Stored procedures are the most polarizing topic in database architecture. I have worked with DBAs who insist that every piece of data access logic belongs in stored procedures, and I have worked with application developers who view stored procedures as a legacy antipattern that should be avoided entirely. After thirty years of building systems that use both approaches, and cleaning up the messes when either philosophy was taken to its extreme, I have opinions.
Strong ones.
The short version: stored procedures are a powerful tool for specific problems, and a terrible default for general application development. The long version is what follows.
What Stored Procedures Actually Are
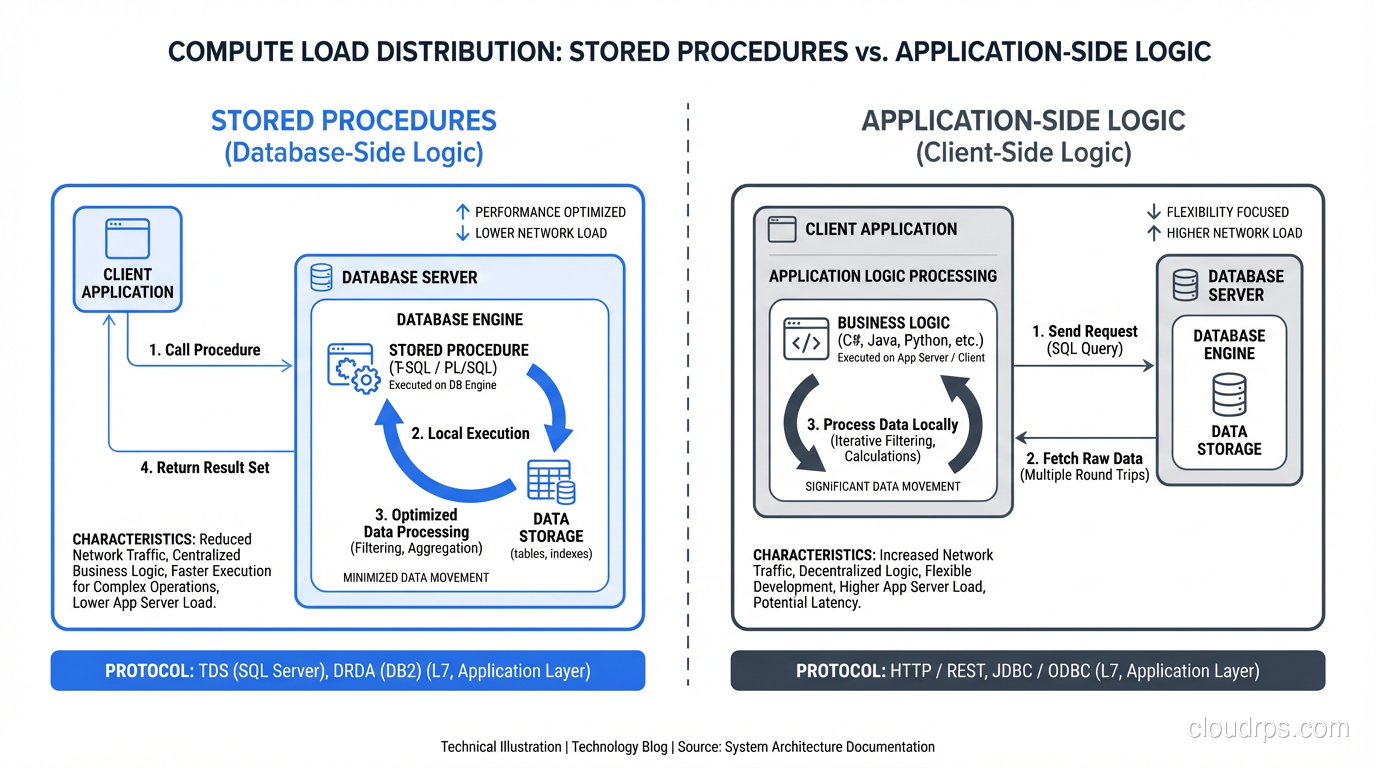
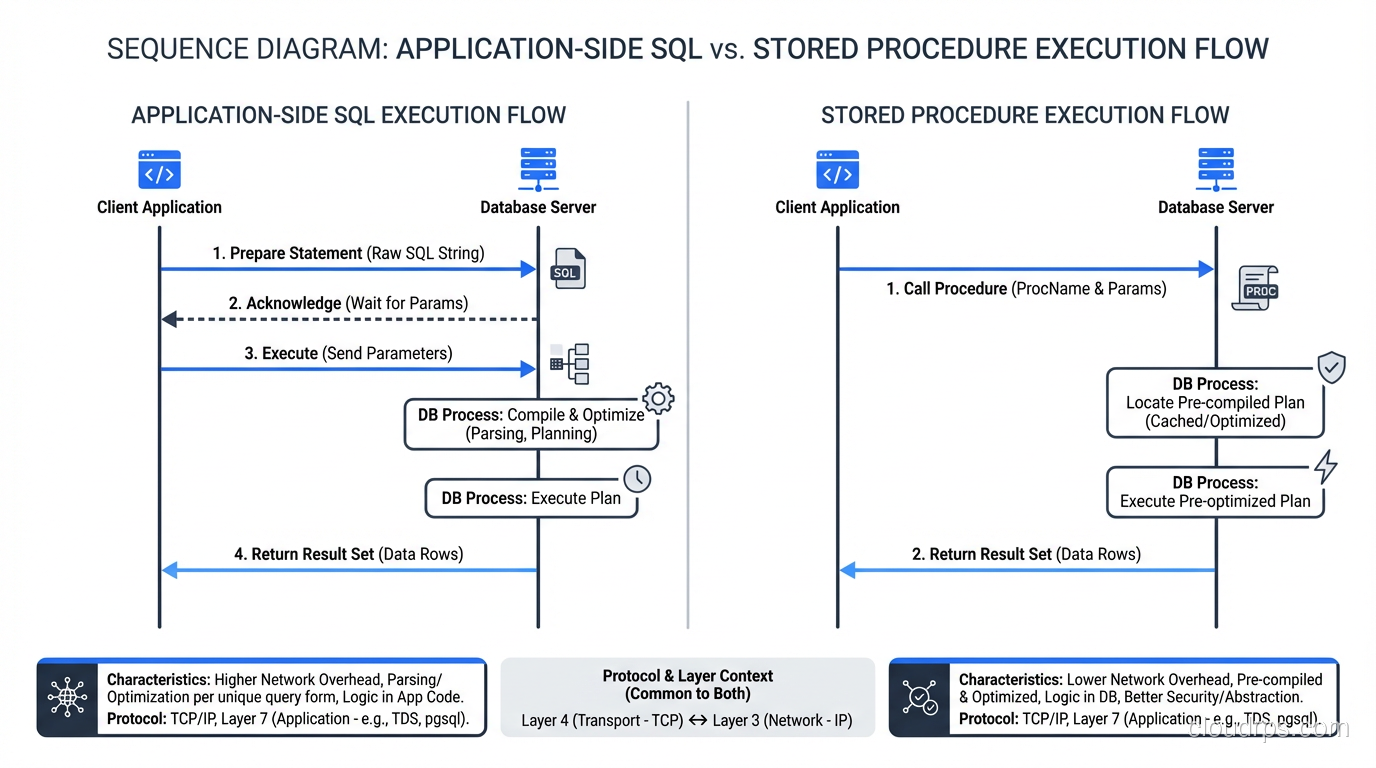
A stored procedure is a named block of SQL and procedural code that lives inside the database and is executed by the database engine. You write the procedure once, store it in the database catalog, and call it by name from your application. The database compiles the procedure (or at least parses and plans it) and can cache the execution plan for reuse.
In PostgreSQL, stored procedures are written in PL/pgSQL (or PL/Python, PL/Perl, PL/V8, and other extension languages). In SQL Server, they are written in T-SQL. In Oracle, PL/SQL. In MySQL, a limited SQL procedural language.
The defining characteristic is that the code runs inside the database process, with direct access to data without any network round trips. When a stored procedure reads a table, the data does not cross a network boundary; it goes from the storage engine to the procedure’s execution context within the same process.
This locality is both the greatest strength and the greatest risk of stored procedures.
When Stored Procedures Win: The Performance Case
There are specific scenarios where stored procedures provide performance that is difficult or impossible to achieve with application-side SQL. Let me walk through the ones I have actually encountered.
