I have spent twenty years building infrastructure, and the GPU cluster problem of the 2020s reminds me of nothing so much as shared HPC clusters from the early 2000s: expensive hardware, multiple teams competing for it, no queuing discipline, and a constant political fight over who gets what. The difference is that H100s cost roughly 30 times what those old SGI boxes did, so the stakes of getting scheduling wrong are considerably higher.
For most of 2023 and 2024, teams cobbled together solutions: static namespace quotas, manual priority flags, FIFO scheduling via cron, custom priority classes. None of it worked well. Then Kueue graduated to a stable Kubernetes SIG project and the picture changed. It is now the standard queuing layer for AI and ML batch workloads on Kubernetes, and if you are running GPU clusters without it, you are almost certainly wasting significant money.
This article explains how Kueue works, how to deploy it for multi-tenant GPU environments, and what you actually need to know to make it production-worthy.
The Problem Kueue Solves
Before getting into Kueue’s architecture, it is worth being precise about the problem. The Kubernetes scheduler is excellent at what it does: placing pods onto nodes based on resource availability, affinities, taints, and tolerations. What it does not do is manage contention at the workload level. It has no concept of a queue of pending jobs, no mechanism for fair-share allocation across teams, no way to express “admit this 16-GPU training job only when all 16 GPUs become available simultaneously.”
Without a queuing layer, GPU clusters exhibit several failure modes I have seen destroy utilization in production:
Head-of-line blocking. A large training job requesting 64 GPUs sits pending because only 40 are free. Meanwhile, dozens of smaller inference or preprocessing jobs that could run on those 40 GPUs get stuck behind the large job in the default scheduler queue. The cluster shows 60% idle GPUs while everyone complains that nothing is running.
