I keep a mental list of the questions I get asked most often during architecture reviews. Near the top: “our pandas pipeline is slow and running out of memory on medium-sized datasets, what should we do?” Twenty years ago, that question had one answer for in-process Python data work. Today it has a better answer: Apache Polars.
Polars is a DataFrame library written in Rust, built on Apache Arrow’s columnar memory format, with a lazy evaluation engine that optimizes queries before executing them. It is not pandas with a faster backend. It is a fundamentally different design philosophy. Moving to Polars for the right workloads cuts pipeline runtime by 5 to 15x and often reduces memory consumption by 60 to 80 percent in practice. Those are not benchmark numbers from a controlled microbenchmark. Those are numbers I have personally measured in real pipelines moving real data at production scale.
This guide covers what makes Polars architecturally different, where it belongs in the modern data stack, and how to actually use it in production without the gotchas that trip up teams migrating from pandas.
Why Pandas Became the Problem
Pandas has been the lingua franca of Python data work since it was open-sourced in 2009. I have written more pandas code than I can count, and for most of the past fifteen years it was the right tool. But pandas carries architectural decisions made when working sets were smaller, machines had fewer cores, and the GIL was a less visible bottleneck.
The core issue is pandas’ memory model. Internally, pandas stores data in NumPy arrays. Every operation that returns a new DataFrame copies data by default. Operations are fundamentally single-threaded because the GIL (Global Interpreter Lock) prevents Python from using multiple cores for compute-heavy tasks. The null handling conflates NaN (a floating-point sentinel value) with missing values, leading to type promotion bugs that surface in production at the worst possible moments.
Pandas 2.0 added an Apache Arrow backend option, which helps significantly. But you have to opt into it per-column, and much of the pandas API still triggers copies even with the Arrow backend active. The fundamental design is eager (every operation executes immediately), and it cannot parallelize across cores the way a native Rust implementation can.
