I spent three years convincing teams to adopt Kubernetes. Then I spent the next two years helping some of those same teams migrate off it. That’s not a contradiction. It’s what happens when you learn the hard way that the right tool depends entirely on what you’re building, how big your team is, and whether the operational overhead of cluster management actually serves your users.
The “Kubernetes vs serverless containers” question comes up constantly now. Google Cloud Run, AWS Fargate (and App Runner), Azure Container Apps, Fly.io, Railway, Render. There’s a whole category of platforms that let you run containers without ever thinking about nodes, control planes, or etcd. And they’ve gotten genuinely good. I’ve seen teams cut their infrastructure maintenance burden by 60-70% by picking the right managed platform instead of defaulting to K8s because that’s what the industry was doing five years ago.
This isn’t about bashing Kubernetes. It’s one of the most important pieces of infrastructure ever built, and I run production K8s today. But it’s a tool with a cost. Let’s talk honestly about when that cost is worth paying.
The Real Cost of Running Kubernetes
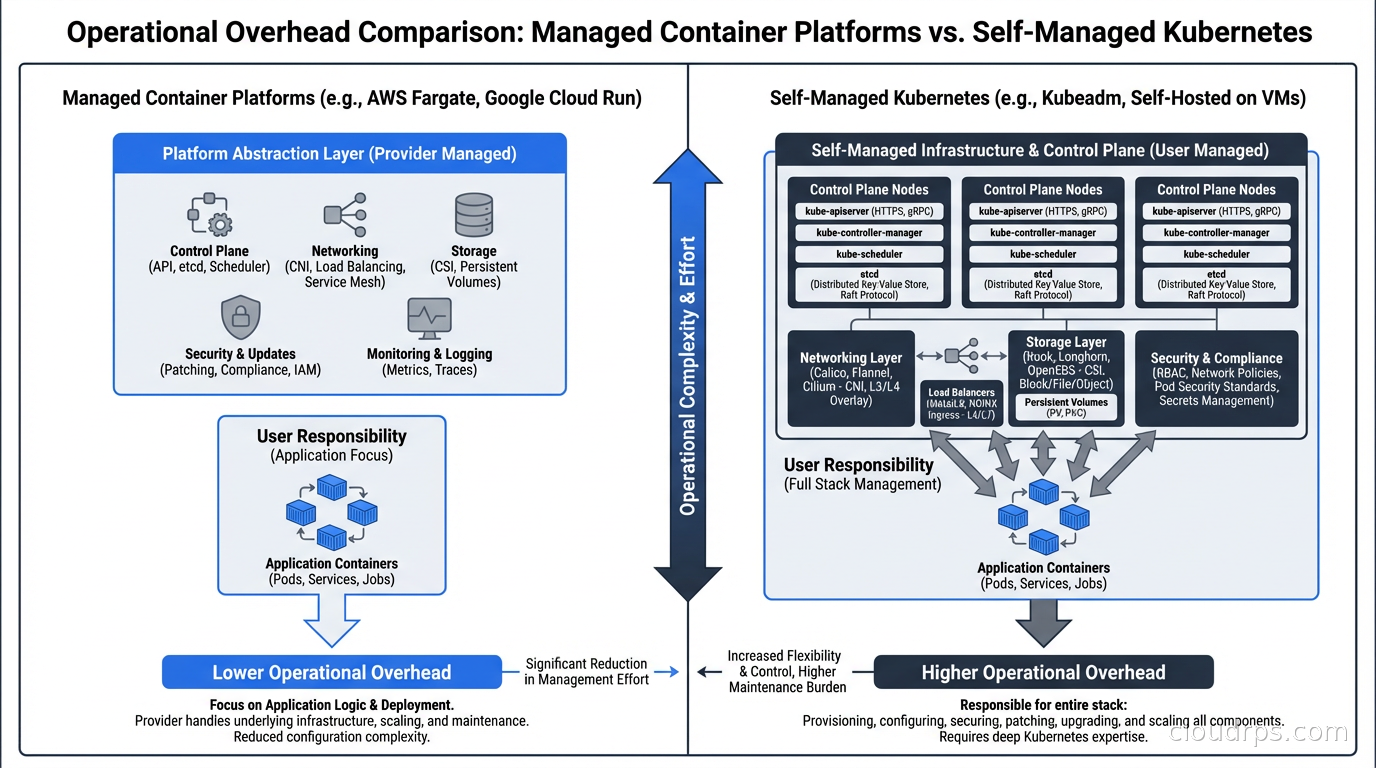
Before you evaluate alternatives, you need to understand what you’re actually paying for with Kubernetes. And I’m not just talking about compute. The hidden tax is the engineering time.
