I watched a team spend three months building a production LLM service on top of a basic FastAPI wrapper calling a Hugging Face model directly. Their GPU utilization hovered around 12% under load, p99 latency was 8 seconds for a 200-token response, and they were burning $40,000 a month on A100s while serving fewer than 5,000 requests per hour. The fix was not buying more GPUs. It was switching to a proper inference engine, which dropped their GPU spend by 70% while tripling throughput.
This is the gap in most LLM infrastructure conversations. Everyone talks about choosing the right GPU, picking the right cloud provider, and scaling Kubernetes. Almost nobody talks about the software layer that actually runs your model, which is where half the performance lives. If you have already worked through hardware selection and GPU types in our LLM inference infrastructure guide, this article covers the software layer sitting directly above the hardware.
Why the Inference Engine Is Not Just a Runtime
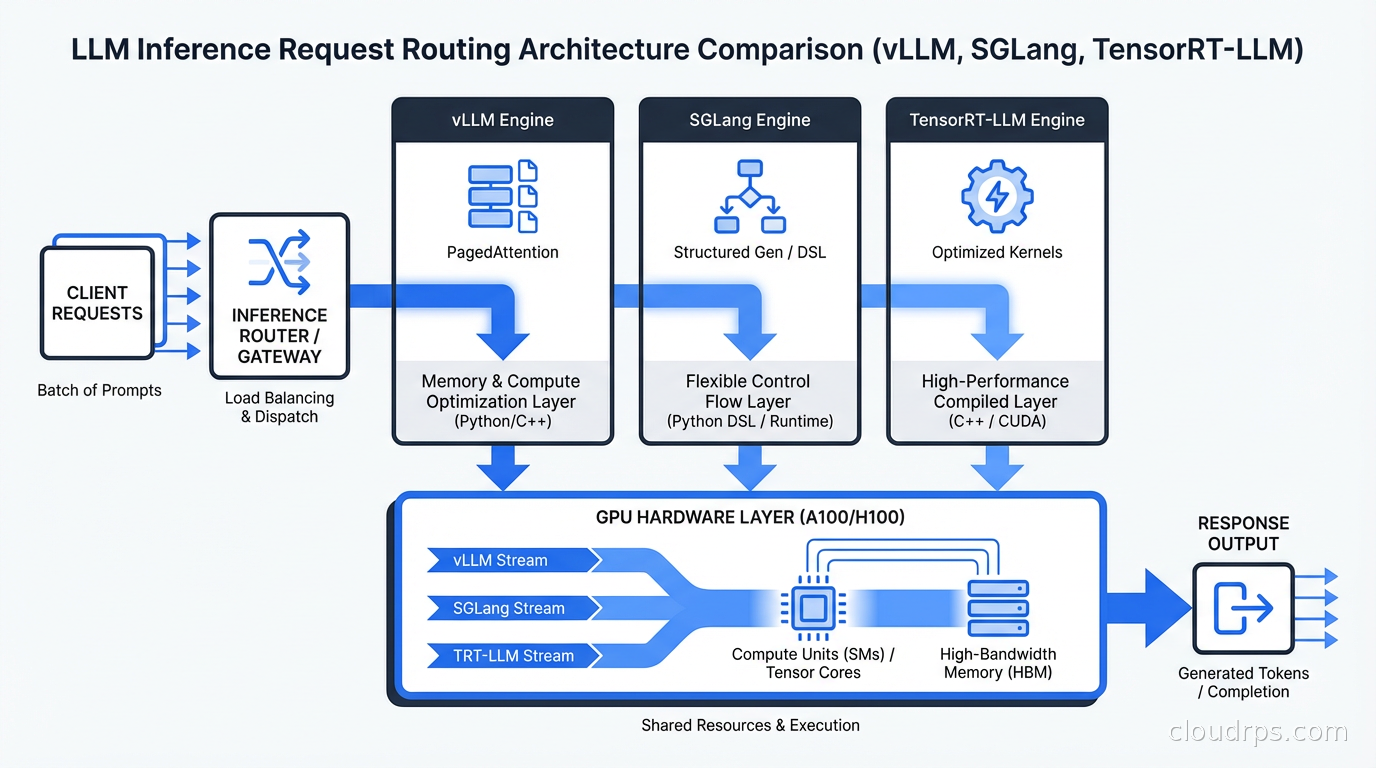
When you call model.generate() in PyTorch, you are leaving an enormous amount of performance on the floor. The naive approach processes one request at a time, waits for the full sequence to complete, then starts the next one. Modern inference engines solve a fundamentally different problem: how to pack as many concurrent requests as possible through a fixed GPU while maintaining acceptable latency guarantees.