GPU fragmentation. Without gang scheduling, distributed training jobs start partially. You get a PyTorchJob where 3 of 8 workers launched, the other 5 are pending, and the 3 running workers are doing nothing but burning GPU memory waiting for the rest to come up. I have seen clusters where 40% of allocated GPU time was wasted on stalled partial allocations.
Quota starvation. One team submits 200 small jobs and saturates the cluster. Other teams get nothing for hours. With standard Kubernetes resource quotas, you can cap namespace resource consumption, but you cannot enforce fairness across teams sharing a common pool dynamically.
Priority inversion. A low-priority preprocessing job is running when a high-priority model training job comes in. Without a preemption framework that understands job semantics (not just pod priority), you end up with blunt preemption that kills the preprocessing job mid-run, wastes the work already done, and may not even free enough resources for the training job if the preempted pods do not clean up quickly.
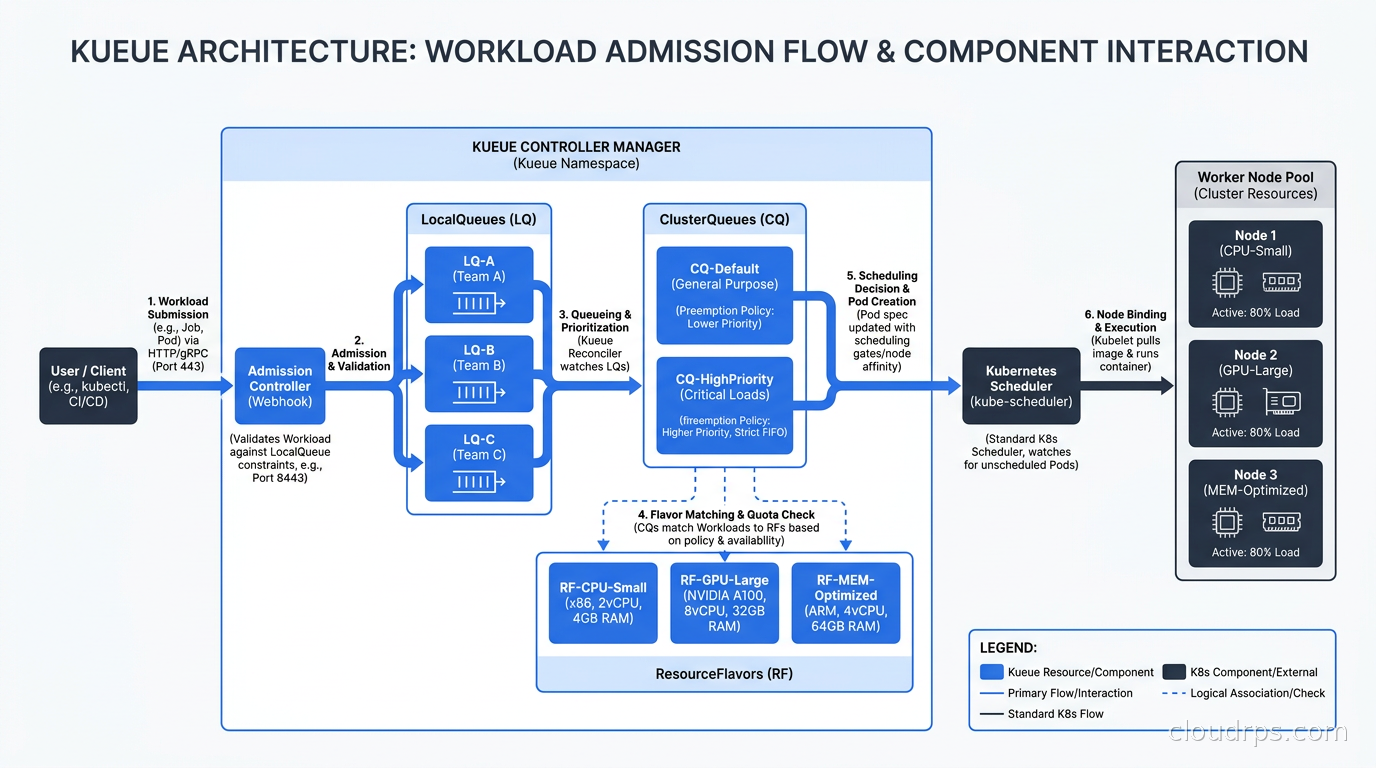
Kueue addresses all four of these. It operates as an admission controller: jobs enter a queue, Kueue decides when and whether to admit them to the cluster for actual scheduling, and the underlying Kubernetes scheduler handles placement once Kueue gives the green light.
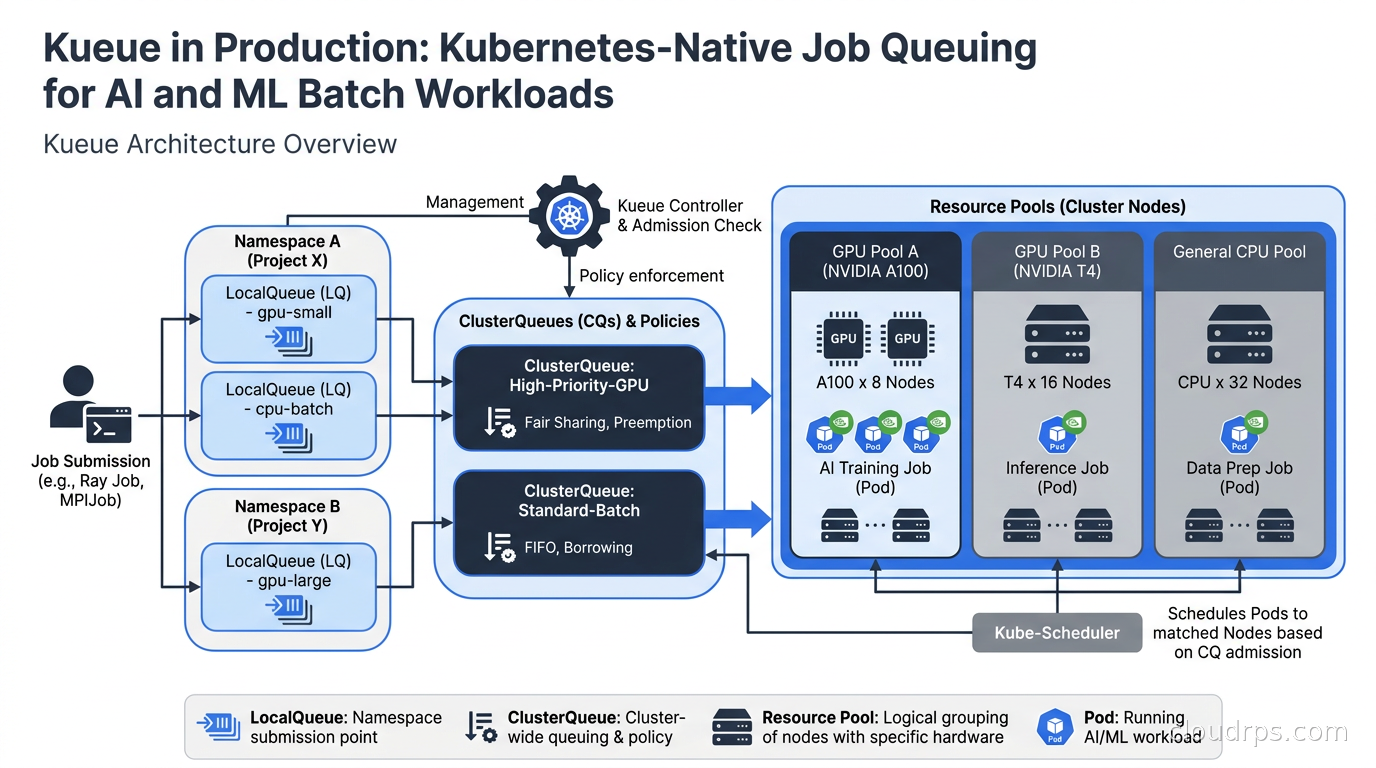
The Four Core Objects
Kueue introduces four main custom resources. Understanding these is essential before trying to configure anything.
ResourceFlavor represents a class of hardware in your cluster. In a heterogeneous GPU cluster, you might have ResourceFlavors for A100-40GB nodes, A100-80GB nodes, H100-SXM nodes, and H100-NVL nodes. ResourceFlavors carry node selector labels and taints so Kueue knows which nodes match each flavor. You can also attach tolerations here. This is the mapping between the abstract concept of “GPU” and the concrete hardware you actually have.
