I spent a good chunk of 2018 buried in Kafka operational misery. Three-broker cluster, ZooKeeper ensemble, replication factors, partition reassignments that took hours, broker restarts that caused consumer lag spikes and woke up the on-call engineer at 2 AM. The throughput was great. The operational surface area was not. When someone on my team finally suggested we look at NATS for our microservice event bus, I was skeptical. A messaging system that fit in a single binary under 20MB? Sure.
Twenty years in cloud infrastructure teaches you that sometimes the boring, simple tool is the right tool. NATS turned out to be exactly that for about 70% of what we were using Kafka for. The other 30%, we kept on Kafka. That distinction matters, and it is what this article is really about.
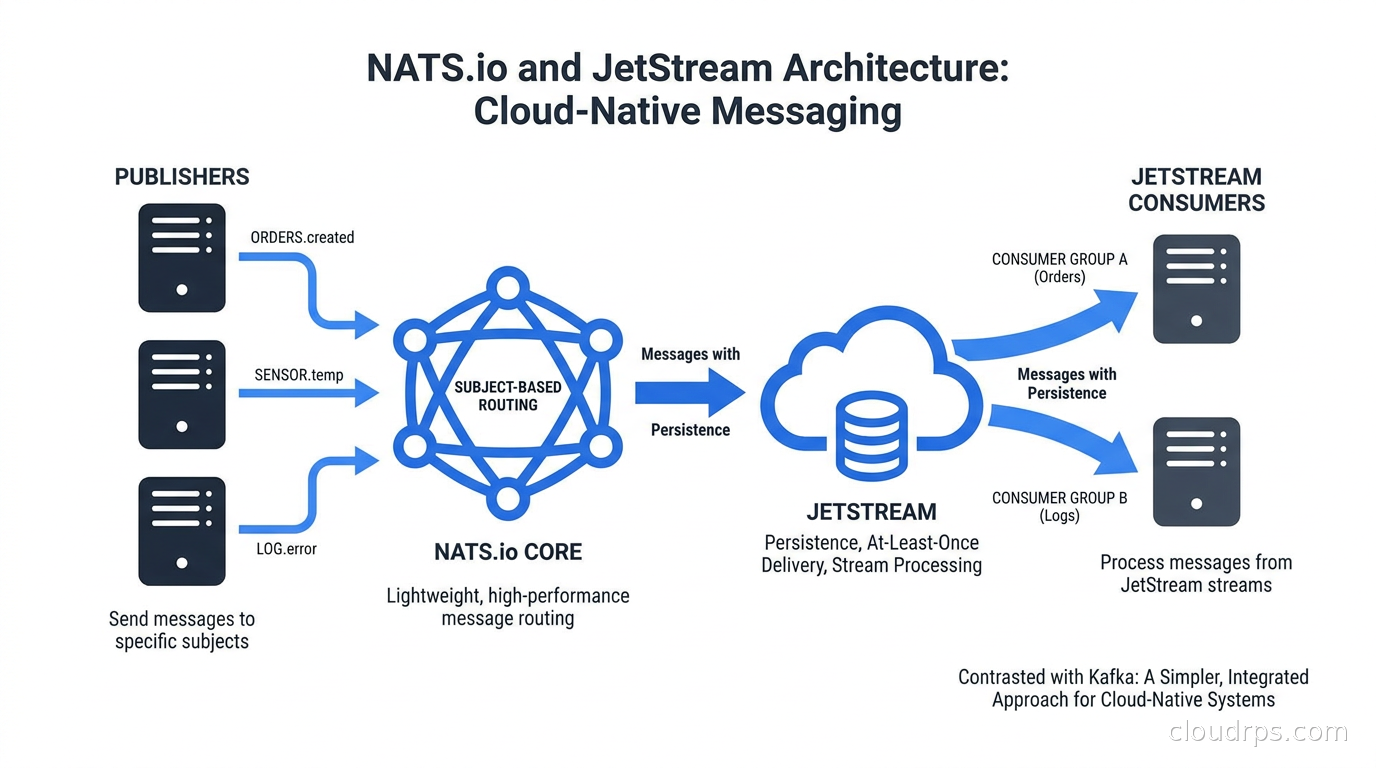
What NATS Actually Is
NATS is an open-source messaging system originally built by Apcera (now under the CNCF umbrella as a graduated project). The core server is written in Go, the client libraries cover every language you care about, and the whole thing is built around a deceptively simple idea: subjects as addresses, subscriptions as routing, and a protocol so lean it fits on a business card.