Reducing Network Round Trips
The most compelling use case for stored procedures is operations that require multiple SQL statements with conditional logic between them. Consider a workflow that needs to:
- Check if an account exists
- If it does, check the balance
- If the balance is sufficient, debit the account
- Insert a transaction record
- Update a summary table
From an application, this is five round trips to the database. If the database is across a network with 2ms latency, that is 10ms of network overhead alone, plus the time for each query. In a stored procedure, all five steps execute within the database with zero network overhead between them.
For high-throughput transactional workloads (payment processing, inventory management, booking systems) I have seen stored procedures reduce transaction latency by 40-60% compared to equivalent application-side logic, purely by eliminating network round trips.
Complex Set-Based Operations
Some operations are fundamentally better expressed in SQL than in application code. A stored procedure that performs a multi-table update with CTEs, window functions, and conditional logic executes as a single compiled plan inside the database. The equivalent application code would need to fetch data, process it in memory, and write results back, moving potentially millions of rows across the network.
I once rewrote a batch processing job that ran in Python, fetching 2 million rows, computing aggregates in pandas, and writing results back. The Python version took 45 minutes. The stored procedure version took 90 seconds. The data never left the database.
Encapsulating Business Rules Close to Data
When business logic absolutely must be consistent regardless of which application or service accesses the data, stored procedures provide a single enforcement point. If the rule “a customer cannot have a negative balance” must be enforced by the customer-facing web app, the admin API, the batch job, and the migration script, a stored procedure that encapsulates the balance check ensures consistency.
This is particularly valuable in environments with multiple applications accessing the same database, a pattern that is common in enterprise environments even if the microservice architecture purists disapprove.
When Stored Procedures Hurt: The Maintainability Case
Now for the other side. The problems with stored procedures are not performance problems; they are engineering problems. And in my experience, engineering problems cause more outages and more developer misery than performance problems.
Version Control and Deployment
Stored procedures live in the database, not in your application’s source code repository. This creates a bifurcated codebase where some logic is in Git and some logic is in the database catalog. Keeping these synchronized is a solved problem in theory (migration scripts, schema management tools like Flyway or Liquibase) but a constant source of friction in practice.
I have lost count of the number of times a deployment failed because the application code expected a stored procedure parameter that did not exist yet (or vice versa) because the database migration and the application deployment happened in the wrong order. Every team I have worked with that relies heavily on stored procedures has experienced this failure mode.
Testing
Testing stored procedures is harder than testing application code. Unit testing frameworks for PL/pgSQL exist (pgTAP, for example) but they are far less mature and less widely adopted than application-level testing frameworks. Integration testing stored procedures requires a running database instance, which makes CI pipelines slower and more complex.
The practical result is that stored procedures tend to be under-tested compared to application code. And under-tested code is the code that breaks in production.
Debugging
Debugging a stored procedure is painful. The tooling for step-through debugging of PL/pgSQL or T-SQL is significantly worse than what you get for Python, Java, or TypeScript. When a stored procedure fails in production, you are often working with error messages, log output, and manual RAISE/PRINT statements rather than a proper debugger.
Portability
Stored procedures are written in database-specific procedural languages. PL/pgSQL is not T-SQL is not PL/SQL. If you ever need to migrate databases (and in thirty years, I have done this more often than I expected) every stored procedure needs to be rewritten. For a system with hundreds of stored procedures, this is a multi-month effort.
For a broader discussion of database performance tuning that includes indexing, query optimization, and other approaches that do not require stored procedures, that post covers the full toolkit.
Scaling
Stored procedures run on the database server. The database server is typically the hardest component in your stack to scale horizontally. Moving complex business logic into stored procedures means moving compute work onto your most constrained resource.
Application servers are cheap and horizontally scalable. Database servers are expensive and vertically scalable (mostly). When a stored procedure consumes 30% of your database CPU computing business logic that could run on an application server, you are using your most expensive compute resource for work that could run on your cheapest.
My Guidelines: When to Use Stored Procedures
After decades of working with both approaches, here are the specific situations where I reach for stored procedures.