Running a production-grade Kubernetes cluster means someone on your team owns: cluster upgrades (and testing for breaking changes), node pool management, networking configuration (CNI plugins, ingress controllers, load balancers), secrets management integration, RBAC policies, pod disruption budgets, resource requests and limits for every workload, horizontal and vertical autoscaling configuration, monitoring and alerting stacks, and certificate management. That’s before you touch your actual application.
I’ve watched startups with five engineers spend two full engineers’ worth of time on Kubernetes operations. That’s 40% of engineering capacity going toward infrastructure that isn’t differentiated. If your product is Kubernetes management tooling, that investment makes sense. If your product is a SaaS application, you’re probably making a mistake.
The break-even point I’ve seen cited is roughly $2.5M in annual compute spend before the 30% efficiency gains from optimizing your own K8s cluster actually outweigh the cost of the engineers required to manage it safely. Below that threshold, you’re almost certainly better off on a managed container platform.
That said, there are non-cost reasons to run Kubernetes. Custom networking requirements, multi-tenant workload isolation, specific compliance postures, GPU scheduling for AI workloads. These are legitimate. But “everyone else is doing it” and “it’ll be useful someday” are not.
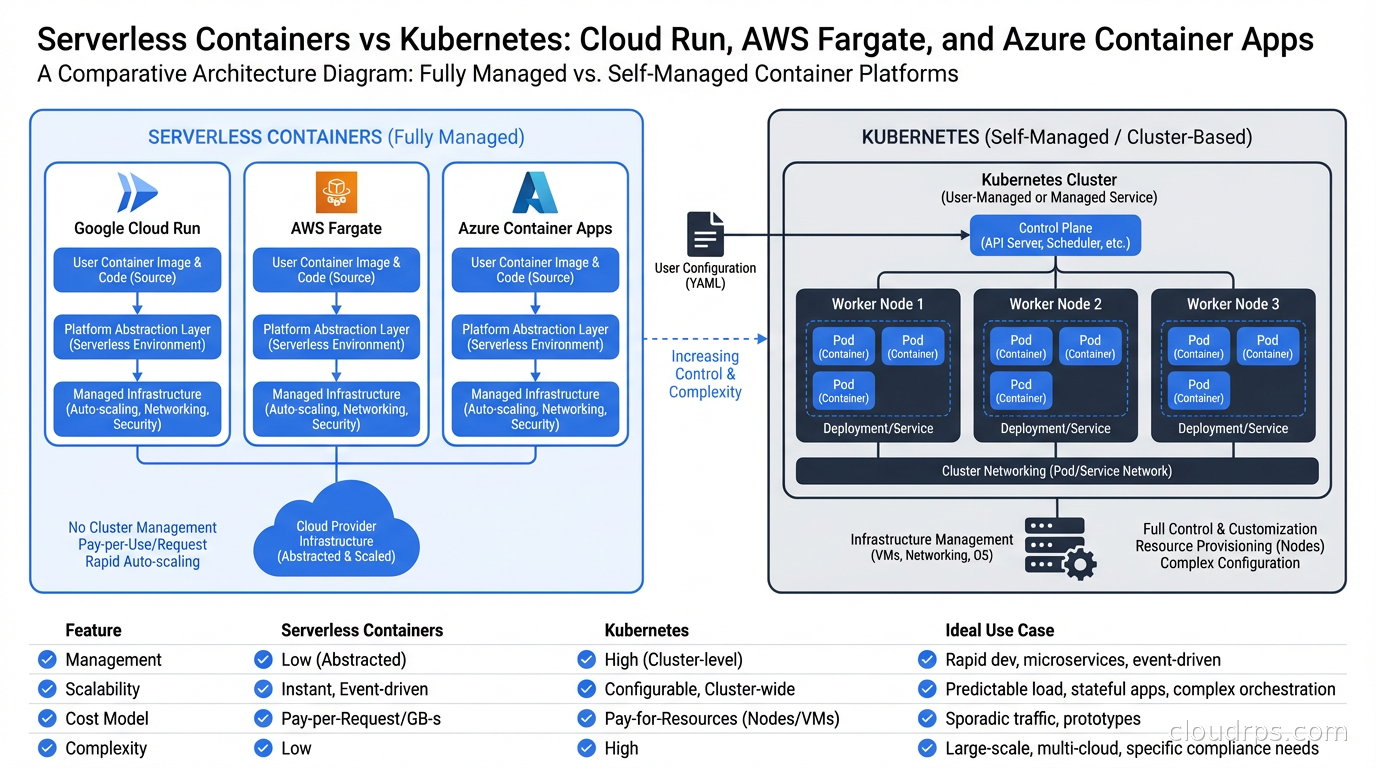
What Serverless Containers Actually Are
The term “serverless containers” gets used loosely. What it actually means in practice: you provide a container image, the platform handles everything else. No nodes. No scheduling. No cluster lifecycle.