At its heart, NATS has two layers. Core NATS is the fire-and-forget, at-most-once delivery layer. Messages go in, messages come out, and if nobody is listening when a message arrives, it disappears. That sounds like a limitation until you realize that most inter-service communication in a microservice architecture is actually fine with at-most-once delivery. Service A pings service B. B processes it. If B was down for that specific message, A retries or the user notices and tries again. This is how the internet works. This is how HTTP works.
JetStream is the second layer, added in NATS 2.2, and it changes the character of the system entirely. JetStream adds persistence, stream retention policies, consumer groups with acknowledgments, and replay capabilities. It turns NATS into a durable message broker that can compete directly with Kafka for many workloads.
The Core NATS Model
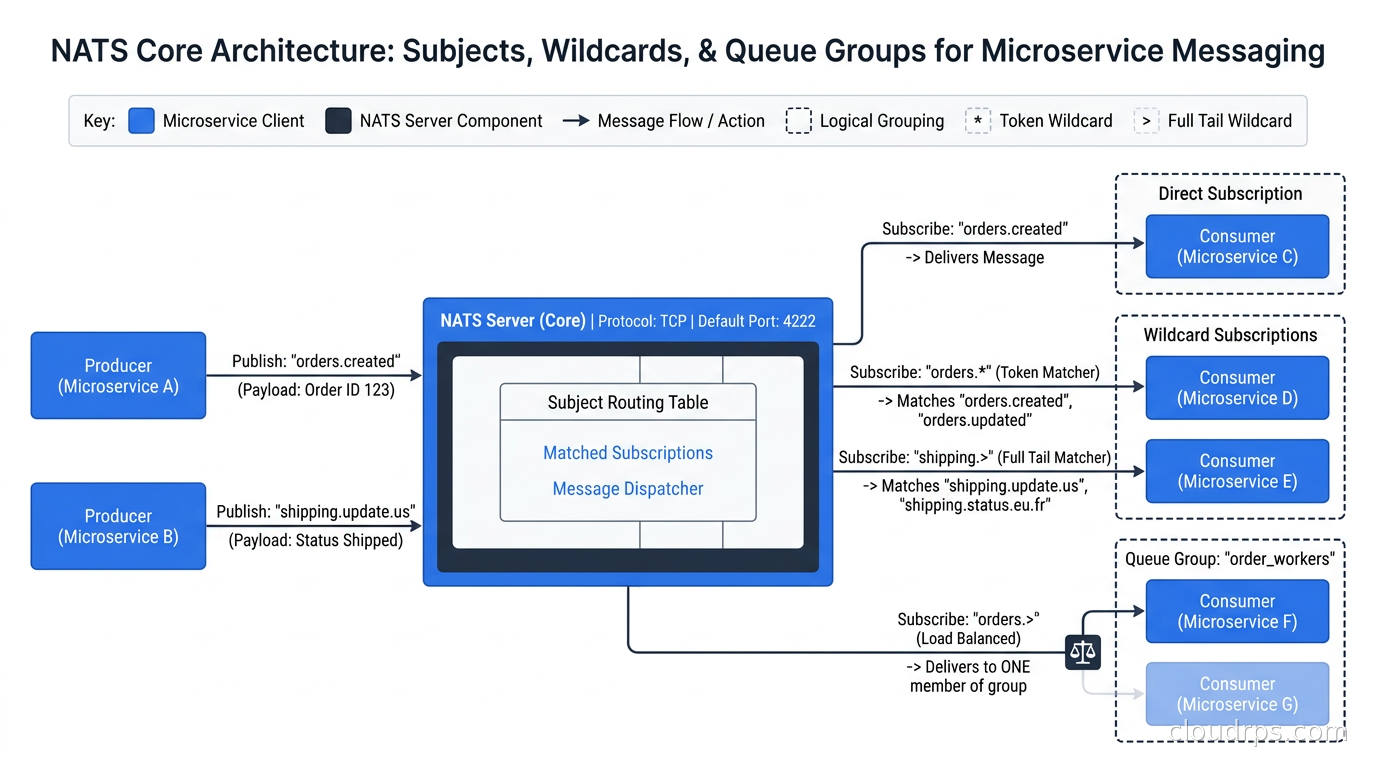
NATS uses subjects for routing. A subject is just a string, like orders.created, payments.processed, or sensor.us-east.temperature. Wildcards work with * (single token) and > (multi-token), so a subscriber on sensor.> receives everything published to sensor.us-east.temperature, sensor.eu-west.pressure, and anything else under that prefix.
