I’ve been configuring routing protocols since the early ’90s, back when RIP was the default and network engineers debated whether OSPF was “ready for production.” Three decades later, the routing protocol landscape has matured dramatically, but I still see people making the same mistakes: running BGP where OSPF would suffice, using static routes where dynamic routing would save them at 3 AM, or deploying RIP because it was in the textbook they read.
Let me walk you through each major routing protocol, when to use it, and when to avoid it, all based on years of actual deployment experience, not just RFC reading.
Routing Basics: What Routing Protocols Actually Do
Before we compare protocols, let’s establish what a routing protocol is doing. Every router needs a forwarding table, essentially a mapping of “if a packet is destined for network X, send it out interface Y to next-hop Z.” You could build this table manually with static routes, but that doesn’t scale and it can’t adapt to failures.
Dynamic routing protocols solve this by having routers automatically:
- Discover neighbors: find other routers they’re directly connected to
- Exchange routing information: share what networks they know about
- Calculate best paths: use algorithms to determine the optimal route to each destination
- Adapt to changes: detect failures and recalculate paths
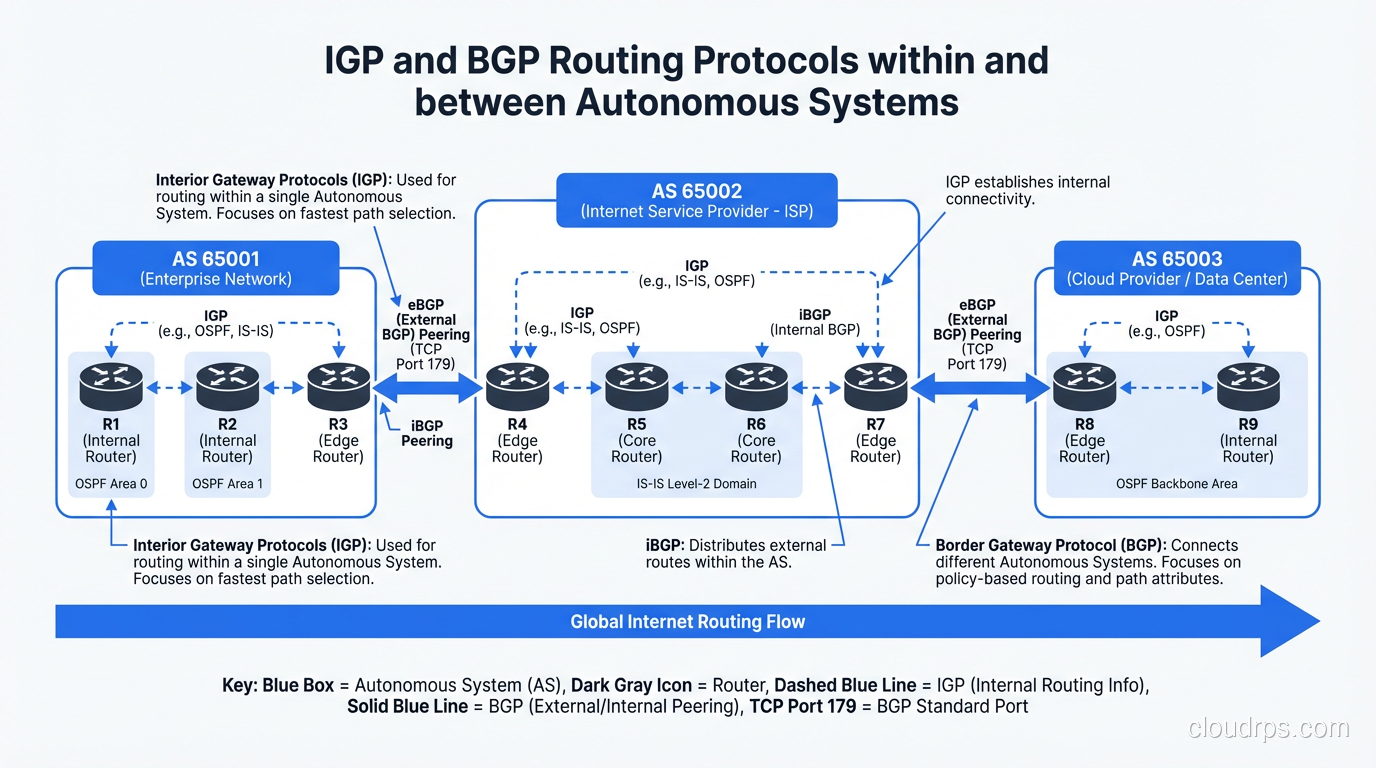
Routing protocols fall into two broad categories based on where they operate:
| Type | Scope | Examples |
|---|---|---|
| IGP (Interior Gateway Protocol) | Within an organization/AS | OSPF, EIGRP, RIP, IS-IS |
| EGP (Exterior Gateway Protocol) | Between organizations/ASes | BGP |
Think of IGPs as the routing within your house (getting from room to room) and EGP (BGP) as the routing between houses on your street (getting from one property to another). The scale, trust model, and design considerations are completely different.
RIP: The Protocol That Refuses to Die
Routing Information Protocol (RIP) is the oldest dynamic routing protocol still in any kind of use. It’s a distance-vector protocol that uses hop count as its metric. The “best” route is the one with the fewest hops, with a maximum of 15 (16 = unreachable).
How RIP Works