ClusterQueue is a cluster-scoped resource pool that defines quotas across ResourceFlavors. A ClusterQueue might say: “pool for the ML platform team, with a nominal quota of 32 H100 GPUs and 512 CPU cores, able to borrow up to 64 H100s from the shared pool when idle capacity exists.” ClusterQueues are where you set borrowing limits, lending limits, and preemption policies. This is the primary lever for multi-tenant fairness.
LocalQueue is a namespaced resource that points to a ClusterQueue. Teams submit jobs to their LocalQueue, and Kueue routes them to the appropriate ClusterQueue. This gives you clean namespace-level separation: the ML training team has a LocalQueue in the ml-training namespace, the ML research team has one in ml-research, both pointing at the same ClusterQueue with a shared pool. Individual teams never need cluster-scoped permissions.
Workload is what Kueue creates automatically for each admitted job. You do not create Workloads directly. When you submit a Kubernetes Job, a RayJob, a Kubeflow PyTorchJob, or another supported type, the relevant Kueue webhook intercepts it and creates a corresponding Workload object that tracks admission status, resource accounting, and lifecycle.
The flow is: you submit a job to a LocalQueue, Kueue creates a Workload, the Workload waits until the ClusterQueue has sufficient quota, Kueue then admits the Workload (which starts the actual pods), and the ClusterQueue quota is decremented accordingly. When the job finishes, the quota is released.
Fair-Share Scheduling and Admission
The default admission algorithm in Kueue is what the project calls Admission Fair Sharing. The problem it solves: even with fair per-team quotas, one team can temporarily monopolize the queue by submitting many jobs that all get admitted in sequence, starving other teams during busy periods.
Admission Fair Sharing tracks historical resource consumption per LocalQueue over a configurable window (the default is 5 minutes). When multiple Workloads across different queues are competing for admission, Kueue prioritizes the queue with the lowest recent consumption. A team that just ran a large training job goes to the back of the line until their consumption score normalizes. A team that has been idle gets priority.