The core technical problem is KV cache management. When generating a token, the model computes key-value tensors for every token in the context. For a 32k context window, that is a massive amount of GPU memory. Naive systems allocate this memory statically, which means a 100-token prompt consumes the same memory reservation as a 32,000-token prompt. Inference engines solve this with paged attention, prefix caching, and dynamic memory management, treating GPU VRAM like virtual memory in an operating system. Getting this right is the difference between 12% GPU utilization and 85%.
On top of the KV cache problem sits continuous batching. Traditional batch inference waits for a batch to fill, runs it, then starts the next batch. Continuous batching (also called iteration-level scheduling) adds new requests mid-flight and removes completed ones on every forward pass. This sounds straightforward. Implementing it correctly under variable sequence lengths is one of the harder systems engineering problems I have encountered. Getting it wrong causes head-of-line blocking where short requests wait behind long ones, making your p50 look great while your p99 tells a horror story.
Then there is tensor parallelism. Models that do not fit on one GPU need to be split across multiple GPUs. How you partition the model, how you synchronize between GPUs, and how you minimize communication overhead determines whether your multi-GPU setup achieves 1.9x throughput or 1.4x throughput relative to a single GPU. Every inference engine makes different trade-offs here, and the right answer depends on your network topology and GPU interconnect bandwidth.
vLLM: The Ecosystem Standard Bearer
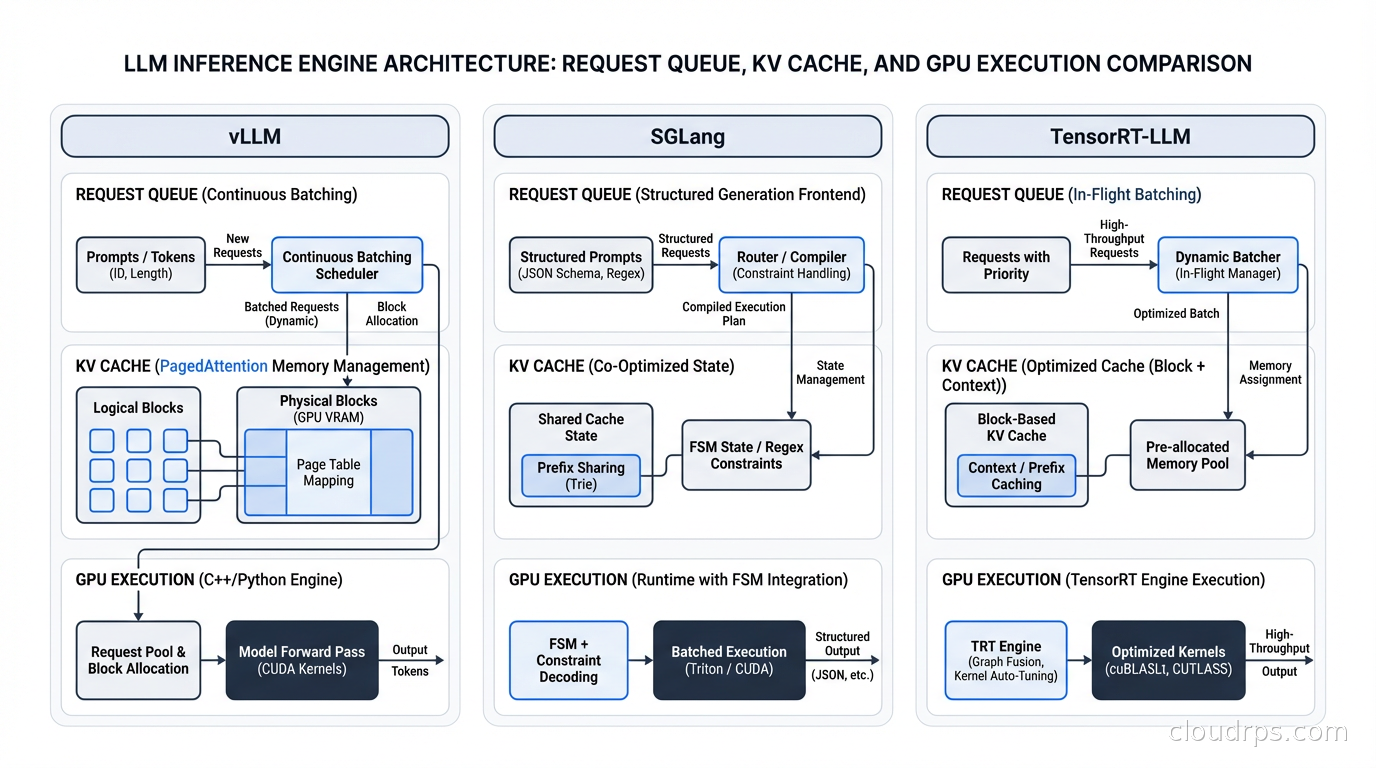
vLLM was the first inference engine to popularize PagedAttention, the memory management technique that brought continuous batching to practical production use. The PagedAttention paper came out of UC Berkeley in 2023, and within a year vLLM had become the default answer to “how do I serve this model.” I have deployed it at three different companies, across dozens of models, and it has rarely surprised me in a bad way.
