In 2006, I was working at a financial services firm where our services communicated by passing around shared API keys hardcoded in config files checked into CVS. We had a single secrets.properties file that got copied onto every application server by hand. Everyone who had ever worked there had a copy on their laptop. When someone left, we’d change the keys and spend three days updating every server. It was embarrassing then.
What I see in 2026 looks different on the surface but is the same problem underneath. Kubernetes Secrets mounted as environment variables. AWS credentials in Helm values files. Database passwords stuffed into Vault with a human-generated token that never rotates. The wrapper changes; the underlying question does not: how does a workload prove who it is to another workload without a human handing over a credential at some point in the chain?
The answer that the industry has been converging on for the last several years is SPIFFE, the Secure Production Identity Framework for Everyone, and its reference implementation SPIRE, the SPIFFE Runtime Environment. Both are CNCF graduated projects, which means they have passed the bar for production maturity that the Cloud Native Computing Foundation sets. Istio uses SPIFFE internally. HashiCorp Vault has native SPIFFE integration. Linkerd uses it. If you have deployed a service mesh, you are probably already using SPIFFE without knowing it.
What most teams are missing is running SPIFFE directly, outside of a service mesh abstraction, to solve the broader problem of service-to-service identity across their entire infrastructure: VMs, bare metal, Kubernetes clusters, cloud providers, and now AI agents.
The Credential Sprawl Problem
Before getting into the architecture, it helps to be precise about what problem we are actually solving.
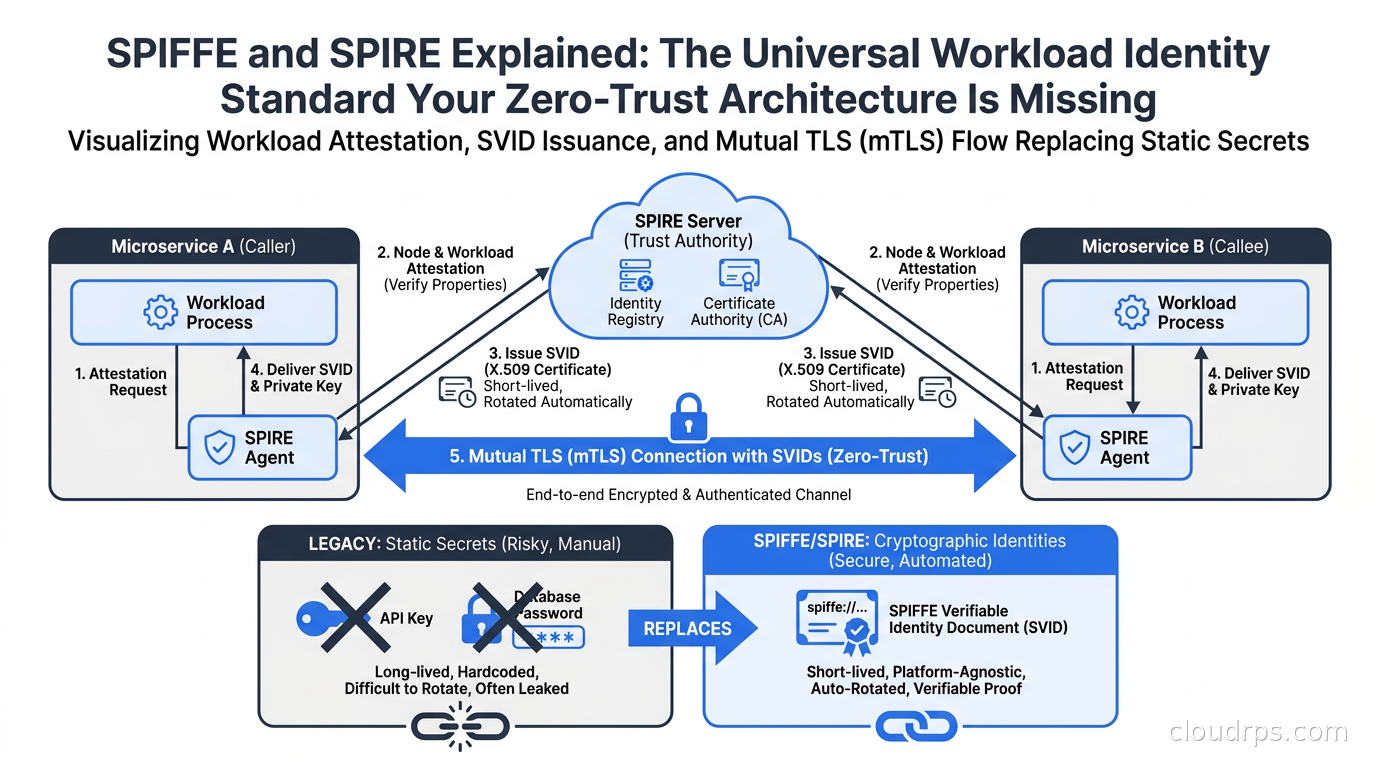
When service A needs to call service B, it needs to authenticate. The traditional approach is to give service A a secret: an API key, a password, a token. That secret has to come from somewhere. Someone generates it, stores it somewhere, and then gets it into service A’s environment. This is credential provisioning, and it is the source of most real-world security incidents.
