I spent the better part of a decade trying to right-size database instances. The ritual was familiar: provision something a bit too large so you have headroom, watch it sit at 12% CPU during off-hours, get paged anyway when a traffic spike reveals you still under-provisioned on connections, repeat. The managed database services (RDS, Cloud SQL, Azure Database) improved the operational story but kept the same fundamental model. You pay for capacity whether you use it or not.
Serverless databases change that contract, and the change is more architectural than it first appears. The word “serverless” has been so badly abused in marketing copy that engineers justifiably roll their eyes at it. But when applied to databases, it describes a specific set of technical choices with real implications for how you build systems. This is a breakdown of how the three most interesting options actually work: Neon, PlanetScale, and Turso.
The Fundamental Problem: Compute and Storage Are Glued Together
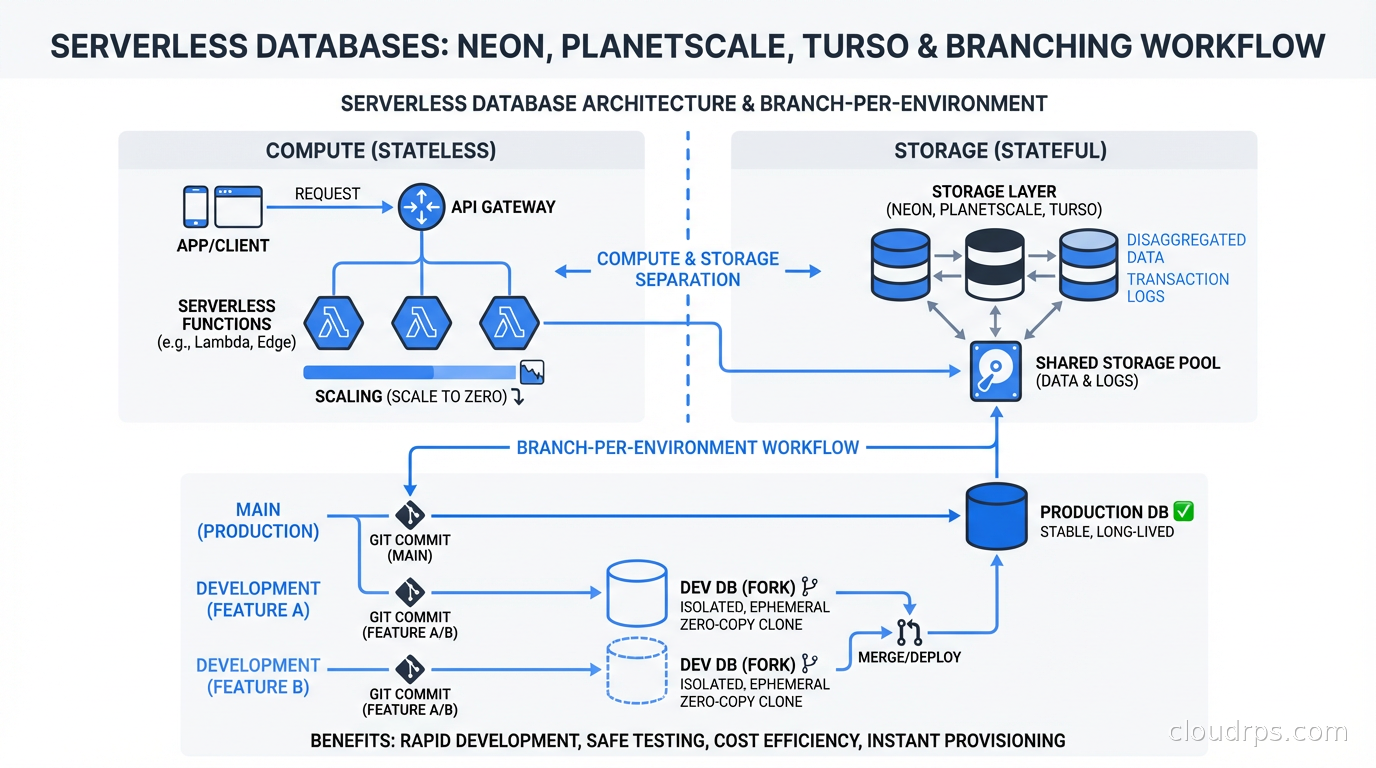
Traditional relational databases, including the managed cloud versions, tie compute and storage together on the same instance. When you stop that instance, the storage is inaccessible. When you want more compute, you resize the instance, which typically requires downtime or a replica promotion. Storage and compute scale together even when their requirements diverge, which they almost always do.
