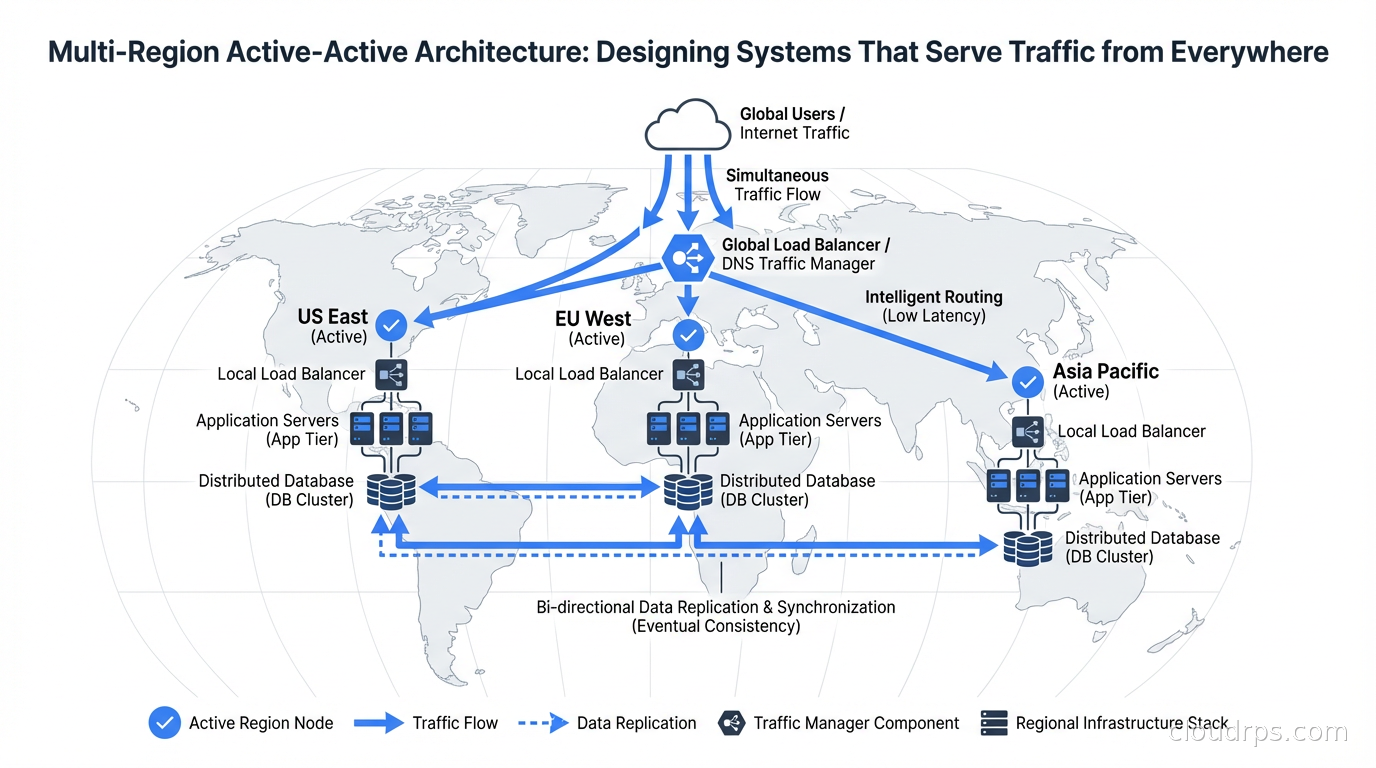
Most teams think they want active-active multi-region architecture. What they actually want is faster recovery from regional failures with low operational complexity. Those are different things, and the gap between them is where teams spend a lot of money and engineering time building infrastructure they did not need.
That said, active-active is real and valuable for specific classes of systems. I have designed and operated active-active architectures for high-traffic consumer applications where the latency reduction from serving users from their nearest region directly drove engagement metrics. I have also seen teams build active-active when active-passive with fast failover would have been cheaper, simpler, and equally resilient. This article covers both when to use active-active and how to do it right.
