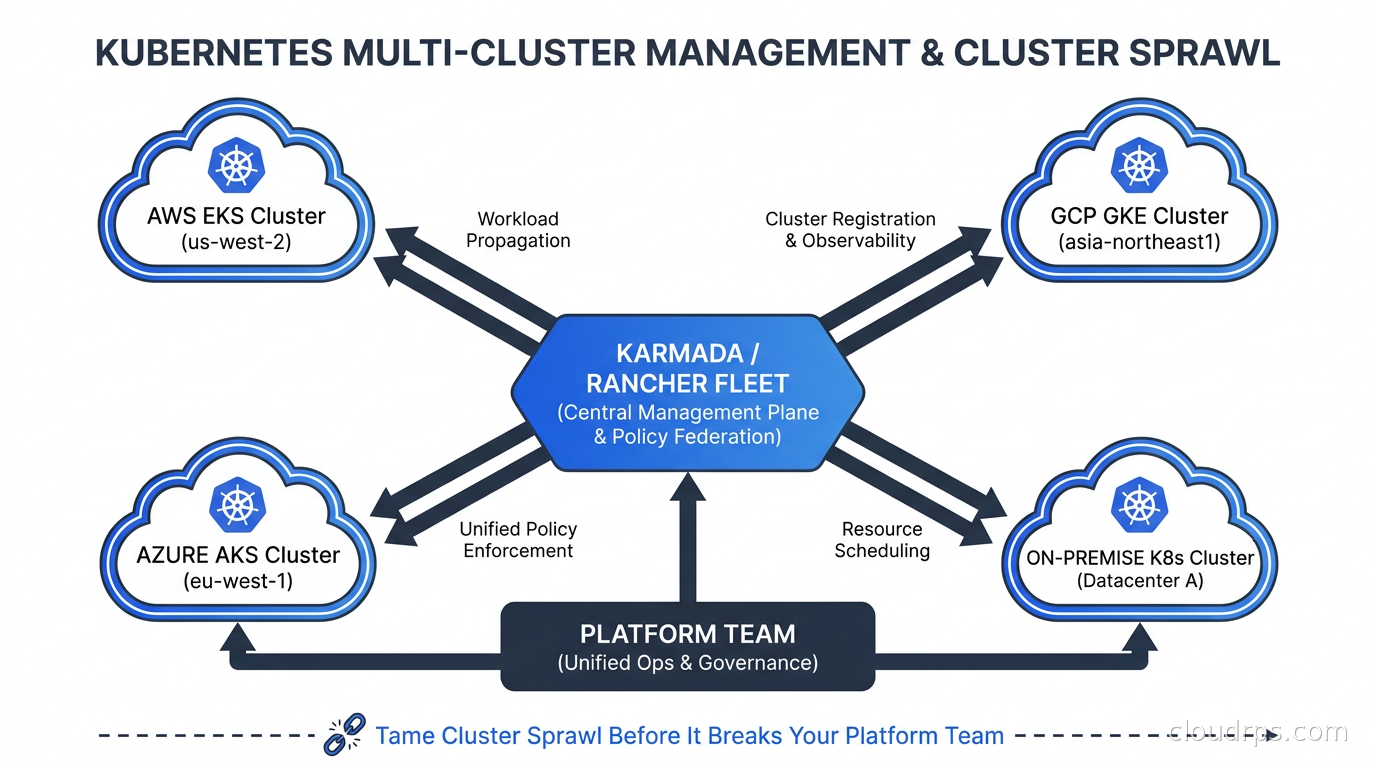
I ran my first multi-cluster Kubernetes environment in 2017. It was two clusters. One for production, one for staging. I thought I was being disciplined. By 2019 that same organization had fourteen clusters, and exactly zero of them were managed consistently. Different CNI plugins, different admission controllers, different RBAC configurations, three different versions of cert-manager running simultaneously, and a monitoring setup that required logging into six different Grafana instances to get a full picture. We called it “distributed chaos” but really it was just sprawl.
That story plays out everywhere. Start with one cluster, add a second for a different region, add a third for a compliance boundary, a fourth because a new team wanted their own environment, and suddenly you have thirty clusters with one exhausted platform team trying to keep all of them current. The Kubernetes ecosystem eventually woke up to this problem, and the solutions are now mature enough to be worth building around. Here is what I have learned about multi-cluster management after doing it the wrong way first.