This is the mechanism I wish we had on our shared clusters fifteen years ago. The politics of “team A keeps monopolizing the cluster” essentially disappears because the system enforces fairness automatically rather than requiring human intervention or manual quota adjustments every time someone submits a burst of jobs.
One important nuance: Admission Fair Sharing operates at admission time. Once a Workload is admitted and running, it continues to run. The fair-share mechanism only affects the order in which pending Workloads get admitted. This is intentional: preempting running training jobs is expensive because you lose the work done so far unless you are using checkpointing.
Gang Scheduling: Why It Matters for Distributed Training
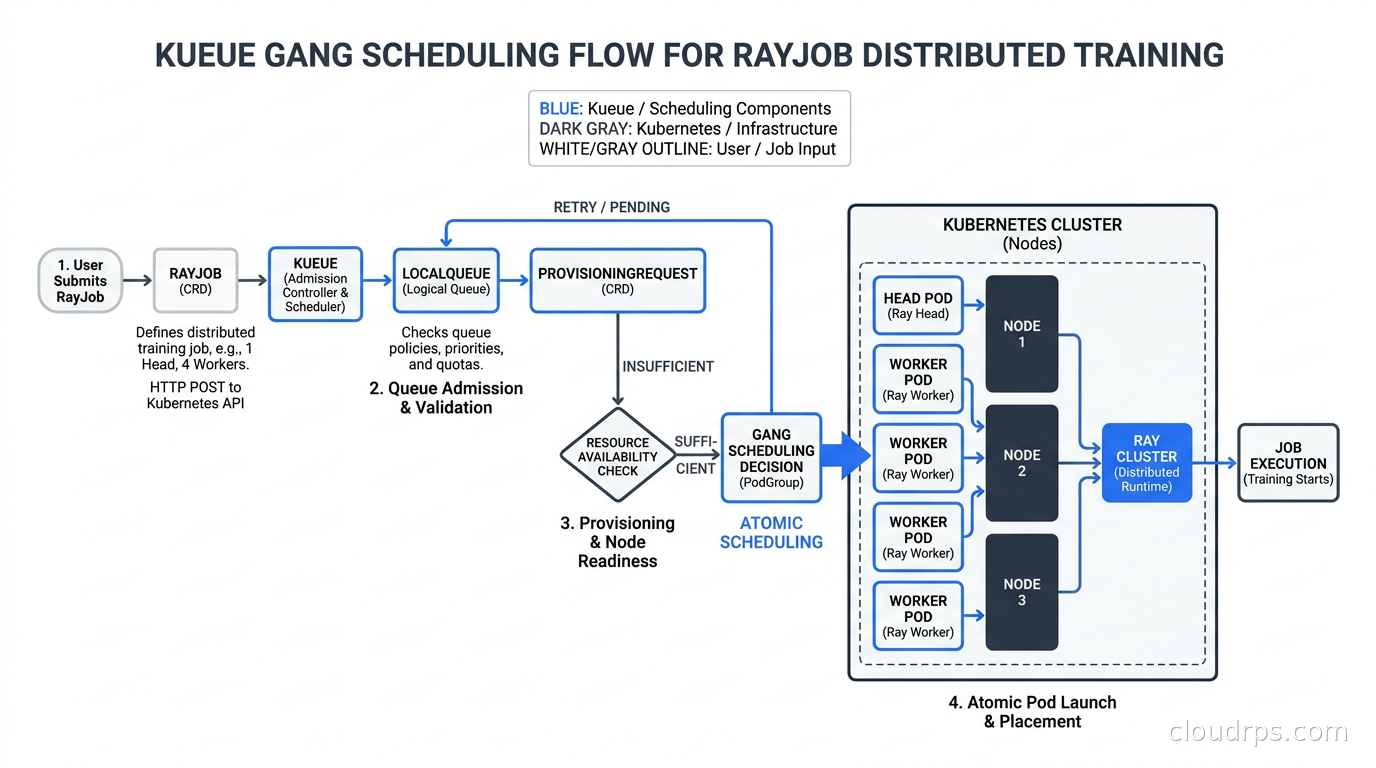
Gang scheduling is the capability I consider most critical for AI workloads. Distributed training jobs (PyTorchJob, RayJob, TFJob) require all their worker pods to run simultaneously. If worker 0 through worker 6 are running but worker 7 is pending for 30 minutes waiting for a GPU, you have 7 workers burning GPU cycles doing nothing.