The major platforms each have a slightly different model:
Google Cloud Run runs containers on demand, scaling to zero when there’s no traffic and scaling up as requests arrive. Concurrency-based scaling means it handles traffic spikes extremely well. Pricing is per-request and per-CPU-second. You pay almost nothing for idle workloads. Cold starts exist but have improved dramatically. I’ve run APIs that handle millions of requests per month for under $50 on Cloud Run.
AWS Fargate is a compute backend for ECS and EKS. It’s not quite serverless in the Cloud Run sense because you’re still defining task definitions, services, and clusters. But you’re not managing EC2 instances or node groups. Fargate on ECS is significantly simpler than EKS. Fargate on EKS gives you serverless nodes with a Kubernetes API. The tradeoffs are real though: Fargate has longer cold starts than Cloud Run, and ECS is AWS-proprietary. One underappreciated advantage of Fargate: since 2023 it runs tasks on Firecracker microVMs, giving you genuine VM-level tenant isolation rather than container-level isolation, which matters if you have strict compliance requirements around workload separation.
AWS App Runner is closer to Cloud Run. You give it a container (or a source repo), it runs it with automatic scaling and no infrastructure to manage. It’s simpler than ECS Fargate but also less flexible.
Azure Container Apps runs on top of Kubernetes internally (KEDA and Dapr are built-in), but exposes a much simpler surface. You get event-driven autoscaling, Dapr integration, and support for long-running workloads and background jobs. It’s the most Kubernetes-adjacent of the managed platforms, which makes it a reasonable stepping stone.
Fly.io occupies its own category. It deploys containers to a global edge network, with each “machine” being a microVM. It’s closer to an opinionated PaaS than a raw container runtime, but it supports complex multi-region architectures with a CLI-first workflow that many developers prefer.
When Managed Platforms Win
Here’s where I’ve seen managed container platforms consistently beat Kubernetes, and where I now reach for them first.
API services and web backends
If you’re running HTTP APIs, web servers, or GraphQL backends that are stateless or nearly stateless, serverless containers are almost always the right call. Cloud Run and App Runner handle traffic-based scaling automatically. You don’t need to think about pod replicas, HPA configuration, or node capacity. You deploy and you’re done.
I migrated a customer-facing API platform from EKS to Cloud Run last year. Three microservices, handling roughly 50 million requests per month. Monthly infrastructure cost dropped from $4,200 to $800. Engineering time spent on infrastructure dropped to essentially zero. The team redirected two weeks per month toward product work.
The key factors that made this work: the services were stateless, they had predictable request-response patterns, and they had no exotic networking requirements. If any of those were different, the calculus would change.
Event-driven and background job processing
Azure Container Apps with KEDA integration, or Cloud Run with Pub/Sub triggers, handles event-driven workloads elegantly. You define a trigger (a queue depth, a schedule, an HTTP endpoint), the platform scales from zero when work arrives and back to zero when the queue is empty. You pay only for actual compute consumed.