The killer advantage of vLLM is breadth. It supports over 80 model architectures including encoder-decoder models like T5 and Whisper that most other engines ignore. It runs on NVIDIA GPUs, AMD ROCm, Google TPUs, AWS Trainium, and Intel Gaudi. If your team runs multiple hardware types across environments, vLLM is often the only engine that works everywhere without a separate codebase for each hardware target. Its contributor base is roughly three times larger than SGLang and about five times larger than TensorRT-LLM’s open component, which means bugs get found and fixed faster and niche model architectures get support sooner.
The OpenAI-compatible API is vLLM’s other major practical advantage. The vllm serve command starts a server that speaks the OpenAI Chat Completions protocol. Your existing application code, your existing OpenAI SDK integrations, your existing AI gateway layer all work without changes. This compatibility layer is genuinely valuable when you are migrating from a managed API to self-hosted inference, because it reduces the blast radius of the change to just the infrastructure, not the application code.
Performance-wise, vLLM is solid but no longer the fastest option. On H100 GPUs running Llama 3 70B at 80% load, it delivers roughly 12,500 tokens per second. That is excellent by historical standards but SGLang benchmarks approximately 29% higher for the same workload. For most applications, that gap is worth accepting because the vLLM deployment story is so much simpler. Where I see teams hit walls with vLLM is prefix caching for long, repeated system prompts. If you are running a RAG application where every request starts with a 4,000-token system prompt, vLLM’s automatic prefix caching helps, but it was designed for the general case. For the architecture behind vector search and RAG workloads, see our vector databases guide.
SGLang: Built for Structured Reasoning and Agent Workloads
SGLang (Structured Generation Language) emerged from the LMSYS organization and made a different bet than vLLM. Where vLLM optimized for general-purpose throughput, SGLang optimized for the workloads that dominate in 2026: multi-turn conversations, agentic loops, and structured JSON output. That bet has paid off spectacularly.
The core innovation is RadixAttention, a KV cache management system that treats cache entries as a radix tree (a trie with compressed edges) rather than a flat hash map. When you have shared prefixes, which is every RAG application, every multi-turn conversation, every request that starts with the same system prompt, RadixAttention finds and reuses cached computation automatically. On prefix-heavy workloads, SGLang delivers six times better cache utilization than naive systems and about twice the cache hit rate of vLLM’s standard prefix caching. I have seen teams running RAG pipelines get three times better effective throughput by switching to SGLang, simply because the system stopped recomputing context it had already seen.
For structured output, SGLang uses a compressed finite state machine for constrained decoding. When you request a JSON response, SGLang precomputes which tokens are valid at each step of generation, masking everything else. This is roughly three times faster than the approach most other engines use, which generates tokens and then validates them after the fact. If your application needs structured outputs and you are running latency-sensitive workloads, this difference shows up at p50, not just p99. For the kinds of agentic AI systems where structured outputs and multi-step reasoning chains are the norm, the case for SGLang is compelling. See our agentic AI production guide for the broader architecture picture.