Without gang scheduling, this happens constantly on busy clusters. The Kubernetes scheduler is stateless and greedy: it places pods one at a time, each onto the first available node that satisfies requirements. So a 8-GPU job might get 6 of its workers scheduled immediately, then wait arbitrarily long for the remaining 2.
Kueue implements all-or-nothing admission. A Workload is only admitted when the entire resource request (all GPUs, all CPUs, all memory) can be satisfied simultaneously. Until that point, the Workload stays in the queue and no pods are created. This means you never end up with partial allocations burning resources.
The practical implementation uses a concept called ProvisioningRequest for cases where you need node autoscaling. The workflow: Kueue checks if the requested resources are available within current quota, creates a ProvisioningRequest if new nodes need to spin up (integrated with Karpenter or Cluster Autoscaler), waits for the nodes to be ready, then atomically admits the entire Workload. Only at that point do the actual pods get created and scheduled.
For GPU training specifically, this integrates cleanly with Ray distributed computing through RayJob, and with Kubeflow’s Training Operator for PyTorchJob and TFJob. Kueue has first-class support for both. You deploy Kueue, install the relevant operator, and the gang scheduling behavior is automatic.
Cohorts and Cross-Queue Borrowing
Static quotas are wasteful. If the ML training team has a quota of 32 H100s and they are only using 16, those other 16 GPUs sit idle while the ML research team is queued waiting for resources. Cohorts fix this.
A Cohort is a group of ClusterQueues that can lend unused capacity to each other. You define a Cohort called ml-teams, add both the training and research ClusterQueues to it, and Kueue automatically allows borrowing across the group. When training is underutilizing its quota, research jobs can borrow those GPUs up to whatever lending limit you configure.
The key detail is how preemption interacts with borrowing. When team A is borrowing team B’s quota and team B submits new jobs, team B’s jobs preempt team A’s borrowed workloads. Team A gets its nominal quota back, the borrowed resources return to team B. You can configure the preemption strategy: whether you preempt the lowest-priority borrowed job first, the most recently admitted one, or the smallest one. This matters for cost: preempting a 1-hour-old checkpoint-less training run is expensive; preempting a 2-minute preprocessing job is cheap.
