The Debugging Nightmare That Changed How I Think About Microservice Networking
A few years back, I was the principal architect on a fintech platform running about 140 microservices on Kubernetes. Things were mostly fine until one Thursday afternoon when our payment processing latency spiked from 200ms to 12 seconds. Customers were timing out. Revenue was bleeding.
Here’s what made it brutal: we had no idea which service was the bottleneck. Our payment flow touched 11 services. Each one had its own retry logic, its own timeout settings, and its own idea of what “healthy” meant. We spent four hours bouncing between logs from different services, trying to correlate timestamps manually, before we finally tracked it down to a single downstream catalog service that had started returning 503s intermittently. The retries from three different upstream services were amplifying the problem into a full-blown cascade failure.
That incident cost us real money and a lot of sleep. It also forced me to seriously evaluate service meshes for the first time. I had dismissed them before as unnecessary complexity. I was wrong, at least for our situation.
If you are running a handful of services, you probably don’t need a service mesh. But if you have crossed the threshold where debugging service-to-service communication feels like detective work, this article is for you. I will walk through what service meshes actually do, compare the two biggest players (Istio and Linkerd), and help you figure out whether your architecture genuinely needs one.
What Is a Service Mesh, Really?
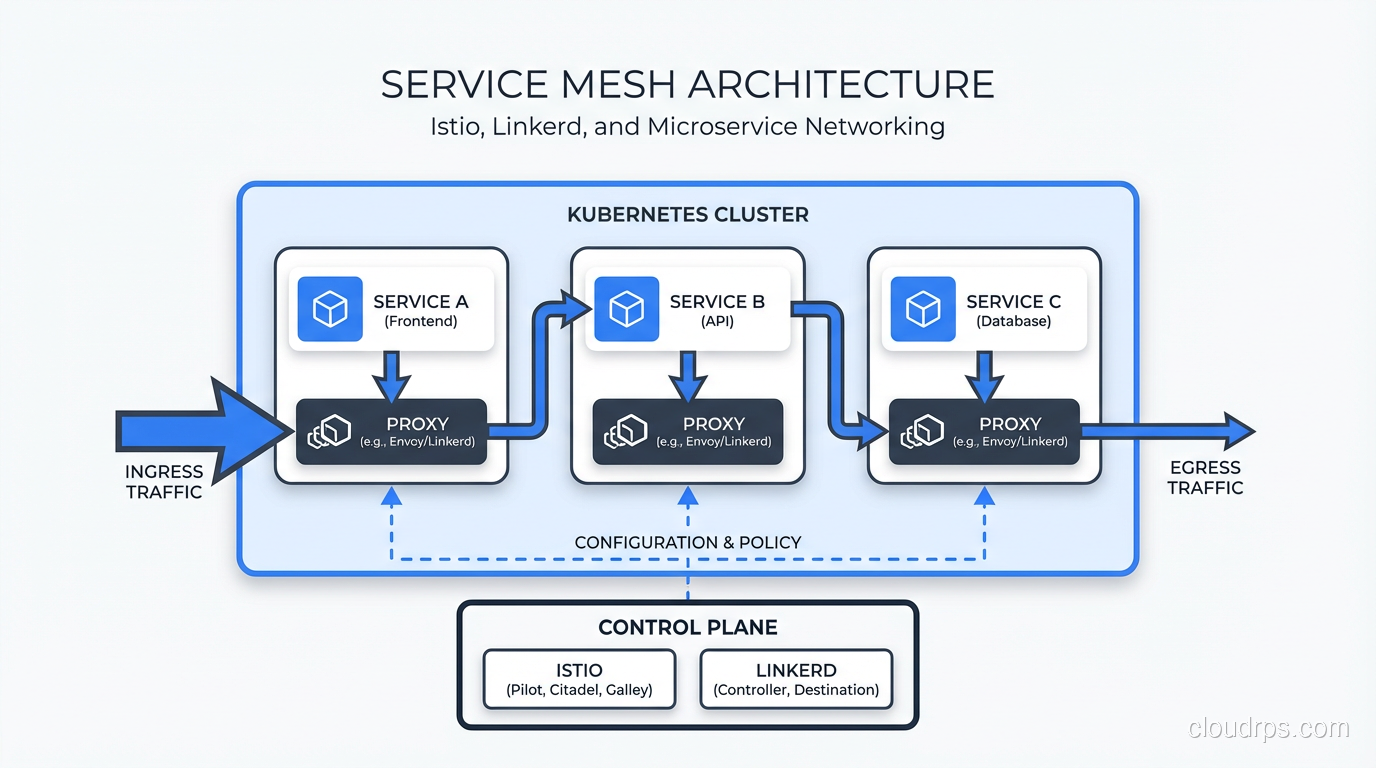
Strip away the marketing, and a service mesh is infrastructure that handles service-to-service communication so your application code doesn’t have to. It manages east-west traffic: requests between services inside your cluster. North-south traffic (external clients to your services) is the job of an API gateway, which handles auth, rate limiting, and routing at the cluster edge. Both are complementary; they solve different halves of the networking problem. Instead of every microservice implementing its own retry logic, timeouts, encryption, and observability, you push all of that down into the infrastructure layer.