RIP routers periodically broadcast their entire routing table to their neighbors (every 30 seconds by default). Each neighbor takes that table, increments the hop count by 1, and merges it with its own table. This is the classic Bellman-Ford algorithm.
Router A knows: 10.1.0.0/16 via directly connected (hop count 0)
Router A tells Router B: "I can reach 10.1.0.0/16, hop count 1"
Router B tells Router C: "I can reach 10.1.0.0/16, hop count 2"
...and so on
RIP Versions
| Feature | RIPv1 | RIPv2 | RIPng |
|---|---|---|---|
| Classful/Classless | Classful only | Classless (VLSM) | Classless |
| Updates | Broadcast | Multicast (224.0.0.9) | Multicast (FF02::9) |
| Authentication | None | MD5/plaintext | IPsec |
| IP Version | IPv4 | IPv4 | IPv6 |
When to Use RIP
Almost never. I’m not being flippant. RIP’s limitations are severe:
- 15-hop limit rules it out for anything beyond a small network
- Slow convergence: it can take minutes to converge after a topology change (count-to-infinity problem)
- Bandwidth waste: sending full routing tables every 30 seconds is absurd by modern standards
- Hop count is a terrible metric: a 3-hop path through gigabit links is “worse” than a 2-hop path through saturated 10 Mbps links
The only legitimate use case I’ve seen in the last decade is in very small, simple networks where the admin doesn’t know OSPF and the network has fewer than 10 routers. Even then, I’d argue the hour it takes to learn OSPF basics is a better investment.
RIPv2 is also still used as a redistribution target in some legacy environments where old equipment doesn’t support anything else.
OSPF: The Workhorse of Enterprise Routing
Open Shortest Path First (OSPF) is a link-state protocol and the IGP I recommend for 90% of enterprise networks. It’s open-standard (no vendor lock-in), well-understood, widely supported, and scales well with proper design.
How OSPF Works
Unlike RIP’s “tell everyone your routing table” approach, OSPF routers exchange Link-State Advertisements (LSAs) that describe the state of their directly connected links. Every router in an OSPF area builds an identical Link-State Database (LSDB), a complete map of the network topology. Each router then independently runs Dijkstra’s Shortest Path First (SPF) algorithm on this database to calculate the best path to every destination.