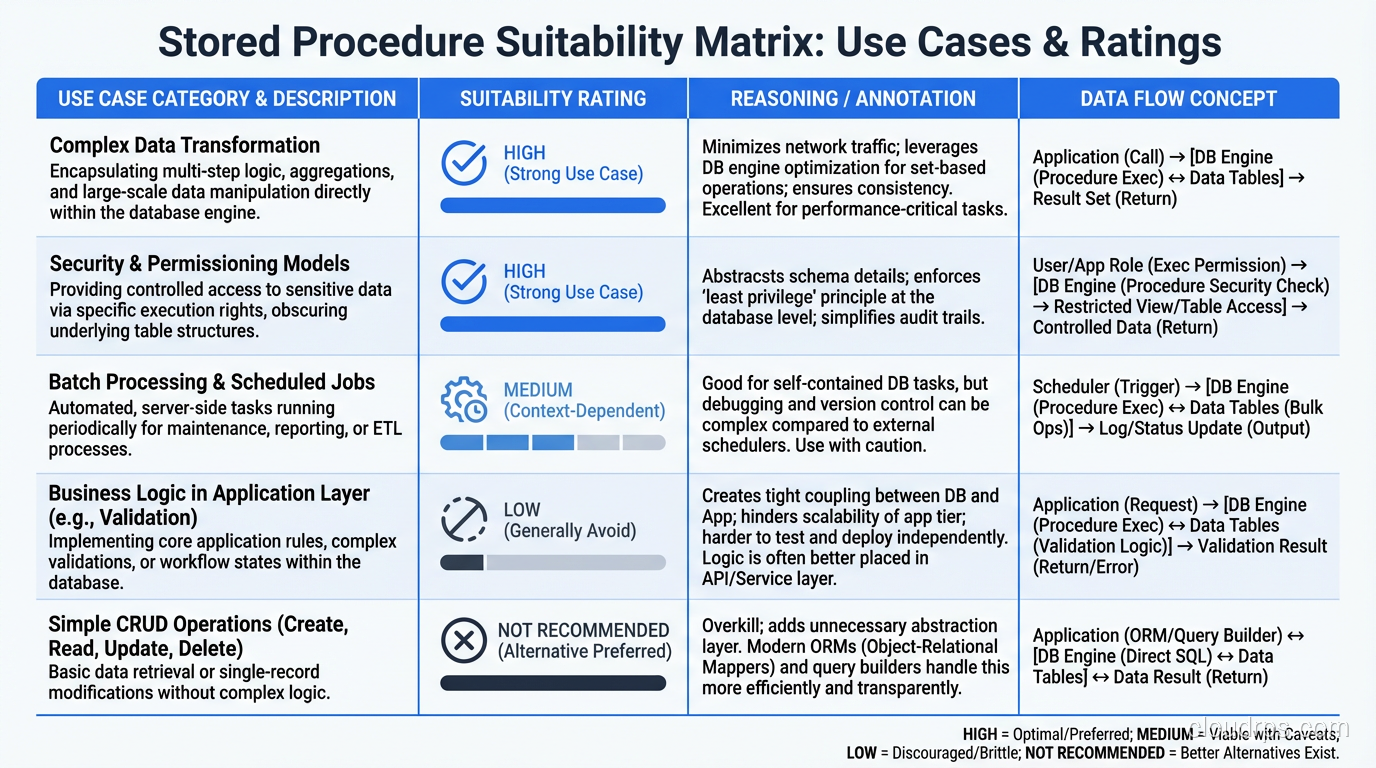
Use Them For: Data Integrity Constraints That Must Be Absolute
When a business rule must be enforced at the data layer regardless of which application accesses the database, a stored procedure (or trigger) is the right tool. Examples: preventing negative balances, enforcing complex referential integrity that check constraints cannot express, maintaining audit trails that must be tamper-proof.
Use Them For: High-Throughput Batch Operations
When you need to process millions of rows with complex logic and the data does not need to leave the database, stored procedures shine. ETL transforms, batch aggregations, data cleanup jobs. These are natural fits.
Use Them For: Security Boundaries
In environments where you want to restrict direct table access and expose only specific operations, stored procedures act as an API layer within the database. You grant EXECUTE on procedures but revoke SELECT/INSERT/UPDATE/DELETE on tables. The application can only interact with data through the procedures you have defined.
I use this pattern in healthcare and financial environments where data access must be auditable and controlled. It is not a replacement for application-level authorization, but it is a valuable defense-in-depth layer.