A service mesh has two main components:
The Data Plane handles the actual network traffic. It sits between your services, intercepting every request and response. It handles load balancing, retries, timeouts, circuit breaking, and mutual TLS. If you have read about load balancing strategies before, think of the data plane as a hyper-intelligent load balancer embedded right next to each service instance.
The Control Plane is the brain. It configures the data plane proxies, distributes policies, collects telemetry, and manages certificates. You interact with the control plane to set traffic rules, and it pushes those rules out to every proxy in the mesh.
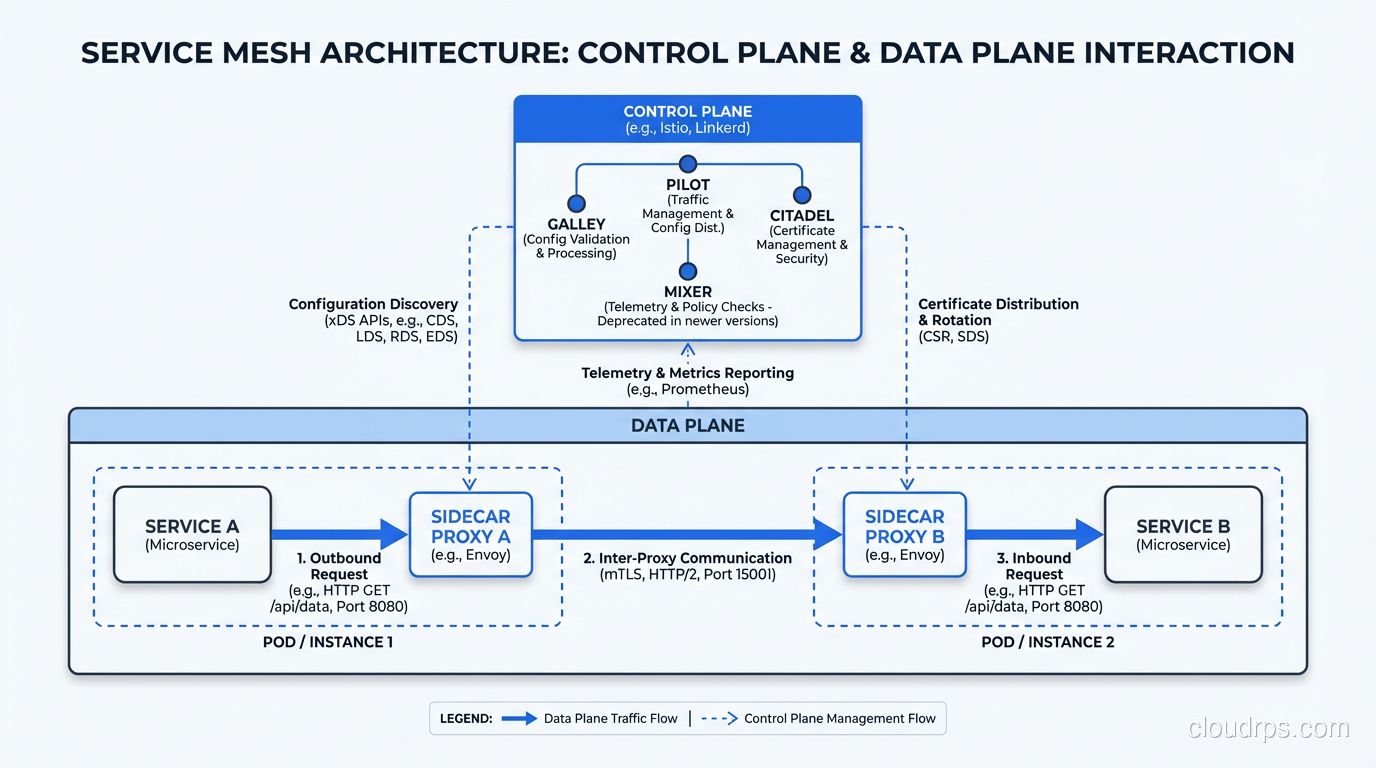
This separation is important because it means your application code stays clean. Your Go or Java service just makes a normal HTTP or gRPC call to another service. The mesh handles everything else transparently.