Active-Active vs Active-Passive: The Real Difference
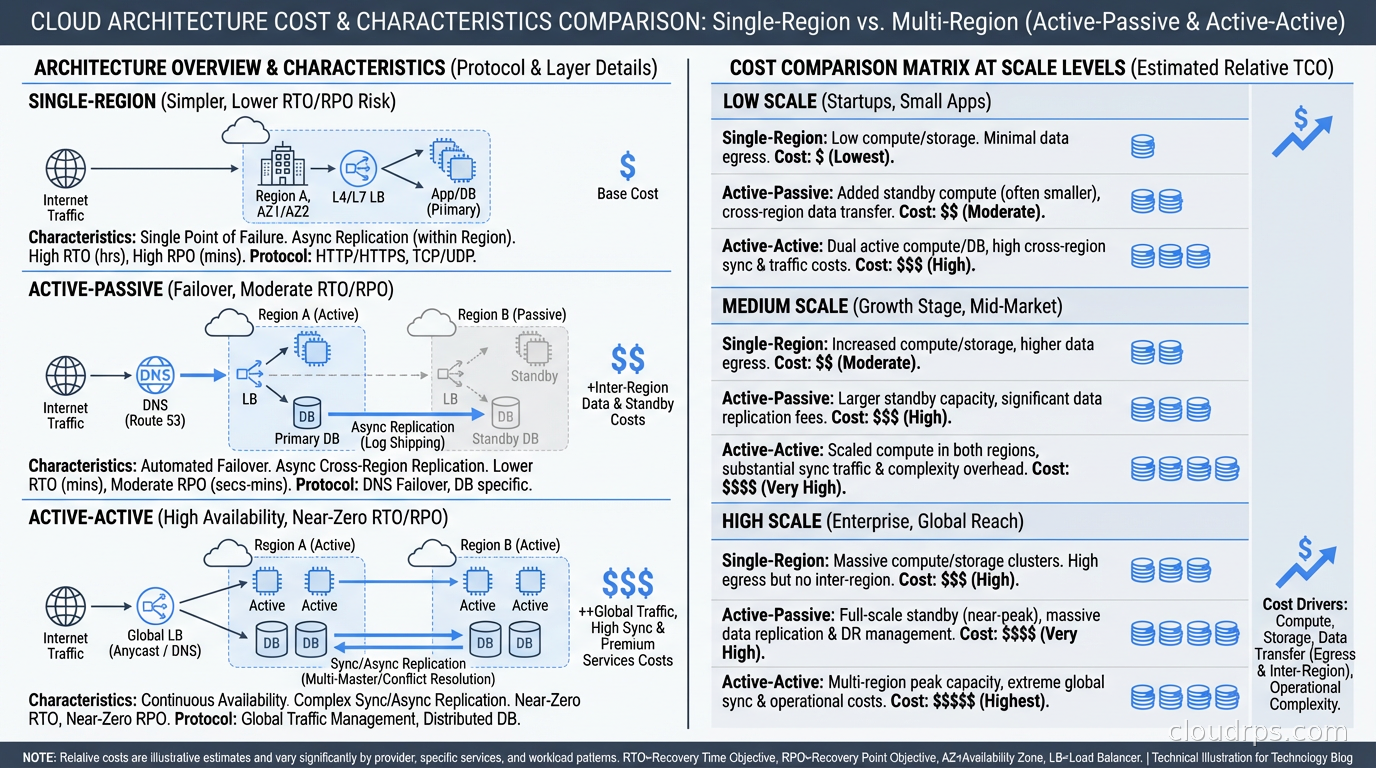
In active-passive architecture, one region handles all traffic. The passive region is a warm standby: it has running infrastructure, receives replicated data, and can take over if the primary fails. Failover takes seconds to minutes, depending on how automated your runbooks are. The passive region is a cost center that earns its keep only during failures.
In active-active architecture, both (or all) regions handle real user traffic simultaneously. Each region is a primary for some subset of requests. The critical implication: writes can happen in any region, which means all regions must be able to receive writes and eventually synchronize.