This is fundamentally different from distance-vector protocols:
| Aspect | Distance-Vector (RIP) | Link-State (OSPF) |
|---|---|---|
| Knowledge | Only knows next hop and metric | Full topology map |
| Updates | Periodic full table dumps | Event-driven, incremental LSA floods |
| Convergence | Slow (minutes) | Fast (sub-second with tuning) |
| Loop prevention | Split horizon, poison reverse | SPF algorithm inherently loop-free |
| CPU/Memory | Low | Higher (full LSDB + SPF calculation) |
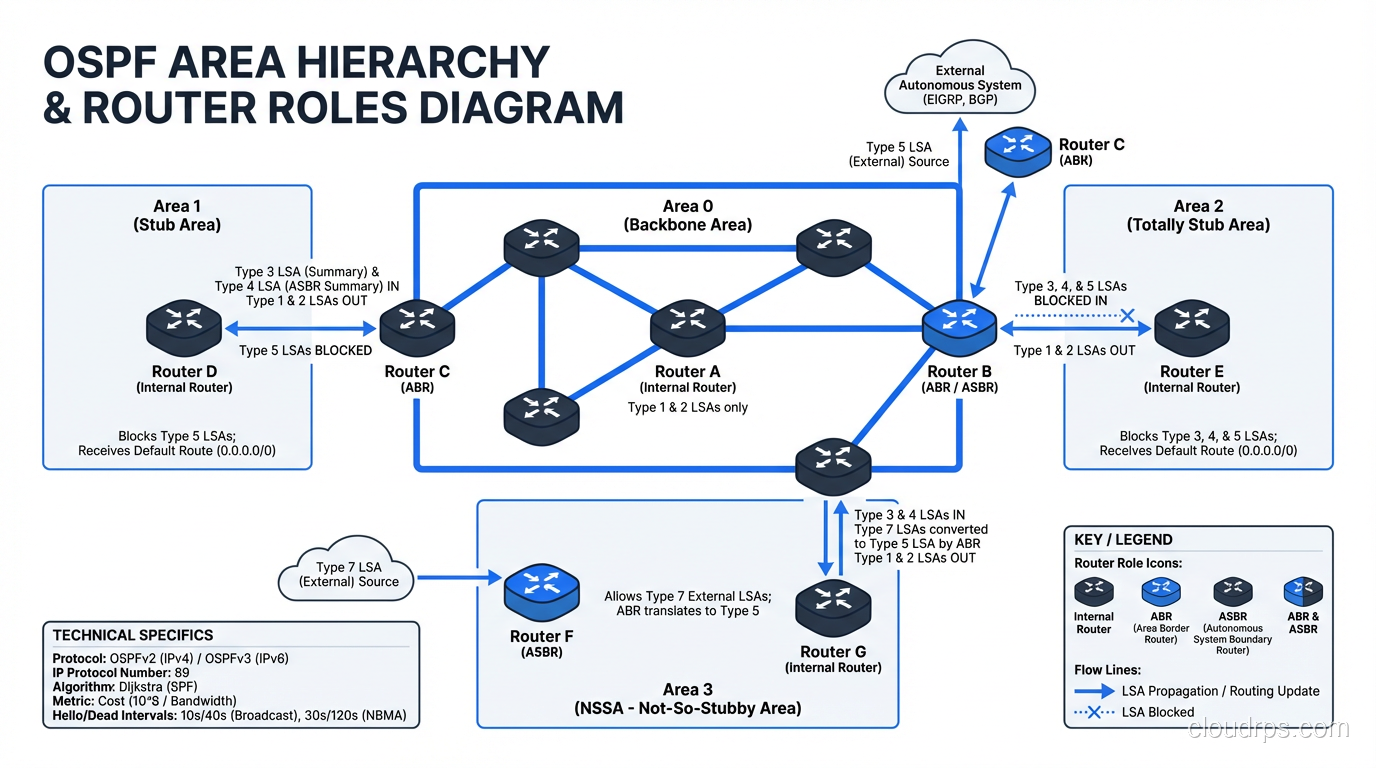
OSPF Areas: Scaling the Protocol
OSPF uses a hierarchical area design to scale. All areas must connect to Area 0 (the backbone). This limits the scope of SPF calculations; a topology change in Area 1 triggers SPF recalculation only within Area 1, not in Area 2.