When your data engineering pipelines start handling datasets in the hundreds of gigabytes, or when your team’s compute costs for transformation jobs become a real line item, pandas starts showing its age. I have watched teams spin up r5.24xlarge instances with 768GB of RAM just to give a pandas groupby enough headroom. That is not a scaling strategy.
What Polars Actually Is
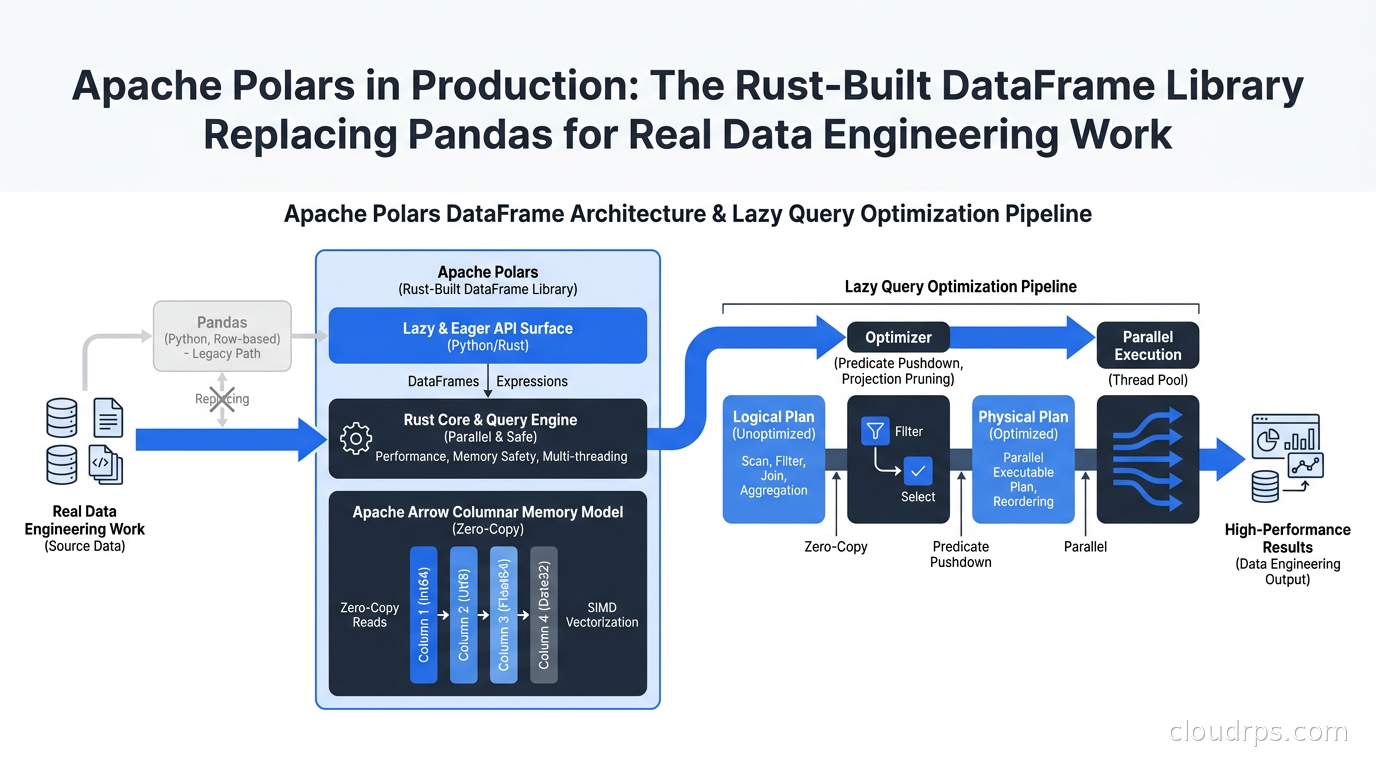
Polars is a DataFrame library whose core is written in Rust, with Python and JavaScript bindings. The Rust core means zero GIL limitations, true multi-core parallelism, and predictable memory safety without garbage collection pauses.
The memory model is Apache Arrow all the way down. Arrow is a columnar in-memory format designed specifically for efficient analytical operations: groupbys, filters, aggregations, joins. Columnar storage means you only read the columns you need from memory, SIMD (Single Instruction Multiple Data) CPU instructions can process multiple column values simultaneously, and sharing data between Polars and other Arrow-native tools like DuckDB happens with zero copying. No serialization. No deserialization. Just a pointer to the same memory.
The third pillar is lazy evaluation. When you call .lazy() on a Polars DataFrame, you get a LazyFrame. Operations on a LazyFrame do not execute immediately. They build a query plan. When you call .collect(), Polars optimizes the entire plan before executing: predicate pushdown, projection pushdown, common subexpression elimination. This is the same concept underlying Apache Spark’s DAG execution model that made Spark dramatically more efficient than vanilla Hadoop MapReduce, brought to single-machine Python data engineering.
The combination of these three things produces performance that genuinely surprises engineers who have spent years working only in pandas.
The Expression API: Where Polars Thinking Differs
The biggest mental shift coming from pandas is not performance. It is the expression API.
In pandas, transformations are imperative and execute immediately:
df['revenue_per_user'] = df['revenue'] / df['active_users']
df['category'] = df['category'].str.upper()
df = df.groupby('region').agg({'revenue_per_user': 'mean'})
Each line executes and potentially copies data. The intermediate states live in memory.
