In 2010, I sat in a conference room and listened to a startup’s CTO explain why they had chosen MongoDB for their entire platform. “SQL doesn’t scale,” he said, with the conviction of someone who had read a blog post and confused it with engineering experience. Two years later, I was hired to help them migrate their core transaction processing back to PostgreSQL after they spent eighteen months fighting MongoDB to do something it was never designed to do.
That story is not unique. I have seen the same mistake play out in the opposite direction too, with teams forcing a relational database into a role where a document store or key-value database would have been dramatically simpler and more effective. The SQL vs NoSQL debate has produced more bad decisions than almost any other architectural discussion in my career, and the root cause is almost always the same: people pick a database based on vibes instead of understanding the actual architecture and trade-offs.
Let me try to fix that.
What “SQL” Actually Means Architecturally
When people say “SQL database,” they are referring to relational database management systems: PostgreSQL, MySQL, Oracle, SQL Server, and their kin. The defining characteristic is not the query language (though SQL is part of it). It is the relational model: data is organized into tables with defined schemas, rows represent individual records, and relationships between tables are expressed through foreign keys and enforced by the database engine.
The Power of the Relational Model
The relational model gives you something that is genuinely hard to replicate in other paradigms: the ability to query your data in ways you did not anticipate when you designed the schema. Because the data is normalized (broken into related tables with well-defined relationships) you can join tables in novel combinations to answer questions that nobody thought to ask when the system was built.
I worked on a healthcare analytics platform in 2016 where the original designers had structured patient records, diagnoses, treatments, and outcomes in a properly normalized relational schema. Five years later, the analytics team was running queries that combined data across seven tables in ways the original architects never imagined. The relational model made this possible without any schema changes.