The SPIFFE threat model says: instead of giving a workload a secret it has to protect, give it a cryptographic identity it proves by virtue of where and what it is. The workload presents a certificate that says “I am the payment service running in production on cluster us-east-1.” The certificate is signed by a trusted authority. The receiver verifies the certificate chain. Nobody had to hand over a password.
This sounds simple. The hard part is answering the question: how does the infrastructure know that the entity asking for a certificate really is the payment service in production? That is the attestation problem, and it is where most of the interesting engineering in SPIFFE happens.
The SPIFFE Standard: Identity as a URI
SPIFFE defines a standard for workload identity, not a specific product. The core concept is the SPIFFE ID, a URI with a specific format:
spiffe://trust-domain/path/to/workload
The trust domain is typically your organization or cluster: spiffe://payments.company.com or spiffe://prod.k8s.internal. The path identifies the specific workload: /services/payment-api/v2 or /ns/payments/sa/payment-service. You define the path structure to match your organization.
The SPIFFE ID lives inside a document called an SVID, a SPIFFE Verifiable Identity Document. There are two formats: X.509-SVID and JWT-SVID.
X.509-SVIDs are standard X.509 certificates with the SPIFFE ID embedded in the Subject Alternative Name field. They are the preferred format because they enable mutual TLS with no additional protocol overhead. When service A connects to service B over mTLS, both sides present their X.509-SVID, both sides verify the certificate chain back to the trust anchor, and both sides know exactly who they are talking to. The connection itself authenticates both parties.
JWT-SVIDs are JSON Web Tokens signed by the SPIRE Server’s key. They are useful when mTLS is impractical: for example, when an HTTPS load balancer terminates TLS before your service, or when you are calling a third-party API that does not speak mTLS. The JWT carries the SPIFFE ID as the subject claim and an audience claim scoped to the specific service being called, which prevents token replay across services.
The default TTL for SVIDs is one hour. SPIRE rotates them automatically, which means you never have long-lived credentials sitting in your environment. If an SVID is compromised, it expires quickly. Compare that to a static API key that a developer generates and never rotates for three years.