In Polars, you think in expressions that describe transformations:
import polars as pl
result = (
df.lazy()
.with_columns([
(pl.col('revenue') / pl.col('active_users')).alias('revenue_per_user'),
pl.col('category').str.to_uppercase()
])
.group_by('region')
.agg(pl.col('revenue_per_user').mean())
.collect()
)
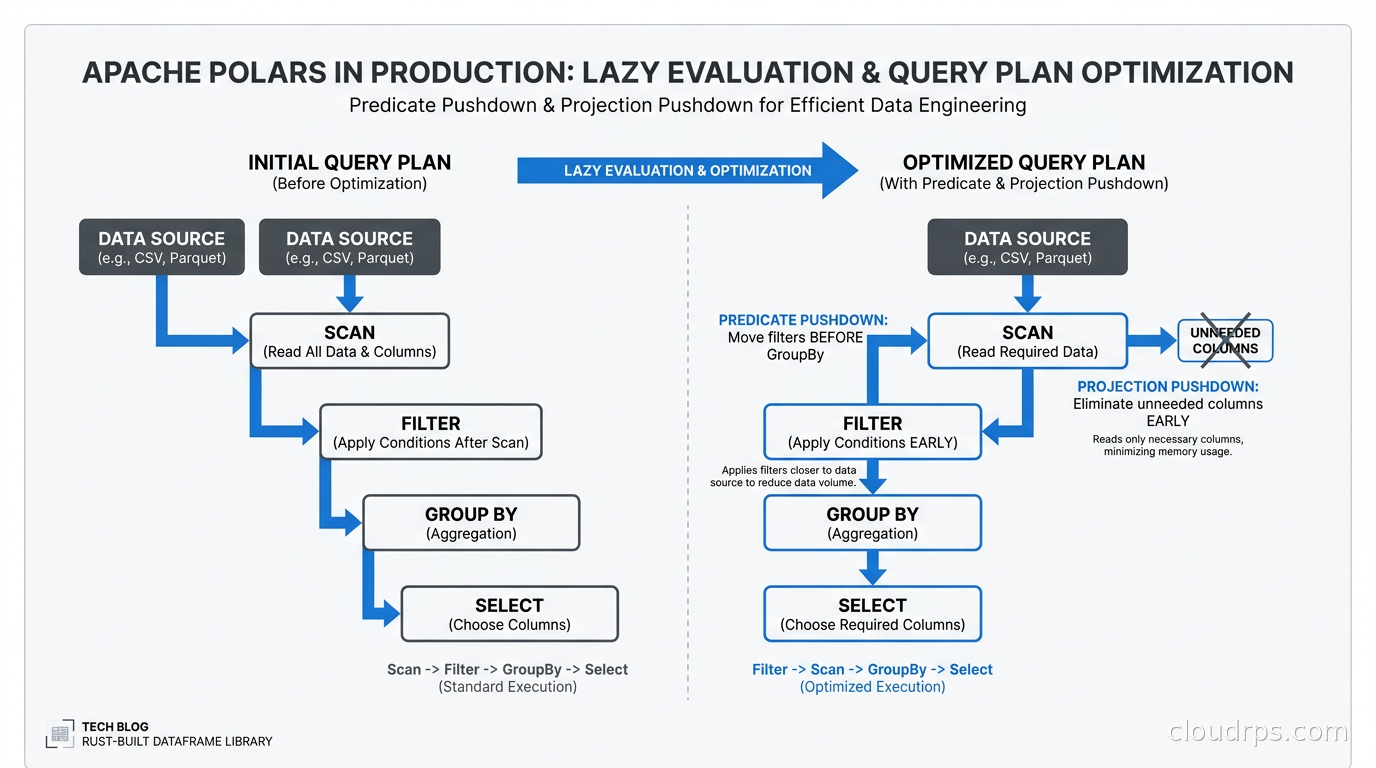
This entire chain is one query plan that Polars optimizes before touching a single row. The optimizer can reorder operations, push filters down to happen before groupby (so you process less data), and parallelize across cores automatically.
The critical production rule: do not break out of the expression API with Python lambdas unless you have no other option. pl.col('x').map_elements(lambda x: some_python_function(x)) works but kills performance because it serializes back to single-threaded Python. If you find yourself reaching for a lambda, look for the native Polars expression equivalent. They exist for the vast majority of real-world use cases.
Real Performance Numbers
I want to give you concrete numbers because benchmarks are often deceptive in blog posts. Here is what I have measured on production workloads.