This wildcard hierarchy is more powerful than it looks. I have built entire event routing topologies on top of subject namespacing. Think of it as a hierarchical topic system where the namespace is part of the contract, not an afterthought.
Publish/Subscribe is the baseline. A publisher sends to a subject, all subscribers receive the message. No consumer groups, no offsets, no coordination. Latency in the low microseconds for intra-cluster delivery.
Request/Reply is a pattern NATS makes native. A requester publishes to a subject and provides a reply-to inbox (an auto-generated subject unique to that request). Responders subscribe to the subject, process the message, and publish back to the inbox. This is synchronous RPC over an asynchronous messaging layer, and it works remarkably well for service-to-service communication where you need a response.
Queue Groups are NATS’s answer to competing consumers. Multiple subscribers join a named queue group on the same subject. Messages are load-balanced across members. If a member goes down, other members pick up the load. No broker-side configuration required. You just add the queue group name when subscribing. This is where NATS genuinely shines compared to building competing consumer patterns in other systems.
JetStream: Persistence Without the Operational Weight
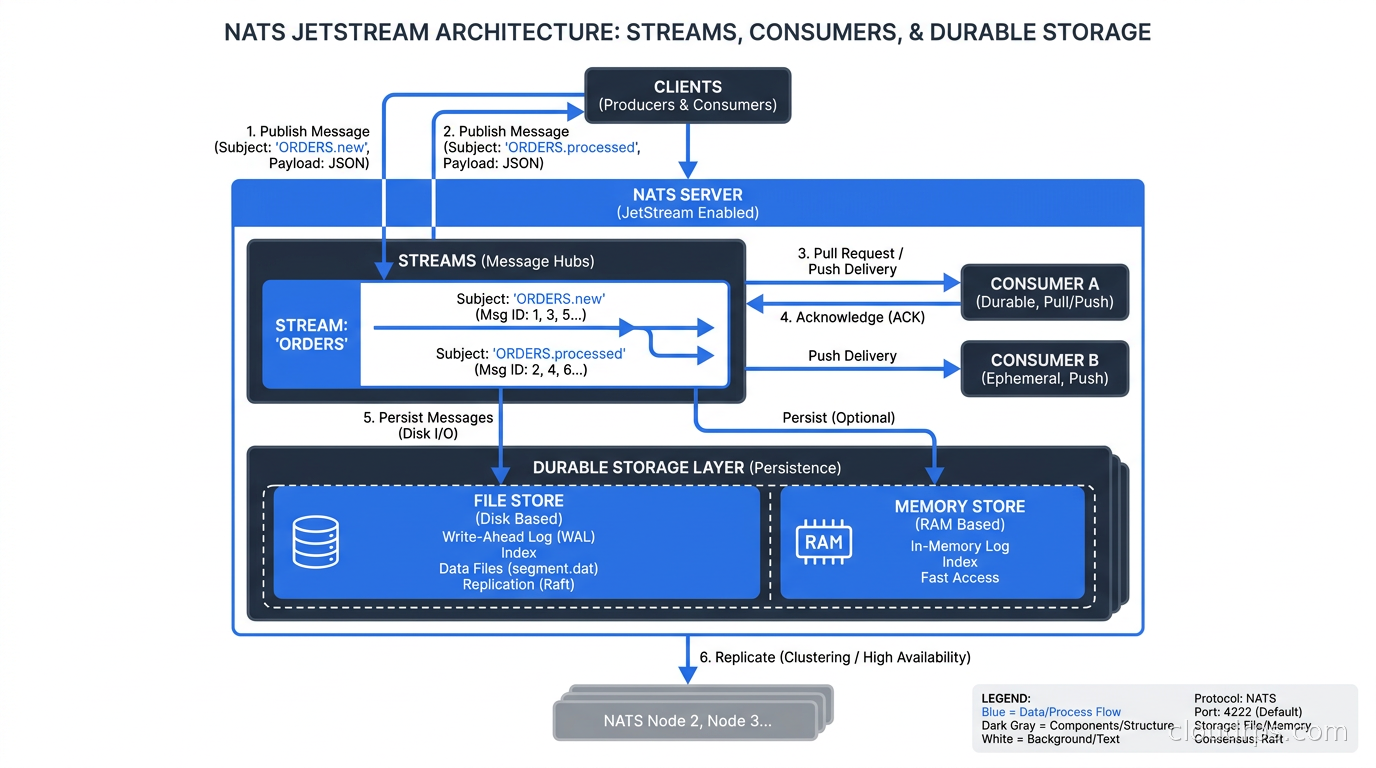
JetStream sits on top of Core NATS and adds a storage layer backed by either file storage or in-memory storage. The key concepts are streams and consumers.
A stream captures messages published to one or more subjects and retains them according to a policy. You can retain by message count, byte size, or age. You can configure replication across cluster nodes (typically R1, R3, or R5). Streams are the durable store.
A consumer is a view into a stream for a specific subscriber or group of subscribers. Consumers can be push-based (server delivers messages) or pull-based (client fetches messages on demand). They track acknowledgment state, support redelivery on failure, and can start from the beginning of a stream, from a specific sequence number, or from a point in time.