Why You End Up With Many Clusters
Before discussing tools, it helps to understand why organizations end up with cluster sprawl in the first place. The reasons are almost always legitimate at the time the cluster gets created.
Blast radius isolation. If one team’s workload goes haywire and exhausts node resources, you do not want it cascading to other teams. Separate clusters provide hard isolation that namespaces cannot fully deliver. Even with network policies and RBAC locking things down, a misbehaving workload can still starve the node’s CPU, exhaust the container runtime, or trigger cascading evictions.
Compliance and data residency. GDPR, HIPAA, PCI-DSS, and country-specific data sovereignty laws force certain workloads into specific regions and environments. You cannot commingle EU customer data with US customer data in the same cluster if your DPA prohibits it. So you build dedicated clusters per regulatory boundary.
Environmental separation. Production, staging, development, and QA each want their own cluster. Fair enough. But multiply those four environments by three cloud regions and two compliance tiers and you are already at twenty-four clusters.
Cloud provider diversity. Multi-cloud strategy (even a modest one) means running EKS in AWS, GKE in GCP, and maybe AKS in Azure. Each provider’s managed Kubernetes service is its own cluster. Before committing to a multi-cloud Kubernetes strategy, make sure you have a clear rationale for each provider choice: the EKS vs GKE vs AKS comparison covers the networking, cost, and operational differences that compound when you’re running fleets across providers.
The economics compound quickly. On EKS, the control plane alone costs roughly $73 per cluster per month. Multiply that by thirty-two clusters and you are paying $2,300 per month just in control plane fees before a single workload runs. Add the per-cluster cost of observability agents, ingress controllers, cert-manager, external-dns, and the operational burden of upgrading each cluster individually, and the math gets ugly fast.
The KubeFed Failure and What We Learned
Kubernetes Federation v1 and v2 (KubeFed) were the official attempts to solve this problem. They both failed, and understanding why matters for evaluating the current generation of tools.
KubeFed’s core problem was the API design. It tried to create a “federation-aware” API layer that translated federated resources into cluster-specific ones. This lowest-common-denominator approach meant every cluster had to support exactly the same feature set, and any cluster-specific capability was impossible to expose through the federated API. The control plane was also a single point of failure, meaning the tool meant to provide resilience across clusters was itself fragile.