This is where active-active gets hard. CAP theorem tells you that a distributed system cannot be simultaneously consistent, available, and partition-tolerant. In active-active with writes in multiple regions, you are choosing availability and partition tolerance, which means accepting eventual consistency. Some operations will see stale data. Some concurrent writes will conflict and require resolution.
The operational complexity and cost of active-active are significant. Before committing to it, answer honestly: what problem are you solving?
If the answer is “we need low latency globally”: You can often achieve this with active-active at the read layer and active-passive at the write layer. Users read from the nearest region (fast). Writes go to the primary region (slightly more latency). This is much simpler than full active-active and serves most latency requirements.
If the answer is “we cannot afford downtime during a regional failure”: Active-passive with automated failover achieves sub-minute RTO for most failure scenarios. If you can tolerate 30-60 seconds of downtime during a failure, active-passive is the right answer and an order of magnitude simpler.
If the answer is “we need zero write latency from any region” or “we cannot tolerate any data loss during a regional failure”: Now you have a genuine active-active requirement. Proceed.
DNS and Traffic Routing
Global traffic distribution is the entry point for active-active. At the DNS layer, you use latency-based or geolocation routing to direct users to the nearest region.
DNS record configuration for active-active typically uses weighted or latency-based routing at the DNS level (Route 53 latency policies, GCP Cloud DNS routing policies), combined with anycast IP addresses where applicable. Each region gets its own endpoint, and the DNS routing layer ensures users hit the nearest one.
The health check integration is critical. If a region fails, DNS routing must stop sending traffic to it automatically. Route 53 health checks, combined with CloudWatch alarms, can withdraw a region from rotation within thirty seconds of detecting unhealthy responses. Configure health checks to verify actual application health, not just TCP connectivity. A region where the application is running but the database is unreachable should be marked unhealthy.
Clients with long DNS TTLs will continue hitting the failed region after DNS has been updated. Set your DNS TTLs low for production traffic endpoints (60 seconds is common). This conflicts with caching benefits, so use different TTLs for different record types: short TTLs for the records your load balancer endpoints return, longer for supporting records. Private connectivity between regions uses Transit Gateway inter-region peering, which routes traffic over AWS’s backbone without touching the internet; the AWS VPC connectivity guide covers how to design that layer.
The Database Problem
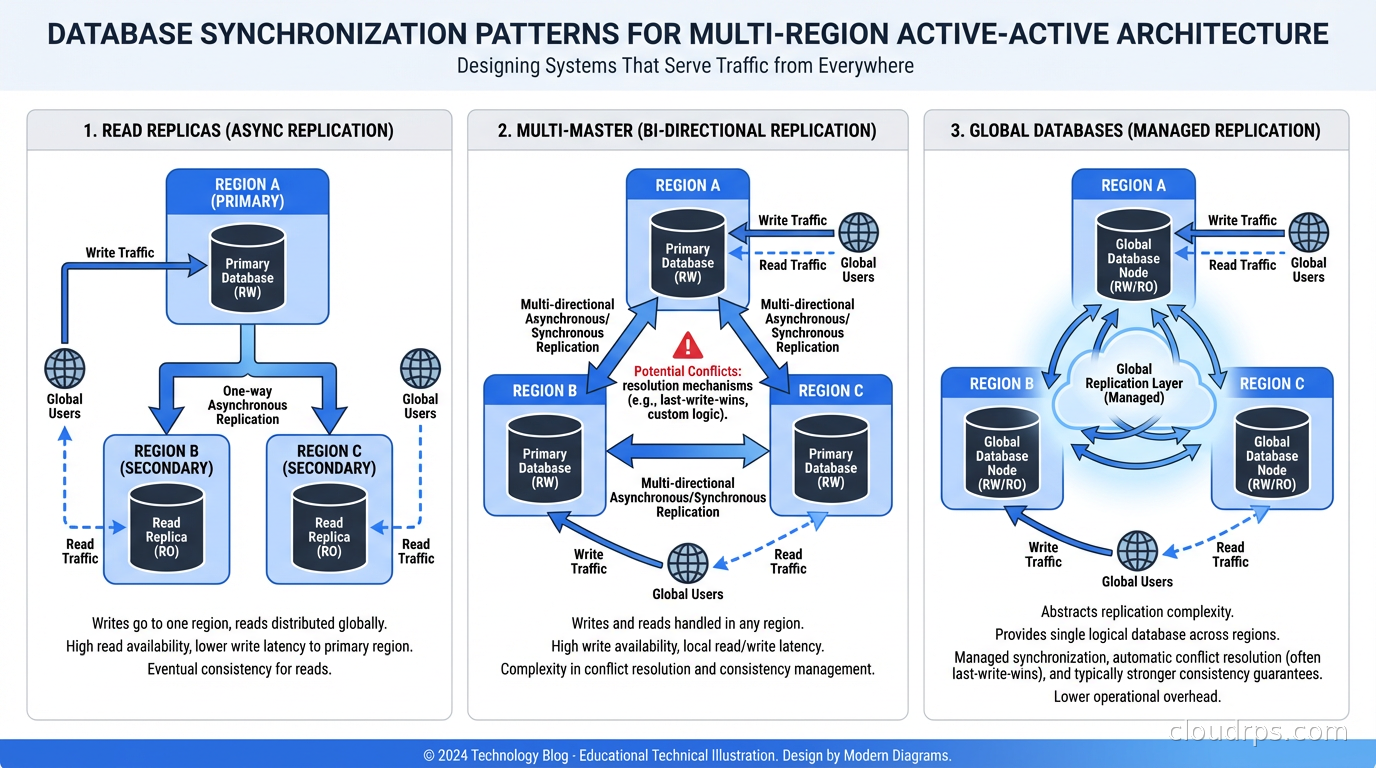