This coupling is a consequence of how databases were built: for single machines where memory, CPU, and disk lived in the same box. Distributed storage did not exist. Network latency was prohibitive for anything requiring tight coordination. The architecture made sense for its era.
Serverless databases break this assumption by separating compute from storage at the architecture level. Storage becomes a distributed, durable layer that any compute node can attach to. Compute can scale to zero without losing data. Multiple compute nodes can read from the same storage layer simultaneously. The relationship between durability and availability also changes: understanding ACID properties and what databases actually guarantee helps you reason about what you are and are not giving up when you adopt this model.
The catch is latency. Accessing storage over a network instead of a local disk adds overhead. Modern serverless databases compensate through aggressive caching, write-ahead log streaming, and carefully designed consistency protocols. Whether that compensation is sufficient depends heavily on your workload.
Neon: PostgreSQL with Disaggregated Storage
Neon is the most technically ambitious of the three. It takes PostgreSQL, leaves the query engine entirely intact with no forks or modifications to the planner, and replaces the storage layer.
PostgreSQL writes to the write-ahead log first, then to data files. Neon intercepts the WAL stream and sends it to its distributed storage layer: Safekeeper nodes for durability, and a Page Server for serving pages to compute. Compute nodes are standard Postgres processes that request pages from the Page Server over the network rather than reading local disk. Understanding how write-ahead logging works is the key to grasping why Neon’s architecture is sound from a durability standpoint. The WAL is the source of truth. Everything else is a derived view.
When a query needs a page, the compute node asks the Page Server. The Page Server applies WAL records on top of its base images to reconstruct the page at the requested LSN (Log Sequence Number). This is lazy materialization: the Page Server does not eagerly apply every WAL record everywhere, it reconstructs pages on demand. This sounds expensive, and it can be, but it enables the architecture’s key properties.
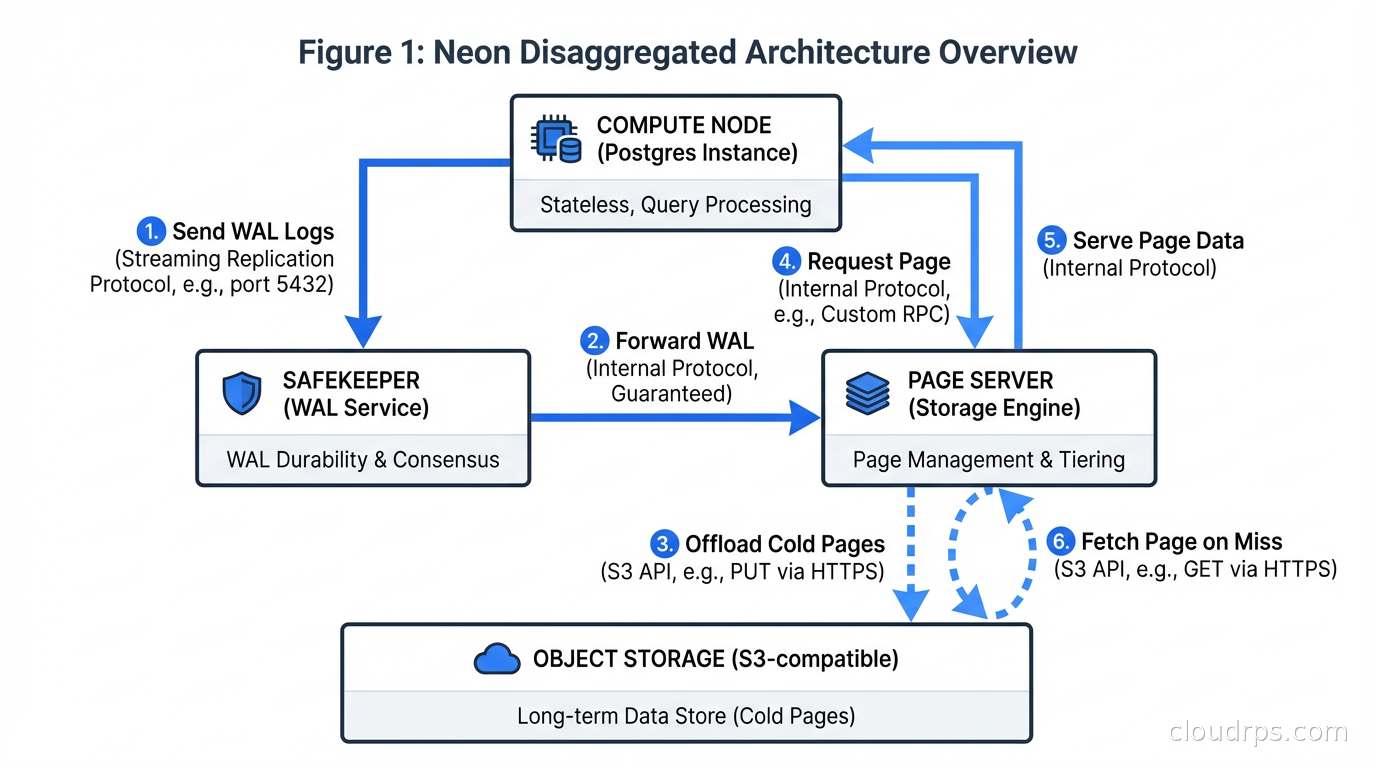