The Sidecar Pattern: How It Actually Works
The way most service meshes inject themselves into your traffic flow is through the sidecar pattern. For every pod in your Kubernetes cluster, the mesh injects a small proxy container that runs alongside your application container. This proxy intercepts all inbound and outbound network traffic for your service.
Here is what happens when Service A calls Service B:
- Service A makes a normal HTTP request to Service B’s address.
- The sidecar proxy in Service A’s pod intercepts the outbound request.
- The proxy applies any configured policies: retries, timeouts, circuit breaking, mutual TLS encryption.
- The request travels across the network to Service B’s pod.
- Service B’s sidecar proxy intercepts the inbound request.
- The proxy terminates TLS, checks authorization policies, and forwards the request to Service B.
- The entire round trip is measured and reported as telemetry.
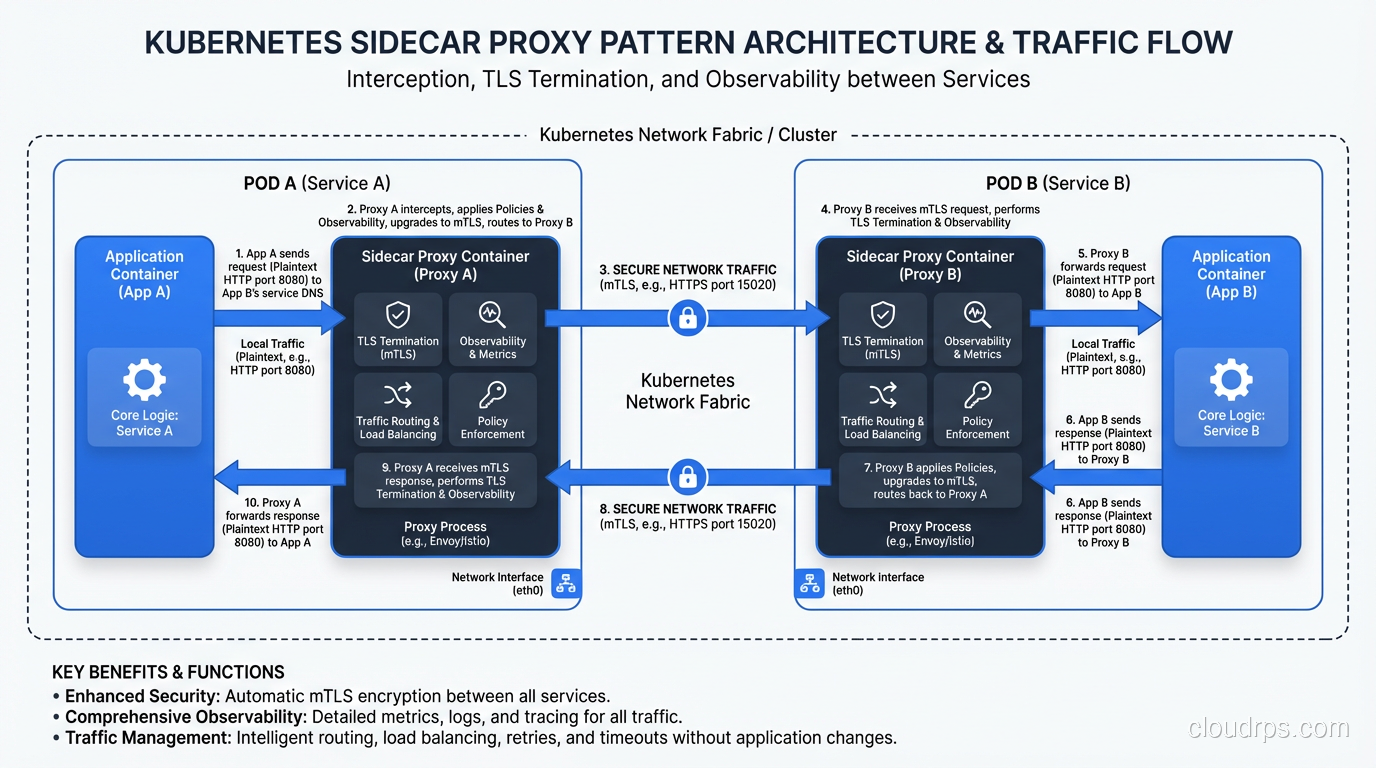
Your application code has zero awareness this is happening. That is both the beauty and the danger of the sidecar pattern. It is beautifully transparent, but it also means you have a proxy in every single pod consuming memory and CPU. In a cluster with 500 pods, that is 500 extra containers running. We will come back to this resource cost later because it matters more than most vendors want to admit.