Database synchronization is the hardest part of active-active. The options form a spectrum from operationally simple to arbitrarily complex.
Option 1: Read replicas in each region, writes to primary region only. Not true active-active for writes, but handles the majority of traffic patterns. Read-heavy applications (most consumer products) see significant latency improvements. The database replication overhead is manageable, and conflicts are impossible because writes are serialized through a single primary. This is the right starting point for most teams.
Option 2: Multi-master Postgres or MySQL. Tools like BDR (Bi-Directional Replication) for Postgres or Group Replication for MySQL enable writes in multiple regions, with logical replication synchronizing changes. Conflicts (concurrent updates to the same row in different regions) are resolved by user-configurable policies (last-write-wins, origin priority, etc.). These work well for workloads where actual write conflicts are rare (users in different regions usually write different data).
Option 3: Globally distributed databases. CockroachDB, Google Spanner, and PlanetScale are designed from the ground up for multi-region active-active. They handle conflict resolution, distributed transactions, and replication automatically. The trade-off is cost, operational complexity of the database itself (or the pricing of managed services), and in the case of Spanner, significant vendor lock-in. For Spanner specifically, the consistency guarantees are remarkable (externally consistent distributed transactions), but you pay for them in latency because achieving consensus across regions takes time. For a detailed breakdown of CockroachDB versus YugabyteDB versus Spanner versus TiDB, see the distributed SQL database comparison.
Option 4: CRDT-based data structures. Conflict-free Replicated Data Types are data structures that are specifically designed to be merged without conflicts, regardless of the order of operations. Counters, sets, maps with specific merge semantics. Redis CRDTs (available in Redis Enterprise) and dedicated CRDT databases like Riak make this practical. CRDTs work well for specific data types: user presence indicators, shopping cart items, feature flag evaluations. They do not work for arbitrary relational data.
Data Partitioning for Active-Active
One of the most effective strategies for avoiding conflicts is partitioning data such that each record is “owned” by a specific region, with the owning region handling all writes for that record.
Geographic partitioning is the natural fit: a user in Europe is owned by the EU region, and all their data is written there. EU users reading from the EU region see fully consistent data. US users reading their own data from the US region also see fully consistent data. Cross-region reads (a US user accessing data about a resource owned by the EU region) see eventually consistent reads.