KubeFed v1 was deprecated. KubeFed v2 was eventually archived. The Kubernetes community effectively said: cluster federation as a first-class API primitive is not the right abstraction.
The current generation of tools takes a different approach. Instead of federating the Kubernetes API itself, they run as controllers that sit above individual clusters, push resources down via standard Kubernetes APIs, and observe cluster state through agents or direct API access. The clusters remain independent. The management plane just coordinates them.
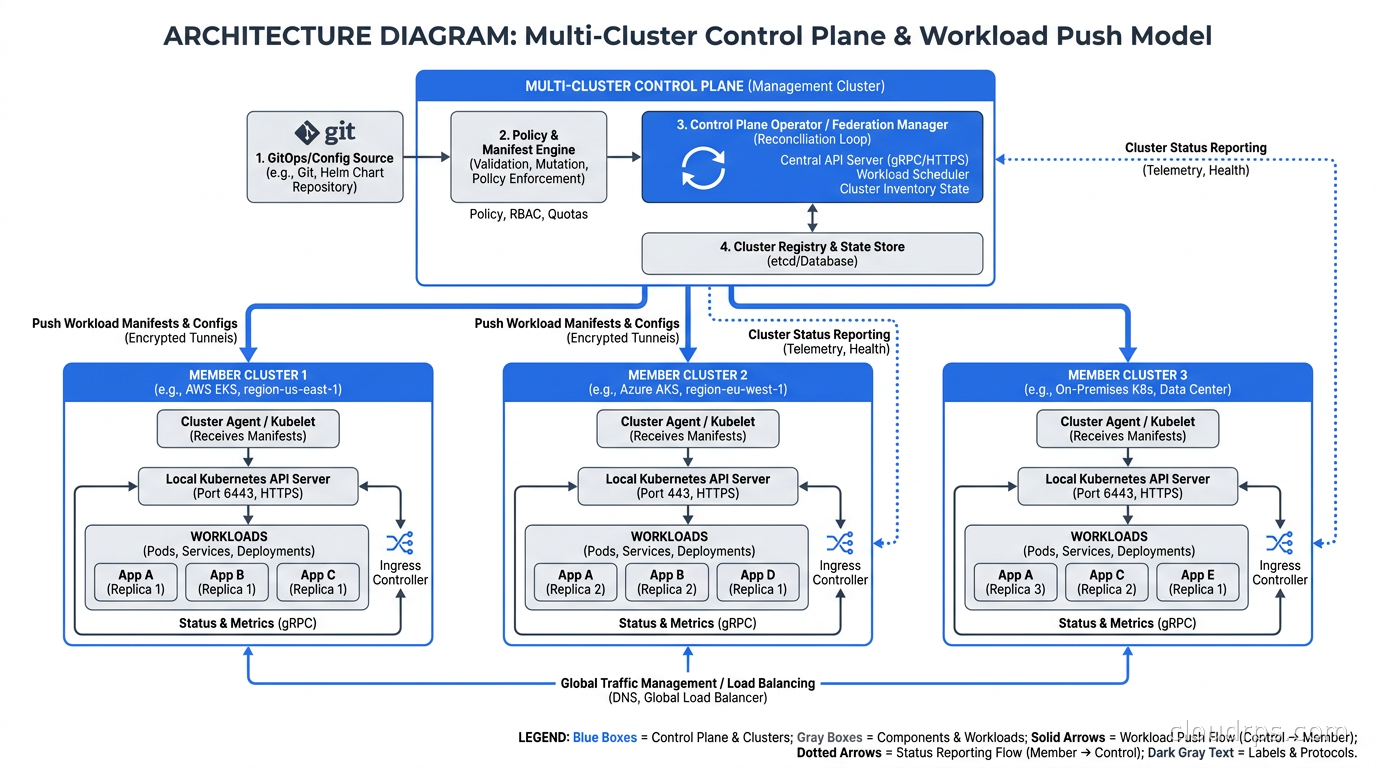
Karmada: The Most Complete Solution
Karmada (Kubernetes Armada) is now a CNCF incubating project and the most feature-complete multi-cluster management system available. The design is elegant: Karmada runs its own API server that speaks native Kubernetes, so you interact with it using standard kubectl and standard resource manifests. Karmada then distributes those resources to member clusters based on placement policies you define.
The core abstraction is the PropagationPolicy. Here is a minimal example:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- us-east-1
- eu-west-1
replicaScheduling:
replicaSchedulingType: Divided
replicaDivisionPreference: Weighted
weightPreference:
staticClusterWeight:
- targetCluster:
clusterNames:
- us-east-1
weight: 2
- targetCluster:
clusterNames:
- eu-west-1
weight: 1
This tells Karmada to spread the nginx Deployment across two clusters with a 2:1 weighting. Two thirds of replicas go to us-east-1, one third to eu-west-1. If one cluster degrades, Karmada can redistribute replicas automatically to maintain capacity.
That failover capability is where Karmada genuinely shines. You define OverridePolicies for cluster-specific configuration (different image registries per cloud, different resource limits per environment) and Karmada handles the delta between your canonical manifest and what actually gets deployed to each cluster. I have used this pattern to run active-active deployments across three cloud providers with a single source of truth in git and automatic traffic rerouting when a cluster degrades.
Karmada also exposes a federated search API so you can query resources across all member clusters from a single endpoint. Running kubectl get pods --all-namespaces against the Karmada API server returns pods from every cluster, not just one. This sounds minor but changes your operational workflow significantly.
Where Karmada falls short. The learning curve is real. Karmada introduces new CRDs (PropagationPolicy, OverridePolicy, ClusterOverridePolicy, ResourceBinding, Work) on top of everything you already manage. There are now failure modes that span the management plane and the member clusters, which makes debugging harder. And because Karmada runs its own etcd and API server, it is another stateful system you need to operate reliably.