This flexibility comes from ACID guarantees, the transactional properties that ensure your data remains consistent even under concurrent access and system failures. When you transfer money between accounts, you need the guarantee that both the debit and the credit either happen together or not at all. Relational databases have provided this guarantee reliably for decades.
Where Relational Databases Hit Walls
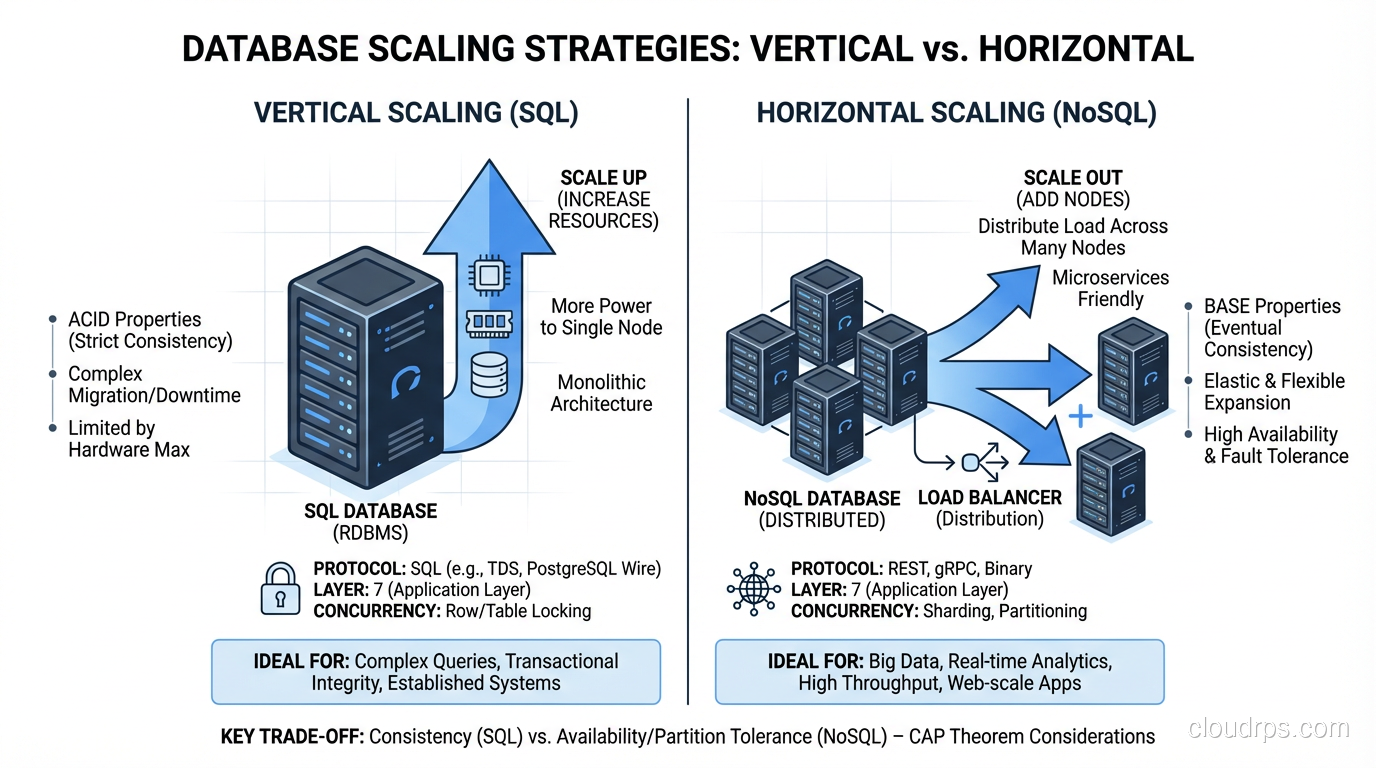
The relational model’s strength (normalization and joins) becomes a weakness at extreme scale. Joining tables requires the database to read from multiple locations and combine the results. When those tables have billions of rows and the join involves data spread across multiple physical machines, the performance cost can be prohibitive.
Scaling a relational database horizontally (spreading it across multiple servers) is genuinely hard. You can read-replicate relatively easily, but distributing writes across multiple nodes while maintaining ACID guarantees is one of the hardest problems in distributed systems. This is the fundamental tension described by the CAP theorem, and it is why companies like Google and Amazon built their own non-relational systems.
Schema rigidity is the other friction point. Every row in a relational table must conform to the defined schema. Adding a column requires an ALTER TABLE operation, which on a large table can be slow and lock-intensive. If your data model is evolving rapidly (as it does in early-stage products) this rigidity can slow development down.
What “NoSQL” Actually Covers
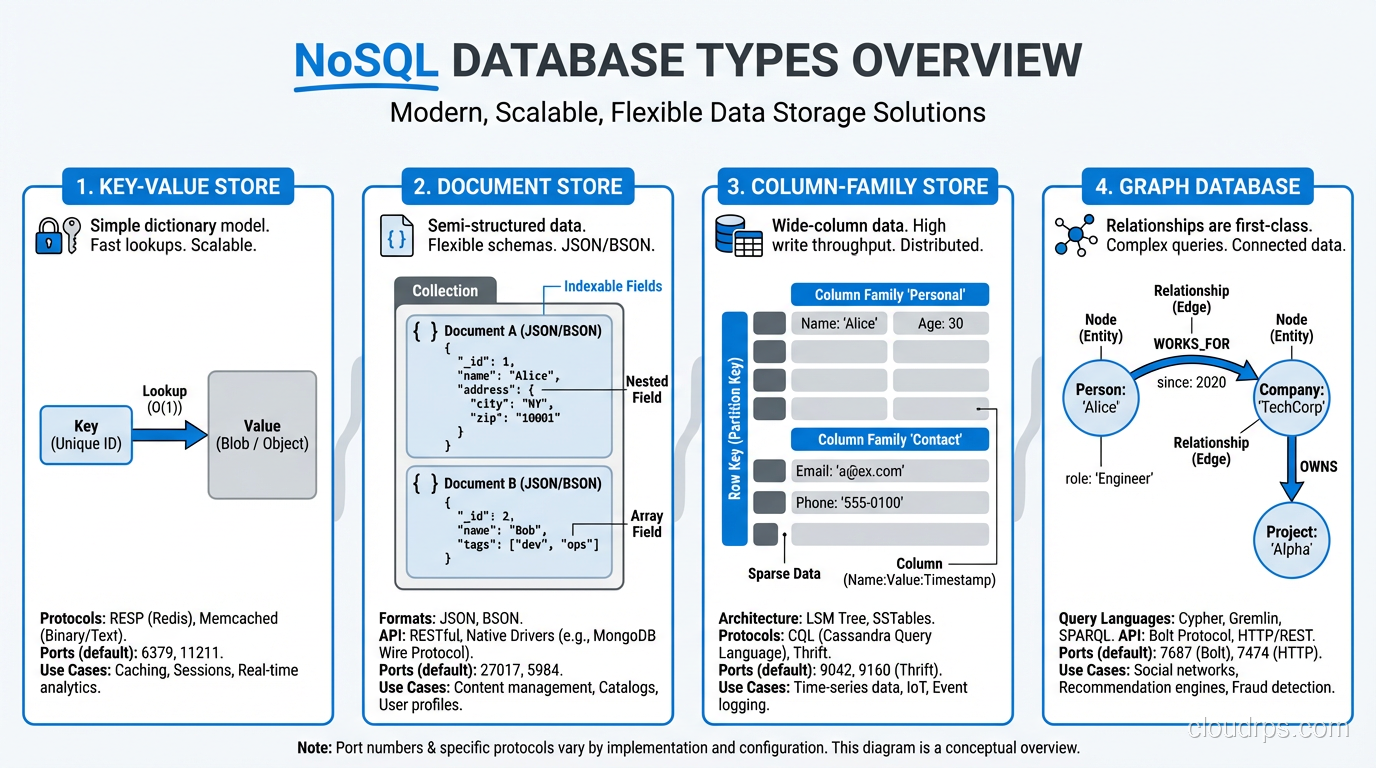
NoSQL is not a single thing. It is an umbrella term for databases that do not use the relational model. This includes at least four fundamentally different architectures, and lumping them together is like saying “non-car vehicles” and expecting that to be a useful category.
Document Databases
MongoDB, CouchDB, and their descendants store data as JSON-like documents. Each document is a self-contained unit that can contain nested objects, arrays, and varying fields. There is no fixed schema enforced by the database, though you can add validation rules.
Document databases excel when your data is naturally hierarchical and self-contained. A product catalog where each product has a different set of attributes. A content management system where articles have varying structures. User profiles where different users have different fields.
