The moment I knew batch processing wasn’t going to cut it anymore was during a Black Friday event in 2015. I was running analytics for a major retailer, and our batch pipeline had a four-hour lag. By the time we saw that a pricing error was sending a $400 item out the door at $4, we’d already shipped 11,000 units. The post-mortem was brutal. Management wanted to know why we couldn’t see this happening in real time, and the honest answer was: because our architecture processed data in batches, and batches are slow.
That experience sent me down the stream processing path, and I’ve been building real-time data systems ever since. Stream processing fundamentally changes how you think about data. Instead of data at rest that you query periodically, you have data in motion that you react to continuously. It’s a different paradigm, with different tools, different failure modes, and different trade-offs.
What Stream Processing Actually Means
Stream processing is the continuous, record-by-record (or micro-batch) processing of data as it arrives. Instead of collecting data into a batch, processing it, and writing results, you process each event or message as soon as it shows up.
The distinction from batch processing isn’t just about speed; it’s about the computation model. In batch processing, you have a complete dataset and compute a result. In stream processing, you have an incomplete, potentially infinite dataset and compute continuously evolving results.
This shift introduces challenges that don’t exist in batch:
- Ordering: Events can arrive out of order due to network delays, retries, or distributed sources.
- Late data: Events from hours or days ago might arrive after you’ve already computed results for that time period.
- State management: Many stream computations (aggregations, joins, windows) require maintaining state across events, and that state needs to survive failures.
- Exactly-once semantics: Processing each event exactly once (not zero times, not twice) is genuinely difficult in a distributed system.
The Building Blocks: Kafka, Flink, and Friends
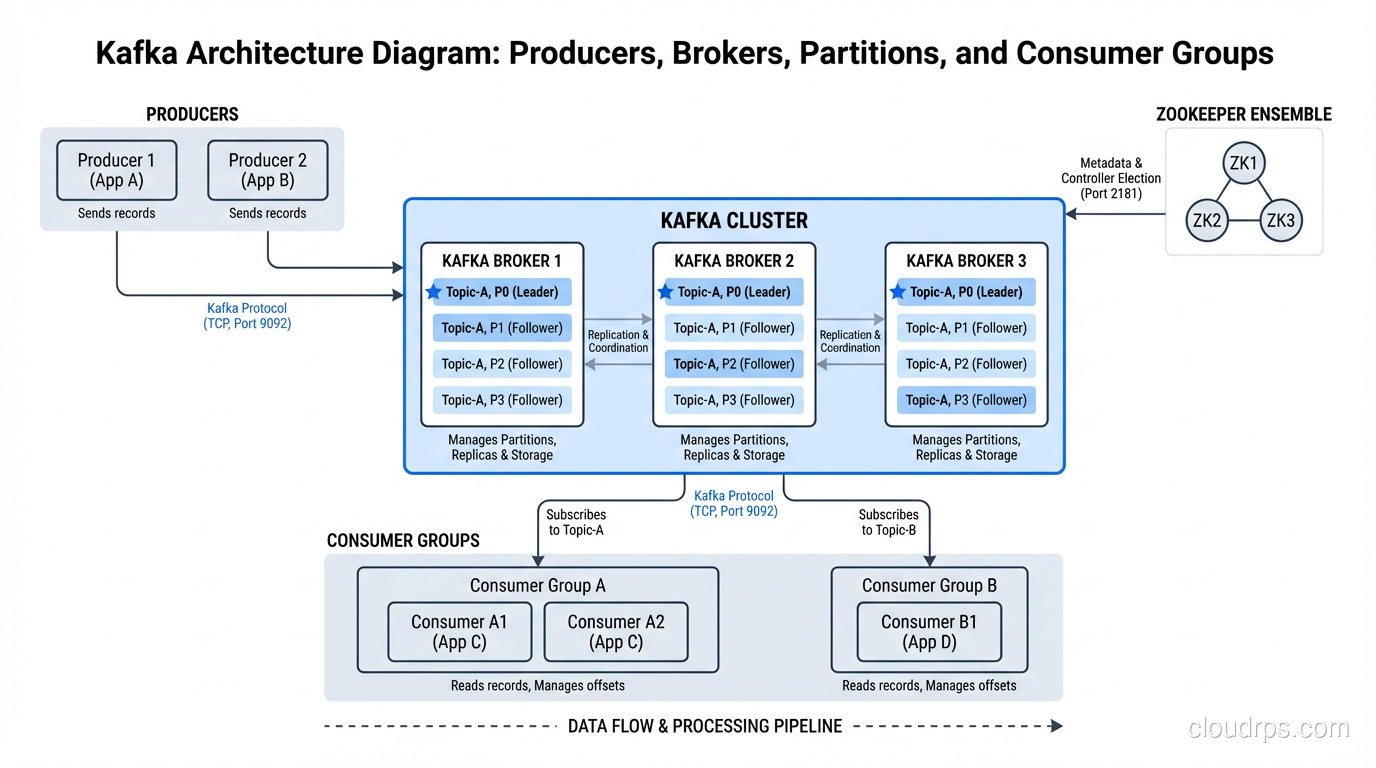
Apache Kafka: The Message Backbone
Kafka isn’t a stream processor. It’s a distributed event streaming platform. Think of it as a durable, ordered, replayable log. Producers write events to topics, topics are partitioned across brokers for scalability, and consumers read events from topics.
What makes Kafka special:
- Durability: Events are persisted to disk and replicated across brokers. You don’t lose data when a consumer goes down.
- Ordering guarantees: Events within a partition are strictly ordered. This is critical for use cases where event sequence matters.
- Replayability: Consumers can re-read events from any point in time. This is enormously valuable for debugging, reprocessing, and backfilling.