If you want a refresher on the networking layers these proxies operate on, check out Layer 4 vs Layer 7. Service mesh proxies are almost always Layer 7 aware, which means they understand HTTP headers, gRPC metadata, and can make routing decisions based on actual request content.
Istio Deep Dive: The Feature-Rich Heavyweight
Istio is the 800-pound gorilla of service meshes. Backed by Google, IBM, and Lyft (which originally created the Envoy proxy that Istio uses), it has the largest feature set and the largest community. It is also the most complex.
Envoy Proxy: The Engine Under the Hood
Istio’s data plane runs on Envoy, a high-performance C++ proxy originally built at Lyft. Envoy is a legitimate engineering marvel. It handles L4/L7 traffic, supports HTTP/1.1, HTTP/2, gRPC, and TCP, and has an extensible filter chain that lets you plug in custom logic. Envoy is the reason Istio can do things like header-based routing, fault injection, and traffic mirroring.
Traffic Management
This is where Istio really shines. You can do things like:
Canary deployments: Route 5% of traffic to a new version of a service while keeping 95% on the stable version. Increase the percentage gradually as confidence grows.
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: payment-service
spec:
hosts:
- payment-service
http:
- route:
- destination:
host: payment-service
subset: v1
weight: 95
- destination:
host: payment-service
subset: v2
weight: 5
Traffic mirroring: Send a copy of production traffic to a shadow service for testing without affecting real users. This is incredibly powerful for validating new versions against real-world traffic patterns.
Fault injection: Deliberately inject delays or errors to test how your system handles failures. Remember that cascade failure I mentioned earlier? With Istio’s fault injection, we could have simulated that exact scenario in staging and discovered our retry amplification problem before it hit production.
Header-based routing: Route requests to different service versions based on HTTP headers. Useful for A/B testing or routing internal team traffic to pre-release versions.
The Complexity Tax
Here is the honest truth: Istio is complicated. The learning curve is steep. The configuration surface area is enormous. I have seen teams spend months getting Istio properly configured, only to discover they were using maybe 20% of its features. The Istio control plane itself (istiod) needs to be properly resourced and monitored. You are adding a significant piece of infrastructure that needs its own care and feeding.
Istio has gotten simpler over the years. The move to a single istiod binary (replacing the old Pilot, Mixer, Citadel architecture) was a big improvement. And the newer “ambient mesh” mode removes the sidecar requirement entirely, using node-level proxies instead. But it is still the most operationally demanding option in this space.
Linkerd Deep Dive: The Lightweight Contender
Linkerd takes a fundamentally different philosophical approach. Where Istio says “here is every feature you could ever want,” Linkerd says “here are the features you actually need, and they should just work.”
The Rust Proxy: linkerd2-proxy
Linkerd’s secret weapon is its purpose-built proxy written in Rust. Unlike Envoy (which is a general-purpose proxy that Istio configures for service mesh use), linkerd2-proxy was designed from the ground up specifically for the service mesh use case. This means it is dramatically smaller, faster, and uses less memory.
In my benchmarks on production workloads, Linkerd’s proxy used roughly 1/10th the memory of Envoy sidecars. For a cluster with hundreds of pods, that adds up to real savings. The tail latency (p99) was also noticeably lower with Linkerd.
