth, and geographic availability have improved but lag the more mature managed Kafka services. If you need a fully managed experience with enterprise support contracts, this is a real consideration.
Where Redpanda wins today: latency-critical workloads where you own the infrastructure, teams that want Kafka compatibility without the JVM operational burden, and edge or embedded deployments where you need a single binary with minimal resource overhead. Think gaming backends, financial order books, IoT edge gateways, and real-time feature computation pipelines.
AutoMQ: Object Storage Changes the Cost Equation
AutoMQ is the most interesting new entrant in this space and the one I have spent the most time with recently. The core insight is simple: cloud object storage (S3, GCS, Azure Blob) is three orders of magnitude cheaper than provisioned SSD storage, and modern object storage performance is good enough to support streaming workloads if you are smart about how you use it.
AutoMQ implements the Kafka protocol but redesigns the storage layer around tiered storage with object storage as the primary tier. Data is written to local SSDs briefly for immediate consumer reads, then flushed to S3 within seconds. The local disk footprint shrinks to a rolling buffer rather than a full retention window. A Kafka cluster that needs 50TB of EBS storage for a 7-day retention policy might need only 200GB of local storage in AutoMQ, with S3 handling the rest at roughly 3-5% of the per-GB cost.
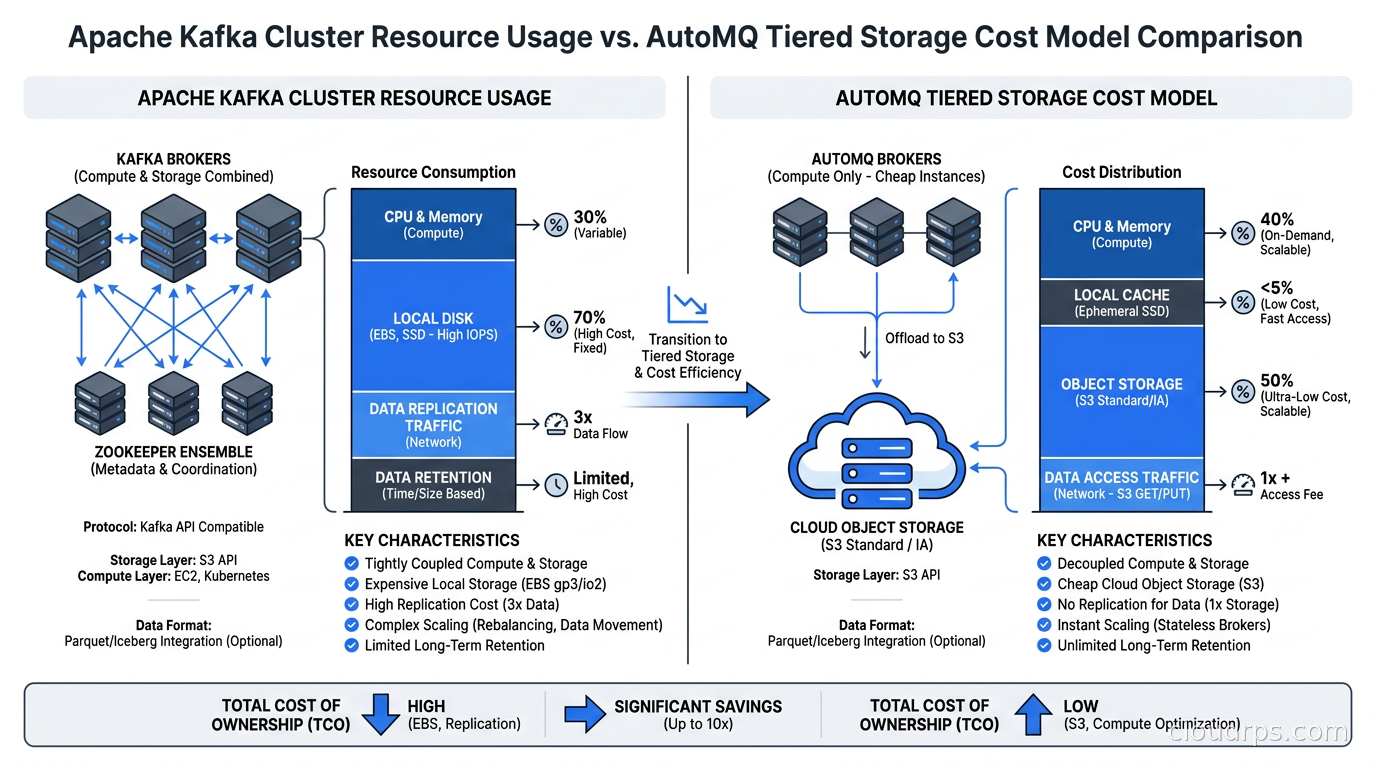
The cost implications are significant. I have seen teams report 70-85% reductions in streaming infrastructure costs after migrating to AutoMQ, particularly for workloads with long retention requirements and bursty consumption patterns. Compliance use cases that need 90-day or 365-day retention in Kafka are particularly brutal on storage costs. AutoMQ makes those architectures economically sane.