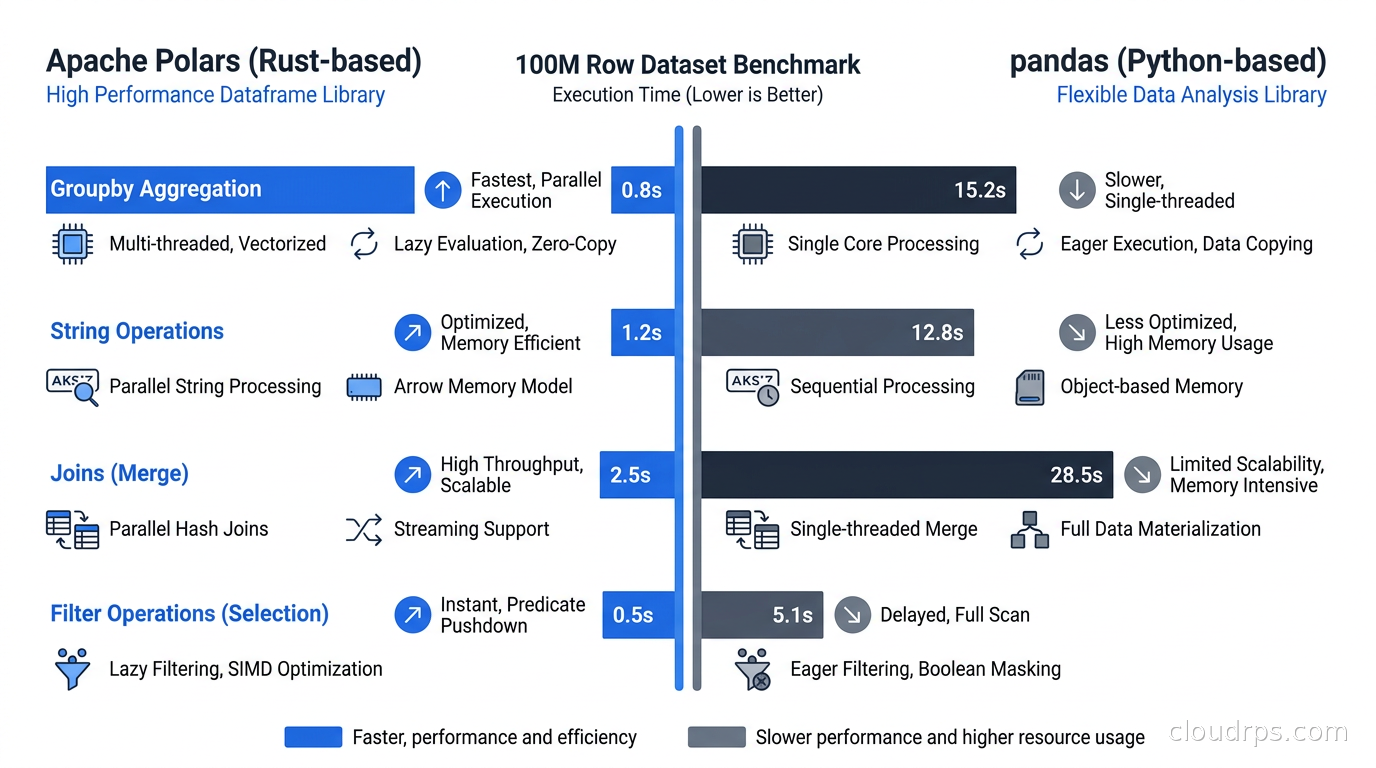
Groupby aggregations: This is where Polars shines most. A groupby aggregation on 100 million rows that takes 45 seconds in pandas takes 3 to 6 seconds in Polars on the same hardware. The driver is that Polars parallelizes the hash-building and reduction phases across all CPU cores.
String operations (str.upper(), str.contains(), str.replace()): Polars runs 8 to 15x faster than pandas because it processes strings in parallel with SIMD instructions and avoids Python object overhead entirely.