Simplicity as a Feature
Linkerd made deliberate choices to keep things simple:
- Installation takes about 60 seconds with the CLI. Seriously.
linkerd install | kubectl apply -f -and you are running. - The default configuration is production-ready. mTLS is on by default. Reasonable timeouts are preconfigured. You do not need to become a YAML expert to get value.
- The dashboard gives you golden metrics (success rate, latency, request volume) for every service immediately after installation.
- The documentation is excellent and does not assume you already understand service mesh concepts.
What Linkerd Does Well
Automatic mTLS: The moment you mesh a service, all communication is encrypted with mutual TLS. No configuration required. Certificate rotation is handled automatically. For teams pursuing zero trust networking, this is a huge win because it means workload identity and encrypted communication come for free.
Reliability features: Retries, timeouts, and load balancing just work. Linkerd uses a clever EWMA (exponentially weighted moving average) algorithm for load balancing that routes traffic away from slow instances automatically.
Observability: Linkerd gives you per-route success rates and latency percentiles without any application instrumentation. This pairs extremely well with your existing monitoring and logging infrastructure. If you already have Prometheus and Grafana, Linkerd plugs right in.
What Linkerd Does Not Do
Linkerd intentionally does not support some things that Istio does:
- No traffic mirroring
- No fault injection
- Limited traffic splitting (basic weighted routing only, no header-based routing)
- No support for non-Kubernetes environments
- No custom Wasm extensions
For many teams, this is actually fine. You are trading features you might never use for simplicity you benefit from every day.
Istio vs Linkerd: An Honest Comparison
I have deployed both in production environments. Here is my practical take:
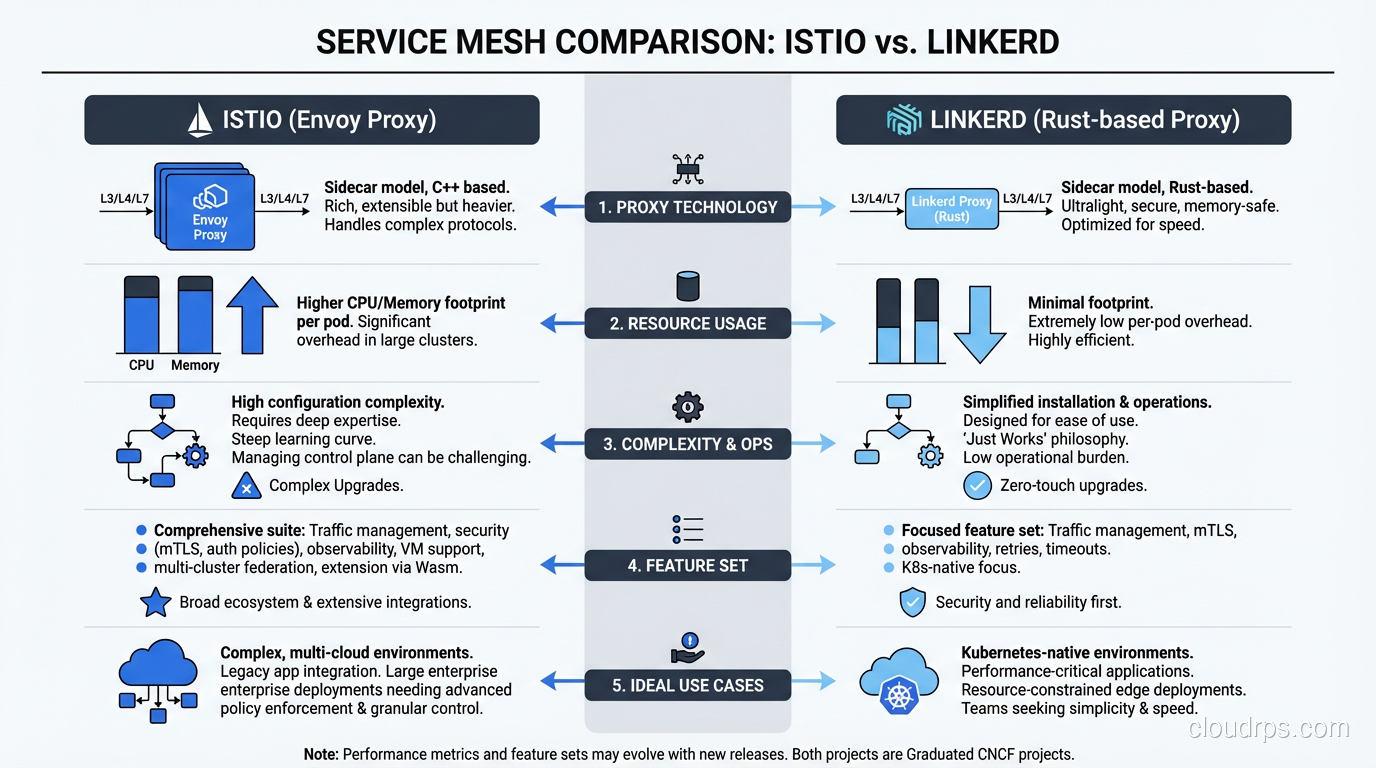
Resource consumption: Linkerd wins here by a significant margin. In a 200-pod cluster, Linkerd’s proxies used around 20MB of memory each versus Envoy’s 60-150MB. Over hundreds of pods, that difference matters.