The pull consumer model deserves special attention. Pull consumers let clients control their own rate of consumption. This is critical for workloads where consumers need backpressure, want to batch fetch, or run at variable speeds. It is a more natural fit than Kafka’s offset-commit model for many application patterns. The NATS team made pull consumers the recommended approach for most durable workloads starting in NATS 2.10.
Key-Value store is built on JetStream streams and provides a simple get/put/delete/watch interface. It is not a replacement for Redis in caching-heavy workloads (see our comparison of distributed caching options), but for configuration data, feature flags, and lightweight coordination state, it is extremely convenient to have this baked directly into your messaging system.
Object store is also built on JetStream and handles large binary payloads with chunking and reassembly. Useful for passing model files, images, or large configuration blobs through the same messaging infrastructure without needing a separate object storage call.
NATS vs Kafka: The Honest Comparison
I have seen a lot of blog posts that treat this comparison as simple. It is not. The right answer depends on what you are actually doing.
Where NATS wins:
Operational simplicity is the biggest differentiator. A three-node NATS cluster with JetStream enabled runs on under 256MB of RAM per node and a handful of CPU threads. A comparable Kafka cluster needs brokers, KRaft controllers (or ZooKeeper historically), careful tuning of heap sizes, log retention, replica assignment, and ISR monitoring. The NATS cluster just works. I have bootstrapped production NATS clusters in under an hour from scratch. I have spent days babysitting Kafka cluster rebalances.
Latency at the low end. Core NATS regularly achieves sub-millisecond delivery within a datacenter. Kafka’s design is optimized for throughput, not latency, and it shows. For real-time service communication where you need fast acknowledgments, NATS has an edge.
Multi-tenancy. NATS supports accounts with isolated subject namespaces, separate JetStream storage quotas, and fine-grained credential delegation. You can run one NATS cluster and give five teams completely isolated messaging environments with their own resource limits. Kafka multi-tenancy is possible but painful, typically requiring separate clusters or careful namespace discipline.
