I need to tell you about the worst week of my career, because it explains why platform engineering exists.
It was 2019, and I was the principal architect for a fintech company that had grown from 15 engineers to 180 in about two years. We had a DevOps team of six people. Six. They were responsible for Terraform modules, Kubernetes clusters across three clouds, a Jenkins instance that had mutated into something unrecognizable, ArgoCD for some teams, Spinnaker for others, and a pile of bash scripts held together by tribal knowledge and good intentions.
One Tuesday morning, a new developer on the payments team needed to spin up a staging environment. She opened a Jira ticket. The ticket sat in a queue for three days because the DevOps team was firefighting an unrelated Kubernetes issue. When someone finally picked it up, they realized the Terraform module she needed had drifted from what was documented in Confluence. The documentation was six months stale. The DevOps engineer spent a full day wrangling the module, then handed the developer a set of instructions that included running 14 commands in a specific order. She got stuck on step 9 and opened another ticket.
That developer waited eight business days to get a staging environment. Eight days. She spent that time reading documentation, attending meetings she didn’t need, and slowly losing the enthusiasm she’d had when she joined the company.
That experience, multiplied across 180 engineers, is what broke us. And it’s what eventually led me to platform engineering.
The DevOps Promise vs. the DevOps Reality
Let me be honest about something that’s uncomfortable for our industry to admit. DevOps, as a cultural movement, was transformative. The ideas behind it (breaking down silos, shared ownership, fast feedback loops) are sound and important. I wrote about many of these principles in my piece on CI/CD pipelines, and I still believe in them.
But somewhere along the way, “you build it, you run it” became “you build it, you also figure out Kubernetes, Terraform, Prometheus, Grafana, ArgoCD, Vault, and seventeen YAML files just to get your app running.” We gave developers freedom and called it empowerment. What we actually gave many of them was a second full-time job they never signed up for.
I’ve talked to hundreds of engineering leaders over the years. The pattern is always the same. They adopted DevOps. They bought the tools. They trained the teams. And then they watched cognitive load climb steadily until their best application developers were spending 40% of their time wrestling with infrastructure instead of solving business problems.
The data backs this up. Puppet’s State of DevOps reports have consistently shown that only about 30% of organizations feel they’ve successfully implemented DevOps at scale. Humanitec’s surveys find that developers spend an average of 30 to 45 minutes per day just waiting for infrastructure-related tasks. That’s not a tooling problem. That’s a structural problem.
What Platform Engineering Actually Is
Platform engineering is the discipline of building and maintaining an internal developer platform (IDP) that gives application developers self-service access to the infrastructure capabilities they need, without requiring them to become infrastructure experts.
Read that again. The key words are “self-service” and “without requiring them to become infrastructure experts.”
A platform team treats internal developers as their customers. They build products for those customers. They gather feedback, iterate on features, and measure success by how productive their developer customers are. This is fundamentally different from a traditional DevOps team that acts as a service desk, fulfilling requests one ticket at a time.
I want to be precise about the relationship between DevOps and platform engineering, because I see people getting confused about this constantly. Platform engineering doesn’t replace DevOps. It operationalizes DevOps. It takes the DevOps principles of automation, fast feedback, and shared ownership, then packages them into something developers can actually use without a PhD in YAML.
Think of it this way: DevOps is the philosophy. Platform engineering is the product management discipline that delivers on that philosophy.
The Architecture of an Internal Developer Platform
Let me get concrete. What does an IDP actually look like under the hood? After building three of these from scratch and consulting on maybe a dozen more, I’ve settled on a layered architecture that works.