- Decoupling: Producers and consumers are completely independent. You can add new consumers to a topic without changing producers.
Kafka’s role in a streaming architecture is as the central nervous system. Every event flows through Kafka, and downstream systems (stream processors, databases, search indexes, analytics engines) consume from it.
I’ve run Kafka clusters handling over 2 million events per second. The technology scales. The operational overhead, however, is significant. Broker management, partition rebalancing, consumer group coordination, schema evolution: these are all real production concerns. If you’re on AWS, MSK handles some of this. If you want to eliminate operations entirely, Confluent Cloud is worth considering, though it’s not cheap.
Kafka Streams: Processing Within Kafka
Kafka Streams is a lightweight stream processing library that runs inside your application, with no separate cluster required. You write Java or Kotlin code that reads from Kafka topics, processes events, and writes results back to Kafka topics.
I reach for Kafka Streams when the processing logic is straightforward: filtering, mapping, simple aggregations, joining two streams. It’s embedded in your application, scales by running more instances, and uses Kafka itself for fault tolerance.
Where Kafka Streams falls short: complex event processing, large state management, and anything requiring advanced windowing. For those, you need a dedicated stream processing engine.
Apache Flink: The Heavy Lifter
Flink is a full-fledged distributed stream processing framework. It runs as a cluster (standalone, on YARN, on Kubernetes), manages its own state, handles complex event processing, and provides exactly-once semantics.
What Flink does well:
- Event time processing: Flink’s watermark mechanism handles out-of-order events correctly. You define how late data is allowed to be, and Flink manages the complexity.
- Stateful processing: Flink maintains state in a way that survives failures through checkpointing. The state can be enormous. I’ve run Flink jobs with terabytes of state.
- Complex windowing: Tumbling windows, sliding windows, session windows, custom windows. Flink handles them all with a clean API.
- Exactly-once semantics: Through checkpointing and two-phase commit with external systems, Flink can guarantee exactly-once processing end-to-end.
Flink’s SQL layer (Flink SQL) has matured significantly and is now my recommendation for teams that want stream processing without writing Java. You define sources, sinks, and transformations in SQL, and Flink compiles it into a distributed streaming job.
Spark Structured Streaming
I’d be remiss not to mention Spark Structured Streaming. If your team already uses Spark for batch processing on Hadoop or in a data lake, Structured Streaming lets you use the same DataFrame API for streaming workloads.