SPIRE: The Reference Implementation
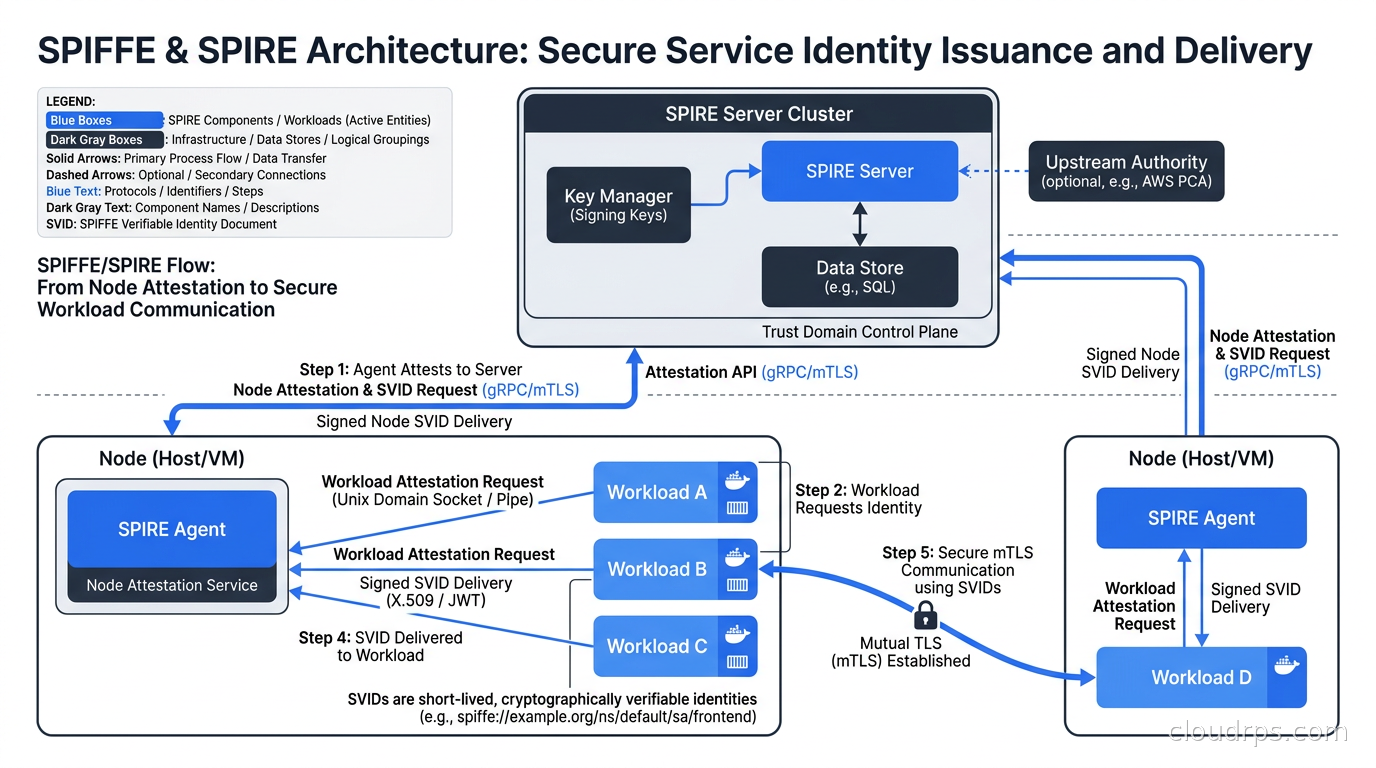
The SPIFFE specification describes the standard. SPIRE is the production implementation. It has two components: the SPIRE Server and the SPIRE Agent.
The SPIRE Server is the certificate authority. It holds the signing keys, maintains a database of registration entries (which SPIFFE IDs should be issued to which workloads), federates with other trust domains, and exposes an API that agents use to get SVIDs issued. In production, you run multiple SPIRE Server instances backed by a shared PostgreSQL database for high availability. The signing key should live in a cloud KMS (AWS KMS, GCP Cloud KMS, Azure Key Vault) or an HSM, not on the server’s local disk.