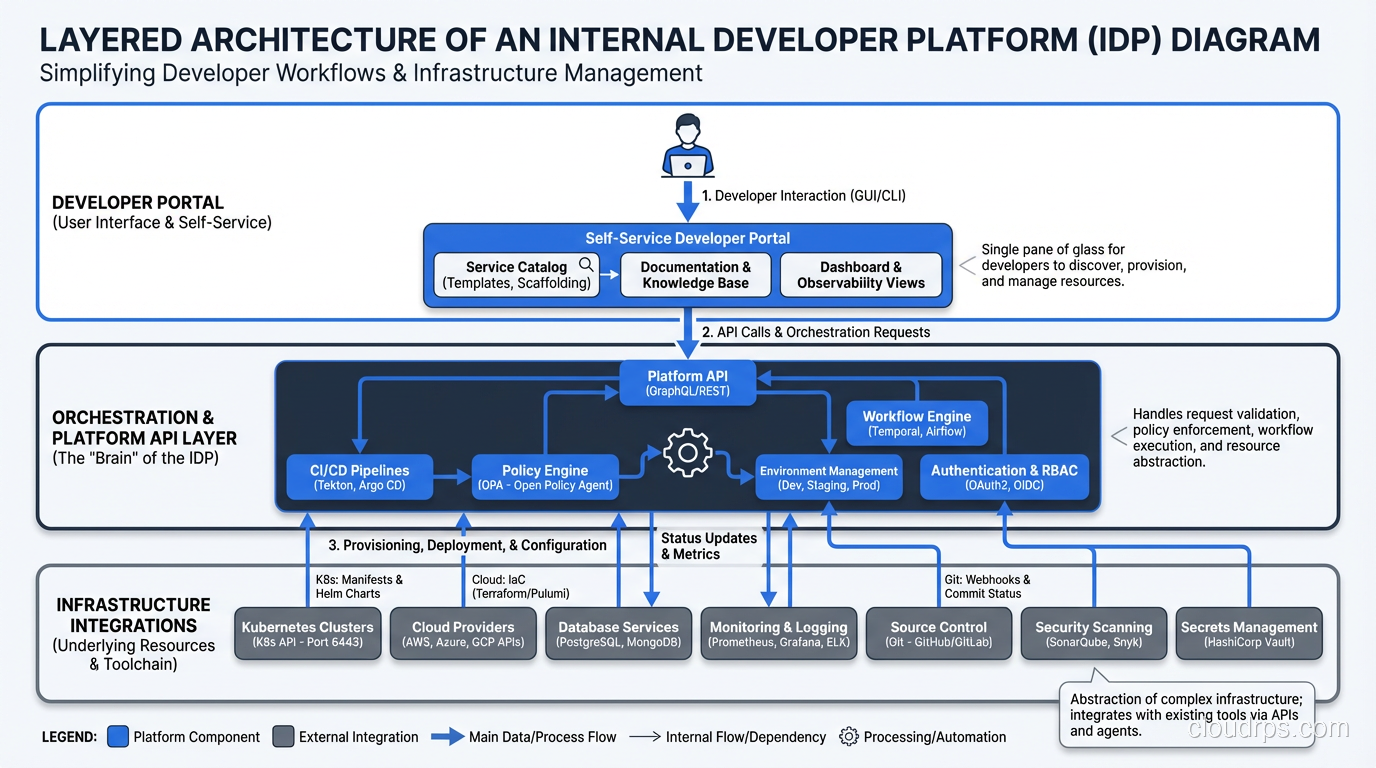
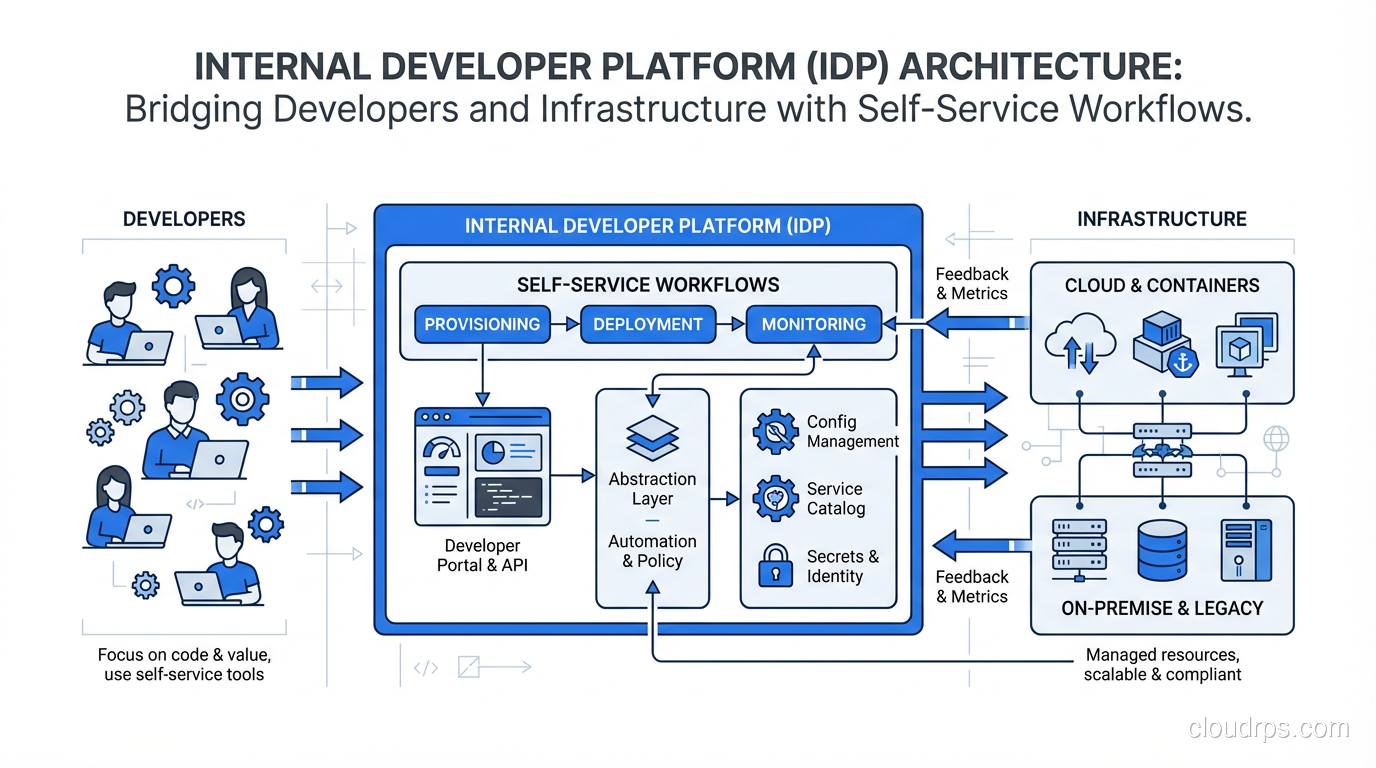
Layer 1: The Developer Portal. This is what developers see and interact with. It’s a web UI (and ideally a CLI as well) where developers can browse a service catalog, create new services from templates, view the health of their running services, check documentation, and trigger workflows like deployments or database provisioning. This is where tools like Backstage, Port, or Cortex live.
Layer 2: The Orchestration and Abstraction Layer. This is the brain of the platform. It takes high-level developer intentions (“I need a PostgreSQL database for my service”) and translates them into the specific infrastructure actions required. It handles environment management, secrets injection, deployment strategies, and resource provisioning. Tools like Crossplane, Humanitec’s Platform Orchestrator, or custom controllers built on Kubernetes operators live here.
Layer 3: The Integration Layer. This connects to your actual infrastructure providers and tools. Your Kubernetes clusters, your cloud provider APIs, your GitOps workflows, your monitoring stack, your CI/CD pipelines. The integration layer is where the messy reality of multi-tool, multi-cloud infrastructure gets abstracted away from the developer.
Layer 4: The Infrastructure. The actual compute, storage, networking, and managed services running underneath everything. The whole point of the layers above is that developers never need to touch this directly.