AutoMQ also handles cluster scaling better than traditional Kafka. Because the storage layer is decoupled from the compute layer, you can scale brokers up and down without rebalancing partitions across disks. Adding a broker does not trigger the expensive partition reassignment process that can degrade Kafka cluster performance for hours. For teams running Kubernetes-based deployments, this elastic scaling behavior is genuinely useful.
The tradeoffs are real. S3 has higher read latency than local SSD, which means consumer latency is higher for data that has been tiered. For use cases where consumers are processing recent events, the local cache usually handles this. For consumers replaying historical data or catching up after a lag, you are working against object storage round-trip times. AutoMQ has improved its prefetching and caching logic substantially, but if you need sub-millisecond consumer latency, AutoMQ is not your tool.
The other consideration is S3 API request costs. Object storage pricing has two components: storage and API requests. High-throughput streaming workloads generate significant GET and PUT request volumes, and those charges can surprise teams that only modeled storage costs. For workloads above roughly 500 MB/s sustained throughput, the request cost math deserves careful modeling.
For your stream processing pipelines that use Apache Flink, AutoMQ works well as the transport layer. The Kafka API compatibility means no changes to your Flink application code.
WarpStream: BYOC Streaming on Your Own Object Storage
WarpStream took a similar object-storage-first approach but with a distinct deployment model. The WarpStream agents run in your cloud account, reading and writing to your S3 bucket, while the control plane is managed SaaS. Confluent acquired WarpStream in late 2024, and the product is now offered as part of the Confluent portfolio.
The BYOC (bring your own cloud) model is genuinely valuable for certain regulatory environments. Your message data never leaves your cloud account. The egress costs that come from shipping data to a vendor-hosted managed Kafka service disappear. Audit trails stay within your existing cloud security perimeter. For heavily regulated industries, this can be the deciding factor.
Post-acquisition, WarpStream has access to Confluent’s ecosystem: Schema Registry, ksqlDB, Kafka Connect managed connectors, and enterprise support infrastructure. This makes the managed experience significantly more complete than it was as an independent product. The downside is vendor lock-in and pricing that reflects the Confluent enterprise model rather than the scrappy startup that WarpStream was. If Schema Registry is a critical dependency for your streaming infrastructure, it is worth understanding your alternatives: Apicurio, AWS Glue Schema Registry, and Redpanda’s built-in registry are all viable options depending on your deployment context and how much exposure you want to IBM’s enterprise pricing model.
Apache Pulsar: The Road Not Often Taken
I would be incomplete without mentioning Apache Pulsar, which has been quietly gaining adoption in China (Tencent, Xiaomi, and others run it at enormous scale) and in enterprise environments that need multi-tenancy at the topic namespace level. Pulsar separates compute (brokers) from storage (BookKeeper) natively, which predates the tiered storage trend by years.
The honest assessment: Pulsar has genuine architectural advantages in multi-tenancy and geo-replication, but the operational complexity is higher than Kafka, not lower. BookKeeper is a sophisticated distributed ledger that requires its own operational expertise. The ecosystem is smaller, the tooling is less mature, and the talent pool is thinner. Unless you have specific requirements around hierarchical topic namespaces or built-in multi-tenancy that map directly to Pulsar’s architecture, the switching cost usually does not pencil out.