Scale-to-zero works because compute is stateless. If your Neon database sees no traffic for five minutes, the compute process terminates. Storage stays intact in the distributed layer. When a new request arrives, a new compute process starts, connects to the Page Server, and serves the query. Cold start is typically 500ms to a few seconds depending on your plan. For a dev environment or a low-traffic production service, that is acceptable. For a latency-sensitive API, it is not.
Branching is where Neon genuinely earns its architectural novelty. A branch in Neon is not a copy of your database. It is a metadata pointer to a specific LSN in the WAL history. Creating a branch takes under a second regardless of database size because no data is copied. The branch shares storage with its parent using copy-on-write semantics: when you write to a branch, only the modified pages go to new storage. The branch diverges from the parent only where changes actually occur.
The practical implication is that you can create a branch of your 100GB production database in one second, run schema migrations against it, verify they work, and discard the branch when you are done. The branch costs nothing until you write to it, and even then only pays for the pages that diverge from the parent.
I have watched teams spend weeks building database provisioning scripts that created “realistic” test environments from sanitized production snapshots. The data was always stale. The process took hours. The environments drifted from production over time. Neon’s branching makes that pattern obsolete for teams already on Postgres.
Where Neon struggles is sustained high-throughput workloads with lots of random writes. The Page Server adds latency compared to local NVMe. Neon is continuously improving this, and the Databricks acquisition in 2025 pushed serious engineering resources toward performance. But if you are running a transaction-heavy OLTP workload with sub-millisecond latency requirements, a traditional managed Postgres cluster with connection pooling via PgBouncer or RDS Proxy still wins on raw latency.
Connection Management: The Serverless Function Problem
One of the less-discussed challenges with serverless databases is how they interact with serverless compute. If you are running Lambda functions or edge workers, each function invocation may open a new database connection. A burst of traffic can spawn thousands of simultaneous connections, overwhelming a database that can only handle a few hundred.