Joins on large tables: On joins across tables with tens of millions of rows, Polars is typically 5 to 10x faster because it uses a parallel hash join algorithm and benefits from the Arrow memory layout for cache efficiency.
Simple column arithmetic: The gap narrows here. For a straightforward df['a'] + df['b'], Polars is still faster but the ratio might be 2 to 3x rather than 10x. Pandas 2.0 with ArrowDtype is competitive on simple arithmetic.
Where pandas is still fine: Small datasets under 10MB where performance simply does not matter, operations that require row-level Python logic with no Polars equivalent, and integration with scikit-learn pipelines where pandas DataFrames are the expected input type. The tool should match the workload.
Streaming Mode for Datasets That Exceed Memory
One of the most underappreciated features of Polars is streaming mode. When you call .collect(streaming=True) on a LazyFrame, Polars processes the data in chunks rather than loading the entire dataset into memory at once.
This is enormously useful for ETL pipelines handling files larger than available RAM. A 300GB CSV file that would crash a pandas pipeline can be processed by a streaming Polars pipeline on a machine with 64GB of RAM. You write the same expression API code. You add streaming=True to the collect call.
result = (
pl.scan_csv('/data/large_events.csv')
.filter(pl.col('status') == 'active')
.group_by('region')
.agg(pl.col('value').sum())
.collect(streaming=True)
)
Note scan_csv instead of read_csv. The scan_* family of functions creates lazy scans that read data only when needed. Combined with streaming, Polars reads chunks of the file, applies the filter before aggregation (pushing less data forward through the pipeline), aggregates incrementally, and flushes intermediate results without ever holding the entire dataset in memory.
This is where Polars competes directly with Apache Spark for medium-scale data. If your dataset fits on one machine’s disk even if not in its RAM, Polars streaming will typically outperform a Spark cluster on that workload because there is no serialization overhead, no shuffle cost across nodes, and no cluster coordination latency. The rule of thumb I use: if your data fits on the largest available cloud instance, Polars can handle it. Beyond that, distributed systems are the appropriate answer.
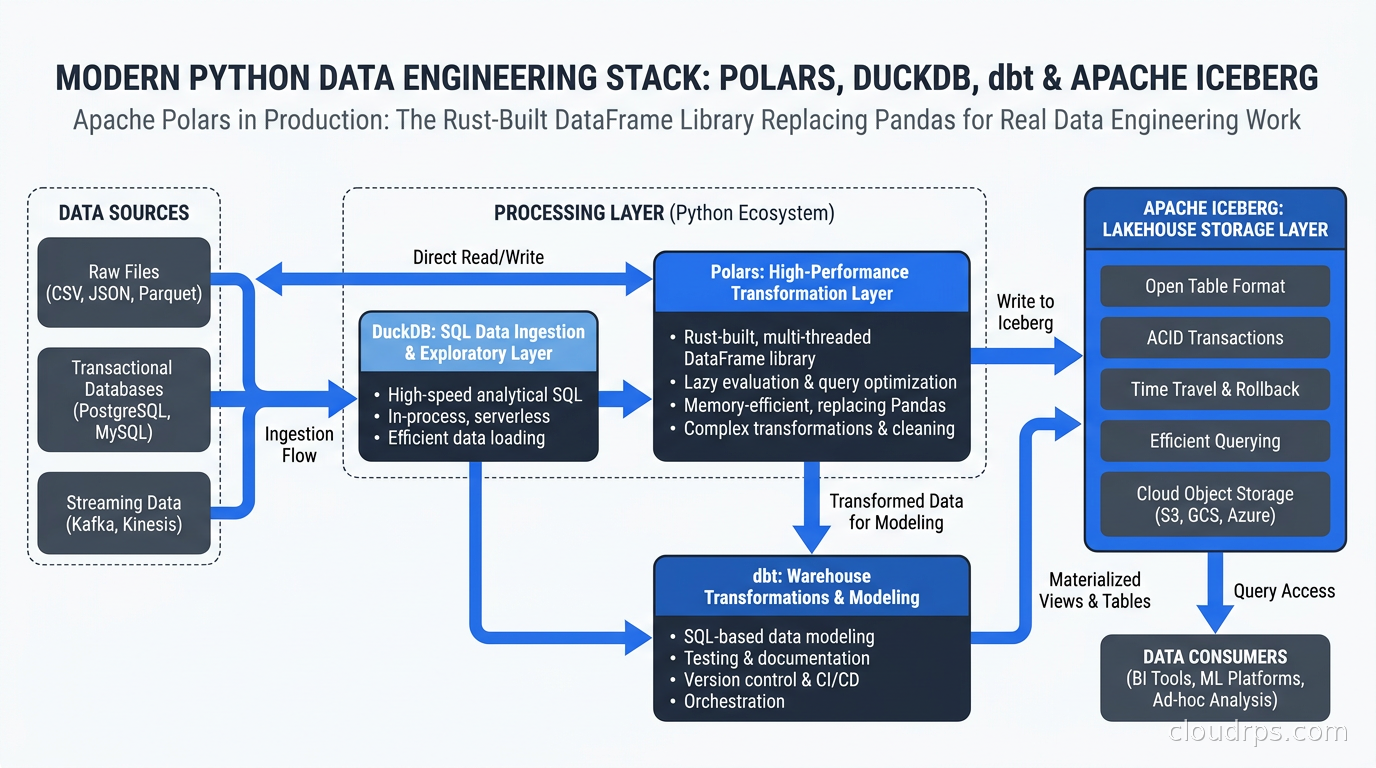