Request/reply patterns. Kafka requires explicit reply topics, correlation IDs, and application-level response routing. NATS makes this native. For microservice RPC patterns, the difference in implementation complexity is significant.
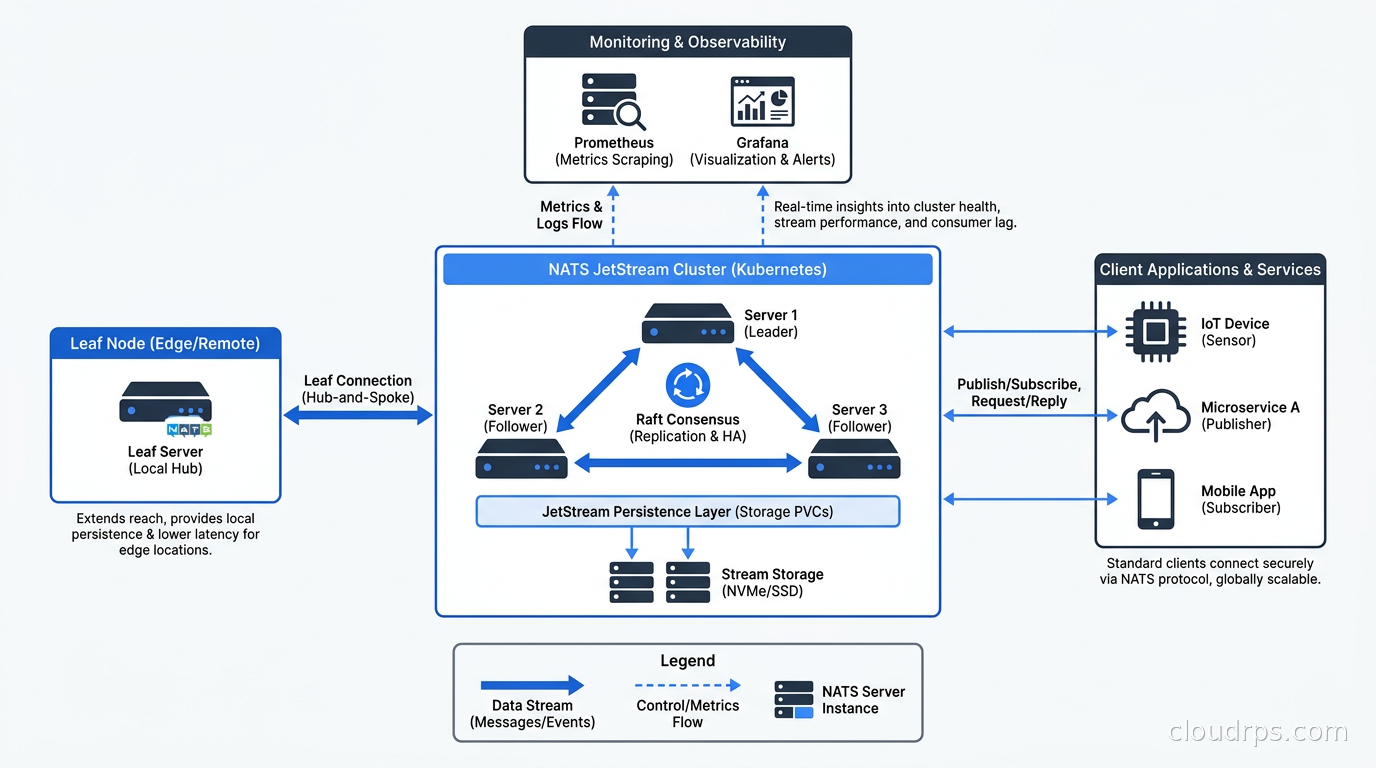
Leaf nodes for edge and IoT. NATS has a native concept called leaf nodes: NATS servers that connect to a central cluster and route specific subjects to and from the edge. You can run a NATS leaf node on an IoT gateway, a factory floor server, or a remote datacenter, and transparently bridge it into your central cluster. This architecture is non-trivial to replicate in Kafka.