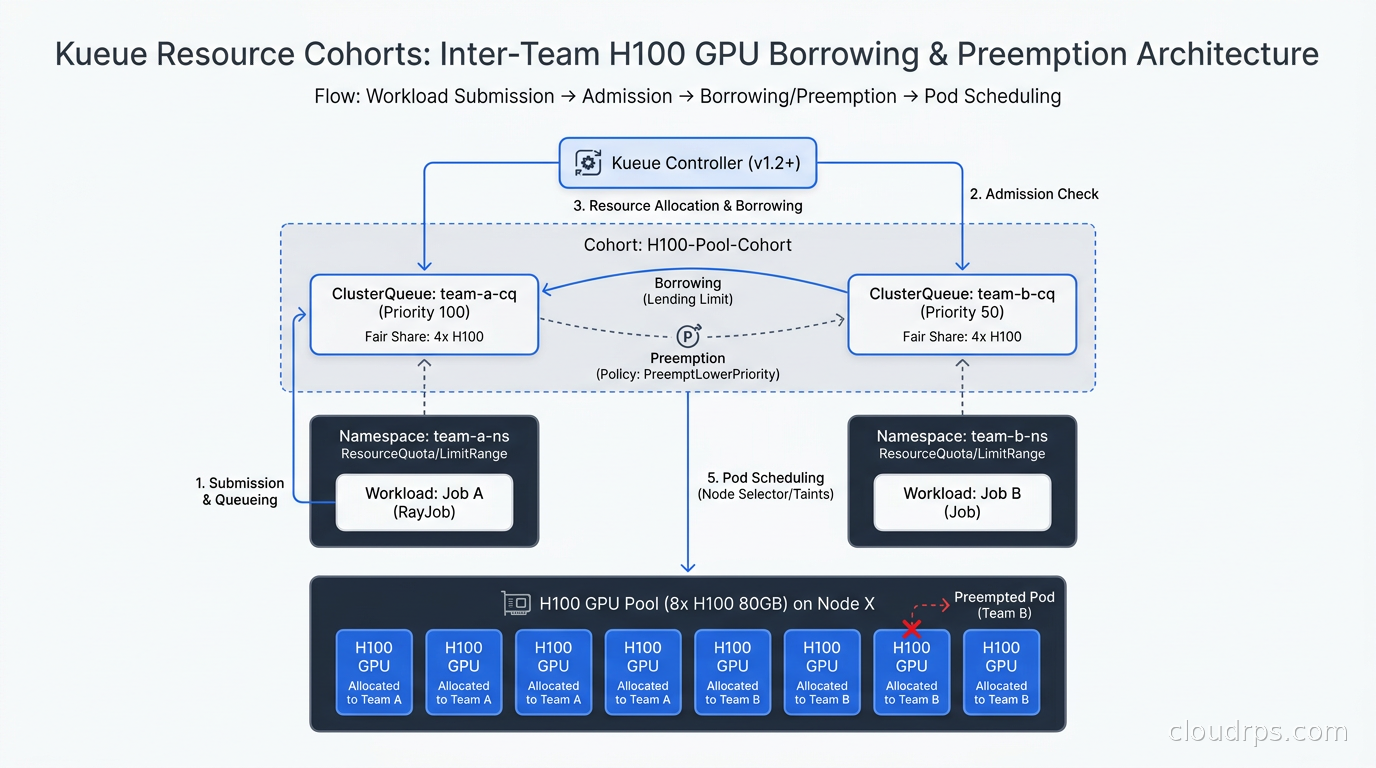
In production, I set borrowing limits conservatively at first. My typical starting configuration is: nominal quota at 60% of total cluster capacity for each team, with borrowing allowed up to 100% of total capacity when other teams are idle. This gives each team a guaranteed baseline while allowing full cluster utilization. You tune from there based on actual usage patterns.
The other important configuration is lendingLimit. By default, a ClusterQueue lends all of its unused nominal quota to the Cohort. But some teams have SLAs: they need guaranteed response time. Setting lendingLimit to, say, 25% of nominal quota means that even if the team is completely idle, they keep 75% of their quota reserved and only the 25% overage can be borrowed by others. When they submit a high-priority job, they can preempt the borrowed portion and reclaim the reserved portion immediately.
Topology Aware Scheduling
For large distributed training runs, where you place jobs within a cluster matters as much as whether you can place them at all. A 64-GPU training job split across nodes connected by slow inter-rack links will train significantly slower than the same job on 64 GPUs in the same rack sharing InfiniBand or NVLink fabric. This is the problem that GPU cluster networking exists to solve, and Kueue’s Topology Aware Scheduling extends quota management into that domain.
With Topology Aware Scheduling, you annotate nodes with hierarchical topology labels: datacenter, rack, host. ResourceFlavors reference these labels. When admitting a Workload, Kueue considers whether the resources can be placed within a single topology domain at the requested level. A training job requiring high-bandwidth interconnect gets admitted only if a rack-level placement is possible; if not, it waits in the queue until a suitable topology opening exists.
This is genuinely new capability that did not exist in any Kubernetes scheduler before Kueue implemented it. I have seen 30-40% training speedup improvements just from ensuring jobs land within a single InfiniBand fabric domain rather than being scattered across multiple racks.