Rancher Fleet: GitOps-First Multi-Cluster
Rancher Fleet takes a different philosophy. Where Karmada is about intelligent workload distribution and scheduling, Fleet is about GitOps at scale. The model is simple: you point Fleet at git repositories, define which clusters should receive which resources, and Fleet continuously reconciles. It was designed to manage thousands of clusters, which is why it has been adopted heavily in edge computing scenarios where you might have hundreds of retail stores or factories each running a small cluster.
Fleet uses Bundle resources that aggregate all the Kubernetes manifests for a given application, and GitRepo resources that define where the source lives. Cluster targeting happens through labels and selectors:
apiVersion: fleet.cattle.io/v1alpha1
kind: GitRepo
metadata:
name: apps
namespace: fleet-default
spec:
repo: https://github.com/myorg/k8s-manifests
branch: main
targets:
- name: production
clusterSelector:
matchLabels:
env: production
region: us-east-1
Fleet handles the Helm values overlay problem cleanly. You can define base values in the repository and then layer cluster-specific overrides using the targets configuration. This is the pattern I recommend for managing configuration differences between environments without duplicating manifests.
Fleet’s weakness is the lack of intelligent workload scheduling. It will not automatically shift replicas from a degraded cluster to a healthy one. It is a deployment and configuration management tool, not a scheduler. If you need cross-cluster failover and replica rebalancing, Fleet alone is not sufficient and you need to combine it with something like Karmada or implement the failover logic separately.
Fleet also has a dependency on Rancher for production-grade support and the full UI experience, though it does run standalone. If your organization is already running Rancher for cluster lifecycle management, Fleet is the obvious choice for application distribution. If you are not on Rancher, the value proposition is less clear compared to ArgoCD ApplicationSets.
Open Cluster Management: The Red Hat Path
Open Cluster Management (OCM) is the upstream for Red Hat Advanced Cluster Management. The CNCF sandbox project provides the control plane primitives: ManifestWork for pushing resources to clusters, ManagedCluster for representing clusters, and Placement for scheduling decisions.
OCM’s philosophy is modularity. The core provides the plumbing and other projects build on top. Argo CD, Flux, and other tools can integrate with OCM to gain multi-cluster awareness without reimplementing cluster discovery and state management.
The honest assessment: OCM has a more limited built-in capability compared to Karmada when used standalone. Where Karmada gives you failover, weighted distribution, and a federated API server out of the box, OCM gives you an extensible framework. The investment makes sense if you are building custom multi-cluster platform tooling or if you are on Red Hat’s commercial stack where ACM wraps OCM with enterprise features.
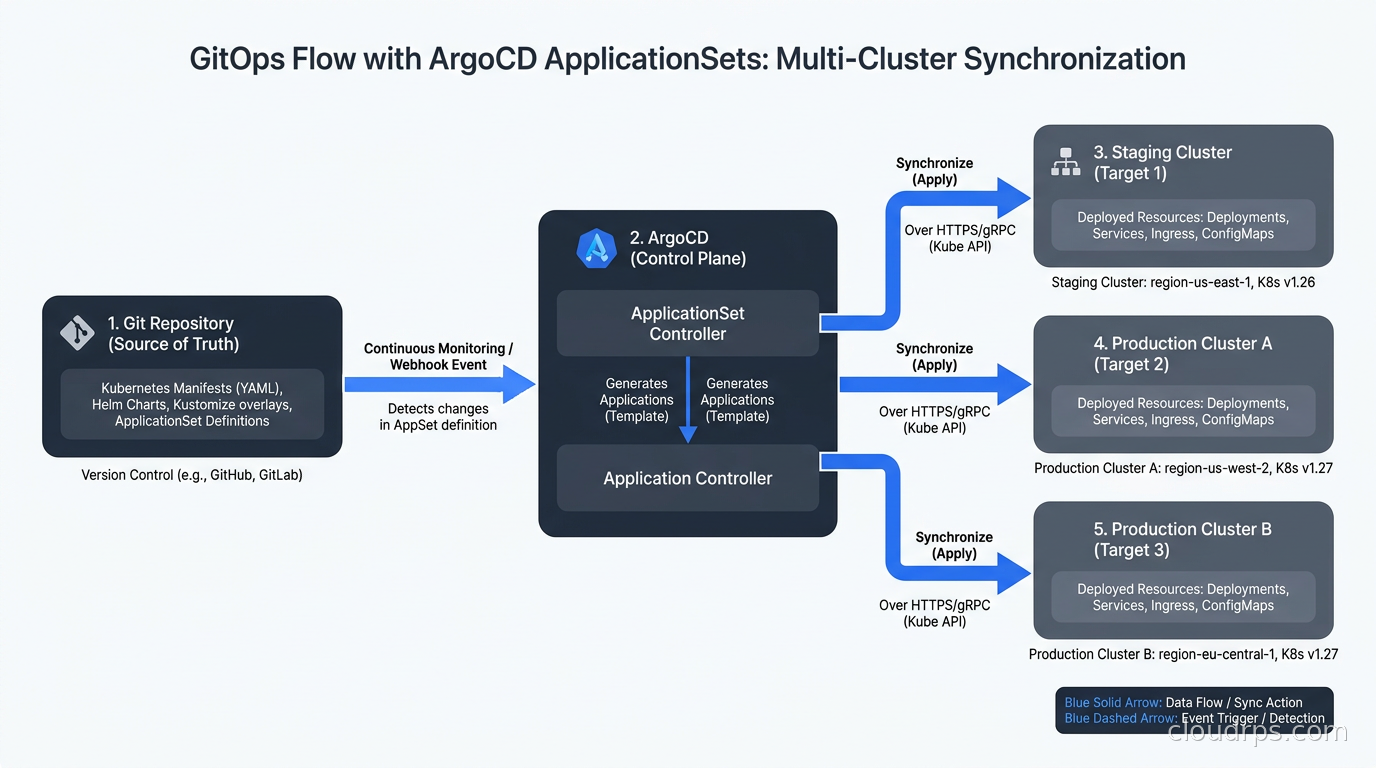