The trade-off: Spark processes streams in micro-batches (though continuous processing mode exists, it’s less mature). This means your latency floor is typically in the hundreds of milliseconds to low seconds range, not the sub-millisecond range that Flink can achieve.
For many use cases, that latency is perfectly fine. If you need data within 5 seconds rather than 5 hours, Spark Structured Streaming might be the pragmatic choice, especially if you already have Spark expertise.
Architecture Patterns
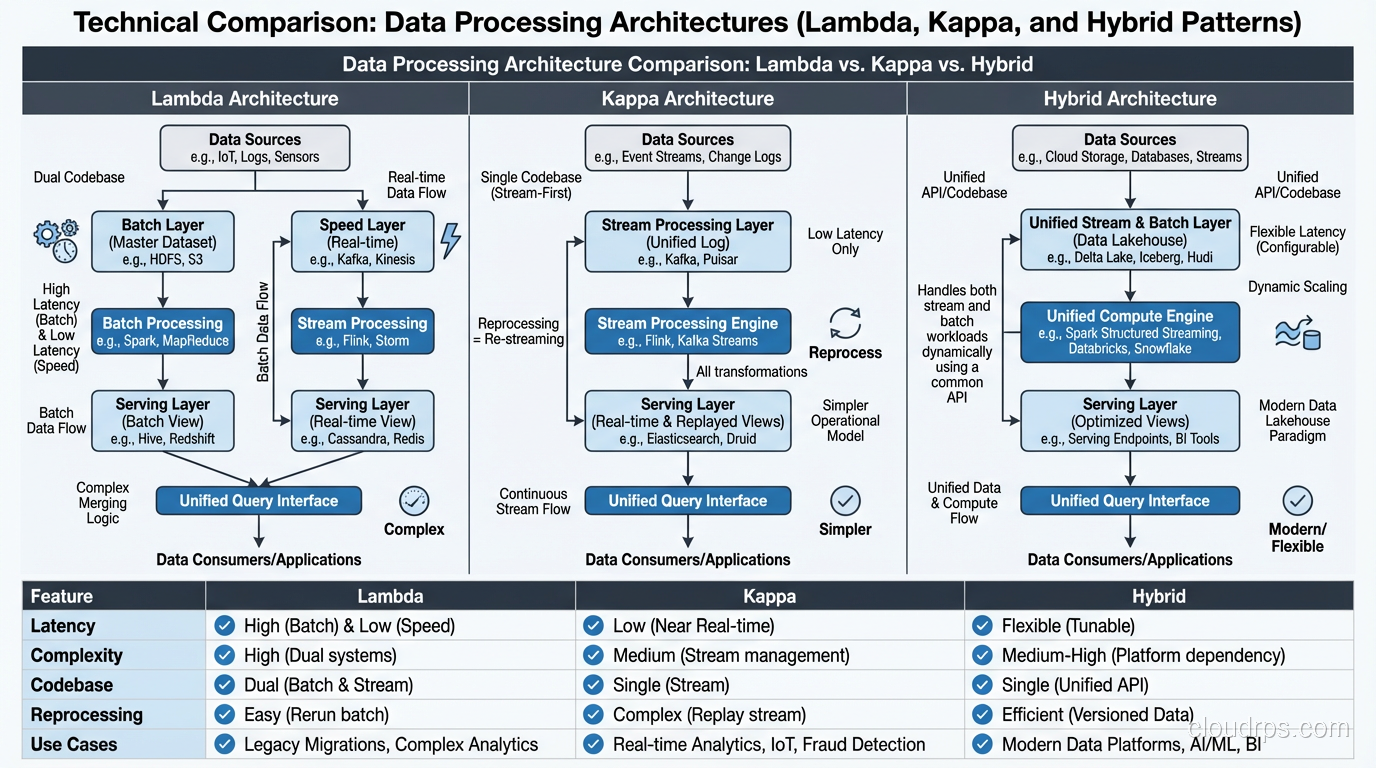
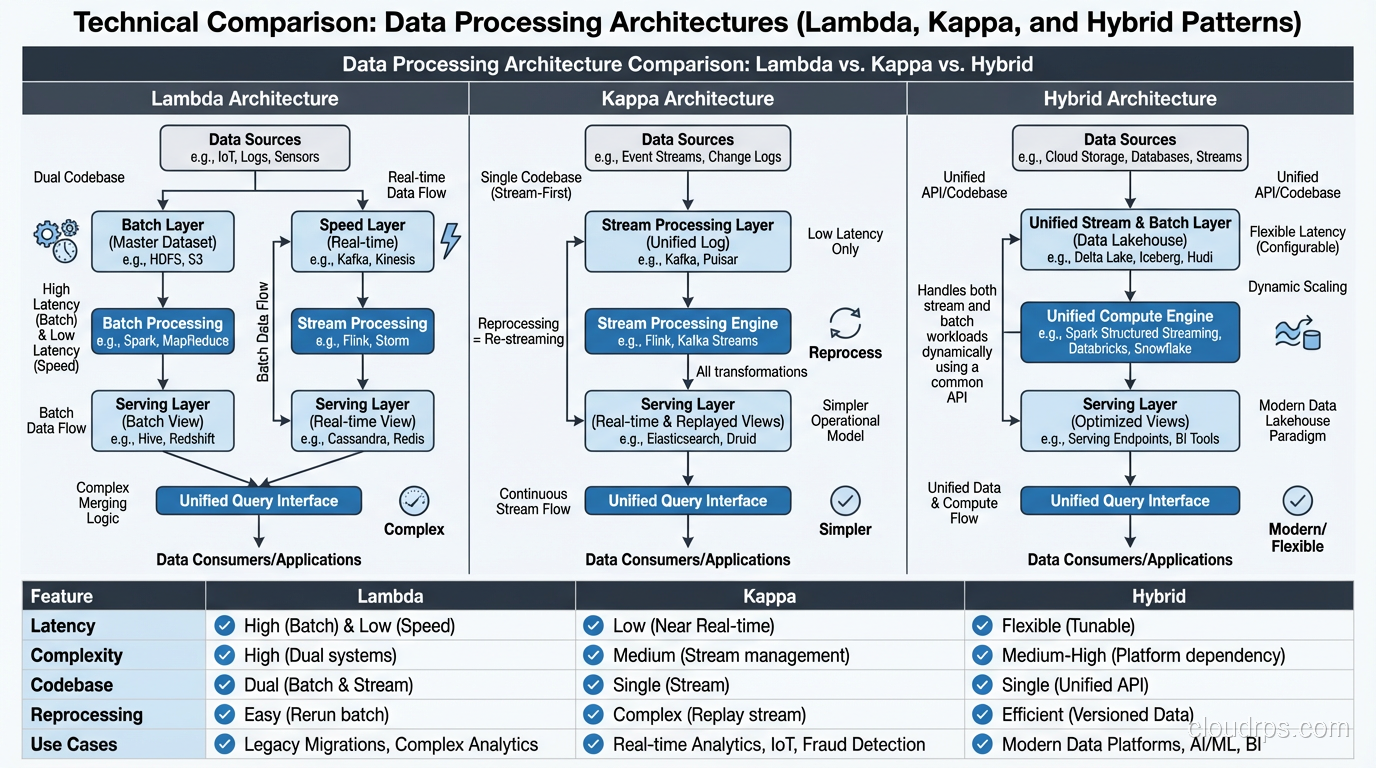
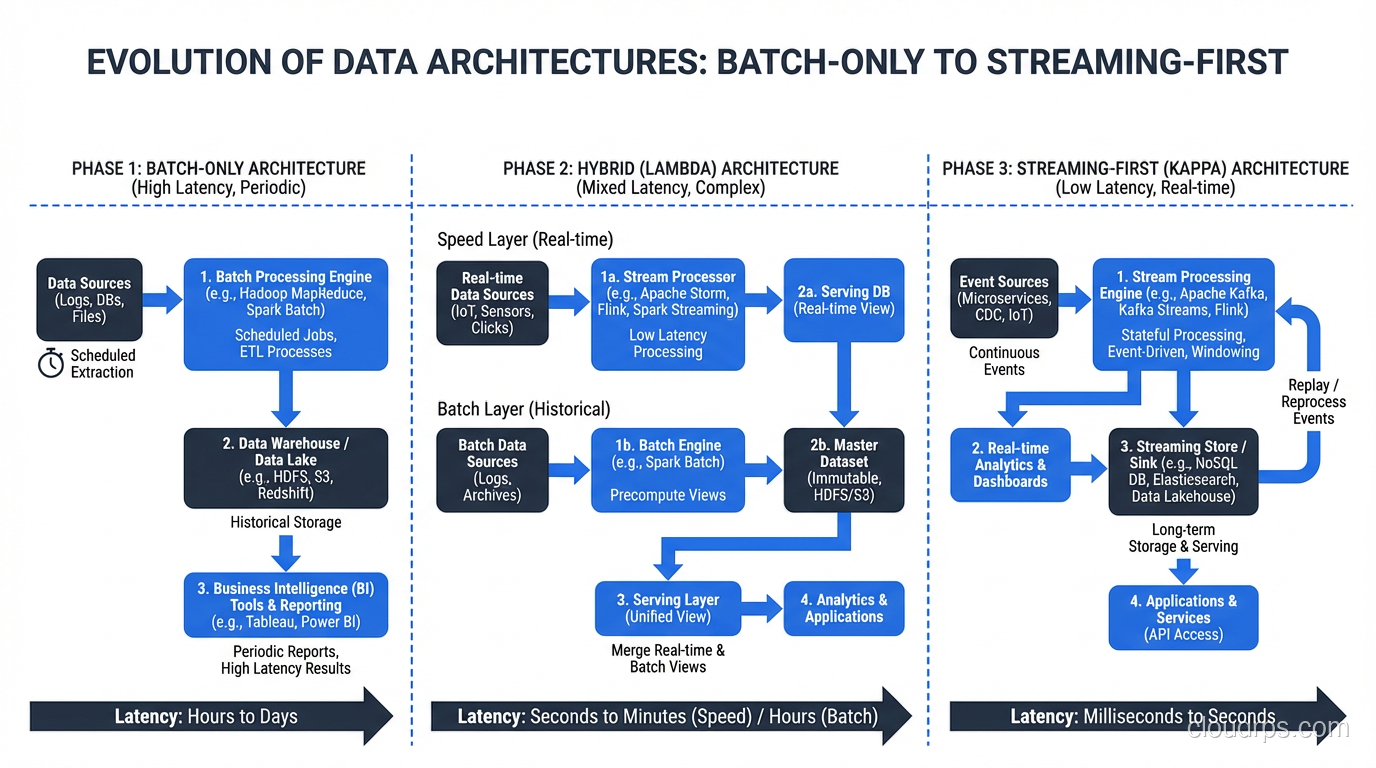
Lambda Architecture
The Lambda architecture runs two parallel paths: a batch layer for comprehensive, accurate processing and a speed layer for low-latency approximate processing. A serving layer merges results from both paths.
I implemented Lambda architectures at three different companies between 2014 and 2018. They work, but they’re operationally painful. You’re maintaining two codebases (batch and streaming) that need to produce consistent results. Every schema change, every business logic update has to be implemented twice. The testing burden is substantial.
Kappa Architecture
The Kappa architecture simplifies by eliminating the batch layer. Everything is a stream. If you need to reprocess historical data, you replay the stream from the beginning.
This works when Kafka (or your streaming platform) retains data long enough for reprocessing and your stream processing engine can handle the replay throughput. In practice, I’ve seen Kappa work well for event-driven systems where the processing logic is relatively stable.
The Pragmatic Hybrid
Most production systems I build today use a hybrid approach. Streaming handles low-latency use cases (fraud detection, real-time dashboards, operational alerts). Batch handles heavy analytics (monthly reporting, ML model training, complex aggregations over large historical windows).
The key: both paths write to the same output tables (often in a lakehouse format like Delta Lake or Iceberg), so consumers see a unified view regardless of how the data was processed.