This beats Kubernetes for this pattern unless you have very specific requirements around job isolation, secrets injection, or complex multi-step pipelines. For those, something like Temporal running on Kubernetes (or a managed Temporal Cloud) is worth the overhead. But for simple queue-to-processor patterns, managed platforms win on every dimension.
Small teams and early-stage products
If your team has fewer than four engineers, nobody should be running Kubernetes. Full stop. I don’t care how much Kubernetes experience someone has. The cognitive overhead of keeping a cluster healthy while simultaneously building a product is brutal, and it inevitably means one or the other suffers.
I’ve watched three startups burn engineering cycles on Kubernetes infrastructure in their first year, building for scale they didn’t have and wouldn’t have for two years. All three eventually migrated to simpler platforms. The cost wasn’t just money; it was six to twelve months of slower feature development. Some teams go even simpler: Docker Compose on a single well-specced server can serve real production traffic for years if your load fits on one host, and the operational overhead is essentially zero compared to managing any orchestration platform.
Cloud Run, App Runner, and Fly.io are built for exactly this scenario. You can iterate on your product, and if you outgrow them, migrating to Kubernetes later is a solvable problem. The reverse is rarely true.
Workloads with spiky or unpredictable traffic
Scale-to-zero economics are genuinely compelling for workloads that aren’t running constantly. A nightly batch job that runs for 30 minutes costs almost nothing on Cloud Run. Running that same job on a dedicated K8s node pays for 24 hours of compute for 30 minutes of work.
Similar logic applies to development and staging environments. One of the best uses of Cloud Run I’ve seen is running staging environments that idle at zero between deployments. On Kubernetes, even a minimal staging cluster costs $300-500/month for idle compute. On Cloud Run, that staging environment costs essentially nothing.
When Kubernetes Is Actually Worth It
I want to be clear: Kubernetes isn’t going away, and there are genuine use cases where it’s the right call. Here’s where I’ve found the investment pays off.
Complex multi-service architectures at scale
When you have 20+ services with complex inter-service communication patterns, Kubernetes gives you primitives that managed platforms don’t: service mesh integration via Istio or Linkerd, fine-grained network policies, custom ingress controllers, and workload identity at the pod level. The operational overhead is justified by the control you gain.
The inflection point I’ve seen is roughly 10-15 services with significant inter-service traffic. Below that, you can manage with service discovery in managed platforms. Above it, you want the network control plane that Kubernetes provides.
GPU and accelerator workloads
Kubernetes Dynamic Resource Allocation has made K8s genuinely compelling for AI inference and training workloads. GPU sharing, fractional GPU allocation, time-slicing, and MIG (multi-instance GPU) partitioning are all Kubernetes-native now. Cloud Run and Fargate support GPUs in limited configurations, but if you’re running serious AI infrastructure, you want Kubernetes.
If you’re running LLM inference at scale, the architecture I’ve seen work involves Kubernetes for the GPU worker pools and something like Cloud Run or Fargate for the API layer that handles routing and rate limiting. Hybrid approaches like this are underrated.
Strong compliance and isolation requirements
Some regulatory environments require workload isolation guarantees that managed container platforms can’t provide by default. HIPAA, PCI-DSS, FedRAMP. When your compliance posture requires documented network isolation, audit trails at the container level, and specific encryption-at-rest configurations, Kubernetes with proper RBAC and network policies gives you the knobs to satisfy auditors.
I’ve helped set up HIPAA-compliant architectures on both EKS and Google GKE. It’s not fun, but it’s tractable because the tooling exists. Trying to meet the same requirements on a managed PaaS involves a lot of “well, the platform handles that” which doesn’t satisfy most compliance auditors.
Teams that already own Kubernetes expertise
There’s real value in institutional knowledge. If your team has three engineers who are genuinely comfortable with Kubernetes operations, the overhead calculus changes significantly. The “two engineers worth of time” problem I described earlier assumes you’re learning as you go. With real expertise, cluster operations compress to a fraction of that.
The trap is assuming expertise transfers easily. I’ve seen teams hire one Kubernetes expert and then act surprised when that person becomes a single point of failure, or when they leave and suddenly nobody can troubleshoot a node pressure issue at 2 AM.