The killer feature is that you can read an entire entity in a single operation. No joins required. A product document contains its name, description, pricing, variants, images, and reviews all in one place. For read-heavy applications that access data by its primary key, this is enormously efficient.
Key-Value Stores
Redis, DynamoDB, and similar systems store data as simple key-value pairs. You look up data by its key, and you get back a value. The database does not know or care what the value contains; it is just bytes.
Key-value stores are the fastest NoSQL pattern. Sub-millisecond reads for known keys. They are ideal for caching, session storage, configuration data, and any workload where you always know exactly what you are looking for.
Column-Family Stores
Cassandra and HBase organize data into rows and columns, but unlike relational tables, each row can have a different set of columns. Data is stored column-by-column rather than row-by-row, which makes them extremely efficient for time-series data and analytical queries that read specific columns across many rows.
Graph Databases
Neo4j and similar systems store data as nodes and edges (entities and relationships). They are optimized for traversing relationships, which makes them powerful for social networks, recommendation engines, fraud detection, and any domain where the connections between entities are as important as the entities themselves.
The Trade-offs That Actually Matter
Forget the marketing. Here is what actually differs between SQL and NoSQL databases in production.
Schema Flexibility vs Data Integrity
NoSQL gives you schema flexibility. You can store documents with different structures in the same collection. You can add fields without modifying existing data. This is genuinely useful during early product development when the data model is unstable.
But schema flexibility means the burden of data integrity shifts from the database to your application code. I cannot tell you how many times I have debugged NoSQL applications where “schema-less” actually meant “schema spread across seventeen different microservices, each with its own assumptions about what fields exist.” At scale, this becomes a maintenance nightmare.