Lessons From Production Streaming Systems
Lesson 1: Schema Evolution Will Bite You
In batch processing, you can update the schema and reprocess the entire dataset. In streaming, your producer might deploy a new schema while consumers are still expecting the old one. Without a schema registry (Confluent Schema Registry, AWS Glue Schema Registry) enforcing compatibility, you’ll have deserialization failures at 3 AM.
Use Avro or Protobuf with a schema registry. Enforce backward compatibility by default. Make breaking changes through a new topic, not by modifying the existing schema.
Lesson 2: Backpressure Is Your Friend
When a stream processor can’t keep up with incoming data, it has two options: buffer (and eventually run out of memory) or apply backpressure (signal upstream to slow down).
Flink handles backpressure automatically through its network buffer pool. Kafka’s consumer-based pull model provides natural backpressure, since consumers pull at their own pace. But downstream sinks (databases, APIs) don’t always handle burst traffic gracefully.
I always build rate limiters and circuit breakers on the sink side of streaming pipelines. The last thing you want is a streaming job overwhelming a production database because upstream throughput spiked.
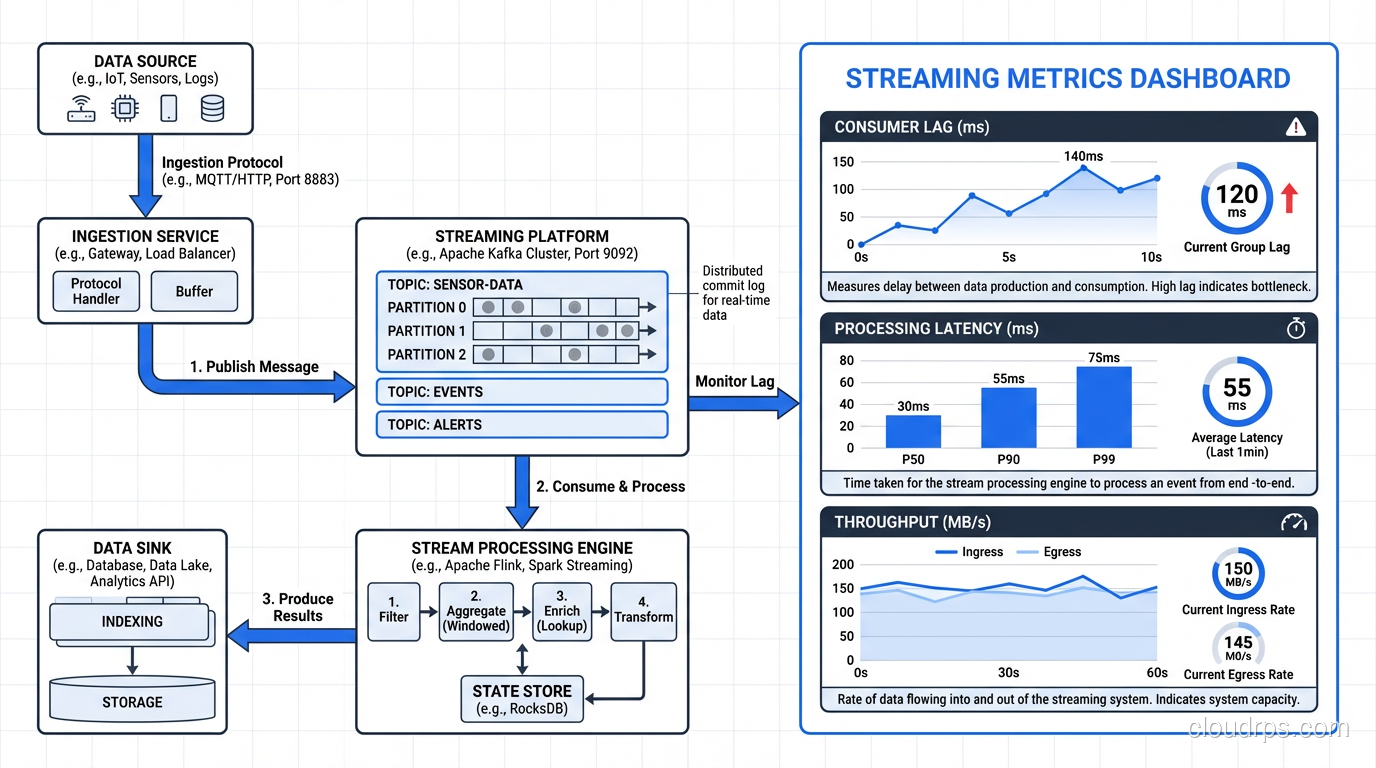
Lesson 3: Monitoring Streaming Systems Is Different
The metrics that matter for streaming systems are different from batch:
- Consumer lag: How far behind is your consumer from the latest event? This is the single most important metric. Rising lag means you’re falling behind.