Latency overhead: Both add latency since traffic now passes through an extra proxy hop. Linkerd’s p99 overhead was roughly 1-2ms in my tests. Istio/Envoy was closer to 3-5ms. For most applications this is negligible, but for latency-sensitive workloads it is worth considering.
Operational complexity: Linkerd is dramatically easier to operate day-to-day. Upgrades are smoother. There are fewer knobs to turn, which means fewer knobs to turn incorrectly. My team could onboard a new engineer to Linkerd in a day. Istio took a week or more.
Feature richness: Istio wins here, no question. If you need traffic mirroring, fault injection, or complex routing rules based on headers or query parameters, Istio is your option. Linkerd deliberately chose not to implement these.
Community and ecosystem: Istio has a larger community and broader vendor support. It is a CNCF graduated project. Linkerd is also a CNCF graduated project but has a smaller ecosystem. Both are mature and production-ready.
My recommendation: Start with Linkerd unless you have a specific feature requirement that only Istio provides. You can always migrate to Istio later if you outgrow Linkerd. Going the other direction (Istio to Linkerd) is much rarer but equally possible.
mTLS and Zero Trust: The Security Story
One of the strongest arguments for a service mesh is mutual TLS (mTLS). In a traditional Kubernetes cluster, traffic between pods travels unencrypted over the cluster network. Anyone who compromises a single pod can potentially sniff traffic between other services. This is a real threat, not a theoretical one.
Both Istio and Linkerd handle mTLS, but they approach it differently.
Linkerd enables mTLS by default for all meshed traffic. There is nothing to configure. When you add a service to the mesh, its traffic is automatically encrypted. Certificates are issued by the Linkerd control plane and rotated automatically. The proxy handles TLS termination and initiation transparently.
Istio also supports automatic mTLS but gives you more control. You can set strict mode (only mTLS allowed) or permissive mode (accept both plain and mTLS traffic). This flexibility is useful during migration when not all services are meshed yet, but it also means you have to be intentional about locking things down.
Beyond encryption, both meshes provide workload identity. Each service gets a cryptographic identity (typically a SPIFFE identity) that can be used for authorization policies. Instead of relying on network-level controls (which IP is this request from?), you can write policies based on service identity (is this request from the payment service?).
This is a fundamental building block of zero trust architecture. Rather than trusting traffic because it originated inside your network perimeter, you verify the identity of every request. If you are working toward zero trust, a service mesh is one of the most practical ways to get there. For a deeper discussion on the principles, see my article on zero trust security models.
When You Actually Need a Service Mesh (and When You Don’t)
After deploying service meshes for multiple organizations, I have developed a pretty clear sense of when they provide real value versus when they add unnecessary complexity.
You Probably Need a Service Mesh If:
You have 20+ microservices and growing. Below this threshold, you can often handle service-to-service concerns in application code or with simpler tools. Above it, the consistency and observability benefits start to justify the overhead.
You need mTLS across all service communication. If compliance or security requirements mandate encrypted internal traffic, a service mesh is by far the easiest way to achieve this. Doing it manually across dozens of services is painful and error-prone.
You are struggling with observability. If debugging a request that spans multiple services requires correlating logs from five different dashboards, a service mesh’s built-in distributed tracing and golden metrics will save you hours per incident.