The Hidden Complexity Tax on Managed Platforms
Managed platforms aren’t without tradeoffs. I’d be dishonest if I didn’t walk through the real limitations I’ve hit.
Cold starts. Cloud Run cold starts are typically 200-500ms for small JVM or interpreted language services, and can hit 2-5 seconds for large Java applications. For latency-sensitive APIs, this is a real problem. Minimum instance settings mitigate it at a cost: you pay for idle instances, which erodes the economics. Container startup optimization (smaller images, GraalVM native compilation, prewarming) helps but adds complexity.
Long-running connections. WebSockets, gRPC streaming, and long-polling don’t fit the request-response model that Cloud Run optimizes for. Cloud Run supports these but with timeout constraints. AWS App Runner has similar limitations. If your service requires persistent connections, Fargate on ECS or Kubernetes gives you more control.
Stateful workloads. I wouldn’t run a database or a stateful message broker on Cloud Run or App Runner. Managed platforms are built for stateless services. If you need stateful workloads, use managed databases (RDS, Cloud SQL, PlanetScale), managed queues (SQS, Pub/Sub), or run stateful services on Kubernetes with proper persistent volume management. The question of databases on Kubernetes is its own debate.
Vendor lock-in. This is the biggest strategic concern. ECS task definitions, App Runner configurations, and Cloud Run service manifests are all proprietary. Migrating between them is painful. The argument for Kubernetes is that your workload definitions are portable (to a degree). If multi-cloud portability matters to your organization, this is a legitimate reason to tolerate K8s complexity. Though I’ll be honest: I’ve seen very few organizations actually execute a cloud-to-cloud migration, so this concern is often more theoretical than practical.
Networking constraints. VPC peering, private endpoint connectivity, complex firewall rules. Managed platforms have caught up significantly on VPC integration, but Kubernetes still gives you more flexibility. If your service needs to talk to on-prem systems over a private network with specific routing requirements, the Kubernetes networking model is easier to reason about.