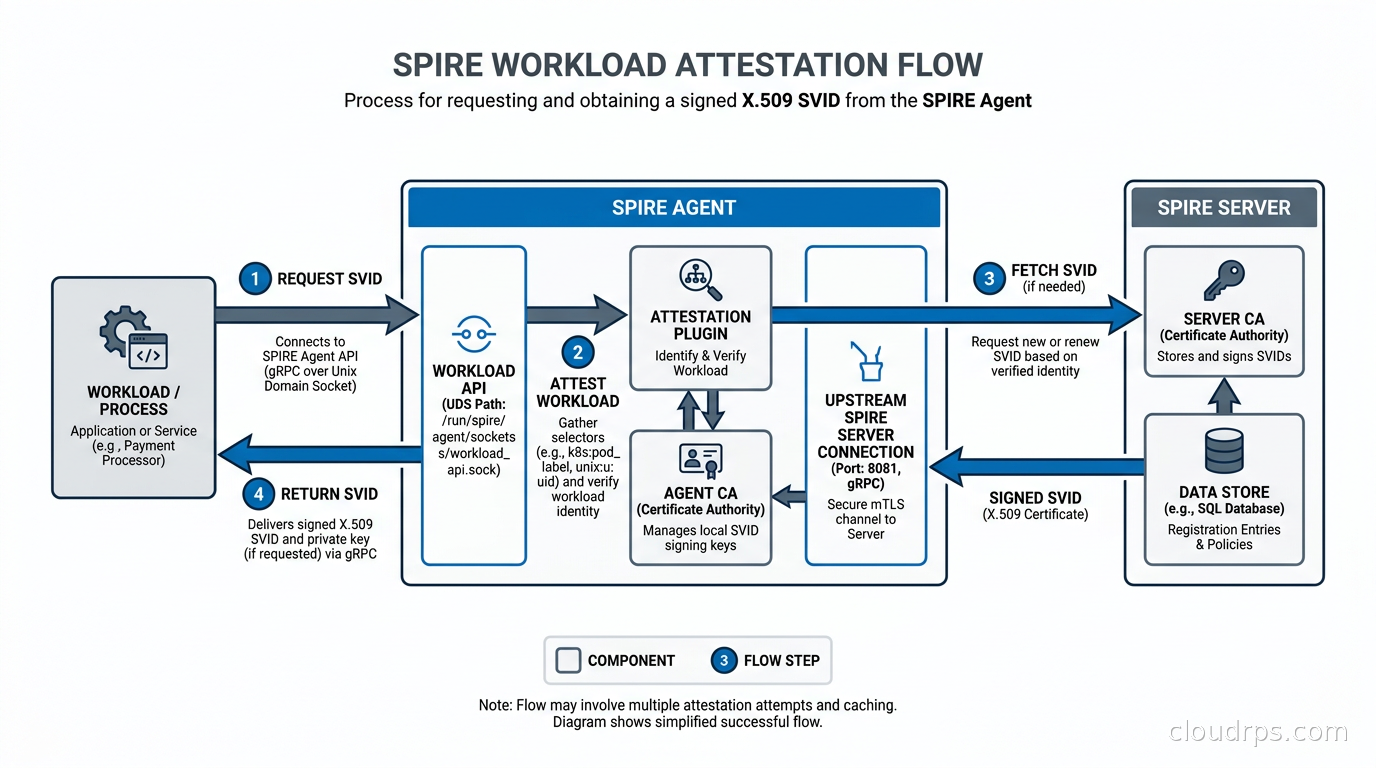
The SPIRE Agent runs on every node in your infrastructure: every Kubernetes node, every VM, every bare-metal host. Its job is to talk to local workloads via a Unix domain socket, attest their identity, fetch the right SVID from the Server, and cache it locally so workloads do not hammer the Server for every request. The Workload API is the Unix socket interface that workloads use to get their SVIDs. SPIRE implements the gRPC Workload API specification, and there are client libraries for Go, Python, Java, and most other languages you might care about.
The separation matters. The SPIRE Server never talks to workloads directly. The SPIRE Agent is the local broker. If a workload is compromised and tries to impersonate a different workload, the Agent’s attestation logic catches it. If the Agent itself is compromised, the blast radius is limited to the node where it runs, not the entire trust domain.
Attestation: How SPIRE Knows Who You Are
Attestation is the mechanism by which SPIRE verifies identity claims. There are two phases: node attestation and workload attestation.
Node attestation answers: is this SPIRE Agent running on a legitimate node? The Agent presents evidence about the node to the Server, and the Server verifies it using an attestor plugin. On AWS, the node attestor uses the EC2 instance identity document, a signed JSON blob that AWS provides to every EC2 instance via the metadata service. The SPIRE Server calls the EC2 API to verify the document and confirm the instance is really in your account. On GCP, it uses the GCE instance identity token. On Kubernetes, it uses the node’s service account token. On bare metal, you can use TPM attestation, where the node presents a cryptographic proof tied to its hardware TPM chip.
Once the node is attested, the Agent is trusted to attest workloads on that node.