[Area 0 - Backbone]
/ | \
[Area 1] [Area 2] [Area 3]
/ \ | / \
[Routers] [Routers] [Routers] [Routers] [Routers]
Common area types:
- Backbone (Area 0): The core; all other areas connect to it
- Normal area: Receives all LSA types
- Stub area: Blocks external routes (from BGP redistribution), uses default route instead
- Totally stubby area: Blocks external AND inter-area routes, pure default route
- NSSA (Not-So-Stubby Area): Like stub but allows limited external route injection
OSPF Configuration Example
Here’s a basic OSPF configuration on Cisco IOS:
router ospf 1
router-id 10.0.0.1
network 10.1.0.0 0.0.255.255 area 0
network 10.2.0.0 0.0.255.255 area 1
passive-interface default
no passive-interface GigabitEthernet0/0
no passive-interface GigabitEthernet0/1
!
interface GigabitEthernet0/0
ip ospf network point-to-point
ip ospf cost 10
Pro tips from years of OSPF deployments:
- Always set a router-id explicitly. Don’t rely on the highest loopback or interface IP. That’s a recipe for confusion.
- Use passive-interface default and then selectively enable OSPF on the interfaces that need it. This prevents accidental adjacencies.
- Use point-to-point network type on point-to-point links. The default broadcast type triggers DR/BDR election, which is wasted overhead on a link with only two routers.
- Tune your timers. Default hello/dead timers (10/40 seconds) are too slow for modern networks. I typically use 1/4 seconds with BFD (Bidirectional Forwarding Detection) for sub-second failover.
OSPF Gotchas
MTU mismatch: OSPF checks MTU by default in DBD (Database Description) packets. If two neighbors have different interface MTUs, the adjacency will get stuck in EXSTART state. This has bitten me more times than I can count, especially when one side has jumbo frames and the other doesn’t.
Area 0 connectivity: Every area MUST connect to Area 0, either directly or through a virtual link. If Area 0 gets partitioned, routing breaks. Virtual links are supposed to be a temporary fix, but I’ve seen them in production for years. Don’t do this.
Route summarization: OSPF only summarizes at ABRs (Area Border Routers) and ASBRs (Autonomous System Boundary Routers). You can’t summarize within an area. Plan your IP addressing scheme hierarchically to take advantage of this.
EIGRP: Cisco’s Secret Weapon
Enhanced Interior Gateway Routing Protocol (EIGRP) is Cisco’s proprietary (well, mostly; it was partially opened in RFC 7868) advanced distance-vector protocol. It’s sometimes called a “hybrid” protocol because it borrows ideas from both distance-vector and link-state approaches.
How EIGRP Works
EIGRP uses the DUAL (Diffusing Update Algorithm) to calculate loop-free paths. Instead of periodic full updates (like RIP) or flooding LSAs (like OSPF), EIGRP:
- Establishes neighbor relationships using Hello packets
- Exchanges full routing tables only once (when an adjacency forms)
- Sends incremental, partial updates only when something changes
- Maintains both a topology table (all known routes from all neighbors) and a routing table (best routes)
EIGRP’s composite metric considers multiple factors:
- Bandwidth (minimum along the path)
- Delay (cumulative along the path)
- Reliability (optional, not recommended)
- Load (optional, not recommended)
The default formula uses only bandwidth and delay:
Metric = 256 * ((10^7 / minimum_bandwidth) + cumulative_delay)
EIGRP’s Killer Feature: Feasible Successors
EIGRP pre-calculates backup routes called feasible successors. If the best route (the successor) fails, EIGRP can instantly switch to a feasible successor without any recalculation. This gives EIGRP sub-second convergence for many failure scenarios, often faster than OSPF.