Polars and DuckDB: The Modern Stack Pairing
The pairing of Polars and DuckDB is becoming a signature pattern in modern data engineering. Both tools are built on Apache Arrow, which means data transfers between them are zero-copy: no serialization, no deserialization, just a pointer exchange to the same Arrow buffers.
The practical division of labor: use DuckDB for complex SQL analytics and ad-hoc querying, use Polars for Python-centric transformation and feature engineering that benefits from the expression API. They are not competing tools. They are complementary layers of the same stack.
import duckdb
import polars as pl
# Read Parquet files from S3 with DuckDB SQL (handles complex SQL naturally)
raw = duckdb.sql("""
SELECT customer_id, region, SUM(revenue) as total_revenue
FROM read_parquet('s3://my-bucket/events/*.parquet')
WHERE event_date >= '2025-01-01'
GROUP BY customer_id, region
""").pl() # Returns a Polars DataFrame via Arrow, zero copy
# Apply Python-centric transformations with Polars expressions
result = (
raw.lazy()
.with_columns([
pl.col('total_revenue').log1p().alias('log_revenue'),
pl.col('region').str.to_uppercase(),
(pl.col('total_revenue') / pl.col('total_revenue').sum()).alias('revenue_share')
])
.filter(pl.col('total_revenue') > 100)
.collect()
)
The .pl() method on a DuckDB relation returns a Polars DataFrame via Arrow with no data copy. This handshake is genuinely seamless at the memory level.
For teams whose data lives in Apache Iceberg lakehouse tables, Polars can scan Iceberg tables directly via the polars-io-iceberg extension. This means your entire pipeline from lakehouse read to transformed output can stay in Polars-adjacent tooling without spinning up a Spark cluster for what is fundamentally a single-machine workload. I have migrated clients off Databricks jobs that cost thousands of dollars a month onto Polars-based pipelines running on a single EC2 r6i.4xlarge. Same output, a fraction of the infrastructure cost.
Polars for ML Feature Engineering
One of the areas where I push teams hardest to adopt Polars is ML feature engineering. Feature engineering pipelines typically involve reading large entity datasets, computing dozens of aggregated features per entity (lag features, rolling windows, grouped statistics), joining back to the base entity table, and writing out the feature matrix.