The Decision Framework
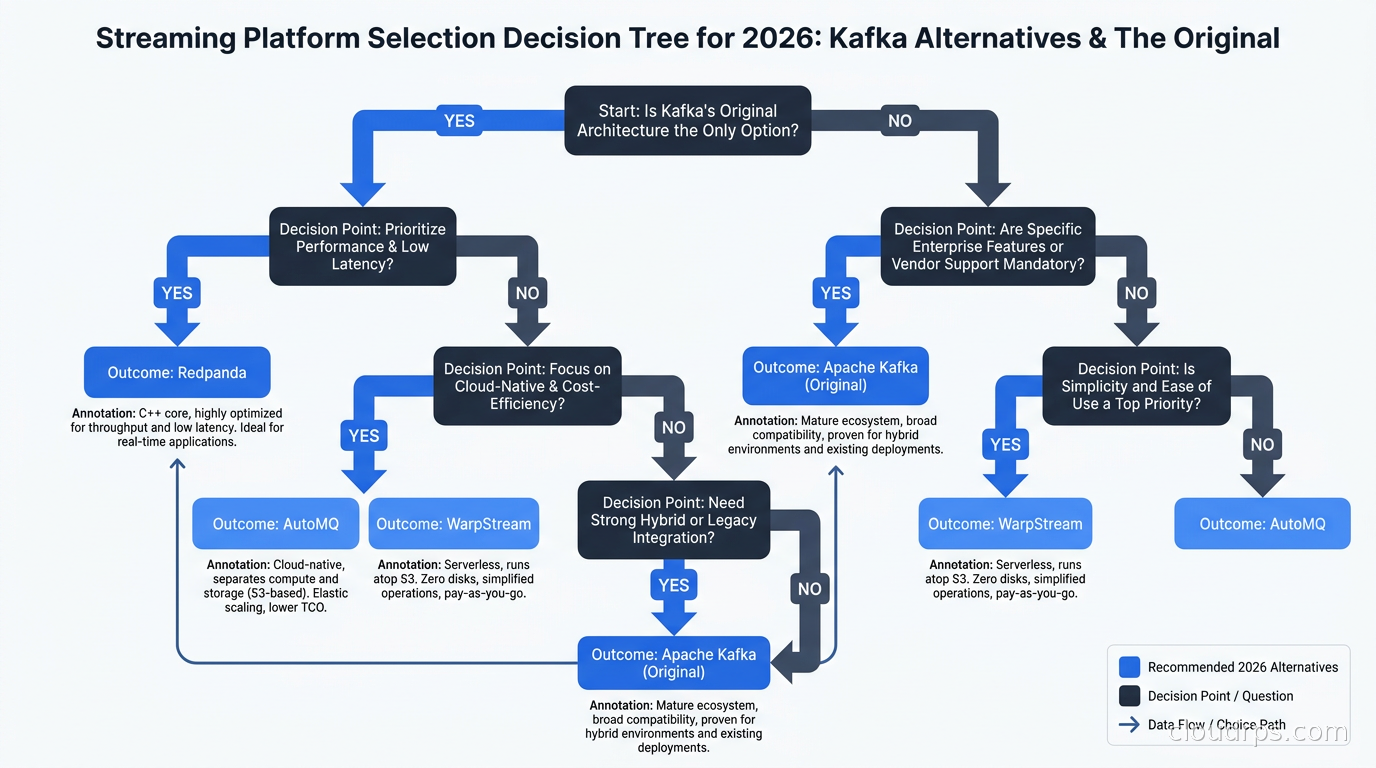
After running various combinations of these systems in production, here is how I actually make the choice:
Stay with Kafka (or upgrade to Kafka 4.0) when you have an existing investment in the Kafka ecosystem, established operational knowledge, and workloads that do not have extreme latency sensitivity or extreme cost pressure on retention. If you are using Kafka Connect for change data capture pipelines with Debezium, the connector ecosystem maturity is hard to replicate. If your team uses Kubernetes operators like Strimzi to manage Kafka, the tooling has matured significantly and there is less reason to leave.
Choose Redpanda when tail latency is a hard requirement, not a preference. If you are building a real-time trading system, a fraud detection pipeline where each millisecond of delay has financial consequences, or a gaming backend where player experience degrades visibly above 10ms event processing latency, the Seastar-based architecture earns its keep. Also consider Redpanda when you want Kafka compatibility without the JVM, particularly for resource-constrained deployments.