- Processing latency: Time from event creation to processing completion. Separate this from end-to-end latency, which includes network, serialization, and sink write time.
- Checkpoint duration: For Flink, how long checkpoints take directly affects your recovery time. Long checkpoints mean slow restarts.
- Throughput: Events per second, bytes per second. Track these at every stage of the pipeline.
Lesson 4: Exactly-Once Is Expensive
Exactly-once processing semantics require coordination between the stream processor, the source, and the sink. Flink achieves this through checkpointing plus two-phase commit on the sink. Kafka achieves it through idempotent producers and transactional consumers.
This coordination adds latency and reduces throughput. In my experience, exactly-once processing is 20-40% slower than at-least-once. For many use cases (metrics aggregation, log processing, non-financial analytics), at-least-once with idempotent writes is the better trade-off.
Reserve exactly-once for use cases where duplicate processing has real business consequences: financial transactions, inventory updates, billing events.
Lesson 5: Test With Production-Scale Data
I’ve seen more streaming systems fail in production than in any other category of infrastructure. The reason is almost always the same: the system worked fine with test data (thousands of events per second) but fell over at production scale (hundreds of thousands or millions of events per second).
State store performance degrades non-linearly with state size. Serialization overhead that’s invisible at low throughput becomes a bottleneck at high throughput. Garbage collection pauses that are harmless with small heaps become stop-the-world events with large heaps.
Load test with production-scale data. Period. No exceptions.
Choosing Between Kafka Streams, Flink, and Spark Streaming
Here’s my decision tree after building streaming systems across all three:
Choose Kafka Streams when:
- Processing logic is simple (filter, map, basic aggregation)
- You want to avoid running a separate cluster
- Latency requirements are moderate (sub-second is achievable)
- Your team is already comfortable with Kafka
Choose Flink when:
- Processing logic is complex (windowed aggregations, event-time processing, complex joins)
- State is large (gigabytes or terabytes)
- You need exactly-once semantics end-to-end
- Latency requirements are strict (milliseconds)
- You’re processing events from sources beyond Kafka
Choose Spark Structured Streaming when:
- You already use Spark for batch processing and want a unified codebase
- Micro-batch latency (seconds) is acceptable
- Your team has Spark expertise but not Flink expertise
- You want tight integration with a data lake or lakehouse
For deeper context on how these tools fit alongside databases for different workload patterns, see SQL vs NoSQL databases.
Where Stream Processing Is Heading
The convergence of batch and streaming is the dominant trend. Flink’s batch mode, Spark’s streaming mode, and lakehouse table formats that handle both batch and streaming writes. The industry is moving toward unified engines that treat batch as a special case of streaming (a bounded stream).
The other major trend is managed services. Confluent Cloud, Amazon Kinesis Data Analytics (which runs Flink under the hood), Google Dataflow. These services eliminate the operational burden of running streaming infrastructure. For most teams, the operational complexity of self-managing Kafka and Flink isn’t worth it. The managed service premium is real money, but it’s cheaper than the engineering time you’d spend on operations.
Stream processing went from a niche capability to a core part of modern data architecture in about a decade. If you’re still running purely batch pipelines with multi-hour lag, you’re leaving real-time insights, and real-time business value, on the table.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.