This is not a new problem. Traditional Postgres maxes out around 100-500 connections before connection overhead starts degrading performance. The solutions (PgBouncer, RDS Proxy, pgpool) add a pooling layer that multiplexes many application connections onto fewer database connections. The connection pooling architecture matters here: transaction-mode pooling is safe for most serverless workloads, but session-mode pooling does not work with scale-to-zero because sessions cannot be parked across cold starts.
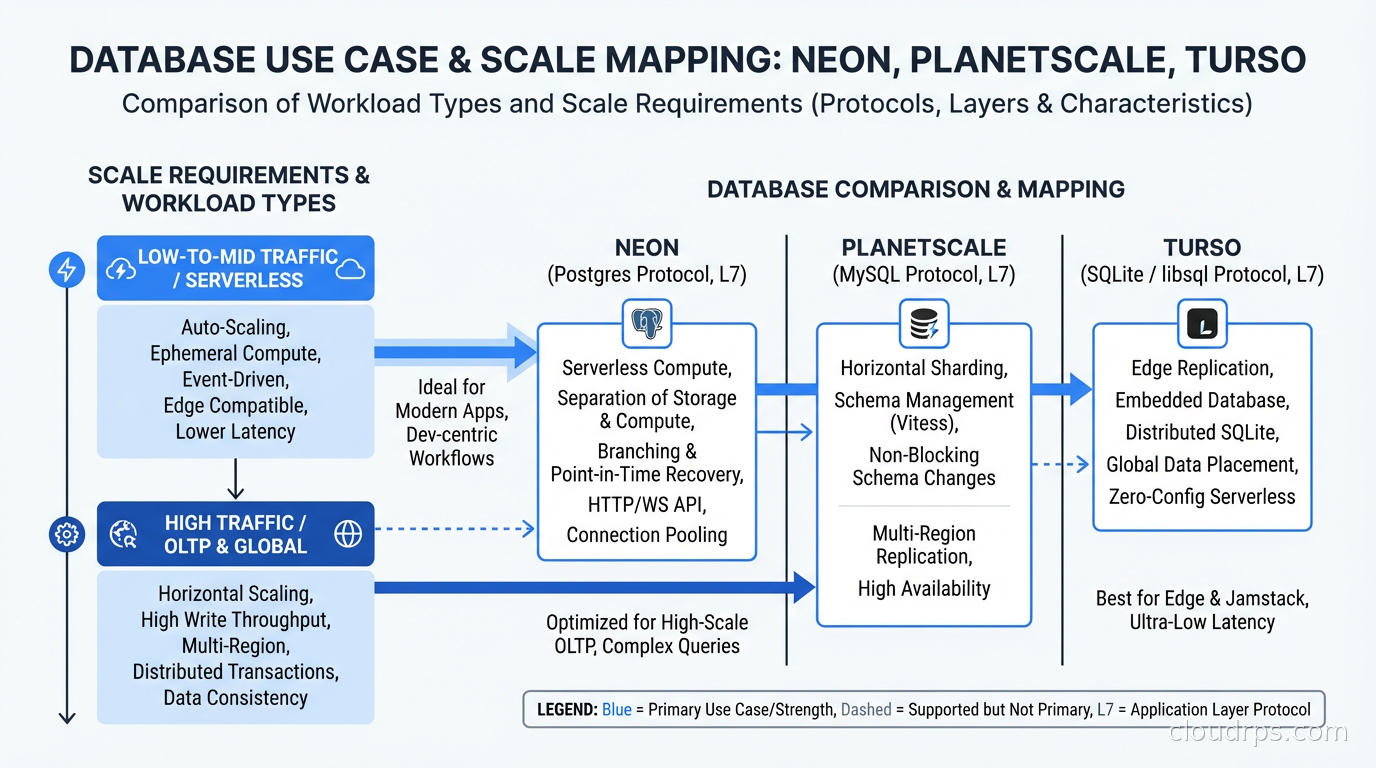
Neon handles this better than raw Postgres. Their serverless driver (which speaks Postgres protocol over HTTP) is designed explicitly for connection-per-request patterns. You get the query semantics of Postgres without the connection lifecycle overhead. PlanetScale, built on Vitess, handles connection multiplexing internally. Turso avoids the problem entirely because SQLite is embedded in the process.