The critical insight here is that each layer hides complexity from the one above it. A developer clicks “deploy to staging” in the portal. The orchestration layer figures out which Kubernetes cluster, which namespace, which Helm chart version, which secrets, and which monitoring dashboards are needed. The integration layer talks to ArgoCD, Vault, Datadog, and AWS. The developer doesn’t know or care about any of those details.
Backstage and the Developer Portal Landscape
I need to talk about Backstage because it’s become almost synonymous with platform engineering, and that’s both good and bad.
Backstage is an open-source developer portal originally built by Spotify and donated to the CNCF. It provides a service catalog, a software templates system (for scaffolding new projects), a docs-as-code viewer (TechDocs), and a plugin architecture that lets you integrate basically anything. It’s powerful, flexible, and has a massive community.
Here’s my honest take after running Backstage in production for two years: it’s excellent infrastructure for building a developer portal, but it’s not a developer portal out of the box. That distinction matters. Backstage gives you a React-based shell, a plugin system, and some core features. You still need to build and customize plugins, write templates, configure integrations, and maintain the whole thing. Expect to dedicate at least two full-time engineers to a Backstage deployment. If that sounds like a lot, it is. But the alternative (building a developer portal completely from scratch) is worse.
If Backstage feels too heavy, there are commercial alternatives worth evaluating. Port.io and Cortex.io offer managed developer portals with less customization but much faster time to value. Configure.8 and OpsLevel are also solid options. For smaller teams (under 50 engineers), I’d genuinely consider whether you need a portal at all, or whether well-structured templates and good documentation are enough.
The portal is the most visible part of the platform, but don’t make the mistake of thinking the portal IS the platform. I’ve seen teams spend six months building a beautiful Backstage deployment that was essentially a glorified link aggregator because they never invested in the orchestration and abstraction layers underneath.
Golden Paths: The Heart of Platform Engineering
If I had to distill platform engineering into a single concept, it would be golden paths.
A golden path is the recommended, paved, well-lit road for accomplishing a common development task. It’s not a requirement or a mandate. Developers can go off-path if they need to. But the golden path should be so good, so frictionless, so obviously the right choice that 90% of developers pick it voluntarily.
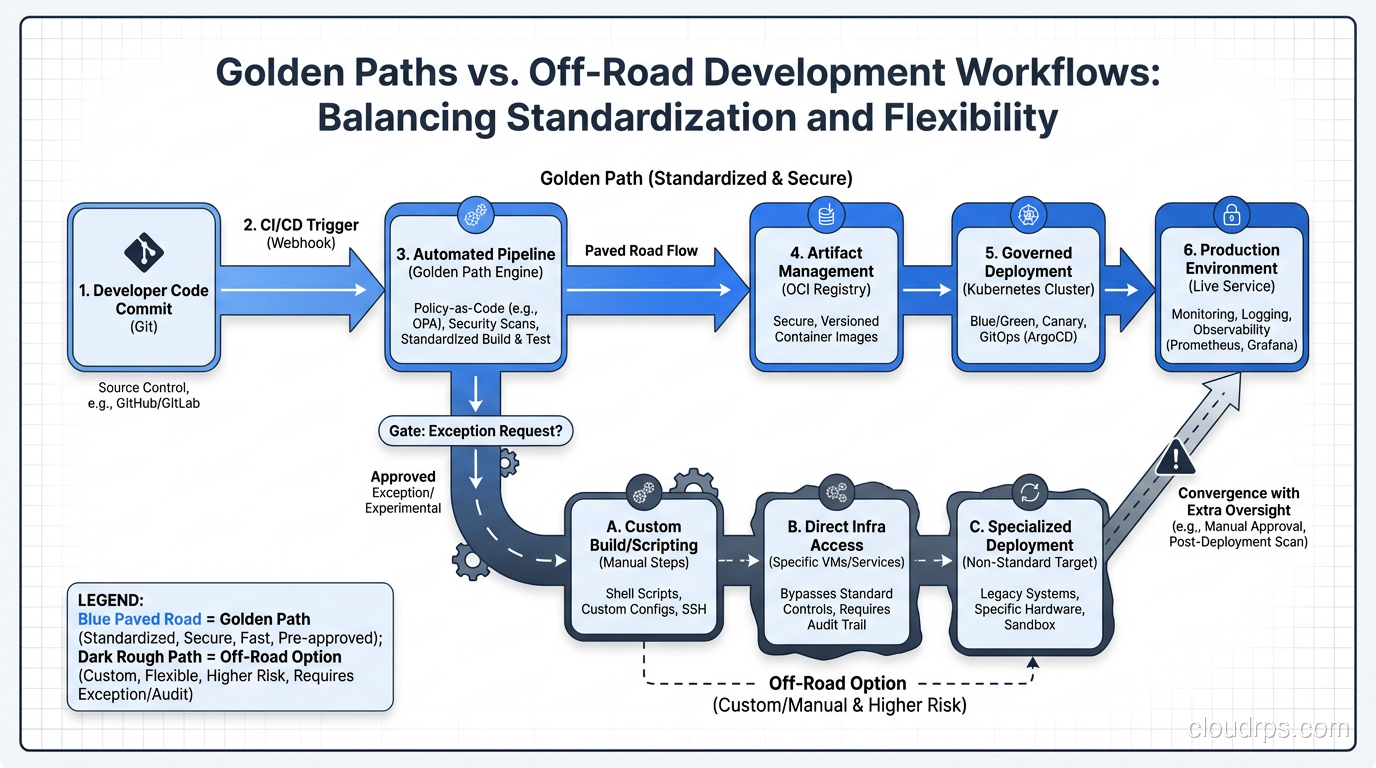
Here are the golden paths I prioritize when building a new platform:
New service creation. A developer should be able to go from zero to a running, monitored, deployed service in under 30 minutes. The template handles repository creation, CI/CD pipeline setup, Kubernetes manifests, monitoring and logging configuration, and basic documentation scaffolding. At the fintech company I mentioned earlier, this used to take three to four weeks and involve six Jira tickets. After we built the golden path, it took 22 minutes.
Database provisioning. “I need a PostgreSQL database” should be a five-minute workflow, not a three-day ticket. The golden path provisions the database, configures backups, sets up monitoring, injects connection secrets into the developer’s service, and adds the database to the service catalog. All behind a simple form or CLI command.
Environment management. Developers need staging, QA, and ephemeral review environments. The golden path lets them create and tear down environments on demand without involving anyone else. This is especially critical for teams practicing trunk-based development, where every pull request ideally gets its own preview environment.
Deployment. This golden path is usually the most mature because most teams already have CI/CD pipelines. The platform team’s job is to make the deployment experience consistent across all services and to add guardrails (automated canary analysis, rollback triggers, deployment freezes during incidents) without adding friction.
Observability. When a developer creates a service through the golden path, it should come pre-wired with metrics, logs, and traces. No configuration required. They should be able to open the developer portal and see dashboards for their service from day one. I’ve written about the infrastructure side of this in my piece on monitoring and logging best practices.
The key principle behind golden paths is that they’re products, not mandates. If developers aren’t choosing your golden path, that’s not a compliance problem. It’s a product-market fit problem. Go talk to your developer customers and figure out why.
Self-Service vs. Tickets: The Cultural Shift
The shift from ticket-based infrastructure to self-service infrastructure is, in my experience, the hardest part of platform engineering. Not technically, but culturally.
Operations teams are used to being gatekeepers. There’s a legitimate reason for that: they’ve been burned by developers who provisioned expensive resources and forgot about them, or who deployed insecure configurations, or who brought down production because they didn’t understand the blast radius of their changes. Gatekeeping was a rational response to real problems.
Platform engineering doesn’t remove the guardrails. It encodes them into the platform. Instead of a human reviewing every database provisioning request, the platform enforces security policies, cost limits, backup requirements, and network isolation automatically. The developer gets their database in five minutes instead of three days, and the operations team gets stronger guarantees than they ever had with manual review.