Workload attestation answers: which SVID should this specific process get? When a process opens the Workload API socket and requests a SVID, the Agent interrogates the process using workload attestor plugins. The Unix attestor looks at the process’s PID, UID, and GID from the OS. The Kubernetes attestor queries the local kubelet API to find which pod the process is running in, then checks the pod’s namespace, service account, and labels. The Docker attestor inspects the container’s image hash and labels.
The attestation results are matched against registration entries in the SPIRE Server. A registration entry is a rule that says: any process with these selector values should receive this SPIFFE ID. For example:
Parent ID: spiffe://prod/k8s/node/us-east-1a
SPIFFE ID: spiffe://prod/services/payment-api
Selectors: k8s:ns:payments, k8s:sa:payment-service
This says: any workload running in the payments namespace with the payment-service service account on an attested node gets the SPIFFE ID spiffe://prod/services/payment-api. The Agent verifies the namespace and service account from the kubelet. No human had to hand the payment service a credential. It proves its identity by where it is running.
SPIFFE Federation: Identity Across Clusters and Clouds
Single-cluster SPIFFE is useful. Multi-cluster SPIFFE is where the architecture gets genuinely powerful.
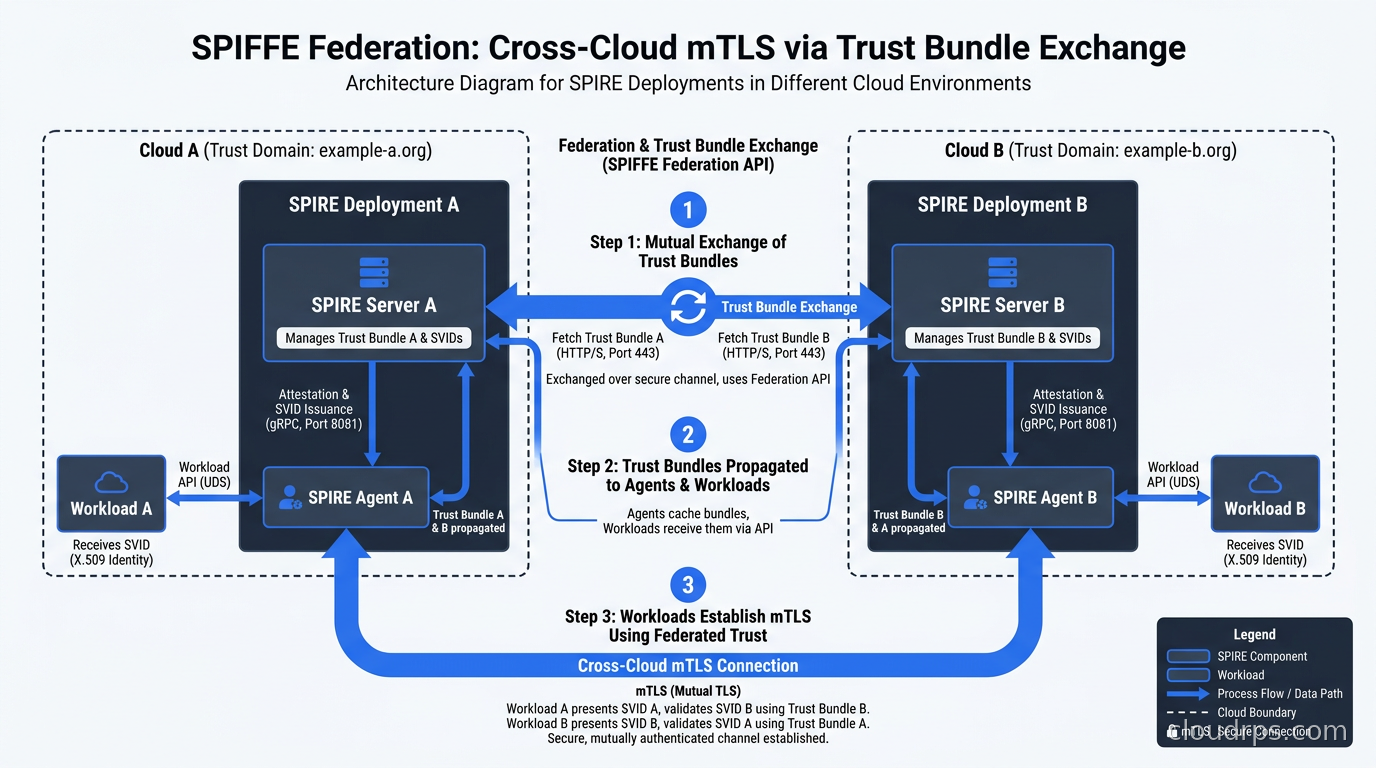
In a realistic production environment in 2026, you have multiple Kubernetes clusters across multiple cloud providers, probably some VMs in a colocation facility, and maybe some on-premises workloads behind a Direct Connect or ExpressRoute link. Each cluster might have its own SPIRE deployment and its own trust domain. The question is: how does a service in spiffe://aws-prod trust a certificate from spiffe://gcp-prod?