If you are building on serverless compute and need a relational database, this connection management story is more important than it might appear. I have seen teams burn significant engineering time debugging connection pool exhaustion under traffic spikes on systems that ran fine during testing. Testing with realistic concurrency before choosing a database platform is not optional.
PlanetScale: Vitess Under a Friendly Interface
PlanetScale is architecturally different from Neon in a foundational way. It is built on Vitess, the MySQL sharding layer that YouTube built to scale its database fleet. Where Neon is stock Postgres with a new storage layer, PlanetScale is MySQL with an industrial-grade sharding and schema management layer on top.
Vitess handles connection pooling internally, meaning you can throw thousands of application connections at PlanetScale without the connection exhaustion problems that plague traditional MySQL deployments. This is a real operational benefit, especially with serverless functions that spawn many short-lived connections.
PlanetScale’s branching story differs from Neon’s. MySQL branches in PlanetScale are schema-only environments: they carry the table structure but not the data. This makes them ideal for iterating on schema changes before applying to production, but it means you cannot run queries against a copy of your production data the way Neon branching enables.
In 2025, PlanetScale shipped a PostgreSQL product with its own branching model. The Postgres branches use restore-from-backup rather than copy-on-write, so they include data but take longer to create for large databases. The MySQL product remains more mature.
PlanetScale’s real strength is schema change management. The platform enforces a workflow: make schema changes on a development branch, run a non-blocking schema change using gh-ost under the hood, and merge to production through a request process. This workflow has prevented a lot of production table locks. If you have watched ALTER TABLE on a 200-million-row table lock your production MySQL for three hours, you understand exactly why this matters.
The horizontal sharding capability via Vitess’s VSchema is available on higher tiers. Most teams never need it, but when you hit the limits of a single MySQL instance, PlanetScale’s sharding path is the most operationally tractable option in a managed service. Understanding sharding vs partitioning trade-offs helps you assess whether you actually need horizontal sharding or whether vertical scaling and read replicas cover your requirements.
Turso: SQLite at the Edge
Turso takes a completely different architectural approach. Instead of distributing a server-side database, it distributes SQLite itself.
SQLite’s reputation as “the database for embedded applications and mobile devices” undersells it significantly. It is the most deployed database in the world by a wide margin: every smartphone, every browser, most desktop apps. Its architecture is specifically designed to be embedded in the process that uses it, which means zero network overhead for reads, no connection management complexity, and extraordinarily low latency.
Turso’s insight is that SQLite embedded in an edge runtime can serve data locally to users with local-read latency (single-digit milliseconds) while syncing writes back to a primary and propagating updates to other edge locations. The architecture is multiwriter in a limited sense: most edge replicas are read-only, and writes go to a primary.
For read-heavy workloads with globally distributed users, Turso offers latency characteristics that no server-side database can match regardless of infrastructure investment. The database is literally running on the same machine as your edge function.
The limitation is SQLite’s concurrency model: one writer at a time. For write-heavy workloads or workloads requiring complex transactions across large datasets, the writer lock becomes a bottleneck.
The use case Turso owns is multi-tenant SaaS where each tenant gets their own database. The operational overhead of managing thousands of Postgres instances is significant. With Turso, each tenant gets a SQLite file that syncs to the edge nearest to them. Creating a new tenant database is nearly instant. Storage costs per tenant are minimal for small tenants. For this specific pattern, Turso is currently the best answer in the market.