Avoid Them For: General CRUD Operations
Creating a stored procedure for every INSERT, UPDATE, DELETE, and SELECT in your application is busywork that adds complexity without adding value. ORMs and query builders handle CRUD operations perfectly well, and the performance difference for simple operations is negligible.
Avoid Them For: Business Logic That Changes Frequently
If your business rules change with every sprint, putting them in stored procedures means coordinating database deployments with application deployments for every change. This slows down development velocity. Keep rapidly evolving logic in the application layer where it can be deployed independently.
Avoid Them For: Logic That Needs Application Context
Stored procedures operate with database context: they know about tables, rows, and columns. They do not have access to application state, user session data, external API responses, or other context that application code naturally has. When business logic requires this context, forcing it into a stored procedure means passing excessive parameters or maintaining state tables, both of which are awkward.
The Stored Procedure Anti-Patterns
Let me describe the patterns I have seen cause the most pain.
The God Procedure
A single stored procedure that handles an entire business process (validation, computation, multiple table updates, error handling, notification triggers) in 2,000+ lines of PL/pgSQL. I inherited one of these that was 4,300 lines long. It had no tests, no documentation, and the original author had left the company. Debugging it required maintaining a mental model of dozens of temporary tables, cursor loops, and exception handlers.
Break large procedures into smaller ones. If a procedure is over 100 lines, it probably needs to be decomposed.
The ORM Bypass
A team uses an ORM for 95% of their data access but writes stored procedures for the remaining 5% “for performance.” The result is two data access patterns that need to be understood, maintained, and tested separately. The stored procedures gradually accumulate business logic that duplicates what the ORM layer does, and the two diverge over time.
If you need stored procedures for performance-critical paths, document clearly why the ORM was insufficient and ensure the stored procedure is tested as rigorously as the ORM-based code.
The Security Theater Procedure
Wrapping every SQL statement in a stored procedure “for security” without actually implementing row-level security, input validation, or audit logging within the procedures. The procedures are just thin wrappers around SQL statements, adding latency and complexity without adding security.
If you are using stored procedures for security, make them actually enforce security policies. Otherwise, you are paying the complexity cost without getting the security benefit.
Stored Procedures in the Modern Stack
The role of stored procedures has shifted over the last decade, and I think the current equilibrium is roughly right.
In the SQL vs NoSQL landscape, stored procedures are predominantly a relational database feature. Most NoSQL databases do not support them (MongoDB has server-side JavaScript, but it is deprecated and rarely used). This reflects the different philosophies: relational databases assume the database is smart and should contain logic; NoSQL databases assume the database is a dumb store and logic belongs in the application.
Modern application architectures (microservices, serverless, event-driven) tend to favor application-side logic because the benefits of horizontal scaling, independent deployment, and polyglot development outweigh the performance benefits of stored procedures for most workloads.
But “most workloads” is not “all workloads.” Financial systems, real-time bidding platforms, high-frequency trading systems, and other latency-sensitive applications still benefit enormously from stored procedures. The network round trip savings and set-based processing advantages are real and significant for these use cases.
If you are designing a schema and wondering whether to incorporate stored procedures, check my post on normalization and denormalization for related schema design considerations. The data modeling decisions you make influence whether stored procedures add value or just add complexity.
The Middle Ground That Works
Here is the architecture I have converged on for most systems:
Application layer handles business logic, validation, authorization, and orchestration. Written in whatever language the team is productive in. Tested with standard application testing frameworks. Deployed independently of the database.
Database layer handles data integrity constraints (CHECK constraints, foreign keys, triggers for audit trails), complex batch operations (stored procedures for ETL and batch processing), and security boundaries (stored procedures with restricted direct table access where required).
The boundary is clear: if the logic primarily manipulates data within the database, it belongs in the database. If it primarily orchestrates application behavior, it belongs in the application. The gray area is small, and when in doubt, I default to the application layer because it is easier to refactor later.
This is not a compromise; it is a deliberate architecture that leverages the strengths of each layer. The database does what it is best at: managing data. The application does what it is best at: managing behavior. Neither tries to do the other’s job.
Stored procedures are a scalpel. They are precise, effective, and dangerous in the wrong hands. Use them where they solve real problems. Avoid them where they create unnecessary complexity. And whatever you do, test them with the same rigor you apply to the rest of your codebase.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.