This is precisely the workload Polars is optimized for. The window function API is particularly strong:
features = (
events.lazy()
.sort(['customer_id', 'event_time'])
.with_columns([
pl.col('value')
.rolling_mean(window_size=7)
.over('customer_id')
.alias('7d_rolling_avg'),
pl.col('value')
.rolling_sum(window_size=30)
.over('customer_id')
.alias('30d_rolling_sum'),
pl.col('value')
.shift(1)
.over('customer_id')
.alias('prev_value'),
pl.col('value')
.rank(method='dense')
.over(['customer_id', 'region'])
.alias('value_rank_in_region'),
])
.collect()
)
In pandas, each .rolling() operation runs sequentially. In Polars, all four window operations run in parallel across cores. On a 50 million row feature engineering pipeline, that difference is measured in minutes versus seconds.
The output of Polars feature engineering integrates naturally with MLOps pipelines. Convert to pandas or Arrow at the boundary where your ML framework expects it. Most modern frameworks including XGBoost, LightGBM, and PyTorch can accept Arrow tables directly, which means a zero-copy handoff from your Polars feature matrix to the training loop.
When using Airflow, Dagster, or Prefect to orchestrate these pipelines, the Polars-based tasks slot in naturally as Python operator or @task functions. The key sizing consideration: Polars holds the full working set for a given task in memory, unlike Spark which partitions data across executor JVM heaps. Size your task resources accordingly. A 200 million row feature engineering job might need 32GB RAM on a Polars task where the equivalent Spark job could run with smaller per-executor allocations.
Migrating from Pandas: What Actually Changes
The Polars API is inspired by pandas but deliberately not compatible. The places where the APIs diverge are precisely the places where pandas has footguns.
No row index: Polars DataFrames do not have a row index. In pandas, every DataFrame has an index used for alignment. In Polars, alignment is always explicit via joins on named columns. This forces cleaner code that is explicit about join keys and prevents the silent alignment bugs that bite pandas users constantly.
Strict type enforcement: Polars will not silently coerce types. If you try to add an integer column to a float column without an explicit cast, Polars raises an error at plan validation time rather than at runtime after processing half your data. This surfaces bugs during development where they belong.
Null vs NaN: Polars uses Arrow null for missing values and treats NaN as a proper floating-point value. pl.col('x').is_null() finds missing values. pl.col('x').is_nan() finds NaN floats. In pandas, pd.isna() catches both and conflates them. The Polars distinction is architecturally correct and prevents subtle aggregation bugs.
Immutability: Polars DataFrames are immutable. There is no df.loc[0, 'col'] = value. You build new DataFrames with transformed columns. This takes adjustment but produces pipeline code that is cleaner to reason about and debug.
Migration strategy that works in practice: start with new components rather than rewriting existing pandas code. Identify the bottleneck stage in your pipeline, typically the groupby-heavy or join-heavy transformation, and rewrite that component in Polars. Measure the improvement. Add .to_pandas() and .from_pandas() calls at the interfaces with existing code. As you see the gains, expand coverage organically. A better path for performance-sensitive boundaries: use Arrow as the interchange format via polars_df.to_arrow() and pl.from_arrow(arrow_table), which avoids the copy that to_pandas() introduces.
The Ecosystem in 2026
Polars is backed by Polars Inc., which funds core development and provides enterprise support. This matters for production adoption decisions: the project has a sustainable business model, not just open-source volunteer bandwidth.
Object storage integration: The polars-io crate supports reading from S3, GCS, and Azure Blob via the Rust object_store library. You can read Parquet files directly from object storage using pl.scan_parquet('s3://bucket/path/*.parquet') with credentials handled via environment variables or instance IAM roles. No JVM. No Hadoop configuration files.
Delta Lake: The deltalake Python library (built on delta-rs, also Rust) integrates directly with Polars. DeltaTable('/path/to/table').to_polars() returns a Polars DataFrame. Polars can participate in Delta Lake pipelines without Spark.