ArgoCD ApplicationSets: GitOps Multi-Cluster Without a New Control Plane
If you are already running ArgoCD for GitOps and want multi-cluster deployment without adding a new management plane, ApplicationSets are worth serious consideration. ApplicationSets let you define a template Application and a generator that produces cluster-specific instances.
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: nginx
spec:
generators:
- clusters:
selector:
matchLabels:
env: production
template:
metadata:
name: '{{name}}-nginx'
spec:
project: default
source:
repoURL: https://github.com/myorg/nginx-chart
targetRevision: main
helm:
valueFiles:
- 'values-{{name}}.yaml'
destination:
server: '{{server}}'
namespace: nginx
This ApplicationSet generates one ArgoCD Application per cluster that matches the env: production label. Add a new cluster with that label and ArgoCD automatically starts deploying to it. Remove the label and the Application gets pruned.
The limitation is that ApplicationSets are purely declarative deployment, not scheduling. You cannot express “run 60% of replicas in us-east-1 and 40% in eu-west-1 with automatic rebalancing.” ApplicationSets are deployment controllers, not workload schedulers. But for the common case of deploying the same application to multiple clusters with cluster-specific overrides, they are simple and effective.
Day-2 Operations: The Real Challenge
Choosing your management plane is maybe 20% of the work. The remaining 80% is making multi-cluster operations actually sustainable.
Policy federation. Enforcing consistent security policies across clusters is hard. The policy as code tools (OPA, Kyverno) need to be deployed and kept consistent across every cluster. Karmada can propagate Kyverno ClusterPolicies as just another Kubernetes resource. OCM has the Policy addon for distributing policies. Fleet handles it through GitRepo bundles. Whatever your management plane, you need to treat security policies as code that lives in git and gets distributed the same way your workload manifests do.
Kubernetes RBAC across clusters. Role-based access control becomes complex when users need access to multiple clusters. The pattern that works: use your identity provider (Okta, Azure AD) with OIDC, define group-to-role mappings as code, and propagate RoleBinding and ClusterRoleBinding manifests through your management plane. This gives you a single source of truth for who can do what, distributed consistently to every cluster.
Observability aggregation. Per-cluster Prometheus instances are manageable when you have three clusters. At fifteen clusters, the operational overhead of maintaining fifteen Prometheus configurations and merging their data for cross-cluster queries becomes a problem. The patterns that actually work: Thanos or Cortex as a global query layer over per-cluster Prometheus instances, or switching to an agent-based model (Grafana Alloy, OpenTelemetry Collector) that ships metrics to a centralized backend. The Prometheus/Loki/Grafana stack scales to multi-cluster with the right sharding strategy.