Here’s a metric I track to measure the shift: the percentage of routine infrastructure requests that are fulfilled without human intervention. When I started at that fintech company, it was 0%. Every single infrastructure request required a ticket and a human. After 18 months of platform engineering work, we got it to 85%. The remaining 15% were genuinely complex or novel requests that warranted human judgment.
The velocity impact was staggering. Our median time from “developer needs something” to “developer has the thing” went from 4.5 days to 12 minutes for the self-service paths. Developer satisfaction scores (yes, we surveyed quarterly) went from 2.1 out of 5 to 4.3 out of 5.
When Should You Invest in Platform Engineering?
Not every organization needs a platform team. I want to be clear about that because I’ve seen small companies hire platform engineers before they had the scale to justify it. Here are the signals I look for:
You probably need platform engineering if:
- You have more than 50 developers and your DevOps/infrastructure team is consistently a bottleneck. If developers are waiting more than a day for routine infrastructure requests, you have a scaling problem.
- You have multiple teams deploying multiple services and the inconsistency between how different teams deploy, monitor, and operate their services is causing real pain. One team uses Helm, another uses Kustomize, a third has custom scripts. This divergence compounds over time.
- Your DevOps team spends more than 60% of their time on reactive work (answering questions, fulfilling tickets, firefighting) instead of proactive work (building automation, improving reliability). Platform engineering is how you flip that ratio.
- You’re seeing patterns in your ticketing system. If the same types of requests come in over and over, those are candidates for self-service automation.
You probably don’t need platform engineering if:
- You have fewer than 20 developers. At that scale, a good DevOps engineer or two and some well-written runbooks will serve you better than a full platform initiative.
- Your infrastructure is genuinely simple. If you’re running a monolith on a single cloud with a straightforward deployment pipeline, don’t add layers of abstraction you don’t need. Not everything needs to be a cloud-native microservices architecture.
- You haven’t solved the basics yet. If you don’t have CI/CD, if you don’t have infrastructure as code, if you don’t have basic monitoring, invest there first. A platform built on shaky foundations will just be a shinier version of chaos.
Platform Maturity: Start Small, Iterate