A feasible successor must satisfy the feasibility condition: its reported distance must be less than the current best path’s feasible distance. This mathematical guarantee prevents routing loops without needing a full topology calculation.
When EIGRP Makes Sense
- All-Cisco shop: If every router is Cisco, EIGRP is dead simple to configure and converges fast
- Hub-and-spoke WANs: EIGRP handles hub-and-spoke topologies elegantly with stub routing
- Quick deployments: EIGRP auto-summarizes (you should disable this) and requires minimal configuration
When EIGRP Doesn’t Make Sense
- Multi-vendor environment: Even though it’s “open,” vendor support outside Cisco is thin
- Service provider networks: Nobody runs EIGRP in SP backbones
- Very large networks: OSPF’s hierarchical area design scales better than EIGRP’s query mechanism in massive topologies
I’ve run EIGRP in networks with 500+ routers and it worked fine, but the query scope had to be carefully managed with stub routers and distribute lists. In the same network, OSPF with proper area design would have been cleaner.
BGP: The Protocol That Runs the Internet
Border Gateway Protocol (BGP) is the only routing protocol that matters at internet scale. It’s the protocol that every ISP, cloud provider, and content delivery network uses to exchange routes. When someone says “the internet went down,” they usually mean “BGP went down.”
eBGP vs iBGP
BGP comes in two flavors:
- eBGP (External BGP): Between different Autonomous Systems. This is what runs the internet.
- iBGP (Internal BGP): Within an Autonomous System. Used to distribute externally-learned routes internally.
The key difference: eBGP assumes untrusted peers and has conservative defaults (TTL of 1, doesn’t propagate routes learned from one iBGP peer to another iBGP peer without route reflection).
How BGP Makes Decisions
BGP’s path selection algorithm considers a long list of attributes, evaluated in order:
- Highest weight (Cisco-specific, local to the router)
- Highest local preference (within the AS)
- Locally originated (prefer routes this router originated)
- Shortest AS path (fewer AS hops = better)
- Lowest origin type (IGP < EGP < incomplete)
- Lowest MED (Multi-Exit Discriminator, a suggestion from the neighbor AS)
- eBGP over iBGP
- Lowest IGP metric to next hop
- Oldest route (stability)
- Lowest router ID
In practice, most BGP routing decisions come down to local preference (for outbound traffic control) and AS path prepending (for inbound traffic control).
BGP Configuration Example
router bgp 65001
bgp router-id 10.0.0.1
neighbor 203.0.113.1 remote-as 65002
neighbor 203.0.113.1 description "Transit Provider A"
neighbor 203.0.113.1 prefix-list PROVIDER-A-IN in
neighbor 203.0.113.1 prefix-list MY-PREFIXES out
neighbor 203.0.113.1 route-map SET-LOCAL-PREF in
!
address-family ipv4 unicast
network 198.51.100.0 mask 255.255.255.0
neighbor 203.0.113.1 activate
exit-address-family
!