Upgrade coordination. Running Kubernetes version upgrades across thirty clusters is where platform teams burn out. The discipline that prevents this: treat cluster configuration (including Kubernetes version) as code stored in git, use a tool like Cluster API or your cloud provider’s managed cluster upgrade API, and roll upgrades in waves (canary cluster, then region by region) with automated smoke tests after each wave. Never upgrade more than one cluster in a batch without verified rollback capability.
Networking between clusters. This deserves its own article, but briefly: for service-to-service communication across clusters you have three patterns. First, go through a load balancer (simple, adds latency, works everywhere). Second, use a service mesh that spans clusters (Istio multi-cluster, Cilium cluster mesh), which enables direct pod-to-pod communication with mTLS. Third, use Kubernetes multicluster-services API with MCS controller to federate service DNS. Which you choose depends on your latency requirements and how much mesh complexity you want to manage.
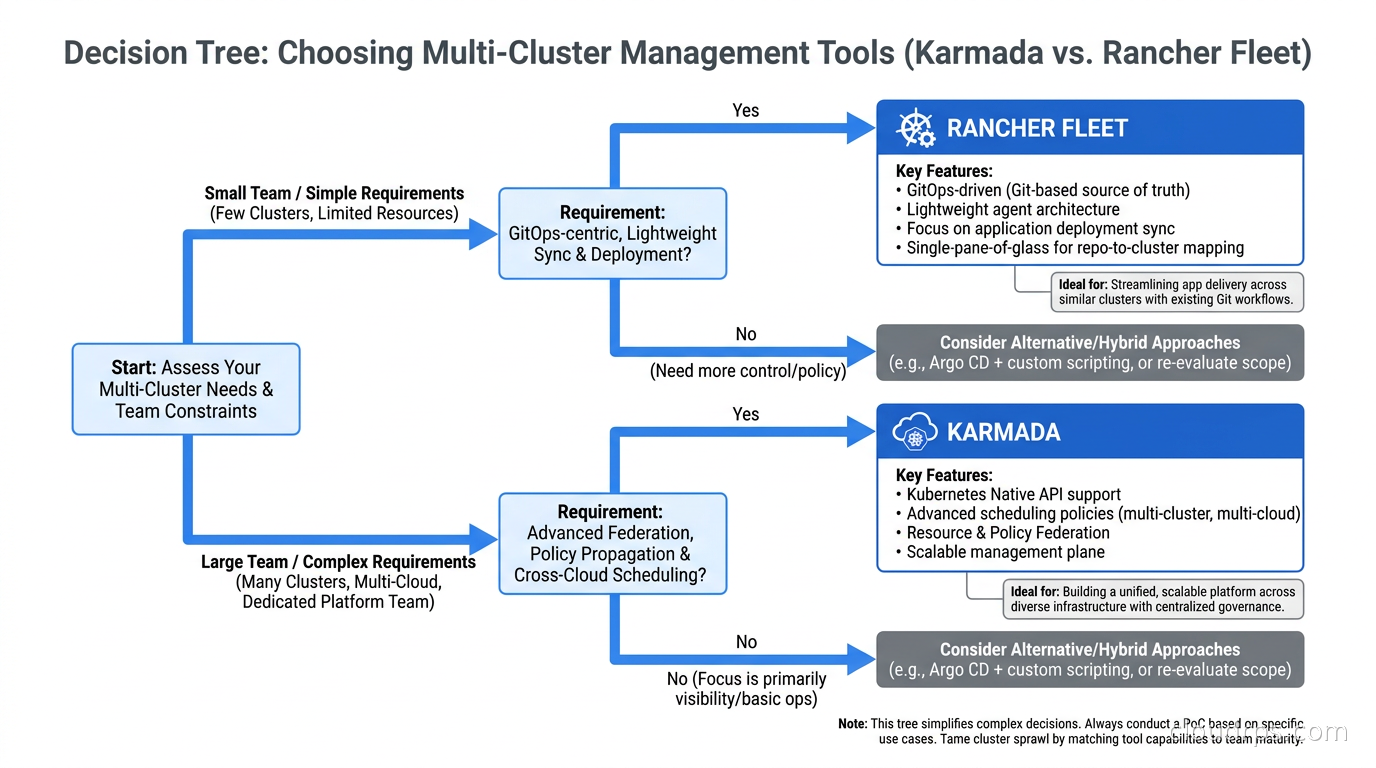
How to Choose
Here is the decision framework I actually use when advising on this:
Start with ArgoCD ApplicationSets if you already run ArgoCD, have under 20 clusters, and need deployment consistency without workload scheduling. Low complexity, high leverage, integrates with your existing GitOps workflow.