Where Kafka wins:
Raw throughput at scale. Kafka benchmarks consistently show higher maximum throughput for high-cardinality, high-volume event pipelines. If you are ingesting millions of events per second from a fleet of mobile clients or a telemetry system, Kafka’s append-only log architecture and zero-copy reads give it an edge.
Long-term event retention and replay. Kafka is built around the concept of the log as the system of record. Retaining events for weeks or months and replaying them for new consumers or audit purposes is a first-class use case. JetStream supports retention and replay too, but Kafka’s storage model is more mature for the “event sourcing backbone” pattern.
Ecosystem depth. Kafka Connect, Kafka Streams, ksqlDB, and Schema Registry form a rich ecosystem for building data pipelines. If you are doing stream processing with Apache Flink or feeding a data lakehouse pipeline with Apache Iceberg, Kafka’s ecosystem integration is broader today.
My rule of thumb after twenty years of building distributed systems: if your primary use case is service-to-service event notification, task distribution, configuration propagation, or lightweight state synchronization, start with NATS. If your primary use case is high-volume data pipeline, event log, or analytics feed, use Kafka. These are not competing products for the same job. They are different tools solving overlapping but distinct problems.
If you are already evaluating Kafka alternatives like Redpanda, AutoMQ, or WarpStream, understand that those tools compete on Kafka’s home turf: high-throughput log streaming. NATS competes in a different lane.
Deploying NATS on Kubernetes
NATS is well-suited for Kubernetes. The NATS Helm chart is mature, the NATS operator exists for more complex cluster management, and the operational profile is lightweight enough that you are not fighting Kubernetes resource limits.
For a production JetStream cluster, I recommend the following setup. Run a StatefulSet with three replicas for R3 JetStream replication. Mount a PersistentVolumeClaim per pod for JetStream file storage. Configure liveness and readiness probes pointing at the monitoring endpoint on port 8222. Use a ClusterIP service for intra-cluster communication and a separate service for clients.
# Helm values for a production NATS JetStream cluster
config:
cluster:
enabled: true
replicas: 3
jetstream:
enabled: true
fileStore:
enabled: true
pvc:
size: 20Gi
storageClassName: gp3
merge:
max_payload: 8MB
ping_interval: 20s
The NATS server exposes a rich monitoring endpoint at /healthz, /varz, /connz, /routez, and /jsz (JetStream-specific). Hook these into your Prometheus and Grafana observability stack with the nats-exporter sidecar. The JetStream metrics at /jsz give you stream message counts, consumer ack pending, and storage utilization.
One operational pattern I have found invaluable: use NATS Surveyor alongside Prometheus for cluster health. Surveyor polls the cluster and exposes a rich set of metrics covering per-account stats, server health, and JetStream stream states. It is much more informative than the basic server-level metrics.
Authentication, Authorization, and Multi-Tenancy
NATS security is built around NKeys (Ed25519 keypairs) and JWTs for identity. The decentralized JWT model is one of NATS’s most underappreciated features. An operator issues account JWTs. Account administrators issue user JWTs. The NATS server validates the JWT chain without phoning home to an auth server on every connection. This is zero-trust by design without the operational overhead of a centralized auth service.
For simpler deployments, NATS supports username/password and token authentication. For production Kubernetes environments, the recommended approach is credential files containing the user JWT and NKey private key. These credentials are mounted as Kubernetes Secrets and injected into client pods.
Authorization maps credentials to subject permissions. A service can be granted publish rights to orders.> and subscribe rights to inventory.updates.*, nothing more. Subject-level permissions are enforced server-side. This is much more granular than Kafka’s ACL model and does not require a separate authorization service.
Multi-tenancy via accounts gives each team their own subject namespace, their own JetStream storage quota, and their own connection limits. Account isolation is enforced at the server level. Team A cannot subscribe to Team B’s subjects without explicit export/import configuration. For platform teams managing shared messaging infrastructure, this is a genuinely useful model.
Real-World Use Cases
Microservice event notification. The classic use case. Services publish domain events (user signed up, order placed, payment processed) to NATS subjects. Downstream services subscribe. Queue groups handle horizontal scaling. JetStream adds durability if the event must not be lost. This replaces a lot of what people use SNS/SQS for in AWS-native architectures, with lower latency and no per-message cost. (For AWS-specific event-driven architecture patterns, the tradeoffs between SNS, SQS, and EventBridge are worth understanding separately.)