ip prefix-list MY-PREFIXES seq 10 permit 198.51.100.0/24
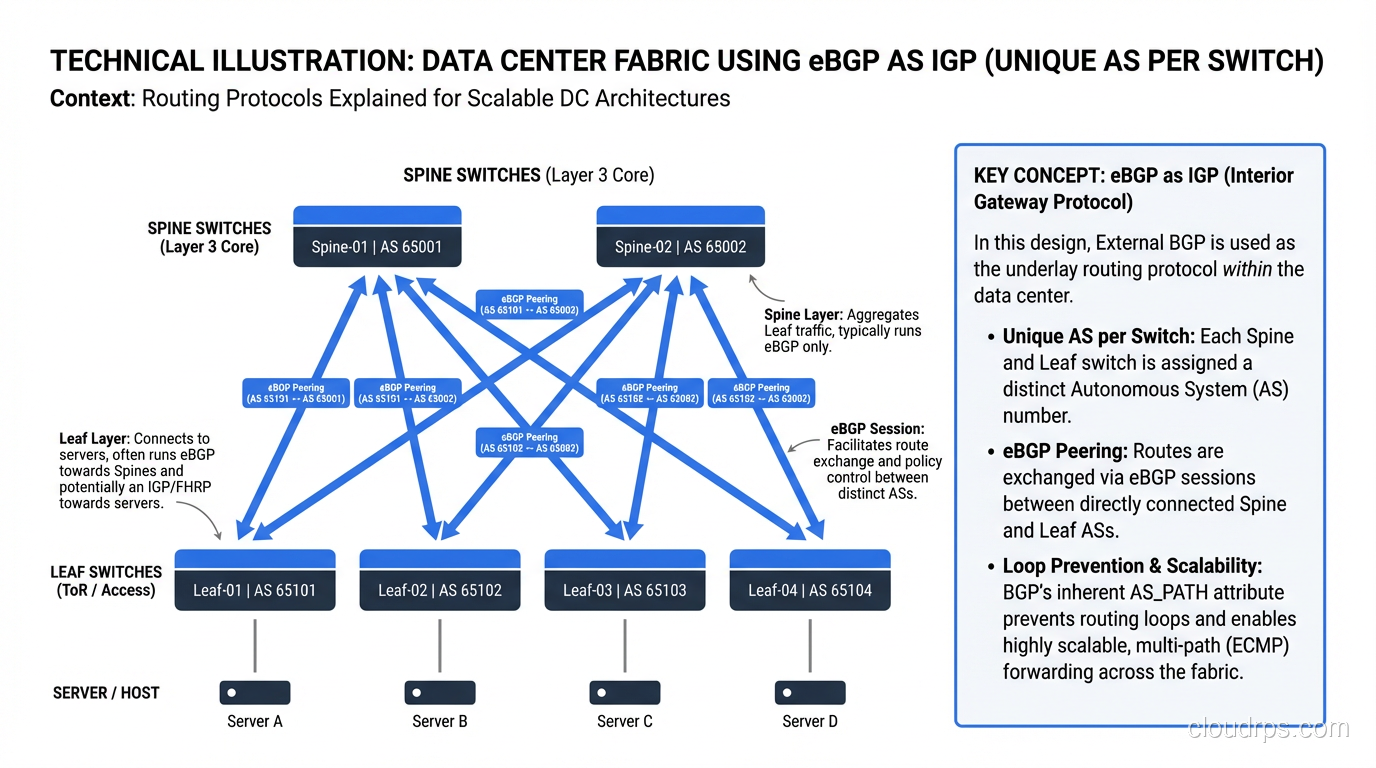
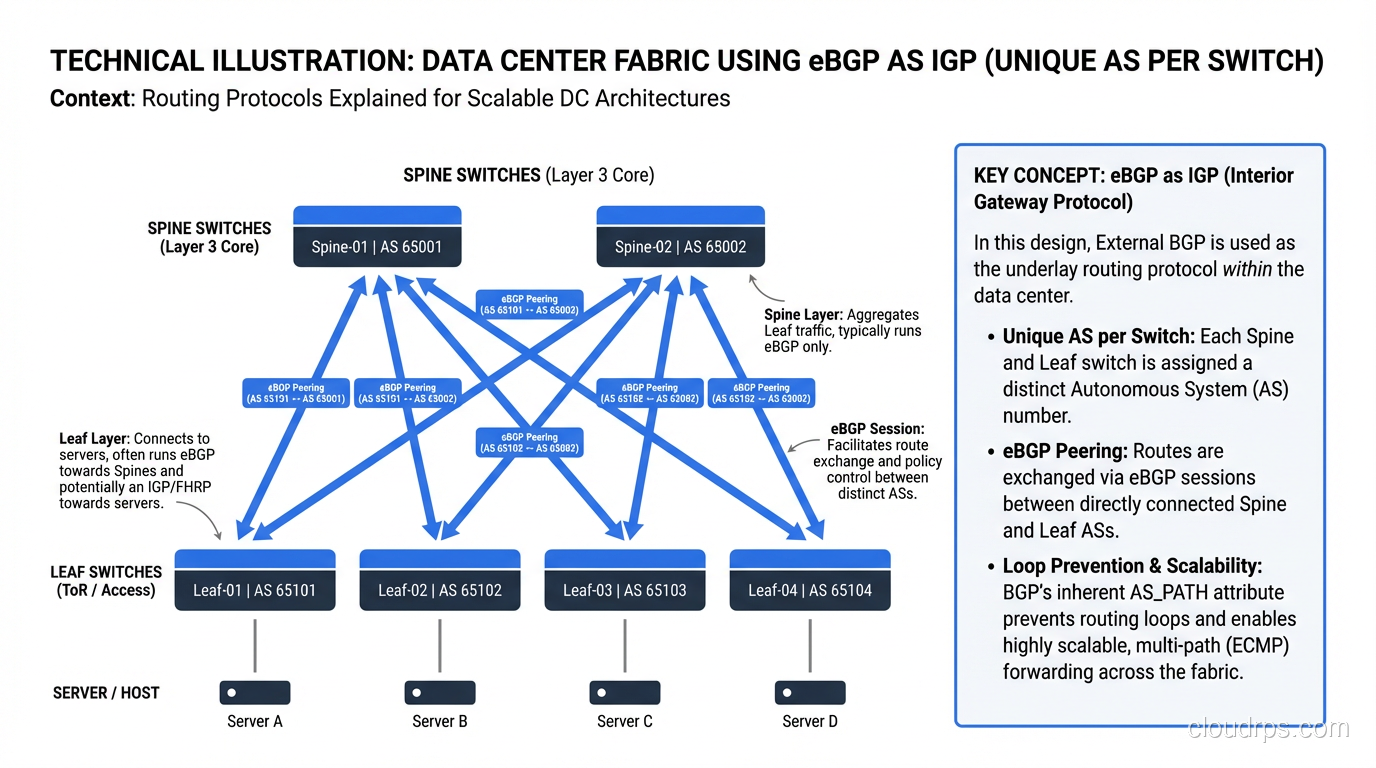
BGP in the Data Center: eBGP as IGP
There’s a fascinating trend in modern data center design: using eBGP as the IGP. Popularized by RFC 7938 and implementations at Facebook, Microsoft, and others, this approach assigns a unique private AS number to every switch in the data center fabric and runs eBGP between them.
[Spine 1 - AS 65001] [Spine 2 - AS 65002]
/ \ / \
[Leaf 1 - AS 65011] [Leaf 2 - AS 65012] [Leaf 3 - AS 65013]
Why? Because BGP’s policy engine is far more flexible than OSPF, and at the scale of a hyperscaler data center (thousands of switches), OSPF’s flooding and SPF calculations become problematic. eBGP between every pair of switches means no iBGP complexity (no route reflectors, no full mesh), and every switch makes independent decisions.
I’ve deployed this pattern in mid-size data centers (50-100 switches) and it works beautifully. The convergence is fast enough with BFD, and the operational simplicity of having one protocol for everything is worth the slightly more verbose configuration.
BGP War Stories
The Facebook Outage of October 2021: Facebook’s entire platform went down for about 6 hours because a maintenance command accidentally withdrew all BGP routes to their DNS servers. Without DNS, nothing worked, not even internal tools to fix the problem. Engineers had to physically go to data centers to restore configuration. This is what happens when your BGP configuration change process isn’t robust.
The Pakistan YouTube Incident (2008): Pakistan Telecom announced a more-specific BGP route for YouTube’s IP space, intending to block YouTube domestically. Due to a misconfiguration, this route propagated to the global internet, black-holing YouTube traffic worldwide for about 2 hours. This is why RPKI (Resource Public Key Infrastructure) and BGP route filtering matter.