The answer is SPIFFE federation. Each SPIRE Server exposes a bundle endpoint, an HTTPS endpoint that publishes its trust bundle (the set of public keys needed to verify SVIDs from that trust domain). When you configure federation between two trust domains, each SPIRE Server periodically fetches the other’s trust bundle and caches it. Now when a service in AWS presents its certificate to a service in GCP, the GCP-side verifier can check the certificate against the AWS trust bundle it fetched and confirm the identity.
This is the primitive that makes true multi-cloud zero trust security work without a shared secrets manager or a central identity provider that becomes a single point of failure. Federation is point-to-point between trust domains, and each domain controls what it trusts. You can federate with a partner organization’s SPIRE deployment and issue temporary identities for cross-organizational API access with no password exchange at all.
For teams running their own service mesh, SPIRE can serve as the upstream certificate authority. You configure Istio’s cert-manager to use the SPIRE Server’s CA instead of Istio’s built-in CA. Now all the mTLS certificates Istio issues for your pods carry SPIFFE IDs and are part of your unified identity system, rather than an Istio-internal PKI that does not interoperate with anything outside the mesh. For services outside the mesh that still need TLS, combining SPIRE with cert-manager and an internal CA gives you a complete certificate lifecycle story: SPIFFE SVIDs for pod-to-pod mTLS and cert-manager for explicit service certificates, both rooted in the same trust hierarchy.
SPIFFE for AI Agents: The 2026 Use Case
One of the most relevant developments in 2026 is the application of SPIFFE to non-human identities beyond traditional microservices: specifically, AI agents.
I have spent the last year working with teams building agentic AI systems in production. The identity problem shows up immediately. An AI agent needs to call a database, query an internal API, write to blob storage. How does it authenticate? The naive answer is: give it a service account key or an API token. That works for exactly one cluster in one cloud provider. The moment your agent spans environments, you are back to the credential distribution problem.
HashiCorp Vault has published guidance on using SPIFFE for AI agent identity. The approach is exactly what you would expect: the agent runtime (KubeRay, Temporal, a custom container) is attested by SPIRE just like any other workload. It gets a SPIFFE ID: spiffe://prod/agents/customer-support-v2. That SPIFFE ID maps to permissions in Vault via Vault’s SPIFFE auth method. The agent calls Vault to get a short-lived database token, never handling a long-lived credential.
When securing AI agents against prompt injection and tool misuse, the identity layer matters enormously. If an agent can only call the tools its SPIFFE ID is authorized to call, and that authorization is enforced by a cryptographically verified identity, the blast radius of a compromised or hijacked agent is dramatically reduced. An agent cannot suddenly start calling the billing API if its SPIFFE-based authorization does not include it.
The same logic applies to CI/CD pipelines. GitHub Actions OIDC is a form of workload identity, and it works well for AWS and GCP. But for multi-cloud pipelines or self-hosted runners, SPIFFE gives you a universal mechanism that is not tied to any cloud provider’s identity system. You can read more about the cloud-provider-specific approaches in our workload identity federation article, but SPIFFE fills the gap where those approaches stop working.
SPIRE vs. Cloud-Native Workload Identity
I get this question on every engagement: “We already have IRSA for EKS and GKE Workload Identity. Why would we add SPIRE?”