Integration with the AI/ML Stack
Kueue is not just for Kubernetes Jobs. The list of natively supported workload types as of 2025 includes:
- Kubernetes Job and CronJob: the baseline
- JobSet: multi-job workloads from the kubernetes-sigs/jobset project, useful for complex training topologies
- RayJob and RayCluster: direct integration with Ray for distributed ML workloads
- Kubeflow PyTorchJob, TFJob, PaddleJob, MPIJob, JAXJob: the full Kubeflow Training Operator suite
- KubeAI InferencePool: for serving workloads that need scheduling constraints
- Flux MiniCluster: HPC-style workloads
For LLM fine-tuning workloads specifically, the typical pattern is: submit a PyTorchJob or RayJob to your LocalQueue with the GPU resource request, let Kueue handle admission when sufficient A100s or H100s are available, and rely on gang scheduling to ensure the entire training run starts simultaneously. This replaces ad-hoc bash scripts that used to wait-loop on kubectl get nodes and then submit jobs manually.
One integration detail that catches people: Kueue manages admission, but it does not set pod scheduling constraints itself. It relies on the ResourceFlavor node selectors and the existing Kubernetes scheduler for actual placement. This means your existing pod scheduling configuration for GPU node affinity and taints continues to work unchanged. Kueue adds a layer above, not below, the existing scheduler.
Kueue vs. Volcano vs. YuniKorn
Every team I talk to asks this question. Here is my honest take.
Volcano is a complete replacement scheduler, not an overlay. It handles both queuing and placement, supports more advanced HPC scheduling algorithms (backfill, FIFO with priority, SDF), and has been in production at Huawei and other large-scale HPC shops for years. If you are running a cluster that looks more like a traditional HPC environment (pure batch, no Kubernetes-native workloads, MPI-first) then Volcano is reasonable. The downside is that replacing the default Kubernetes scheduler is a significant operational commitment, and the Kubernetes ecosystem (Cluster Autoscaler, Karpenter, KEDA, etc.) assumes the default scheduler. Volcano does not integrate with these cleanly.
Apache YuniKorn sits between the two: it works as a scheduler plugin rather than a full replacement, it has gang scheduling, hierarchical queues, and fair-share, and it handles a broader range of workload types including Spark. If your team runs mixed Spark and ML workloads on the same cluster, YuniKorn is worth evaluating.
Kueue is my default recommendation for teams building on the modern Kubernetes AI stack. The reasons: it works with the default scheduler rather than replacing it, it integrates natively with Karpenter and Cluster Autoscaler (which you almost certainly already use if you are on EKS, GKE, or AKS), and it has first-class support for the operator-based workload types (RayJob, Kubeflow) that AI teams actually use. The tradeoff is that Kueue’s scheduling algorithms are simpler than Volcano’s. If you need backfill scheduling or complex multi-resource gang constraints beyond what Kueue supports, Volcano is worth the operational complexity.
For most teams running AI/ML on a managed Kubernetes platform, Kueue is the right call. The managed Kubernetes providers (GKE Autopilot, EKS, AKS) have all added documentation and support for Kueue. That ecosystem alignment matters operationally.
Resource Management and Kubernetes Integration
Kueue works alongside standard Kubernetes resource management features, not instead of them. You still set requests and limits on pods. ResourceQuotas still apply. LimitRanges still apply. Kueue adds queue-level admission control on top of all that.
The one area where they interact in a non-obvious way is namespace quotas. If you have a namespace-level ResourceQuota that caps GPU consumption and a team tries to borrow from the Cohort beyond that namespace quota, the pod creation will fail even after Kueue admits the Workload. This is a footgun. My recommendation: do not set namespace-level ResourceQuotas for resources managed by Kueue. Let Kueue’s ClusterQueue quotas be the sole enforcement mechanism for those resources. ResourceQuotas still make sense for things Kueue does not manage (CPU bursts, storage).
For GPU cost visibility and chargeback, Kueue’s LocalQueue labels carry through to admitted workloads, which means OpenCost and Kubecost can attribute GPU costs to the team level automatically. You label LocalQueues with team and cost-center labels, and those labels propagate to pods via the Workload admission process.
Production Configuration Checklist
Things I have learned the hard way running Kueue in production:
Namespace isolation first. Before any Kueue configuration, ensure your team namespaces are properly isolated. Kueue’s RBAC model assumes teams can submit to their own LocalQueue but cannot directly modify ClusterQueues. A team that can modify a ClusterQueue can set their own quota to unlimited. Lock this down with standard Kubernetes RBAC.