You need traffic management for safe deployments. Canary deployments, traffic splitting, and gradual rollouts are much easier with a service mesh than with custom Kubernetes configurations.
You are pursuing zero trust networking. Service meshes provide workload identity and authorization policies that are foundational to zero trust.
You Probably Don’t Need a Service Mesh If:
You have fewer than 10 services. The operational overhead of running and maintaining a service mesh outweighs the benefits at this scale. Use a service mesh when the pain of not having one is real, not when you anticipate future pain.
Your team is small and already stretched thin. A service mesh adds operational surface area. If you are a team of three engineers already struggling to keep the lights on, adding a mesh will make things worse before it makes things better.
Your services mostly communicate asynchronously. If your architecture is primarily event-driven (services communicate through message queues or event streams rather than synchronous HTTP/gRPC calls), a service mesh provides less value. It is designed for request-response communication patterns.
You are not on Kubernetes. While Istio technically supports VMs, both meshes are primarily designed for Kubernetes. If you are running on VMs, ECS, or bare metal, the integration story is much weaker. You might want to explore other approaches to service networking first.
You just want the resume bullet point. I have seen this more than I would like. Engineers push for Istio because it looks impressive, not because the organization needs it. Please don’t do this. Architecture decisions should be driven by actual problems.
Beyond Sidecars: The Ambient Mesh Evolution
Both Istio and Linkerd are evolving beyond the traditional sidecar model, though in different directions.
Istio’s “ambient mesh” mode is the most significant architectural shift in this space. Instead of injecting a sidecar into every pod, ambient mesh uses shared node-level proxies (called ztunnels) for L4 processing and optional per-service “waypoint proxies” for L7 features. This dramatically reduces resource consumption and removes the need for sidecar injection entirely. As of 2026, ambient mesh is production-ready and becoming the recommended deployment model for new Istio installations. Much of this sidecarless evolution is powered by eBPF, which enables kernel-level networking and observability without the overhead of userspace proxies in every pod.
Linkerd has taken a different approach, focusing on making their existing sidecar proxy so lightweight that the resource argument largely disappears. With proxy memory usage under 20MB and sub-millisecond latency overhead, the Linkerd team argues that the sidecar model still makes sense because it provides better isolation and security boundaries than shared node-level proxies.
Both approaches have merit. Ambient mesh reduces resource waste but introduces shared failure domains. Lightweight sidecars maintain isolation but still add per-pod overhead. My advice: evaluate based on your specific constraints rather than assuming one approach is universally better.
Practical Advice From Someone Who Has Done This
If you have read this far and decided a service mesh is right for you, here are a few hard-won lessons:
Start with observability, not traffic management. The quickest win from a service mesh is visibility into your service-to-service communication. Get that golden metrics dashboard running first. You will immediately see value and build organizational confidence in the mesh.
Mesh incrementally, not all at once. Both Istio and Linkerd support gradual adoption. Start with your least critical services. Get comfortable with the operational model. Then expand to production-critical services once your team is confident.
Monitor the mesh itself. Your service mesh is now critical infrastructure. If the control plane goes down, certificate rotation stops and new proxy configurations do not propagate. Treat it with the same care as your database or your Kubernetes control plane.
Budget for the resource overhead. Sidecar proxies consume CPU and memory. Plan for this in your capacity planning. I typically budget an additional 10-15% cluster capacity for the mesh.
Keep your networking fundamentals solid. A service mesh does not replace understanding how networking works. It builds on top of that foundation. If your team is shaky on DNS, TCP, or how network protocols work, invest in that education before adopting a mesh.
Wrapping Up
Service meshes solve real problems, but they are not free. They add operational complexity, consume resources, and require teams to learn new tooling. The question is never “is a service mesh good?” It is always “does the value outweigh the cost for my specific situation?”
For most teams running a meaningful number of microservices on Kubernetes, the answer is increasingly yes. The observability, security, and traffic management capabilities are genuinely hard to replicate otherwise. And with tools like Linkerd making the barrier to entry lower than ever, the cost-benefit math keeps tilting in favor of adoption.
If I were starting fresh today with a growing microservice architecture, I would install Linkerd on day one for the mTLS and observability alone. If I later needed advanced traffic management features like mirroring or fault injection, I would evaluate whether to add those through Istio or through other tools in the ecosystem. That pragmatic, incremental approach has served me well, and I think it will serve you well too.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.