The Branch-per-Environment Pattern
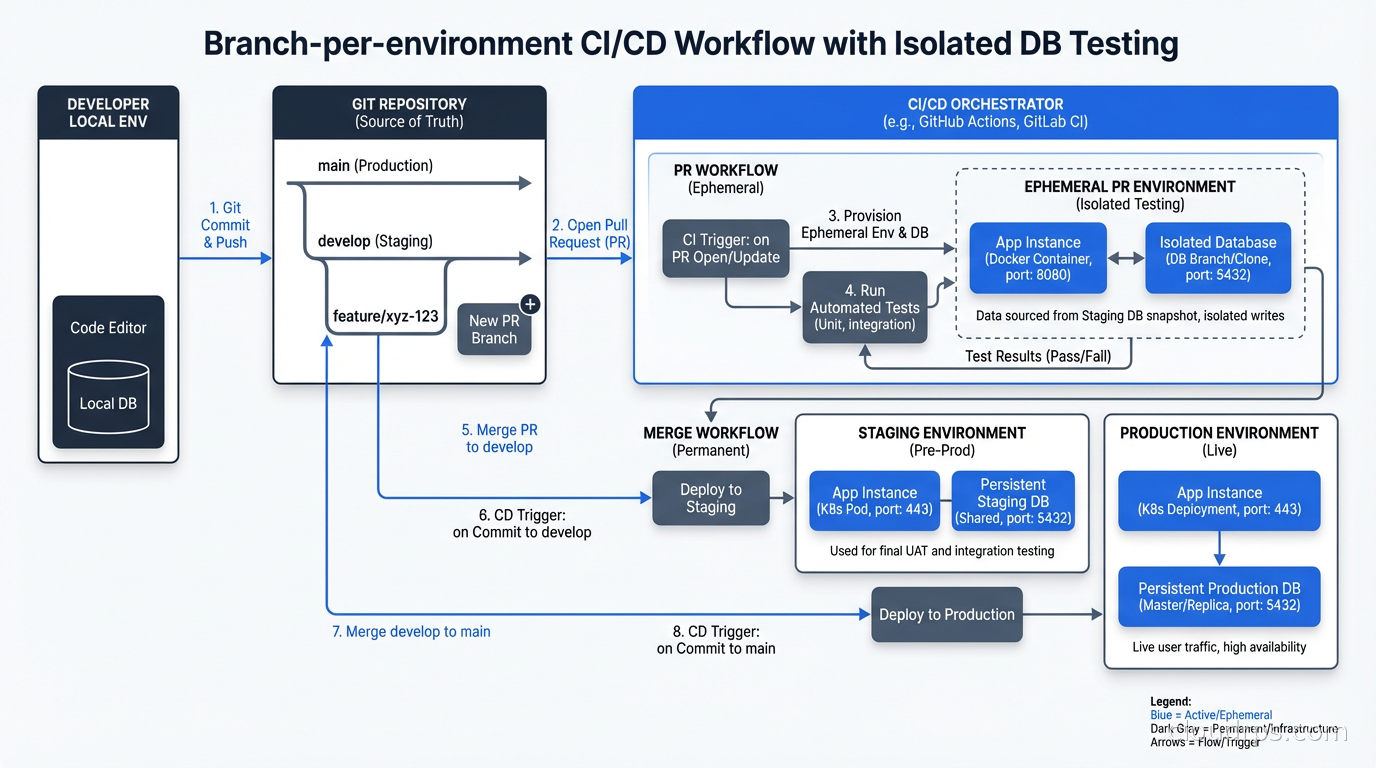
All three platforms have leaned into branching as a core workflow concept. The idea: every pull request gets its own database branch, CI/CD runs migrations against the branch, tests run against it, and the branch is destroyed when the PR closes.