The ecosystem story has matured significantly. SGLang powers Grok 3 at xAI, Azure model endpoints, LinkedIn AI features, Cursor code completion, and runs across hundreds of thousands of GPUs in production. That is not a research project anymore. The risk is that the contributor community is smaller than vLLM and certain model architectures (especially encoder-decoder models) have incomplete or missing support. Before committing to SGLang, verify your target model architecture is explicitly supported and test the full deployment path, not just the benchmark numbers.
TensorRT-LLM: NVIDIA’s Proprietary Performance Play
If you need the absolute maximum tokens per second from NVIDIA hardware and you can absorb significant operational complexity, TensorRT-LLM is the answer. NVIDIA built it to extract every cycle from their GPUs using hardware-specific optimizations that are simply not available to software running at a higher abstraction level. The INT4 quantization with GPTQ, the custom CUDA kernels for multi-head attention, the FlashAttention-3 integration that ships before any open-source implementation: all of it is optimized specifically for A100 and H100 silicon.
In my experience, TensorRT-LLM delivers 15 to 25% better throughput than vLLM for the same model on the same hardware, and the gap widens for quantized models. For large-scale deployments where GPU costs are the dominant line item, that improvement pays back the integration complexity within a few months. The problem is the integration complexity is genuinely significant. TensorRT-LLM requires a build step to compile your model into an optimized TensorRT engine. That build takes 30 to 90 minutes depending on model size. Your deployment pipeline needs to account for this. Your model update cycle needs to account for this. If you are doing frequent model updates or A/B testing different model versions, that friction adds up in ways that are easy to underestimate during evaluation.
The other constraint is hardware lock-in. TensorRT-LLM is NVIDIA-only, and many optimizations are specific to A100 or H100. If you run mixed GPU fleets or you are hedging between cloud providers as described in our GPU cloud infrastructure guide, you need a separate strategy for non-NVIDIA hardware. NVIDIA’s Triton Inference Server wraps TensorRT-LLM and adds a proper serving layer with request routing, dynamic batching, and health checking. Most production deployments I have seen combine TensorRT-LLM as the execution engine with Triton as the serving frontend.
The Rest of the Field
A few other engines deserve mention for specific use cases.
Text Generation Inference (TGI), Hugging Face’s server, was a vLLM competitor in 2023. It has since fallen behind on raw performance and is mainly used when teams need tight integration with the Hugging Face Hub or specific Hugging Face safety and moderation features. I would not start a new production deployment on TGI today unless the Hugging Face ecosystem integration is genuinely non-negotiable.
Ollama has become the standard for local development and is the right tool for that job. It downloads models, handles quantization automatically, and provides a clean API that mirrors the OpenAI protocol. Use it for developer laptops, local testing, and prototyping. Do not run it in production. Its batching implementation is limited and it is not designed for multi-tenant serving under real load.
LMDeploy from Shanghai AI Lab is genuinely competitive with SGLang on pure throughput benchmarks, particularly for the Qwen model family where they have invested heavily in architecture-specific optimizations. LMDeploy’s TurboMind engine has matched or beaten SGLang on several independent benchmarks for Qwen 2 and Qwen 2.5 models. If you are specifically deploying Qwen models, benchmark LMDeploy seriously before settling on another engine.
What the Benchmarks Actually Tell You
Benchmark comparisons between inference engines require careful interpretation. Most published numbers are on configurations that favor the organization doing the benchmarking. The three metrics that matter in production are not always the ones that look best in marketing materials.
Throughput (tokens per second at target GPU utilization) tells you cost efficiency: how much you can serve per dollar of GPU spend. Time-to-first-token (TTFT) tells you user-perceived latency for streaming responses: how long before the user sees anything. Inter-token latency tells you streaming smoothness: whether the stream feels like a continuous flow or a series of bursts. These three metrics trade off against each other in non-obvious ways, and different engines prioritize different ones. A system optimized for maximum throughput will typically sacrifice TTFT, which is exactly backwards from what a user-facing chat application needs.