IoT and edge telemetry. NATS leaf nodes make this elegant. Edge devices publish sensor readings to a local NATS leaf node. The leaf node bridges selected subjects to the central cluster. The central cluster’s JetStream persists the data. The edge node continues operating in island mode if connectivity drops, and reconnects transparently. I have seen this architecture handle fleets of 10,000 devices with a three-node central cluster under 30% load.
Distributed work queue. JetStream pull consumers with work queue retention (message deleted once any consumer acks it) create a durable, distributed task queue. Producers push tasks to a stream. Worker pods pull batches, process them, acknowledge. Add horizontal scaling for workers. This pattern handles everything from image processing pipelines to batch data enrichment jobs. It is simpler to operate than running a separate task queue system.
Configuration and feature flag propagation. The JetStream KV store with watch APIs is excellent for pushing configuration to a fleet of services. Publish a new config value; all subscribed services receive the update within milliseconds. Combined with subject-level permissions, you can namespace configuration by environment and service. This is genuinely useful for teams that want to avoid the operational overhead of running a separate configuration service.
Service discovery sidecar alternative. In architectures where service mesh overhead is undesirable, NATS request/reply over queue groups provides a lightweight alternative for service-to-service communication. Services advertise their presence by subscribing to a well-known subject. Callers publish requests to that subject. The queue group handles load balancing. No sidecar required.
Operational Realities
JetStream storage on fast NVMe drives makes a significant difference. NATS file storage is synchronous by default for durability. Slow storage causes back-pressure on producers. In Kubernetes, use a StorageClass backed by gp3 or equivalent with at least 3000 IOPS. I have seen deployments grind to a halt because someone provisioned JetStream on gp2 volumes with default IOPS.
Cluster sizing: for most workloads under 50,000 msg/sec sustained, three nodes each with 2 vCPU and 1GB RAM is plenty for Core NATS with JetStream. Push toward 4 vCPU and 2GB once you exceed that. NATS does not need the beefy instances that Kafka brokers typically require.
The nats CLI tool is excellent. nats stream report shows stream health at a glance. nats consumer report shows consumer lag. nats bench runs load tests. Make the CLI part of your runbooks before you need it at 3 AM.
One gotcha with JetStream replication: when you lose a node, the cluster continues serving R3 streams at reduced redundancy. When the node comes back, JetStream syncs the missed messages automatically. This is well-designed. What trips people up is running R3 streams on a two-node cluster during a rolling restart. You briefly drop below quorum and consumers stall. Plan your rolling restart windows accordingly and use --graceful-shutdown to allow in-flight messages to drain.
Where NATS Fits in the Broader Stack
NATS is not trying to replace every component in your data infrastructure. It is not a data lakehouse with Apache Iceberg. It is not a CDC pipeline with Debezium. It is not a distributed SQL database. It is a fast, lightweight, operationally simple messaging layer for services that need to communicate.
The sweet spot: teams running 10 to 200 microservices that need durable messaging without the operational overhead of a full Kafka deployment. SaaS companies with multi-tenant messaging requirements. Edge and IoT platforms with leaf node topologies. Platform engineering teams that want to give developers a messaging primitive without managing separate Kafka clusters per environment.
If you are already running Kafka for data pipeline work, NATS is not a replacement for that. But it is worth evaluating NATS alongside Kafka in the same architecture, with each doing what it does best: NATS handling service communication and lightweight event notification, Kafka handling the high-volume analytics pipeline.
The CNCF graduation in November 2024 signals that NATS has reached production maturity from the industry’s perspective. The client library ecosystem is solid. The server is stable. The JetStream APIs are no longer experimental. This is a good time to take it seriously if you have been watching from the sideline.
Twenty years of messaging systems teaches you that the best one is the one your team can operate confidently at 2 AM when something goes wrong. For most microservice architectures, that is NATS.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.