This pattern eliminates most conflicts because writes to the same record are serialized through the owning region. The challenge is determining and enforcing ownership, especially for data that does not map cleanly to geography. A B2B application where a US company shares a project with a European partner has a genuine conflict: who owns the shared resource?
Sharding strategies that work for single-region scaling can be extended to multi-region active-active by treating region as an additional shard dimension. The mental model is similar; the implementation requires careful thought about where reads and writes for cross-shard data go.
Service Architecture for Active-Active
The application tier in active-active is usually simpler than the database tier. Stateless services deployed in each region handle local requests. High availability within each region uses the standard patterns: multiple availability zones, auto-scaling, health checks, circuit breakers.
The complexity comes from services that maintain state or coordinate across regions.
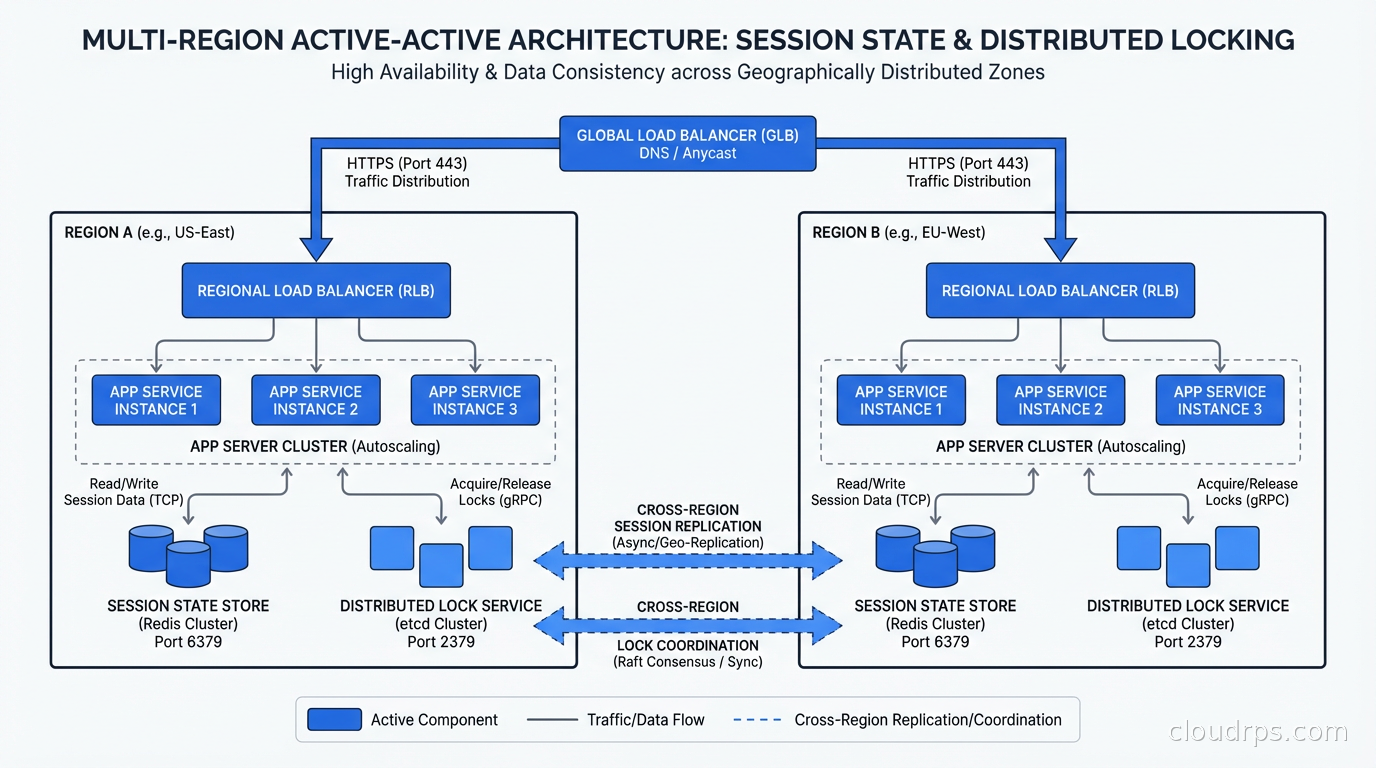
Session state: Use a global session store or design for session affinity. If a user’s session is created in us-east-1 and a subsequent request routes to eu-west-1, the EU instance must be able to read the session. Options: replicate session data globally (Redis with cross-region replication), use JWT tokens that carry session state without server-side storage, or accept that session affinity via sticky routing is required for your application.