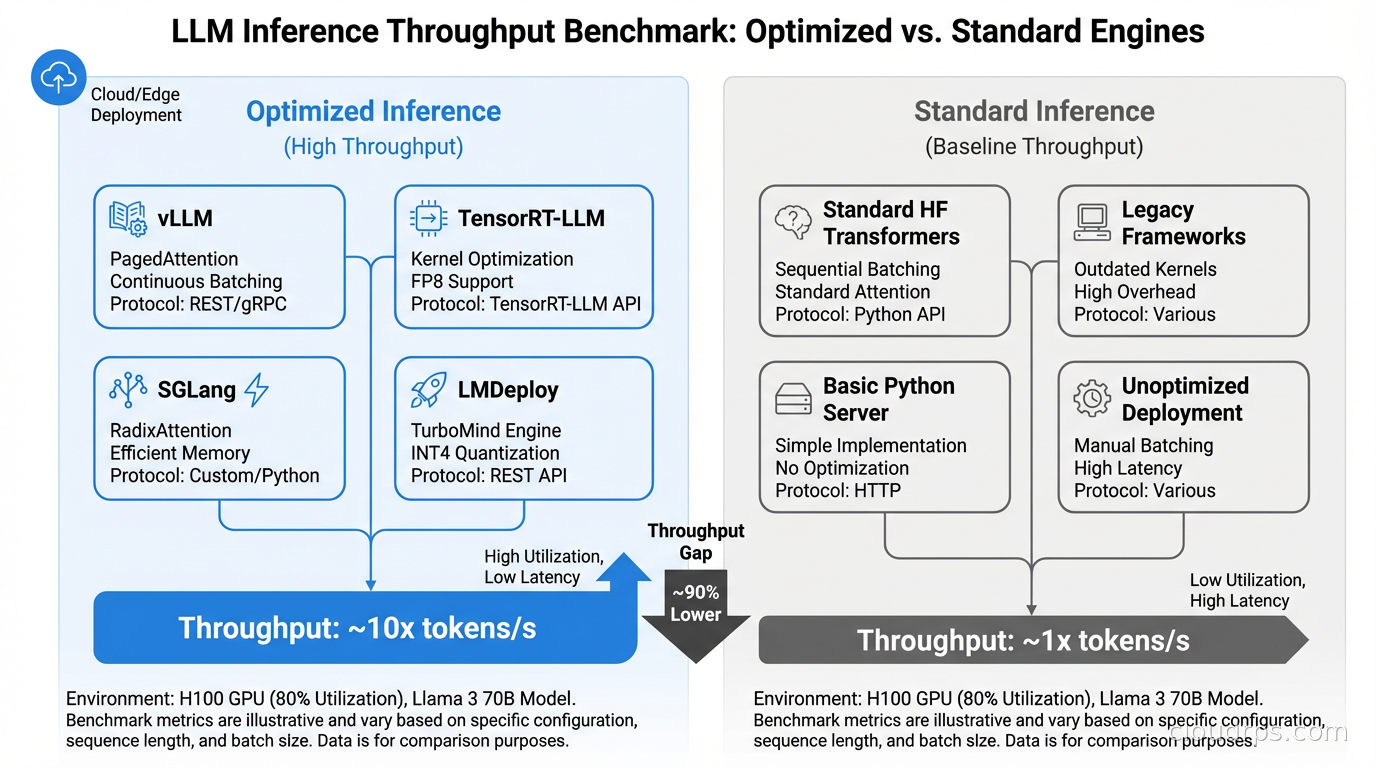
The honest summary from independent benchmarks run in early 2026: SGLang and vLLM are within 5% of each other for general mixed workloads. SGLang wins by 20 to 30% on prefix-heavy and structured-output workloads. TensorRT-LLM beats both by 15 to 25% for pure throughput when hardware-specific optimization is the priority and build complexity is acceptable. LMDeploy is competitive for Qwen-family models specifically. For a realistic production deployment with mixed request patterns, the gap between vLLM and SGLang is often smaller than the headline numbers suggest, and the decision frequently comes down to operational factors rather than raw performance.
The single most important thing I can tell you: run your own benchmarks with your actual request distribution, your actual model, and your actual latency requirements. I have watched teams choose SGLang based on a published benchmark that was running a different model architecture on a completely different workload pattern than their production use case. The results were disappointing.
Production Considerations Nobody Talks About
Memory management under heavy load is where inference engines diverge most sharply from each other.
vLLM’s paged attention includes KV cache preemption: when memory pressure is high, it suspends long-running requests and frees their KV cache memory. This keeps the system from OOMing but causes sudden latency spikes for the preempted requests. SGLang handles memory pressure differently, with aggressive eviction of less-recently-used cache entries from the RadixAttention tree. This is better for cache-heavy workloads but can cause cache thrashing under adversarial request patterns. TensorRT-LLM is stricter: it rejects requests with a 503 when capacity is exceeded rather than degrading service quality. None of these approaches is universally better. The right choice depends on your SLO commitments and whether you prefer predictable rejection over unpredictable degradation.