Choose Karmada if you need intelligent workload distribution across clusters, cross-cluster failover, or a federated API for querying resources across your fleet. Accept the higher operational complexity of running the Karmada control plane itself.
Choose Rancher Fleet if you are already on the Rancher/SUSE stack, have edge scenarios with hundreds of small clusters, or need to manage clusters at a scale where individual ArgoCD Applications become unwieldy.
Choose Open Cluster Management if you are building a custom multi-cluster platform on Red Hat infrastructure, need the extensibility hooks OCM provides for integrating custom controllers, or are purchasing Red Hat ACM commercially.
The pattern I have seen work most consistently at organizations operating more than thirty clusters: Cluster API for lifecycle management (creating, upgrading, deleting clusters declaratively), Karmada or ArgoCD ApplicationSets for workload distribution, and Kyverno policies propagated through the same management plane for consistent security enforcement. Add Crossplane on top if you need multi-cluster infrastructure provisioning from the same control plane. The Crossplane approach to infrastructure provisioning pairs naturally with Karmada’s workload distribution.
The Control Plane Is a Liability Too
One thing I want to be direct about: every multi-cluster management plane you add is itself a single point of failure and a new operational burden. Karmada’s control plane needs its own etcd, its own API server, its own HA setup. If Karmada goes down, you lose the ability to update workloads across clusters (though existing workloads continue running in member clusters).
I have seen organizations over-architect this layer. They add Karmada, then add Argo Rollouts for progressive delivery, then add Fleet for config management, then add OCM for policy, and end up with four overlapping management planes that nobody fully understands. Pick one primary plane and resist the temptation to layer more tools on top.
The minimum viable multi-cluster setup for most organizations:
- One cluster lifecycle tool (EKS managed node groups / GKE Autopilot / Cluster API)
- One deployment distribution tool (ArgoCD ApplicationSets for most, Karmada if you need scheduling)
- Policies in git, propagated by the same tool that propagates workloads
- A global observability backend with per-cluster agents
Everything else is complexity you are paying for even when nothing is on fire. And when something is on fire across three clusters simultaneously, you want the smallest possible number of tools to reason about.
Practical Starting Point
If you are starting from scratch or rationalizing existing sprawl, the sequence I recommend:
First, audit every cluster and document why it exists. You will find clusters that were created for a reason that no longer applies and can be decommissioned. In my experience, a third of clusters in sprawled environments can be eliminated outright by consolidating dev and staging environments with proper namespace isolation and resource quotas.
Second, standardize cluster configuration as code before deploying any management plane. A management plane distributes your configuration consistently, so if your configuration is inconsistent it will propagate inconsistency consistently.
Third, deploy ArgoCD in hub-spoke mode as your baseline. Even if you later layer Karmada on top, ArgoCD provides a deployment audit trail and drift detection that is worth having regardless of what else you run.
Fourth, pick a policy tool (Kyverno is my recommendation for most teams given its Kubernetes-native CRD syntax) and write your baseline policies before connecting member clusters. It is much easier to enforce policies on new clusters than to remediate policy violations across clusters that have been running without them.
Multi-cluster management is genuinely hard. The tools have matured enormously, but the operational complexity of running a fleet of clusters is real and should not be underestimated. The teams that do it well treat their cluster fleet like a product with an owner, proper DORA metrics for change failure rate and deployment frequency, and a deliberate decision framework for when a new cluster is actually justified versus when namespace isolation or a virtual cluster (vCluster) would suffice.
The teams that struggle treat each cluster as a one-off infrastructure decision made by whoever needed compute that week. You can guess which set of teams is sleeping better.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.