Choose AutoMQ when storage cost is the primary pain point, especially for workloads with long retention requirements or highly variable throughput. Compliance workloads that need year-long retention, analytics pipelines that need months of replay history, and bursty workloads that would require significantly over-provisioned Kafka clusters to handle peak load are AutoMQ’s strongest cases. If you are already storing analytical data in Apache Iceberg on your data lakehouse, having your streaming layer with similar economics on the same object storage infrastructure simplifies your architecture and your bills.
Choose WarpStream (via Confluent) when you need the managed experience, have regulatory requirements that preclude shipping data to a third-party control plane, and want the depth of the Confluent ecosystem without running your own brokers. The BYOC model satisfies data residency requirements that pure managed Kafka cannot.
Migration Realities
If you are considering migrating from Kafka to any of these alternatives, the protocol compatibility reduces but does not eliminate risk. Here is what I have learned from actual migrations.
Consumer group offsets are the first thing to plan. Offsets in Kafka are stored in the __consumer_offsets internal topic. When you migrate to Redpanda or AutoMQ, those offsets need to be either migrated or your consumers need to reset to a specific timestamp. If your migration window allows a clean cutover, timestamp-based reset is usually cleaner than trying to migrate offsets. If you need zero data loss with consumers picking up exactly where they left off, plan for an offset migration tool.
Kafka Streams applications require the most testing. Because Kafka Streams uses internal state topics and changelog topics with specific naming conventions, compatibility varies. Redpanda handles most of this correctly, but edge cases exist. Full integration tests against a staging Redpanda or AutoMQ cluster before production cutover are not optional.
Transaction semantics are another area to validate. Kafka’s exactly-once semantics using transactions and idempotent producers are increasingly used in data pipelines that connect streaming to data pipeline orchestration tools. Both Redpanda and AutoMQ support Kafka transactions, but at different maturity levels. Test your specific transaction patterns in staging.
The tooling ecosystem matters for Day 2 operations. Kafka has excellent tooling for observability, including native integration with Prometheus metrics exporters, Burrow for consumer lag monitoring, and Cruise Control for partition balancing. Before committing to an alternative, verify that your monitoring stack works against the alternative’s metrics endpoints. For the observability architecture side, our guidance on building a cloud-native observability stack applies directly here: you want the same Prometheus metrics pipeline watching your streaming infrastructure that watches everything else.
The Actual 2026 Answer
The question I get asked most often is “should we move off Kafka?” After twenty years of building distributed systems and the last three watching this space closely, my honest answer is: probably not, unless you have a specific reason.
Kafka 4.0 with KRaft is a genuinely better system than Kafka 2.x was. The ZooKeeper tax is gone. The scalability improvements are real. If you are running an older version and have been living with its pain, upgrade before you migrate.
But if you are starting fresh and your workload profile fits one of the scenarios above, the alternatives have closed the maturity gap considerably. AutoMQ in particular represents a fundamentally different cost model for long-retention, bursty workloads that I would not have recommended two years ago but would today. Redpanda has proven itself in production at scale for latency-sensitive use cases.
The mistake I see most often is treating this as a religious choice rather than an engineering one. Teams that switched to Redpanda because it was new and exciting, without validating that their p99 latency actually needed improvement, created migration work for no business outcome. Teams that stayed on Kafka without evaluating their retention costs are writing checks they do not need to write.
Match the tool to the constraint. That is the only framework that survives contact with production.
One more nuance worth flagging: Redpanda, AutoMQ, and WarpStream all compete on Kafka’s home turf, which is high-throughput log streaming. If your primary use case is lightweight service-to-service event notification, request/reply patterns, or IoT telemetry with edge routing, NATS.io with JetStream is a fundamentally different model worth evaluating before committing to any Kafka-compatible system. It is not a Kafka alternative so much as a different tool for a different job.
There is also an underappreciated operational truth here: whichever streaming platform you choose, your ClickHouse or other real-time analytics database that consumes from it needs to be sized for the throughput you are delivering. The streaming layer and the consumption layer need to be codesigned, not treated as independent decisions.
The streaming wars are not over. With Confluent now owning WarpStream, with Redpanda pivoting to AI infrastructure, and with AutoMQ gaining momentum, the landscape will look different again in 18 months. Build with abstractions where you can, but do not let abstraction be an excuse to avoid understanding the underlying constraints. Kafka, Redpanda, AutoMQ, and WarpStream all make different bets about where the cost and complexity should live. The right one depends entirely on where you can afford to absorb it.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.