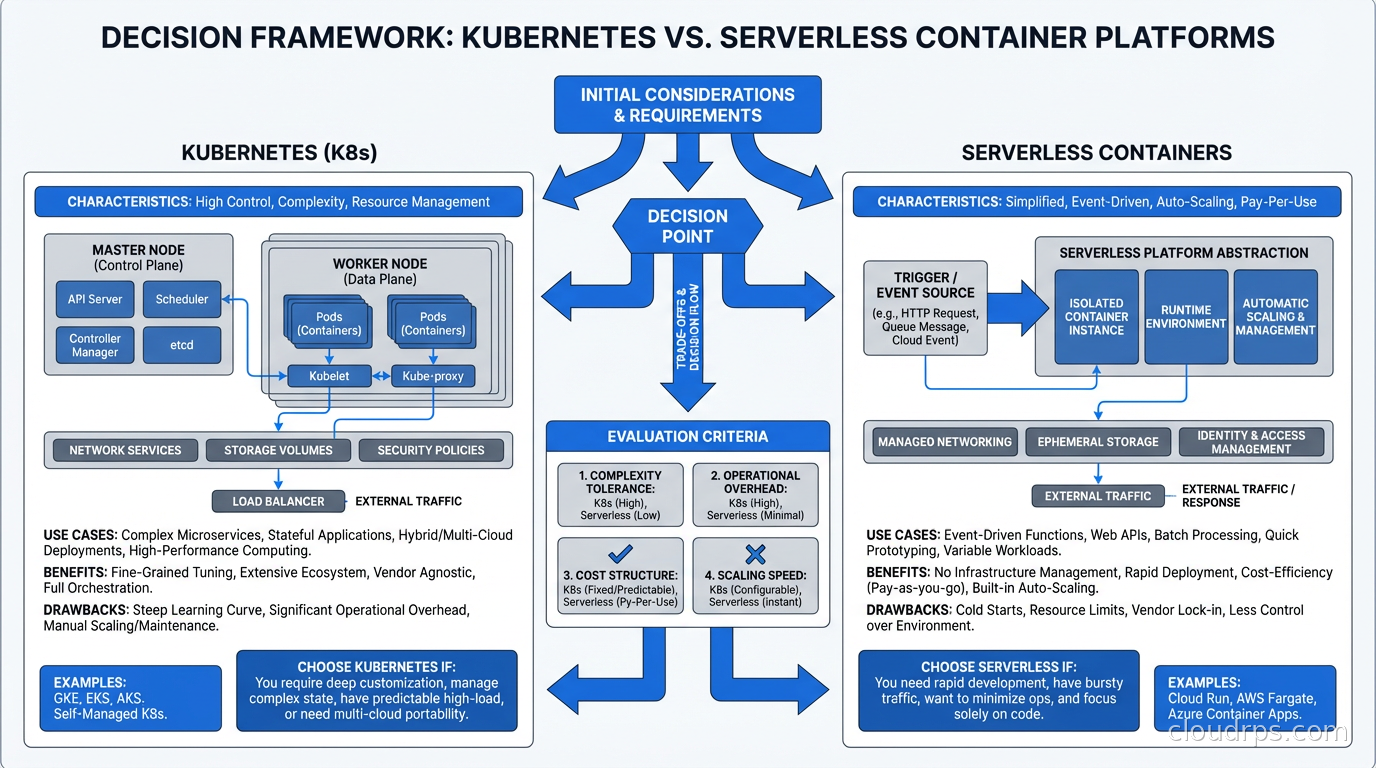
A Framework for Making the Decision
Here’s the decision process I actually use with teams:
Start with team size and operational capacity. Less than five engineers with no dedicated platform team? Managed platform. No exceptions.
Next, assess workload characteristics. Stateless HTTP services, event-driven processors, scheduled jobs? Managed platform. Stateful services, GPU workloads, complex service meshes? Kubernetes.
Then consider traffic patterns. Spiky or unpredictable traffic with tolerance for cold starts? Cloud Run economics are compelling. Constant baseline traffic that must minimize latency? Managed platforms may cost more than Kubernetes with Karpenter-driven autoscaling.
Finally, audit compliance requirements. If your security and compliance team needs workload-level isolation guarantees and you can’t satisfy them with the managed platform’s security model, Kubernetes is probably required.
The honest answer for most teams I’ve worked with in the past two years: start on managed platforms, stay on managed platforms until you hit a real ceiling, then migrate to Kubernetes incrementally. The GitOps workflows you build on managed platforms translate reasonably well to Kubernetes deployments when the time comes. Running your CI/CD pipeline through a managed platform while your control plane matures is a reasonable intermediate state.
If you’re thinking about infrastructure as code for managed platforms, both Terraform and Pulumi have excellent support for Cloud Run, ECS, and Container Apps. The infrastructure definitions are simpler than EKS/GKE cluster management. This is a feature, not a limitation.
The Cost Modeling You Should Actually Do
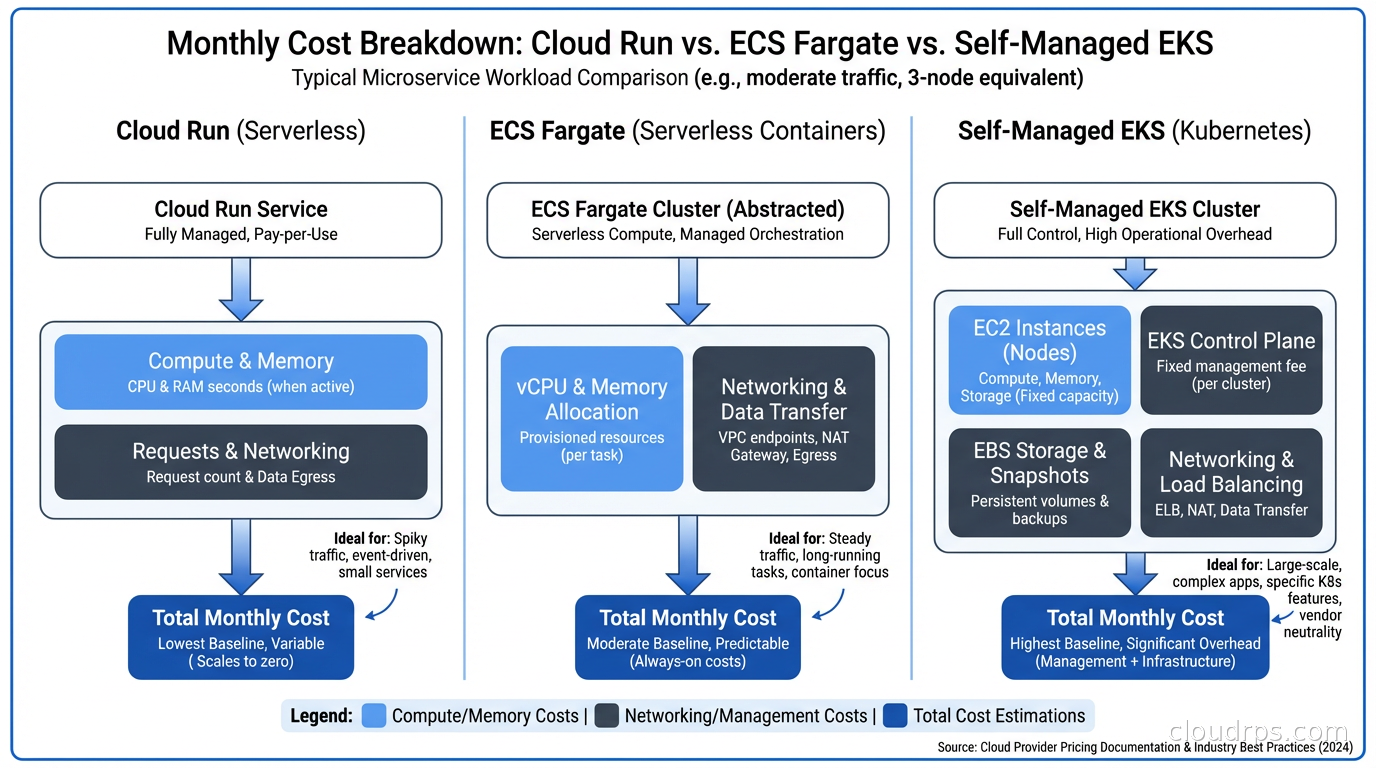
Stop making this decision on vibes. Do the math.
For a typical microservice handling 10 million requests per month with an average execution time of 50ms on Cloud Run: approximately $30-40/month in compute. On a shared EKS cluster with two m5.large nodes, the same workload costs $140/month for the nodes plus about $70/month for the managed control plane, before you add monitoring, logging infrastructure, and the cost of engineering time.