Relational databases enforce the schema, which means the database itself guarantees that your data conforms to your model. Constraints, foreign keys, check constraints, unique indexes: these are not annoyances, they are your data quality safety net. I have never regretted having a foreign key constraint. I have frequently regretted not having one.
Joins vs Denormalization
Relational databases normalize data and use joins to recombine it. This minimizes data duplication and ensures consistency. Update a customer’s address in one place and it is reflected everywhere.
NoSQL databases typically denormalize data; they embed related data within documents or duplicate it across records. This makes reads fast but means updates to shared data require changing it in multiple places. If a customer’s address appears in a hundred order documents and the address changes, you have a hundred documents to update.
In practice, the choice depends on your read-to-write ratio and how frequently shared data changes. If you read orders a million times for every address change, denormalization makes sense. If addresses change constantly and consistency matters, normalization with joins is safer.
Horizontal Scaling
This is where NoSQL has a genuine architectural advantage. Most NoSQL databases were designed from the ground up for horizontal scaling, sharding data across multiple nodes with automatic rebalancing, replication, and failover.
Relational databases can scale horizontally, but it requires more effort and typically involves trade-offs. Read replicas are straightforward, but sharding writes while maintaining referential integrity and transaction isolation is hard. Solutions like Citus (for PostgreSQL), Vitess (for MySQL), and CockroachDB (a distributed SQL database) have made this more accessible, but the complexity is real.
That said, most applications do not need horizontal write scaling. A properly tuned PostgreSQL instance on modern hardware can handle thousands of transactions per second. I have personally managed single PostgreSQL instances handling 20,000 transactions per second on hardware that cost less than a junior engineer’s salary. Premature optimization for scale you will never reach is a real and common anti-pattern.
My Decision Framework
Here is how I actually choose between SQL and NoSQL in practice.
Start with PostgreSQL. I am serious. PostgreSQL handles relational data, JSON documents (with excellent indexing and querying), key-value patterns, full-text search, geospatial data, and time-series data. It is the Swiss Army knife of databases, and for the majority of applications, it is the right choice.
Move to a specialized NoSQL database when PostgreSQL cannot meet a specific, measured requirement. Not a hypothetical requirement. Not “we might need to scale someday.” A real, present requirement backed by actual load testing.
Common legitimate reasons to choose NoSQL:
- You need sub-millisecond key-value lookups at millions of operations per second (Redis, DynamoDB)