Start with BestEffortFIFO, not StrictFIFO. Kueue supports two queue ordering strategies. StrictFIFO admits jobs in strict submission order, which can cause head-of-line blocking if a large job sits at the front. BestEffortFIFO skips ahead of a job that cannot be admitted due to quota constraints and admits the next job that fits. For GPU clusters with heterogeneous workloads (some jobs needing 64 GPUs, others needing 2), BestEffortFIFO dramatically improves utilization.
Set conservative lending limits initially. I start at 25-30% lendable from each ClusterQueue. You can increase this once teams are comfortable with preemption behavior and understand that their borrowed jobs might get preempted.
Configure preemption budgets. The maxPreemptedWorkloads field in a preemption configuration caps how many running workloads a single incoming job can preempt. Without this, a single large high-priority job can preempt dozens of running jobs simultaneously, causing a cascade of restarts across the cluster.
Checkpoint-aware preemption. Work with your ML teams to ensure training jobs that might be preempted write checkpoints frequently. Kueue’s preemption is workload-level: it terminates all pods in a preempted Workload. A training job that has been running for 6 hours and has no checkpoint loses all that work. This is a workflow question as much as an infrastructure one, but it is a prerequisite for enabling aggressive preemption policies.
Monitor queue depth. The critical Kueue metrics are kueue_pending_workloads (how many jobs are waiting) and kueue_admitted_workloads_total (admission rate). If pending workloads accumulate over hours for a given ClusterQueue, either quota is too low, jobs are too large, or fair-share is working but legitimately backing up. Distinguish these cases before increasing quota reflexively.
Observability and Debugging
Kueue exposes Prometheus metrics natively. The key ones beyond queue depth: kueue_cluster_queue_resource_usage (how much of each resource flavor is currently allocated), kueue_cluster_queue_nominal_quota (what the quota is), and kueue_admitted_workloads broken down by LocalQueue.
For debugging admission problems, the Workload object is your first stop:
kubectl describe workload <workload-name> -n <namespace>
The status conditions tell you why a Workload is pending: insufficient quota in the ClusterQueue, waiting for a ProvisioningRequest, failed admission check, or quota exceeded with borrowing enabled but no idle capacity in the Cohort.
The kueue controller logs (at debug level) show the admission loop in detail, including why specific Workloads were skipped in a scheduling cycle. This is verbose but invaluable when troubleshooting fair-share ordering that seems wrong.
The GPU Utilization Reality Check
Before wrapping up, a realistic expectation for what Kueue actually delivers. The numbers I quoted earlier (25-35% utilization without queuing, 60-85% with Kueue) are real, but the full improvement requires several things happening together: gang scheduling enabled, BestEffortFIFO ordering, Cohort borrowing configured, and ML teams actually using checkpointing so you can enable aggressive preemption.
If you deploy Kueue with all defaults and no Cohort configuration, you will see a real improvement over no queuing, but not the dramatic gains. The gains come from tuning the borrowing and preemption configuration based on your actual workload mix.
For teams running AI FinOps programs, Kueue is a prerequisite, not a nice-to-have. You cannot do meaningful GPU cost optimization without knowing which team and which job consumed what resources, and you cannot prevent waste at the cluster level without queue-based admission control enforcing the boundaries.
This is infrastructure that pays for itself immediately. One team I worked with went from $400K/month in GPU costs to $280K/month within 60 days of deploying Kueue, purely from eliminating fragmentation and partial allocations. The cluster did not get any larger; it just stopped wasting resources it already had.
If you are running AI workloads on Kubernetes and you do not have a queuing layer, this is the first thing to add, ahead of autoscaling, ahead of cost dashboards, ahead of any other optimization. The utilization gains are the precondition for everything else.
The Dynamic Resource Allocation (DRA) system in recent Kubernetes versions handles the per-device scheduling side of GPU allocation. Kueue handles the workload admission and fairness side. They are complementary, not competing, and the production AI stack increasingly needs both. The combination of DRA for fine-grained GPU partitioning and Kueue for fair-share queuing is what the enterprise Kubernetes AI platform looks like in 2026.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.