The honest answer: if you are running a single Kubernetes cluster on a single cloud provider and your services only talk to other services in that cluster and that cloud’s managed services, the cloud-native workload identity system is probably sufficient. IRSA for EKS, GKE Workload Identity, and Azure Workload Identity are simpler to operate and are managed by the cloud provider. They are the right choice for most single-cloud, single-cluster deployments.
SPIRE earns its operational overhead when:
You run services across multiple Kubernetes clusters and need those services to authenticate to each other without a shared secrets manager in between. Federation solves this cleanly.
You have workloads on VMs or bare metal alongside Kubernetes. Cloud-native workload identity only covers workloads running in the managed Kubernetes control plane. SPIRE covers everything.
You need to issue identities to AI agents or other non-Kubernetes workloads that need to authenticate across your entire infrastructure, not just to a specific cloud’s services.
You have on-premises workloads behind a hybrid cloud connection that need to participate in your zero-trust network without cloud-native identity systems.
You need secret management that is not vendor-specific. HashiCorp Vault’s SPIFFE auth method works identically across AWS, GCP, Azure, and bare metal. Your secret retrieval logic does not change when you add a new cloud.
Deploying SPIRE in Production
SPIRE is infrastructure, and like all infrastructure, it requires operational discipline.
The SPIRE Server needs to be highly available. Run at least three instances behind a load balancer, backed by a PostgreSQL or MySQL database. The Server instances share no state other than the database, so scaling out is straightforward. Protect the CA private key with a cloud KMS or HSM. A compromised CA key compromises every SVID in your trust domain.
The SPIRE Agent is a DaemonSet in Kubernetes: one Agent pod per node, with hostPath mounts to access the node’s Kubernetes API and expose the Workload API socket to pods. On VMs, it runs as a systemd service. The Agent is stateless between restarts except for the cache: it will re-attest from scratch on restart, which means the SPIRE Server must be reachable at startup.
For the management plane, the SPIRE team maintains Tornjak, an open-source UI for managing SPIRE Server registration entries and viewing issued SVIDs. It is not required but it makes debugging attestation issues significantly less painful. Without it, you are running spire-server entry show from the command line, which works but does not scale to large registration entry sets.
Monitor your SVID rotation failure rate. If the Agent cannot reach the Server to rotate SVIDs, workloads will start failing when their cached SVIDs expire. Treat SPIRE Agent connectivity to the SPIRE Server as a critical path, the same way you treat DNS resolution. The TLS certificate chain that underpins your entire zero-trust fabric fails silently if rotation stops working, and you will not know until services start rejecting each other’s certificates.
For Kubernetes RBAC, the SPIRE Agent DaemonSet needs specific permissions to talk to the kubelet API for workload attestation. Get these wrong and attestation fails for all pods on the node. The SPIRE Helm charts handle this correctly; if you are writing your own manifests, review the required ClusterRole and ServiceAccount configuration carefully.
The Bigger Picture
The core insight behind SPIFFE is not new: identity should be tied to cryptographic proof, not secrets. PKI has worked this way for decades. What SPIFFE adds is a standard for doing this in dynamic, ephemeral, polyglot infrastructure where workloads spin up and down constantly and the set of services changes faster than any PKI administrator could manually issue certificates.
After twenty years of watching security incidents unfold, the ones that hurt the most are not the sophisticated zero-day exploits. They are the cases where an attacker found a static secret in a config file, in a Git commit, in an environment variable exposed by a misconfigured metrics endpoint, and used it to move laterally for weeks before anyone noticed. SPIFFE does not prevent every attack, but it eliminates the class of attacks that start with credential theft. You cannot steal a secret that does not exist.
The infrastructure ecosystem has voted: SPIFFE is the workload identity standard. Istio runs on it. Linkerd runs on it. The CNCF has graduated it. HashiCorp has integrated it into Vault. The question is not whether to adopt it. The question is how quickly you migrate from static credentials to cryptographic identity, and whether you do it proactively or after an incident forces your hand.
In my experience, the teams that wait for an incident to force the migration always wish they had done it sooner.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.