One of the biggest mistakes I see is teams trying to build the perfect platform before launching anything. They spend a year in stealth mode, building a comprehensive portal with integrations to every tool, and then launch it to developers who have already built their own workarounds and aren’t interested in adopting yet another tool.
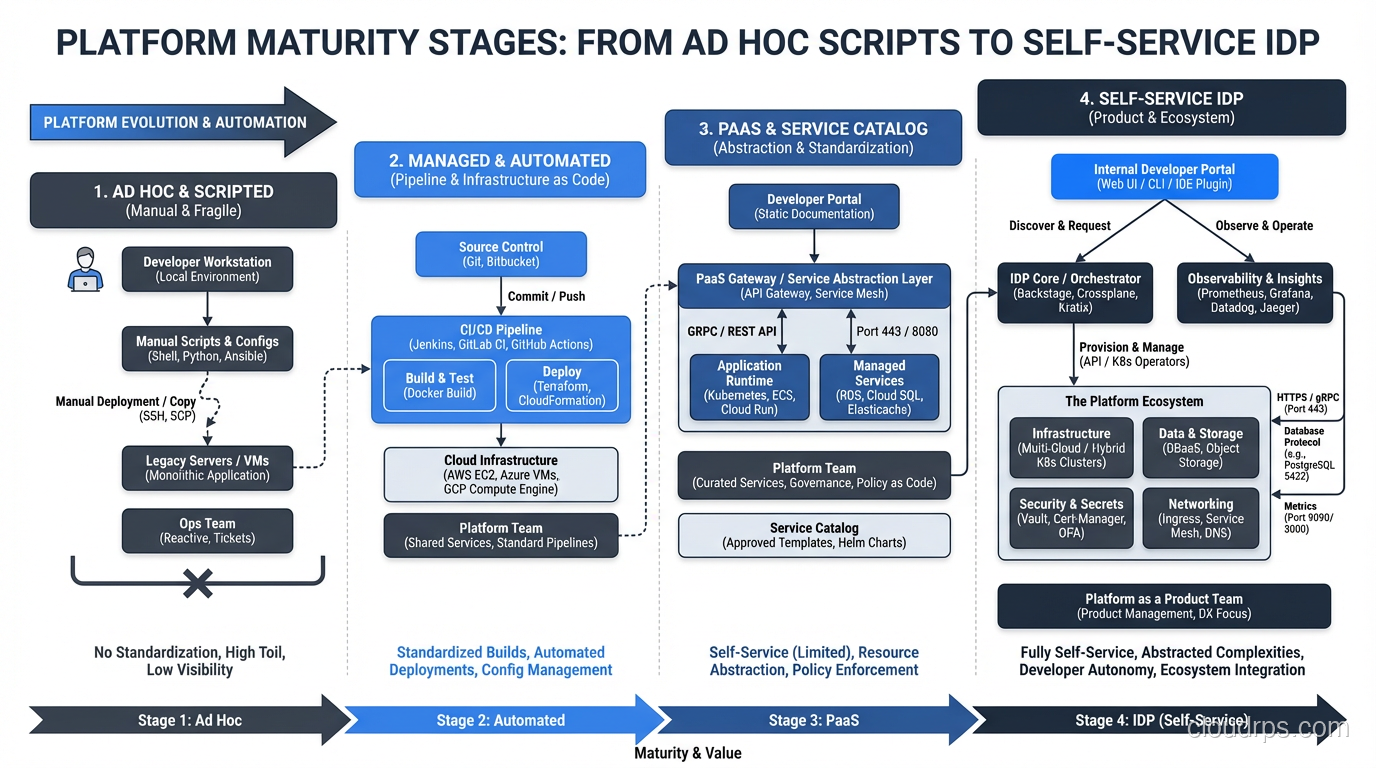
Here’s the maturity model I recommend, based on what I’ve actually seen work:
Stage 1: Standardize and document (month 1 to 3). Pick one golden path. Just one. I usually recommend the “new service creation” path because it’s the most visible and has the highest impact on developer first impressions. Build a template. Write clear documentation. Make it work reliably. Don’t build a portal yet. A well-structured Git repo with a README and a CLI script is fine.
Stage 2: Automate and self-serve (month 3 to 9). Take your most requested infrastructure tickets and turn them into self-service workflows. Database provisioning, environment creation, secret management. Use simple tools: GitHub Actions workflows, Terraform modules with sensible defaults, maybe Crossplane if you’re already running Kubernetes. Start measuring developer satisfaction and cycle time.
Stage 3: Build the portal (month 9 to 18). Now that you have real self-service capabilities, give them a unified interface. This is when Backstage or a commercial portal starts to make sense. Populate the service catalog. Integrate your golden paths into the portal. Build dashboards that show developers the health of their services. This stage is also when you should start building scalable patterns into your platform, because adoption is about to accelerate.
Stage 4: Optimize and expand (month 18 and beyond). Add more golden paths based on developer feedback. Build developer productivity metrics into the platform. Start tackling harder problems like cost visibility, security compliance automation, and multi-region deployments. At this stage, your platform is a real product with a roadmap, a backlog, and users who have opinions.
The timeline above is aggressive but realistic. I’ve seen teams move faster and I’ve seen teams move slower. The important thing is the sequencing: solve real problems first, then build the interface.
The Pitfalls I’ve Watched Teams Fall Into
After years of doing this, I have a catalog of failure modes. Here are the ones that come up most often.
Building for completeness instead of adoption. Your platform doesn’t need to support every possible workflow on day one. It needs to support the three to five most common workflows really, really well. I watched one team build an elaborate multi-cloud abstraction layer that supported AWS, GCP, and Azure equally. The company used AWS for 98% of their workloads. They spent nine months building Azure and GCP support that two teams used.