This solves a problem I have watched teams hack around for years. The common anti-patterns:
- Shared dev database that everyone writes to, causing constant conflicts
- Per-developer Postgres instances that drift from production schema
- Running tests against SQLite locally even though production is Postgres, then being surprised when behavior differs
- Sanitized production snapshots that take hours to restore and are immediately stale
Branch-per-environment eliminates these anti-patterns when the database is already in the cloud. A CI pipeline that creates a Neon branch, runs migrations, runs tests, and deletes the branch takes seconds for the database provisioning step and costs fractions of a cent. The branch is always at production schema plus whatever migration you are testing.
The workflow in practice: your GitHub Action checks out the PR branch, uses the Neon or PlanetScale CLI to create a database branch from production, runs your migration tool against it, runs the test suite, and tears down the branch on completion. You get a real Postgres environment with production data shape, isolated from everyone else’s work, at throwaway cost.
This is the workflow change that genuinely improves how teams work. Not the cost savings on idle dev instances. Not the scale-to-zero economics. The ability to treat database environments as ephemeral as pull requests: that is the real value.
Cold Starts: What They Actually Cost You
Scale-to-zero is the most headline-grabbing serverless database feature and the one most likely to cause production surprises. The economics make sense for dev environments, staging, and low-traffic services. They make less sense when users are waiting.
Neon’s cold start on paid tiers typically runs 500ms to 2 seconds. Their Pro plan supports always-on compute that avoids cold starts at the cost of continuous billing. Most production applications should run always-on and reserve scale-to-zero for non-production environments. The cost of running a small Neon compute continuously is low enough that it is not worth the latency trade-off to save it.
PlanetScale does not use the same scale-to-zero model. Their serverless pricing is consumption-based for row reads and writes rather than compute time. There is no cold start in the traditional sense.
Turso’s edge replicas are embedded in edge runtimes that stay running, so cold starts are not a relevant concept for the primary read path.
The advice I give teams: use scale-to-zero for development, CI/CD, and staging environments where occasional 2-second delays are acceptable. Keep production compute warm even if “warm” costs a few dollars a month. The user experience cost of cold starts in production is almost always larger than the compute savings.
When Serverless Databases Are Wrong
High-throughput OLTP with sub-millisecond latency requirements: network round-trips to remote storage add up. A co-located Postgres instance on fast NVMe still has a latency advantage. Aurora’s distributed storage architecture predates this serverless wave and has similar disaggregation principles, but is not scale-to-zero and has stronger latency guarantees for hot data.
Complex analytical queries: these platforms are not optimized for analytical workloads. The data warehousing path goes through ClickHouse, BigQuery, or Redshift. The architectural difference between columnar and row-based storage explains why the same data organized differently performs orders of magnitude better for analytical queries.
Existing large PostgreSQL deployments with heavy customization: Neon is standard Postgres, but the managed nature means you cannot install custom C extensions requiring superuser access. Check compatibility before migrating.
Massive concurrent write workloads: if you are processing millions of writes per second, you are probably beyond what any single managed service can handle and need to think about horizontal sharding strategies.
Making the Choice
After putting serious time into all three platforms, here is my current mental model:
Choose Neon if you are on Postgres, want the best branching workflow, and do not have extreme latency requirements. The stock Postgres compatibility means no migration headaches. The branching is the best in class.
Choose PlanetScale if you are on MySQL, need the non-blocking schema change workflow enforced by the platform, or are building something that might eventually need horizontal sharding.
Choose Turso if you are building multi-tenant SaaS with one-database-per-tenant, need edge latency characteristics, or are working with a read-heavy workload with globally distributed users.
For new projects, I default to Neon unless there is a specific reason otherwise. The Postgres compatibility story matters: the tooling ecosystem, the extension library, the operational knowledge base, all of it transfers. The branching workflow changes how I think about development environments for the better. And the scale-to-zero economics make dev and staging environments genuinely cheap to leave running.
Serverless databases are not a panacea. They represent a real architectural choice with real trade-offs. But the compute-storage separation and branching primitives solve real problems that I have watched teams work around expensively for years. The platforms are mature enough for production. The question is whether they are the right tool for your specific workload.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.