Database connectors: The connectorx library provides fast database reads into Polars DataFrames, bypassing Python’s DBAPI overhead by reading in Rust and delivering via Arrow.
Version stability: Polars reached 1.0 in 2024 and API stability has improved significantly. That said, pin your dependency version. The pre-1.0 API changed frequently enough that minor version bumps broke production pipelines for teams that followed semver too casually.
Where Polars Does Not Belong
An honest assessment is more useful than a sales pitch.
Deep scikit-learn pipelines: If your code is heavily integrated with scikit-learn Pipeline, ColumnTransformer, and preprocessing steps, those expect pandas DataFrames or NumPy arrays. Converting at the boundary works, but if 80 percent of your code is scikit-learn transformers anyway, the API friction may not justify the migration.
True distributed workloads at terabyte scale: Polars is single-machine. If your dataset is 5TB and you need distributed compute across a cluster, Spark or cloud-native analytics engines remain the correct answer. Polars streaming handles datasets larger than RAM on a single machine, but it cannot spread computation across nodes. The breakpoint in practice: if your data fits comfortably on the largest cloud instance class, Polars can handle it. Beyond that, distributed systems are the right tool.
SQL-first transformations in your data warehouse: dbt operates inside your data warehouse using SQL. Polars runs in Python processes on extracted data. They serve different layers of the stack and are not in competition. For SQL-defined transformations inside a warehouse, dbt wins. For Python-defined transformations on data that has been extracted from the warehouse, Polars wins. Know where your architectural boundary sits.
Libraries that assume pandas internals: Some libraries access df._data or rely on pandas’ specific null representation in ways that break even after .to_pandas() conversion. These are edge cases, but they exist. Check your specific library dependencies before committing to a migration in those areas.
What Twenty Years of Data Engineering Teaches You
I have watched the Python data ecosystem go through significant transitions over my career: CSV to HDF5, HDF5 to Parquet, Spark replacing MapReduce, Arrow replacing text serialization as the in-memory exchange format. Each transition had a period of resistance followed by a tipping point where the new approach became the default for new work.
Polars is at that tipping point right now. The production adoption list in 2026 includes serious names in financial services, e-commerce, and media. The performance gap is real and measurable on production workloads, not just benchmarks. The ecosystem is mature enough for serious production use.
What I tell my teams: do not rewrite every pandas script. Do not make Polars adoption a departmental crusade with a migration deadline. Start with the pipelines where performance actually matters, the jobs you can measure, the ones showing up on your cloud bill. Build the muscle memory with the expression API. When a new greenfield pipeline comes up, default to Polars.
The broader ecosystem is moving toward Apache Arrow as the common in-memory format for the entire Python data stack. DuckDB uses Arrow. PyArrow is Arrow. Polars is Arrow. The polars-io-iceberg reading Iceberg metadata and data files via Arrow is Arrow. Polars is the most principled and performant DataFrame implementation of that vision. That trajectory does not reverse.
The Short Version
Apache Polars brings three things that matter for production data engineering: a Rust core that parallelizes automatically across all CPU cores, Apache Arrow as the native memory format for both analytical efficiency and zero-copy tool integration, and lazy evaluation that optimizes entire query plans before executing them.
On groupby-heavy, join-heavy, and string-heavy workloads, the performance difference versus pandas is not marginal. It is the kind of difference that lets you downsize your compute infrastructure or process 10x more data in the same time window. The streaming mode handles datasets larger than RAM without changing your API. The DuckDB pairing handles SQL complexity that the expression API cannot match.
The places it belongs: ETL and feature engineering pipelines on single machines with datasets from gigabytes to low terabytes, anywhere your pandas pipeline is becoming a resource problem, and greenfield data engineering work where you want to avoid inheriting pandas’ architectural debt. The places it does not belong: deep scikit-learn pipelines, truly distributed multi-terabyte workloads that require cluster-level parallelism, and SQL transformation layers where dbt is the right architectural choice.
Learn the expression API now. The migration pressure will arrive regardless.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.