Treating the platform as a mandate instead of a product. The moment you force developers onto your platform with top-down mandates, you’ve already lost. You’ll get compliance, not adoption. Developers will use your platform grudgingly and find workarounds for the parts they don’t like, which means you won’t get the feedback you need to improve. Treat your platform like a startup: if developers aren’t choosing it, figure out why and fix it.
Ignoring the developer experience. I’ve seen platforms that were technically brilliant but had terrible UX. Confusing naming, poor error messages, documentation that assumed deep infrastructure knowledge, slow feedback loops. Platform engineering is, at its core, a developer experience discipline. If you wouldn’t hire a product manager and a UX designer for an external product, fine. But someone on the platform team needs to think like one.
Understaffing the platform team. A serious platform initiative needs at least three to four dedicated engineers. I’ve seen companies try to do it with one person as a side project, and it always stalls. That one person ends up doing maintenance on existing infrastructure and never has time to build platform capabilities. If you can’t dedicate at least three engineers, you’re probably not at the scale where you need a platform team. Go back to the “when to invest” section above.
Abstracting too much. This one is subtle but deadly. You want to hide unnecessary complexity from developers, but you don’t want to hide information they actually need. If a deployment fails, the developer needs to understand why. If their service is slow, they need access to real metrics, not a dumbed-down dashboard. The platform should simplify the happy path while still providing escape hatches to the underlying infrastructure when needed.
Forgetting about day two operations. Golden paths for creating services are table stakes. What about golden paths for debugging a service at 3 AM? For doing a database migration? For decommissioning a service that’s no longer needed? Day two operations are less glamorous than day one, but they’re where developers spend most of their time.
Where This Is All Heading
Platform engineering is not a fad. The fundamental problem it solves (cognitive overload from tool and infrastructure sprawl) is only getting worse as cloud ecosystems grow more complex. Every year, the CNCF landscape adds more projects. Every year, the number of things a developer “should” know about infrastructure grows.
I’m seeing some interesting trends in how platforms are evolving. The rise of serverless and function-as-a-service is influencing platform design, with some teams building platforms that let developers deploy without even thinking about containers. AI-assisted development is creating new demands for platform teams, as developers need GPU provisioning, model serving infrastructure, and experiment tracking capabilities baked into their golden paths. And the “platform as a product” mindset is pushing teams toward better analytics, A/B testing of platform features, and formal user research with their developer customers.
The most mature platform teams I work with today have something in common: they measure themselves not by the technical sophistication of their platform, but by the productivity of the developers who use it. Lines of infrastructure code don’t matter. What matters is how fast a new developer can ship their first feature, how long a senior developer spends on infrastructure tasks versus product work, and how often teams choose the golden path without being forced.
Getting Started: My Practical Advice
If you’ve read this far and you’re thinking “this sounds like what my organization needs,” here’s what I’d do tomorrow.
First, measure the pain. Track how long routine infrastructure requests take. Survey your developers about their biggest friction points. Look at your ticketing system and count the repeating request types. You need data to justify the investment and to prioritize what to build first.
Second, start with one golden path. Don’t try to boil the ocean. Pick the workflow that will have the most visible impact and build it well. Ship it to a pilot team, get feedback, iterate.
Third, hire (or appoint) someone who thinks like a product manager. Platform engineering fails when it’s treated as a pure infrastructure project. You need someone who talks to developers, prioritizes ruthlessly, and cares about the experience of using the platform, not just whether it works technically.
Fourth, set expectations with leadership. Platform engineering is a long-term investment. You won’t see dramatic results in the first quarter. But if you do it right, by the end of the first year, you’ll wonder how your organization ever functioned without it.
The developer who waited eight days for a staging environment? She eventually became one of the biggest advocates for our platform engineering initiative. Once she could spin up environments in minutes instead of days, she started shipping features at a pace that made her one of the most productive engineers on the team. That’s the promise of platform engineering, and after doing this work for years, I can tell you: the promise is real.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.