IS-IS: The Other Link-State Protocol
I’d be remiss not to mention IS-IS (Intermediate System to Intermediate System). It’s a link-state protocol like OSPF, but with some key differences:
- IS-IS runs directly on Layer 2 (not IP), making it protocol-independent
- IS-IS uses a two-level hierarchy (Level 1 and Level 2) instead of OSPF’s area model
- IS-IS is extensible via TLVs (Type-Length-Values), making it easier to add new features
IS-IS is the IGP of choice for most large ISPs and cloud providers. Google, Amazon, and Facebook all run IS-IS in their backbones. The main reason: IS-IS’s TLV extensibility made it easier to add MPLS traffic engineering and segment routing extensions compared to OSPF’s more rigid LSA structure.
For enterprise networks, OSPF is still the better choice due to wider support on enterprise-grade equipment and more available documentation and training.
Protocol Selection Guide
Here’s my decision framework after deploying routing in hundreds of networks:
| Scenario | Recommended Protocol | Why |
|---|---|---|
| Small office (< 10 routers) | OSPF single area | Simple, standard, reliable |
| Enterprise campus | OSPF multi-area | Hierarchical, vendor-neutral, well-understood |
| All-Cisco enterprise WAN | EIGRP or OSPF | EIGRP is simpler; OSPF is more portable |
| Data center fabric | eBGP | Policy flexibility, no iBGP complexity |
| Internet peering | eBGP | It’s the only option |
| ISP backbone | IS-IS + eBGP | IS-IS for internal, BGP for customer/peer routes |
| Connecting to cloud (AWS/Azure) | eBGP | Direct Connect/ExpressRoute use BGP |
| Legacy tiny network | Static routes | If it’s 3 routers and never changes, keep it simple |
Understanding the OSI Model Context
Routing protocols operate at Layer 3 of the OSI model, but they interact with Layer 2 in interesting ways. OSPF, for example, uses multicast on the local link (224.0.0.5 and 224.0.0.6) to discover neighbors, while BGP runs over TCP (Layer 4) on port 179. Understanding where each protocol sits helps you troubleshoot. If OSPF neighbors aren’t forming, check Layer 2 first. If BGP peers aren’t coming up, check Layer 3/4 (can you TCP to port 179?).
Redistribution: Where Things Get Scary
Route redistribution (injecting routes from one protocol into another) is where network designs go to die. I have a rule: never redistribute unless you absolutely must, and when you do, always filter.
Common redistribution scenarios:
- OSPF↔BGP at the network edge (normal, expected)
- EIGRP↔OSPF during a protocol migration (temporary, scary)
- Static↔OSPF for default routes (common, usually fine)
The danger is routing loops caused by mutual redistribution. If you redistribute from OSPF into EIGRP AND from EIGRP into OSPF, you can create a feedback loop where routes bounce back and forth, each time with modified metrics. I’ve seen this take down production networks.
Always use route tags and distribute lists to prevent redistributed routes from being redistributed back into the source protocol.
Wrapping Up
Routing protocols are the foundation of every network you’ll ever build. My advice:
- Default to OSPF for enterprise networks. It’s standard, well-documented, and works.
- Use BGP for internet connectivity, cloud connectivity, and data center fabrics.
- Avoid RIP unless you’re supporting legacy equipment that can’t run anything else.
- Consider EIGRP only if you’re 100% Cisco and want simplicity.
- Learn BGP deeply. It’s the most important protocol in networking, and understanding it separates junior engineers from senior ones.
And remember: the best routing protocol is the one your team understands. A perfectly designed IS-IS network that nobody on your team can troubleshoot is worse than a “good enough” OSPF network that everyone knows inside out. Match the protocol to your team’s capabilities, not just to the textbook recommendation.
For a deeper look at how routers and switches work together in a network, or how these protocols fit into the broader OSI model, check out our related posts.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.