- Your data model is fundamentally a graph and you need multi-hop traversals (Neo4j)
- You are storing time-series data at massive ingestion rates (Cassandra, InfluxDB)
- You need to scale writes horizontally across regions with tunable consistency (Cassandra, DynamoDB)
- Your documents are genuinely schema-variant and self-contained (MongoDB)
Common illegitimate reasons I have seen people choose NoSQL:
- “SQL doesn’t scale” (it does, for most workloads)
- “We don’t want to deal with schemas” (you are going to deal with them anyway, just in worse places)
- “MongoDB is easier to get started with” (ease of getting started is not the same as ease of operating in production)
- “Everyone is using it” (this is not engineering)
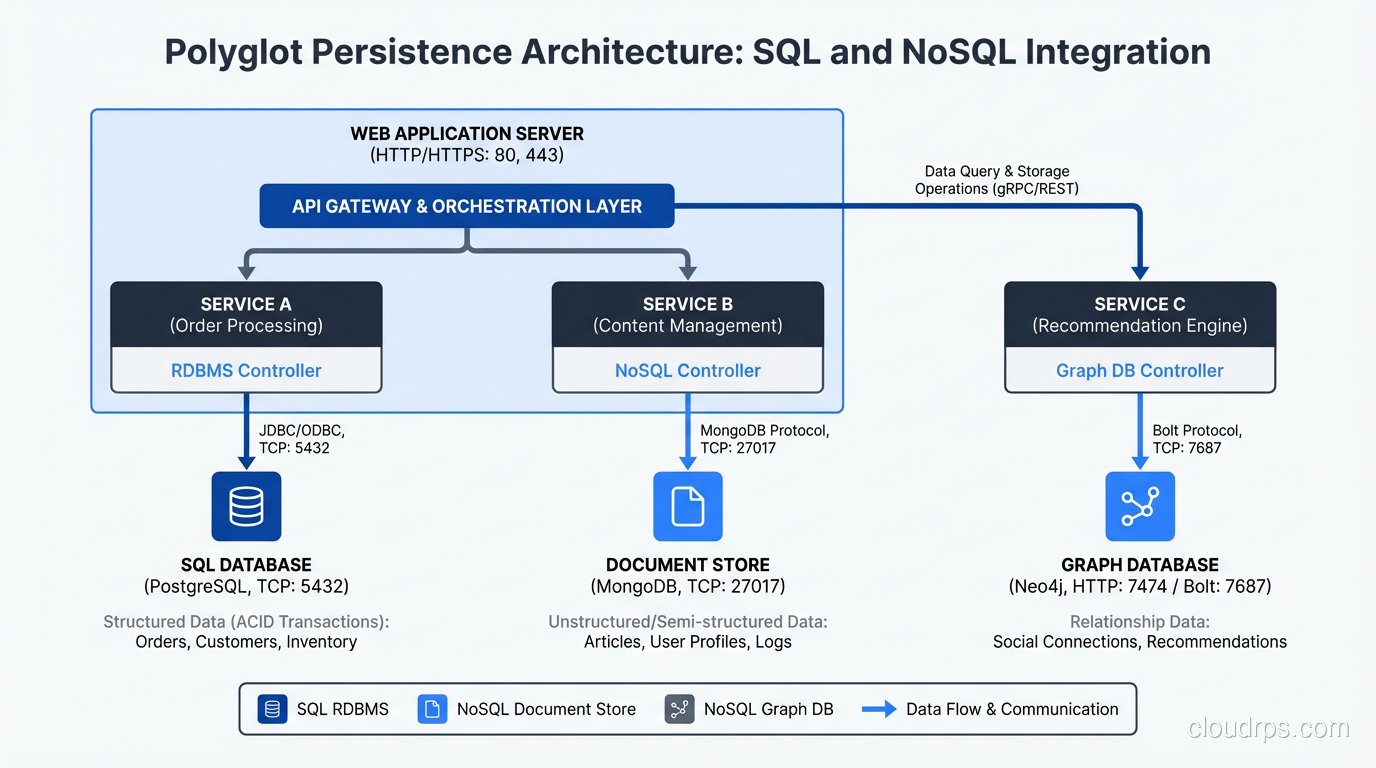
Polyglot Persistence: Use Both
The mature architectural approach is polyglot persistence: using different databases for different workloads within the same system. Your user accounts and financial transactions live in PostgreSQL. Your session data lives in Redis. Your product catalog lives in MongoDB. Your analytics live in ClickHouse.
This is not overcomplicated; it is appropriate specialization. You would not use a screwdriver to hammer a nail. Do not use a single database paradigm for every data storage need.
The key is to keep the number of databases manageable. I have seen teams with twelve different databases for one application, each chosen by whichever engineer happened to be on the project that week. That is not polyglot persistence, that is chaos. Two or three well-chosen databases will cover virtually any application. One addition worth knowing about if you are building AI features: PostgreSQL with the pgvector extension handles vector similarity search for embeddings, meaning many teams can skip a dedicated vector database entirely. The vector databases guide covers when pgvector is enough versus when you need Pinecone or Weaviate.
What I Wish I Had Known Earlier
The SQL vs NoSQL debate wasted years of industry energy because it was framed as an either-or choice when it was always a “right tool for the job” question. The NoSQL movement of the early 2010s produced some genuinely useful technology (Cassandra, Redis, and DynamoDB are all excellent at what they do) but it also produced a wave of bad architectural decisions driven by hype rather than analysis.
If you take one thing from this post, make it this: the most dangerous words in database selection are “I heard that…” followed by a generalization about an entire category of technology. SQL databases scale. NoSQL databases can ensure consistency. The specifics of your workload, your team’s expertise, and your operational requirements matter infinitely more than any category-level generalization.
Choose your database the way you choose any tool: by understanding what it is good at, what it is bad at, and whether those characteristics match what you actually need. Everything else is noise.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.