Speculative decoding is a technique where a smaller draft model generates candidate tokens at high speed and the main model verifies them in parallel. Done correctly, it reduces TTFT by two to three times for many workloads. Both vLLM and SGLang support speculative decoding, but the implementation maturity differs. TensorRT-LLM’s speculative decoding is the most polished and has been in production the longest. If TTFT is your primary bottleneck, speculative decoding is often worth the complexity before you add more hardware.
Multi-node serving matters once your model exceeds a single 8-GPU node. SGLang’s recent work on disaggregated prefill and decode, separating the prompt processing phase from the token generation phase across different node pools, is ahead of vLLM’s implementation for this pattern. This matters significantly for very large models (405B parameters and above) and for workloads where prompt processing is the bottleneck. The InfiniBand networking, RDMA configuration, and node failure handling required for multi-node inference must be planned together with the engine choice, not independently.
The Decision Framework
Here is the framework I actually use when evaluating inference engines for a new deployment.
Start with your primary workload type. Multi-turn conversations with long shared history, RAG applications with repeated system prompts, and agentic applications with structured output requirements all favor SGLang. Batch processing pipelines (document summarization, offline classification, code generation pipelines) favor TensorRT-LLM or SGLang depending on hardware constraints. General-purpose APIs that need to support many model architectures including encoder-decoder models favor vLLM. The key question is whether your workload is prefix-heavy, structured-output-heavy, or neither.
Next, evaluate operational constraints. How frequently will you update models? Weekly or more frequent updates favor vLLM or SGLang over TensorRT-LLM because of the build time. Do you run multiple hardware types? Only vLLM runs on AMD, TPUs, and Trainium alongside NVIDIA with full support. Do you have GPU cost pressure severe enough that a 20% throughput improvement justifies two to four weeks of engineering investment to deploy and operate? If not, start with vLLM and benchmark before switching.
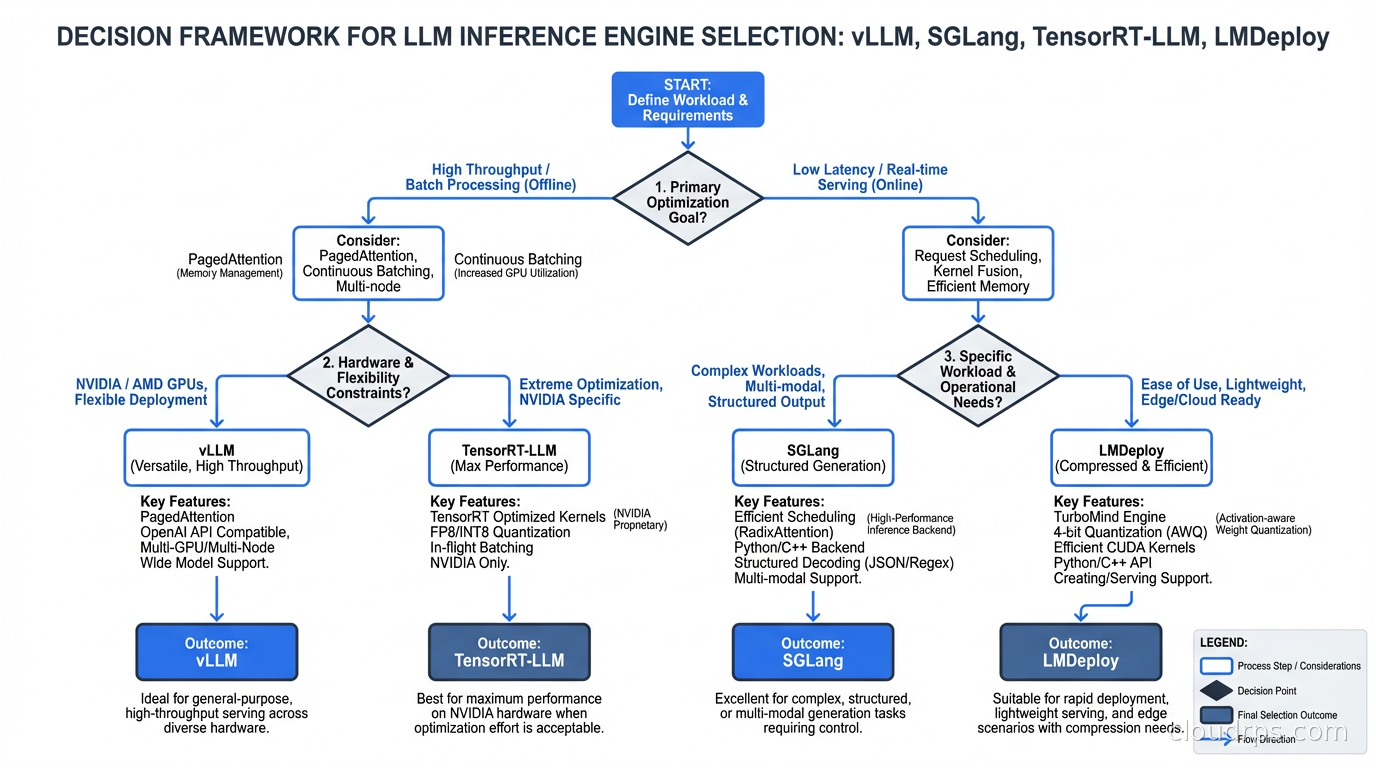
Then check your team’s existing operational context. If you are already running Kubernetes and are comfortable with Kubernetes deployments, both vLLM and SGLang have Helm charts and Kubernetes operators. If you are running AWS and are already using SageMaker, TensorRT-LLM through SageMaker managed endpoints is a reasonable path that offloads the Triton configuration. The inference engine does not exist in isolation from the rest of your AI infrastructure: it is one layer in a stack that includes hardware selection, the serving and routing layer above it, and the application code that calls it.