Distributed locking: If your application uses distributed locks for coordination (preventing duplicate payment processing, enforcing unique constraints across shards), those locks must be globally coordinated. This is expensive in a multi-region setup because cross-region lock acquisition requires a network round trip with tens of milliseconds of latency. Design your application to minimize or eliminate cross-region lock requirements.
Background jobs: Deduplicate background job processing across regions. A webhook delivery job that runs in every region will triple your deliveries if not designed carefully. Use region-specific job queues that are populated based on data ownership, or use a global job queue with region-aware consumer partitioning.
Failure Modes Unique to Active-Active
Active-active introduces failure modes that do not exist in single-region or active-passive systems.
Split brain: If the network link between regions fails but both regions remain internally healthy, they will both continue accepting writes that conflict with each other. When the network recovers, you have a backlog of conflicts to resolve. Your conflict resolution strategy must handle this gracefully. Favor automated resolution policies that can merge the split-brain window’s worth of changes, and have monitoring that detects and alerts on elevated conflict rates.
Replication lag spikes: Under heavy write load or network stress, replication lag between regions can spike from milliseconds to seconds or even minutes. A user who wrote data in us-east-1 and then issues a read from eu-west-1 may see stale data during lag spikes. Design your application to handle stale reads gracefully. At minimum, monitor and alert on replication lag and have operational runbooks for when it exceeds your threshold.
Asymmetric load: One region receives more traffic than another. The lighter region is over-provisioned. Auto-scaling helps but cannot anticipate sudden traffic shifts. Budget for this over-provisioning as an inherent cost of active-active.
RTO and RPO: What Active-Active Actually Buys You
For RTO and RPO planning, active-active changes the math significantly. In a regional failure:
- RTO: Near-zero. DNS health checks reroute traffic within 30-60 seconds. No manual failover required.
- RPO: Depends entirely on your replication strategy. With synchronous replication across regions, RPO is zero but write latency increases by the cross-region round trip. With asynchronous replication, RPO is the replication lag at the time of failure (typically seconds to minutes, depending on traffic and lag).
Most active-active systems use asynchronous replication because the latency cost of synchronous multi-region writes is prohibitive (50-150ms round trip latency added to every write). Accepting RPO of a few seconds of data loss is usually acceptable for the latency benefit.
The disaster recovery calculus is different for active-active than for traditional DR. Traditional DR is about surviving a specific scenario (data center fire, regional cloud outage) with acceptable loss. Active-active is about continuous resilience where a regional failure is a non-event for users. The operational discipline required is higher because both regions are always live and any infrastructure change affects production.
Cost Reality Check
Active-active costs roughly two to three times more than single-region for the same traffic. You are running full production infrastructure in multiple regions simultaneously. Cross-region data transfer costs add up quickly (egress pricing for replication traffic). The engineering investment to design and maintain active-active correctly is substantial.
Before committing, run the numbers with your actual traffic and data volumes. For many applications, the incremental resilience of active-active over well-implemented active-passive does not justify the cost differential. If you can achieve 99.99% availability with active-passive and your requirement is 99.99%, stop there. If you need 99.999% or need provably zero RTO, active-active earns its cost.
Active-active is not a goal. It is a tool for specific requirements. Use it when those requirements genuinely exist, design it carefully when you do, and resist the organizational pressure to build it “just in case” when simpler architectures will do the job.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.