The engineering time component is the one most teams undercount. Track it for a quarter. Ask your engineers how many hours per week touch Kubernetes operations. Multiply by fully-loaded hourly rate. I’ve done this exercise with a dozen teams and the number is almost always surprising.
For FinOps purposes, managed container platforms have a simpler cost model: you pay for what you use. Kubernetes cost modeling is harder because you’re paying for capacity that may be partially idle, and optimizing utilization requires continuous attention. Cloud resource observability on managed platforms is also simpler since you’re instrumenting services rather than both services and cluster infrastructure.
Closing Thoughts
The pendulum is swinging back toward simplicity, and I think that’s healthy. Kubernetes became the default answer to “how do I run containers in production?” for a few years, and a lot of teams adopted it without really understanding the operational contract they were signing up for.
Cloud Run, Fargate, and Container Apps represent real maturity in the managed container space. These aren’t toy platforms. Large-scale production workloads run on them. Spotify runs workloads on Cloud Run. Many Fortune 500 companies use ECS Fargate. The operational simplicity isn’t a crutch; it’s the point.
My current mental model: managed platforms are the default choice, and Kubernetes is an intentional upgrade you make when specific requirements justify the operational investment. Not the other way around.
If you’re evaluating cloud-native architectures for a new project, I’d start with the simplest platform that can serve your requirements, then add complexity only when you hit real constraints. The decision to move to Kubernetes is reversible but expensive. The decision to stay on a managed platform longer than necessary costs you almost nothing.
The teams I’ve seen succeed with this approach aren’t the ones with the most sophisticated Kubernetes deployments. They’re the ones who made deliberate infrastructure choices and spent the rest of their energy building product.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.