Finally, benchmark with your actual workload before committing. Spin up a single GPU instance, run your target model on vLLM and SGLang, send your actual request distribution (not synthetic benchmarks), and measure TTFT, throughput, and inter-token latency at your target utilization level. This takes one day. It will tell you more than any published benchmark and almost certainly reveal surprising differences in how each engine handles your specific request patterns.
Deployment Patterns That Work
The pattern I recommend for teams starting out: deploy vLLM with its vllm serve command behind an OpenAI-compatible endpoint, with the AI gateway layer handling routing, rate limiting, and cost tracking. This uses the same client code as a managed API, keeps the application layer fully decoupled from the inference engine, and makes switching engines later a single-day infrastructure change rather than a code migration.
For teams at significant scale (more than 30 GPU nodes), the architecture I have seen work is heterogeneous engine routing at the gateway layer. SGLang for primary conversational and RAG models where prefix caching delivers measurable cost savings. TensorRT-LLM for batch processing models where throughput is the only metric that matters and the build complexity is justified by volume. vLLM as a fallback for model types and hardware targets that the primary engines do not support. This heterogeneous approach adds operational complexity, but at sufficient scale the cost savings are substantial.
Where This Is Heading
The inference engine landscape in 2026 is still fragmented in ways that will not survive the next two years. NVIDIA is investing heavily in TensorRT-LLM and, as NVIDIA hardware continues to dominate AI compute, hardware-specific optimization will put increasing pressure on hardware-agnostic engines. At the same time, vLLM’s and SGLang’s contributor momentum is accelerating with each major model release, and the performance gap narrows steadily.
My read: by 2027 you will be choosing between two engines in most cases. The open-source general-purpose standard (likely SGLang absorbing vLLM’s ecosystem breadth, or vice versa through convergence) and NVIDIA’s proprietary option for maximum performance on NVIDIA hardware. The middle of the field will consolidate or fade.
For right now, start with vLLM for new projects. Benchmark SGLang if you have prefix-heavy or structured-output workloads and the performance data justifies the ecosystem trade-offs. Evaluate TensorRT-LLM only after you have proven a throughput bottleneck that the open-source options cannot close at acceptable cost. Do not over-engineer this decision at the start. The inference engine is easier to swap later than almost any other layer in your stack, especially when your application talks to an OpenAI-compatible endpoint rather than engine-specific APIs. Build that abstraction in from day one and the choice becomes reversible.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.